Aplicações modernas processam e geram grandes volumes de dados. A possibilidade de um único servidor web/fonte de dados falhar, resultando na perda de aplicativos e dados inestimáveis é um pesadelo comum entre os desenvolvedores de software. No entanto, você pode obter alta disponibilidade de dados se todos os nós do servidor tiverem uma cópia idêntica dos dados – isso significa que não haverá perda de dados se alguns nós falharem no cluster. Mas, o que acontece quando os dados começam a se expandir significativamente? Em casos como esses, você deve retornar a replicação e começar a particionar os dados.
NCache sendo uma solução de cache distribuída e na memória, oferece alta escalabilidade, desempenho e disponibilidade para aplicativos com uso intensivo de dados. Antecipa o POR (Réplica particionada) para dividir os dados em vários blocos (buckets) e colocá-los em diferentes partições. Para distribuir uniformemente as cargas de leitura e gravação, os dados são particionados em vários nós. Isso resolve o problema inicial de obter escalabilidade dividindo os dados, mas como exatamente os dados são particionados igualmente? Este blog tem como objetivo educá-lo sobre como o particionamento de dados ocorre em NCache.
Particionamento baseado em hash para distribuição igual de dados
Na maioria das vezes, vários aplicativos empregam a estratégia round-robin para atribuir dados a diferentes partições. Embora essa abordagem garanta uma distribuição uniforme, ela apresenta um desafio quando se trata de localizar itens de dados específicos. A pesquisa e a recuperação de dados podem se tornar demoradas e ineficazes, sem nenhuma maneira de rastrear os locais dos itens.
Para resolver esse problema, NCache incorpora Particionamento baseado em hash. Os dados são divididos em vários baldes que são posteriormente dispersos entre várias partições. O objetivo é distribuir os buckets uniformemente entre os nós do cluster para otimizar o desempenho e garantir alta disponibilidade. Para alcançar isto, NCache emprega uma técnica de hash que mapeia cada item de dados para um balde específico com base na chave do item. Agora, para descobrir o dono do balde, você precisa aplicar a função hash na chave do item e modificá-lo pelo número total de baldes – temos 1000 baldes no total.
O que é um Mapa de Distribuição?
O servidor coordenador é essencial em um cluster de cache distribuído porque ele supervisiona a distribuição do depósito e garante que cada item seja atribuído a um depósito específico com base em sua chave. Para conseguir isso, o servidor coordenador cria um mapa de distribuição incluindo a distribuição de bucket e a distribui para todas as outras partições no cluster, bem como para todos os clientes conectados.
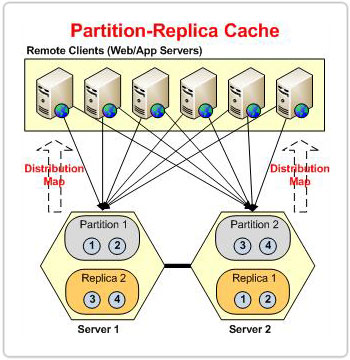
Figura 1: Partições com base no mapa de distribuição na topologia POR
Não importa quantos servidores estejam no cluster, NCache garante que cada item receba um endereço de bucket consistente por meio desse método. Isso ocorre porque o mapa de distribuição permanece constante, mesmo que o número de servidores no cluster mude. Como resultado, mesmo que um bucket se mova de uma partição para outra em qualquer estágio, o endereço do bucket de um item permanece o mesmo. Isso garante que os dados permaneçam intactos e nenhum dado seja perdido durante os movimentos da caçamba.
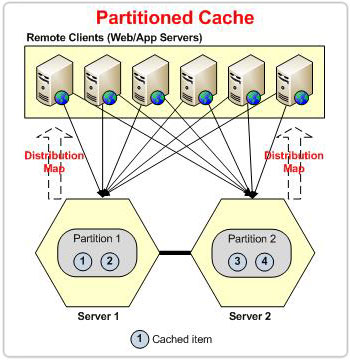
Figura 2: Partição com base no mapa de distribuição na topologia da partição
No caso de topologia particionada, sempre que um nó sai do cluster, o cluster sofre perda de dados. Os baldes pertencentes ao nó de saída serão todos perdidos. Porém, no caso de POR, a réplica está presente em outro nó que será redistributado com base no mapa de distribuição – evitando a perda de dados.
Distribuição de dados com base em um mapa de distribuição
Os dados são distribuídos igualmente entre todos os nós no cluster de cache, graças à estratégia de distribuição de balde dinâmica oferecida por NCache. Todos os 1000 depósitos são atribuídos ao nó quando você inicia um cluster de cache, o que resulta no armazenamento de todos os dados em uma única partição. Para fornecer o melhor desempenho e balanceamento de carga, os depósitos são divididos igualmente nas partições quando mais nós são adicionados ao cluster.
Os 1000 baldes, por exemplo, são divididos igualmente entre as duas partições quando um segundo nó é adicionado ao cluster, dando a cada divisão 500 baldes. Da mesma forma, quando um terceiro nó entra no cluster, os baldes são redistributado, dando a cada partição 333, 333 e 334 baldes, de acordo.
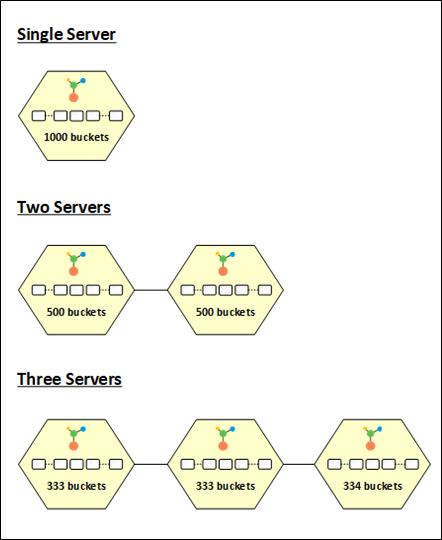
Figura 3: NCache Distribuição de Balde
A distribuição do bucket é modificada mais uma vez se uma partição sair do cluster. Para manter uma distribuição uniforme dos dados, por exemplo, quando uma partição sai de um cluster de três nós, os 333 ou 334 depósitos que pertencem a essa partição são dispersos pelos dois nós restantes. NCacheO mecanismo de transferência de estado do 's entra em ação para reequilibrar os dados entre os nós sempre que a distribuição do balde muda, garantindo que os dados sejam distribuídos de maneira ideal de acordo com a distribuição do balde. Da mesma forma, o cliente também recebe o mapa de distribuição que informa sobre os nós do servidor em execução e suas distribuições baseadas em hash.
Balanceamento de carga de dados
Enquanto redisdistribuição de baldes em torno dos nós do cluster de cache, NCache adota uma estratégia centrada em dados para garantir que a quantidade de dados que cada partição recebe seja equilibrada. Para isso, cada partição do cluster troca periodicamente as estatísticas dos buckets que possui com as outras partições do cluster. Isso permite a criação de um equilíbrio mapa de distribuição que responde pela quantidade de dados que cada partição possui. NCache equilibra automaticamente os dados para garantir que cada partição receba um compartilhamento igual de dados. Também permite balancear os dados manualmente. Você pode ler mais sobre isso SUA PARTICIPAÇÃO FAZ A DIFERENÇA.
Conclusão
Em conclusão, utilizando POR para dividir dados em NCache é uma técnica útil para aumentar a velocidade e a escalabilidade dos aplicativos. Você pode garantir que os dados estejam sempre disponíveis e diminuir a possibilidade de gargalos de desempenho dividindo os dados em partes menores e distribuindo-os por vários nós de cache.





