Seis motivos NCache é melhor que Redis
Webinar gravado
Por Iqbal Khan
Saiba como Redis e NCache comparar uns com os outros no nível do recurso. O objetivo deste webinar é tornar sua tarefa de comparar os dois produtos mais fácil e rápida.
O webinar abrange o seguinte:
- Diferentes áreas funcionais do produto.
- Que suporte faz Redis e NCache fornecer em cada área de recurso?
- Quais são os pontos fortes NCache Acima de Redis e vice versa?
NCache é um popular cache distribuído na memória de código aberto (Licença Apache 2.0) para .NET. NCache é comumente usado para armazenamento em cache de dados de aplicativos, armazenamento de estado de sessão ASP.NET e compartilhamento de dados de tempo de execução no estilo pub/sub por meio de eventos.
Redis é também um popular armazenamento de estrutura de dados em memória de código aberto (licença BSD) usado como banco de dados, cache e corretor de mensagens. Redis é muito popular no Linux, mas recentemente recebeu atenção no Azure devido à promoção da Microsoft.
Visão geral
Olá a todos, meu nome é Iqbal Khan e sou evangelista de tecnologia na Alachisoft. Alachisoft é uma empresa de software com sede na área da baía de São Francisco e fabricante do popular NCache produto, que é um cache distribuído de código aberto para .NET. Alachisoft também é o fabricante de NosDB, que é um banco de dados sem SQL de código aberto para .NET. Hoje, vou falar sobre seis razões pelas quais NCache é melhor do que Redis para aplicativos .NET. Redis, como você sabe, é desenvolvido por Redis labs e foi escolhido pela Microsoft para o Azure. A principal razão para a escolha foi que Redis oferece suporte multiplataforma e muitos idiomas diferentes, enquanto NCache é puramente focado em .NET. Então vamos começar.
Cache Distribuído
Antes de entrar nas comparações, deixe-me dar uma breve introdução sobre o que é o cache distribuído e por que você precisa dele e qual problema ele resolve. O cache distribuído é realmente usado para ajudar a melhorar a escalabilidade de seus aplicativos. Como você sabe, se você tiver um aplicativo da Web ou um aplicativo de serviços da Web ou qualquer aplicativo de servidor, poderá adicionar mais servidores na camada do aplicativo. Normalmente, as arquiteturas de aplicativos permitem que isso seja feito com muita facilidade. Mas você não pode fazer o mesmo na camada de banco de dados, especialmente se estiver usando um banco de dados relacional ou dados de mainframe legados. Você pode fazer isso sem SQL. Mas você sabe, na maioria dos casos, você precisa usar bancos de dados relacionais por motivos técnicos e comerciais.
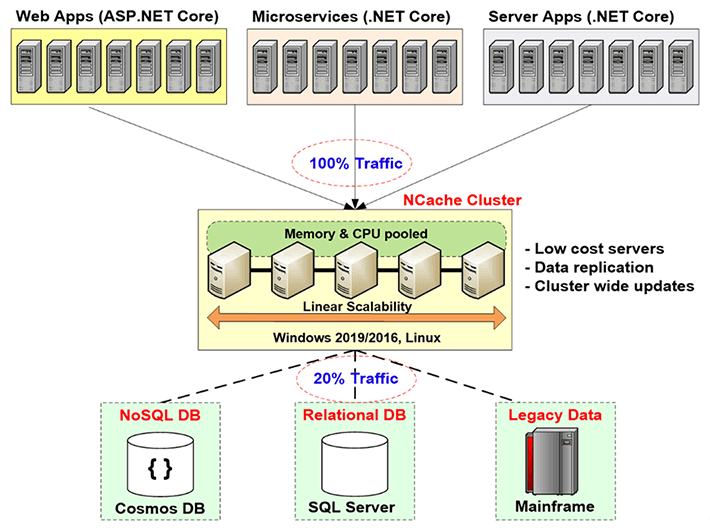
Portanto, você precisa resolver esse gargalo de escalabilidade que os bancos de dados relacionais ou o mainframe legado fornecem por meio do armazenamento em cache distribuído, e a maneira de fazer isso é criando uma camada de armazenamento em cache entre a camada do aplicativo e o banco de dados. Essa camada de cache consiste em dois ou mais servidores. Geralmente são servidores de baixo custo. No caso de NCache, a configuração típica é uma máquina dual CPU, quad-core, com 16 a 32 Gig de RAM e uma a duas placas de rede, que são de 1 a 10 gigabits de velocidade. Esses servidores de cache formam um cluster baseado em TCP em caso de NCache e agrupar os recursos de todos esses servidores em uma capacidade lógica. Dessa forma, à medida que você cresce, a camada de aplicativo, digamos, se você tiver mais e mais tráfego ou mais e mais carga de transação, poderá adicionar mais servidores na camada de aplicativo. Você também pode adicionar mais servidores na camada de cache. Normalmente, você mantém uma proporção de 4 para 1 ou 5 para 1 entre a camada de aplicativo e a camada de armazenamento em cache.
