Manipulando Dados Relacionais em um Cache Distribuído
Webinar gravado
Por Ron Hussain e Adam J. Keller
Neste webinar em vídeo, aprenda como aplicar seus relacionamentos de dados existentes a objetos de cache para armazenamento em cache distribuído.
Você pode esperar ouvir sobre:
- O modelo de armazenamento de dados para um banco de dados relacional e para um cache distribuído
- A bondade do mapeamento relacional de objetos – como gerenciar relacionamentos de dados no nível do objeto
- Mapeamento de relacionamentos 'um-um', 'um-muitos' e 'muitos-muitos'
- utilização NCache recursos para construir relacionamentos entre objetos para imitar comportamentos de dados relacionais
- uso de dependência baseada em chave, linguagem de consulta de objeto, grupos, APIs de grupo, coleções e tags
- Outros recursos importantes de cache distribuído para dados relacionais
Vou falar sobre ter um cache distribuído no local. Quando você tem um banco de dados relacional, você sabe, você tem alguns desafios, alguns problemas de desempenho, alguns problemas de escalabilidade e, em seguida, você passa a usar um cache distribuído junto com o banco de dados relacional. Quais são os desafios que você recebe e como gerenciar esses desafios? Então, é isso que temos em agenda para o webinar de hoje.
Vai ser bem prático. Quero mostrar alguns exemplos de código. Vou falar sobre alguns exemplos reais. Eu tenho alguns exemplos alinhados que realmente usarei para demonstrar isso. E, no final, eu também teria uma parte prática para repassar algumas NCache configurações.
NCache, esse é o principal produto de cache distribuído. Usaremos isso como um produto de exemplo para este webinar específico. Mas, no geral, é um webinar geral de tópicos. Nós temos um dado relacional no banco de dados e então você tem um cache distribuído. Como fazer a transição e começar a usar o cache distribuído dentro, você sabe, dos dados relacionais que têm relacionamentos e que são dados estruturados. Então, vamos passar por isso.
O que é escalabilidade?
Então, antes de tudo, vou falar sobre escalabilidade, o conceito de escalabilidade. A escalabilidade é uma capacidade dentro do aplicativo em que você pode aumentar a carga transacional. Onde você pode lidar com mais e mais solicitações carregadas da arquitetura do aplicativo. E você não compromete o desempenho, portanto, se você tiver um alto rendimento e baixa latência, essa capacidade é chamada de escalabilidade. Assim, você pode lidar com uma grande quantidade de cargas de solicitações e o desempenho de solicitações individuais não diminui. É o mesmo! E, com mais recursos, você pode até aumentar isso, e a escalabilidade linear é um termo associado que permite realmente dimensionar onde você tem mais ou mais capacidade de manipulação de carga de solicitação introduzida no sistema, adicionando mais servidores. E, na maioria dos casos, o desempenho não diminui.
Portanto, se você tiver baixa latência e tiver uma melhoria linear na carga de solicitações, anteriormente você lidava com, digamos, 10,000 solicitações por segundo ou até mesmo para cinco usuários, você tem certa quantidade de latência, digamos alguns milissegundos ou tempos de resposta abaixo de milissegundos para cinco usuários ; você deve ter o mesmo tipo de respostas, o mesmo tipo de execução do mesmo tipo de latência para cinco mil usuários ou cinquenta mil usuários. E essa capacidade de continuar aumentando a carga do usuário e a carga de solicitações associadas, isso é chamado de escalabilidade linear.
Quais aplicativos precisam de escalabilidade?
Então, quais são os aplicativos típicos que precisam de escalabilidade,

Serão seus aplicativos Web ASP.NET, aplicativos Web Java ou até mesmo aplicativos Web gerais .NET que são voltados para o público. Pode ser um sistema de comércio eletrônico, pode ser um sistema de passagens aéreas, um sistema de reservas ou pode ser um serviço financeiro ou serviço de saúde que tem muitos usuários realmente usando seu público. Isso pode ser o WCF de serviços da Web ou qualquer outro serviço de comunicação que esteja interagindo com algumas camadas de acesso a dados ou esteja lidando com alguns aplicativos front-end. Mas pode estar lidando com milhões de solicitações a qualquer momento. Pode ser a Internet das Coisas, alguns dispositivos de back-end que podem dados que algumas tarefas processam para esses dispositivos. Então, pode ter um monte de solicitações de carga. Processamento de big data é uma palavra de ordem comum nos dias de hoje, onde temos muitos servidores de computação pequenos e baratos e, por meio da distribuição de dados em vários servidores, você processa uma grande quantidade de cargas de dados.
E, da mesma forma, haveria uma enorme carga de solicitações de modelo para esses dados específicos. E, então, podem ser quaisquer outros aplicativos gerais de servidor e aplicativos de camada que possam estar lidando com milhões de solicitações, muitos usuários, esses são os principais candidatos à escalabilidade. Esses são os aplicativos que precisam de escalabilidade dentro da arquitetura.
Gargalo de escalabilidade
Este é um diagrama típico. Qual é o gargalo de escalabilidade?
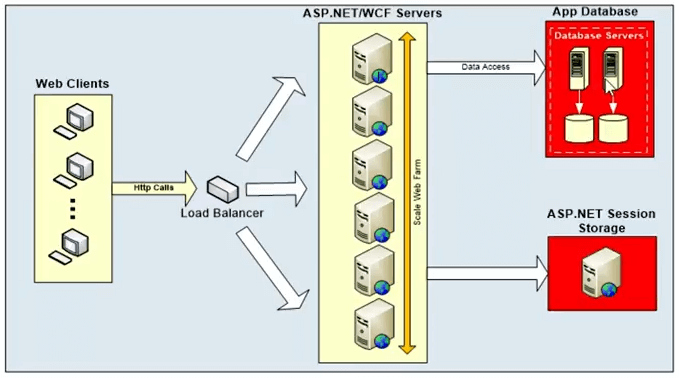
Então, essas são as aplicações. Por design, essas estruturas são muito escaláveis. Formulário da Web ASP.NET ou formulário WCF, existem opções que você pode usar para dimensionar esses sistemas. Mas, todos eles falam com um banco de dados back-end e normalmente é um banco de dados relacional. Também pode ser um armazenamento de sessão ASP.NET ou um mainframe ou um sistema de arquivos, mas não é isso que estamos abordando no webinar de hoje. O webinar de hoje é mais focado em dados relacionais. Assim, os dados relacionais são uma única fonte. Embora você tenha uma plataforma muito escalável aqui. Você pode adicionar mais e mais servidores nessa camada. Você pode expandir colocando um balanceador de carga na frente e esse balanceador de carga pode rotear solicitações entre diferentes servidores. Mas todos esses servidores web acabam se comunicando com uma camada de banco de dados que não é tão escalável.
