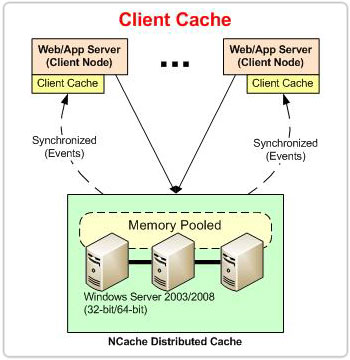
Caché de cliente
NCache Las topologías de clúster están diseñadas para proporcionar el mejor rendimiento y escalabilidad para sus aplicaciones. Con las crecientes necesidades comerciales, las aplicaciones deben procesar más solicitudes y datos de los clientes. Agregar más nodos a la memoria caché distribuida sin problemas proporciona escalabilidad lineal. Al igual que un caché de procesador de hardware, el caché del cliente lleva el rendimiento de sus aplicaciones a un nivel superior al acercar el conjunto de datos calientes a su aplicación, incluso dentro del proceso de la aplicación con el Modo InProc.
Considere el ejemplo de una aplicación de comercio electrónico. La aplicación accede frecuentemente al catálogo de productos y a los datos de los usuarios actualmente activos. Estos datos se pueden guardar en la memoria caché del cliente que se ejecuta en el cuadro del cliente. Por un lado, mantener estos datos en la caché del cliente aumenta el rendimiento de la aplicación al evitar viajes a la base de datos y a la caché agrupada. Por otro lado, descarga muchas operaciones de lectura/escritura de la caché del clúster al permitir que la caché del clúster acepte más solicitudes. Y esta ganancia de rendimiento no compromete la coherencia de los datos. La caché del cliente mantiene sus datos sincronizados con la caché del clúster. En las siguientes secciones se explica cómo se sincroniza la caché del cliente con la caché del clúster.
Plug & Play: Usar el caché del cliente es bastante simple. No se requieren cambios de código al final de la aplicación. Es una opción de configuración sencilla. Puede crear un caché de cliente a través de la NCache Centro de gestion o de NCache cmdlets de Powershell compatibles. Una vez que se haya configurado el cliente, las aplicaciones cliente comenzarán a usarlo automáticamente. Para aplicaciones que ya se están ejecutando, es necesario reiniciar la aplicación.
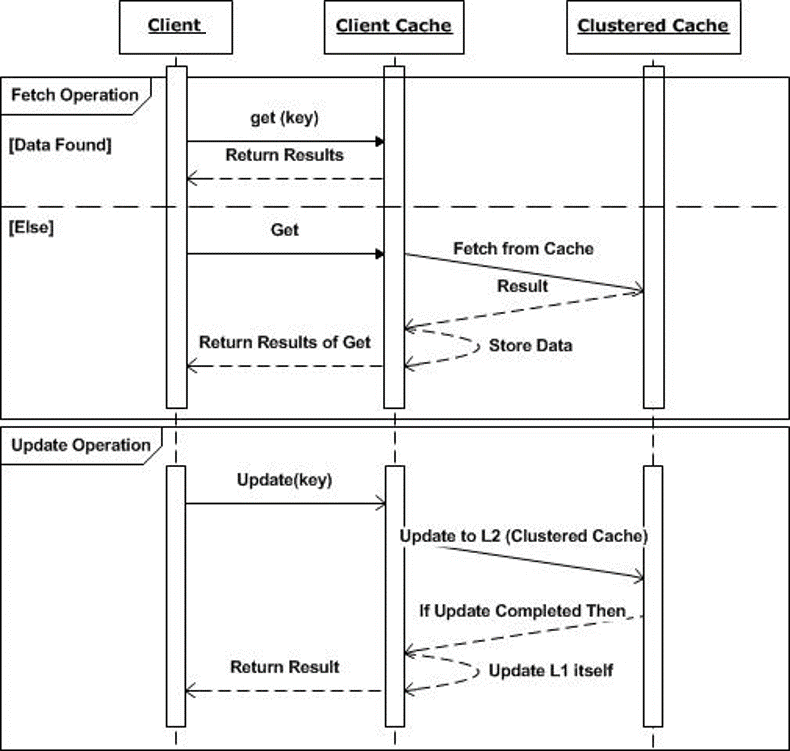
Todos Operaciones CRUD que toman claves de caché como entrada, como Añada, Recibe, recuadroy Eliminar, se enrutan a través de la caché del cliente. Las operaciones de lectura primero buscan los datos dentro de la caché del cliente. La caché del Cliente devuelve los datos (si se encuentran). De lo contrario, la operación de lectura se ejecuta en la memoria caché del clúster. Los datos devueltos desde la caché del clúster se devuelven a la aplicación después de que se hayan agregado a la caché del cliente. Por lo tanto, la próxima llamada de lectura para los mismos datos se realizará desde la memoria caché del cliente. Para las operaciones de lectura masiva, solo los datos que faltan en la caché del cliente se recuperan de la caché del clúster.
