NCache Benchmarks de Performance
2 millions d'opérations/s
(Cluster à 5 nœuds)
Préface
NCache peut vous aider à évoluer linéairement et à améliorer les performances facilement et à moindre coût. Les entreprises Fortune 500 à travers le monde ont fait confiance NCache depuis plus de 13 ans pour éliminer les goulots d'étranglement liés aux performances liées au stockage de données et aux bases de données et pour faire évoluer les applications .NET vers le traitement transactionnel extrême (XTP).
Ce document utilisera NCache 5.0 avec des API modernes et de nouvelles fonctionnalités pour démontrer l'évolutivité linéaire et les performances extrêmes que vous pouvez obtenir pour vos applications .NET. Dans cette expérience, nous avons regroupé un modem NCache API avec une topologie de cache partitionné avec pipeline activé. Les données sont entièrement distribuées sur tous les serveurs de mise en cache et les clients se connectent à tous les serveurs pour les demandes de lecture et d'écriture.
Dans ce benchmark, nous démontrons que le NCache cluster peut évoluer linéairement et que nous avons atteint 2 millions de transactions par seconde en utilisant seulement 5 nœuds de serveur de cache. Nous allons également démontrer que NCache peut fournir une latence inférieure à la microseconde même dans un grand cluster. Dans ce livre blanc, nous couvrirons les paramètres de référence, les étapes d'exécution des références, les configurations de test, les configurations de charge et les résultats. Vous pouvez voir l'expérience de référence en action dans ce vidéo.
Aperçu de la configuration de l'analyse comparative
Passons en revue notre configuration de référence. Nous allons utiliser les serveurs AWS m4.10xlarge pour ce test. Nous en avons cinq NCache serveurs sur lesquels nous allons configurer notre cluster de cache. Nous aurons 15 serveurs clients, à partir desquels nous exécuterons des applications pour se connecter à ce cluster de cache.
Nous allons utiliser Windows Server 2016 comme système d'exploitation - Data Center Edition, 64 bits. Le NCache la version utilisée est 5.0 Enterprise. Dans cette configuration de référence, nous utiliserons un Topologie de cache partitionné. Dans une topologie de cache partitionné, toutes les données seront entièrement distribuées dans des partitions sur tous les serveurs de mise en cache. Et tous les clients seront connectés à tous les serveurs pour les demandes de lecture et d'écriture afin d'utiliser tous les serveurs en même temps. La réplication n'est pas activée pour cette topologie, mais il existe d'autres topologies telles que Topologie de réplique partitionnée qui est équipé d'un support de réplication.
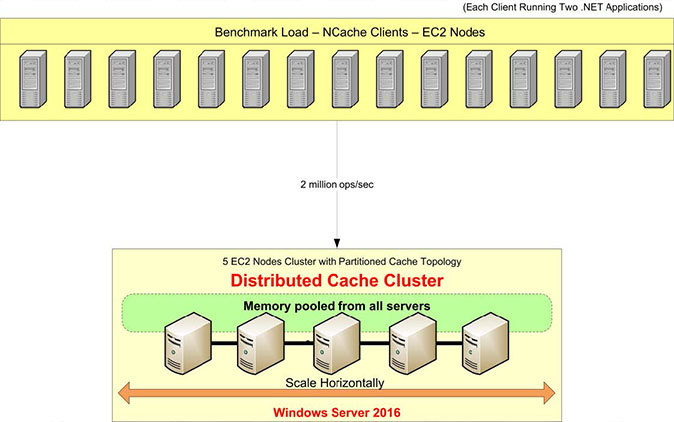
Nous aurons Pipelining activé qui est une nouvelle fonctionnalité dans NCache 5.0. Il fonctionne de telle manière que du côté client, il accumule toutes les requêtes qui se produisent au moment de l'exécution et qu'il applique ces requêtes en même temps du côté serveur. L'accumulation se fait en micro-secondes, elle est donc très optimisée et c'est la configuration recommandée lorsque vous avez des exigences de charge transactionnelle élevées.
Voici un aperçu rapide de notre configuration de référence, y compris les configurations matérielles, logicielles et de charge.
