Distributed Persistent Caches
NCache provides key-value distributed persistent caches, to reliably retrieve valuable data as required. It maintains a copy of cache data in the persistence store and later loads persisted data on cache restart (planned or unplanned). It stores and loads as much data as the cache servers can hold. Persistence ensures high data availability, and simultaneously in-memory data provides high performance. In this document, a Distributed Cache with Persistence is also called a persistent cache.
Notes
Le cache distribué avec persistance prend uniquement en charge Topologies partitionnées ainsi que Caches locaux (OutProc).
Vous pouvez créer un cache distribué avec persistance à l'aide d'un NoSQL Document Store en tant que magasin de persistance pour la sauvegarde des données. Le cache conservera toutes les API d'écriture, les méta-informations, flux, structures de donnéeset index dynamiques au magasin principal.
Notes
Les messages Pub/Sub ne sont pas conservés, mais NCache supports API Pub/Sub et vous permet de créer un espace dédié Cache de messagerie Pub/Sub.
Veuillez noter que les données supprimées du cache en raison d'une invalidation de données ou d'une suppression explicite seront également supprimées du magasin de persistance sous-jacent. L'ajout d'éléments avec expiration et dépendance de clé est pris en charge. Cependant, nous ne recommandons pas cette approche car les données stockées dans un tel cache persistant sont des données permanentes. Pendant ce temps, les données avec dépendance à la base de données et la dépendance à l’égard de sources extérieures ne devrait pas persister.
Notes
Semblable à un cache distribué volatil, une source de sauvegarde est prise en charge pour un cache distribué avec persistance.
Persistent Cache: Why Persist Data
NCache stocke les données dans la RAM pour un accès plus rapide. Étant donné que la mémoire cache est volatile, la perte de données est inévitable dans les scénarios suivants :
- Nœud arrêté dans la topologie partitionnée.
- Plusieurs nœuds arrêtés simultanément dans la topologie Partition-Replica.
- Cluster down soit pour des raisons de maintenance, soit en cas de panne catastrophique.
Avec un cache persistant, vous pouvez obtenir les résultats suivants :
Haute disponibilité des données : En cas de défaillance de la mémoire due à l'une des raisons mentionnées précédemment, NCache récupère rapidement les données en les chargeant à partir du magasin de persistance sous-jacent. Le cache devient opérationnel sans affecter les opérations du client même après une panne catastrophique.
Tolérance aux pannes: Le maintien d'une copie en temps réel des données de cache minimise les temps d'arrêt et offre une tolérance aux pannes lorsque des nœuds uniques/multiples quittent le cluster.
Important
Pour la persistance, la longueur de la clé ne doit pas dépasser 1023 octets.
Persistent Cache: How it Works
Nous décrivons ici le fonctionnement et le comportement d'un cache distribué avec persistance. Le schéma ci-dessous montre l'architecture de base. Vous pouvez créer un cache distribué avec persistance avec un magasin de persistance au niveau du backend. Le magasin est centralisé et accessible à tous les nœuds. NCache écrit les données ajoutées au cache dans le magasin principal à des intervalles de temps gérables. Au redémarrage du cache ou à la sortie/rejoindre du nœud, les données persistantes sont chargées dans la mémoire autant que les serveurs de cache peuvent en contenir.
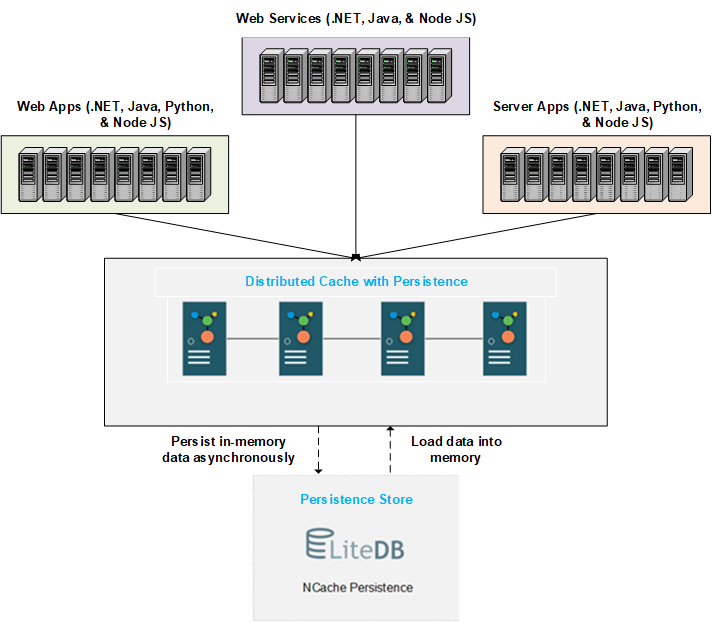
Nous discutons ci-dessous du processus détaillé de persistance et de chargement des données.