Então, isso vai ser uma fonte de discórdia. Vai ser lento para começar e, em seguida, não pode escalar. É uma fonte única, não há opção de adicionar mais e mais servidores de banco de dados para aumentar a capacidade de solicitação. Portanto, a capacidade de solicitação pode atingir o máximo e isso pode levar a alta latência. Portanto, é um problema de capacidade para o tratamento de solicitações e também pode acabar em um problema de latência, para que possa sufocar o sistema quando você tiver uma carga de solicitações muito grande.
A Solução
Então, esse é o principal problema com fontes de dados relacionais e a solução para isso é muito simples que você comece a usar um cache distribuído.
Um sistema de cache distribuído como NCache que é super-rápido porque está na memória em comparação e é linearmente escalável. Não é apenas um único servidor. É um ambiente de vários servidores onde temos uma equipe de servidores unidos em capacidade. Você agrupa a capacidade de memória e a capacidade transacional e obtém um modelo muito linearmente escalável. E, NCache é exatamente esse tipo de solução que você pode usar para lidar com problemas de escalabilidade do banco de dados.
O que é Cache Distribuído na Memória?
Como é um sistema geral de cache distribuído na memória NCache? Quais são as características?
Cluster de vários servidores de cache baratos
Será um cluster de vários servidores de cache baratos que são unidos em uma capacidade lógica.
Então, este é um exemplo disso. Você pode ter de dois a três servidores de cache. Por NCache, você pode usar o ambiente Windows 2008, 2012 ou 2016. Apenas pré-requisito para NCache é .NET 4. E é uma camada intermediária entre seu aplicativo e o banco de dados e é muito escalável em comparação com sua camada de banco de dados, mas é algo que lhe daria o mesmo tipo de escalabilidade que você obteria de uma Web .NET acelerada formulário ou formulário da web de serviços da web WCF.
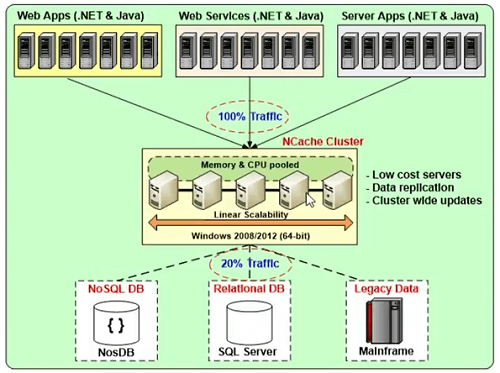
Sincroniza atualizações de cache em todos os servidores de cache
Sincroniza as atualizações de cache em todos os servidores de cache para que a consistência dos dados seja incorporada ao protocolo. Todas as atualizações são aplicadas de forma automática com o entendimento de visualização de dados consistente para todos os clientes que estão conectados a ela.
Escala linearmente transações e capacidade de memória
Ele deve escalar linearmente para transações, bem como da capacidade de memória, você simplesmente adiciona mais servidores e não deve aumentar a capacidade em resposta a isso. Se você tiver dois servidores e adicionar o terceiro e o quarto servidor, ele deve basicamente dobrar a capacidade desse sistema agora que você tem o dobro da quantidade de serviço. Então, isso é o que NCache oferece também.
Replica dados para confiabilidade
Então a replicação é outro recurso para confiabilidade. Qualquer servidor inativo, antes de tudo, não deve ter perda de dados ou tempo de inatividade. Deve ser um sistema altamente confiável e altamente disponível e é isso que NCache cuida.
NCache desenvolvimento
Então, tendo discutido isso, você tem um problema de escalabilidade com fontes de dados relacionais e sistemas de cache distribuídos como NCache é uma solução para isso e que se torna a camada central entre seus aplicativos e o banco de dados e seus dados existem em dois lugares.
Você tem dados no banco de dados e, em seguida, tem dados no cache distribuído. Então NCache também gerencia alguns desafios de sincronização que você pode ter quando tiver dados em duas fontes diferentes. Há um webinar separado sobre este tópico, mas, apenas para que você saiba que existem alguns provedores de camada de acesso a dados, existem algumas dependências de notificação de alteração que você pode configurar.
Assim, qualquer alteração no banco de dados pode desencadear uma invalidação ou atualização de itens no cache e, da mesma forma, quaisquer alterações ou atualizações que ocorram no cache podem ser aplicadas no banco de dados. Portanto, isso pode ser alcançado com a ajuda de nossos provedores de camada de acesso a dados; Read-through e Write-through.
E, então, também temos algumas dependências de alteração de banco de dados, dependências de alteração de registro que realmente usamos para garantir 100% de sincronização entre o banco de dados e os registros de cache. Mas, normalmente, os dados existem em dois lugares diferentes. Você tem dados no cache que geralmente são um subconjunto dos dados e, em seguida, você tem dados reais no banco de dados. Quando você migra dados, é essencialmente uma migração de dados. Embora você esteja usando essas duas fontes em combinação, essas são duas fontes diferentes.
Quais dados armazenar em cache?
Antes de prosseguirmos, falaremos rapidamente sobre os tipos de dados que você pode armazenar em cache, podem ser dados de referência, podem ser dados transacionais.

É mais um dado intensivo de leitura que você armazena em cache geralmente pertence ao banco de dados relacional. Não é que não esteja mudando, não é 100% estático. Está mudando os dados, mas a frequência dessa mudança não é tão grande. Então, isso seria categorizado como um dado de referência. E, então, nós sempre transacionamos dados que estão mudando com muita frequência. Tão frequentemente quanto em alguns segundos, alguns minutos ou em alguns casos que pode ser em alguns milissegundos.
E, então, a maioria dos dados em cache são relacionais. Ele é trazido de um banco de dados relacional e eu já discuti que você tem dados de cópia mestre no banco de dados relacional e então você tem um subconjunto desses dados, uma referência e transacional, trazido para o cache distribuído. Direita!
Qual é o desafio?
Então, qual é o desafio? Então, vamos realmente discutir esse desafio! Quando você move seus dados de uma fonte de dados para uma relação em um cache distribuído para obter mais desempenho, mais escalabilidade e mais confiabilidade para o sistema. Vamos discutir rapidamente quais são os desafios que você vê.

Funciona muito bem. Melhora seu desempenho porque está na memória. é linearmente escalável, portanto, cuida dos problemas de escalabilidade com o banco de dados. Não é um único ponto de falha porque existem vários servidores e qualquer servidor pode ser derrubado. Você pode trazer servidores sem problemas. A manutenção fica muito mais fácil. Suas atualizações ficam muito mais fáceis. Então, em comparação, você obtém muitos benefícios. Mas há um desafio que você precisa resolver e precisa levar isso em consideração ao migrar seus dados ou mover seus dados do banco de dados para o cache distribuído e começar a usar o sistema de cache distribuído.
