Topologies de réplication de partition et de cache de partition
Dans un cluster, si tous les nœuds du serveur ont la même copie des données, cela vous offre une haute disponibilité de ces données. Cela signifie que le cluster peut survivre à quelques pannes de nœuds sans subir de perte de données. Cependant, cela ne vous offre pas d’évolutivité. Lorsque les données commencent à croître énormément, la conception doit réduire l’étendue de la réplication et commencer à partitionner les données.
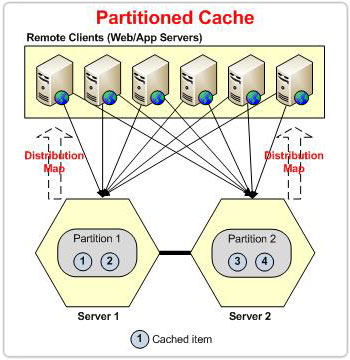
Le partitionnement signifie que vous devez répartir vos données entre plusieurs nœuds afin que le chargement des données en lecture et en écriture soit réparti. À mesure que vos données augmentent, vous pouvez ajouter davantage de nœuds de serveur dans le cluster pour contenir davantage de données. Chaque nœud de serveur d'un cluster est appelé une partition.
En partitionnant les données, vous pouvez atteindre l'évolutivité, mais la question est maintenant de savoir comment ces données sont-elles partitionnées ? Une solution simple pourrait consister à attribuer des données à une partition de manière circulaire, mais comment allons-nous trouver une donnée particulière une fois qu'elle a été ajoutée au magasin ?
Grâce au round-robin, nous perdrons la possibilité de suivre l’emplacement des données. Nous avons besoin d’une meilleure manière de distribuer les données, garantissant non seulement une répartition équitable des données, mais également la possibilité de les consulter rapidement.
Notes
La topologie partitionnée est également prise en charge dans NCache Professional.
Notes
La seule différence entre les topologies Partitioned et Partition-Replica est que la première n'a pas de caches de réplique, ce qui la rend sujette à la perte de données.
Partitionnement de données basé sur le hachage pour les caches de partition
NCache divise les données en plusieurs morceaux et place ces morceaux dans différentes partitions. Ces morceaux sont appelés buckets. Il existe un total de 1000 1000 compartiments répartis à parts égales entre les nœuds du cluster. L'idée ici est d'appliquer une fonction de hachage sur la clé de l'élément et de la moder par le nombre total de buckets (XNUMX dans ce cas) pour obtenir un bucket propriétaire pour ces données.
Carte de répartition
Le serveur coordinateur du cluster a la responsabilité de générer une carte contenant la distribution du compartiment. Cette carte est appelée carte de répartition. Le serveur coordinateur partage cette carte de distribution avec le reste des partitions du cluster et avec les clients connectés. Cette méthode vous donne toujours la même adresse de compartiment pour un élément, quel que soit le nombre de serveurs dans le cluster. Même si le compartiment peut passer d'une partition à une autre à tout moment, le compartiment d'un élément ne peut jamais changer. Cela signifie que lorsqu’un bucket se déplace, il emporte toutes ses données avec lui.
Distribution des données selon la carte de distribution
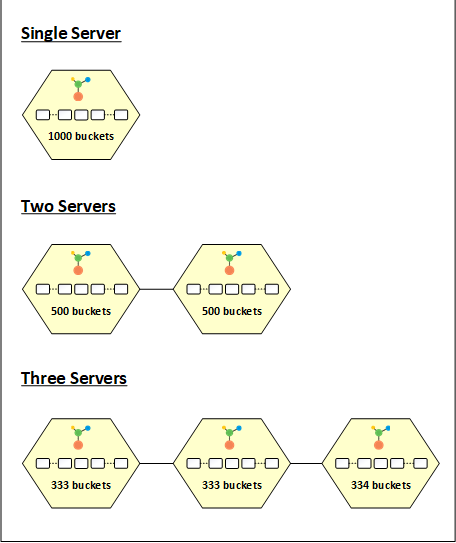
Lorsque vous démarrez un cluster de cache avec une seule partition, les 1000 500 compartiments sont attribués à ce nœud. Cela signifie que toutes les données vont sur cette partition. Lorsque vous démarrez un autre nœud dans le cluster, les compartiments sont répartis de manière égale entre les deux partitions ayant chacune XNUMX compartiments. De même, lors de l'ajout d'un troisième nœud au cluster, les buckets sont à nouveau redisrendu hommage. Dans ce cas, les trois nœuds auront respectivement 333, 333 et 334 compartiments.