Configuration matérielle:
| Détails du client et du serveur (Machine virtuelle) |
AWS m4.10xlarge : 40 cœurs, 160 Go de mémoire, réseau - Ethernet 10 Gbit/s |
| Nombre de nœuds de serveur | 5 |
| Nombre de nœuds clients | 15 |
Configuration du logiciel:
| Système d'exploitation | Windows Server 2016 Édition centre de données – x64 |
| NCache Version | 5.0 |
| Topologie de cluster | Configuration du cache partitionné |
Charger la configuration:
| Taille du cache | 4 GB |
| Taille des données | Tableau d'octets de taille 100 |
| Articles au total | 1,000,000 |
| Pipelining | Activé |
| Obtenir/Mettre à jour le rapport | 80:20 |
| Threads | 1280 |
| Instances d'application | 2 instances par ordinateur client, 30 instances au total |
Population de données
Après la configuration de notre environnement de référence, nous commencerons avec une population de données d'un million d'éléments dans le cluster de cache. Nous allons exécuter l'application client (Cache Item Loader) qui va se connecter et ajouter 1 million d'éléments dans le cache. Un client se connectera à tous les serveurs de mise en cache et ajoutera 1 million d'éléments dans le cluster de cache, après quoi nous pourrons commencer avec les requêtes de lecture et d'écriture.
Vous pouvez utiliser cette Forfait Nuget – NCache SDK pour installer le SDK sur la machine cliente et configurer le pipelining entre le client-serveur et déployer l'application de génération de charge (GitHub) pour remplir 1 million d'éléments de cache sur le cluster de cache.
Créer une charge de transaction
Nous allons maintenant exécuter l'application pour générer une charge transactionnelle sur ce cluster de cache avec 80 % d'opérations de lecture et 20 % d'écriture. Vous pouvez surveiller toutes les activités à l'aide des compteurs Perfmon. Dans un premier temps, nous allons connecter 10 instances clients à chacune NCache serveur avec activité sur les récupérations ainsi que sur les mises à jour par seconde.
Étape 1 Charge de transaction d'un million d'opérations/seconde
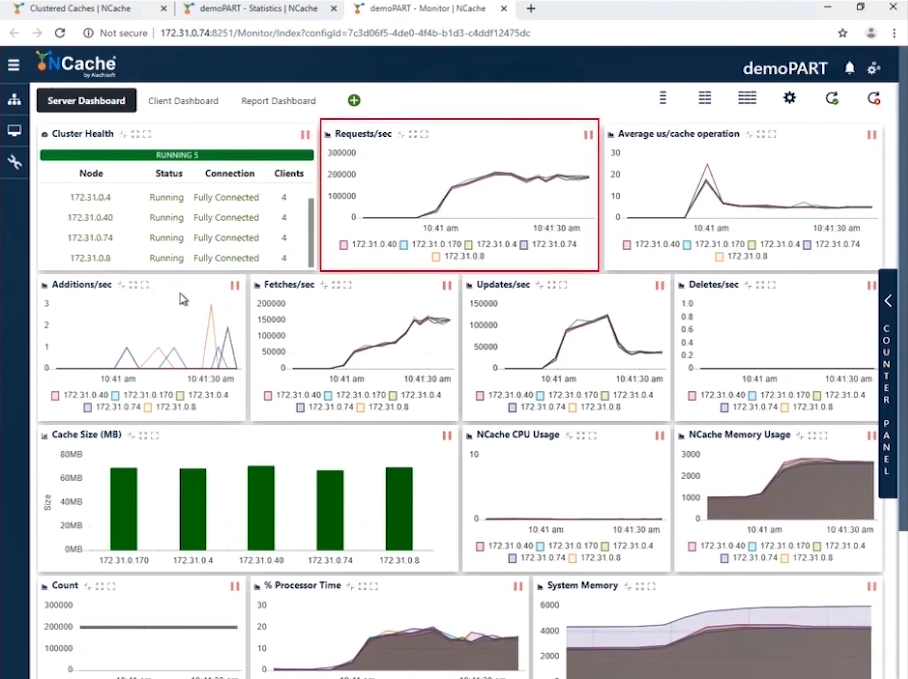
Vous pouvez voir dans la capture d'écran qu'avec 10 instances clientes se connectant à un cluster à 5 nœuds, nous avons des requêtes par seconde numérotées entre 180,000 190,000 et 5 XNUMX. Et puisque nous avons XNUMX NCache serveurs qui fonctionnent en parallèle, l'accumulation de ces requêtes nous amène à 1 Million de requêtes par seconde par ce cluster de cache.
