Topologias de partição-réplica e cache de partição
Em um cluster, se todos os nós do servidor tiverem a mesma cópia de dados, você terá uma alta disponibilidade desses dados. Isso significa que o cluster pode sobreviver a algumas falhas de nós sem sofrer perda de dados. No entanto, isso não oferece escalabilidade. Quando os dados começam a crescer enormemente, o design precisa reduzir a extensão da replicação e começar a particionar os dados.
Particionar significa que você precisa distribuir seus dados entre vários nós para que o carregamento de dados de leitura e gravação seja distribuído. À medida que seus dados aumentam, você pode adicionar mais nós de servidor ao cluster para armazenar mais dados. Cada nó de servidor em um cluster é chamado de partição.
Com o particionamento dos dados, você pode obter escalabilidade, mas agora a questão é como esses dados são particionados? Uma solução simples poderia ser atribuir dados a uma partição de forma round-robin, mas como encontraremos um determinado dado depois de adicionado ao armazenamento?
Através do round-robin, perderemos a capacidade de rastrear a localização dos dados. Precisamos de uma forma melhor de distribuir os dados, garantindo não só a distribuição equitativa dos dados, mas também a capacidade de os consultar rapidamente.
Note
A topologia particionada também é suportada em NCache Professional.
Note
A única diferença entre as topologias Partitioned e Partition-Replica é que a primeira não tem caches de réplica, o que a torna propensa à perda de dados.
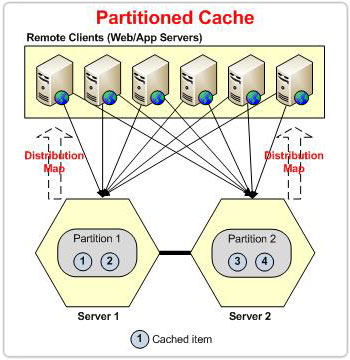
Particionamento de dados baseado em hash para caches de partição
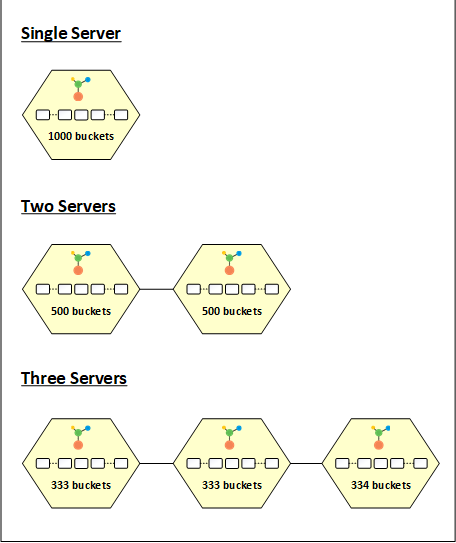
NCache divide os dados em vários pedaços e coloca esses pedaços em partições diferentes. Esses pedaços são chamados de baldes. Há um total de 1000 buckets divididos igualmente entre os nós do cluster. A ideia aqui é aplicar uma função hash na chave do item e modificá-la pelo número total de buckets (1000 neste caso) para obter um bucket proprietário para esses dados.
Mapa de Distribuição
O servidor coordenador no cluster tem a responsabilidade de gerar um mapa que contém a distribuição do bucket. Este mapa é chamado de mapa de distribuição. O servidor coordenador compartilha esse mapa de distribuição com o restante das partições do cluster e com os clientes conectados. Este método sempre fornece o mesmo endereço de bucket para um item, independentemente do número de servidores no cluster. Mesmo que o depósito possa ser movido de uma partição para outra em qualquer estágio, o depósito de um item nunca pode mudar. Isso significa que, quando um bucket se move, ele leva consigo todos os seus dados.
Distribuição de dados de acordo com o mapa de distribuição
Quando você inicia um cluster de cache com uma única partição, todos os 1000 buckets são atribuídos a esse nó. Isso significa que todos os dados vão para essa partição. Quando você inicia outro nó no cluster, os buckets são distribuídos igualmente entre as duas partições com 500 buckets cada. Da mesma forma, na adição de um terceiro nó ao cluster, os buckets são novamente redistributado. Nesse caso, os três nós terão 333, 333 e 334 buckets, respectivamente.
Da mesma forma, quando uma partição sai do cluster, a distribuição do bucket muda. Por exemplo, quando uma partição sai de um cluster de três nós, os 333 ou 334 buckets pertencentes a essa partição são redistributado entre os dois nós restantes. Sempre que há uma mudança na distribuição, ela aciona uma transferência de estado para reequilibrar os dados entre os nós, de acordo com a distribuição do bucket.
