Como usar o cache com o Azure Cosmos DB
Webinar gravado
Por Ron Hussain e Sam Awan
O Azure Cosmos DB é um multimodelo distribuído globalmente baseado em nuvem NoSQL database serviço. Isso é muito popular NoSQL database serviço para aplicativos de alta transação devido à sua simplicidade de implantação e aos SLAs fortes da Microsoft.
Você pode aumentar ainda mais o CosmosDB com NCache. NCache estar na memória significa que é super rápido. E, NCache sendo distribuído significa que ele pode ser dimensionado linearmente. Também, NCache fica muito mais próximo do seu aplicativo e, portanto, é muito mais rápido de acessar. Saiba como incorporar o cache distribuído em seu aplicativo Azure Cosmos DB usando NCache.
Neste webinar, saiba como melhorar o desempenho do Azure CosmosDB com NCache.
Este webinar cobre:
- Introdução ao Azure Cosmos DB e suas operações comuns
- Cache de dados CRUD no aplicativo Azure Cosmos DB usando NCache
- Manipular o cache de coleções
- Gerenciando a sincronização de cache com o Azure Cosmos DB
- Exemplos práticos e demonstrações em todo
O tópico de hoje será acelerar o Microsoft Azure Cosmos DB com a ajuda de NCache. NCache é o nosso principal produto de cache distribuído em Alachisoft. Você pode usá-lo dentro do .NET, .NET Core ou aplicativos Java ou quaisquer outros aplicativos gerais e você pode melhorar o desempenho, escalabilidade e confiabilidade de seu aplicativo. Hoje falaremos sobre as opções de cache que você pode utilizar junto com o Azure Cosmos DB. Porque o Cosmos DB também está ficando muito popular. É muito importante NoSQL database. Então, eu alinhei alguns exemplos práticos para vocês começarem a fazer cache com o Cosmos DB e usar NCache como um produto de exemplo para isso. Então, eu acredito que tudo parece bom. Então, vamos começar rapidamente e se houver alguma dúvida enquanto estou apresentando recursos diferentes, sinta-se à vontade para me interromper e postar quantas perguntas você precisar e Sam ficará de olho nessas perguntas e responderemos a elas abaixo da linha.
Introdução ao Azure Cosmos DB
Os primeiros slides são slides bem básicos sobre a introdução ao Microsoft Azure Cosmos DB. Tenho certeza de que todos sabem, o que é o Azure Cosmos DB? Mas apenas por uma questão de completude, é um banco de dados multimodelo distribuído globalmente. Assim, você pode usá-lo em qualquer lugar. É um serviço de banco de dados hospedado totalmente gerenciado no Microsoft Azure e é um banco de dados multimodelo. Isso significa essencialmente que você pode usar o valor da chave, pode usar a família de tabelas, pode usar a API SQL, há um conector MongoDB e também há uma API Gremlin para gráficos. Então, você tem muitas maneiras diferentes onde, usando isso, você pode usar o Cosmos DB em seu aplicativo como um banco de dados.
Então, é essencialmente um NoSQL database mas a Microsoft afirma ser um banco de dados multimodelo. Então, é um pouco mais do que NoSQL database nesse particular. Portanto, é um banco de dados multimodelo conforme a definição e é muito flexível, fácil de implantar porque é um serviço de banco de dados totalmente gerenciado. Portanto, você só precisa usar os pacotes NuGet em seu aplicativo e apontar para sua instância do Cosmos DB no Microsoft Azure. Se for um aplicativo local, você ainda poderá se conectar ao Microsoft Azure Cosmos DB e é apoiado por SLAs abrangentes da Microsoft. Portanto, é totalmente gerenciado, portanto, você não precisa se preocupar com nenhuma implantação ou qualquer outro problema. Ele suporta um formato JSON muito flexível. Assim, você pode usar dados de documentos não estruturados. Você pode simplesmente criar um documento usando o formato JSON e, em seguida, enviá-lo por push para o Cosmos DB e é isso que você recupera. Portanto, é muito flexível, muito fácil de usar, menos código necessário para começar com isso e é muito popular em aplicativos altamente transacionais. Você pode ter seus aplicativos da web usando-o. Podem ser serviços da Web, microsserviços, aplicativos de servidor de back-end. Qualquer tipo de aplicativo pode utilizar o Microsoft Azure Cosmos DB, se houver necessidade de ingerir processos e lidar com muitos dados em seus aplicativos.
Aqui está um diagrama que novamente fala sobre tabela, SQL, JavaScript, Gremlin, Spark. Portanto, diferentes conectores que você pode utilizar e, em seguida, o mais comum é o valor-chave. Depois, há uma família de colunas, documentos com documentos aninhados e, em seguida, Gremlin para gráficos também. Assim, você pode armazenar gráficos.
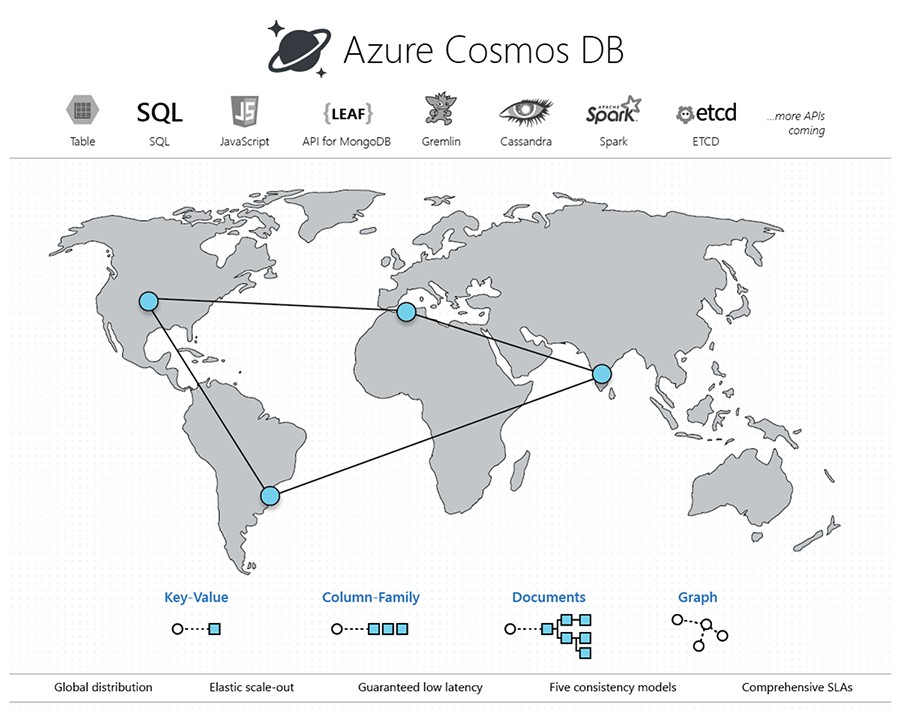
Então, é algo que é distribuído globalmente também. No Microsfot Azure você pode ter vários datacenters. Você também pode ter vários particionamentos. Então, todas as coisas boas que acompanham o Microsoft Azure Cosmos DB.
Casos de uso comuns do Cosmos DB
Alguns dos casos de uso comuns. Você pode usá-lo em IoT e Telemática para ingerir, processar e armazenar muitos dados e, normalmente, se estiver lidando com aplicativos altamente transacionais nesse setor específico, poderá usar o Cosmos DB e não precisará se preocupar em gerenciar essa quantidade de dados e gerenciar essa quantidade de solicitações também. Marketing regional para armazenamento de informações de catálogo, fornecimento de eventos, processamento de pedidos, jogos em que a camada de banco de dados é um componente crucial. Assim, você pode ter vários aplicativos de jogos utilizando ou pode haver diferentes jogadores interagindo uns com os outros. Informações do torneio, tabelas de classificação de alta pontuação e integração de mídia social para esse assunto.
Aplicativos da Web e móveis, esse pode ser outro caso de uso. Os aplicativos sociais podem ser outro exemplo de integração com serviços de terceiros. Portanto, você pode utilizá-lo em praticamente qualquer aplicativo que precise lidar com muitos dados, processar e armazenar muitos dados. Portanto, o Cosmos DB pode ser a escolha preferida para isso. Agora, eu acho que isso é bom, detalhe em termos de introdução. Por favor, deixe-me saber se houver alguma dúvida.
O foco de hoje é quais são os requisitos para armazenamento em cache, certo e por que você precisa de cache para esse assunto? E para isso, há dois problemas com o Microsoft Azure Cosmos DB e isso se baseia no teste de desempenho que fizemos e nas estimativas de custo unitário da solicitação que fizemos.
Problemas com o Azure Cosmos DB
Portanto, existem basicamente dois problemas com o Microsoft Azure Cosmos DB.
