Sei motivi per cui NCache è meglio di Redis
Webinar registrato
Di Iqbal Khan
Scopri come Redis ed NCache confrontare tra loro a livello di funzionalità. L'obiettivo di questo webinar è rendere più semplice e veloce il tuo compito di confrontare i due prodotti.
Il webinar tratta quanto segue:
- Diverse aree funzionali del prodotto.
- Cosa fa il supporto Redis ed NCache fornire in ogni area caratteristica?
- Quali sono i punti di forza di NCache ancora Redis e viceversa?
NCache è una popolare cache distribuita in memoria open source (licenza Apache 2.0) per .NET. NCache è comunemente usato per la memorizzazione nella cache dei dati delle applicazioni, l'archiviazione dello stato della sessione ASP.NET e la condivisione dei dati di runtime in stile pub/sub tramite eventi.
Redis è anche un popolare archivio di strutture dati in memoria Open Source (licenza BSD) utilizzato come database, cache e broker di messaggi. Redis è molto popolare su Linux ma ultimamente ha attirato l'attenzione su Azure grazie alla promozione di Microsoft.
Panoramica
Ciao a tutti, mi chiamo Iqbal Khan e sono un evangelista tecnologico presso Alachisoft. Alachisoft è una società di software con sede nella Baia di San Francisco ed è il produttore del popolare NCache product, che è una cache distribuita open source per .NET. Alachisoft è anche il creatore di NosDB, che è un database open source senza SQL per .NET. Oggi parlerò di sei motivi per cui NCache è meglio che Redis per applicazioni .NET. Redis, come sai, è sviluppato da Redis labs ed è stato scelto da Microsoft per Azure. Il motivo principale della scelta era quello Redis offre supporto multipiattaforma e molte lingue diverse, mentre NCache è esclusivamente incentrato su .NET. Quindi iniziamo.
Cache distribuita
Prima di entrare nei confronti, lascia che ti dia una breve introduzione di cos'è la cache distribuita e perché ne hai bisogno e quale problema risolve. La cache distribuita viene effettivamente utilizzata per migliorare la scalabilità delle applicazioni. Come sai, se disponi di un'applicazione Web o di un'applicazione di servizi Web o di qualsiasi applicazione server, puoi aggiungere più server a livello di applicazione. Di solito le architetture dell'applicazione consentono che ciò avvenga senza problemi. Tuttavia, non puoi fare lo stesso a livello di database, soprattutto se stai utilizzando un database relazionale o dati mainframe legacy. Puoi farlo senza SQL. Ma sai, nella maggior parte dei casi devi usare database relazionali sia per motivi tecnici che commerciali.
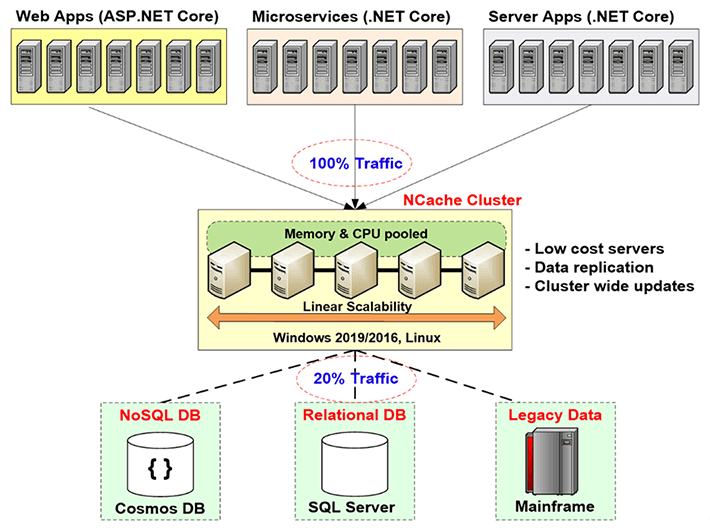
Quindi, devi risolvere questo collo di bottiglia della scalabilità che i database relazionali o il mainframe legacy ti danno attraverso la memorizzazione nella cache distribuita e il modo in cui lo fai è creare un livello di memorizzazione nella cache tra il livello dell'applicazione e il database. Questo livello di memorizzazione nella cache è costituito da due o più server. Questi sono solitamente server a basso costo. In caso di NCache, la configurazione tipica è una doppia CPU, macchina quad-core, con da 16 a 32 giga di RAM e da una a due schede di rete, che hanno una velocità compresa tra 1 e 10 gigabit. Questi server di cache formano un cluster basato su TCP in caso di NCache e per raggruppare le risorse di tutti questi server in un'unica capacità logica. In questo modo man mano che cresci, il livello dell'applicazione, diciamo se hai sempre più traffico o un carico di transazioni sempre maggiore, puoi aggiungere più server al livello dell'applicazione. Puoi anche aggiungere più server al livello di memorizzazione nella cache. Solitamente si mantiene un rapporto di 4 a 1 o 5 a 1 tra il livello dell'applicazione e il livello di memorizzazione nella cache.
Quindi, per questo motivo la cache distribuita non diventa mai un collo di bottiglia. Quindi, puoi iniziare a memorizzare nella cache i dati dell'applicazione qui e ridurre il traffico al database. L'obiettivo è che circa l'80% del tuo traffico vada alla cache e circa il 20% del traffico, che di solito è costituito dai tuoi aggiornamenti, vada al database. E se lo fai, la tua applicazione non dovrà mai affrontare un collo di bottiglia della scalabilità.
Usi comuni della cache distribuita
Va bene, tenendo presente il vantaggio di una cache distribuita, parliamo dei diversi casi d'uso che conosci, delle diverse situazioni in cui puoi utilizzare una cache distribuita.
Memorizzazione nella cache dei dati dell'applicazione
Il numero uno è l'Application Data Caching, che è lo stesso che ho appena spiegato dove si memorizzano nella cache i dati che risiedono nel database, in modo da poter migliorare le prestazioni e la scalabilità. La cosa principale da tenere a mente per un'applicazione di memorizzazione nella cache dei dati è che i tuoi dati ora esistono in due posti. Esiste nel tuo database che è l'origine dei dati principali ed esiste anche nel livello di memorizzazione nella cache e quando ciò accade, la cosa più importante che devi tenere a mente è che, sai, la preoccupazione più grande che viene è, sai , la cache diventerà obsoleta? La cache avrà una versione precedente dei dati, anche se i dati sono stati modificati nel database. Se si verifica questa situazione, ovviamente hai un grosso problema e molte persone a causa di questa paura dei problemi di integrità dei dati, memorizzano nella cache solo i dati di sola lettura. Bene, i dati di sola lettura sono un sottoinsieme molto piccolo dei dati totali che dovresti memorizzare nella cache e rappresentano circa il dieci-quindici percento dei dati.
