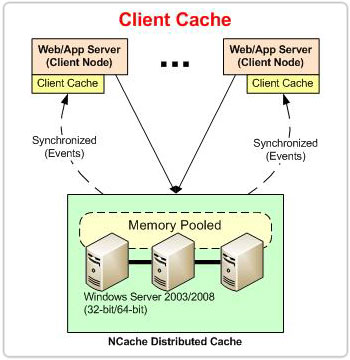
Cache de cliente
NCache topologias de cluster destinam-se a fornecer o melhor desempenho e escalabilidade para seus aplicativos. Com as crescentes necessidades de negócios, os aplicativos precisam processar mais solicitações e dados de clientes. Adicionar mais nós ao cache distribuído fornece escalabilidade linear de forma transparente. Como um cache de processador de hardware, o cache do cliente leva o desempenho de seus aplicativos a um nível superior, aproximando o conjunto de dados quentes de seu aplicativo, mesmo dentro do processo do aplicativo com o Modo InProc.
Considere o exemplo de um aplicativo de comércio eletrônico. O aplicativo acessa frequentemente o catálogo de produtos e os dados dos usuários ativos no momento. Esses dados podem ser mantidos no cache do cliente em execução na caixa do cliente. Por um lado, manter esses dados no cache do cliente aumenta o desempenho do aplicativo, evitando viagens ao banco de dados e ao cache clusterizado. Por outro lado, ele descarrega muitas operações de leitura/gravação do cache do cluster, permitindo que o cache do cluster receba mais solicitações. E esse ganho de desempenho não compromete a consistência dos dados. O cache do cliente mantém seus dados sincronizados com o cache do cluster. A forma como o cache do cliente sincroniza com o cache do cluster é explicada nas seções a seguir.
Plug & Play: Usar o cache do cliente é bastante simples. Nenhuma alteração de código é necessária no final do aplicativo. É uma opção de configuração simples. Você pode criar um cache de cliente por meio do NCache Centro de Gerenciamento ou de NCache cmdlets Powershell suportados. Depois que o cliente for configurado, os aplicativos cliente começarão a usá-lo automaticamente. Para aplicativos já em execução, é necessário reiniciar o aplicativo.
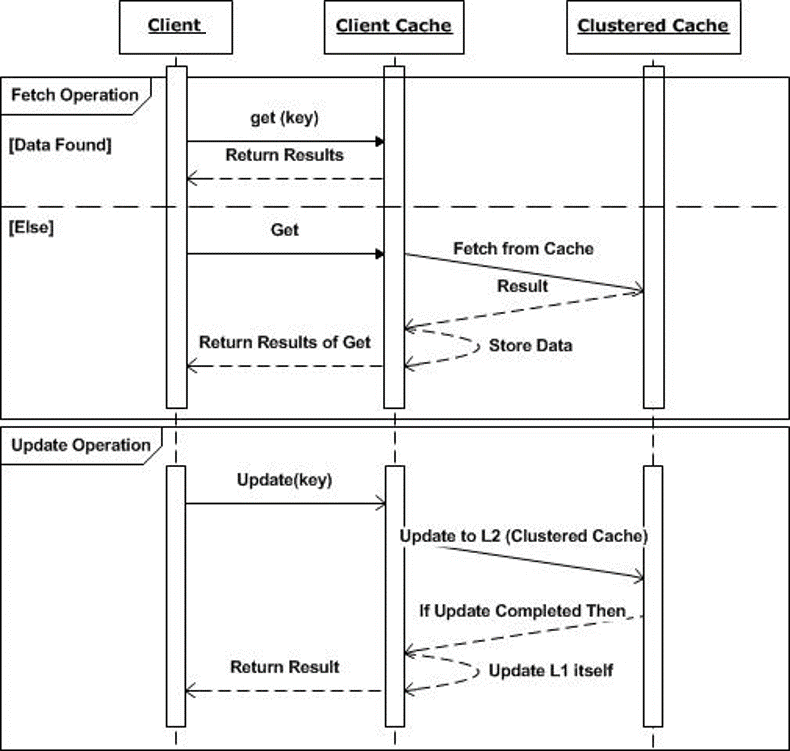
Todos os Produtos Operações CRUD que aceitam chaves de cache como entrada, como Adicionar, Get, inserção e Eliminar, são roteados por meio do cache do cliente. As operações de leitura primeiro procuram os dados dentro do cache do cliente. O cache do Cliente retorna os dados (se encontrados). Caso contrário, a operação de leitura será executada no cache do cluster. Os dados retornados do cache do cluster são retornados ao aplicativo após serem adicionados ao cache do cliente. Portanto, a próxima chamada de leitura para os mesmos dados será atendida pelo cache do cliente. Para operações de leitura em massa, apenas os dados ausentes no cache do cliente são obtidos do cache do cluster.