Distribuição aleatória de dados
Esse método de particionamento oferece uma quantidade razoável de aleatoriedade para garantir que os dados sejam particionados igualmente entre os buckets e as partições. Entretanto, com esse método de particionamento, você perde o controle sobre quais dados devem ser atribuídos a qual partição. Principalmente, você não se importaria com o destino de seus dados. Mas, em alguns casos, você pode querer que os dados relacionados sejam co-localizados. Para isso, você pode usar Location Affinity, onde uma função hash é aplicada em alguma parte da chave em vez de em toda a chave.
Distribuição equilibrada de dados
Sempre que os baldes redistributado entre os nós, NCache garante que os baldes redistributados de tal forma que o tamanho dos dados que cada partição recebe é quase o mesmo. Cada partição compartilha as estatísticas dos buckets que possui, em um intervalo configurável, com outras partições no cluster. Isto ajuda a gerar um mapa de distribuição equilibrado quando necessário, o que é justo em termos dos dados que cada partição obtém. O balanceamento é baseado no tamanho dos dados e não no número de itens. Esse balanceamento geralmente é garantido no momento do balde redisatribuição como resultado da saída ou adesão de um nó.
Balanceamento de carga de dados automático e manual
No entanto, há uma pequena chance de você observar que uma ou mais partições em um cluster estão distorcidas e estão recebendo mais carga do que o restante. Nesse caso, você tem a opção de balancear manualmente os dados de um nó específico, o que garante que os dados desse nó sejam iguais ao tamanho médio dos dados que cada partição recebe. Depois, há também um recurso chamado 'Balanceamento automático de carga de dados' que faz o trabalho automaticamente em segundo plano. Esse recurso está desabilitado por padrão porque, se usado sem cautela, pode causar redistribution e, portanto, transferências de estado indesejadas entre as partições.
Tamanho dos dados por partição
O tamanho dos dados que cada partição pode conter é igual ao tamanho do cache configurado. Por exemplo, se o tamanho do cache configurado for 2 GB e o tamanho do cluster for de três partições, o tamanho total do cache neste cluster será 6 GB.
Portanto, com essa topologia, você não apenas distribui a carga de leitura e gravação entre os servidores, mas também aumenta a capacidade a cada novo servidor adicionado ao cluster.
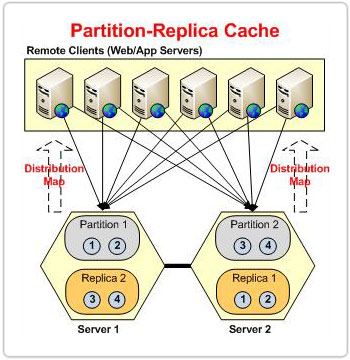
Réplica de partição
Agora que abordamos como a topologia Partition-Replica dimensiona a carga de transações e a capacidade de armazenamento. Vamos falar sobre como ele lida com alta disponibilidade. Cada nó no cluster tem um backup de outra partição que atua como uma partição passiva chamada de réplica. Em caso de falha de nó, o cluster de cache sabe que os dados pertencentes à partição perdida ainda estão disponíveis em sua réplica. Portanto, os aplicativos cliente continuam a funcionar sem problemas, pois os dados pertencentes à partição perdida ainda são atendidos pelo cluster por meio dessa réplica.
Os aplicativos cliente se comunicam diretamente apenas com as partições ativas. Cada partição é então responsável por replicar seus dados para sua respectiva réplica.
Mesmo que o grau de replicação nesta topologia não seja tanto quanto você tem na Topologia replicada, ter pelo menos um backup garante que, em caso de falha de um nó, seus dados ainda estarão seguros. Desde que não haja falhas simultâneas de nós, os dados nesta topologia estão seguros, o que cobre a maioria dos cenários.
Cada nó do cluster tem um ativo e uma réplica, e instâncias ativas e de réplica existem no mesmo processo de cache em cada nó do cluster.
Devido à existência da instância de réplica em cada nó de cache, ela requer o mesmo tamanho de memória que a instância de cache ativa. Isso significa que cada nó de cache de réplica de partição requer memória dupla em relação ao tamanho de cache configurado.
Todos os dados adicionados do cliente são armazenados no nó ativo, de onde são replicados para sua réplica dedicada, que está em algum outro nó do cluster. Esse arranjo de nós de réplica garante que os dados não sejam perdidos quando um nó ativo ficar inativo.