Gargalo de desempenho
O número 1 e mais crucial é o gargalo de desempenho. O Microsoft Azure afirma que o Cosmos DB fornecerá um tempo de resposta de milissegundos, certo e isso também é verdade com base em nossos resultados de teste, mas e se você precisar de respostas abaixo de milissegundos? Porque com NCache em nossos testes locais, mesmo um cache local, não estamos falando de particionamento diferente ou ter vários servidores hospedando os dados do cache, mesmo um cache local pode ser na rede também, é capaz de obter respostas em milissegundos e com base em nosso comparações com as quais testamos o Cosmos DB NCache.
Portanto, a diferença de desempenho é enorme quando você compara o Microsoft Azure Cosmos DB com NCache. Portanto, de segundos a milissegundos e de milissegundos a menos de milissegundos, você pode ver que o Cosmos DB precisa de melhorias de desempenho. Principalmente, depois de analisá-lo um pouco mais, é principalmente devido ao fato de dentro de seu aplicativo quando você avançar e implantá-lo em produção, seu Microsoft Azure Cosmos DB é um serviço hospedado. Portanto, sempre estaria na VNET em sua própria assinatura. Pode permitir parte da sua assinatura e eles cobram com base na unidade de solicitação, mas está hospedado no Microsoft Azure e no seu aplicativo, se já estiver hospedado em uma rede virtual, se passar pela VNET, é aí que tem que ter o custo da rede adicionado a ele e isso aumenta a parte de latência também.
Então, isso é um e em segundo lugar, se seus aplicativos estiverem no local, seus aplicativos também serão mais lentos. Então, inicialmente eu falei sobre comparação básica entre Cosmos DB e NCache. NCache já é mais rápido porque está na memória e fornece respostas abaixo de milissegundos em comparação com milissegundos e depois em cima disso, quando você realmente o implanta e seus aplicativos serão hospedados na nuvem. O Cosmos DB do Azure estará em VNET e de comunicação VNET-to-VNET, há uma latência significativa que pode entrar em jogo e se você tiver vários particionamentos e dois datacenters e os dados estiverem indo e voltando e se você acabar indo para outra partição ou outro datacenter, as coisas seriam ainda mais lentas em comparação e, em seguida, no local. Esse não é um caso de uso muito comum, em que os aplicativos locais estão usando o Microsoft Azure Cosmos DB, mas se for esse o caso, você precisará passar pela WAN para acessar o Cosmos DB. Então, essa não é uma opção muito rápida.
Portanto, esse é o problema número um que o Microsoft Azure Cosmos DB não está muito bem implantado em termos de desempenho. Portanto, seu desempenho será degradado especificamente sob alta transação. Quando você recebe muitas solicitações e precisa lidar com esses dados de maneira rápida e oportuna. Então, isso pode causar alguma degradação no desempenho e a solução é muito simples, que abordaremos no próximo slide que você começa a usar um sistema de cache como NCache.
Unidade de solicitação cara
O problema número dois é o custo caro da unidade de solicitação e isso é algo que o prejudica em dólares. Portanto, cada unidade de solicitação tem um custo. Cada vez que você acessa o Microsoft Azure Cosmos DB, mesmo para os dados somente leitura. Se esses dados não estão sendo alterados com tanta frequência, é o mesmo conteúdo, mas você ainda tem a fonte mestre vinda do Cosmos DB, que são os dados que você está procurando. Para esses dados, você precisa ir e voltar para o Microsoft Azure Cosmos DB e é aí que você paga em termos de unidade de solicitação e isso aumenta seu custo. Assim, os custos aumentariam se a carga da sua solicitação aumentasse. Portanto, é muito escalável, na medida em que as solicitações são carregadas, mas não será muito econômica nesse cenário. Então, isso vai impactar o fator custo também. Portanto, pode ser um obstáculo potencial para a expansão. Quando você planeja expandir. Você tem várias partições, sua carga de dados aumenta, mas o fator de custo aumenta junto com isso.
Portanto, talvez seja necessário considerar esses dois problemas ao lidar com o Microsoft Azure Cosmos DB.
A solução: NCache Cache Distribuído
A solução para esses problemas é muito simples que você usa um sistema de cache distribuído como NCache. Em primeiro lugar, NCache está na memória. Então, tudo o que você armazena em NCache será armazenado na memória em comparação. Então, ele vai lhe dar algumas melhorias de desempenho de milissegundos imediatamente e, em seguida, fizemos uma comparação entre o Cosmos DB em execução no host local, na mesma máquina e NCache rodando na mesma máquina, NCache foi um fator mais rápido. Foi muito mais rápido em comparação. Foi em milissegundos em comparação com respostas de milissegundos para o mesmo conjunto de dados.
Em segundo lugar, ele também pode ser hospedado em seu aplicativo de rede e você pode usá-lo além do Cosmos DB. Não é um substituto do Cosmos DB. Neste webinar em particular, explicarei diferentes abordagens nas quais você pode usar o Cosmos DB ao lado NCache e NCache será um produto de ajuda, onde armazenará em cache a maioria dos seus dados e garantirá que ele economize viagens caras ao Cosmos DB em termos de custo e desempenho. Em segundo lugar NCache é um cluster de cache distribuído. Então, ele pode escalar de acordo. A alta disponibilidade está incorporada a ele e também é muito confiável porque há vários servidores e cada servidor também tem um backup em outro servidor e aqui está um diagrama de implantação que ajuda a suportar isso.
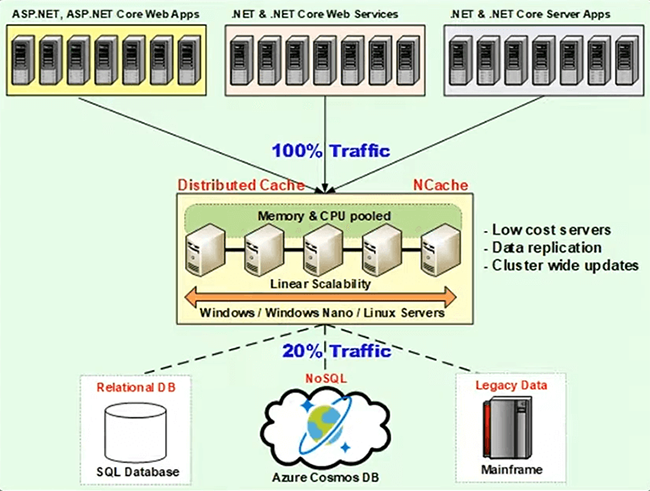
Você pode ter qualquer tipo de aplicativo ASP.NET ou ASP.NET Core aplicativos da web .NET ou .NET Core serviços da Web e, da mesma forma, qualquer outro aplicativo de servidor, mesmo aplicativos Java. Anteriormente, se eles estivessem usando o Cosmos DB na nuvem ou seus aplicativos estivessem no local ou tudo estivesse na nuvem, você pode introduzir uma camada de cache nas mesmas linhas. No Microsoft Azure você pode simplesmente usar NCache no Azure usando .NET ou .NET Core instalação. Está disponível em Microsoft Azure marketplace também e então você pode formar um cluster de cache e uma coisa legal sobre NCache é que vai ficar dentro de sua própria VNET. Portanto, a latência da rede será completamente mitigada. Então, isso não é mais um problema e ainda por cima, NCache está na memória.
então, NCache já é muito rápido em comparação. Assim, o desempenho será melhorado imediatamente e para seus aplicativos locais, você pode manter NCache no local também e o Cosmos DB ainda pode residir na nuvem do Microsoft Azure e isso mudaria tudo em termos de desempenho. Em termos de unidades de custo, você pode armazenar todos os seus dados. Como você pode ver, 100% do tráfego pode ser roteado para NCache e isso, por sua vez, economizaria viagens caras para o Microsoft Azure Cosmos DB e, assim que você economizasse viagens para o Cosmos DB, isso o ajudaria em termos de economia de custos porque a unidade de solicitação cairia. Você teria menos espaço de unidade de solicitação e teria menos custos associados ao acesso e uso do Microsoft Azure Cosmos DB em comparação. Apenas 20% ou até menos de tráfego pode ir para o Microsoft Azure Cosmos DB e falaremos sobre essas opções de cache que ajudariam a beneficiar seus aplicativos.
Então, por favor, deixe-me saber, se houver alguma dúvida? Criamos alguns detalhes básicos sobre por que você deve considerar o uso de produtos como NCache para melhorar sua aplicação. A próxima coisa que vou falar será um caso de uso comum de NCache e então teremos algumas amostras, que eu gostaria de demonstrar. Então, por favor, deixe-me saber se há alguma dúvida neste momento. Assumindo que não há perguntas neste momento. Então, eu vou continuar.