Il vero vantaggio sta nel fatto che puoi iniziare a memorizzare nella cache i dati transazionali. Questi sono i tuoi clienti, le tue attività, la tua cronologia, sai, tutti i tipi di dati che vengono creati in fase di esecuzione e cambiano molto frequentemente, devi comunque memorizzare nella cache quei dati ma devi memorizzarli nella cache in modo che la cache sia sempre rimane fresco. Quindi, questo è il primo caso d'uso e su questo torneremo.
Memorizzazione nella cache specifica di ASP.NET
Il secondo caso d'uso riguarda la memorizzazione nella cache specifica di ASP.NET, in cui si memorizza nella cache lo stato della sessione, lo stato di visualizzazione e se non si dispone del framework MVC e di un output di pagina. In questa situazione, stai memorizzando nella cache lo stato della sessione perché una cache è un archivio molto più veloce e scalabile del tuo database, che è dove altrimenti memorizzeresti nella cache queste sessioni o le altre opzioni fornite da Microsoft e, in questo caso i dati sono transitorio. Transitorio significa che è di natura temporanea. È necessario solo per un breve periodo di tempo, dopodiché lo butti via e i dati esistono solo nella cache. La cache è il negozio principale. Quindi, in questo caso d'uso, la preoccupazione non è che la cache debba essere sincronizzata con il database, ma invece la preoccupazione è che se un server della cache si interrompe, perdi alcuni dati. Perché è tutto spazio di archiviazione in memoria e la memoria, come sai, è volatile. Quindi, una buona cache distribuita deve fornire strategie di replica intelligenti. Quindi, che tutti i dati esistano in più di un server. Se un server si interrompe, non si perdono dati, ma la replica ha un costo associato, il costo delle prestazioni. Quindi, la replica deve essere super veloce, ecco cosa NCache fa, tra l'altro.
Condivisione dei dati di runtime
Il terzo caso d'uso è il caso d'uso Runtime Data Sharing, in cui si utilizza la cache essenzialmente come piattaforma di condivisione dei dati. Quindi, molte applicazioni diverse sono collegate alla cache e possono condividere i dati in un modello Pub/Sub. Quindi, un'applicazione produce i dati, li mette nella cache, attiva un evento e altre applicazioni che hanno registrato interesse per quell'evento verranno avvisate, quindi possono andare e consumare quei dati. Quindi, ci sono anche altri eventi. Ci sono eventi basati su chiavi, eventi a livello di cache, c'è una funzione di query continua che NCache ha. Quindi, ci sono diversi modi in cui puoi utilizzare una cache distribuita come NCache per condividere i dati tra diverse applicazioni. Anche in questo caso, anche se i dati vengono creati dai dati nel database ma la forma in cui vengono condivisi può esistere solo nella cache. Quindi, devi assicurarti che la cache replichi i dati. Quindi, la preoccupazione è la stessa della memorizzazione nella cache di ASP.NET. Quindi, questi sono i tre casi d'uso comuni per un uso della cache distribuita. Per favore, tieni a mente questi casi d'uso mentre confronto le funzionalità che NCache fornisce quale Redis non.
Motivo 1: mantenere la cache fresca
Quindi, il primo motivo, perché dovresti usare NCache ancora Redis è questo, NCache fornisce funzionalità molto potenti per mantenere la cache fresca. Mentre ne abbiamo parlato, se non riesci a mantenere la cache fresca, sei costretto a memorizzare nella cache i dati di sola lettura e se i tuoi dati di sola lettura memorizzano nella cache, sai, questo non è il vero vantaggio. Quindi, devi essere in grado di memorizzare nella cache praticamente tutti i tuoi dati. Anche i dati che cambiano ogni 10-15 secondi.
Scadenze assolute / Scadenze decrescenti
Quindi, il primo modo per mantenere la cache fresca è attraverso le scadenze. La scadenza è qualcosa che entrambi NCache ed Redis fornire. Quindi, ad esempio, c'è una scadenza assoluta in cui dici alla cache di far scadere questi dati dopo 10 minuti o 2 minuti o 1 minuto. Dopo quel tempo, la cache rimuove quei dati dalla cache e stai facendo un'ipotesi, stai dicendo, sai, penso che sia sicuro mantenere questi dati nella cache per così tanto tempo perché non penso che lo farà modifica nel database. Quindi, sulla base di tale ipotesi, stai dicendo alla cache di far scadere i dati.
Ecco come appare la scadenza. Ti mostro solo una cosa. In caso di NCache, durante l'installazione NCache a proposito, sai, ti dà un sacco di campioni. Quindi, uno degli esempi si chiama operazioni di base che ho aperto qui. Quindi, nelle operazioni di base, lascia che ti dia anche rapidamente, ecco cosa usa una tipica applicazione .NET NCache sembra.
Ti colleghi con NCache in fase di esecuzione NCache.Web assembly quindi si utilizza il NCache.Durata spazio dei nomi, NCache.Web.Caching namespace e quindi all'inizio della tua applicazione, ti connetti con la cache. Tutte le cache sono nominate.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Se vuoi come creare una cache, guarda il nostro video introduttivo. Questo è disponibile sul nostro sito web. Ma diciamo che ti sei connesso a questa cache, quindi hai un handle di cache. Ora crei i tuoi dati, che sono un mucchio di oggetti e poi lo fai cache.Aggiungi. cache.Aggiungi ha una chiave che è una stringa e il valore effettivo che è il tuo oggetto e quindi in questo caso stai specificando una scadenza assoluta di un minuto. Quindi, stai dicendo di far scadere questo oggetto tra un minuto e dicendo che lo stai dicendo NCache per far scadere questo oggetto. Quindi, è così che funziona la scadenza che ovviamente, come ho detto, Redis fornisce anche te.