Estratégia de seleção de réplicas
NCache seleciona automaticamente o nó de réplica com base na ordem em que os nós estão ingressando no cluster de cache. A réplica do primeiro nó está presente no nó do servidor que ingressou no cluster após o primeiro nó e assim por diante. E a réplica do último nó é colocada no primeiro nó do servidor (servidor coordenador) do cluster de cache.
Todo esse processo de seleção de réplicas é automático. Sempre que um nó de servidor sai do cluster de cache ou um novo nó se junta ao cluster de cache, as réplicas também são reatribuídas de acordo com o mapa de associação atualizado.
Consumo de memória de nó único
Cada nó do servidor (ativo e réplica) mantém um registro do tamanho do cache configurado e garante que os dados armazenados nunca excedam o limite de memória especificado. Existem dois cenários especiais em que essa verificação de limite de memória funciona de maneira diferente. Eles são explicados abaixo:
- Apenas um nó está em estado de execução e dados estão sendo adicionados a ele. A instância de cache ativa pode usar o dobro do tamanho de cache especificado para armazenar os dados, pois sua réplica não tem utilidade.
- Em um cluster de vários nós, quando todos os outros nós saem do cluster e apenas um nó permanece ativo, os dados de sua instância de cache de réplica são transferidos para a instância de cache ativa. A memória livre da réplica é então consumida pelo cache ativo para acomodar os dados recebidos da réplica.
Estratégias de replicação
A topologia Partition-Replica tem duas estratégias de replicação para replicar os dados do nó do servidor ativo para o nó de réplica:
Replicação assíncrona: Neste modo, filas em segundo plano são usadas para replicar os dados sem bloquear as operações do cliente. Cada operação de gravação é enfileirada e threads de segundo plano dedicados selecionam os dados dessa fila em partes e os replicam para a instância de réplica. Essa estratégia de replicação é adequada para aplicativos que tendem a fazer gravações frequentes, mas não desejam esperar que as replicações sejam concluídas antes da próxima operação de cache. No entanto, existe uma chance de perda de dados se um nó sair abruptamente. Neste caso, as operações enfileiradas que não foram replicadas serão perdidas.
Replicação de sincronização: Com o modo de replicação síncrona, cada operação de gravação do cliente é replicada para a réplica antes de retornar o controle ao aplicativo cliente. Esse modo de replicação garante que as instâncias de cache ativa e de réplica tenham a mesma cópia dos dados do usuário. Se a replicação falhar na instância de réplica, esse item será removido das instâncias de cache ativas e de réplica.
Comportamento da Operação
Despejos, vencimentos, dependências, writeThru/writeBehind, etc são controlados pelo nó ativo. Sempre que um nó ativo remove um item dele com base em qualquer um dos recursos mencionados, ele o replica para sua réplica para remover os dados armazenados anteriormente. De forma similar, writeThru/writeBehind as operações são executadas apenas a partir do cache ativo.
Na topologia Partição-Réplica, os clientes estão conectados diretamente com cada nó do servidor, mas apenas com suas partições/instâncias ativas. Porém, existem algumas situações em que os clientes interagem temporariamente com as instâncias de réplica por meio de chamadas de cluster. Eles são explicados abaixo:
- Durante a transferência de estado, quando um nó sai do cluster, as operações do cliente destinadas ao nó que sai são atendidas a partir de sua réplica.
- Quando um cluster está em modo de manutenção, todas as operações destinadas ao nó em manutenção são atendidas a partir de sua réplica durante o período de manutenção.
Transferência de Estado
A transferência de estado é um processo para transferir/copiar automaticamente os dados entre os nós de cache. A transferência de estado é acionada quando um novo nó se junta ao cluster ou qualquer nó atual sai do cluster. A saída/junção do nó também causa alteração de associação no cluster.
Quando um nó recebe a atualização mapa de distribuição, ele verifica a existência dos buckets (que foram atribuídos a ele) em seu ambiente local. Os buckets atribuídos que não existem no ambiente local do nó são extraídos um por um de outros nós. Portanto, dependendo do número de nós de servidor no cluster de cache, vários buckets são transferidos durante a transferência de estado.