Usos comuns de NCache
Alguns dos casos de uso comuns. Inicialmente, falamos sobre casos de uso em todo o setor. Então, todos esses aplicativos podem usar NCache também. Na verdade, NCache tem um conjunto maior de clientes, variedade de clientes, que estão usando NCache. Então, pode ser comércio eletrônico, pode ser bancário, pode ser financeiro, pode ser automação, pode ser IoT, setor de telecomunicações. Assim, todo setor tem potencial de NCache porque você pode utilizar NCache normalmente em todos os aplicativos que lidam com dados. Eles precisam de desempenho, escalabilidade, alta disponibilidade e confiabilidade e estão lidando com esses problemas. Então, eles são os principais candidatos para NCache. Mas no que diz respeito aos casos de uso técnico, você pode usar NCache para cache de dados do aplicativo.
Cache de dados do aplicativo
Portanto, o primeiro caso de uso é o cache de dados do aplicativo. No Microsoft Azure Cosmos DB, você tem o Cosmos DB como sua fonte primária. É aí que a maioria dos seus documentos ou todos eles existiriam e então alguns ou todos podem ser trazidos para NCache para acesso mais rápido. Portanto, para melhorar os executores e diminuir o efeito da unidade de solicitação em seu aplicativo, você pode ter diferentes tipos de abordagens de sincronização, que também abordarei neste webinar. Portanto, esse é o nosso caso de uso mais comum em relação a bancos de dados relacionais e também em relação ao Cosmos DB.
Ron, eu tenho uma pergunta para você e a pergunta é como o mesmo Cosmos DB com NCache, muda com NCache? Ok, acabei de falar sobre isso. Então, temos um segmento alinhado para isso. Temos um mecanismo dentro do Microsoft Azure Cosmos DB. Ele usa o feed de alterações. Há um padrão de observador. Assim, ele permite que você gerencie adições e atualizações e rastreie essas adições e atualizações no feed de alterações. Portanto, tenho duas abordagens alinhadas neste webinar, onde falarei sobre como usar essas notificações de feed de alterações para ajudar a aplicar essas alterações em NCache também. Assim, assim que houvesse mudança, o banco de dados Cosmos DB seria aplicado automaticamente em NCache também. Então, isso é algo que eu coloquei em uma das demos de hoje.
Cache de Sessões e SignalR Backplane
Alguns outros casos de uso também. Temos ASP.NET e ASP.NET Core aplicativos da web também podem usar NCache para sessões, para Sinal R, para armazenamento em cache de resposta, visualize o estado e o cache de saída e, em seguida, NCache também é uma plataforma de mensagens. Você pode usar Mensagens do Pub/Sub. O SignalR tem backup por meio de mensagens do Pub/Sub. Temos eventos orientados a dados, eventos Pub/Sub e também eventos de consulta contínua. Então, NCache pode ser usado como barramento de mensagens, como plataforma de mensagens e plataforma de compartilhamento de dados.
Demonstração prática
Tudo bem, vou mostrar rapidamente como começar com NCache. Então, nós apenas criamos um cache e então vamos falar sobre diferentes abordagens. Como fazer o cache e como começar com isso? Então, alguns exemplos básicos, na verdade, vamos construir em cima disso e mostrar a você como usar a sincronização e como gerenciar coleções e atualizações.
Então, em primeiro lugar, vou começar com meu ambiente de demonstração. NCache pode ser hospedado no local, bem como no Microsoft Azure Cloud. A opção de implantação preferida para NCache é VM e temos uma ferramenta de gerenciamento baseada na web, que permite gerenciar caixas Windows, bem como caixas Linux. Assim, com a ajuda de .NET Core você pode instalar NCache no Linux também. Então, depende inteiramente de você. Se você deseja manter seu cache na VM no Windows ou no Linux. Estou usando caixas do Windows. Então, vamos em frente e criar um cache. Então, primeiro de tudo eu vou criar.
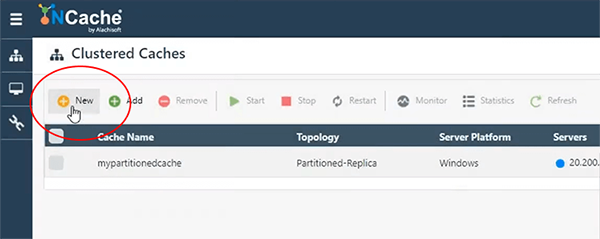
Vou iniciar este assistente aqui. Vou nomear meu cache Democache.
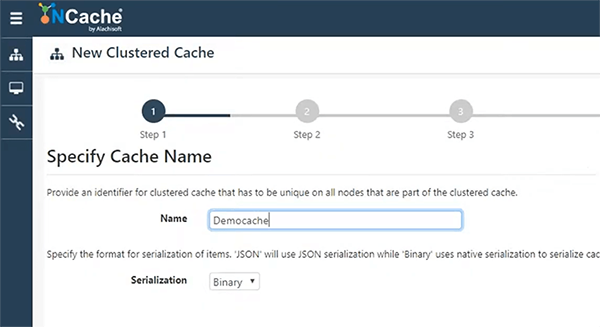
Manterei tudo padrão e os detalhes sobre essas configurações estão disponíveis em nossa documentação, bem como em nossos outros webinars, que são mais focados em NCache arquitetura. Portanto, manterei o cache de réplica particionado. Esse é o mais preferido.
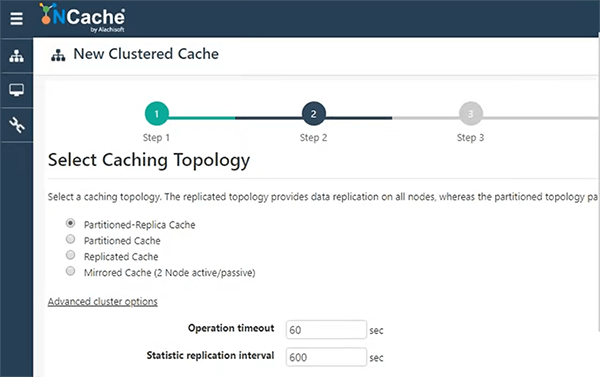
Replicação assíncrona entre a partição ativa e o backup desta. Se houver dois servidores, o servidor um terá backup em dois e o servidor dois terá backup em um. Portanto, manter esse backup pode ser síncrono ou assíncrono com base nas solicitações que estão chegando. Então, vou escolher assíncrono porque é novamente muito rápido e preferido também. Então, vou especificar dois servidores, que vão hospedar meu cache.
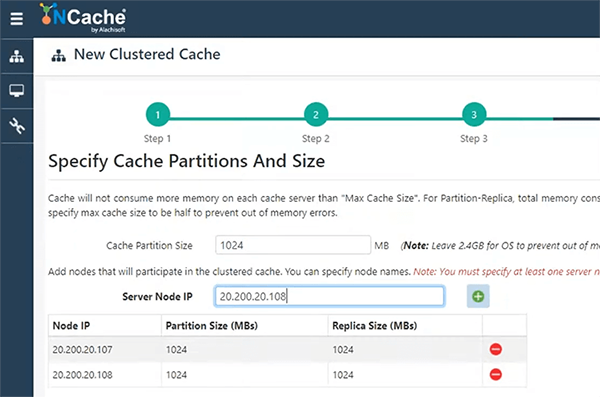
NCache já está instalado. Estas são caixas do Windows. Vou manter tudo padrão quanto às configurações de TCP/IP, NCache é um protocolo baseado em TCP/IP. Então, ele precisa de um endereço IP e uma porta para se comunicar um com o outro e ele pega de lá e então eu vou manter tudo padrão na tela também e vou iniciar esse cache no final.
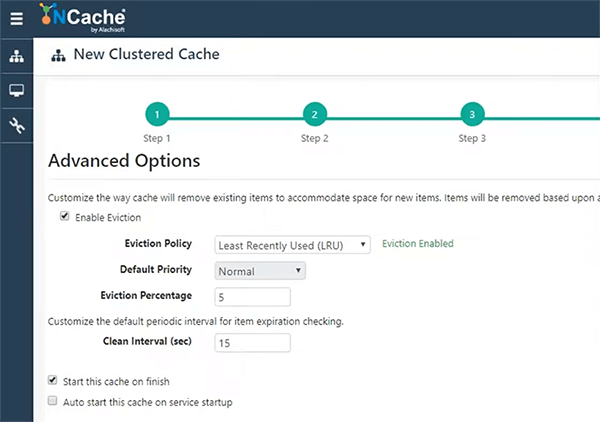
Então, isso é configurado e iniciado imediatamente e isso levará algum tempo e criaria automaticamente o cache e eu tenho meu emulador do Azure Cosmos DB aqui. Estou usando uma implantação localhost dele. Eu tenho duas lojas de documentos aqui, clientes e locações.
