Caches persistentes distribuídos
NCache fornece caches persistentes distribuídos de valor-chave, para recuperar dados valiosos de forma confiável, conforme necessário. Ele mantém uma cópia dos dados do cache no armazenamento de persistência e posteriormente carrega os dados persistidos na reinicialização do cache (planejada ou não). Ele armazena e carrega tantos dados quanto os servidores de cache podem conter. A persistência garante alta disponibilidade de dados e, simultaneamente, os dados na memória fornecem alto desempenho. Neste documento, um cache distribuído com persistência também é chamado de cache persistente.
Note
Cache distribuído com suporte apenas para persistência Topologias Particionadas e Caches Locais (OutProc).
Você pode criar um cache distribuído com persistência usando um NoSQL Document Store como armazenamento de persistência para backup de dados. O cache persistirá em todas as APIs de gravação, meta-informações, córregos, estruturas de dados e índices dinâmicos para a loja de back-end.
Note
As mensagens do Pub/Sub não são persistentes, mas NCache suporta API Pub/Sub e permite que você crie um Cache de mensagens do Pub/Sub.
Observe que os dados removidos do cache devido a qualquer invalidação de dados ou remoção explícita também serão removidos do armazenamento de persistência subjacente. A adição de itens com expiração e dependência de chave é suportada. No entanto, não recomendamos essa abordagem, pois os dados armazenados em um cache persistente são dados permanentes. Enquanto isso, dados com dependência do banco de dados e a dependência de fontes externas não está definida para persistir.
Note
Semelhante a um cache distribuído volátil, uma fonte de apoio é suportada por um Cache Distribuído com Persistência.
Cache persistente: por que persistir dados
NCache armazena dados na RAM para acesso mais rápido. Como a memória cache é volátil, a perda de dados é inevitável nos seguintes cenários:
- Node down na topologia particionada.
- Mais de um nó desativado simultaneamente na topologia Partition-Replica.
- Agrupe-se devido a motivos de manutenção ou falha catastrófica.
Com um cache persistente, você pode conseguir o seguinte:
Alta disponibilidade de dados: Em caso de falha de memória devido a qualquer um dos motivos mencionados anteriormente, NCache recupera rapidamente os dados carregando-os do armazenamento de persistência subjacente. O cache torna-se operacional sem afetar as operações do cliente, mesmo após uma falha catastrófica.
Tolerância ao erro: A manutenção de uma cópia em tempo real dos dados do cache minimiza o tempo de inatividade e fornece tolerância a falhas quando um ou vários nós deixam o cluster.
importante
Para persistência, o comprimento da chave não deve exceder 1023 bytes.
Cache persistente: como funciona
Aqui descrevemos o funcionamento e o comportamento de um cache distribuído com persistência. O diagrama abaixo mostra a arquitetura básica. Você pode criar um cache distribuído com persistência com um armazenamento de persistência no back-end. A loja é centralizada e acessível a todos os nós. NCache grava dados adicionados ao cache para o armazenamento de back-end em intervalos de tempo sustentáveis. Na reinicialização do cache ou na saída/junção do nó, os dados persistentes são carregados na memória tanto quanto os servidores de cache podem conter.
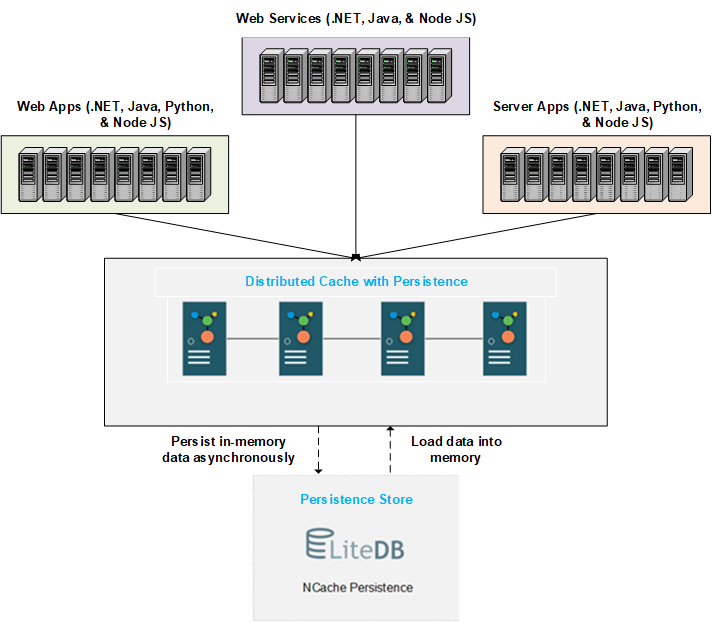
Discutimos o processo detalhado de persistência e carregamento de dados abaixo.
