Topología de caché de réplica
En un clúster, si todos los nodos del servidor tienen la misma copia de datos, nos brinda alta disponibilidad. Eso significa que el clúster puede sobrevivir a algunas fallas de nodo sin perder datos. Para este propósito, NCache proporciona la topología replicada para garantizar que los datos del usuario no se pierdan, incluso si fallan varios servidores al mismo tiempo. Esta topología le permite tener varios servidores y cada servidor tiene la misma copia de datos. Entonces, cada servidor es una réplica exacta de cada uno. Por lo tanto, la falla de varios servidores al mismo tiempo no causa ninguna pérdida de datos.
Note
Esta característica también está disponible en NCache Professional.
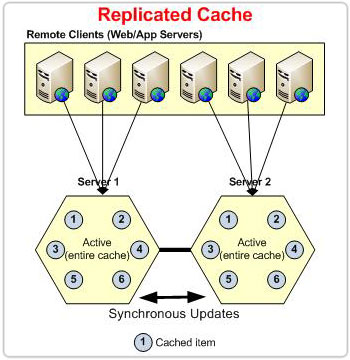
Sincronizar replicación
Cada vez que un cliente realiza una operación de escritura (añade, actualizacioneso elimina), esta operación se transmite por todo el clúster para replicarla en todos los servidores de caché antes de devolver el control al cliente. El servidor que recibe las operaciones del cliente es responsable de transmitir estas operaciones. Durante este proceso, se toma un token de secuencia del servidor coordinador y se asocia con la operación actual para garantizar que esta operación se realice en todos los servidores en la misma secuencia para lograr la coherencia de los datos.
Si una operación de escritura transmitida falla en cualquier servidor de caché, su falla también se transmite a todos los servidores de caché para eliminar estos datos. Esto se hace para lograr la coherencia de los datos en todo el clúster, lo que significa que si existen datos en la memoria caché, todos los servidores tienen los mismos datos.
Dado que la replicación se realiza de forma sincrónica, esta topología no es adecuada para operaciones de escritura porque más servidores requieren más tiempo para que los datos se repliquen en todos los servidores de caché antes de devolver el control a la aplicación de escritura. Se recomienda limitar el tamaño del clúster a 3 servidores si no desea experimentar ninguna degradación en el rendimiento de las operaciones de escritura.
Rol del Servidor Coordinador
El servidor Coordinador (el nodo de servidor más antiguo) realiza múltiples tareas como transferencia de estado, operaciones de escritura diferida, invalidaciones de datos como vencimientos y dependencias, etc. Después de decidir eliminar cualquiera de los elementos del caché, solicita a todos los demás nodos que también eliminen estos elementos de su almacén de caché. Cuando el servidor coordinador abandona el clúster, el siguiente servidor de mayor rango se convierte en el servidor coordinador y reanuda sus responsabilidades.
Operaciones de lectura totalmente escalables
Como todos los servidores tienen los mismos datos, y los clientes se distribuyen entre todos los servidores de caché. Entonces, cada servidor proporciona los mismos datos a los clientes. Más servidores en el clúster significan que se atienden simultáneamente más solicitudes de lectura de datos.
Equilibrio de carga de conexión
La topología replicada tiene una característica especial para equilibrar automáticamente las conexiones de los clientes entre los servidores para compartir la carga de datos entre los servidores de caché. Cuando un cliente se conecta con un servidor, este servidor verifica que todos los demás nodos del servidor también tengan la misma cantidad de clientes. Si otros servidores tienen menos clientes, rechaza elegantemente la solicitud de conexión del cliente y la redirige a los otros servidores. De esta manera, todos los servidores tienen la misma cantidad de clientes y ningún servidor está sobrecargado con más clientes en comparación con los otros servidores de caché.
Conectividad del cliente
En la topología replicada, un cliente solo está conectado con un servidor de un clúster a la vez. Si el servidor conectado deja de funcionar, el cliente se conecta automáticamente con otro servidor del clúster sin ninguna intervención humana.
Transferencia de estado
Se activa una transferencia de estado al unirse y al salir del nodo en la topología replicada. La transferencia de estado que se activa cuando un nodo abandona el clúster no sirve de mucho, ya que todos los nodos tienen los mismos datos. Pero, al unirse al nodo, un nodo recién unido solicita al servidor coordinador que proporcione todos los datos almacenados en caché para sincronizarse con el resto del clúster.
Vea también
Topologías con particiones
Topología duplicada
Clúster de caché
Caché local