A transferência de estado é acionada nos três cenários principais a seguir:
Na junção do nó
Quando um novo nó se junta ao cluster de cache, o servidor coordenador gera um novo mapa de distribuição para distribuir os buckets dos nós atuais para o nó recém-ingressado. E, depois de receber o mapa de distribuição, o nó recém-ingressado extrai os buckets dos nós atuais. Durante essa transferência de estado, o nó recém-ingressado puxa um bucket por vez. Depois de receber um bucket, ele puxa o próximo bucket e assim por diante, até buscar todos os buckets atribuídos de outros nós, de acordo com seu mapa de distribuição.
Ao sair do nó
Da mesma forma, a transferência de estado é acionada quando um nó de cache sai do cluster de cache. O servidor coordenador redishomenageia seus buckets entre os nós ativos do cluster. Nesse caso, os nós ativos extraem os dados da réplica do nó de saída.
Note
Se mais de um nó sair do cluster ao mesmo tempo ou um após o outro enquanto já houver uma transferência de estado em andamento, isso poderá causar perda de dados
No balanceamento automático de carga de dados
A topologia Partition-Replica tem um recurso de Balanceamento automático de carga de dados no qual monitora continuamente a distribuição de dados entre os nós do cluster. E, se a distribuição dos dados não estiver dentro da faixa de distribuição esperada (60% a 40%), ele aciona automaticamente o balanceamento automático de carga de dados. Neste caso, o servidor coordenador regenera um novo mapa de distribuição e redishomenageia os buckets de forma que todos os nós do cluster tenham dados do mesmo tamanho.
Note
O balanceamento de carga de dados também pode ser realizado manualmente do NCache Centro de Gestão.
Seja qual for o motivo da transferência de estado, todo este processo é automático e contínuo. E, durante a transferência de estado, especialmente quando um nó de servidor sai do cluster de cache, todas as operações do cliente destinadas ao nó que sai são atendidas a partir de sua réplica por meio de operações de cluster.
As réplicas também realizam transferência de estado de seus nós ativos, assim como outros nós ativos. As réplicas extraem seus buckets atribuídos de seus nós ativos para buscar a cópia dos dados no momento da transferência de estado. No entanto, esta transferência de estado só ocorre na reatribuição do bucket. Caso contrário, os dados serão replicados nas réplicas por meio do mecanismo de replicação.
Diferentes maneiras de monitorar a transferência de estado
NCache fornece várias maneiras de monitorar a transferência de estado no cluster de cache. Eles são explicados abaixo:
- Logs de cache: sempre que a transferência de estado é acionada e interrompida, ela é registrada nos logs de cache do cluster. Os logs de cache existem sob o %NCHOME%/bin/log pasta.
- Contadores personalizados: NCache também publica contadores personalizados que podem ser visualizados no Windows e no Linux.
- Contadores baseados em Perfmon: No Windows, NCache também publica os contadores de transferência de estado por meio da ferramenta Windows Perfmon.
- Logs de eventos do Windows: Informações/eventos relacionados à transferência de estado também são publicados nos logs de eventos do Windows.
- Alertas de E-mail: Alertas de e-mail específicos de transferência de estado podem ser configurados em seu início e interrupção.
Conectividade do cliente
Conforme explicado no particionamento, os dados são distribuídos entre todos os servidores do cluster. Ao contrário de outras topologias, o cliente para topologias particionadas precisa se conectar a todas as partições, onde cada partição contém um subconjunto do total de dados.
O cliente recebe um mapa de distribuição na chamada de conexão, que instrui o cliente sobre os nós do servidor em execução e seus distribuições baseadas em hash. O cliente se conecta a todos os nós do servidor para obter dados completos do cache. O cliente recebe um mapa atualizado em cada alteração de associação de cluster para manter a conectividade. O cliente também recebe uma notificação sobre a saída/ingresso do membro e redefine a conectividade de acordo com o recebido mapa,.
O cliente realiza de forma inteligente as operações de leitura/gravação diretamente no nó do servidor que contém a chave de acordo com o mapa de distribuição baseado em hash ele recebe. Para todas as operações em que a chave não é conhecida, como Pesquisa SQL, GetByTags, etc, o cliente transmite a solicitação para todos os nós do servidor e combina suas respectivas respostas.
Se, em qualquer caso, o cliente não conseguir se conectar a qualquer nó de servidor do cluster, isso não significa que ele falha ao gravar e recuperar informações desse nó de servidor. Para isso, utiliza os outros nós do servidor aos quais está conectado, que em seu nome solicita ao nó do servidor inalcançável para realizar as operações. Por exemplo, se o cliente não conseguir se conectar com o node1 e quiser obter uma chave que resida no node1, ele enviará a solicitação para o node2, que redirecionará para o node1 e retornará a resposta.