Operações de gravação baseadas em chave, como, Adicionar e inserção, são executados primeiro no cache do cluster. Após a conclusão bem-sucedida, os dados são adicionados ao cache do cliente e depois encaminhados para o aplicativo. Outras instâncias de cache do cliente são atualizadas através de um mecanismo de sincronização de dados em segundo plano, que é explicado mais tarde.
O cache do cliente contém apenas um subconjunto de dados do cache do cluster. Portanto, todas as outras operações não baseadas em chave, como ObterGrupo, consultas SQL e GetByTags, etc, são executados diretamente no cache do cluster.
Cache do cliente: modos de isolamento
O cache do cliente é executado no nó cliente em que seus aplicativos estão sendo executados. Dependendo de suas necessidades de desempenho e da arquitetura do aplicativo, você pode escolher um dos seguintes modos de isolamento em nível de processo suportados pelo cache do cliente.
Em processo
Como o nome sugere, o cache do cliente é executado dentro do processo do aplicativo, eliminando a comunicação entre processos. Os dados do usuário são mantidos em formato de objeto para evitar o custo de desserialização. Este modo fornece desempenho máximo ao aplicativo. Como o cache do cliente está hospedado dentro do processo do aplicativo, os dados dentro do cache do cliente não são compartilhados entre outras instâncias do aplicativo. Cada instância do aplicativo hospeda uma instância de cache de cliente dedicada. Embora o modo InProc forneça o processo máximo, ele é adequado apenas se:
O conjunto de dados dinâmicos do aplicativo não é muito grande.
O aplicativo possui apenas algumas instâncias em cada nó cliente com memória física suficiente. Lembre-se de que cada instância de cache do cliente contém sua cópia dos dados.
O ciclo de vida do aplicativo é longo o suficiente para colher os benefícios do cache do cliente. Lembre-se de que o ciclo de vida do cache do cliente depende do ciclo de vida do aplicativo. Quando o aplicativo fica inativo, todos os dados dentro do cache do cliente também são perdidos. Os aplicativos com ciclos de vida curtos seriam encerrados ou reiniciados antes que o cache do cliente fosse totalmente preenchido.
Cada aplicativo tem seu próprio conjunto de dados quente, que é diferente de outros aplicativos.
OutProc
Este modo fornece isolamento em nível de processo para o cache do cliente. O cache do cliente é executado em seu processo dedicado no nó cliente. Os aplicativos se comunicam com o cache do cliente por meio de soquetes TCP. Várias instâncias de aplicativos podem se comunicar com o mesmo cache do cliente e, portanto, compartilhar dados. Embora o InProc supere o modo OutProc em desempenho, o modo OutProc vem com seu próprio conjunto de vantagens.
Vários aplicativos executados na mesma máquina cliente se comunicam com o mesmo cache do cliente. Vários aplicativos compartilham dados. Os dados carregados ou atualizados por um aplicativo ficam disponíveis para outros aplicativos.
A reinicialização do aplicativo não resulta em perda de dados do cache do cliente.
Menos recursos físicos, como RAM e CPU, são necessários para executar o cache do cliente no modo OutProc em comparação ao modo InProc, quando cada processo de aplicativo mantém sua cópia do cache do cliente.
