NCache Leistungsbenchmarks
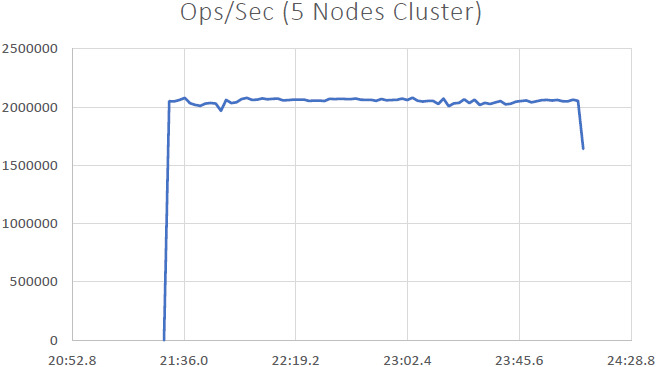
2 Millionen Operationen/Sek
(5-Knoten-Cluster)
Executive Summary
NCache kann Ihnen dabei helfen, die Leistung einfach und kosteneffizient linear zu skalieren und zu steigern. Fortune-500-Unternehmen auf der ganzen Welt haben darauf vertraut NCache seit über 13 Jahren, um Leistungsengpässe im Zusammenhang mit Datenspeicherung und Datenbanken zu beseitigen und .NET-Anwendungen auf Extreme Transaction Processing (XTP) zu skalieren.
Dieses Dokument wird verwendet NCache 5.0 mit modernen APIs und einigen neuen Funktionen, um die lineare Skalierbarkeit und extreme Leistung zu demonstrieren, die Sie für Ihre .NET-Anwendungen erreichen können. In diesem Experiment haben wir ein Modem gebündelt NCache API mit einer partitionierten Cache-Topologie mit aktiviertem Pipelining. Die Daten werden vollständig auf alle Caching-Server verteilt und Clients stellen für Lese- und Schreibanfragen eine Verbindung zu allen Servern her.
In diesem Benchmark zeigen wir, dass die NCache Cluster kann linear skaliert werden und das haben wir erreicht 2 Millionen Transaktionen pro Sekunde mit nur 5 Cache-Serverknoten. Auch das werden wir demonstrieren NCache kann selbst in einem großen Cluster eine Latenzzeit von weniger als einer Mikrosekunde liefern. In diesem Whitepaper behandeln wir Benchmark-Einstellungen, Schritte zur Durchführung von Benchmarks, Testkonfigurationen, Lastkonfigurationen und Ergebnisse. Hier können Sie das Benchmark-Experiment in Aktion sehen Video.
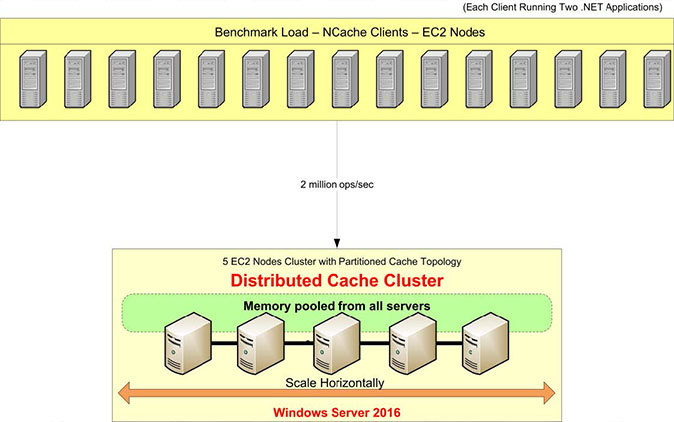
Übersicht über die Benchmark-Einrichtung
Sehen wir uns unser Benchmark-Setup an. Für diesen Test werden wir AWS m4.10xlarge-Server verwenden. Wir haben fünf davon NCache Server, auf denen wir unseren Cache-Cluster konfigurieren. Wir werden 15 Client-Server haben, von denen aus wir Anwendungen ausführen, um eine Verbindung zu diesem Cache-Cluster herzustellen.