De même, lorsqu'une partition quitte le cluster, la distribution du bucket change. Par exemple, lorsqu'une partition quitte un cluster à trois nœuds, les 333 ou 334 compartiments appartenant à cette partition sont redisrendu hommage parmi les deux nœuds restants. Chaque fois qu'il y a un changement dans la distribution, cela déclenche un transfert d'état pour rééquilibrer les données entre les nœuds, en fonction de la distribution du bucket.
Distribution aléatoire des données
Cette méthode de partitionnement vous offre une part assez aléatoire pour garantir que les données sont partitionnées de manière égale entre les compartiments et les partitions. Cependant, avec cette méthode de partitionnement, vous perdez le contrôle sur quelles données doivent être affectées à quelle partition. La plupart du temps, vous ne vous souciez pas de la destination de vos données. Mais, dans certains cas, vous souhaiterez peut-être que les données associées soient colocalisées. Pour cela, vous pouvez utiliser Location Affinity, où une fonction de hachage est appliquée sur une partie de la clé au lieu de la clé entière.
Distribution équilibrée des données
Chaque fois que les seaux sont redistribut entre les nœuds, NCache s'assure que les seaux sont redishommage de telle manière que la taille des données que chaque partition reçoit est presque la même. Chaque partition partage les statistiques des compartiments qu'elle possède, à un intervalle configurable, avec d'autres partitions du cluster. Cela permet de générer une carte de distribution équilibrée en cas de besoin, ce qui est équitable en termes de données obtenues par chaque partition. L'équilibrage est basé sur la taille des données plutôt que sur le nombre d'éléments. Cet équilibrage est généralement assuré au moment du seau redistribut à la suite du départ ou de l’adhésion d’un nœud.
Équilibrage automatique et manuel de la charge de données
Cependant, il est possible que vous observiez qu'une ou plusieurs partitions d'un cluster sont asymétriques et reçoivent plus de charge que les autres. Dans ce cas, vous avez la possibilité d'équilibrer manuellement les données d'un nœud particulier, ce qui garantit que les données sur ce nœud sont égales à la taille moyenne des données que chaque partition reçoit. Ensuite, il existe également une fonctionnalité appelée "Auto Data Load Balancing" qui fait le travail automatiquement en arrière-plan. Cette fonctionnalité est désactivée par défaut car, si elle est utilisée sans précaution, elle peut provoquer des sauts fréquents. redistribution et, par conséquent, des transferts d'état indésirables entre les partitions.
Taille des données par partition
La taille des données que chaque partition peut contenir est égale à la taille du cache configurée. Par exemple, si la taille du cache configurée est de 2 Go et que la taille du cluster est composée de trois partitions, la taille totale du cache sur ce cluster est de 6 Go.
Ainsi, avec cette topologie, non seulement vous répartissez la charge de lecture et d'écriture entre les serveurs, mais vous augmentez également la capacité à chaque nouveau serveur ajouté au cluster.
Réplique de partition
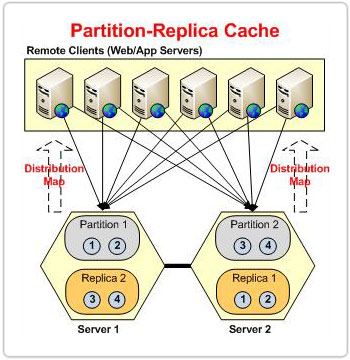
Maintenant que nous avons couvert la façon dont la topologie Partition-Replica adapte la charge de transaction et la capacité de stockage. Parlons de la façon dont il gère la haute disponibilité. Chaque nœud du cluster possède une sauvegarde d'une autre partition qui agit comme une partition passive appelée réplique. En cas de défaillance d'un nœud, le cluster de cache sait que les données appartenant à la partition perdue sont toujours disponibles dans sa réplique. Ainsi, les applications clientes continuent de fonctionner correctement car les données appartenant à la partition perdue sont toujours servies par le cluster via cette réplique.
