Le applicazioni moderne elaborano e generano grandi volumi di dati. La possibilità che un singolo server Web/fonte di dati si guasti, con conseguente perdita di applicazioni e dati inestimabili, è un incubo comune tra gli sviluppatori di software. Tuttavia, è possibile ottenere un'elevata disponibilità dei dati se tutti i nodi del server dispongono di una copia identica dei dati: ciò implica che non si verificherà alcuna perdita di dati in caso di errore di alcuni nodi nel cluster. Ma cosa succede quando i dati iniziano ad espandersi in modo significativo? In casi come questi, è necessario richiamare la replica e iniziare a partizionare i dati.
NCache essendo una soluzione di memorizzazione nella cache distribuita e in memoria, offre scalabilità, prestazioni e disponibilità elevate per applicazioni a uso intensivo di dati. Anticipa il POR (Replica partizionata) per dividere i dati in più blocchi (bucket) e posizionarli in partizioni diverse. Per distribuire uniformemente i carichi di lettura e scrittura, i dati vengono partizionati su diversi nodi. Questo risolve il problema iniziale nel raggiungere la scalabilità dividendo i dati, ma in che modo esattamente i dati vengono partizionati equamente? Questo blog ha lo scopo di istruirti su come avviene il partizionamento dei dati NCache.
Partizionamento basato su hash per una distribuzione uniforme dei dati
Il più delle volte, varie applicazioni utilizzano la strategia round-robin per assegnare i dati a diverse partizioni. Sebbene questo approccio garantisca una distribuzione uniforme, presenta una sfida quando si tratta di individuare elementi di dati specifici. La ricerca e il recupero dei dati può diventare dispendioso in termini di tempo e inefficace senza alcun modo per tenere traccia delle posizioni degli articoli.
Per risolvere questo problema, NCache incorpora Partizionamento basato su hash. I dati vengono suddivisi in molti bucket che vengono successivamente dispersi tra diverse partizioni. L'obiettivo è distribuire uniformemente i bucket tra i nodi del cluster per ottimizzare le prestazioni e garantire un'elevata disponibilità. Per realizzare questo, NCache utilizza una tecnica di hashing che associa ciascun elemento di dati a un bucket specifico in base alla chiave dell'elemento. Ora, per capire il proprietario del bucket, devi applicare la funzione hash sulla chiave dell'elemento e modificarla in base al numero totale di bucket: abbiamo 1000 bucket in totale.
Cos'è una mappa di distribuzione?
Il server coordinatore è essenziale in un cluster di cache distribuita perché supervisiona la distribuzione del bucket e garantisce che ogni elemento sia assegnato a un particolare bucket in base alla sua chiave. Per raggiungere questo obiettivo, il server coordinatore crea un file mappa di distribuzione inclusa la distribuzione del bucket e la distribuisce a tutte le altre partizioni nel cluster, nonché a tutti i client connessi.
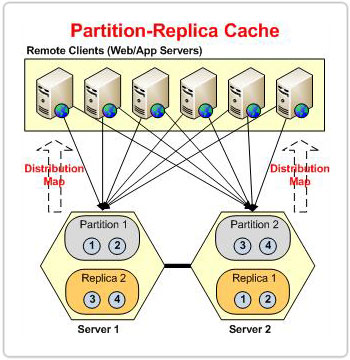
Figura 1: partizioni sulla base della mappa di distribuzione nella topologia POR
Indipendentemente dal numero di server presenti nel cluster, NCache si assicura che a ogni articolo venga assegnato un indirizzo bucket coerente tramite questo metodo. Questo perché il mappa di distribuzione rimane costante, anche se il numero di server nel cluster cambia. Di conseguenza, anche se un bucket si sposta da una partizione all'altra in qualsiasi momento, l'indirizzo del bucket di un elemento rimane lo stesso. Ciò garantisce che i dati rimangano intatti e che nessun dato venga perso durante i movimenti del bucket.