Portanto, o cache distribuído é uma tabela de hash como interface. Direita! É cada item separado com a chave e um valor, certo? Então, é uma tabela de hash onde os itens cada objeto no cache ou cada item no cache ou um registro no cache é representado com a ajuda de uma chave. Então, não é uma tabela ou não é um dado relacional onde temos relacionamentos, temos esquemas definidos, temos entidades que possuem relacionamentos adequados entre si. Será um item de valor-chave separado representando um objeto no cache. Então, banco de dados tem relacionamentos entre entidades e quando você migra seus dados ou quando você move seus dados de um banco de dados relacional para um cache distribuído, você perde aquele relacionamento característico desses dados.
Então, por padrão, você não tem essa capacidade para que possamos removê-la. Esse é um dos principais desafios e, em seguida, existem alguns outros desafios associados que as consultas de banco de dados resultam em uma coleção de objetos. Também resulta em uma tabela de dados ou leitor de dados. Então, lidar com tabelas de dados e leitores de dados em um cache distribuído não é uma boa ideia, certo? então vamos passar por todos esses desafios um por um.
Em primeiro lugar, discutiremos como gerenciar relacionamentos no cache distribuído depois que você trouxer dados de uma fonte de dados relacional para o cache e como abordar esse detalhe.
Espie dentro do NCache API
Então, a seguir falaremos sobre a API de cache.

Agora que discutimos que é basicamente um armazenamento de valor-chave. Temos um cache.add onde temos uma chave “mykey” e então temos um objeto que é qualquer dado permitido e objeto serializado permitido. pode ser qualquer objeto cliente, objeto produto, objeto pedido. Mas este é um exemplo muito simples de hello world onde chamamos métodos de valor de chave usando cache.add, cache.update. Da mesma forma, chamamos cache.get para obter o mesmo item de volta e, em seguida, chamamos cache.remove.
Gerenciar relacionamentos no cache
Se movendo! Então, como gerenciar relacionamentos no cache? Agora que definimos esse desafio, o cache é uma tabela de hash como uma interface, é um par de valores-chave. Valor é objeto .NET e chave é uma chave de string que você formata e estes são objetos independentes um do outro. E, banco de dados tem tabelas de relações que têm relações entre si. Pode ser uma relação um-para-um um-para-muitos e muitos-para-muitos entre tabelas diferentes.
Primeira etapa: use a dependência de cache
Há duas coisas que você deve considerar fazer antes de tudo, você deve considerar usar a dependência de cache e estamos focados principalmente na dependência baseada em chave que é um dos recursos e mostrarei alguns exemplos de código sobre isso que ajudam você a manter um rastreamento de dependência unidirecional entre os itens de cache.

Então, você pode ter um objeto pai e então você pode ter um objeto dependente nesse objeto específico. E, a maneira como funciona é que um item depende de outro. O item principal, o objeto primário ou o objeto pai; se passar por uma mudança é atualizado ou removido o item dependente automático é removido do cache.
Um exemplo típico que alinhei nos próximos slides é a lista de pedidos para um determinado cliente. Então, você tem um cliente A. Ele tem uma lista de pedidos, digamos 100 pedidos, e se esse cliente for atualizado ou removido do cache. Você não precisa desses pedidos associados a isso, então você pode querer fazer algo em torno da coleção de pedidos também e é exatamente para isso que essa dependência serve, você precisa ter uma ligação entre esses 2 registros, pois eles estão relacionados no in the banco de dados relacional.
Então, essa dependência também pode ser em cascata na natureza, onde A depende de B e B depende de C. Qualquer alteração no C desencadearia uma invalidação de B e isso, por sua vez, invalidaria A também. Portanto, pode ser uma dependência em cascata e também pode ser uma dependência de vários itens. Um item pode ser dependente do item A assim como do item B e, da mesma forma, um item pai também pode ter vários itens filhos. E esse foi um recurso inicialmente introduzido pelo cache ASP.NET. Foi uma das características poderosas que NCache também tem. Nós o fornecemos como um objeto de dependência de cache separado e um dos objetos sofisticados e esse será o foco principal deste webinar em particular.
Segunda Etapa: Use o Mapeamento Relacional de Objetos
Segundo passo, para mapear seus dados relacionais, há um outro desafio que recomendamos que você realmente deve mapear seus objetos de domínio para seu modelo de dados, certo?

Portanto, seus objetos de domínio devem representar uma tabela de banco de dados. Você deve usar algum tipo de mapeamento O/R, você também pode usar algumas ferramentas de mapeamento O/R. Ele simplifica sua programação, você pode reutilizar o código depois de mapear as classes nas tabelas do banco de dados. Você pode usar até mesmo as ferramentas de mapeamento ORM ou O/R, como Entity Framework e NHibernate. Estas são algumas ferramentas populares.
A ideia aqui é que você deve ter classes no aplicativo. Os objetos, os objetos de domínio no aplicativo. Assim, seus objetos de banco de dados, tabelas de dados ou leitores de dados são transformados mapeados para os objetos de domínio. Portanto, uma tabela de clientes deve representar uma classe de clientes no aplicativo. Da mesma forma, a coleção ordenada ou a tabela de pedidos devem representar a classe de pedidos e o aplicativo. E então esses são os objetos que você lida e armazena em cache distribuído e formula relacionamentos com a ajuda de Dependência de Chave.
Exemplo de tratamento de relacionamentos
Vamos dar um exemplo!
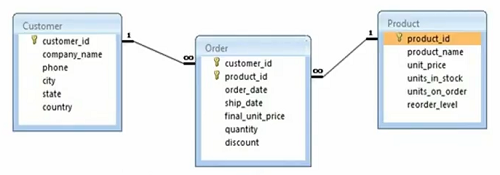
E temos nosso modelo de banco de dados da Northwind. Temos a tabela de clientes, temos a tabela de pedidos e depois temos o produto. Temos todos os nomes das colunas do cliente temos ID do cliente, nome da empresa, telefone, cidade, estado, país, alguns atributos. Da mesma forma, temos produto com ID do produto, nome, preço, unidades em estoque, unidades em pedido, nível de reabastecimento. Então, esses são alguns atributos ou algumas colunas do produto e também temos a tabela de pedidos que tem o ID do cliente e o ID do produto como chaves estrangeiras. Isso é formular uma chave primária composta e então temos a data do pedido, a data de envio e alguns atributos dos próprios pedidos. E se você perceber isso, há uma relação de um para muitos entre o cliente e o pedido e, em seguida, há uma relação de um para muitos entre o produto e o pedido. Da mesma forma, temos muitos-para-um e muitos-para-um entre pedido e cliente e pedido e produto, respectivamente. Então, vamos abordar este cenário específico.
Inicialmente, foi o relacionamento muitos-para-muitos do produto do cliente que foi normalizado em dois relacionamentos um-para-muitos. Portanto, este é um modelo de dados normalizado e usaremos um exemplo disso em que temos uma classe no objeto principal mapeada para esse modelo de dados específico. Então, falaremos um pouco sobre o objeto primário, mas deixe-me mostrar rapidamente o exemplo aqui.