Data Persistence in a Persistent Cache
Une fois que vous avez créé un cache distribué avec persistance, toutes les opérations d'écriture sont d'abord effectuées en mémoire, puis conservées dans le magasin principal. Depuis NCache a une architecture distribuée, chaque nœud de serveur conserve ses données tandis que tous les nœuds de serveur peuvent accéder au magasin. De plus, étant donné que la distribution des données est basée sur des compartiments en raison des partitions, les données sont également conservées.
Async Persistence in a Persistent Cache
NCache conserve les données en mémoire dans le magasin de persistance via la persistance asynchrone. Nous expliquons ici comment cela fonctionne. Chaque partition dispose d'une file d'attente de persistance pour enregistrer les opérations client effectuées. Toutes les opérations d'écriture effectuées par le client sont mises en file d'attente une fois réussies. Étant donné que la persistance fonctionne de manière asynchrone, le client n'attend pas après avoir mis l'opération en file d'attente. Les opérations en file d'attente sont vérifiées périodiquement à un moment configurable. persistence-interval et éventuellement répliqué dans le magasin principal par un thread de persistance. Chaque file d'attente est écrite indépendamment.
Notes
La valeur par défaut de persistence-interval is 1 secondes et il est configurable dans le NCache Centre de gestion.
Normalement, le lot est appliqué après persistence-interval, mais si le lot de persistance échoue consécutivement, alors après persistence-retries l'intervalle de lot est décalé à persistence-interval-longer. Une fois l'opération réussie, l'intervalle de lot sera réinitialisé à persistence-interval.
Important
Les performances du cache ne se dégradent pas puisque les opérations client se déroulent comme d'habitude en raison de la réplication asynchrone.
Si le cache ne peut pas conserver les données dans la file d'attente de persistance en raison d'un problème, il continuera à effectuer des opérations d'écriture jusqu'à ce qu'il soit plein. Si les opérations en file d'attente ne persistent pas, les informations sur les compartiments ayant échoué sont consignées dans les journaux du cache.
Notes
La topologie Partition-Réplique récupère après un échec de file d'attente via la file d'attente du réplica. Cependant, la perte de données est inévitable si un nœud et sa réplique tombent simultanément en panne.
Data Loading in a Persistent Cache
Une fois les données dans le magasin, le cache recharge automatiquement les données persistantes dans la RAM au redémarrage du cache. Le magasin persistant doit être disponible pour les nœuds de cache à tout moment. S'ils ne peuvent pas accéder au magasin, le cache ne démarrera pas. Le chargement des données s'effectue de manière distribuée. Étant donné que le stockage des données est une procédure basée sur des compartiments, chaque nœud peut accéder au magasin centralisé pour charger ses compartiments attribués en fonction de la carte de distribution des données. De plus, si vous avez configuré des index pour interroger les données dans le cache, les index de requête se régénèrent au redémarrage du cache.
Important
Le magasin de persistance doit être disponible à tout moment pour tous les nœuds de cache.
Comportement de fonctionnement pendant le chargement des données
Les processus de chargement et de persistance des données s'exécutent simultanément. Pendant ce temps, les extractions basées sur les clés sont servies à partir du cache si les données demandées sont chargées. Si ce n'est pas dans le cache, ces opérations sont servies directement depuis le magasin via un chargement différé. Dans ce cas, les performances du Get le fonctionnement en sera affecté.
Veuillez noter que les opérations de recherche non basées sur des clés ou sur des critères, telles que GetGroupKeys, GetKeysByTag, et les requêtes SQL, ne seront pas traitées tant que les données ne seront pas entièrement chargées du magasin dans la mémoire.
Si une opération de recherche non basée sur une clé se produit pendant le chargement des données et que les données demandées ne se chargent pas complètement, l'application lèvera une exception indiquant les données ne sont pas complètement chargées à partir du magasin de persistance.
Scénarios de chargement de données
Les données sont chargées à partir du magasin de persistance dans les scénarios suivants :
Au démarrage du cache : Au démarrage du cache, le nœud coordinateur charge tous les compartiments. Dès que d'autres nœuds rejoignent le cluster, la distribution des buckets est mise à jour. Chaque nœud recherche les compartiments qui lui sont attribués dans l'environnement local. Les compartiments chargés dans le cache sont extraits transfert d'état. Si les buckets affectés à un nœud ne se chargent pas complètement, ces buckets sont chargés directement depuis le magasin par ce nœud. Chaque nœud peut accéder au magasin pour charger ses compartiments attribués s'ils sont présents dans le cache.