Nous avons une utilisation efficace de la mémoire et du processeur et l'opération moyenne en microsecondes/cache est d'un peu moins de 10 microsecondes par opération. Notre première étape est terminée lorsque nous avons atteint 1 million d'opérations par seconde à partir de notre cluster de cache.
| Étape 1 – Fiche de données récapitulative | |
| Nombre total de serveurs de cache dans le cluster | 5 |
| Nombre total d'instances client connectées | 10 |
| Requêtes par seconde/nœud | 180,0000 ~ 190,000 |
| Requêtes totales - Cluster de cache | 950,000 ~ 1,000,000 |
| % Temps processeur (Max) | 20% |
| Mémoire système | 4.2 GB |
| Latence (microseconde/opération de cache) | 10 microsecondes/opération |
Étape 2 Charge de transaction d'un million d'opérations/seconde
Maintenant que nous avons atteint le million de TPS, il est temps d'augmenter la charge sous la forme d'instances d'application supplémentaires pour augmenter la charge transactionnelle. Et dès que ces applications s'exécuteraient, vous verriez une augmentation du compteur de requêtes par seconde. Nous allons augmenter le nombre de clients à 1. Avec cette configuration, vous pouvez voir dans la capture d'écran ci-dessous que nous affichons maintenant 20 300,000 requêtes par seconde et par instance. Nous avons réussi à atteindre 1.5 million de requêtes par seconde à partir de ce cluster de cache.
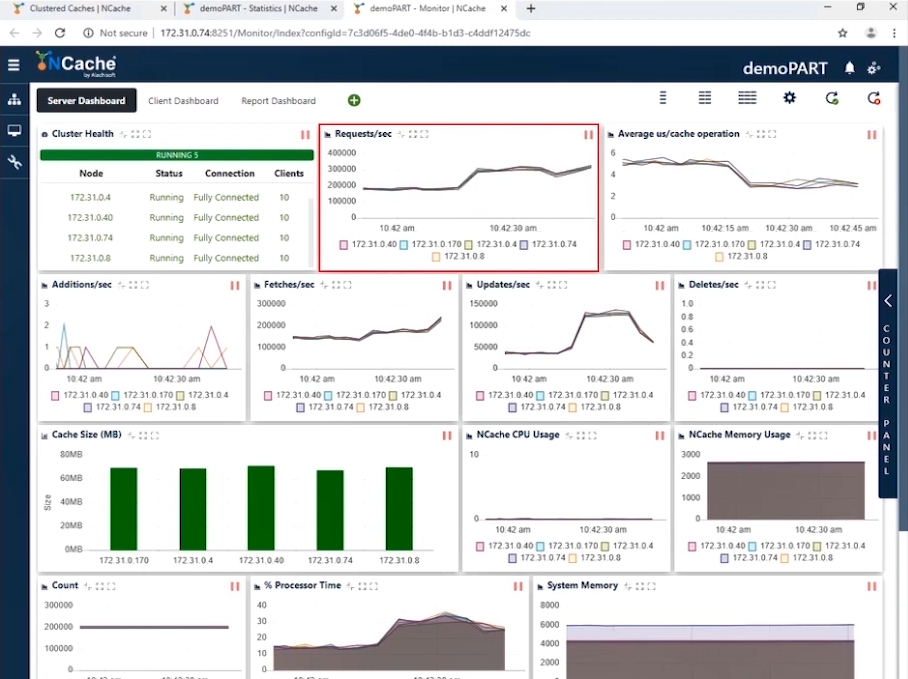
Vous pouvez voir que le nombre de requêtes par seconde par chaque serveur est de 300,000 200,000. Les extractions sont un peu plus de 50,000 100,000 par seconde et les mises à jour se situent entre 4 3 et 4 XNUMX et vous pouvez voir que la microseconde moyenne par opération de cache est inférieure à XNUMX microsecondes ; c'est incroyable parce que nous avons une latence très faible avec l'impact du pipelining. Lorsque vous avez une charge transactionnelle élevée du côté client, le pipelining aide vraiment et réduit la latence et augmente le débit. C'est pourquoi nous vous recommandons de l'activer. De plus, nous avons la microseconde moyenne par opération de cache maintenant autour de XNUMX-XNUMX microsecondes par opération de cache.