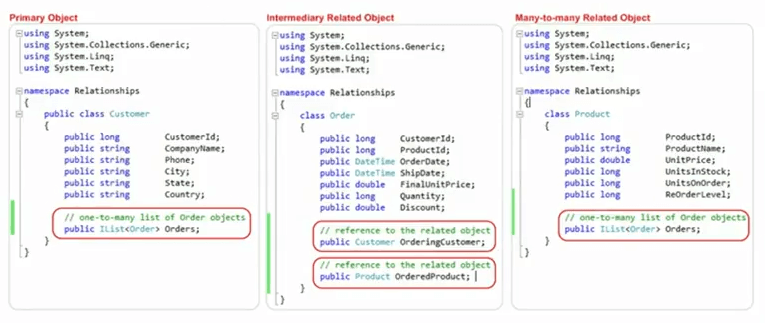
Observe que os objetos de domínio foram mapeados em nosso modelo de banco de dados. Para este mesmo exemplo, temos uma classe de cliente que possui um ID de cliente que será usado como chave primária e, em seguida, temos uma coleção de pedidos que representa muitos relacionamentos com a classe de pedido. Da mesma forma, temos um produto que possui atributos de produto iguais a esses ID do produto, nome, preço unitário, certo? E também temos a coleta de pedidos aqui, o que representa um relacionamento de um para muitos e, no lado do pedido, temos o ID do cliente trazido daqui ID do produto trazido daqui e, em seguida, temos o cliente do pedido, o cliente muitos-para- um relacionamento e, em seguida, temos o pedido de produtos tantos para um relacionamento capturado como parte do objeto de domínio.
Então, esta é uma das técnicas que vou abordar em detalhes nos próximos slides. Deixe-me mostrar esses objetos no visual studio também, então essa é uma das classes.
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.Runtime;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Alachisoft.NCache.Runtime.Dependencies;
using System.Collections;
namespace Relationships
{
public class Customer
{
public long CustomerId;
public string CompanyName;
public string Phone;
public string City;
public string State;
public string Country;
// one-to-many list of Order objects
public IList<Order> Orders;
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// Let's cache each product as seperate item. Later
// we'll search them through OQL
foreach (Product product in products)
{
string productKey = "Product:ProductId:" + product.ProductId;
cache.Add(productKey, product, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
cache.GetGroupData("DummyGroup", "DummySubGroup");
cache.GetByTag(new Alachisoft.NCache.Runtime.Caching.Tag("DummyTag"));
}
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string query = "SELECT Relationships.Product WHERE this.UnitPrice >= ?";
Hashtable values = new Hashtable();
values.Add("UnitPrice", unitPrice);
ICacheReader products = cache.ExecuteReader(query, values, true);
IList<Product> prodList = new List<Product>();
// For simplicity, assume that list is not very large
while (products.Read())
{
prodList.Add((Product)products.GetValue(1));// 1 because on 0 you'll get the Cache Key
}
return prodList;
}
}
}Uma coisa que eu recomendo é que você decore essas classes com tag serializável, certo? Então, você precisa armazená-los em cache, certo? Portanto, esses objetos de domínio devem ser serializados porque são eles que vão e voltam entre seu aplicativo cliente e o cache distribuído.
Então, temos a classe do cliente, temos a classe do produto, bem aqui. Uma lista de pedidos e temos a classe de pedidos que também possui todos os atributos mostrados no slide da apresentação.
O que é Objeto Primário?
A seguir, falaremos sobre o objeto primário. Agora que mostramos alguns objetos principais que são mapeados neste modelo de dados de domínio. Mostraremos algumas técnicas para analisar relacionamentos um-para-um-um-muitos e muitos-para-muitos.
Então, antes de tudo, falarei sobre um termo que usarei nos próximos slides.

Objeto primário, é um objeto de domínio. Está mapeado para o seu banco de dados. É um ponto de partida da sua aplicação, por exemplo, você tem um objeto cliente e então se você precisar de pedidos você precisa que o cliente comece, certo? Então, é o primeiro objeto que sua aplicação busca e todos os outros objetos que estão relacionados a isso serão trazidos em relação a isso, certo?
Outro exemplo pode ser se você estiver processando os pedidos corretamente, então você pode querer buscar pedidos nessa unidade de processamento e, em seguida, gostaria de saber sobre o cliente que fez o pedido para despachar esse pedido específico, certo? Portanto, nesse caso, o pedido se torna seu objeto principal e, em seguida, tem um relacionamento de muitos para um ou tem um relacionamento com um dos clientes que realmente pediu esse pedido específico ou todos os produtos desse pedido. Então, vai ser de uma forma ou de outra, mas estaremos dando que usaremos um objeto primário que será armazenado em cache e, em seguida, tornaremos outros objetos dependentes disso. Essa é a abordagem que se seguirá.
Relacionamentos em Cache Distribuído
Então, vamos realmente começar com isso. Então, antes de tudo, falaremos sobre relacionamentos um-para-um e muitos-para-um dentro do cache distribuído que é o cenário mais comum, certo? Portanto, uma opção é armazenar em cache os objetos relacionados com o objeto primário. Agora que você viu nossos objetos de domínio, temos uma lista de pedidos como parte dos clientes. Então, se nós preenchermos esses pedidos e o cliente tiver esses pedidos como parte dele, se você armazenar o cliente como um único objeto no cache que tem todos os pedidos como parte dele, certo? Então, isso faria o trabalho.
Objeto Relacionado ao Cache com Objeto Primário
Então, aqui está um exemplo de código para isso.
// cache order along with its OrderingCustomer and OrderedProduct
// but not the "Orders" collection in both of them
public void CacheOrder(Cache cache, Order order)
{
// We don't want to cache "Orders" from Customers and Product
order.OrderingCustomer.Orders = null;
order.OrderedProduct.Orders = null;
string orderKey = "Order:CustoimerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Temos um pedido de cache, definimos o cliente solicitante no pedido como “nulo”. Tudo bem! Então, que não temos um pedido também com referência ao cliente. É redundante. Esta não é uma prática de programação muito boa, mas isso é apenas para reforçar. Não queremos pedidos em cache do ID do cliente e do produto. Então, queremos apenas ter um cliente adicionado ao cache e, em seguida, gostaríamos de ter pedidos como parte disso.
Então, vamos dar uma olhada nisso, certo? Então, definimos isso como null e simplesmente armazenamos ou, se não definimos como null, isso pode realmente ter uma referência a isso. Da mesma forma, se tivermos um cliente, certo? então, se não definirmos o pedido como nulo, embora este seja um objeto separado, mas se simplesmente armazenarmos esse cliente, deixe-me levá-lo a isso, pois ele tem uma lista de pedidos, se simplesmente armazenarmos esse cliente como um único objeto no cache, ele tem nossa coleção de pedidos como parte desse objeto. Embora eu esteja definindo null para outro exemplo, mas apenas para mostrar esse caso em particular, você pode classificar um objeto grande e ele teria todos os objetos relacionados como parte desse objeto.