A sincronização dos dados do cache do cliente (explicado posteriormente) com o cache do cluster sobrecarrega menos o cache do cluster, pois você executa uma única instância de cache do cliente por máquina cliente.
Note
Se o cache do cliente OutProc estiver inativo, o aplicativo executará operações diretamente no cache do cluster. Quando o cache do cliente for reiniciado, ele se conectará automaticamente ao cache do cliente. Você pode alterar esse comportamento definindo o skip-client-cache-if-unavailable bandeira em cliente.ncconf. Se o sinalizador estiver definido como false, as operações de cache falharão se o cache do cliente estiver inativo.
Sincronizando dados com cache de cluster
Apesar de uma configuração Plug & Play fácil, não podemos ignorar o fato de que o cache do cliente contém uma cópia dos dados do cache do cluster. As alterações feitas nos dados em um cache de cluster devem ser propagadas para o cache do cliente. Podem existir vários caches de cliente em execução no modo InProc ou OutProc para um determinado cache de cluster. As alterações de dados feitas pelo aplicativo cliente são executadas na instância de cache do cliente à qual o aplicativo está conectado. Portanto, esta instância do cache do cliente é sincronizada automaticamente. Entretanto, outras instâncias do cache do cliente não têm conhecimento dessas alterações. As alterações feitas nos dados de cache do cluster são sincronizadas com essas instâncias de cache do cliente por meio de um mecanismo de sincronização de dados em segundo plano explicado abaixo:
Quando os dados são adicionados ao cache do cliente, ele registra a notificação de alteração de dados com o cache do cluster para os dados fornecidos.
O cache do cluster acompanha cada
CacheItemque um cache de cliente mantém e monitora as alterações feitas nos dados.Quando os dados são Atualizada/afastado do cache do cluster, o cache do cluster registra essas alterações.
Um thread de trabalho em segundo plano dedicado inspeciona as alterações de dados a cada segundo e determina quais caches de clientes devem ser notificados sobre as alterações. Ele envia uma notificação aos caches do cliente afetados de que os dados foram alterados.
Outro thread de trabalho em segundo plano dedicado em execução no cache do cliente é responsável por sincronizar as alterações de dados com o cache do cluster ao receber a notificação de alteração de dados. Assim que recebe a notificação, ele solicita o cache do cluster e solicita atualizações de dados. Chamamos esse mecanismo de sincronização de pesquisa de cache do cliente.
Este encadeamento de trabalho em execução no cache do cliente pesquisa as alterações de dados a cada 10 segundos se não tiver recebido nenhuma notificação do cache do cluster para lidar com os casos em que pode ter perdido uma notificação devido à perda de conectividade entre o cache do cliente e o cache do cluster.
Esse poderoso mecanismo de sincronização garante que os aplicativos cliente sejam sempre atendidos com os dados mais recentes do cache do cliente com desempenho e escalabilidade adicionais.
Modos de Sincronização
Junto com o mecanismo de sincronização de dados em segundo plano, o cache do cliente oferece suporte aos dois modos de sincronização a seguir.
Sincronização otimista
Este é o modo de sincronização padrão do cache do cliente. Quando um aplicativo busca dados do cache do cliente e o cache do cliente retém esses dados, os dados são simplesmente retornados ao aplicativo. A sincronização é realizada em segundo plano, conforme explicado acima.
Sincronização Pessimista
O mecanismo de sincronização em segundo plano é adequado para a maioria dos aplicativos e fornece desempenho e escalabilidade ideais para o aplicativo. No entanto, para aplicativos que são mais sensíveis e desejam ter certeza de que serão sempre atendidos com os dados mais recentes, o modo pessimista foi projetado para eles. Com esse modo, quando um aplicativo busca dados do cache do cliente e o cache do cliente retém esses dados, o cache do cliente verifica a versão do item com o cache do cluster. Se uma versão atualizada dos dados for encontrada no cache do cluster, ela será buscada e atualizada no cache do cliente. Assim, o aplicativo tem a garantia de obter a versão mais recente do CacheItem.
Veja também
Topologias de cache
Clustering dinâmico
Cache Local
Cliente de cache
Ponte para replicação WAN