| Étape 2 – Fiche de données récapitulative | |
| Nombre total de serveurs de cache dans le cluster | 5 |
| Nombre total d'instances client connectées | 20 |
| Moy. Requêtes par seconde/nœud | 300,000 |
| Requêtes totales - Cluster de cache | 1,500,000 |
| % Temps processeur (Max) | 30% |
| Mémoire système | 6 GB |
| Latence (microseconde/opération de cache) | 3 ~ 4 microsecondes/opération |
Étape 3 Charge de transaction d'un million d'opérations/seconde
Augmentons encore la charge en exécutant d'autres instances d'application qui afficheront également une nouvelle augmentation du nombre de requêtes par seconde. Nous allons maintenant connecter 30 instances de clients à toutes NCache les serveurs.
Selon la capture d'écran ci-dessous, vous pouvez maintenant voir que nous avons réussi à traiter 400,000 XNUMX requêtes par seconde que nous recevons chacune NCache serveur; nous avons 5 NCache serveurs, ce qui porte le nombre à deux millions de transactions par seconde par ce NCache grappe de cache. Et nous avons le nombre moyen de microsecondes par opération de cache inférieur à 3 microsecondes. Nous avons également la mémoire système et le temps processeur bien en deçà des limites avec une utilisation de 40 à 50 % sur les deux fronts.
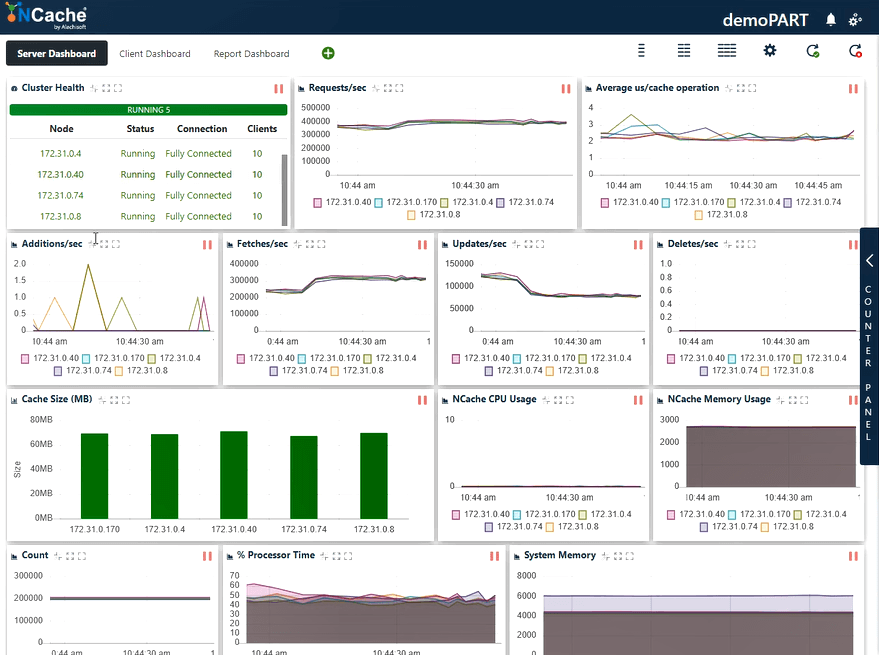
Nous avons maintenant une latence de 2 ~ 3 us/opération, une amélioration par rapport au résultat précédent. Vous pouvez à nouveau voir un mélange de récupérations, de mises à jour et une utilisation efficace des ressources CPU et mémoire. Nous pouvons conclure ici que NCache est linéairement évolutif. Passons maintenant en revue nos chiffres d'évolutivité.