Lorsqu'un cache distribué avec persistance démarre pour la première fois, il peut être rempli en configurant Chargeur de démarrage du cache puisque le magasin de persistance n'a pas de données à ce moment-là. Une fois le magasin rempli, les données sont toujours chargées à partir du magasin au démarrage du cache, même si vous avez configuré le chargeur de cache. Cependant, si vous avez besoin d'ajouter plus de données périodiquement, vous pouvez utiliser Rafraîchissement du cache. Le rafraîchissement du cache s'exécute à intervalles réguliers, que le cache et le magasin contiennent déjà les données.
Lors de la jonction de nœud : Lorsqu'un nouveau nœud rejoint le cluster, il obtient les compartiments attribués des nœuds de cluster existants via le transfert d'état s'ils sont déjà chargés. Si les compartiments attribués ne se chargent pas complètement dans le cache, ils sont chargés depuis le magasin par le nouveau nœud.
Au départ du nœud : Les données sont chargées à partir du magasin pour éviter la perte de données lorsqu'un ou plusieurs nœuds quittent le cluster. Le comportement de chargement lors de la sortie d'un nœud varie selon les différentes topologies.
Topologie partitionnée : Lorsqu'un nœud quitte, ses buckets sont répartis entre les nœuds de cluster existants et chargés à partir du magasin de persistance par les nouveaux propriétaires.
Topologie de partition-réplique : Partition-Replica tolère les pannes de nœuds jusqu'à un niveau en récupérant les compartiments perdus via le transfert d'état depuis la réplique. Toutefois, lorsqu'un nœud et sa réplique sont arrêtés simultanément, les données perdues peuvent toujours être récupérées à partir du magasin de sauvegarde.
Important
Le cache doit avoir la capacité d'accueillir les données en cas de nœud inactif/quitté.
Gestion de la capacité pour un cache distribué avec persistance
Un cache persistant peut récupérer d'une perte de données lors de la fermeture ou de l'arrêt du nœud uniquement lorsque le cache dispose de suffisamment de coussin pour accueillir les données du ou des nœuds quittés. Si le cache ne peut pas accueillir toutes les données du magasin de persistance en raison de sa saturation ou pour toute autre raison, les opérations d'ajout ou de mise à jour commenceront à échouer. Pendant ce temps, certains compartiments ne disposeront pas de données complètes. Ces buckets incomplets se rechargent depuis le magasin dans deux cas :
- Un nouveau nœud rejoint le cluster.
- La taille du cache augmente grâce à l'application à chaud.
Notes
Si un cache est plein mais synchronisé à 100 % avec le magasin de persistance, seuls les nouveaux ajouts sont bloqués. Toutes les autres opérations peuvent se produire sur le cache sans aucun problème.
Lorsque le cache est plein avec des données partielles en mémoire, le cache peut ne pas servir des opérations non basées sur des clés ou basées sur des critères (telles que GetGroupKeys, GetKeysByTag, et requêtes SQL). D'autre part, les récupérations basées sur les clés seront toujours servies via le cache ou via le magasin. Plus précisément, le cache essaiera de charger paresseusement tous les téléchargements basés sur des clés pour les compartiments incomplets en cas d'échec du cache.
Si une opération de recherche basée sur des critères a lieu lorsque le cache est plein et que les données demandées ne sont pas dans le cache, une exception sera levée L'opération ne peut pas se produire car le cache n'a pas toutes les données en mémoire.
Planification de la capacité pour le cache plein
Pour éviter les problèmes soulevés par le cache plein, vous devez planifier la capacité de votre cache persistant avant de commencer à l'utiliser. Lors de la planification de la capacité d'un cache distribué avec persistance, nous vous recommandons de planifier la taille du cache par nœud afin que si un nœud tombe en panne, les nœuds restants puissent accueillir toutes les données du nœud perdu.
Extension de la taille du cache lorsque le cache est plein
Important
NCache tente d'assurer une haute disponibilité des données lors du congé d'un seul nœud dans un cache distribué basé sur une partition-réplique avec persistance grâce à l'expansion de la taille. Cependant, la haute disponibilité des données n’est ni promise ni garantie.