Portanto, você precisa começar a partir do seu objeto de domínio, deve ter seu relacionamento capturado como parte do objeto de domínio e deve fazer isso independentemente. E, depois disso, você deve armazenar em cache, deve ter uma lista preenchida de pedidos, lista de objetos relacionados como parte disso. Então, esta é a abordagem mais simples que você pode obter.
Existem alguns benefícios disso que você tem um objeto que está representando tudo. Mas, existem algumas desvantagens também. Seria um objeto maior em tamanho. Alguns casos, você só precisa do cliente, mas acaba recebendo pedidos como parte disso. Você estará lidando com uma carga maior. E você não tem pedidos granulares como itens separados no cache, então você teria que lidar com a coleta de pedidos o tempo todo, embora você esteja interessado em apenas um, certo? Então, essa é uma abordagem. Esse é o ponto de partida.
Cache de objetos relacionados separadamente
Segundo, você armazena em cache o objeto ponderado como um item separado no cache.
public void CacheOrder(Cache cache, Order order)
{
Customer cust = order.OrderingCustomer;
// Set orders to null so it doesn't get cached with Customer
cust.Orders = null;
string custKey = "Customer:CUstomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures order is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Um exemplo disso é a classe order onde temos a ordem de cache, certo? Então, este é o exemplo em que temos um cliente. Em primeiro lugar, certo? E então estamos armazenando o cliente como um único objeto, você pode ver que recebemos o pedido e, em seguida, do pedido, extraímos o cliente e definimos a coleção de pedidos dentro desse objeto do cliente como nula, certo? Então, isso é algo que você deve fazer dentro do construtor, mas isso está sendo feito aqui apenas para garantir que esse objeto cliente não tenha esse pedido como parte disso. E, então, você armazena esse cliente como um único objeto. O que estamos fazendo aqui é criar uma chave de cliente que é cliente, ID do cliente, o parâmetro de tempo de execução e, em seguida, estamos armazenando nosso cliente como um único objeto no cache.
A próxima coisa que estamos fazendo é criar uma dependência de cache. Então, falamos sobre duas etapas que queríamos fazer uma etapa era mapear seu modelo de dados em seu objeto de domínio, então seus objetos de domínio devem representar a tabela relacional no banco de dados e, uma vez que você planeja armazená-los em cache, você tem o objeto primário neste caso é o cliente e então temos pedidos que estão relacionados ao cliente na relação um-para-muitos. Você cria uma dependência entre o cliente e a coleção de pedidos com a ajuda de um objeto de dependência de cache. Você cria uma dependência de cache. Essa mesma dependência de cache recebe dois parâmetros; primeiro é arquivo, certo? Então, pode ser dependente do nome do arquivo e também pode ser dependente da chave, certo? Então, definimos o primeiro parâmetro como nulo. Portanto, não queremos que dependa de nenhum arquivo.
Há outro recurso que dentro NCache onde você pode tornar os itens dependentes de um determinado sistema de arquivos alguns arquivos em seu sistema de arquivos. E, se você usar a dependência baseada em chave, ela precisará da chave do item pai do qual o item filho será dependente. E, então, construímos a chave do pedido da coleção do pedido. Temos toda a coleção de pedidos aqui que é passada para este método e então simplesmente chamamos Cache.Add order.
Agora cliente e pedido estão relacionados um ao outro. Temos uma lista de pedidos deste cliente que são representados como um objeto separado no cache, então sempre que você precisar de todos os pedidos desse cliente em particular, basta usar essa chave. Tudo o que você precisa fazer é ligar, deixe-me usar este exemplo aqui. Eu sinto Muito! Você pode chamar Cache.Get e, em seguida, simplesmente passar a chave de pedido e isso buscaria esse pedido específico que construímos dentro desse método, certo?
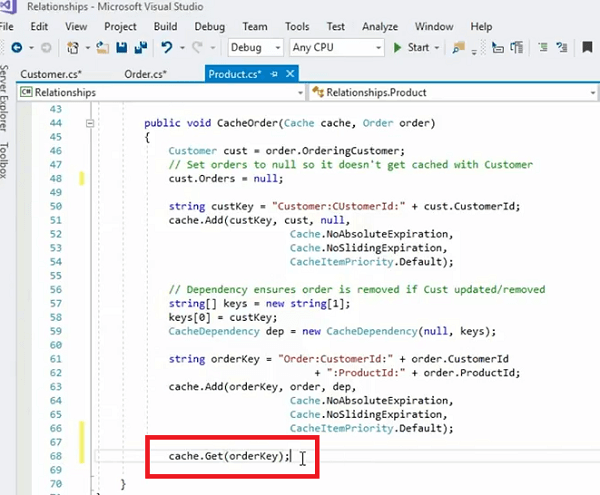
Então, é isso que você precisa para buscar toda a coleção de todos os pedidos desse cliente específico de uma só vez. Mas, e se o cliente passar por uma mudança? Se o cliente for atualizado a coleção de pedidos não precisa ficar no cache. Ele pode ser removido ou, em alguns casos, também pode ser atualizado, certo?
Então, essa é a nossa abordagem número dois que é mais sofisticada em termos de armazenamento, em termos de usabilidade e também mapeia dois registros em nossa relação de um para muitos ou muitos para um. Também poderia ser de outra forma, que abordaremos um pouco, onde você pode ter listas de pedidos e cada pedido pode ser mapeado para esses pedidos individuais pode ser mapeado para esses vários pedidos de ID pode ser mapeado para um cliente se o pedido é o objeto principal para esse código de aplicativo específico. Agora, isso define um relacionamento entre cliente e pedidos.
Mais alguns detalhes sobre o recurso de dependência de cache.
Se eu for aqui, em primeiro lugar, exposto, mas com a ajuda de Alachisoft.NCache.Runtime.Dependencies e essa é uma das sobrecargas que você usa e então você simplesmente usa esse método específico, aqui mesmo. E, o comportamento disso é de tal forma que permite que você simplesmente rastreie a dependência unidirecional entre objetos e também pode ser cascata conforme discutido anteriormente na apresentação.
Relacionamento Um para Muitos
A seguir, falaremos sobre relacionamentos um-para-muitos. Como falamos de um para um ou muitos para um onde tínhamos pedido e depois tínhamos um cliente, isso é semelhante a um para muitos na maioria dos casos, mas como o ponto de partida era o pedido e depois inserimos o cliente, armazenamos o cliente e depois armazenamos a coleção de pedidos e então definimos uma relação muitos-para-um entre a coleção de pedidos e esse cliente.

Agora, relacionamento um-para-muitos, será muito semelhante ao que discutimos. Nossa primeira opção é que você armazene em cache sua coleção de objetos como parte do objeto principal, de modo que o cliente seja seu objeto principal, o pedido deve fazer parte disso.
O segundo item é que seus objetos relacionados são armazenados em cache separadamente, mas itens individuais no cache, certo?