Als Betriebssystem verwenden wir Windows Server 2016 – Data Center Edition, 64-Bit. Der NCache Die verwendete Version ist 5.0 Enterprise. In diesem Benchmark-Setup verwenden wir a Partitionierte Cache-Topologie. In einer Partitioned-Cache-Topologie werden alle Daten vollständig in Partitionen auf allen Caching-Servern verteilt. Und alle Clients werden für Lese- und Schreibanfragen mit allen Servern verbunden, um alle Server gleichzeitig zu nutzen. Für diese Topologie ist die Replikation nicht aktiviert, aber es gibt andere Topologien wie die Partitionierte Replikattopologie das mit Replikationsunterstützung ausgestattet ist.
Wir werden haben Pipelining aktiviert, was eine neue Funktion in ist NCache 5.0. Es funktioniert so, dass es auf der Clientseite alle Anfragen sammelt, die zur Laufzeit erfolgen, und diese Anfragen auf der Serverseite sofort anwendet. Die Akkumulation erfolgt in Mikrosekunden, ist also sehr optimiert und ist die empfohlene Konfiguration, wenn Sie hohe Anforderungen an die Transaktionslast haben.
Hier finden Sie einen kurzen Überblick über unser Benchmark-Setup, einschließlich Hardware, Software und Lastkonfigurationen.
Hardware-Konfiguration:
| Client- und Serverdetails (Virtuelle Maschine) |
AWS m4.10xlarge: 40 Kerne, 160 GB Speicher, Netzwerk – 10 Gbit/s Ethernet |
| Anzahl der Serverknoten | 5 |
| Anzahl der Client-Knoten | 15 |
Softwarekonfiguration:
| Betriebssystem | Windows Server 2016 Data Center Edition – x64 |
| NCache Version | 5.0 |
| Cluster-Topologie | Partitionierte Cache-Konfiguration |
Konfiguration laden:
| Cache-Größe | 4 GB |
| Datengröße | Byte-Array der Größe 100 |
| Gesamtanzahl | 1,000,000 |
| Pipelining | Aktiviert |
| Get/Update-Verhältnis | 80:20 |
| Themen | 1280 |
| Anwendungsinstanzen | 2 Instanzen pro Client-Maschine, insgesamt 30 Instanzen |
Datenpopulation
Nach der Einrichtung unserer Benchmark-Umgebung beginnen wir mit einer Datenpopulation von 1 Million Elementen im Cache-Cluster. Wir werden die Client-Anwendung (Cache Item Loader) ausführen, die eine Verbindung herstellt und 1 Million Elemente zum Cache hinzufügt. Ein Client stellt eine Verbindung zu allen Caching-Servern her und fügt 1 Million Elemente zum Cache-Cluster hinzu. Anschließend können wir mit Lese- und Schreibanforderungen beginnen.
Sie können diese Nuget-Paket – NCache SDK um das SDK auf dem Client-Computer zu installieren und das Pipelining zwischen dem Client-Server zu konfigurieren und die Load Generation Application (GitHub) bereitzustellen, um 1 Million Cache-Elemente im Cache-Cluster zu füllen.
Transaktionslast aufbauen
Wir werden nun die Anwendung ausführen, um eine gewisse Transaktionslast auf diesem Cache-Cluster mit 80 % Lese- und 20 % Schreibvorgängen aufzubauen. Sie können alle Aktivitäten mithilfe von Perfmon-Zählern überwachen. Zunächst werden wir jeweils 10 Client-Instanzen verbinden NCache Server mit Aktivität bei Abrufen und Aktualisierungen pro Sekunde.