Portanto, por causa disso, o cache distribuído nunca se torna um gargalo. Assim, você pode começar a armazenar em cache os dados do aplicativo aqui e reduzir o tráfego para o banco de dados. O objetivo é que cerca de 80% do seu tráfego vá para o cache e cerca de 20% do tráfego, que geralmente são suas atualizações, vá para o banco de dados. E se você fizer isso, seu aplicativo nunca enfrentará um gargalo de escalabilidade.
Usos comuns do cache distribuído
Ok, mantendo esse benefício de um cache distribuído em mente, vamos falar sobre os diferentes casos de uso que você conhece, as diferentes situações em que você pode usar um cache distribuído.
Cache de dados do aplicativo
O número um é o Application Data Caching, que é o mesmo que acabei de explicar onde você armazena em cache os dados que residem em seu banco de dados, para que você possa melhorar o desempenho e a escalabilidade. A principal coisa a ter em mente para um cache de dados de aplicativo é que seus dados agora existem em dois lugares. Ele existe em seu banco de dados que é a fonte de dados mestre e existe também na camada de cache e quando isso acontece, a coisa mais importante que você precisa ter em mente é que, você sabe, a maior preocupação que vem é, você sabe , o cache ficará obsoleto? O cache terá uma versão mais antiga dos dados, mesmo que os dados tenham sido alterados no banco de dados. Se essa situação ocorrer, é claro que você tem um grande problema, e muitas pessoas por causa desse medo de problemas de integridade de dados, eles armazenam apenas dados somente leitura em cache. Bem, os dados somente leitura são um subconjunto muito pequeno do total de dados que você deve armazenar em cache e são cerca de dez a quinze por cento dos dados.
O benefício real está se você puder começar a armazenar em cache os dados transacionais. Estes são seus clientes, suas atividades, seu histórico, você sabe, todos os tipos de dados que são criados em tempo de execução e mudam com muita frequência, você ainda precisa armazenar em cache esses dados, mas precisa armazená-los de forma que o cache sempre permanece fresco. Então, esse é o primeiro caso de uso, e voltaremos a isso.
Cache específico do ASP.NET
O segundo caso de uso é para cache específico do ASP.NET, onde você armazena em cache o estado da sessão, o estado de exibição e se você não tiver a estrutura MVC e uma saída de página. Nesta situação, você está armazenando em cache o estado da sessão porque um cache é um armazenamento muito mais rápido e escalável do que seu banco de dados, que é onde você estaria armazenando em cache essas sessões ou as outras opções que a Microsoft oferece e, nesse caso, os dados são transitório. Transitório significa que é de natureza temporária. Ele é necessário apenas por um pequeno período de tempo, após o qual você o joga fora e os dados só existem no cache. O cache é o armazenamento mestre. Portanto, neste caso de uso, a preocupação não é que o cache precise ser sincronizado com o banco de dados, mas a preocupação é que, se algum servidor de cache cair, você perderá alguns dos dados. Porque tudo é armazenamento na memória e a memória, como você sabe, é volátil. Portanto, um bom cache distribuído deve fornecer estratégias de replicação inteligentes. Então, que você tenha todos os dados existentes em mais de um servidor. Se algum servidor ficar inativo, você não perderá nenhum dado, mas a replicação terá custo associado, custo de desempenho. Então, a replicação deve ser super rápida, que é o que NCache faz, aliás.