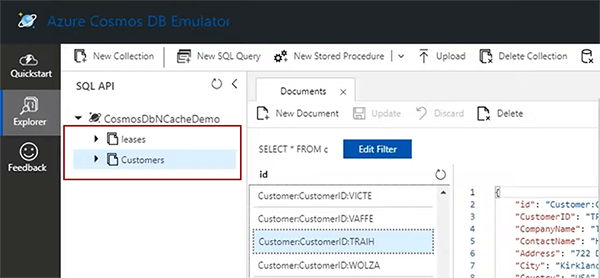
Leases é novamente para sincronização através do feed de alterações. Falarei sobre isso em breve ou em um momento posterior, quando falaremos sobre sincronização. Então, cliente, é a loja de documentos básica da loja do cliente onde temos clientes diferentes. Se eu clicar nos clientes, você pode ver que tenho clientes com nome, ID, endereço, cidade e país e esses são os que vou manipular ao longo desta demonstração.
{
"id": "Customer:CustomerID:TRAIH",
"CustomerID": "TRAIH",
"CompanyName": "Trail's Head Gourmet Provisioners",
"ContactName": "Helvetius Nagy",
"Address": "722 DaVinci Blvd.",
"City": "Kirkland",
"Country": "USA",
"_rid": "Xpd7ANtwbZjSAAAAAAAAAA==",
"_self":"dbs/Xpd7AA==/colls/Xpd7ANtwbZI=/docs/Xpd7ANtwbZjSAAAAAAAAAA==/",
"_etag":"\"00000000-0000-0000-1649-a9a8daaa01d5"
"_attachements": "attachements/"
"_ts":1559153371
}Então, voltando aqui, meu cache está totalmente iniciado. Posso verificar isso e ver os detalhes e posso adicionar minha caixa como cliente. Essa é uma etapa opcional. Se você estiver usando o pacote NuGet, pode pular esta etapa, mas eu irei para facilitar o uso. Então, eu adicionaria tudo do gerenciador de GUI para que eu tenha a configuração preenchida na minha máquina cliente. Acho que estamos bem. Eu vou fazer outra coisa. Abrirei a janela de estatísticas e também abrirei as ferramentas de monitoramento que vêm instaladas com NCache. Então, eles me dão contadores de desempenho e essas janelas são NCache ferramentas de monitoramento, veja um pouco dos aspectos de monitoramento de NCache e, em seguida, abrirei uma janela do PowerShell e executarei um aplicativo de ferramenta de teste de estresse, que vem instalado com NCache e logo depois disso, falaremos sobre o aplicativo de exemplo, que preparei para o Cosmos DB. Essa é a ferramenta que irá simular alguma carga fictícia no meu cluster de cache e, assim que ela aparecer, devo poder ver alguma atividade. Um cliente está conectado.
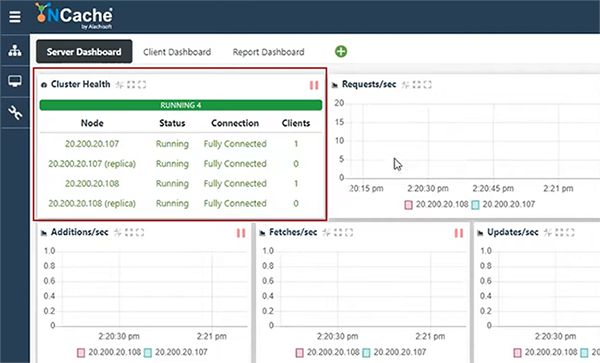
E você deve ver solicitações por segundo aparecendo, mostrando alguma atividade também e, na verdade, eu posso apenas fazer logon nesta caixa aqui, mostrar isso de uma máquina diferente para que possamos ter uma visão mais rápida disso. Tudo bem, você pode ver a atividade aqui. Eu acho que a ferramenta GUI não é capaz de atualizar. Acho que há alguns problemas de permissão. Mas, no entanto, você pode ver a contagem sendo atualizada e, em seguida, você pode ver as solicitações por segundo e é isso que precisamos para esta demonstração em particular.
Cache de dados do aplicativo com o Azure Cosmos DB
Então, eu estou pronto para ir com o aplicativo de exemplo. Falarei rapidamente sobre o caso de uso de cache de dados do aplicativo e, como parte disso, também explicarei como meu aplicativo de exemplo funciona e, em seguida, depuraremos o aplicativo de exemplo passo a passo e mostrarei os comandos, que integrei para começar com o armazenamento em cache. É um programa muito simples e básico. É um olá mundo inicialmente e depois progride a partir daí.
Então, temos o cache de dados do aplicativo. A primeira coisa que você precisa fazer é lidar com dados de referência. Dados que não mudam com tanta frequência e também podem ser dados transacionais, que estão mudando e para isso eu tenho um segmento separado alinhado, mas para dados de referência, você estará lidando principalmente com leituras, certo. Então, você precisa primeiro se conectar ao Cosmos DB e depois se conectar ao NCache. Você precisa executar operações de obtenção e, em seguida, também precisa executar operações de atualização. Nas operações get, você pode armazenar em cache um único documento ou uma coleção de documentos e, em seguida, na atualização, você pode adicionar, atualizar e excluir documentos. Então, esses são os trechos de código e eles serão destacados aqui.
//Add NCache Nuget and Include Namespaces
using Alachisoft.NCache.Client;
using Alachisoft.NCache.Runtime.Caching;
//Add Cosmos DB Nuget and Include Namespaces
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
...
{
//NCache Connection call
static ICache _NCacheClient = CacheManager.GetCache("DemoCache");
//Cosmos DB Connection call
static DocumentClient _CosmosDbClient = new DocumentClient(
serviceEndpoint: new Uri("https://localhost:8081"),
authKeyOrResourceToken:@"C2y6yDjf5/R+ob0N8A7Cgv30VRDJIWEHLM+4QDU5DE2nQ9nDuVTqobD4b8mGGyPMbIZnqyMsEcaGQy67XIw/Jw==");
}...Então, dentro do meu CRUD NCache Aplicativo de exemplo Cosmos DB, tenho diferentes casos, diferentes casos de teste. Então, antes de mais nada, eu iria em frente e forneceria o nome do cache que é DemoCache. Não diferencia maiúsculas de minúsculas e, em seguida, tenho algumas configurações de conexão do Cosmos DB. Estou usando o cliente SQL, como exemplo para isso porque esse é o mais relevante do ponto de vista dos exemplos que escolhi. Mas você pode criar qualquer cliente do Cosmos DB e ainda poder usar NCache porque o NCache API é bastante simples. Ele pode obter a resposta, que pode ser um objeto JSON e você pode armazená-lo em cache, usando NCache APIs e dentro NCache temos diferentes formas de interagir com o cache também. Portanto, você pode escolher entre eles, mas a ideia para o armazenamento em cache permanece exatamente a mesma.
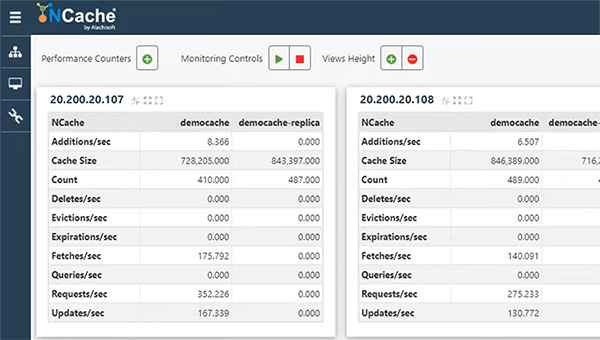
Tudo bem. Então, dentro do meu Cosmos DB, se você vier aqui, você pode ver URL, chave primária, strings de conexão. Então, essas são as configurações que você precisa especificar aqui e então você pode abrir uma conexão. Então, é assim que você obtém um identificador de cache “_cache”, interface ICache, certo. Se eu mostrar isso, isso também fornecerá algumas das APIs de gerenciamento, certo. Deixe-me apenas, tudo bem e a classe CacheManager também, fornece uma coleção de cache. Ele tem ICache, CacheHealth e alguns outros métodos StartCache e StopCache para esse assunto. Uma vez conectado a isso, a primeira coisa que você precisa fazer é simplesmente buscar um item de cache, certo, buscar alguns documentos do Cosmos DB e também armazená-lo em cache. Mas como estamos usando NCache no meio, então, nosso aplicativo deve ser projetado de tal forma que você deve sempre verificar primeiro no cache e é assim que você economizaria viagens caras ao Cosmos DB também e é exatamente isso que está acontecendo no nosso caso um certo aqui.