Sincronizza la cache con il database
Ma il problema con la scadenza è che stai facendo un'ipotesi che potrebbe non essere corretta, potrebbe non essere accurata. Quindi, cosa succede se i dati cambiano prima di un minuto prima di quei cinque minuti che avevi specificato. Quindi, è qui che hai bisogno di quest'altra funzionalità chiamata sincronizzare la cache con il database. Questa è la caratteristica che NCache ha e Redis non ha.
Così, NCache lo fa in diversi modi. Il primo è il numero Dipendenza SQL. La dipendenza SQL è una caratteristica del server SQL tramite ADO.NET, in cui in pratica specifichi un'istruzione SQL e dici al server SQL e dici, sai, per favore monitora questo set di dati e se questo set di dati cambia, significa che viene aggiunta qualsiasi riga , aggiornato o cancellato che corrisponde ai criteri di questo set di dati, per favore avvisami. Quindi, il database ti invia una notifica del database e quindi puoi intraprendere l'azione appropriata. Quindi, il modo NCache questo è, NCache utilizzerà la dipendenza SQL e c'è anche una dipendenza Oracle che fa la stessa cosa con Oracle. Entrambi funzionano con gli eventi del database. Così, NCache utilizzerà la dipendenza SQL. Lascia che ti mostri quel codice qui. Quindi, andrò solo al codice di dipendenza SQL. Ancora una volta, allo stesso modo si collega ad alcuni degli assiemi. Ottieni l'handle della cache e ora che stai aggiungendo roba, vado solo a questo, vado alla definizione. Quindi, ora che stai aggiungendo questi dati, come parte dell'aggiunta specifichi una dipendenza SQL. Quindi, la dipendenza dalla cache è un NCache classe che accetta una stringa di connessione al database. Ci vuole un'istruzione SQL. Quindi, diciamo, in questo caso stai dicendo, voglio che l'istruzione SQL sia dove l'ID prodotto è questo ID. Quindi, dal momento che stai memorizzando nella cache un oggetto prodotto, lo stai abbinando alla riga corrispondente nella tabella del prodotto. Quindi, stai dicendo, stai dicendo NCache per parlare con il server SQL e utilizzare la dipendenza SQL in modo che il server SQL possa monitorare questa istruzione e se questi dati cambiano, il server SQL notifica NCache.
Quindi, ora il server cache è diventato un client del tuo database. Quindi, il server della cache ha chiesto al tuo server SQL di informarmi se questo set di dati cambia e quando quel set di dati cambia Il server SQL notifica il server della cache e il NCache il server rimuove quindi quell'elemento dalla cache e il motivo per cui lo rimuove è perché una volta rimosso la prossima volta che ne avrai bisogno non lo troverai nella cache e sarai costretto a recuperarlo dal database. Quindi, è così che lo aggiorni. C'è un altro modo per ricaricare automaticamente l'elemento di cui parlerò tra poco.
Quindi, la dipendenza SQL lo consente NCache per sincronizzare davvero la cache con il database e con la dipendenza Oracle funziona esattamente allo stesso modo, tranne per il fatto che funziona con Oracle anziché con SQL Server. La dipendenza SQL è davvero potente ma è anche loquace. Quindi, diciamo, se hai 10,000 elementi o 100,000 elementi creerai 100,000 dipendenze SQL che comportano un sovraccarico di prestazioni sul database del server SQL perché per ogni dipendenza SQL il database del server SQL crea una struttura di dati e il server per monitorare quei dati e questo è un sovraccarico extra.
Quindi, se hai molti dati da sincronizzare, forse è meglio limitarsi alla dipendenza dal DB. Le dipendenze DB sono la nostra caratteristica in cui invece di utilizzare un'istruzione SQL e gli eventi del database, NCache effettivamente estrae il database. C'è una tabella speciale che crei e si chiama NCache Sincronizzazione DB e quindi modifichi i tuoi trigger, in modo da andare ad aggiornare un flag di seguito, corrispondente a questo elemento memorizzato nella cache e quindi NCache estrae questa tabella ogni tanto, diciamo, ogni 15 secondi circa per impostazione predefinita e quindi puoi, sai, se trova una riga che è stata modificata, invalida gli elementi memorizzati nella cache corrispondenti dalla cache. Quindi, sia questi che ovviamente la dipendenza dal DB possono funzionare su qualsiasi database. Non è solo SQL Server, Oracle ma anche se hai un DB2 o MySQL o altri database.
Quindi, con la combinazione di queste funzionalità, ti senti davvero sicuro che la tua cache sarà sempre sincronizzata con il database e che potrai memorizzare nella cache praticamente tutti i dati. C'è un terzo modo che è una stored procedure CLR, in modo che tu possa effettivamente implementare una stored procedure CLR. Da lì puoi fare un NCache chiamata. In questo modo, si chiama la stored procedure dal trigger del database. Diciamo che hai una tabella cliente e hai un trigger di aggiornamento o un trigger di eliminazione o anche un trigger di aggiunta in realtà. In un caso di procedura CLR, puoi anche aggiungere nuovi dati. Quindi, questa è la procedura CLR che viene chiamata dal trigger e la procedura CLR crea NCache chiamate e in questo modo stai praticamente facendo in modo che il database aggiunga i dati o aggiorni i dati nella cache.
Quindi, quei tre modi diversi lo consentono NCache da sincronizzare con il database e questo è un motivo davvero potente per l'utilizzo NCache ancora Redis perché Redis ti obbliga a utilizzare solo scadenze che non sono sufficienti. Ti rende davvero vulnerabile o ti costringe a memorizzare nella cache i dati di sola lettura.
Sincronizza la cache con il database non relazionale
Puoi anche sincronizzare la cache con database non relazionali. Quindi, se hai un database legacy, mainframe, puoi avere una dipendenza personalizzata che è il tuo codice che viene eseguito sul server cache e ogni tanto NCache chiama il tuo codice per monitorare l'origine dati e puoi magari effettuare chiamate al metodo Web o fare altre cose per monitorare l'origine dati personalizzata e in questo modo puoi sincronizzare l'elemento memorizzato nella cache con le modifiche ai dati in tale origine dati personalizzata. Quindi, la sincronizzazione del database è un motivo molto potente per cui dovresti usarlo NCache ancora Redis perché ora metti nella cache praticamente tutti i dati. Considerando che, in caso di Redis sarai costretto a memorizzare nella cache i dati che sono di sola lettura o dove puoi fare ipotesi con molta sicurezza su Scadenze.