Stufe 1 Million Operationen/Sek. Transaktionslast
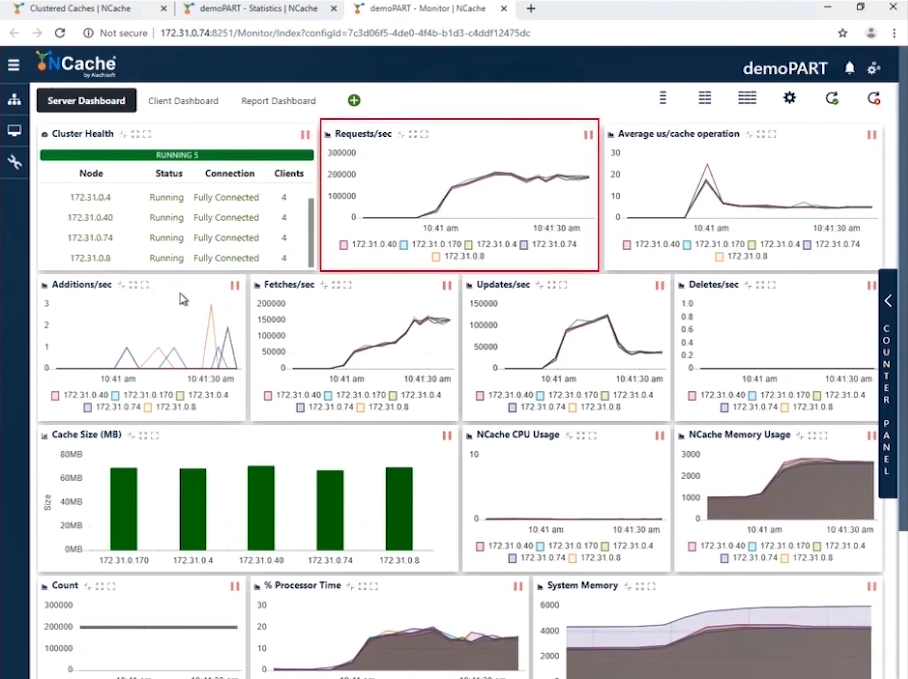
Im Screenshot sehen Sie, dass wir bei 10 Client-Instanzen, die sich mit einem 5-Knoten-Cluster verbinden, Anfragen pro Sekunde haben, die zwischen 180,000 und 190,000 liegen. Und da wir 5 haben NCache Bei parallel arbeitenden Servern erreicht die Anhäufung dieser Anfragen eine Million Anfragen pro Sekunde durch diesen Cache-Cluster.
Wir haben eine effiziente Speicher- und CPU-Auslastung und der durchschnittliche Mikrosekunden-/Cache-Vorgang beträgt etwas weniger als 10 Mikrosekunden pro Vorgang. Unsere erste Phase ist abgeschlossen, wo wir 1 Million Operationen pro Sekunde aus unserem Cache-Cluster erreicht haben.
| Stufe 1 – Zusammenfassendes Datenblatt | |
| Gesamtzahl der Cache-Server im Cluster | 5 |
| Gesamtzahl der verbundenen Client-Instanzen | 10 |
| Anfragen pro Sekunde/Knoten | 180,0000 ~ 190,000 |
| Gesamtanzahl der Anfragen – Cache-Cluster | 950,000 ~ 1,000,000 |
| % Prozessorzeit (Max) | 20% |
| System Memory | 4.2 GB |
| Latenz (Mikrosekunden-/Cache-Vorgang) | 10 Mikrosekunden/Operation |
Stufe 1.5 Million Operationen/Sek. Transaktionslast
Nachdem wir nun die 1 Million TPS erreicht haben, ist es an der Zeit, die Last in Form weiterer Anwendungsinstanzen zu erhöhen, um die Transaktionslast zu erhöhen. Und sobald diese Anwendungen ausgeführt würden, würden Sie einen Anstieg der Anfragen pro Sekunde feststellen. Wir werden die Anzahl der Clients auf 20 erhöhen. Mit dieser Konfiguration können Sie im Screenshot unten sehen, dass wir jetzt 300,000 Anfragen pro Sekunde und Instanz anzeigen. Wir haben erfolgreich 1.5 Millionen Anfragen pro Sekunde von diesem Cache-Cluster erreicht.