O que estamos realmente fazendo é obter um ID de cliente, que planejamos obter. Pode ser um ID do cliente, uma busca baseada no ID do cliente e, antes de tudo, farei uma chamada “_cache.Get” e fornecerei uma chave. Chave é algo que você define em NCache. NCache armazena tudo em um par chave-valor. Portanto, a chave pode ser o cliente, a ID do cliente pode estar no parâmetro de tempo de execução e, se você encontrar dados do cache, não precisará acessar o Cosmo DB. Você pode retornar a partir deste ponto. Caso contrário, você sempre executa a API do Cosmos DB. Por exemplo, neste caso, está recebendo uma resposta usando Cosmos DB “_client.ReadDocumentAysnc” e fornecendo todos os detalhes, por exemplo, CollectionID e a chave e, com base nisso, ele buscaria registros do Cosmos DB e também o armazenaria em cache. Isso é para garantir que, na próxima vez, você já tenha os dados no cache.
Então, vou executar o exemplo sem depurar pela primeira vez. Mostre-lhe todos os casos de teste e, em seguida, passaremos por esses casos de teste um por um e demonstrarei que é assim que ele funcionará. Por favor, deixe-me saber, se houver alguma dúvida?
Então, vou adicionar um cliente. Digamos que eu apenas forneça Ross123, pressione enter e, em seguida, você revise um cliente, novamente posso fornecer Ross123 e você pode ver que ele criou um cliente fictício Ross123 com nome de contato, anexou a data e a hora a isso .
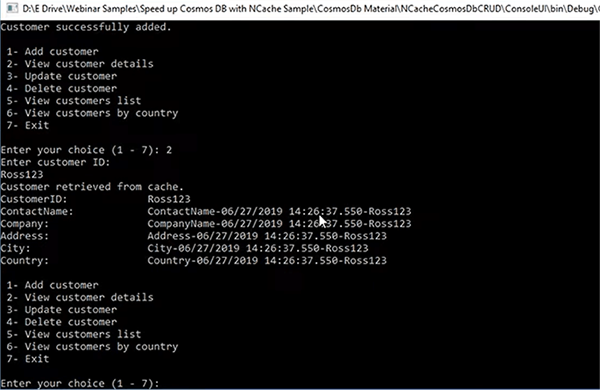
Posso apenas procurar outros clientes, que já estão no Cosmo DB também. Então, consegui isso e com base nisso, enquanto estamos fazendo isso, você poderá ver dois itens no cache Ross e ALFKI já adicionados ao cache.
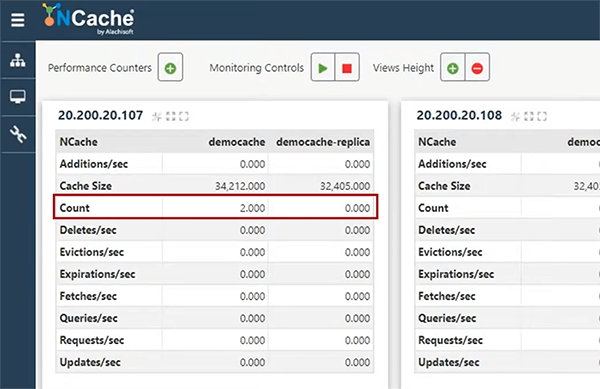
Então, eu posso continuar fazendo isso. Posso atualizar este cliente. Por exemplo, Ross123. Não está pegando nenhum parâmetro. Está simplesmente atualizando o valor de data/hora. Então, se eu acertar isso novamente, agora você pode ver 14:27:13 em comparação com 14:26:37. Então, ele atualizou isso no cache e também no Cosmos DB e, se eu mostrar isso aqui, posso mostrar rapidamente o cliente atualizado no painel Explorer e ele tem o valor atualizado. Então, está lidando com essas duas fontes lado a lado. Eu posso excluir este cliente também. Eu posso ver o cliente com base na verdade, deixe-me me livrar desses pontos de interrupção. Ok, isso vai me trazer todos os clientes, se eu atingir 5 e então se eu atingir 6, ele vai conseguir clientes baseados em um país.
Então, a primeira coisa que eu queria destacar é obter um cliente do cache usando o Cosmos DB e NCache, armazenando em cache um único documento. Então, vamos revisar isso rapidamente.
Customer GetCustomer (Customer customer)
{
string key = $"Customer:CustomerID:{customer.customerID}";
//Check data in NCache first
Customer customer = _NCacheClient.Get<Customer>(key);
if (customer != null)
{
return customer;
}
//If data is not in NCache then get from Cosmos DB and Cache it
else
{
ResourceResponse<Document> response =
_CosmosDbClient.ReadDocumentAsync(UriFactory.CreateDocumentUri (DatabaseId,CollectionId,key)).Result;
customer = (Customer)(dynamic)response.Resource;
_NCacheClient.Insert(key, customer);
return customer;Eu não vou mostrar add neste momento porque isso já é muito simples. Então, eu vou apertar o play, eu atingi este ponto de interrupção e antes de fazer isso, fazer alterações. Vou em frente e limpar o conteúdo. Então, que eu comece de novo. OK. Portanto, o conteúdo é zero em ambos os servidores. Isso é o que se espera. Então, vamos acertar isso. Está no ponto de ruptura, certo. Então, você notaria rapidamente que está esperando que eu busque um cliente ALFAKI e com base nisso, se eu continuar pressionando isso pela primeira vez, ele construirá uma chave de cliente. Essa é a chave com a qual estamos lidando e eu tentaria buscá-la no cache e, obviamente, encontraria null porque é um novo começo.
Em um nulo, ele iria buscá-lo no Cosmos DB e, em seguida, adicioná-lo ao cache também e você pode ver um item adicionado e, em seguida, ele recuperaria e exibiria o valor na tela também e se Eu executo isso mais uma vez, está esperando o mesmo cliente do cache desta vez porque agora está em cache e cada vez que você avança e também pode especificar todo tipo de TTL, todo tipo de propriedades que você tem no Cosmo DB como bem e você obtém o cliente do cache também. Exatamente o mesmo cliente e, desta vez, não iria para o Cosmos DB e apenas mostraria isso na tela também.
Então, é um programa simples de olá mundo, obtendo os mesmos valores do cache porque agora está armazenado em cache e é assim que você faria e é muito mais rápido. Você pode executar um teste de comparação lado a lado entre o Cosmos DB e NCache e você pode ver NCache é muito mais rápido e você também pode economizar viagens para o Cosmos DB e isso afetaria o fator custo também. Apenas reduziria. Então, esse é o primeiro caso de uso.
O segundo caso de uso é como gerenciar coleções e há duas opções aqui. Você tem a coleção inteira como um item ou pode armazenar em cache cada item da coleção separadamente também. Então, para isso você pode, em primeiro lugar, passar por cinco e se eu mostrar o código aqui, você pode armazenar uma lista como um único item. Então, eu apenas atingiria um ponto de interrupção aqui. Isso não é esperar nada, eu apenas mostraria a você pegando do cache e depois apertando o botão play imediatamente.
Rony, eu tenho uma pergunta para você. Existe alguma opção de pesquisa do tipo SQL disponível ou qualquer outro tipo de recurso especial? Sim, essa é uma pergunta muito boa. Esta é uma API básica que estou mostrando. NCache também tem um mecanismo de uso de tags. Você também pode usar a pesquisa SQL, você pode usar LINQ, também temos a Pesquisa de Texto Completo disponível. Então, é muito comparável. Se vocês estão familiarizados com SQL, podem usar a API SQL de NCache. É chamado Linguagem de consulta de objeto. Se vocês estão familiarizados com o LINQ e é isso que você prefere, você pode buscar itens com base no LINQ e, em seguida, a pesquisa de texto completo é outro recurso. Estamos mostrando um par de valores-chave para simplificar. Mas, como eu disse, essas são todas as opções que você pode utilizar como parte disso também.
Então, na primeira vez, ele obtém um valor nulo novamente e, se eu apertar play, devo ter esse cliente carregado como um único item no cache. Apenas um item é carregado. Se eu executar isso mais uma vez, sem parar nada, isso me traz essa coleção de clientes do cache desta vez. Portanto, temos 98 elementos de lista, mas esta é uma lista de clientes de clientes como uma única loja de itens. Então, essa é uma opção. Se você estiver interessado no cache do conjunto de resultados, você pode armazenar em cache a coleção inteira como um item e saber com certeza que essa é a coleção, que você precisa o tempo todo e não precisa de nenhum outro membro da lista ou do conjunto de resultados que você está interessado em armazená-los como um item não faz mal. Mas é recomendado principalmente para coleções menores e também para armazenamento em cache do conjunto de resultados.
