Todos nós nos deparamos com situações em que temos que esperar uma eternidade para obter uma resposta do banco de dados em troca das consultas geradas no servidor de aplicativos. Para aplicações críticas de negócios, a latência e o atraso na resposta são intoleráveis. É aqui que surge a necessidade de uma solução de cache otimizada.
Embora os caches sejam comumente associados a armazenamentos de valor-chave, NCache leva um passo adiante, permitindo que você consulte dados em atributos não-chave de seus objetos. Isso significa que você pode acessar dados com base em uma ampla variedade de propriedades além de apenas as chaves. Essa abordagem oferece maior flexibilidade e eficiência para recuperação de dados, facilitando a análise e o gerenciamento de seus dados.
Com o tempo, os dados no cache aumentam, então você precisa desses recursos em caches, onde você pode gerar consultas para um desempenho mais rápido de pesquisa e recuperação. NCache permite que você consulte seus dados de maneira eficiente quando estiver pesquisando.
Como funciona o dobrador de carta de canal NCache otimiza o desempenho de pesquisa e recuperação?
NCache otimiza seu desempenho de pesquisa e recuperação por meio de indexação, projeções, tamanho do bloco e cache do cliente. Ao armazenar em cache os resultados de consultas na capacidade de resposta de solicitação de memória é significativamente melhorada. Como muitas consultas são atendidas diretamente do cache, viagens adicionais ao banco de dados são salvas. NCache usa várias maneiras de aumentar o desempenho de pesquisa e recuperação, conforme discutido abaixo.
1. Crie índices estrategicamente
Para uma pesquisa de dados eficiente com base em consultas, NCache requer a criação de índices de busca. Ao contrário dos bancos de dados tradicionais, que podem ser lentos sem índices e realizar pesquisas completas na loja para encontrar dados, NCache prioriza o desempenho, tornando obrigatória a criação de índices. Ao criar índices, NCache pode determinar o tipo de dados e o formato de armazenamento que melhor atendem às suas necessidades de pesquisa, garantindo que as pesquisas sejam rápidas e eficientes
O Mercado Pago não havia executado campanhas de Performance anteriormente nessas plataformas. Alcançar uma campanha de sucesso exigiria NCache usos indexação uma vez que é uma abordagem orientada para o desempenho, mas a indexação dos atributos para uma pesquisa deve ser feita com muito cuidado, pois requer espaço para reter um índice, e a indexação de atributos desnecessários pode resultar em sobrecarga de memória e desempenho.
NCache fornece duas maneiras de definir índices.
• Índice pré-definido (Índice Estático)
• Índice de tempo de execução (Índice Dinâmico)
2. Use projeções de forma inteligente
Quando se trata de perguntas, projeções pode melhorar significativamente o desempenho do seu aplicativo. Com base na sua consulta, NCache permite que você recupere todas as características indexadas de uma classe ou projeções específicas do cache-store.
utilização NCache, você pode especificar as colunas de sua escolha a serem projetadas em sua consulta para executar a pesquisa com mais eficiência. Além de projeções de coluna específicas, você também pode recuperar várias projeções. Abaixo mencionado é um exemplo que projeta $GROUP$ e $Value$ em uma única consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
string query = "SELECT $Value$, $Group$ FROM FQN.Product WHERE Productid > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader. Read()) { Product value = reader.GetValue(1); string group Name = reader.GetValue(2); // Perform operations } } else { // Null query result set retrieved } |
Por padrão, se você não especificar as projeções, o objeto completo junto com as características indexadas viajam do servidor para o cliente mediante solicitação – será mais lento que os dados seletivos. Abaixo mencionado é um exemplo que recupera todos os campos relacionados à classe Produto do cache através do * operador.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
string query = "SELECT * FROM FQN.Product WHERE ProductID > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { string result = reader.GetValue("ProductID"); // Perform operations } } else { // Null query result set retrieved } |
É importante notar que, ao usar projeções, NCache reduz o trabalho extra de recuperação de todas as características indexadas do objeto e recupera apenas as colunas desejadas. NCache ajuda os usuários a melhorar o desempenho dessa maneira, facilitando uma melhor sintaxe de consulta.