Um para muitos – Coleção de objetos relacionados ao cache separadamentepublic void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Então, esta é uma coleção que é separada, temos pedidos, temos um objeto de cliente aqui um para muitos e o cliente tem pedidos, tiramos a coleção de pedidos e, em seguida, definiremos os pedidos do cliente como nulos, para que o cliente seja um e objeto, um objeto primário, a coleção de pedidos é um objeto separado e então você armazena o cliente, armazena a dependência de cache de dados e armazena os pedidos. Então, vai ser um-para-muitos toda a coleção.
Um para muitos – Cache de cada objeto na coleção relacionada separadamenteA segunda abordagem é que essa coleção também pode ser dividida.
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
// Let's cache each order as seperate item but assign it
// a group so we can fetch all orders for a given customer
foreach (Order order in orders)
{
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
CacheItem cacheItem = new CacheItem(order);
cacheItem.Group = "Customer:CustomerId:" + cust.CustomerId;
cacheItem.Dependency = dep;
cache.Add(orderKey, cacheItem);
}
}A coleção de pedidos pode ser separada, cada item dessa coleção pode ser um item separado no cache. Então, neste caso, usaríamos apenas a mesma abordagem. Obteremos os clientes, obteremos os pedidos, armazenaremos o cliente, criaremos uma dependência desse cliente usando a dependência de chave e, em seguida, percorreremos todos os pedidos.
Deixe-me passar pelo método do cliente de cache aqui porque é mais intuitivo aqui. Então, tiramos a coleção de pedidos dele, definimos os pedidos do cliente como nulos para que os clientes sejam apenas sobre o cliente, armazenamos o cliente no cache usando cache. Adicionar chave, construímos uma dependência de cache em torno de uma chave específica do cliente e então nós simplesmente iteramos. Há um loop por aqui. Devemos realmente iterar por ele e isso é realmente melhor iterarmos por ele e então simplesmente armazenamos de uma só vez como itens individuais no cache para que o pedido tenha sua própria chave em cada pedido seja um item separado no cache. E, então, outra coisa que fizemos foi agrupar esses itens, que chamamos de itens de cache, adicionar grupo e o ID do cliente também é um grupo. Então, na verdade estamos gerenciando uma coleção dentro do cache também.
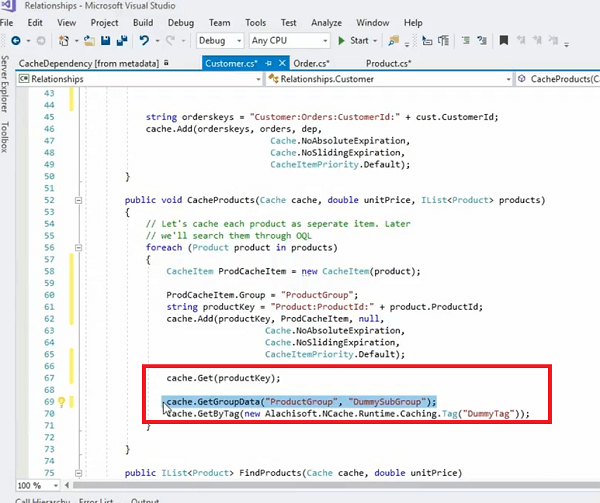
Deixe-me ver se eu tenho.. lá vai você na verdade, por exemplo, nós temos isso aqui. Na verdade, poderíamos armazenar em cache esses produtos, a propósito, esse é outro exemplo, onde percorremos toda a coleção de produtos e os armazenamos individualmente e, na verdade, colocamos tudo em um grupo, certo?
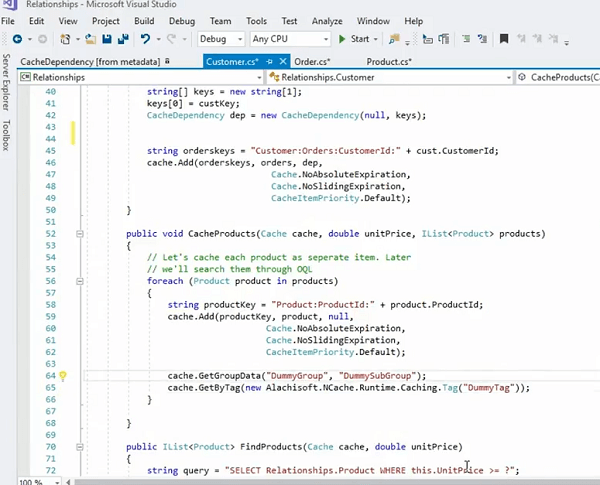
Então, este produto que está sendo armazenado como um item também pode ser armazenado assim onde temos um ProdCacheItem. Meu teclado está tocando, então, por favor, tenha paciência comigo! Vamos usar isso por enquanto e então eu vou fazer de forma simples. Eu posso realmente adicionar um grupo. Então, isso é o que realmente me permitiria definir um grupo para isso. Vamos dizer grupo fictício agora. Se eu armazenar esse item de cache e ele realmente puder ter um produto como item para isso, certo? Então, em vez de armazenar o objeto bruto real, posso até organizá-lo em um grupo. Eu posso simplesmente usar o item de cache do produto. Ai está! Direita? Então, agora está realmente sendo ou em vez de usar o grupo fictício, digamos grupo de produtos certo e quando eu precisar buscar isso eu posso simplesmente usar o grupo de produtos e ele buscaria todos os itens desta coleção de uma só vez. Embora estes estejam sendo armazenados individualmente, estes são Cache.Get individuais. Chamadas de produtos individuais dentro da coleção de produtos são classificados individualmente, mas posso organizá-los em um grupo em uma coleção e depois buscá-los. Mas o legal disso é que ainda está usando uma dependência, certo? Então, está usando uma dependência de um cliente nesses itens individuais.
Então, vamos dar um exemplo, temos um cliente que tem cem pedidos. Então, no total, teríamos um item por cliente no cache, teríamos cem pedidos armazenados separadamente como cem itens no cache e haveria uma dependência unidirecional entre esse cliente e cem pedidos. Se você remover esse cliente do cache, cem pedidos serão invalidados de uma só vez. E agora você tem o benefício de buscar pedidos individuais, se precisar. Assim, você pode interagir com esses itens individualmente. Um item de cada vez. Você precisa de um determinado pedido, pode processá-lo e, quando precisar de toda a coleção desses pedidos de uma só vez, basta chamar Cache.GetGroupData e fornecer o grupo de produtos e, em seguida, o subgrupo pode ser qualquer coisa. Pode ser null mesmo e então você também pode usar a tag.
Por exemplo; a outra forma de gerenciar isso é você usar o item do produto e criar uma tag para ele, certo? E, então você .. há um .. sim! lá está e você pode fornecer uma tag que pode ser algo como a tag do produto, certo? e então você pode associar isso como parte daquilo.