Modo de Manutenção
Quando a correção ou atualização de hardware/software é necessária em um NCache servidor, você pode não encontrar tempo de inatividade do aplicativo. No entanto, parar um nó de cache aciona transferência de estado dentro de todo o cluster de cache, resultando em uso excessivo de recursos como rede, CPU e memória. Esse transferência de estado O processo pode ser caro dependendo do tamanho dos dados do cache e do cluster. Um fluxo de trabalho típico de atualização envolve reiniciar o nó de cache por vez, o que requer duas transferências de estado, uma na saída do nó e outra na entrada do nó.
O modo de manutenção é introduzido para evitar essas transferências de estado dispendiosas durante a manutenção em servidores de cache. Depois que um servidor de cache é interrompido para manutenção por um período especificado, a réplica do nó em manutenção torna-se ativa temporariamente e começa a receber solicitações do cliente. Quando o nó (que estava em manutenção) retorna após a conclusão de sua manutenção dentro do tempo especificado, o nó transferência de estado é iniciado para que este nó o sincronize com o cluster de cache.
O cluster sai do Modo de manutenção em três estados diferentes. Se o nó de manutenção ingressar no cluster de cache dentro do tempo especificado, transferência de estado é iniciado para sincronizar o estado do cluster e o cluster sai do Modo de manutenção. Se o nó de manutenção não conseguir ingressar novamente no cluster de cache dentro do tempo especificado, o cluster considerará o nó inativo e sairá do Modo de manutenção, gera um novo mapa,, e inicia o transferência de estado. Além do sucesso e do fracasso, há outra anomalia que sai do Modo de manutenção, ou seja, quando um nó sai. Se o cluster estiver no Modo de manutenção e qualquer nó que não seja o nó de manutenção sai, o cluster sai do Modo de manutenção, e isso pode levar à perda de dados.
Recuperação de cérebro dividido
O termo Cérebro dividido refere-se a um estado em que um cluster de cache se divide em vários subclusters. Os servidores de cache em um cluster se comunicam por meio de TCP. Portanto, qualquer falha ou problema de rede pode causar perda de comunicação entre os servidores presentes em um cluster. Se a perda de comunicação entre os servidores se estender além de um determinado tempo, o mapa de associação mudará de acordo com a conectividade entre os servidores. Isso resulta na formação de vários subgrupos. Esses subgrupos são chamados de divisões. Nós chamamos isso cérebro dividido como os subgrupos não podem se comunicar uns com os outros, semelhante a como as metades do cérebro não podem se comunicar umas com as outras na síndrome do cérebro dividido.
Todos os subclusters são íntegros e processam os dados que contêm. Além disso, os clientes podem se conectar a esses subclusters para outras operações de leitura/gravação. O cliente recebe um mapa de associação dos servidores de cluster para atualizar a conectividade. Aqui, o cliente pode se conectar a qualquer subcluster dependendo do primeiro mapa recebido.
Cérebro dividido é detectado apenas quando a comunicação entre os servidores é retomada e é descoberto que todos os servidores estão ativos e em execução, mas não fazem parte de um único cluster. Duas ou mais divisões são possíveis dependendo da perda de comunicação entre os servidores. Uma vez cérebro dividido for detectado, o processo de recuperação será iniciado. Todas as divisões são recuperadas uma a uma até que todos os subclusters sejam mesclados.
A cérebro dividido o processo de recuperação inicia logo após sua detecção. São necessárias duas divisões saudáveis, identifica seus servidores coordenadores, decide a divisão vencedora e perdedora com base no tamanho do cluster, adquire um bloqueio na divisão perdedora para restringir a atividade do cliente nesse cluster e altera a associação do cluster. Depois disso, todos os clientes são redirecionados para a divisão do cluster vencedor e todos os nós da divisão perdedora são reiniciados um por um para ingressar no cluster vencedor. Todas as divisões perdedoras se fundem com a divisão do cluster vencedor da mesma maneira e o cluster se torna íntegro novamente.
A perda de dados é esperada em cérebro dividido recuperação à medida que o cluster se divide em vários subclusters, a perda de dados ocorre porque vários nós em um cluster saem simultaneamente. Os subclusters podem atender solicitações de clientes em um estado de cérebro dividido, essas operações podem ser perdidas se a divisão à qual o cliente está conectado for uma divisão perdedora que é reiniciada para ingressar no cluster principal.
Veja também
Topologia replicada
Topologia espelhada
Cluster de cache
Cache Local