Les applications clientes communiquent directement avec les partitions actives uniquement. Chaque partition est alors responsable de la réplication de ses données vers sa réplique respective.
Même si le degré de réplication dans cette topologie n'est pas aussi élevé que dans le Topologie répliquée, avoir au moins une sauvegarde vous garantit qu'en cas de panne de nœud, vos données sont toujours en sécurité. Tant qu'il n'y a pas de pannes de nœuds simultanées, les données de cette topologie sont sécurisées, ce qui couvre la plupart des scénarios.
Chaque nœud de cluster a un actif et un réplica, et les instances actives et répliquées existent dans le même processus de cache sur chaque nœud de cluster.
En raison de l'existence de l'instance de réplica sur chaque nœud de cache, elle nécessite la même taille de mémoire que celle de l'instance de cache active. Cela signifie que chaque nœud de cache Partition-Replica nécessite une double mémoire par rapport à sa taille de cache configurée.
Toutes les données ajoutées par le client sont stockées dans le nœud actif, d'où elles sont ensuite répliquées vers sa réplique dédiée, qui se trouve sur un autre nœud du cluster. Cette disposition des nœuds de réplique garantit que les données ne sont pas perdues lorsqu'un nœud actif tombe en panne.
Stratégie de sélection des répliques
NCache sélectionne automatiquement le nœud de réplique en fonction de l'ordre dans lequel les nœuds rejoignent le cluster de cache. La réplique du premier nœud est présente sur le nœud serveur qui a rejoint le cluster après le premier nœud, et ainsi de suite. Et, la réplique du dernier nœud est placée sur le premier nœud serveur (serveur coordinateur) du cluster de cache.
Tout ce processus de sélection de répliques est automatique. Chaque fois qu'un nœud de serveur quitte le cluster de cache ou qu'un nouveau nœud rejoint le cluster de cache, les répliques sont également réaffectées en fonction de la carte d'appartenance mise à jour.
Consommation de mémoire à nœud unique
Chaque nœud de serveur (actif et réplique) conserve un enregistrement de la taille de cache configurée et garantit que les données stockées ne dépassent jamais la limite de mémoire spécifiée. Il existe deux scénarios particuliers dans lesquels cette vérification de limite de mémoire fonctionne différemment. Ils sont expliqués ci-dessous :
- Un seul nœud est en cours d’exécution et des données y sont ajoutées. L'instance de cache active peut utiliser deux fois la taille de cache spécifiée pour contenir les données, car sa réplique n'est d'aucune utilité.
- Dans un cluster à plusieurs nœuds, lorsque tous les autres nœuds quittent le cluster et qu'un seul nœud reste actif, les données de son instance de cache de réplique sont transférées vers l'instance de cache active. La mémoire libre de la réplique est ensuite consommée par le cache actif pour accueillir les données reçues de la réplique.
Stratégies de réplication
La topologie Partition-Replica a deux stratégies de réplication pour répliquer les données du nœud de serveur actif vers le nœud de réplique :
Réplication asynchrone : Dans ce mode, les files d'attente en arrière-plan sont utilisées pour répliquer les données sans bloquer les opérations client. Chaque opération d'écriture est mise en file d'attente et des threads d'arrière-plan dédiés sélectionnent les données de cette file d'attente en morceaux et les répliquent sur l'instance de réplica. Cette stratégie de réplication convient aux applications qui ont tendance à effectuer des écritures fréquentes mais qui ne souhaitent pas attendre que les réplications soient terminées avant leur prochaine opération de cache. Cependant, il existe un risque de perte de données si un nœud quitte brusquement. Dans ce cas, les opérations en file d'attente qui n'ont pas été répliquées seront perdues.