Operaciones de escritura basadas en claves como, Añada y recuadro, se realizan primero en la caché del clúster. Una vez finalizados con éxito, los datos se agregan a la caché del cliente y luego se reenvían a la aplicación. Otras instancias de caché del cliente se actualizan a través de un mecanismo de sincronización de datos en segundo plano, que es explicado luego.
La caché del cliente contiene solo un subconjunto de datos de la caché del clúster. Por lo tanto, todas las demás operaciones no basadas en claves como ObtenerGrupo, Consultas SQLy Obtener por etiquetas, etc., se realizan directamente en la caché del clúster.
Caché de cliente: modos de aislamiento
La memoria caché del cliente se ejecuta en el nodo del cliente donde se ejecutan sus aplicaciones. Según sus necesidades de rendimiento y la arquitectura de la aplicación, puede elegir uno de los siguientes modos de aislamiento a nivel de proceso compatibles con la memoria caché del cliente.
en proceso
Como sugiere el nombre, la caché del cliente se ejecuta dentro del proceso de la aplicación, lo que elimina la comunicación entre procesos. Los datos del usuario se mantienen en forma de objeto para evitar el costo de deserialización. Este modo proporciona el máximo rendimiento a la aplicación. Como la caché del cliente está alojada dentro del proceso de la aplicación, los datos dentro de la caché del cliente no se comparten entre otras instancias de la aplicación. Cada instancia de la aplicación aloja una instancia de caché de cliente dedicada. Aunque el modo InProc proporciona el máximo proceso, sólo es adecuado si:
El conjunto de datos activos de la aplicación no es demasiado grande.
La aplicación sólo tiene unas pocas instancias en cada nodo cliente con suficiente memoria física. Recuerde que cada instancia de caché del cliente contiene su copia de datos.
El ciclo de vida de la aplicación es lo suficientemente largo como para aprovechar los beneficios de la memoria caché del cliente. Recuerde que el ciclo de vida de la caché del cliente depende del ciclo de vida de la aplicación. Cuando la aplicación deja de funcionar, todos los datos dentro de la memoria caché del cliente también se pierden. Las aplicaciones con ciclos de vida cortos se cerrarían o reiniciarían antes de que la memoria caché del cliente se llene por completo.
Cada aplicación tiene su propio conjunto de datos calientes, que es diferente de otras aplicaciones.
OutProc
Este modo proporciona aislamiento a nivel de proceso para la caché del cliente. La caché del cliente se ejecuta en su proceso dedicado en el nodo del cliente. Las aplicaciones se comunican con la caché del cliente a través de sockets TCP. Varias instancias de aplicaciones pueden comunicarse con la misma memoria caché del cliente y, por lo tanto, compartir datos. Aunque InProc supera al modo OutProc en rendimiento, el modo OutProc viene con su propio conjunto de ventajas.
Múltiples aplicaciones que se ejecutan en la misma máquina cliente se comunican con la misma memoria caché del cliente. Múltiples aplicaciones comparten datos. Los datos cargados o actualizados por una aplicación quedan disponibles para otras aplicaciones.
El reinicio de la aplicación no provoca la pérdida de datos de caché del cliente.
Se requieren menos recursos físicos como RAM y CPU para ejecutar la caché del cliente en el modo OutProc en comparación con el modo InProc cuando cada proceso de aplicación mantiene su copia de la caché del cliente.
