NCache Benchmark delle prestazioni
2 milioni di operazioni/sec
(cluster a 5 nodi)
Sintesi
NCache può aiutarti a scalare linearmente e migliorare le prestazioni in modo semplice ed economico. Le aziende Fortune 500 in tutto il mondo si sono fidate NCache per oltre 13 anni per rimuovere i colli di bottiglia delle prestazioni relativi all'archiviazione dei dati e ai database e per ridimensionare le applicazioni .NET all'elaborazione estrema delle transazioni (XTP).
Questo documento utilizzerà NCache 5.0 con API moderne e alcune nuove funzionalità per dimostrare la scalabilità lineare e le prestazioni estreme che puoi ottenere per le tue applicazioni .NET. In questo esperimento, abbiamo raggruppato un modem NCache API con una topologia di cache partizionata con pipeline abilitata. I dati sono completamente distribuiti su tutti i server di memorizzazione nella cache e i client si connettono a tutti i server per le richieste di lettura e scrittura.
In questo benchmark, dimostriamo che il NCache cluster può scalare linearmente e che abbiamo raggiunto 2 milioni di transazioni al secondo utilizzando solo 5 nodi del server cache. Lo dimostreremo anche noi NCache può fornire una latenza inferiore al microsecondo anche in un cluster di grandi dimensioni. In questo whitepaper tratteremo le impostazioni dei benchmark, i passaggi per l'esecuzione dei benchmark, le configurazioni di test, le configurazioni di carico e i risultati. Puoi vedere l'esperimento di benchmark in azione in questo video.
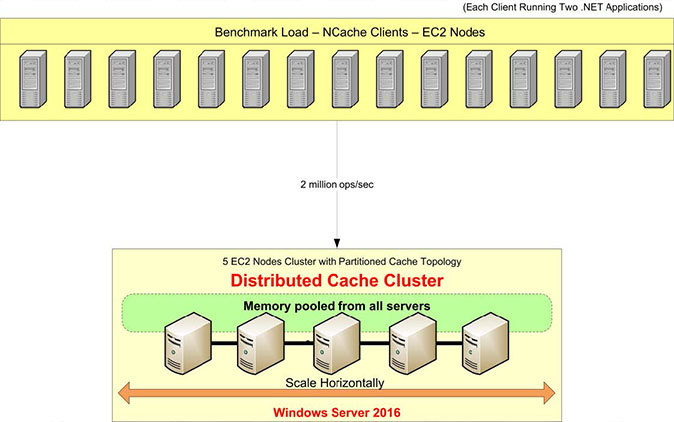
Panoramica della configurazione del benchmark
Esaminiamo la nostra configurazione del benchmark. Utilizzeremo i server AWS m4.10xlarge per questo test. Ne abbiamo cinque NCache server su cui configureremo il nostro cluster di cache. Avremo 15 server client, da cui eseguiremo le applicazioni per la connessione a questo cluster di cache.
Utilizzeremo Windows Server 2016 come sistema operativo: Data Center Edition, 64 bit. Il NCache la versione in uso è 5.0 Enterprise. In questa configurazione di benchmark, utilizzeremo a Topologia della cache partizionata. In una topologia di cache partizionata, tutti i dati verranno completamente distribuiti in partizioni su tutti i server di memorizzazione nella cache. E tutti i client saranno connessi a tutti i server per le richieste di lettura e scrittura per utilizzare tutti i server contemporaneamente. Non abbiamo la replica attivata per questa topologia, ma esistono altre topologie come la Topologia della replica partizionata che è dotato di supporto per la replica.
Avremo pipelining abilitato che è una nuova funzionalità in NCache 5.0. Funziona in modo tale che sul lato client accumuli tutte le richieste che si verificano in fase di esecuzione e le applichi immediatamente sul lato server. L'accumulo avviene in micro-secondi, quindi è molto ottimizzato ed è la configurazione consigliata quando si hanno requisiti di carico transazionale elevati.
Ecco una rapida panoramica della nostra configurazione di benchmark, inclusi hardware, software e configurazioni di carico.