Réplication de synchronisation : Avec le mode de réplication synchrone, chaque opération d'écriture du client est répliquée sur la réplique avant de rendre le contrôle à l'application cliente. Ce mode de réplication garantit que les instances de cache actives et répliquées disposent de la même copie des données utilisateur. Si la réplication échoue sur l'instance de réplique, cet élément est supprimé des instances de cache active et de réplique.
Comportement de fonctionnement
Expulsions, expirations, dépendances, writeThru/writeBehind, etc. sont contrôlés par le nœud actif. Chaque fois qu'un nœud actif en supprime un élément sur la base de l'une des fonctionnalités mentionnées, il le réplique dans sa réplique pour en supprimer les données précédemment stockées. De la même manière, writeThru/writeBehind les opérations ne sont effectuées qu'à partir du cache actif.
Dans la topologie Partition-Replica, les clients sont directement connectés à chaque nœud de serveur, mais uniquement à ses partitions/instances actives. Cependant, il existe quelques situations dans lesquelles les clients interagissent temporairement avec les instances de réplica via des appels de cluster. Ils sont expliqués ci-dessous :
- Lors du transfert d'état, lorsqu'un nœud quitte le cluster, les opérations client destinées au nœud sortant sont servies depuis sa réplique.
- Lorsqu'un cluster est en mode maintenance, toutes les opérations destinées au nœud en maintenance sont servies à partir de sa réplique pendant la période de maintenance.
Transfert d'État
Le transfert d'état est un processus de transfert/copie automatique des données entre les nœuds de cache. Le transfert d'état est déclenché lorsqu'un nouveau nœud rejoint le cluster ou qu'un nœud actuel quitte le cluster. Quitter/Joindre un nœud entraîne également un changement d'appartenance dans le cluster.
Lorsqu'un nœud reçoit la mise à jour carte de répartition, il vérifie l'existence des buckets (qui lui ont été attribués) dans son environnement local. Les compartiments attribués qui n'existent pas dans l'environnement local du nœud sont extraits un par un des autres nœuds. Ainsi, en fonction du nombre de nœuds de serveur dans le cluster de cache, plusieurs compartiments sont transférés lors du transfert d'état.
Le transfert d'état est déclenché dans les trois scénarios majeurs suivants :
Lors de la jonction de nœud
Lorsqu'un nouveau nœud rejoint le cluster de cache, le serveur coordinateur génère une nouvelle carte de distribution pour distribuer les compartiments des nœuds actuels au nœud nouvellement rejoint. Et, après avoir reçu la carte de distribution, le nœud nouvellement rejoint extrait les compartiments des nœuds actuels. Au cours de ce transfert d'état, le nœud nouvellement joint extrait un compartiment à la fois. Après avoir reçu un compartiment, il extrait le compartiment suivant, et ainsi de suite, jusqu'à ce qu'il récupère tous ses compartiments attribués à partir d'autres nœuds, selon sa carte de distribution.
À la sortie du nœud
De même, le transfert d'état est déclenché lorsqu'un nœud de cache quitte le cluster de cache. Le serveur coordinateur redisrend hommage à ses buckets parmi les nœuds actifs du cluster. Dans ce cas, les nœuds actifs extraient les données du réplica du nœud sortant.
Notes
Si plusieurs nœuds quittent le cluster en même temps ou l'un après l'autre alors qu'un transfert d'état est déjà en cours, cela peut entraîner une perte de données.
Sur l'équilibrage automatique de la charge des données
La topologie Partition-Replica a une caractéristique de Équilibrage automatique de la charge des données dans lequel il surveille en permanence la distribution des données entre les nœuds du cluster. Et, si la distribution des données ne se situe pas dans la plage de distribution attendue (60 % à 40 %), l'équilibrage automatique de la charge des données est automatiquement déclenché. Dans ce cas, le serveur coordinateur régénère une nouvelle carte de distribution et redisrend hommage aux buckets de manière à ce que tous les nœuds du cluster aient des données de taille égale.
Notes
L'équilibrage de la charge des données peut également être effectué manuellement du NCache Centre de gestion.