La sincronización de los datos de la memoria caché del cliente (explicada más adelante) con la memoria caché del clúster reduce la carga de la memoria caché del clúster, ya que ejecuta una única instancia de memoria caché del cliente por máquina cliente.
Note
Si la caché del cliente OutProc está inactiva, la aplicación realizará operaciones directamente en la caché del clúster. Cuando la caché del cliente se reinicie, se conectará automáticamente con la caché del cliente. Puede cambiar este comportamiento configurando el skip-client-cache-if-unavailable bandera en cliente.ncconf. Si la bandera se establece en false, las operaciones de caché fallarán si la caché del cliente está inactiva.
Sincronización de datos con caché de clúster
A pesar de una sencilla configuración Plug & Play, no podemos ignorar el hecho de que la caché del cliente contiene una copia de los datos de la caché del clúster. Los cambios realizados en los datos de la caché de un clúster deben propagarse a la caché del cliente. Pueden existir varias cachés de cliente que se ejecutan con el modo InProc o OutProc para una caché de clúster determinada. Los cambios de datos realizados por la aplicación cliente se realizan en la instancia de caché del cliente a la que está conectada la aplicación. Por lo tanto, esta instancia de la caché del cliente se sincroniza automáticamente. Sin embargo, otras instancias de la caché del cliente desconocen estos cambios. Los cambios realizados en los datos de la caché del clúster se sincronizan con estas instancias de la caché del cliente a través de un mecanismo de sincronización de datos en segundo plano que se explica a continuación:
Cuando se agregan datos al caché del cliente, registra una notificación de cambio de datos con el caché del clúster para los datos proporcionados.
La memoria caché del clúster realiza un seguimiento de cada
CacheItemque un caché de cliente contiene y supervisa los cambios realizados en los datos.Cuando los datos son actualizado/remoto Desde la caché del clúster, la caché del clúster registra estos cambios.
Un subproceso de trabajo en segundo plano dedicado inspecciona los cambios de datos cada segundo y determina qué cachés de cliente deben ser notificados de los cambios. Envía una notificación a las cachés de los clientes afectados de que se han modificado los datos.
Otro subproceso de trabajo en segundo plano dedicado que se ejecuta en la caché del cliente es responsable de sincronizar los cambios de datos con la caché del clúster al recibir la notificación de cambio de datos. Tan pronto como recibe la notificación, solicita la caché del clúster y solicita actualizaciones de datos. A este mecanismo de sincronización lo llamamos sondeo de caché del cliente.
Este subproceso de trabajo que se ejecuta en la caché del cliente sondea los datos que cambian cada 10 segundos si no ha recibido ninguna notificación de la caché del clúster para manejar los casos en los que puede haber perdido una notificación debido a la pérdida de conectividad entre la caché del cliente y la caché del clúster.
Este poderoso mecanismo de sincronización asegura que las aplicaciones cliente siempre reciban los datos más recientes de la memoria caché del cliente con mayor rendimiento y escalabilidad.
Modos de sincronización
Junto con el mecanismo de sincronización de datos en segundo plano, la memoria caché del cliente admite los siguientes dos modos de sincronización.
Sincronización optimista
Este es el modo de sincronización predeterminado de la memoria caché del cliente. Cuando una aplicación obtiene datos del caché del cliente y el caché del cliente contiene esos datos, los datos simplemente se devuelven a la aplicación. La sincronización se realiza en segundo plano, como se explicó anteriormente.
Sincronización pesimista
El mecanismo de sincronización en segundo plano es adecuado para la mayoría de las aplicaciones y proporciona el rendimiento y la escalabilidad óptimos de la aplicación. Sin embargo, para las aplicaciones que son más sensibles y quieren asegurarse de que siempre reciban los datos más recientes, el modo pesimista está diseñado para ellas. Con este modo, cuando una aplicación recupera datos de la caché del cliente y la caché del cliente contiene esos datos, la caché del cliente verifica la versión del elemento con la caché del clúster. Si se encuentra una versión actualizada de los datos en la caché del clúster, se recupera y se actualiza en la caché del cliente. Por lo tanto, se garantiza que la aplicación obtendrá la última versión del CacheItem.
Vea también
Topologías de caché
Agrupación dinámica
Caché local
Cliente de caché
Puente para replicación WAN