| Étape 3 – Fiche de données récapitulative | |
| Nombre total de serveurs de cache dans le cluster | 5 |
| Nombre total d'instances client connectées | 30 |
| Moy. Requêtes par seconde/nœud | 400,000 |
| Requêtes totales - Cluster de cache | 2,000,000 |
| % Temps processeur (Max) | 60% |
| Mémoire système | 6 GB |
| Latence (microseconde/opération de cache) | 2 ~ 3 microsecondes/opération |
Résultats de référence
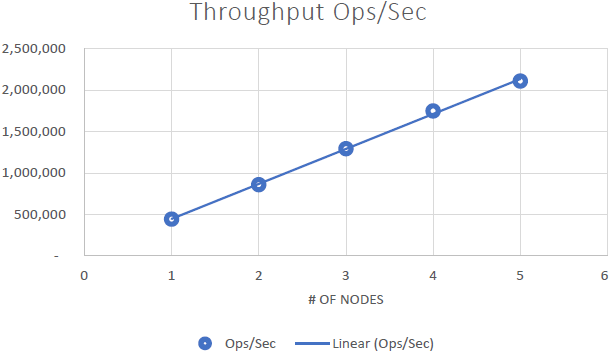
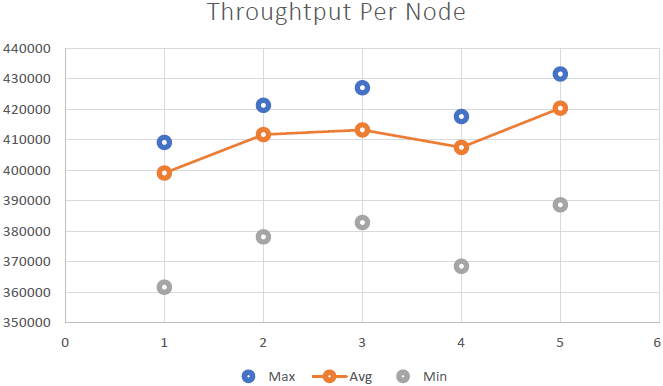
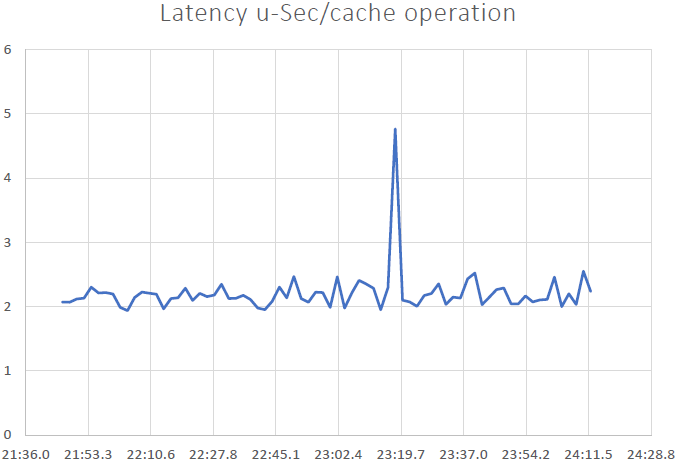
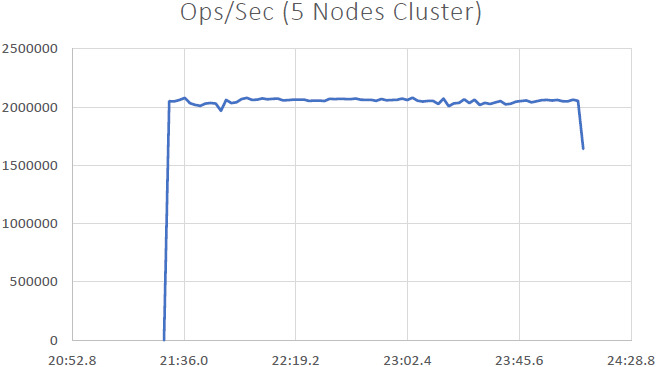
Nous avons pu démontrer que NCache est linéairement évolutif et nous avons pu obtenir les résultats suivants après avoir exécuté les benchmarks :
Conclusions
- Évolutivité linéaire : Avec 5 NCache serveurs, nous avons pu atteindre 2 millions de requêtes par seconde. L'ajout de plus en plus de serveurs signifie plus de capacités de traitement des demandes de NCache.
- Faible latence et haut débit : NCache offre une latence inférieure à la microseconde (2.5 ~ 3 microsecondes) même avec une grande taille de cluster. NCache permet de répondre aux exigences de faible latence et de débit élevé, même à grande échelle. Nous avons une latence très faible, un impact dérivé du pipelining. Lorsque vous avez des charges transactionnelles élevées du côté client, le pipelining aide vraiment et réduit la latence et augmente le débit.