Dans le cas de Partition-Replica, si un nœud quitte un cluster, les nœuds restants du cluster hébergent les données appartenant au nœud sortant. Cependant, il est possible que les données du nœud sortant ne disposent pas d'espace en raison de problèmes de taille. NCache prend en charge l'expansion automatique de la taille du cache lorsqu'un nœud quitte le cache distribué basé sur la partition-réplica avec persistance. Le mode d'expansion n'est pris en charge que pour un seul nœud en panne. Le but est d'éviter les données partielles dans le cache et d'effectuer les opérations basées sur des critères sur le cache complet.
Le processus d'expansion se produit en interne. Le mode d'expansion se déclenche lorsqu'un seul nœud quitte le cluster alors que les nœuds en cours d'exécution sont égaux ou supérieurs aux nœuds configurés. La taille développée est calculée en fonction des nœuds configurés ou des nœuds en cours d'exécution dans le cluster (selon le plus élevé). Lorsque le cache est en mode étendu, chaque nœud du cluster augmente automatiquement sa taille pour accueillir les données reçues via le transfert d'état lors de la sortie du nœud.
Important
L'expansion ne se produit que lorsque le nombre de nœuds restants (après l'arrêt du nœud) est max de {nœuds configurés/nœuds en cours d'exécution}-1. La taille développée est calculée en fonction des nœuds configurés ou des nœuds en cours d'exécution dans le cluster (selon le plus élevé).
En mode étendu, les opérations basées sur les clés et les critères sont servies. Cependant, il bloquera toujours les opérations d'ajout si la taille du cache a une fois dépassé la taille du cache configuré.
Le cache sort du mode étendu lorsqu'un nouveau nœud rejoint le cluster ou que la taille du cache augmente via l'application à chaud. Ensuite, la carte de distribution est mise à jour et le transfert d'état est déclenché. Une fois le transfert d'état terminé, chaque nœud sort du mode étendu et la taille du cache est réduite à la taille de cache configurée.
Notes
Une entrée est consignée à la fois dans les journaux de cache et dans les journaux d'événements lorsque le cache entre et existe en mode étendu.
Comportements d'inaccessibilité
Les données se chargent à partir du magasin de persistance au démarrage du cache. Le magasin doit donc être disponible pour les nœuds de cache de manière cohérente. Ici, nous discutons des comportements lorsque le magasin de persistance est inaccessible ;
- Au moment de la création du cache : La connexion au magasin est vérifiée au moment de la création du cache. S'il est inaccessible, vous ne pourrez pas créer le cache et recevrez une notification d'erreur. De même, un cache ne démarrera pas si le magasin n'est disponible pour aucun nœud de cluster.
Le cache ne démarre pas tant que le magasin de persistance n'est pas accessible à tous les nœuds du serveur au moment de la création du cache.
Au moment du chargement des données : Le magasin peut devenir inaccessible pendant le chargement des données en raison d'une défaillance du réseau. Dans ce cas, le cache réessayera de charger les buckets de données restants dans l'état de chargement. Pendant ce temps, les opérations de recherche non basées sur des clés échoueront. Tu peux configurer les tentatives de chargement des données dans le fichier de configuration du service.
Au moment de l'exécution du cache : Le magasin peut devenir inaccessible pour un cache en cours d'exécution en raison d'une défaillance du réseau, soit pendant une brève période, soit pendant une durée infinie. Lors d'une telle perte de connexion, le cache continuera d'accepter et de mettre en file d'attente les opérations d'écriture. Entre-temps, NCache continuera d'essayer de conserver les opérations mises en file d'attente sur des intervalles de lot jusqu'à ce que la connexion au magasin de persistance soit rétablie.
Si vous perdez la connexion indéfiniment, les opérations d'écriture se produisent jusqu'à ce que la mémoire cache soit pleine. Une fois le cache plein, les opérations d'écriture suivantes échoueront. Cependant, les opérations de récupération basées sur les clés seront servies comme indiqué précédemment.
Création et surveillance du cache persistant
Notes
Seul le cache sérialisé JSON est pris en charge pour un cache distribué avec persistance.
Vous pouvez créer un cache distribué avec persistance en spécifiant un nouveau magasin ou un magasin existant (créé à l'aide de NCache) soit par l'intermédiaire du NCache Centre de gestion Ou à travers Outil PowerShell.
NCache fournit différents compteurs de performance pour surveiller les statistiques d'un cache distribué avec persistance. De plus, vous pouvez surveiller un cache distribué avec persistance par l'intermédiaire du NCache Outil Monitor, PowerShell et PerfMon.
Voir aussi
Créer un cache distribué avec persistance
Premiers pas avec le cache distribué avec persistance