Motivo 2: ricerca SQL
Motivo numero due, ok. Ora che hai, diciamo, hai iniziato a utilizzare la sincronizzazione con la funzionalità del database e ora puoi memorizzare nella cache praticamente molti dati. Quindi, più dati metti nella cache, più la cache inizia a sembrare un database e quindi se hai solo la possibilità di recuperare i dati in base alle chiavi, qual è ciò che Redis allora è molto limitante. Quindi, devi essere in grado di fare altre cose. Quindi, devi essere in grado di trovare i dati in modo intelligente. NCache offre diversi modi in cui è possibile raggruppare i dati e trovare i dati in base agli attributi dell'oggetto o in base a gruppi e sottogruppi oppure è possibile assegnare tag, tag nome. Quindi, tutti questi sono modi diversi per recuperare raccolte di dati. Ad esempio, se dovessi emettere una query SQL, lascia che ti mostri che, diciamo, faccio una query SQL qui. Quindi, voglio andare a trovare, diciamo, tutti i clienti dove customer.city è New York. Quindi, emetterò uno stato SQL, dirò clienti selezionati, sai, il mio spazio dei nomi completo, cliente in cui questo. Città è un punto interrogativo e nel valore che specificherò New York come valore e quando emettere quella query, otterrò una raccolta di quegli oggetti cliente che corrispondono a questi criteri.
Quindi, questo ora assomiglia molto a un database. Quindi, ciò significa che puoi effettivamente iniziare a memorizzare nella cache i dati. Puoi memorizzare nella cache interi set di dati, in particolare tabelle di ricerca o altri dati di riferimento in cui la tua applicazione è stata utilizzata per eseguire query SQL rispetto a quelle nel database e lo stesso tipo di query SQL che puoi eseguire NCache. L'unica limitazione è che può fare join in caso di NCache ma molti di questi non sono necessari per fare davvero le articolazioni. Ricerca SQL rende la cache molto intuitiva per cercare e trovare davvero i dati che stai cercando.
Raggruppamento e sottoraggruppamento lascia che ti mostri questo l'esempio di raggruppamento. Quindi, ad esempio qui puoi aggiungere un mucchio di oggetti e puoi aggiungerli tutti. Quindi li stai aggiungendo come gruppo. Quindi, questa è la chiave, il valore, ecco il nome del gruppo, ecco il nome del sottogruppo e poi puoi dire di darmi tutto ciò che appartiene al gruppo di elettronica. Questo ti restituisce una raccolta e puoi scorrere la raccolta per ottenere le tue cose.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}Puoi anche recuperare le chiavi in base al gruppo. Puoi fare anche altre cose in base al gruppo. Quindi, gruppi e tag funzionano in modo simile. Etichette nome sono anche gli stessi dei tag tranne per il fatto che è un concetto di valore chiave. Quindi, diciamo, se stai memorizzando nella cache del testo a mano libera e vuoi davvero ottenere alcuni dei metadati del testo indicizzati, in modo da poter utilizzare il concetto di valore chiave con le etichette dei nomi e in questo modo una volta che qualsiasi gruppo di tag e tag di nome hai quindi puoi includerli nelle query SQL.
Puoi anche emettere LINQ query. Se ti senti più a tuo agio con LINQ, puoi inviare query LINQ. Quindi, nel caso di LINQ, ad esempio, diciamo, ecco il tuo NCache. Quindi, faresti un NCache interrogare con un oggetto prodotto. Ti dà un Interrogabile interfaccia e quindi puoi eseguire una query LINQ proprio come faresti con qualsiasi raccolta di oggetti e stai effettivamente cercando nella cache.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}Quindi, quando si esegue questa query, quando si esegue questa query, si sta effettivamente andando al livello di memorizzazione nella cache e cercando gli oggetti. Quindi, sai, l'interfaccia a tua disposizione è molto semplice, in un modo molto amichevole, ma dietro le quinte in realtà sta memorizzando nella cache o cercando nell'intero cluster di cache. Quindi, il motivo numero due è che puoi cercare nella cache, puoi raggruppare i dati attraverso gruppi e sottogruppi, tag e tag denominati e rende possibile trovare i dati in modo amichevole, cosa in cui nessuna di queste funzionalità esiste Redis.
Indicizzazione dei dati è un altro aspetto di questo, che quando si cerca in base a questi attributi, allora è imperativo, è davvero importante che gli indici della cache, creino indici su quegli attributi. Altrimenti, è un processo estremamente lento per trovare quelle cose. Così, NCache consente di creare indicizzazione dei dati. Ad esempio, ogni gruppo e sottogruppo, tag, targhette nome vengono automaticamente indicizzati ma puoi anche creare indici sui tuoi oggetti. Quindi, potresti, ad esempio, creare un indice sul tuo oggetto cliente sull'attributo città. Quindi, l'attributo della città perché sai che cercherai sull'attributo della città. Dici, voglio indicizzare quell'attributo e in quel modo NCache lo indicizzerà.
Motivo 3 – Codice lato server
Il motivo numero tre è che con NCache puoi effettivamente scrivere codice lato server. Quindi, qual è quel codice lato server e perché è così importante. Diamo un'occhiata a quello. È read-through, write-through, write-behind e caricatore di cache. Così, lettura è essenzialmente il tuo codice che implementi e viene eseguito sul server cache. Quindi, in realtà lascia che ti mostri com'è fatto un read-through. Quindi, ad esempio, se si implementa un IReadThruProvider interfaccia.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}Questa interfaccia ha tre metodi. C'è un metodo init che viene chiamato all'avvio della cache e il suo scopo è connettere il tuo gestore di lettura all'origine dati e c'è un metodo chiamato dispose che viene chiamato quando la cache viene interrotta e in questo modo puoi disconnetterti dalla tua origine dati e c'è un metodo di caricamento dal sorgente, che passa la chiave e si aspetta un output di un elemento della cache, un oggetto dell'elemento della cache del provider. Quindi, ora puoi usare la chiave per determinare quale oggetto devi recuperare dal tuo database. Quindi, la chiave come ho detto potrebbe essere cliente, ID cliente 1000. Quindi, ti dice che il tipo di oggetto è cliente, la chiave è ID cliente e il valore è 1000. Quindi, se usi formati del genere, puoi, in base a ciò puoi andare avanti e trovare il tuo codice di accesso ai dati.