A segunda e mais preferida abordagem seria armazenar em cache cada item de coleção separadamente também. Então, você obtém uma consulta executada, uma API executada no Cosmos DB, obtém vários documentos, itera nesses documentos e os armazena individualmente e, em seguida, agrupa-os logicamente com a ajuda de uma tag. Então, por exemplo, estamos fazendo isso aqui.
void GetCustomersByCity (string country)
{
//Retrieve all customers from NCache first
List<Customer> customers = new List<Customer>();
var tagByCountry = new Tag($"Customer:Country:{country}");
IDictionary<string, Customer> items = _NCacheClient.SearchService.GetByTags<Customer>(new[]{tagByCountry},
TagSearchOptions.ByAnyTag);
//If data is not in NCache then get from Cosmos DB and Cache it
if (items != null && items.Count > 0)
{
IDocumentQuery<Customer> query = _CosmosDbClient.CreateDocumentQuery<Customer>(
UriFactory.CreateDocumentCollectionUri(DatabaseId, CollectionId), new FeedOptions { MaxItemCount = -1,
EnableCrossPartitionQuery=true }).Where(c => c.Country == country
).AsDocumentQuery();Se eu mostrar o código, por exemplo, este é o caso de teste aqui. Digite o nome do país, algumas verificações com base nisso construiria a lista e também constrói uma tag por país com o parâmetro de tempo de execução country e então chama “_cache.SearchService” e como parte do serviço de busca temos também OQL. Nos tambem temos consulta contínua, também temos LINQ e temos algum outro mecanismo de pesquisa que você pode usar. Mas estou usando get by tag.
Portanto, espera-se que ele já tenha sido armazenado em cache individualmente e todos esses itens individuais não sejam uma lista, mas você pode colocá-los em uma coleção usando uma tag. Então, usando essa tag, você pode recuperar toda a coleção. Pela primeira vez, ele verificaria no cache, se encontrar retorna, se não retornar, ele iria para o Cosmo DB, executaria a consulta e, em seguida, iteraria pelos itens de cliente individuais para cada cliente. Construir o item de cache e também anexar tag a itens individuais e com base nisso, ele os armazenaria em NCache também usando cache.InsertBulk e se eu trouxer aqui, o caso número seis aqui. Está chamando a coleção, criando uma lista de itens de cache e cache.InsertBulk.
Então, vamos executar isso mais uma vez. Se eu lhe fornecer a opção número seis, neste caso, deixe-me mostrar a contagem de cache também e, desta vez, seria apenas esperar um nome de país, digamos Reino Unido, com base nessa primeira vez, seria apenas construir a lista. List estaria vazio porque sua primeira iteração e, em seguida, executaria o Cosmos DB e, em seguida, construiria um item de cache, iteraria por todos eles. Vamos ver quantos. Acho que oito a dez e inseriu na cache também e você pode ver seis e mais três. Então, cerca de seis itens, acho que sete itens são adicionados individualmente, mas com um grupo chamado tag por país, com essa tag que é marcada por país, que é um parâmetro de tempo de execução country, que é um tempo de execução e tem esse formato para esse assunto e se eu executar isso mais uma vez, o que significa que entrei neste bloco principal mais uma vez. Eu deveria ser capaz de obter todos eles usando a tag que acabei de falar. Tudo bem. E desta vez, espero receber todos esses itens individuais, embora armazenados individualmente, mas categorizados com uma etiqueta, decorados com a etiqueta. Então, essa etiqueta deve me trazer todos esses sete itens de volta como uma coleção, certo. Então, ele retorna uma lista de clientes como parte disso. Então, é IDictionary de clientes e então você pode iterar por eles e se eu apertar play, recebo exatamente a mesma resposta do cache também e novamente, NCache vai ser, isso é uma grande melhoria em termos de desempenho, em termos de área de cobertura, mesmo para sete unidades de solicitação. Para este aplicativo de exemplo, pense nele com milhões de documentos, com milhões de solicitações entrando e saindo. Então, é assim que você gerencia as coleções e as armazena como um único item como uma coleção, itens inteiros ou de cada coleção separadamente no cache.
Cache de operações de atualização com o Azure Cosmos DB
Em seguida, temos operações de atualização com o Azure Cosmos DB. Estes são muito simples, cada vez que você precisar adicionar alguns documentos, você pode chamar cache.add nas mesmas linhas. Eu só vou te mostrar isso para economizar algum tempo. Então, você constrói um documento, “CreateDocumentAsync” no Cosmo DB e então chama cache.Insert. Então, você adiciona no banco de dados, adiciona no cache também e para atualizar, você sempre pode atualizar no cache, no Cosmos DB e depois também no cache e excluir é muito simples também. Você remove do Cosmos DB usando “DeleteDocumentAsync” e então chama “cache.remove” também. Então, isso deve ser concluído e temos esses exemplos alinhados. Então, se houver alguma dúvida, vou passar para o nosso próximo segmento, que é a sincronização, e isso também levará algum tempo. Então, por favor, deixe-me saber, se houver alguma dúvida, caso contrário, abordarei a sincronização NCache com o Azure Cosmos DB. Ron, estamos indo bem nas perguntas. Acho que você fez um ótimo trabalho apresentando o produto. Se alguma pergunta vier, eu definitivamente vou jogar em você.
sincronização NCache com Azure Cosmos DB
OK. A sincronização é um grande aspecto. Quando você tem dados existentes em dois lugares diferentes, no cache e no banco de dados e isso é o que preconizamos também, que você deve usar o cache em combinação com o Cosmos DB. Sempre que houver uma alteração no cache, você também aplicará essa alteração no banco de dados. Há uma atualização, aplique essa atualização. Excluir, aplique essa exclusão. Mas o que acontece se os dados forem alterados diretamente no Cosmos DB e esse será o cenário mais natural em que o Cosmos DB pode estar sendo atualizado por outro aplicativo, outro conector e dados estão sendo ingeridos por outra fonte e seu aplicativo está apenas lendo esses dados e, embora os dados que estão sendo atualizados pelo seu aplicativo também estão sendo atualizados no Cosmos DB, mas para outros aplicativos, isso é uma alteração de dados diretamente no Cosmos DB.
Então, e se eu tiver algo em cache. Vamos supor que eu faça uma alteração no Cosmos DB e essa alteração seja feita no Cosmos DB aqui. Mas essa mudança não será refletida no cache porque os dados existem em dois lugares diferentes e essas duas fontes ficam fora de sincronia. Então, você precisa ter algum tipo de sincronização entre o Azure Cosmos DB e NCache e o conceito que estávamos usando aqui é baseado no processamento de feed de alterações do Microsoft Azure. Portanto, temos um mecanismo de feed de alterações e, com base nisso, temos duas opções diferentes que você pode experimentar.
Uma é uma função do Azure com gatilho Cosmos DB. Portanto, é um processamento de feed de alteração implícito. Portanto, o it0 faz muito trabalho de volta para você e gerencia a adição e as atualizações para começar e você pode criar uma solução alternativa para excluir. A Microsoft afirma que é uma exclusão reversível. Então, você pode usar uma abordagem de exclusão reversível, que é essencialmente uma atualização, mas com o tempo de vida anexado a ela, com alguma palavra-chave anexada a ela, você pode usar em seu aplicativo alguma palavra-chave e pode ser notificado de que esse item não é mais vai estar no Cosmos DB.
A segunda opção é a implementação explícita de processadores de feed de alterações. Você mesmo implementa essa interface em vez de usar um gatilho Cosmos DB na função do Azure. Eu tenho os dois exemplos alinhados. Então, primeiro vamos nos concentrar na função do Azure.
Gatilho de banco de dados do Azure Function
Portanto, com o gatilho de banco de dados de função do Azure, este é um diagrama muito simples.
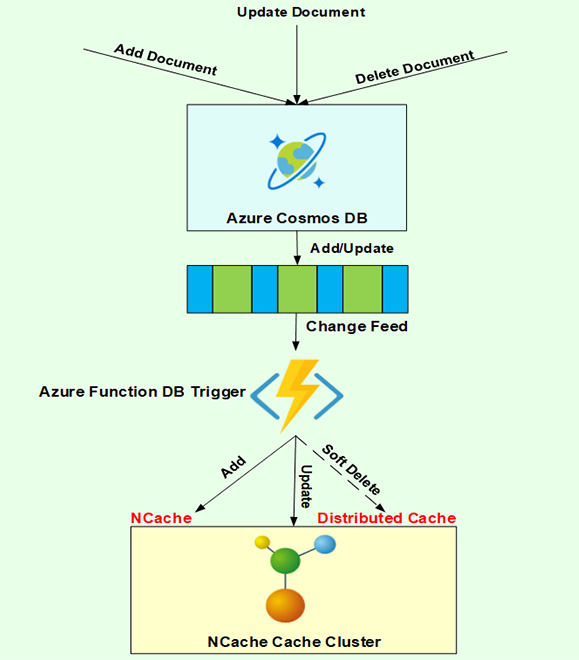
Novamente, seu Cosmos DB está bem aqui, NCache está bem aqui. Seu aplicativo está usando NCache e Cosmos DB ou em algum lugar aqui. E se houver um documento que é adicionado, atualizado ou excluído? Assim, o Microsoft Azure faria, você pode implementar um feed de alterações e pode basear um processador em cima dele. Portanto, esse feed de alterações gerencia eventos de adição e atualização. A exclusão ainda não é compatível com o Microsoft Azure Cosmos DB e você pode implementar a função do Azure com o gatilho de banco de dados. Isso pode adicionar e atualizar essas alterações em qualquer fonte como NCache e tenho uma implementação, onde estou fazendo NCache comando add, update e delete. Exclusão suave, que abordaremos imediatamente.