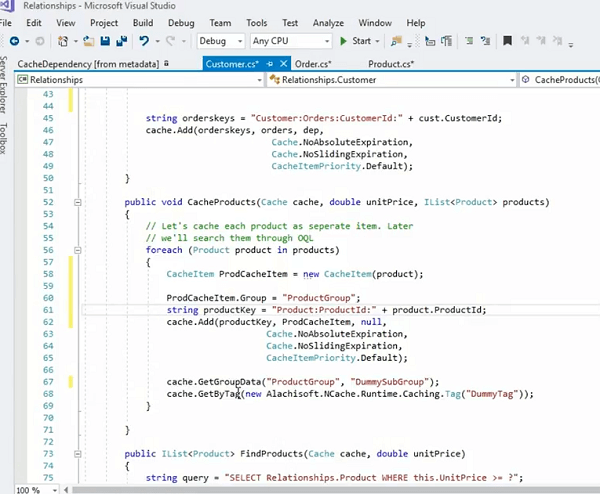
Então, isso realmente funcionaria nas mesmas linhas e você também pode chamar métodos get by tag e isso cuidaria de todos os itens de uma só vez. Traria todos os itens de uma vez. Portanto, isso lhe daria mais controle sobre o arranjo de dados no cache e ainda manteria um relacionamento um-para-muitos intacto.
Então, isso cuida de um cenário muito particular onde temos um relacionamento um-para-muitos e temos um objeto adicionado e, em seguida, temos esses itens do lado de muitos que a coleção armazena individualmente os itens dessa coleção armazenados individualmente no cache e, em seguida, você ainda tem uma dependência e ainda tem um tipo de comportamento de coleção para isso com esses itens relacionados. Então, esses itens estão relacionados uns com os outros, eles estão formando uma coleção e então eles têm nossa relação com outro objeto em uma Formulação um-para-muitos. Então, esse trecho de código, uma API intuitiva muito simples, cuida de todos esses cenários. Você tem um relacionamento um-para-muitos capturado com a ajuda da dependência de chave. Você organizou esses itens individualmente no cache, mas ainda os colocou em uma coleção lógica de grupos ou tags e, quando precisar desses itens individualmente, você chama cache start get, certo?
Então, uma forma de conseguir esse item é chamar Cache.Get, certo? e use a chave que é a chave do produto aqui, certo? Então, isso buscaria esse produto específico que está sendo armazenado com essa chave específica, certo? E a outra opção é que você precisa de todos os itens dessa coleção de uma só vez para poder usar Cache.GetGroupData. Assim, ele pode fornecer um comportamento de cobrança e, ao mesmo tempo, também pode fornecer a você o gerenciamento individual desses itens relacionados.
Então, isso deve cuidar de coleções e itens dentro da coleção e de um para muitos de uma só vez.
Relacionamentos muitos-para-muitos
Em seguida, temos um relacionamento muitos-para-muitos.

Relacionamentos muitos para muitos não existem normalmente nos objetos de domínio. Ele sempre será normalizado em dois relacionamentos um-para-muitos no banco de dados também. Na verdade, tínhamos um relacionamento de muitos para muitos entre cliente e produtos. Relacionamentos muitos-para-muitos que normalizamos com a ajuda de um objeto intermediário em dois relacionamentos um-para-muitos. Então, temos um para muitos aqui e muitos para um aqui entre pedido do cliente e pedido para produto, respectivamente. Então, é assim que você lidaria com muitos-para-muitos. Então, acabaria usando relacionamentos um-para-um-muitos-um ou um-para-muitos.
Portanto, isso deve cuidar de seus relacionamentos muitos-para-muitos.
Manipulando Coleções em Cache Distribuído
Em seguida, você tinha uma coleção, já abordamos isso com a ajuda de nosso exemplo de produto, mas ainda vou analisar isso que você armazena em nossa coleção como um item.

Por exemplo, você armazena o produto. Vamos passar por isso, certo?
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// cache the entire collection as one item
string productskey = "Product:UnitPrice:" + unitPrice;
cache.Add(productskey, products, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string productskey = "Product:UnitPrice:" + unitPrice;
IList<Product> products = (IList<Product>)cache.Get(productskey);
return products;
}Então, você tem produtos de cache, então você cria uma chave de produto e então você tem uma lista de produtos que está sendo trazido aqui e então você os armazena em cache e tem um único objeto. E, como expliquei anteriormente, vai funcionar, basta fazer o trabalho e funcionará principalmente quando você precisar de todos os itens dessa lista de uma só vez. Você não está interessado em itens individuais dessa lista. Você está interessado na lista inteira da loja inteira como um item, mas isso tornará o objeto mais pesado, não lhe daria suporte de codificação, pesquisa e esse é o nosso próximo tópico. Porque é uma lista genérica, eu listo, tem um produto lá mas para NCache isso é apenas uma lista, eu listo. Direita! Portanto, você não consegue identificar o objeto dentro dessa lista e, em seguida, os atributos e, em seguida, não tem a capacidade de pesquisar com base nesses atributos.
Portanto, uma maneira mais sofisticada de lidar com isso é armazenar em cache cada item da coleção separadamente. Isso abordamos como parte de nosso exemplo anterior, mas vamos analisá-lo mais uma vez. Por exemplo; vamos passar pelos produtos de cache mais uma vez e você simplesmente os armazena como itens individuais. Deixe-me encontrar este exemplo para você! OK! Aí está.
Então, em primeiro lugar, vamos armazenar os produtos individualmente, certo? Teremos uma chave construída em torno disso para produtos individuais. O legal disso é que todos os itens individuais da coleção de produtos são armazenados como itens individuais no cache para que você possa buscá-los usando a chave que é a sobrecarga para isso, o método para esse Cache.Get. Você também pode buscá-los como uma coleção. Isso é algo que discutimos em grandes detalhes. Uma outra opção é que você também execute consultas e essas consultas de pesquisa do tipo SQL podem ser aplicadas diretamente nos atributos dos objetos. E, você só pode fazer isso se os tiver armazenado individualmente, todos os itens da coleção são armazenados como itens individuais. Você os mapeia para um objeto de domínio, produto neste caso, e os produtos dentro de uma coleção de produtos são armazenados individualmente como itens separados no cache.