Quindi, questo gestore di lettura viene effettivamente eseguito sui server di cache. Quindi, in realtà distribuisci questo codice su tutti i server cache. In caso di NCache è abbastanza senza soluzione di continuità. Puoi farlo attraverso un NCache strumento di gestione. Quindi, distribuisci quel gestore di read-through ai server della cache e quel gestore di read-through viene chiamato dalla cache. Diciamo che la tua applicazione fa il cache.Get e quell'elemento non è nella cache. NCache chiama il tuo gestore di lettura. Il tuo gestore di lettura va al tuo database, recupera quell'elemento, lo restituisce NCache. NCache lo mette nella cache e poi lo restituisce all'applicazione. Quindi, l'applicazione sembra che i dati siano sempre nella cache. Quindi, anche se non è nella cache, la cache ora ha la capacità di andare a recuperare i dati dal tuo database. Questo è il primo vantaggio della lettura continua.
Il secondo vantaggio del read-through è che quando si verificano le scadenze. Diciamo che hai avuto una scadenza assoluta. Hai detto di far scadere questo articolo tra 5 minuti o tra 2 ore, in quel momento invece di rimuovere quell'elemento dalla cache, puoi dirlo NCache per ricaricare quell'elemento automaticamente chiamando il gestore read-through. E ricaricare significa che l'elemento non viene mai rimosso dalla cache. È solo aggiornato e questo è davvero importante perché molte delle tabelle di ricerca di riferimento, hai molte transazioni solo leggendo quei dati e se quei dati vengono rimossi anche per un breve periodo di tempo, molte transazioni sul database verrà creato per recuperare quei dati, contemporaneamente. Quindi, se potessi semplicemente aggiornarlo nella cache, è molto meglio. Quindi, questo è un caso d'uso.
Il secondo caso d'uso riguarda la sincronizzazione del database. Quindi, quando si verifica la sincronizzazione del database e l'elemento viene rimosso, invece di rimuoverlo, perché non ricaricarlo dal database e questo è ciò che è NCache volere. Puoi configurare NCache, in modo che quando si avvia la sincronizzazione del database, il file NCache invece di rimuovere quell'elemento dalla cache, chiamerà il tuo gestore di lettura per ricaricarne una nuova copia. Ancora una volta, allo stesso modo della scadenza, quell'elemento non viene mai rimosso. Non viene mai rimosso dalla cache. Quindi, il read-through è una funzionalità davvero potente.
Un altro vantaggio del read-through è che semplifica le tue applicazioni, perché ti muovi sempre di più se hai codice di persistenza nel livello di memorizzazione nella cache e se hai più applicazioni che accedono agli stessi dati, tutto ciò che devono fare è fare un cache.Get. UN cache.Get è una chiamata molto semplice che esegue quindi un corretto tipo di codifica ADO.NET.
Quindi, la lettura semplifica il codice dell'applicazione. Si assicura inoltre che la cache contenga sempre i dati. Si ricarica automaticamente alle scadenze e alle sincronizzazioni del database.
La funzionalità successiva è la scrittura. Il write-through funziona proprio come il read-through, tranne che per l'aggiornamento. Lascia che ti mostri come appare la scrittura. Quindi, questo è stato letto. Lasciami solo andare a scrivere. Quindi, implementi un gestore write-through. Ancora una volta, hai un metodo init. Hai un metodo dispose, proprio come il read-through, ma ora hai un metodo di scrittura nell'origine dati e hai un metodo di scrittura in blocco nell'origine dati. Quindi, questo è qualcosa che è diverso dalla lettura.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Quindi, in caso di write-through, sai, ottieni anche l'oggetto e l'operazione e questa operazione potrebbe essere un'aggiunta, potrebbe essere un aggiornamento o potrebbe essere un'eliminazione, giusto. Perché potresti fare un cache.Aggiungi, cache.Inserisci, cache.Eliminae tutto ciò comporterà l'esecuzione di una chiamata write-through. Questo ora può andare e aggiornare i dati nel database.
Allo stesso modo, se si esegue un'operazione in blocco, un aggiornamento in blocco, è possibile eseguire anche un aggiornamento in blocco al database. Quindi, il write-through ha anche gli stessi vantaggi del read-through che può semplificare l'applicazione perché sposta sempre più codice di persistenza nel livello di memorizzazione nella cache.
Ma c'è anche la funzione write-behind che è una variazione del write-through. Con il write-behind è fondamentalmente, aggiorni la cache e la cache quindi aggiorna l'origine dati in modo asincrono. Fondamentalmente, lo aggiorna in seguito. Quindi, la tua applicazione non deve aspettare.
Il write-behind velocizza davvero la tua applicazione. Perché, sai, gli aggiornamenti del database non sono veloci come gli aggiornamenti della cache. Quindi, sai, puoi utilizzare un write-through con una funzione di write-behind e la cache viene aggiornata immediatamente. La tua applicazione torna indietro e fa il suo dovere, quindi il write-through viene chiamato in modalità write-behind e va ad aggiornare il database e, naturalmente, se l'aggiornamento del database non riesce, l'applicazione viene notificata.
Quindi, ogni volta che viene creata una coda, c'è il rischio che se quel server va giù quella coda andrà persa. Bene, in caso di NCache la coda write-behind viene replicata anche su più di un server e in questo modo, se un server cache si interrompe, la coda write-behind non va persa. Quindi, ecco come NCache garantisce un'elevata disponibilità. Quindi, write-through e write-behind sono funzionalità molto potenti. Semplificano il codice dell'applicazione e anche in caso di write-behind velocizzano l'applicazione perché non è necessario attendere l'aggiornamento del database.