Configurazione hardware:
| Dettagli client e server (Macchina virtuale) |
AWS m4.10xlarge: 40 core, 160 GB di memoria, rete - Ethernet 10 Gbps |
| N. di nodi server | 5 |
| N. di nodi client | 15 |
Configurazione software:
| Sistema operativo | Di Windows Server 2016 Edizione Data Center – x64 |
| NCache Versione | 5.0 |
| Topologia a grappolo | Configurazione della cache partizionata |
Carica configurazione:
| Dimensione della cache | 4 GB |
| Dimensione dei dati | Matrice di byte di dimensione 100 |
| Articoli totali | 1,000,000 |
| pipelining | abilitato |
| Ottieni/Aggiorna rapporto | 80:20 |
| Discussioni | 1280 |
| Applicazioni Istanze | 2 istanze per macchina client, totale 30 istanze |
Popolazione di dati
Dopo la configurazione dell'ambiente di benchmark, inizieremo con una popolazione di dati di 1 milione di elementi nel cluster di cache. Eseguiremo l'applicazione client (Cache Item Loader) che si collegherà e aggiungerà 1 milione di elementi nella cache. Un client si collegherà a tutti i server di memorizzazione nella cache e aggiungerà 1 milione di elementi nel cluster di cache, dopodiché potremo iniziare con le richieste di lettura e scrittura.
È possibile utilizzare questa Pacchetto Nuget – NCache SDK per installare l'SDK sul computer client e configurare il pipelining tra il client-server e distribuire l'applicazione di generazione del carico (GitHub) per popolare 1 milione di elementi della cache nel cluster di cache.
Costruisci il carico di transazione
Ora eseguiremo l'applicazione per creare un carico transazionale su questo cluster di cache con l'80% di operazioni di lettura e il 20% di operazioni di scrittura. Puoi monitorare tutte le attività utilizzando i contatori Perfmon. Inizialmente, collegheremo 10 istanze client a ciascuna NCache server con attività sui recuperi e sugli aggiornamenti al secondo.
Stage 1 1 milione di operazioni al secondo carico di transazione
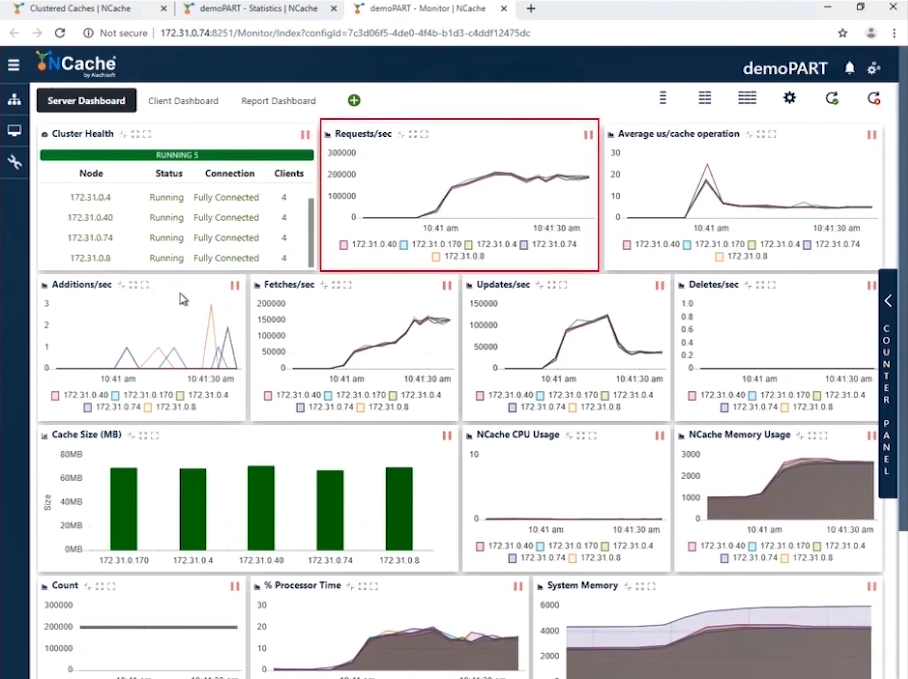
Nello screenshot puoi vedere che con 10 istanze client che si connettono a un cluster a 5 nodi abbiamo richieste al secondo che vanno da 180,000 a 190,000. E poiché ne abbiamo 5 NCache server che lavorano in parallelo, l'accumulo di queste richieste ci porta a 1 milione di richieste al secondo da questo cluster di cache.