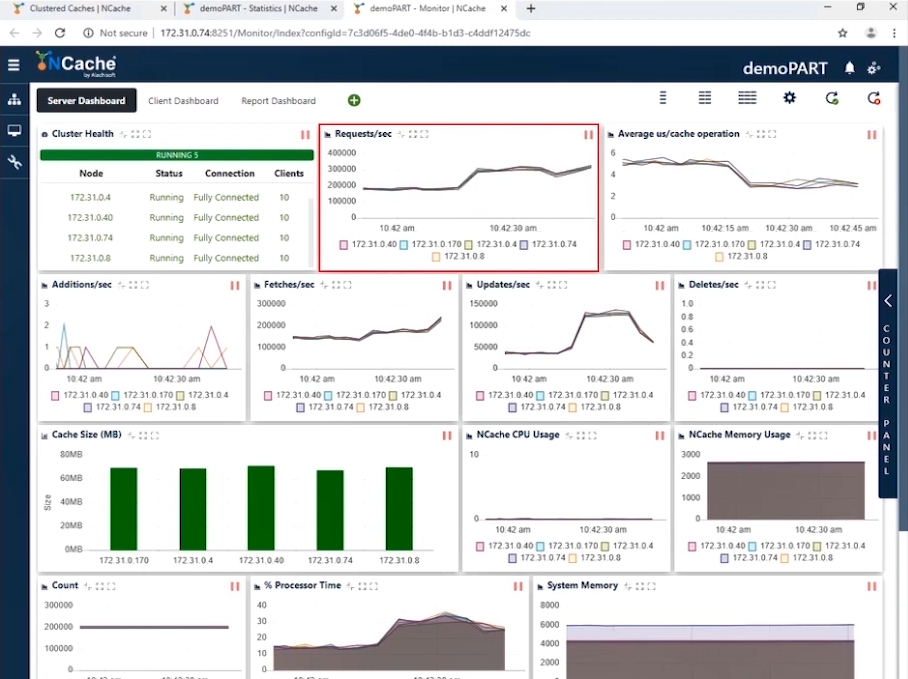
Sie können sehen, dass die Anzahl der Anfragen pro Sekunde von jedem Server 300,000 beträgt. Die Anzahl der Abrufe beträgt etwas mehr als 200,000 pro Sekunde und die Aktualisierungen liegen zwischen 50,000 und 100,000. Sie können sehen, dass die durchschnittliche Mikrosekunde pro Cache-Vorgang weniger als 4 Mikrosekunden beträgt. Das ist erstaunlich, da wir zusammen mit den Auswirkungen des Pipelinings eine sehr geringe Latenz haben. Wenn Sie auf Client-Seite eine hohe Transaktionslast haben, hilft Pipelining wirklich, reduziert die Latenz und erhöht den Durchsatz. Aus diesem Grund empfehlen wir, dies zu aktivieren. Darüber hinaus liegt die durchschnittliche Mikrosekunde pro Cache-Vorgang jetzt bei etwa 3–4 Mikrosekunden pro Cache-Vorgang.