Compartilhamento de dados em tempo de execução
O terceiro caso de uso é o caso de uso Runtime Data Sharing, em que você usa o cache essencialmente como uma plataforma de compartilhamento de dados. Assim, muitos aplicativos diferentes estão conectados ao cache e podem compartilhar dados em um modelo Pub/Sub. Assim, uma aplicação produz os dados, coloca no cache, dispara um evento e outras aplicações que registraram interesse nesse evento serão notificadas, para que possam ir e consumir esses dados. Então, há também outros eventos. Existem eventos baseados em chave, os eventos de nível de cache, há um recurso de consulta contínua que NCache tem. Portanto, existem várias maneiras de usar um cache distribuído, como NCache para compartilhar dados entre diferentes aplicativos. Também neste caso, embora os dados sejam criados a partir de dados no banco de dados, a forma em que estão sendo compartilhados pode existir apenas no cache. Portanto, você deve certificar-se de que o cache replica os dados. Portanto, a preocupação é a mesma do cache do ASP.NET. Então, esses são os três casos de uso que são comuns para um cache distribuído de uso. Por favor, lembre-se desses casos de uso enquanto comparo os recursos que NCache fornece quais Redis não.
Razão 1 – Mantendo o Cache Fresco
Então, a primeira razão pela qual você deve usar NCache Acima de Redis é aquele, NCache fornece recursos muito poderosos para manter o cache atualizado. Como falamos sobre isso, se você não puder manter o cache atualizado, será forçado a armazenar em cache os dados somente leitura e, se seus dados forem somente leitura, você sabe, esse não é o benefício real. Então, você precisa ser capaz de armazenar em cache praticamente todos os seus dados. Mesmo dados que mudam a cada 10-15 segundos.
Expirações Absolutas / Expirações Deslizantes
Portanto, a primeira maneira de manter o cache atualizado é por meio das expirações. A expiração é algo que ambos NCache e Redis providenciar. Assim, por exemplo, há uma expiração absoluta em que você diz ao cache que expire esses dados após 10 minutos ou 2 minutos ou 1 minuto. Após esse tempo, o cache remove esses dados do cache e você está fazendo um palpite, você está dizendo, você sabe, acho que é seguro manter esses dados no cache por tanto tempo porque não acho que alteração no banco de dados. Então, com base nesse palpite, você está dizendo ao cache para expirar os dados.
Veja como a Expiração se parece. Eu só vou te mostrar uma coisa. No caso de NCache, ao instalar NCache a propósito, você sabe, dá-lhe um monte de amostras. Então, uma das amostras é chamada de operações básicas que eu abri aqui. Então, em operações básicas, deixe-me dar a você rapidamente, aqui está o que um aplicativo .NET típico usando NCache parece.
Você liga com NCache em tempo de execução NCache.Web assembly, então você usa o NCache.Tempo de execução espaço de nomes, NCache.Web.Caching namespace e, em seguida, no início de seu aplicativo, você se conecta ao cache. Todos os caches são nomeados.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Se quiser como criar uma cache, por favor veja o nosso vídeo de introdução. Que está disponível em nosso site. Mas, digamos que você se conectou a esse cache, portanto, você tem um identificador de cache. Agora você cria seus dados, que são alguns objetos e então você faz cache.Adicionar. cache.Adicionar tem uma chave que é uma string e o valor real que é seu objeto e então neste caso você está especificando uma expiração absoluta de um minuto. Então, você está dizendo expirar este objeto daqui a um minuto e dizendo que você está dizendo NCache para expirar este objeto. Então, é assim que funciona a expiração que, claro, como eu disse, Redis também lhe fornece.
Sincronizar Cache com Banco de Dados
Mas, o problema com a expiração é que você está fazendo um palpite que pode não estar correto, pode não ser preciso. Então, e se os dados mudarem antes daquele minuto antes dos cinco minutos que você especificou. Então, é aí que você precisa desse outro recurso chamado sincronizar o cache com o banco de dados. Esta é a característica que NCache tem e Redis não tem.