Persistência de dados em um cache persistente
Depois de criar um cache distribuído com persistência, todas as operações de gravação são executadas primeiro na memória e depois persistidas no armazenamento de back-end. Desde NCache tem uma arquitetura distribuída, cada nó do servidor persiste seus dados enquanto todos os nós do servidor podem acessar o armazenamento. Além disso, como a distribuição dos dados é baseada em intervalos devido às partições, os dados são persistidos da mesma forma.
Persistência assíncrona em um cache persistente
NCache persiste dados na memória para o armazenamento de persistência por meio de persistência assíncrona. Aqui explicamos como funciona. Cada partição possui uma fila de persistência para registrar as operações do cliente realizadas. Quaisquer operações de gravação executadas pelo cliente são enfileiradas quando bem-sucedidas. Como a persistência funciona de forma assíncrona, o cliente não espera após enfileirar a operação. As operações enfileiradas são verificadas periodicamente em um valor configurável persistence-interval e, eventualmente, replicado para o armazenamento de back-end por um thread de persistência. Cada fila é escrita independentemente.
Note
O valor padrão de persistence-interval is 1 s e é configurável no NCache Centro de Gerenciamento.
Normalmente, o lote é aplicado após persistence-interval, mas se o lote de persistência falhar consecutivamente, depois persistence-retries intervalo de lote é deslocado para persistence-interval-longer. Assim que for bem-sucedido, o intervalo do lote será redefinido para persistence-interval.
importante
O desempenho do cache não diminui, pois as operações do cliente ocorrem normalmente devido à replicação assíncrona.
Se o cache não puder persistir os dados dentro da fila de persistência devido a algum problema, ele continuará realizando operações de gravação até ficar cheio. Se as operações na fila não persistirem, as informações sobre os buckets com falha serão registradas nos logs de cache.
Note
A topologia Partição-Réplica se recupera de falhas na fila por meio da fila da réplica. No entanto, a perda de dados é inevitável se um nó e sua réplica ficarem inativos simultaneamente.
Carregamento de dados em um cache persistente
Assim que os dados estiverem no armazenamento, o cache recarrega automaticamente os dados persistentes na RAM na reinicialização do cache. O armazenamento persistente deve estar disponível para os nós de cache o tempo todo. Se eles não puderem acessar a loja, o cache não será iniciado. O carregamento de dados ocorre de maneira distribuída. Como o armazenamento de dados é um procedimento baseado em balde, cada nó pode acessar o armazenamento centralizado para carregar seus baldes atribuídos com base no mapa de distribuição de dados. Além disso, se você configurou índices para consultar dados no cache, os índices de consulta são regenerados na reinicialização do cache.
importante
O armazenamento de persistência deve estar sempre disponível para todos os nós de cache.
Comportamento da operação durante o carregamento de dados
Os processos de carregamento e persistência de dados são executados simultaneamente. Enquanto isso, as buscas baseadas em chave são servidas do cache se os dados solicitados forem carregados. Se não estiver no cache, essas operações serão atendidas diretamente da loja por meio de carregamento lento. Nesse caso, a atuação do Get operação será afetada.
Observe que as operações de pesquisa não baseadas em chave ou baseadas em critérios, como GetGroupKeys, GetKeysByTag, e consultas SQL, não serão atendidas até que os dados sejam completamente carregados do armazenamento na memória.
Aviso
Se ocorrer uma operação de pesquisa não baseada em chave durante o carregamento de dados e os dados solicitados não forem carregados completamente, o aplicativo lançará uma exceção informando dados não completamente carregados do armazenamento de persistência.