Abbiamo un utilizzo efficiente della memoria e della CPU e l'operazione media di microsecondi/cache è di poco inferiore a 10 microsecondi per operazione. La nostra prima fase è stata completata in cui abbiamo raggiunto 1 milione di operazioni al secondo dal nostro cluster di cache.
| Fase 1 – Scheda tecnica riepilogativa | |
| Server di cache totali nel cluster | 5 |
| Totale istanze client connesse | 10 |
| Richieste al secondo/nodo | 180,0000 ~ 190,000 |
| Richieste totali - Cluster di cache | 950,000 ~ 1,000,000 |
| % Tempo processore (massimo) | 20% |
| Memoria di sistema | 4.2 GB |
| Latenza (operazione di microsecondi/cache) | 10 microsecondi/operazione |
Stage 2 1.5 milione di operazioni al secondo carico di transazione
Ora che abbiamo raggiunto 1 milione di TPS, è tempo di aumentare il carico sotto forma di più istanze dell'applicazione per aumentare il carico transazionale. E non appena queste applicazioni vengono eseguite, vedresti un aumento delle richieste al secondo contatore. Aumenteremo il numero di client a 20. Con questa configurazione puoi vedere nello screenshot qui sotto che ora stiamo mostrando 300,000 richieste al secondo per istanza. Abbiamo raggiunto con successo 1.5 milioni di richieste al secondo da questo cluster di cache.
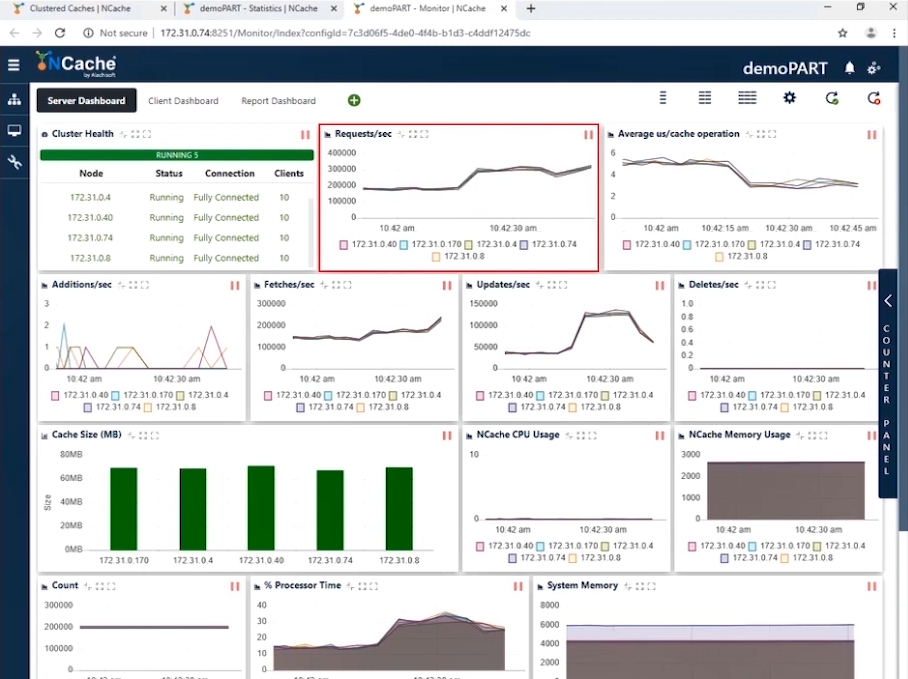
Puoi vedere che il conteggio delle richieste al secondo da parte di ciascun server è 300,000. I recuperi sono poco più di 200,000 al secondo e gli aggiornamenti sono compresi tra 50,000 e 100,000 e puoi vedere che il microsecondo medio per operazione di cache è inferiore a 4 microsecondi; è sorprendente perché abbiamo una latenza molto bassa insieme all'impatto del pipelining. Quando hai un carico transazionale elevato dal lato client, il pipelining aiuta davvero e riduce la latenza e aumenta il throughput. Questo è il motivo per cui consigliamo di attivarlo. Inoltre, ora abbiamo un microsecondo medio per operazione di cache intorno ai 3-4 microsecondi per operazione di cache.