Então, esta é a implementação geral. O que acontecerá após esta demonstração é que cada vez que você adicionar um documento no Cosmos DB que refletirá automaticamente no NCache. Se houver uma atualização no Cosmos DB que refletiria automaticamente no NCache e da mesma forma, se houver uma exclusão, também temos um gerenciamento para exclusão. Então, você teria essas duas fontes 100% sincronizadas entre si e isso garantiria que não houvesse problemas de inconsistência de dados e isso poderia ser um grande problema para aplicativos, que precisam de dados consistentes que precisam estar atualizados dados e esses são dados de missão crítica e dados muito sensíveis também. Então, essa é a solução que estamos apresentando para isso.
Então, antes de tudo, deixe-me mostrar a função do Azure aqui com o gatilho de banco de dados.
[FunctionName("AzureFunction1")]
public static void Run([CosmosDBTrigger(
databaseName: "CosmosDbNCacheDemo",collectionName: "Customers",
ConnectionStringSetting = "CosmosDbConnection",
LeaseCollectionPrefix ="NCache-CosmosDbTrigger-",
LeaseCollectionName = "leases")]IReadOnlyList<Document> documents,
ILogger log)
{
using (var cache = CacheManager.GetCache("myCache"))
{
Customer customer = null;
foreach (var document in documents)
{
customer = new Customer{Address =
document.GetPropertyValue<string>("Address"),
City = document.GetPropertyValue<string>("City"),
CompanyName =document.GetPropertyValue<string>("CompanyName"),
ContactName =document.GetPropertyValue<string>("ContactName"),
Country = document.GetPropertyValue<string>("Country"),
CustomerID = document.GetPropertyValue<string>("CustomerID")
};Então, ele pega novamente o nome do cache e isso é uma implementação. Ele tem um gatilho Cosmos DB. Deixe-me apenas levá-lo aqui. Então, você pode ver que tem informações de locações e locação eu tenho um arquivo de documentos com o nome locações. Você pode nomear qualquer coisa e isso permite que você tenha um ponteiro, por exemplo, 158 é o último ponteiro. Então, ele tem um monte de parâmetros. Então, o processador de alimentos em cadeia é outra coisa, mas eu tenho 158 como o último ponteiro. Assim, ele mantém um registro de todas as atualizações na memória desde a última vez que operou. Assim, há um acervo de todos os documentos e que são adicionados e atualizados desde a última vez que monitorava essas mudanças. Portanto, é baseado no padrão de observador de feed de alterações, para o qual o Cosmo DB envia informações consistentemente e essas informações são mantidas na memória e também há uma referência a isso no Cosmos DB.
Então, aqui está a implementação de exemplo para isso. Se eu trouxer de volta a função do Azure. Então, ele precisa desse gatilho Cosmos DB. Ele precisa do nome do banco de dados, é claro. Coleção que você está tentando monitorar por meio do feed de alterações. A cadeia de conexão também aluga o prefixo da coleção que é algo, que você coloca no documento de concessões e, em seguida, aluga a coleção denominada concessões. E então eu preciso do meu nome de cache aqui também. Por exemplo, esse é o nome, estou usando o democache e, em seguida, o que ele está fazendo é vamos para cada cliente nesta coleção construir esse objeto de cliente e, em seguida, chamar cache.InsertAsync. Essa é uma tarefa de invocação assíncrona. Então, você pode usar isso e para excluir, falarei sobre isso daqui a pouco. Mas vamos antes de tudo revisar a parte de inserção.
Então, se eu executar este aplicativo, ele aguardará as alterações. Usando esse mecanismo de feed de alterações e dentro dessas concessões, ele esperaria por todos os documentos adicionados e atualizados da última vez e, com base nessa adição e atualização, faria um NCache Chamada de API também. Então, deixe-me apenas executar isso. Levaria algum tempo para depurar. Eu serei reconstruído e, depois disso, devo ser capaz de aplicá-los. Eu não implementei nenhum logger para isso. Portanto, você pode obter alguns erros do registrador com base na minha implementação de exemplo. Mas você também pode implementar alguns detalhes de registro ao lado disso. É um código completo que usei para o meu propósito. Então, eu posso compartilhá-lo no final da demonstração também. Então, essa é a minha função do Azure. Alguns dos parâmetros estão faltando e é por isso que você está obtendo valores nulos, mas no geral, está fazendo o trabalho de sincronização de NCache caso ocorra alguma alteração no Cosmos DB.
E enquanto isso, deixe-me apenas preparar meu documento que vou alterar. Vamos usar Ross123 porque isso é o que criamos inicialmente. Digamos, eu acrescentaria alguns valores. Deixe-me ver se está funcionando agora. Sim, está em execução e em modo de espera. Então, o host inicializou e o aplicativo foi iniciado. Sua função de execução da última vez porque eu estava jogando, fazendo algumas alterações também. Então, deixe-o completo. Ai está. Está cuidando do Ross123 que atualizei. Então, esse documento de arrendamentos foi atualizado.
Então, deixe-me ir em frente e limpar o conteúdo do cache mais uma vez e depois começar de novo. Portanto, temos zero itens no cache e este está em estado de execução. Então, vou mantê-lo aqui e, desta vez, vou abrir o Cosmos DB e anexar alguns caracteres no final do país. Vamos dizer UK várias vezes e então eu também vou adicionar Ross123, algumas strings aleatórias para a cidade também e se eu clicar em atualizar aqui, isso deve acionar o Cosmos DB também e você pode ver lá você vai Ross123 UK UK e Ross123 44. Então, ele está usando essa coleção de leasing e, na verdade, executou essa função e o que isso fez foi adicionar esse cliente aqui e, se eu for e clicar no meu, esse aplicativo foi mantido em execução . Então, se eu ver Ross123, eu preciso apertar play porque há um debug. Esse é o logger que eu não implementei. Isso deve ter Ross123 444 e Ross123 com alguns caracteres aleatórios adicionados a ele. Então, é assim que é simples implementar a função do Azure para Cosmos DB.
Ron, temos uma pergunta sobre a função do Azure e a pergunta é: é obrigatório usá-la como uma função do Azure e qual é o custo associado a ela? A função do Azure é novamente, não é obrigatória, você também pode usar a outra abordagem, que vou demonstrar a seguir. Você mesmo pode implementar um observador de campo de mudança. Isso é uma interface. Implemente todos os métodos e não use o gatilho do Azure Cosmos DB na função do Azure. Então, essa é outra opção. Então, não é obrigatório. Não é a única opção. A função do Azure está hospedada no Microsoft Azure. Portanto, há um custo associado a isso também. Mas é mínimo para esse assunto. É simplista em termos de uso, mas não é a única opção.
Para excluir, isso abrange adicionar e atualizar. Se eu adicionar um novo documento e isso deve ser trazido automaticamente para cá. Eu preciso manter isso em execução porque estou usando adicionar e atualizar, a coleção de concessões é atualizada nas mesmas linhas, mas excluída é um caso em que a Microsoft recomenda que você use uma exclusão reversível e para isso eles recomendam que você use atualização como alternativa e use uma palavra chave, alguma palavra chave aleatória, por exemplo, isso é um delete dentro do documento e ao invés de deletar no Microsoft Azure Cosmos DB você usa esse atributo. Qualquer aleatório excluído, descartado e, em seguida, use um TTL e, em seguida, atualize-o. E com base nisso, se eu executar isso mais uma vez e mostrar o código também. O que isso é feito, se descobrir que há um documento com a propriedade excluída, ele chamará cache ou removerá dele e, com base nesse TTL, será removido do banco de dados de qualquer maneira, mas será removido do cache agora mesmo.
Então, eu vou rodar isso, acho que já está rodando, sim, está. Embora haja um código de erro, mas é isso que o logger. Se eu fizer uma alteração aqui e atualizar este documento, ela também será aplicada no cache. O cliente de função Ross123 também foi excluído do cache. Se eu vier aqui, você pode ver que não está no cache. E agora, a próxima coisa é que já que temos um TTL. Então, após 10 segundos, Ross123 deve ser removido daqui. Portanto, é assim que o Microsoft Azure recomenda que você gerencie a exclusão. Adicionar e atualizar é a única opção para o observador de feed de alterações no momento. Portanto, a exclusão deve ser uma exclusão reversível e essa é a solução alternativa que eu recomendaria também, com base nas recomendações da Microsoft.