| Stufe 2 – Zusammenfassendes Datenblatt | |
| Gesamtzahl der Cache-Server im Cluster | 5 |
| Gesamtzahl der verbundenen Client-Instanzen | 20 |
| Durchschn. Anfragen pro Sekunde/Knoten | 300,000 |
| Gesamtanzahl der Anfragen – Cache-Cluster | 1,500,000 |
| % Prozessorzeit (Max) | 30% |
| System Memory | 6 GB |
| Latenz (Mikrosekunden-/Cache-Vorgang) | 3 ~ 4 Mikrosekunden/Betrieb |
Stufe 2 Million Operationen/Sek. Transaktionslast
Erhöhen wir die Auslastung weiter, indem wir einige weitere Anwendungsinstanzen ausführen, was ebenfalls zu einem weiteren Anstieg der Anfragen pro Sekunde führen wird. Wir werden jetzt die Instanzen von 30 Clients mit allen verbinden NCache Servers
Auf dem Screenshot unten können Sie nun sehen, dass wir 400,000 Anfragen pro Sekunde erfolgreich bearbeitet haben, die wir jeweils erhalten NCache Server; wir haben 5 NCache Servern, so dass die Zahl damit auf bis zu zwei Millionen Transaktionen pro Sekunde steigt NCache Cache-Cluster. Und wir haben eine durchschnittliche Mikrosekundenzahl pro Cache-Vorgang von weniger als 3 Mikrosekunden. Auch der Systemspeicher und die Prozessorzeit liegen mit einer Auslastung von 40–50 % an beiden Fronten deutlich unter den Grenzwerten.
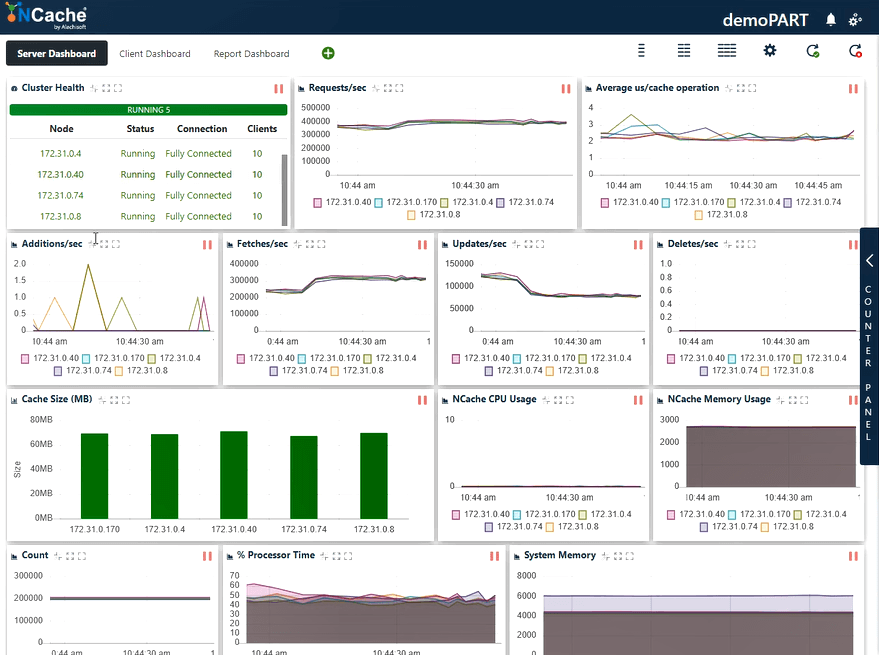
Wir haben jetzt eine Latenz von 2 bis 3 us/Vorgang, eine Verbesserung gegenüber dem vorherigen Ergebnis. Sie können erneut eine Mischung aus Abrufen, Aktualisierungen und einer effizienten Auslastung der CPU- und Speicherressourcen erkennen. Daraus können wir hier schließen NCache ist linear skalierbar. Sehen wir uns nun unsere Skalierbarkeitszahlen an.