| Fase 2 – Scheda tecnica riepilogativa | |
| Server di cache totali nel cluster | 5 |
| Totale istanze client connesse | 20 |
| media Richieste al secondo/nodo | 300,000 |
| Richieste totali - Cluster di cache | 1,500,000 |
| % Tempo processore (massimo) | 30% |
| Memoria di sistema | 6 GB |
| Latenza (operazione di microsecondi/cache) | 3 ~ 4 microsecondi/operazione |
Stage 3 2 milione di operazioni al secondo carico di transazione
Aumentiamo ulteriormente il carico eseguendo altre istanze dell'applicazione che mostreranno anche un ulteriore aumento delle richieste al secondo. Ora collegheremo tutte le istanze di 30 client NCache server.
Secondo lo screenshot qui sotto, ora puoi vedere che abbiamo toccato con successo 400,000 richieste al secondo che riceviamo da ciascuna NCache server; ne abbiamo 5 NCache server in modo che il numero raggiunga i due milioni di transazioni al secondo NCache cluster di cache. E abbiamo la media dei microsecondi per operazione di cache che è inferiore a 3 microsecondi. Abbiamo anche la memoria di sistema e il tempo del processore ben al di sotto dei limiti con un utilizzo del 40 - 50% su entrambi i fronti.
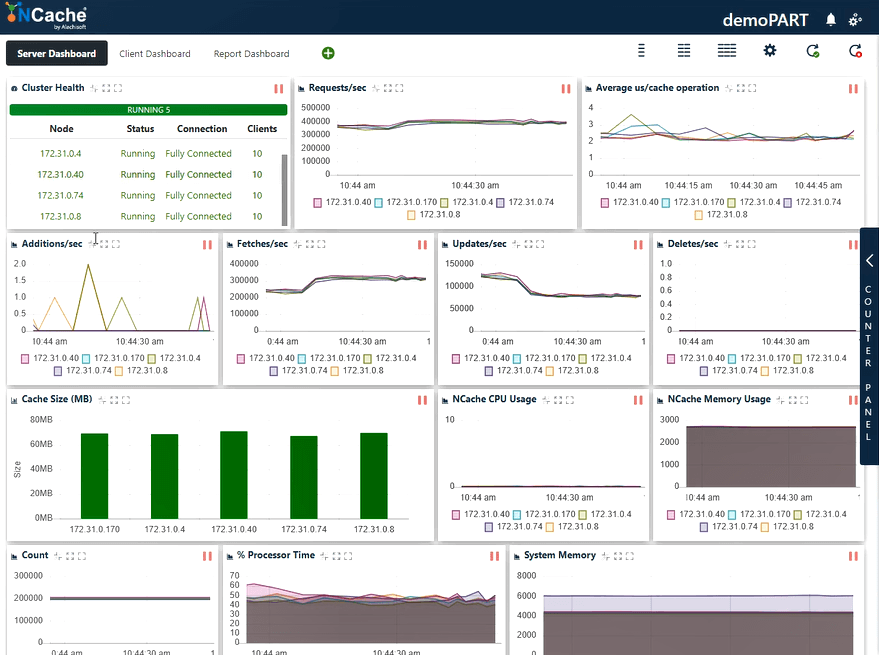
Ora abbiamo 2 ~ 3 us/latenza operativa, un miglioramento rispetto al risultato precedente. Puoi vedere ancora una volta un mix di recuperi, aggiornamenti e un utilizzo efficiente della CPU e delle risorse di memoria. Possiamo concludere qui che NCache è linearmente scalabile. Ora esaminiamo i nostri numeri di scalabilità.