Alterar processador de feed
O próximo segmento é sincronizar o cache com o Cosmos DB por meio do processador de feed de alterações. Então, havia uma pergunta, a função do Azure não é a única opção. Você também pode usar o processador de feed de alterações explicitamente e essa é a interface IChangeFeedObserver que você implementa. Deixe-me mostrar-lhe o código para isso.
namespace Microsoft.Azure.Documents.ChangeFeedProcessor.FeedProcessing
{
public interface IChangeFeedObserver
{
Task CloseAsync(IChangeFeedObserverContext context,
ChangeFeedObserverCloseReason reason);
Task OpenAsync(IChangeFeedObserverContext context);
Task ProcessChangesAsync(IChangeFeedObserverContext context,
IReadOnlyList<Document> docs);
}
}Dá-lhe muito mais controle em comparação. Por exemplo, esta é a minha fábrica, bem aqui. Então, eu implementei IChangeFeedObserverFactory. Deixe-me mostrar isso daqui. OK, então, ele tem vários métodos. Eu implementei este IChangeFeedObserver. Tem um método que fecha as conexões. Ele tem um método que abre a coleção e nisso eu estou inicializando o cache e no close, na verdade estou chamando cached.Dispose para descartar os recursos e então o método principal é ProcessChangesAsync. Então, tem IChangeFeedObserver Context, uma lista, token de cancelamento e algumas coisas básicas. Então, o que eu estou realmente fazendo aqui é pegar isso dentro dos documentos desta coleção, lista de documentos. Essa é a que vai ser compartilhada comigo. Então, eu implementei isso de tal forma que o ChangeFeedObserverFactory está me obtendo todos os recursos relevantes e, com base nisso, com base em todas as informações de concessões e informações de documentos que forneci, posso processar rapidamente a exclusão, adições e atualizações. Então, desta vez, deixe-me mostrar a atualização, adicionar casos de uso também, atualizar e excluir e depois concluiremos a demonstração.
Portanto, esta é uma implementação explícita de IChangeFeedObserver. É isso que está sendo usado pela função do Microsoft Azure com a ajuda do gatilho Cosmos DB. Portanto, o gatilho do Cosmos DB implementa isso automaticamente, o que é mais fácil, mas você precisa ter uma função do Azure. Mas e se, se seu aplicativo precisar cuidar disso, você mesmo puder implementar isso. Então, o cache foi iniciado. Deixe-me ver se é, na verdade eu estava usando outro cache. Deixe-me pesquisar, sim e a propósito estou dando todos os detalhes aqui, a demonstração do Cosmo DB, o documento de concessões e o documento de clientes que quero monitorar e estou configurando todos esses parâmetros aqui, democache, save e execute-o e desta vez vou adicionar um documento, atualizá-lo e excluí-lo e mostrar a você que eles serão aplicados no cache de acordo.
Deixe-me executar o operação CRUD também, então, que nós temos. Estou encerrando a função do Azure e, em seguida, estou. Isso já foi adicionado. OK, então, meu cache aqui, já que ele mantém uma referência, então um documento já está lá. Eu quero me livrar dele, para que possamos começar de novo, mais uma vez e desta vez eu adicionaria algo no Cosmo DB e você deve conseguir obtê-lo do cache imediatamente e você pode ver daqui, eu apenas copiaria esta. Novo Documento. Vamos colar aqui. Em vez de Ross123, deixe-me apenas dizer Ron1122 e fornecer os mesmos campos aqui também. Apenas atualizando alguns valores porque este documento já foi deletado, então não importa. E acho que estamos bem. Certo, salve. Então, este documento está bem aqui Ron1122 e se eu mostrar a você o observador de feed de alterações, ele automaticamente cuidou disso. Agora, tudo o que tenho a fazer é ver isso do cache. Em primeiro lugar, foi no cache. Portanto, se estiver no cache, ele será carregado do cache de qualquer maneira. Então, vou dizer Ron1122 e você pode ver, acho que estraguei o ID. É Ron1122. Ai está. Então, tem os mesmos itens.
Agora vou atualizá-lo, para que possamos ver o caso de uso atualizado também. Novamente, vou atualizar alguns personagens dentro da cidade. Digamos, NYK NYK e desta vez em vez de UK, eu diria apenas USA USA USA. Então, isso aplicaria uma atualização e isso iria para os arrendamentos e com base nisso, isso deveria ser aplicado automaticamente. Veja, quão instantaneamente ele está lidando com isso. Então, se eu executar isso mais uma vez e fornecer o ID do cliente Ron1122, você poderá ver o valor atualizado aqui, que é com NYK NYK USA e USA.
Para a exclusão, novamente preciso usar o delete, que é a exclusão reversível e, para isso, tudo o que preciso fazer é adicionar um atributo aleatório. A propósito, será qualquer atributo e também fornecerá um TTL. Por exemplo, excluído com TTL 10 que deve atualizá-lo, mas, por sua vez, eu o removeria porque meu código tem um tratamento para palavra-chave excluída e o tempo de vida cuidará da exclusão do Cosmo DB e da palavra-chave excluída assim que eu encontrar um, eu sei que meu aplicativo foi projetado de tal forma que o Cosmo DB vai se livrar deste documento. Então, eu preciso me livrar do cache. Portanto, é uma exclusão reversível para o Cosmos DB e, se você notar aqui, lá está. As seguintes chaves foram excluídas, o que significa que isso não existirá mais no cache. Se eu tivesse que entrar item com determinado ID não existe. Portanto, ele não fornece dados obsoletos, se você usar NCache com essas duas abordagens.
Então, deixe-me resumir rapidamente. Sam, eu só levaria mais dois minutos. Então, inicialmente falamos sobre cache de dados, operações de obtenção. Você pode começar com APIs simples. No que diz respeito à obtenção de um documento, chame cache.Get. Primeiro verifique no cache, não o encontre, obtenha-o no Cosmos DB e adicione-o também no cache. Então, isso completa o ciclo. Coleções, armazenar em cache toda a coleção é um item ou armazenar em cache cada item de coleção separadamente e falamos sobre os méritos dessas duas abordagens e, em seguida, o aspecto mais importante é adicionar atualizações através dessas mesmas APIs. Sincronização de NCache é possível com o Cosmos DB. É bem direto. Temos duas opções, função do Azure com gatilho de banco de dados ou interface IChangeFeedObserver implementada explicitamente. Assim, ambas as abordagens foram discutidas e você pode escolher entre elas.
Perto do fim, NCache é um cache distribuído .NET altamente disponível, linearmente escalável e muito confiável. Temos várias topologias de cache. Cache do cliente, ponte de replicação WAN. Assim, você pode usá-lo para o Microsoft Azure Cosmos DB no local, na nuvem e também no local. Portanto, diferentes opções estão disponíveis como parte disso. Por favor, deixe-me saber se houver alguma dúvida, no que diz respeito aos detalhes técnicos, caso contrário, eu a entregaria ao Sam.
Ron, há uma questão que meio que abordamos, mas a questão é: você recomendaria mais, qual seria a opção mais recomendada? IChangeFeed ou uma função do Azure? Você falou sobre isso, mas se você quiser lançar alguma luz sobre isso. Claro, isso é um debate a propósito. Se você deseja facilidade de uso, está mais confortável com a função do Azure, vá com isso e se você é um desenvolvedor que deseja usar componentes e manter as coisas sob controle, porque a interface IChangeFeedObserver é algo que você obtém controle total ao abrir as conexões , fechando a conexão e aplicando. Então, se você quiser mais controle, use o IChangeFeedObserver e use a implementação customizada. Se você quiser facilidade de uso, use a função do Azure com gatilho de banco de dados.
OK, temos outra pergunta, há um webinar para explicar mais sobre NCache arquitetura e trabalho? Sim existe. Em nosso webinar gravado, temos uma série de webinars disponíveis e um dos webinars se chama NCache Arquitetura. Então, você pode dar uma olhada nisso. E tudo isso está disponível em nosso site, certo Rony? Sim, aliás, essa gravação será publicada nos próximos dias. Ok perfeito. Então, temos apenas um minuto. Então, pessoal, muito obrigado por se juntar a todos. Eu espero que isso tenha sido útil. Tentamos responder ao maior número de perguntas possível. Se houver alguma dúvida adicional, entre em contato com support@alachisoft.com. Se você quer que nós agende uma demonstração personalizada, teremos o maior prazer em fazer isso para você também. Se você tiver alguma dúvida relacionada a vendas, sempre poderá entrar em contato com nossa equipe de vendas em sales@alachisoft.com. Dito isto, gostaria de agradecer mais uma vez a todos pela adesão. Entre em contato conosco, se tiver alguma dúvida e aprecie seu tempo. Obrigado e tenha um ótimo dia.