3. Tamanho do bloco / Busca de dados em blocos
NCache fornece outro recurso para otimização de consulta chamado Chunk Size. Depois de executar uma consulta de pesquisa, o aplicativo recebe pacotes de dados/chaves em blocos, onde cada bloco representa um tamanho específico de pacotes de dados/chaves. Existem várias maneiras de consultar dados, quer você queira consultar apenas as chaves ou itens seletivos, ou um conjunto completo de propriedades de um objeto – chamado de conjunto de dados.
Quanto maior o conjunto de resultados, mais lento é buscar em resposta à consulta gerada. Portanto, o cliente que está consumindo os dados, em vez de buscar todo o conjunto de resultados de uma vez, consome os dados em blocos do servidor, um por um. NCache por padrão, traz os dados em blocos menores do servidor para o lado do cliente, mescla os blocos de dados e fornece os dados ao aplicativo.
O valor padrão de um tamanho de bloco é 512 KB, mas os usuários podem configurar tamanho do pedaço com base em seus requisitos, enquanto executa o leitor para realizar uma pesquisa no cache com base na consulta especificada. Como os dados viajam na forma de blocos pela rede, isso melhora o desempenho da pesquisa e recuperação de dados.
4. Usando o Cache do Cliente
NCache tem um recurso versátil chamado Client Cache (L1 Cache). L1 é um subconjunto do cache principal que reside mais próximo do aplicativo que pode ser InProc e, OutProc. Por ser um subconjunto do cache principal (L2 Cache), as consultas não são executadas usando o L1 Cache. Somente operações baseadas em chave, como add, getou getbulk as operações são executadas pesquisando as chaves no cache L1 primeiro e obtendo as chaves ausentes do cache L2, mesclando e servindo.
O cache L2 contém dados completos, portanto, consultas e operações realizadas por tags sempre são executadas nele. Em vez de executar uma consulta para recuperar todos os dados do L2 Cache, o usuário pode obter chaves apenas do L2 Cache. E então use bulk get para recuperar essas chaves do L1 Cache. Se algum dado estiver faltando, ele será servido do cache L2. As operações de leitura/gravação executadas com frequência são armazenadas no cache do cliente, resultando em tempos de recuperação mais rápidos para solicitações subsequentes dos mesmos dados.
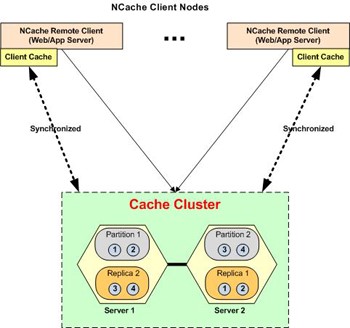
Diagrama representando o funcionamento do Client Cache
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// Executing query to fetch keys only ICacheReader reader = _cache.SearchService.ExecuteReader(queryCommand, false); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { //Populate Keys List keys.Add(reader.GetValue(0)); } } //Get Data using Bulk API. IDictionary<string, Product> productsList = _cache.GetBulk(keys); //If the number of keys is very large, you can break the list into multiple chunks and then do GetBulk for each chunk separately. |
NCache fornece aplicativo de exemplo para buscar dados de forma eficiente do cache do cliente em GitHub.
Conclusão
Neste blog, abordamos as várias maneiras pelas quais NCache usa para aprimorar sua pesquisa de consulta e desempenho de recuperação de dados. NCache não apenas aumenta o desempenho do aplicativo, mas também garante alta disponibilidade e escalabilidade para atender à carga do usuário. Então, sem mais espera Baixar NCache agora e comece sua avaliação gratuita de 60 dias!