Quelle que soit la raison du transfert d’État, l’ensemble de ce processus est automatique et transparent. Et, lors du transfert d'état, en particulier lorsqu'un nœud de serveur quitte le cluster de cache, toutes les opérations client destinées au nœud sortant sont servies depuis sa réplique via des opérations de cluster.
Les répliques effectuent également un transfert d'état à partir de leurs nœuds actifs, tout comme les autres nœuds actifs. Les réplicas extraient les compartiments qui leur sont attribués de leurs nœuds actifs pour récupérer la copie des données au moment du transfert d'état. Cependant, ce transfert d'état n'a lieu qu'en cas de réaffectation de compartiment. Sinon, les données sont répliquées vers les réplicas via le mécanisme de réplication.
Différentes façons de surveiller le transfert d'état
NCache fournit plusieurs façons de surveiller le transfert d'état dans le cluster de cache. Ils sont expliqués ci-dessous :
- Journaux de cache : chaque fois que le transfert d'état est déclenché et arrêté, il est enregistré dans les journaux de cache du cluster. Les journaux de cache existent sous le %NCHOME%/bin/journal dossier.
- Compteurs personnalisés : NCache publie également des compteurs personnalisés qui sont visibles sur Windows et Linux.
- Compteurs basés sur Perfmon : Sur Windows, NCache publie également les compteurs de transfert d'état via l'outil Windows Perfmon.
- Journaux d'événements Windows : Les informations/événements liés au transfert d'état sont également publiés dans les journaux d'événements Windows.
- Alertes courrier électronique: Des alertes email spécifiques aux transferts d'état peuvent être configurées lors de leur lancement et de leur arrêt.
Connectivité client
Comme expliqué dans le partitionnement, les données sont réparties entre tous les serveurs du cluster. Contrairement aux autres topologies, le client des topologies partitionnées doit se connecter à toutes les partitions, où chaque partition contient un sous-ensemble des données totales.
Le client reçoit une carte de distribution lors de l'appel de connexion, qui renseigne le client sur les nœuds de serveur en cours d'exécution et leur distributions basées sur le hachage. Le client se connecte à tous les nœuds du serveur pour obtenir des données complètes du cache. Le client obtient un carte mise à jour à chaque changement d'appartenance au cluster pour maintenir la connectivité. Le client reçoit également une notification lorsqu'un membre quitte/rejoindre et réinitialise la connectivité en fonction des informations reçues. Localisation.
Le client effectue intelligemment les opérations de lecture/écriture directement sur le nœud serveur contenant la clé en fonction du carte de distribution basée sur le hachage il reçoit. Pour toutes les opérations où la clé n'est pas connue, comme Recherche SQL, ObtenirByTags, etc., le client diffuse la requête à tous les nœuds du serveur et combine leurs réponses respectives.
Si, dans tous les cas, le client ne parvient pas à se connecter à un nœud de serveur du cluster, cela ne signifie pas qu'il ne parvient pas à écrire et à récupérer des informations à partir de ce nœud de serveur. Pour cela, il utilise les autres nœuds serveurs auxquels il est connecté, qui demandent en son nom au nœud serveur inaccessible d'effectuer des opérations. Par exemple, si le client ne parvient pas à se connecter au nœud 1 et souhaite obtenir une clé qui réside dans le nœud 1, il envoie la demande au nœud 2, qui redirige vers le nœud 1 et renvoie la réponse.
Mode de maintenance
Lorsqu'un correctif ou une mise à niveau du matériel/logiciel est requis sur un NCache serveur, vous ne rencontrerez peut-être pas de temps d'arrêt de l'application. Cependant, l'arrêt d'un nœud de cache déclenche transfert d'état dans l'ensemble du cluster de cache, ce qui entraîne une utilisation excessive des ressources telles que le réseau, le processeur et la mémoire. Cette transfert d'état Le processus peut être coûteux en fonction de la taille des données du cache et du cluster. Un flux de travail typique de mise à niveau implique le redémarrage du nœud de cache à la fois, ce qui nécessite deux transferts d'état, l'un à la sortie du nœud et l'autre à la connexion du nœud.