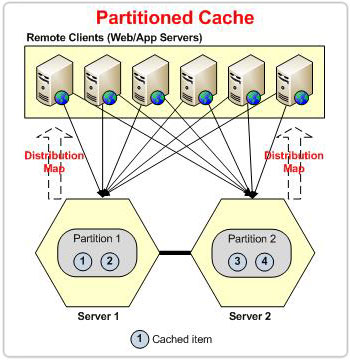
Figura 2: partizione sulla base della mappa di distribuzione nella topologia delle partizioni
In caso di topologia partizionata, ogni volta che un nodo lascia il cluster, il cluster subisce una perdita di dati. I bucket di proprietà del nodo uscente andranno tutti persi. Tuttavia, in caso di POR, la replica è presente su un altro nodo che sarà redistributato sulla base della mappa di distribuzione – prevenendo la perdita di dati.
Distribuzione dei dati basata su una mappa di distribuzione
I dati vengono distribuiti equamente tra tutti i nodi nel cluster di cache grazie alla strategia di distribuzione dinamica dei bucket offerta da NCache. Tutti i 1000 bucket vengono assegnati al nodo quando avvii un cluster di cache, il che comporta l'archiviazione di tutti i dati in una singola partizione. Per fornire le migliori prestazioni e bilanciamento del carico, i bucket vengono quindi divisi equamente tra le partizioni quando vengono aggiunti più nodi al cluster.
I 1000 bucket, ad esempio, vengono divisi equamente tra le due partizioni quando viene aggiunto un secondo nodo al cluster, dando a ciascuna suddivisione 500 bucket. Allo stesso modo, quando un terzo nodo entra nel cluster, i bucket lo sono redistributato, assegnando a ciascuna partizione 333, 333 e 334 bucket, di conseguenza.
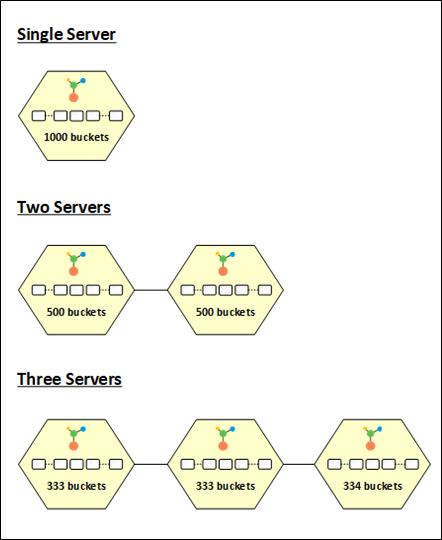
Figura 3: NCache Distribuzione del secchio
La distribuzione del bucket viene modificata ancora una volta se una partizione lascia il cluster. Per mantenere una distribuzione uniforme dei dati, ad esempio, quando una partizione esce da un cluster a tre nodi, i bucket 333 o 334 che appartengono a quella partizione vengono dispersi tra i due nodi rimanenti. NCacheIl meccanismo di trasferimento dello stato di interviene per ribilanciare i dati tra i nodi ogni volta che cambia la distribuzione del bucket, assicurando che i dati siano distribuiti in modo ottimale in conformità con la distribuzione del bucket. Allo stesso modo, il client riceve anche la mappa di distribuzione che informa sui nodi del server in esecuzione e sulle loro distribuzioni basate su hash.
Bilanciamento del carico dei dati
Mentre redistributing bucket attorno ai nodi del cluster di cache, NCache adotta una strategia incentrata sui dati per assicurarsi che la quantità di dati che ogni partizione riceve sia bilanciata. Per fare ciò, ogni partizione del cluster scambia periodicamente le statistiche dei bucket di sua proprietà con le altre partizioni del cluster. Ciò consente la creazione di un equilibrato mappa di distribuzione che tiene conto della quantità di dati posseduta da ciascuna partizione. NCache bilancia automaticamente i dati per garantire che ogni partizione riceva una quota uguale di dati. Consente inoltre di bilanciare i dati manualmente. Puoi leggere di più a riguardo qui.
Conclusione
In conclusione, utilizzando POR per dividere i dati in NCache è una tecnica utile per migliorare la velocità e la scalabilità delle applicazioni. Puoi garantire che i dati siano sempre disponibili e ridurre la possibilità di colli di bottiglia delle prestazioni suddividendo i dati in blocchi più piccoli e distribuendoli su numerosi nodi di cache.