Cenários de Carregamento de Dados
Os dados são carregados do armazenamento de persistência nos seguintes cenários:
No início do cache: No início do cache, o nó coordenador carrega todos os baldes. Assim que outros nós se juntam ao cluster, a distribuição do bucket é atualizada. Cada nó procura seus buckets atribuídos no ambiente local. Os baldes carregados no cache são extraídos transferência de estado. Se os depósitos atribuídos a um nó não carregarem completamente, esses depósitos serão carregados diretamente do armazenamento por esse nó. Cada nó pode acessar o armazenamento para carregar seus baldes atribuídos, se presentes no cache.
Quando um cache distribuído com persistência é iniciado pela primeira vez, ele pode ser preenchido configurando Carregador de inicialização de cache já que o armazenamento de persistência não tem dados naquele momento. Depois que o armazenamento é preenchido, os dados sempre são carregados do armazenamento no início do cache, mesmo que você tenha configurado o Cache Loader. No entanto, se você precisar adicionar mais dados periodicamente, poderá usar Atualizador de cache. A atualização do cache é executada em intervalos periódicos, independentemente de o cache e o armazenamento já terem os dados.
Na junção do nó: Quando um novo nó ingressa no cluster, ele obtém os buckets atribuídos dos nós do cluster existentes por meio da transferência de estado, se eles já estiverem carregados. Se os buckets atribuídos não carregarem completamente no cache, eles serão carregados do armazenamento pelo novo nó.
Ao sair do nó: Os dados são carregados do armazenamento para evitar a perda de dados quando um nó/nós saem do cluster. O comportamento de carregamento na saída do nó varia para diferentes topologias.
Topologia Particionada: Quando um nó sai, seus buckets são distribuídos entre os nós de cluster existentes e carregados do armazenamento de persistência pelos novos proprietários.
Topologia Partição-Réplica: A Partition-Replica tolera falhas de nós em até um nível, recuperando buckets perdidos por meio da transferência de estado da réplica. No entanto, quando um nó e sua réplica ficam inativos simultaneamente, os dados perdidos ainda podem ser recuperados do armazenamento de backup.
importante
O cache deve ter capacidade para acomodar os dados em caso de inatividade/saída do nó.
Gerenciamento de capacidade para um cache distribuído com persistência
Um cache persistente pode se recuperar da perda de dados na saída ou inatividade do nó somente quando o cache tiver espaço suficiente para acomodar os dados do nó/nós que partiram. Se o cache não puder acomodar todos os dados no armazenamento de persistência por estar cheio ou por qualquer outro motivo, as operações de adição ou atualização começarão a falhar. Enquanto isso, alguns dos intervalos não terão dados completos. Esses buckets incompletos são recarregados do armazenamento em dois casos:
- Um novo nó se junta ao cluster.
- O tamanho do cache aumenta através da aplicação a quente.
Note
Se um cache estiver cheio, mas 100% sincronizado com o armazenamento de persistência, apenas novas adições serão bloqueadas. Todas as outras operações podem ocorrer no cache sem problemas.
Quando o cache está cheio com dados parciais na memória, o cache pode não servir operações não baseadas em chaves ou baseadas em critérios (como GetGroupKeys, GetKeysByTage consultas SQL). Por outro lado, as buscas baseadas em chave sempre serão atendidas por meio do cache ou da loja. Especificamente, o cache tentará carregar lentamente todas as obtenções baseadas em chave para os depósitos incompletos em caso de erros de cache.
Aviso
Se uma operação de pesquisa baseada em critérios ocorrer no cache cheio e os dados solicitados não estiverem no cache, uma exceção será lançada A operação não pode ocorrer porque o cache não tem todos os dados na memória.
Planejamento de capacidade para cache cheio
Para evitar os problemas levantados no cache cheio, você precisa planejar a capacidade de seu cache persistente antes de começar a usá-lo. Ao fazer o planejamento de capacidade para um cache distribuído com persistência, recomendamos que você planeje o tamanho do cache por nó para que, se um nó ficar inativo, os nós restantes possam acomodar todos os dados do nó perdido.
Expansão do tamanho do cache no cache cheio
importante
NCache tenta garantir alta disponibilidade de dados em um único nó deixado em um cache distribuído baseado em réplica de partição com persistência por meio de expansão de tamanho. Contudo, a elevada disponibilidade de dados não é prometida nem garantida.