| Fase 3 – Scheda tecnica riepilogativa | |
| Server di cache totali nel cluster | 5 |
| Totale istanze client connesse | 30 |
| media Richieste al secondo/nodo | 400,000 |
| Richieste totali - Cluster di cache | 2,000,000 |
| % Tempo processore (massimo) | 60% |
| Memoria di sistema | 6 GB |
| Latenza (operazione di microsecondi/cache) | 2 ~ 3 microsecondi/operazione |
Risultati del benchmark
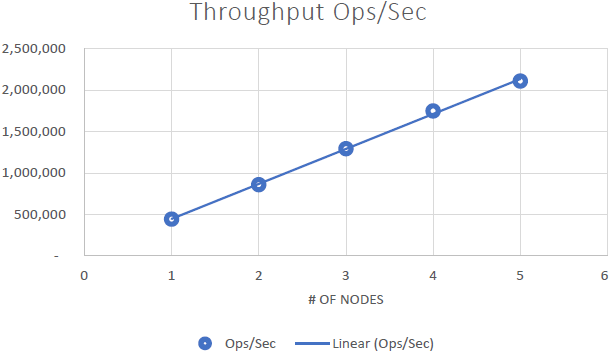
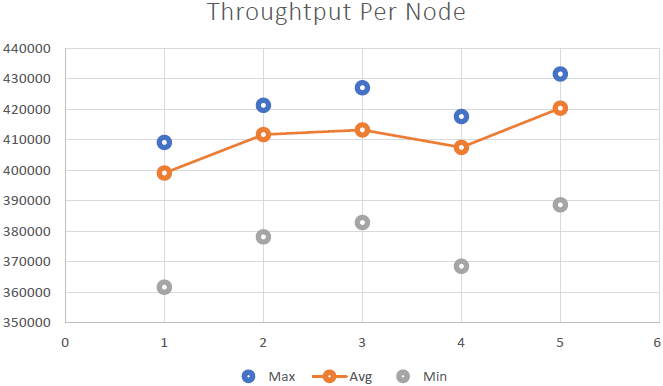
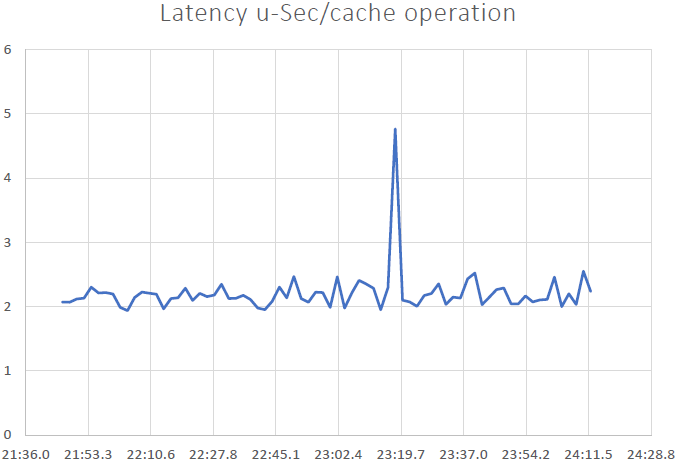
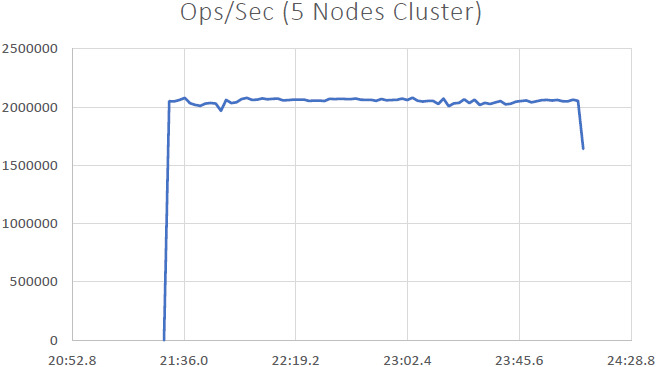
Siamo stati in grado di dimostrarlo NCache è linearmente scalabile e siamo stati in grado di ottenere i seguenti risultati dopo aver eseguito i benchmark:
Conclusioni
- Scalabilità lineare: Con 5 NCache server siamo stati in grado di raggiungere 2 milioni di richieste al secondo. L'aggiunta di sempre più server significa maggiori capacità di gestione delle richieste da NCache.
- Bassa latenza e alta produttività: NCache offre una latenza inferiore al microsecondo (2.5 ~ 3 microsecondi) anche con cluster di grandi dimensioni. NCache aiuta a soddisfare i requisiti di bassa latenza e di throughput elevato anche su larga scala. Abbiamo una latenza molto bassa, un impatto derivato dal pipelining. Quando si hanno carichi transazionali elevati dal lato client, il pipelining aiuta davvero, riduce la latenza e aumenta il throughput.