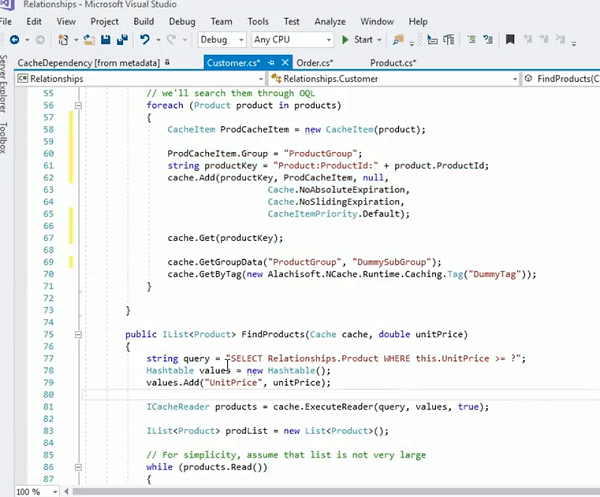
Agora você pode indexar o preço unitário do produto, ID do produto e, em seguida, pode executar uma consulta como esta. Selecione o produto, que é o namespace do produto, onde define o preço unitário igual a um parâmetro de tempo de execução. E, então, você pode chamar Cache.ExecuteReader e isso buscaria todos os produtos pelos quais você pode iterar e continuar buscando em seu aplicativo também. Da mesma forma, você também pode dizer onde This.Tag. Se você tiver associado uma tag em cima dela, também poderá executar consultas sobre ela. Esse é outro benefício das tags, juntamente com os benefícios de recuperação, benefícios de desempenho, e também oferece flexibilidade do ponto de vista da pesquisa. E, as tags também fornecem Cache.Get por uma tag. Ele fornece todas as APIs, obtém por todas as tags, obtém por qualquer tag, para que você possa buscar objetos usando essas APIs de tags também. Mas, o recurso que eu queria destacar é que você os organiza individualmente. Esse é o ponto de partida. Você cria coleções lógicas usando Tag ou Grupos. Assim, a recuperação é mais fácil. Você precisa de itens individuais que você chama de Cache.Get. Obtenha os itens com base na chave. Você precisa de coleções, use o grupo ou a tag apareça e em cima disso você pode executar consultas e associar, você pode realmente buscar nossos itens com base em um critério.
Neste caso pode ser o preço unitário. Pode ser preço unitário maior que 10 e menor que cem. Portanto, os operadores lógicos são suportados, você também pode ter alguma agregação, contagem, soma, há alguma ordem de classificação por um grupo por operador semelhante em operação, por isso é bastante interessante extensivo no que diz respeito ao suporte, é semelhante ao SQL é um subconjunto de Consultas SQL, mas é muito flexível no uso e oferece muita facilidade de uso em termos de quais itens você precisa. Você não precisa mais trabalhar com chaves. Então, isso só aconteceria se você simplesmente usar cada item da coleção armazenado separadamente no cache. Espero que isso ajude.
Começando com NCache
Isso completa o nosso tópico de hoje. No final, mostrarei cinco etapas simples para começar a usar NCache apenas passar por cima NCache configurações e, em seguida, ser capaz de executar essas APIs em um aplicativo da vida real.
Ok! Então, eu vou começar rapidamente com isso. Eu tenho a ferramenta de gerenciamento aberta. A propósito, nós lançamos recentemente, na verdade acabamos de lançar o 4.9. Então, essa é a nossa versão mais recente, então você pode querer começar com isso. Então, tudo que você precisa fazer é criar um cache, pelo nome dele, escolher próximo, escolher uma topologia de cache, o cache de réplica de partição é o mais adequado, opção assíncrona para replicação e aqui você especifica os servidores que hospedarão esse cache. Eu tenho demo um e dois já instalados com NCache.
Então, o primeiro passo é baixar e instalar NCache. O segundo passo é criar um cache nomeado. Então, eu vou passar por isso, manter tudo padrão porque esse não é o principal escopo da discussão hoje. Vou apenas passar pelos valores padrão e tamanho do cache que está em cada servidor. Basta definir as configurações básicas e escolher concluir.
A etapa três é adicionar um nó cliente. Vou usar minha máquina. Veja se eu tenho acesso a isso, sim! Tudo bem! Então, essa é a minha máquina aqui. Eu adicionei isso para que a etapa três esteja concluída. Todas as configurações no servidor e no cliente estão completas. Agora preciso iniciar e testar esse cluster de cache como parte da minha etapa 4 e, em seguida, revisarei isso e o usarei no aplicativo real. Então, é assim que é simples começar com NCache.
Mostrarei alguns contadores rápidos para mostrar as coisas em ação e, em seguida, concluiremos rapidamente a apresentação também. Clico com o botão direito do mouse e escolho estatísticas que abririam contadores de desempenho e também posso abrir ferramentas de monitoramento que são NCache monitor, vem instalado com NCache.
Portanto, é acionado por contador de desempenho. Ele fornece contadores de desempenho do lado do servidor e o lado do cliente também executa contadores. E, no lado do aplicativo cliente, posso executar este aplicativo de ferramenta de teste de estresse que novamente vem instalado com NCache. Leva o nome, pois há configurações feitas para que ele se conecte automaticamente ao cache e comece a simular a carga no meu cluster de cache. Ai está! Portanto, temos carga de solicitação chegando aqui e no outro servidor.
Da mesma forma, temos atividade sendo mostrada neste servidor, bem como clientes conectados ao servidor e cliente do visualizador de relatórios. E então você também pode ter seus próprios painéis personalizados onde você pode conectar qualquer um desses contadores. Por exemplo, os logs da API são um bom exemplo. Ele registra todas as requisições que estão sendo executadas no cache agora em tempo real, certo?
Então, esse é um exemplo rápido de usar esses contadores da esquerda principal. Como eu disse, isso é apenas para você ter uma ideia de como é o armazenamento em cache. Agora eu posso realmente usar isso em um aplicativo da vida real. Eu posso usar minha máquina aqui e posso simplesmente usar uma amostra de operação básica que vem instalada com NCache. Tudo que você precisa fazer é que existem diferentes pastas de agulhas dentro de exemplos de operações básicas do .NET, tanto quanto usar NCache bibliotecas do lado do cliente que você pode usar NCache Pacote SDK NuGet. Essa é a maneira mais fácil de obter todos os recursos do lado do cliente.
A outra opção é que você realmente usa Alachisoft.NCache.Tempo de execução e Alachisoft.NCache.Bibliotecas da Web você mesmo. Você inclui aqueles. Isso é algo que essas são as bibliotecas que começam com NCache nas pastas do Cache da Microsoft. Assim que instalar NCache seria parte disso e, depois disso, mostrarei rapidamente o que você precisa fazer. Ai está! Então, a primeira coisa que você precisa é adicionar referências a essas duas bibliotecas; runtime e web, inclua esses namespaces que acabei de destacar. Web.caching e, a partir desse ponto, este exemplo é muito bom o suficiente para inicializar o cache conectando-se a ele, criando um objeto lendo-o, excluindo-o e atualizando-o todo o tipo de operações de criação, leitura, atualização e exclusão.
Então, é assim que você inicializa o cache. Esta é a chamada principal, certo? Ele precisa que o nome do cache retorne um identificador de cache e, em seguida, basta chamar o cache ou adicionar armazenar tudo em um par de valores-chave Cache.Get items e, em seguida, atualizar o cache ou inserir itens e, em seguida, você Cache.delete. E já mostramos alguns exemplos detalhados do uso de dependência baseada em chave usando tags usando grupos usando SQL como pesquisa. Portanto, isso deve fornecer alguns detalhes sobre a configuração do ambiente e, em seguida, poder usá-lo em um aplicativo real.
Isso conclui nossa apresentação.