No caso de Réplica de Partição, se um nó sair de um cluster, os nós restantes no cluster acomodarão os dados pertencentes ao nó que saiu. Porém, existe a possibilidade de que os dados da saída do nó não tenham espaço devido a problemas de dimensionamento. NCache oferece suporte à expansão automática do tamanho do cache quando um nó sai do cache distribuído baseado em réplica de partição com persistência. O modo de expansão é suportado apenas para um único nó inativo. O objetivo é evitar dados parciais no cache e servir operações baseadas em critérios no cache completo.
O processo de expansão ocorre internamente. O modo de expansão é acionado quando um único nó deixa o cluster enquanto os nós em execução são iguais ou maiores que os nós configurados. O tamanho expandido é calculado com base nos nós configurados ou em execução no cluster (o que for maior). Quando o cache está no modo expandido, cada nó no cluster aumenta seu tamanho automaticamente para acomodar os dados recebidos por meio da transferência de estado na saída do nó.
importante
A expansão ocorre apenas quando o número de nós restantes (após o nó inativo) é máximo de {nós configurados/nós em execução}-1. O tamanho expandido é calculado com base nos nós configurados ou nos nós em execução no cluster (o que for maior).
No modo expandido, as operações baseadas em critérios e chaves são atendidas. No entanto, ele ainda bloqueará as operações de adição se o tamanho do cache tiver ultrapassado o tamanho do cache configurado.
O cache sai do modo expandido quando um novo nó se junta ao cluster ou o tamanho do cache aumenta por meio de hot apply. Em seguida, o mapa de distribuição é atualizado e a transferência de estado é acionada. Depois que a transferência de estado é concluída, cada nó sai do modo expandido e o tamanho do cache é reduzido para o tamanho do cache configurado.
Note
Uma entrada é registrada nos logs de cache e logs de eventos quando o cache entra e existe no modo expandido.
Comportamentos de inacessibilidade
Os dados são carregados do armazenamento de persistência na inicialização do cache - portanto, o armazenamento deve estar disponível para os nós de cache de forma consistente. Aqui, discutimos os comportamentos quando o armazenamento de persistência está inacessível;
- No momento da criação do cache: A conexão com a loja é verificada no momento da criação do cache. Se estiver inacessível, você não poderá criar o cache e receberá uma notificação de erro. Da mesma forma, um cache não será iniciado se o armazenamento não estiver disponível para nenhum nó de cluster.
Aviso
O cache não será iniciado até que o armazenamento de persistência esteja acessível a todos os nós do servidor no momento da criação do cache.
No momento do carregamento dos dados: O armazenamento pode ficar inacessível durante o carregamento de dados devido a falha na rede. Nesse caso, o cache tentará novamente carregar os depósitos de dados restantes no estado de carregamento. Enquanto isso, as operações de pesquisa não baseadas em chave falharão. Você pode configurar tentativas de carregamento de dados no arquivo de configuração do serviço.
No momento da execução do cache: O armazenamento pode ficar inacessível para um cache em execução devido a uma falha de rede por um breve período ou por um tempo infinito. Em tal perda de conexão, o cache continuará aceitando e enfileirando operações de gravação. Enquanto isso, NCache continuará tentando persistir as operações enfileiradas em intervalos de lote até que a conexão com o armazenamento de persistência seja restabelecida.
Se você perder a conexão infinitamente, as operações de gravação ocorrerão até que a memória cache esteja cheia. Quando o cache estiver cheio, as operações de gravação subsequentes falharão. No entanto, as operações de busca baseadas em chave serão atendidas conforme discutido anteriormente.
Criação e monitoramento de cache persistente
Note
Somente o cache serializado JSON é compatível com um cache distribuído com persistência.
Você pode criar um cache distribuído com persistência especificando um novo armazenamento ou um existente (criado usando NCache) seja através do NCache Centro de Gerenciamento Ou através de Ferramenta PowerShell.
NCache fornece diferentes contadores de desempenho para monitorar as estatísticas de um cache distribuído com persistência. Além disso, você pode monitorar um cache distribuído com persistência através de NCache Ferramenta Monitor, PowerShell e PerfMon.
Veja também
Criar um cache distribuído com persistência
Introdução ao cache distribuído com persistência