La terza caratteristica è il caricatore di cache. Ci sono molti dati che preferiresti precaricare nella cache, in modo che le tue applicazioni non debbano andare al database. Se non hai una funzione di caricamento della cache, ora devi scrivere quel codice. Bene, non solo devi scrivere quel codice, devi anche eseguirlo da qualche parte come processo. È l'esecuzione come processo che diventa davvero più complicato. Quindi, nel caso di un caricatore di cache, devi semplicemente registrare la tua cache. Implementi un'interfaccia di caricamento della cache, con cui registri il tuo codice NCache, NCache chiama il tuo codice ogni volta che viene avviata la cache e in questo modo puoi assicurarti che la cache sia sempre precaricata con così tanti dati.
Quindi, queste tre funzionalità read-through, write-through, write-behind e caricatore memorizzato nella cache, sono funzionalità molto potenti che solo NCache ha. Redis non ha tali caratteristiche. Quindi, in caso di Redis perdi tutta questa capacità che NCache prevede diversamente.
Motivo 4: cache client (vicino alla cache)
Il motivo numero quattro lo è Cache cliente. La cache del client è una funzionalità molto potente. È davvero una cache locale che si trova nella casella del server delle applicazioni, ma non è una cache isolata. È locale per la tua applicazione. Può essere in corso. Quindi, questa cache del client potrebbe essere oggetti mantenuti come nel tuo heap e in caso di NCache se scegli l'opzione In-Proc che NCache mantiene la forma dei dati e dell'oggetto. Non in forma serializzata, nella cache del client. Nella cache cluster lo mantiene in una forma serializzata. Ma nella cache del client lo mantiene sotto forma di oggetto. Come mai? Quindi, ogni volta che lo prendi, non devi deserializzarlo in un oggetto. Quindi, accelera i prelievi o ottiene molto di più.
Una cache client è una funzionalità molto potente. È una cache sopra una cache. Quindi, una delle cose che perdi quando passi da una cache In-Proc standalone a una cache distribuita è che in una cache distribuita la cache conserva i dati in un processo separato, anche su un server separato e c'è un processo interprocesso comunicazione in corso, è in corso una serializzazione e deserializzazione e questo rallenta le prestazioni. Quindi, rispetto a un In-Proc, una cache a forma di oggetto, una cache distribuita è almeno dieci volte più lenta. Quindi, con una cache client ottieni il meglio di entrambi i mondi. Perché, se non si dispone della cache del client, se si dispone solo di una cache isolata autonoma, ci sono molti altri problemi relativi alle dimensioni della cache, e se il processo si interrompe? Quindi perdi la cache e come mantieni la cache sincronizzata con le modifiche su più server. Tutti questi problemi vengono affrontati da NCache nella sua cache client.
Quindi, ottieni il vantaggio di quella cache In-Proc autonoma ma sei connesso al cluster di memorizzazione nella cache. Quindi, tutto ciò che è conservato in questa cache del client, è anche nella cache del cluster e se uno qualsiasi dei client lo aggiorna qui, il livello di memorizzazione nella cache notifica la cache del client. In modo che possa andare ad aggiornarsi, immediatamente. Quindi, è così che ti assicuri o ti assicuri che la cache del tuo client sarà sempre sincronizzata con il livello di memorizzazione nella cache che viene quindi sincronizzato con il database.
Quindi, in caso di NCache una cache client è qualcosa che si collega semplicemente senza alcuna programmazione aggiuntiva. Esegui le chiamate API come se stessi parlando con il livello di memorizzazione nella cache e la cache del client si collega semplicemente a una modifica della configurazione e una cache del client ti offre prestazioni 10 volte più veloci. Questa è una caratteristica che Redis non ha. Quindi, nonostante tutte le prestazioni affermano che Redis ha, sai, sono un prodotto veloce, ma lo è anche NCache. Così, NCache è testa a testa in performance con Redis senza la cache del client. Ma quando accendi la cache del client, NCache è 10 volte più veloce. Quindi, questo è il vero vantaggio dell'utilizzo di una cache client. Quindi, questo è il motivo numero quattro per l'utilizzo NCache ancora Redis.
Motivo 5: supporto multi-datacenter
Il motivo numero cinque è quello NCache fornisce un supporto multi-datacenter. Sai, al giorno d'oggi se hai un'applicazione ad alto traffico, è molto probabile che tu la stia già eseguendo in più data center per il ripristino di emergenza DR o per due data center attivo-attivo per il bilanciamento del carico o una combinazione di DR e bilanciamento del carico , sai, o forse il suo bilanciamento del carico geografico. Quindi, sai, potresti avere un data center a Londra e New York o conosci Tokyo o qualcosa del genere per soddisfare il traffico regionale. Ogni volta che hai più data center, i database forniscono la replica perché senza di essa non saresti in grado di avere più data center. Perché i tuoi dati sono gli stessi su più data center. Se i dati non erano gli stessi allora, sai, è un separato, non c'è problema ma in molti casi i dati sono gli stessi e quindi non solo, ma vuoi essere in grado di scaricare parte del traffico da uno datacenter all'altro senza soluzione di continuità. Quindi, se il database si replica tra i data center, perché non la cache? Redis non fornisce tali funzionalità, NCache fornisce funzionalità molto potenti.
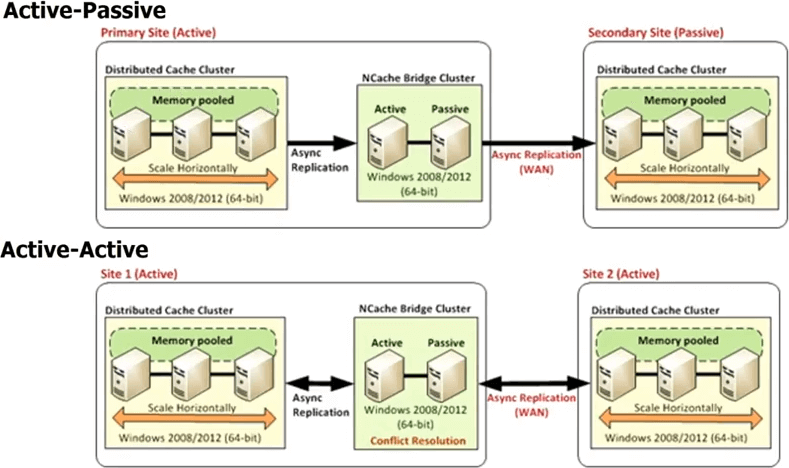
Quindi, in caso di NCache hai tutti i data center che avranno il proprio cluster di cache ma c'è un topologia del ponte nel mezzo. Quel bridge essenzialmente connette i cluster di cache in ogni data center, in modo che tu possa replicare in modo asincrono. Quindi, puoi avere un bridge attivo-passivo, dove questo è un data center attivo, questo è passivo. Puoi anche avere un bridge attivo-attivo e stiamo anche rilasciando più di due configurazioni di datacenter attivo-attivo o attivo-passivo, in cui puoi avere, diciamo, tre o quattro datacenter e la cache verrà replicata su tutti loro in modo attivo-attivo o attivo-passivo. In un active-active, poiché gli aggiornamenti vengono eseguiti in modo asincrono o la replica è stata eseguita in modo asincrono, è possibile che lo stesso elemento sia stato aggiornato in entrambi i data center.