| Stufe 3 – Zusammenfassendes Datenblatt | |
| Gesamtzahl der Cache-Server im Cluster | 5 |
| Gesamtzahl der verbundenen Client-Instanzen | 30 |
| Durchschn. Anfragen pro Sekunde/Knoten | 400,000 |
| Gesamtanzahl der Anfragen – Cache-Cluster | 2,000,000 |
| % Prozessorzeit (Max) | 60% |
| System Memory | 6 GB |
| Latenz (Mikrosekunden-/Cache-Vorgang) | 2 ~ 3 Mikrosekunden/Betrieb |
Benchmark-Ergebnisse
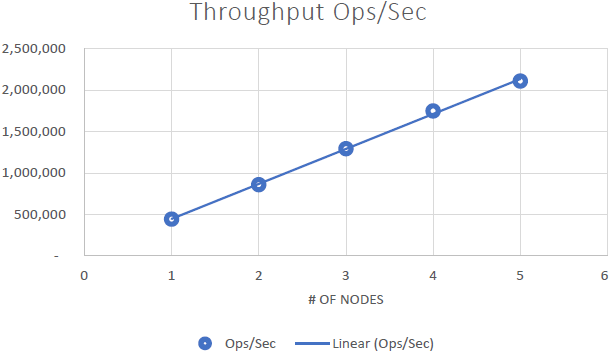
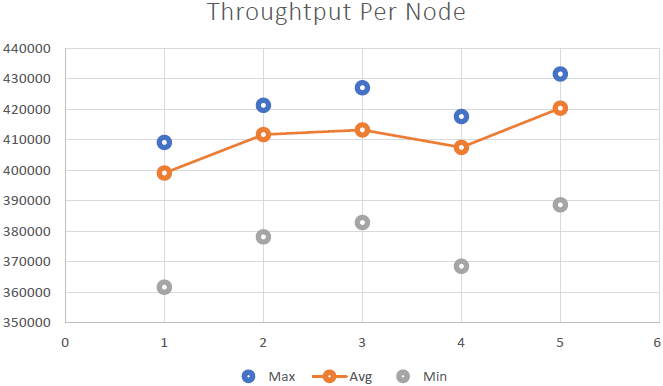
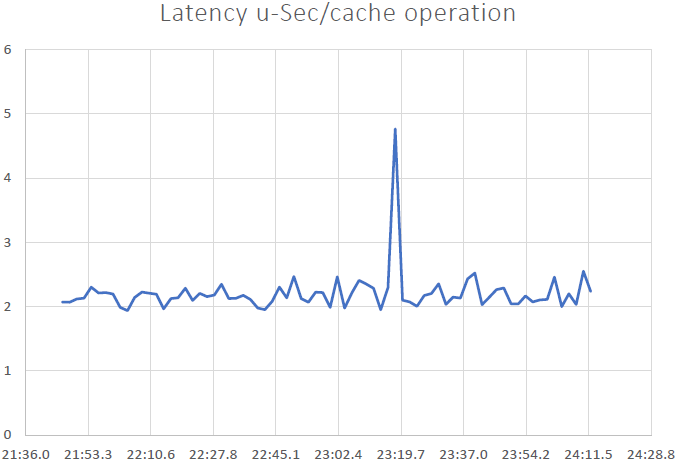
Das konnten wir beweisen NCache ist linear skalierbar und wir konnten nach Durchführung der Benchmarks folgende Ergebnisse erzielen:
Schlussfolgerungen
- Lineare Skalierbarkeit: Mit 5 NCache Servern konnten wir 2 Millionen Anfragen pro Sekunde erreichen. Das Hinzufügen von immer mehr Servern bedeutet mehr Möglichkeiten zur Anforderungsbearbeitung NCache.
- Geringe Latenz und hoher Durchsatz: NCache liefert selbst bei einer großen Clustergröße eine Latenz von weniger als einer Mikrosekunde (2.5 bis 3 Mikrosekunden). NCache Hilft dabei, Anforderungen an geringe Latenz und hohen Durchsatz auch im großen Maßstab zu erfüllen. Wir haben eine sehr geringe Latenz, eine Auswirkung, die durch das Pipelining entsteht. Bei hohen Transaktionslasten seitens des Clients hilft Pipelining wirklich, reduziert die Latenz und erhöht den Durchsatz.