Le mode de maintenance est introduit pour éviter ces transferts d'état coûteux lors de la maintenance sur les serveurs de cache. Une fois qu'un serveur de cache est arrêté pour maintenance pendant une durée spécifiée, la réplique du nœud en maintenance devient temporairement active et commence à répondre aux demandes des clients. Lorsque le nœud (qui était en maintenance) rejoint une fois sa maintenance terminée dans le délai spécifié, le transfert d'état est lancé pour ce nœud afin de le synchroniser avec le cluster de cache.
Le cluster quitte le Mode de Maintenance dans trois états différents. Si le nœud de maintenance rejoint le cluster de cache dans le délai spécifié, transfert d'état est lancé pour synchroniser l'état du cluster, et le cluster quitte le Mode de Maintenance. Si le nœud de maintenance ne parvient pas à rejoindre le cluster de cache dans le délai spécifié, le cluster considère le nœud comme étant en panne, quitte le Mode de Maintenance, génère un nouveau Localisation, et démarre le transfert d'état. Outre le succès et l'échec, il y a une autre anomalie qui sort du Mode de Maintenance, c'est-à-dire lorsqu'un nœud quitte. Si le cluster est dans le Mode de Maintenance et que tout nœud autre que le nœud de maintenance quitte, le cluster quitte le Mode de Maintenance, et cela peut entraîner une perte de données.
Récupération du cerveau divisé
Le terme Cerveau divisé fait référence à un état dans lequel un cluster de cache se divise en plusieurs sous-clusters. Les serveurs de cache dans un cluster communiquent via TCP. Par conséquent, tout problème ou problème de réseau peut entraîner une perte de communication entre les serveurs présents dans un cluster. Si la perte de communication entre les serveurs se prolonge au-delà d'un certain temps, la carte des membres changera en fonction de la connectivité entre les serveurs. Cela se traduit par la formation de plusieurs sous-groupes. Ces sous-groupes sont appelés divisions. Nous l'appelons cerveau divisé car les sous-groupes ne peuvent pas communiquer entre eux, de la même manière que les moitiés du cerveau ne peuvent pas communiquer entre elles dans le syndrome du cerveau divisé.
Tous les sous-clusters sont sains et traitent les données qu'ils contiennent. De plus, les clients peuvent se connecter à ces sous-clusters pour d'autres opérations de lecture/écriture. Le client reçoit une carte d'appartenance des serveurs de cluster pour mettre à jour la connectivité. Ici, le client peut se connecter à n'importe quel sous-cluster en fonction de la première carte reçue.
Cerveau divisé est détecté uniquement lorsque la communication entre les serveurs reprend et qu'il est découvert que tous les serveurs sont opérationnels mais ne font pas partie d'un seul cluster. Deux divisions ou plus sont possibles en fonction de la perte de communication entre les serveurs. Une fois que cerveau divisé est détecté, le processus de récupération démarre. Toutes les divisions se rétablissent une par une jusqu'à ce que tous les sous-clusters fusionnent.
Les cerveau divisé le processus de récupération démarre juste après sa détection. Il prend deux répartitions saines, identifie leurs serveurs coordonnateurs, décide de la répartition gagnante et perdante en fonction de la taille du cluster, acquiert un verrou sur la répartition perdante pour restreindre l'activité des clients sur ce cluster et modifie l'appartenance au cluster. Après cela, tous les clients sont redirigés vers le cluster gagnant et tous les nœuds du cluster perdant sont redémarrés un par un pour rejoindre le cluster gagnant. Toutes les divisions perdantes fusionnent avec la division du cluster gagnant de la même manière et le cluster redevient sain.
Une perte de données est attendue dans cerveau divisé récupération lorsque le cluster se divise en plusieurs sous-clusters, une perte de données se produit car plusieurs nœuds d'un cluster partent simultanément. Les sous-clusters peuvent traiter les demandes des clients dans un état de cerveau divisé, ces opérations peuvent être perdues si le split auquel le client est connecté est un split perdant qui est redémarré pour rejoindre le cluster principal.
Voir aussi
Topologie répliquée
Topologie en miroir
Cluster de cache
Cache local