Così, NCache fornisce due diversi meccanismi per gestire la risoluzione dei conflitti. Uno è chiamato l'ultimo aggiornamento vince. Laddove l'ultimo elemento aggiornato, viene applicato a entrambe le posizioni. Quindi, supponiamo che tu aggiorni un elemento qui, un altro utente aggiorni l'elemento qui. Entrambi ora iniziano a propagarsi nell'altra cache. Quindi, quando arrivano al ponte, il ponte si rende conto che sono stati aggiornati in entrambi i posti. Quindi, quindi controlla il timestamp e qualsiasi timestamp sia stato l'ultimo, applica quell'aggiornamento all'altra posizione e scarta l'aggiornamento che è stato effettuato dall'altra posizione. Quindi, è così che l'ultimo aggiornamento attivo-attivo vince la risoluzione dei conflitti. Se ciò non è sufficiente per te, puoi implementare un gestore di risoluzione dei conflitti. Questo è il tuo codice. Quindi, in caso di conflitto, il bridge chiamerà il tuo codice, passerà entrambe le copie degli oggetti, in modo da poter eseguire analisi basate sul contenuto e quindi in base a tale analisi potrai quindi determinare quale oggetto è più appropriato da aggiornare, per essere applicato a entrambi i datacenter. La stessa regola si applica se hai anche più di due datacenter.
Quindi, un supporto multi-datacenter è una caratteristica molto potente NCache ti dà fuori dagli schemi. Una volta che compri NCache, è tutto lì, Redis non lo fa e se prevedi di avere più datacenter o anche se vuoi semplicemente avere la flessibilità, anche se oggi non hai più datacenter ma vuoi avere la flessibilità di poter andare a più datacenter, lo faresti acquistare oggi un database che non supporta la replica? Probabilmente non lo faresti, anche se hai un solo datacenter. Quindi, perché scegliere la cache che non supporta la replica WAN. Quindi, questa è una caratteristica molto potente di NCache.
Quindi, fino ad ora abbiamo parlato principalmente delle caratteristiche che deve avere una buona cache distribuita. NCache, sai, brilla. Vince a mani basse Redis. Redis è una cache semplice molto semplice.
Motivo 6: piattaforma e tecnologia (per app .NET)
.NET e Windows vs Linux
Il motivo numero sei è probabilmente uno dei motivi più importanti per te, ovvero piattaforma e tecnologia. Se si dispone di un'applicazione .NET, si preferisce avere lo stack .NET completo. Sono sicuro che vorresti, non vorresti mescolare .NET con Java o Windows con Linux, nella maggior parte dei casi. In alcuni casi, sai, potresti, ma nella maggior parte dei casi le persone che stanno sviluppando applicazioni .NET preferiscono utilizzare la piattaforma Windows e preferiscono che tutto il loro intero stack sia .NET, se possibile. Bene, Redis non è un prodotto .NET. È un prodotto basato su Linux che è stato sviluppato in C/C++.

Lascia che ti mostri un po'. Ecco il Redis sito web di laboratori che è l'azienda che produce Redis. Se vai alla pagina di download vedrai che non ti danno nemmeno un'opzione di Windows. Quindi, nonostante Microsoft li abbia scelti per Azure, non hanno assolutamente alcuna intenzione di supportare Windows. Quindi, per quanto Redis Labs è preoccupato, Redis è solo per Linux. Il porting di Microsoft Open Technology Group Redis su Windows. Quindi, esiste una versione per Windows di Redis a disposizione. È open source e non è supportato ma, sai, è buggato e instabile e la prova è nel pudding ma che Microsoft stessa non lo usa in Azure. Così la Redis che usi in Azure è in realtà basato su Linux Redis e non la base di Windows. Quindi, se vuoi incorporare Redis nel tuo stack di applicazioni, mescolerai olio con acqua, lo sai. Considerando che, in caso di NCache tutto è .NET nativo. Hai Windows. Hai il 100% di .NET. NCache è stato sviluppato in C Sharp (C#). È certificato per Windows Server 2012 R2 e ogni volta che arriva una nuova versione del sistema operativo viene certificato per questo. Sai, lanceremo molto presto l'ASP.NET Core sostegno. Quindi, abbiamo ufficialmente un client .NET. Abbiamo anche un client Java ufficialmente. Quindi, penso, se usi NCache e di nuovo NCache è anche open source. Quindi, se non hai i soldi, vai con la versione open source di NCache. Ma, se il tuo progetto è importante, scegli la versione Enterprise che ti offre più funzionalità e supporta entrambi. Ma ti consiglio vivamente di utilizzare NCache se si dispone di un'applicazione .NET sia per la combinazione .NET che per Windows.
Supporto in sede
Il secondo vantaggio che NCache ti dà è, se non sei nel cloud, diciamo, non hai deciso di passare al cloud, stai ospitando la tua applicazione, quindi è essenzialmente in locale. Quindi, è bene nel tuo datacenter Redis disponibile da Microsoft è solo in Azure. Quindi, tutto ciò che è in locale, quindi c'è un Redis disponibile in locale da Redis Labs ma è solo Linux e l'unico locale su Windows è l'open source, quello che viene fornito senza supporto e quello che è buggato e instabile e quello che è così buggato che Microsoft stessa non lo usa in Azure.

Considerando che, in caso di NCache puoi continuare a utilizzare l'open source che è gratuito, che ovviamente non è supportato, se non hai i soldi. Ma è tutto .NET nativo o se hai un progetto importante per la tua azienda, allora dal Edizione Enterprise che ha più funzionalità e viene fornito con supporto ed è una licenza perpetua. È abbastanza conveniente, sai, possederlo e ti offriamo anche supporto 24 ore su 7, XNUMX giorni su XNUMX nel caso sia importante per te.
Quindi, è completamente supportato in locale. La maggior parte dei nostri clienti che sono clienti di fascia alta stanno ancora utilizzando NCache in una situazione in sede. NCache è sul mercato da più di 10 anni. Quindi, è davvero un prodotto stabile.
Supporto cloud
Per quanto riguarda il supporto cloud, Redis ti offre un modello di servizio nel cloud, che Microsoft ha implementato a Redis servizio. Bene, Redis servizio significa che non hai accesso ai server di cache. Sai, per te è una scatola nera. Non c'è codice lato server. Quindi, tutto il read-through, write-through, write-behind, il caricatore della cache, la dipendenza personalizzata e un sacco di altre cose, non puoi fare con Redis. Sai, hai solo l'API client di base e come ho detto, sai, su Azure, Microsoft ti dà il Redis come servizio.
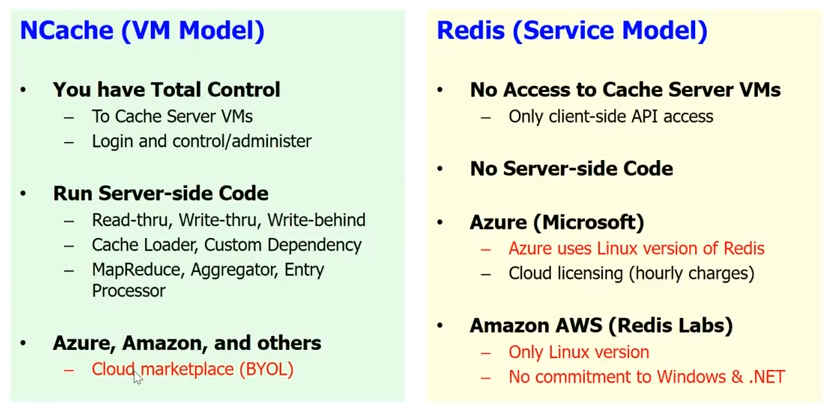
NCache, abbiamo scelto intenzionalmente un modello VM. Perché vogliamo che la cache sia vicina alla tua applicazione e vogliamo che tu abbia un controllo totale sulla cache. Questo è qualcosa di molto importante perché abbiamo molti anni di esperienza e sappiamo che i nostri clienti sono molto sensibili. Anche un piccolo, diciamo, se usi il Redis come servizio e devi fare un salto in più per raggiungere la cache ogni volta, il che uccide solo l'intero scopo di avere una cache. Considerando che, in caso di NCache puoi averlo come parte della VM. Puoi avere la cache del client. È davvero integrato nella distribuzione dell'applicazione. Quindi, puoi eseguire tutto il codice lato server.
NCache funziona anche azzurro. Funziona Amazon AWS e anche altri leader piattaforme cloud nel modello BYOL. Quindi, in pratica ottieni la tua VM. In realtà, hai il NCache nel mercato. Ottieni un NCache VM e tu acquisti la licenza da noi e inizi a usarla NCache.
Quindi, approcci molto diversi. Ma questo è l'approccio previsto se la tua applicazione è davvero importante e vuoi controllare l'applicazione, ogni suo aspetto e non dover fare affidamento su qualcun altro che gestisce una parte della tua infrastruttura a livello di applicazione. Una cosa è gestire le VM e l'hardware sottostante, ma man mano che inizi a salire sempre più in alto, perdi quel controllo e, naturalmente, in caso di memorizzazione nella cache, in caso di NCache, non è solo quel controllo, ma anche molte funzionalità che perderesti, se andassi con il modello di servizio.
Quindi, il motivo numero 6 è la tecnologia della piattaforma. Per l'applicazione .NET, NCache è un'opzione molto più adatta di Redis. non sto dicendo Redis è una cattiva opzione ma penso per le applicazioni .NET NCache è un'opzione molto più superiore di Redis.
NCache Storia
Lascia che ti dia solo una breve storia di NCache. NCache esiste dalla metà del 2005. Quindi, sono gli 11 anni, sai, NCache è stato nel mercato. È la più antica cache .NET sul mercato. 2015 gennaio, siamo diventati open source. Quindi, ora siamo la licenza Apache 2.0. Nostro Edizione Enterprise è costruito sulla base del nostro open source. Quindi, l'open source è una versione stabile e affidabile. Ha molte caratteristiche. Naturalmente, Enterprise ha più funzionalità ma l'open source è un prodotto molto utilizzabile. La cosa fondamentale è che se non hai i soldi vai con l'open source. Se la tua applicazione aziendale è importante e hai il budget, scegli la Enterprise Edition. Viene fornito con il supporto e ti offre anche più funzionalità.
Abbiamo centinaia di clienti, praticamente in ogni settore possibile che necessita di memorizzazione nella cache. Quindi, abbiamo clienti del settore finanziario, abbiamo Walmart, altri settori della vendita al dettaglio. Abbiamo le compagnie aeree, abbiamo il settore assicurativo, auto/automobile, proprio in tutti i settori.
Quindi, questa è la fine del mio discorso. Per favore, vai avanti e scarica l'Enterprise Edition di NCache. Lascia che ti porti davvero al nostro sito web. Quindi, in sostanza, vai al pagina di download e ti consiglio vivamente di scaricare l'edizione Enterprise. Anche se finirai per utilizzare l'edizione open source, scarica l'edizione Enterprise. È una prova di 30 giorni completamente funzionante, che possiamo facilmente estendere e giocare.
Se vuoi andare avanti e scaricare l'open source, vai avanti e scarica l'open source. Puoi anche andare su GitHub e puoi vedere NCache su GitHub. Per favore contattaci se vuoi che facciamo come a demo personalizzata. Magari parla dell'architettura della tua applicazione, rispondi alle tue domande. Grazie mille per aver guardato questo discorso.