então, NCache faz isso de várias maneiras. O número primeiro é Dependência SQL. A dependência SQL é um recurso do SQL Server através do ADO.NET, onde você basicamente especifica uma instrução SQL e informa ao SQL Server e diz, você sabe, por favor, monitore este conjunto de dados e se este conjunto de dados mudar, significa que qualquer linha é adicionada , atualizado ou excluído que corresponda a este critério de conjunto de dados, por favor, notifique-me. Assim, o banco de dados envia uma notificação de banco de dados e você pode tomar as medidas apropriadas. Então, o caminho NCache isso é, NCache usará a dependência do SQL e também há uma dependência do Oracle que faz a mesma coisa com o Oracle. Ambos trabalham com eventos de banco de dados. Então, NCache usará a dependência SQL. Deixe-me mostrar-lhe esse código aqui. Então, vou apenas para o código de dependência SQL. Novamente, da mesma forma que você vincula com alguns dos assemblies. Você obtém o identificador de cache e agora que está adicionando coisas, vou para isso, vá para a definição. Então, agora que você está adicionando esses dados, como parte da adição, você especifica uma dependência SQL. Assim, a dependência de cache é um NCache classe que leva uma string de conexão para seu banco de dados. É preciso uma instrução SQL. Então, digamos, neste caso você está dizendo, eu quero que a instrução SQL seja onde o ID do produto é esse ID. Então, como você está armazenando em cache um objeto de produto, você o está combinando com a linha correspondente na tabela de produtos. Então, você está dizendo, você está dizendo NCache para falar com o SQL Server e usar a dependência do SQL para que o SQL Server possa monitorar essa instrução e se esses dados forem alterados, o SQL Server notificará NCache.
Então, agora o servidor de cache se tornou um cliente do seu banco de dados. Portanto, o servidor de cache pediu ao seu servidor SQL para me notificar se esse conjunto de dados for alterado e quando esse conjunto de dados for alterado O servidor SQL notificará o servidor de cache e o NCache server então remove aquele item do cache e a razão pela qual ele o remove é porque uma vez que ele seja removido na próxima vez que você precisar dele, você não o encontrará no cache e você será forçado a obtê-lo do banco de dados. Então, é assim que você o atualiza. Há outra maneira de recarregar automaticamente o item sobre o qual falarei em breve.
Assim, a dependência SQL permite NCache para realmente sincronizar o cache com o banco de dados e com a dependência do Oracle funciona exatamente da mesma maneira, exceto que funciona com o Oracle em vez do SQL server. A dependência do SQL é realmente poderosa, mas também faladora. Então, digamos, se você tiver 10,000 itens ou 100,000 itens, você criará 100,000 dependências SQL, o que coloca uma sobrecarga de desempenho no banco de dados do servidor SQL, porque para cada dependência do SQL o banco de dados do servidor SQL cria uma estrutura de dados e o servidor para monitorar esses dados e isso é uma sobrecarga extra.
Então, se você tiver muitos dados para sincronizar, talvez seja melhor apenas a dependência do banco de dados. Dependências de banco de dados é nosso próprio recurso onde, em vez de usar uma instrução SQL e eventos de banco de dados, NCache realmente puxa o banco de dados. Há uma tabela especial que você cria, chamada NCache DB sync e então você modifica seus gatilhos, então, você vai e atualiza um sinalizador em uma linha, correspondente a este item em cache e, em seguida, NCache puxa esta tabela de vez em quando, digamos, a cada 15 segundos ou mais por padrão e então você pode, você sabe, se encontrar alguma linha que foi alterada, invalida os itens em cache correspondentes do cache. Portanto, ambos e, claro, a dependência de banco de dados podem funcionar em qualquer banco de dados. Não é apenas o servidor SQL, Oracle, mas também se você tiver um DB2 ou MySQL ou outros bancos de dados.
Assim, a combinação desses recursos permite que você realmente se sinta confiante de que seu cache estará sempre sincronizado com o banco de dados e que você pode armazenar em cache praticamente qualquer dado. Há uma terceira maneira que é um procedimento armazenado CLR, para que você possa realmente implementar um procedimento armazenado CLR. A partir daí você pode fazer uma NCache ligar. Assim, você chama o procedimento armazenado do gatilho do banco de dados. Digamos que você tenha uma tabela de clientes e tenha um gatilho de atualização ou um gatilho de exclusão ou até mesmo um gatilho de adição. Em um caso de procedimento CLR, você também pode adicionar novos dados. Então, esse procedimento CLR é chamado pelo gatilho e o procedimento CLR faz NCache chamadas e dessa forma você está praticamente tendo o banco de dados adicionando os dados ou atualizando os dados de volta ao cache.
Então, essas três maneiras diferentes permitem NCache para ser sincronizado com o banco de dados e esta é uma razão realmente poderosa para usar NCache Acima de Redis Porque Redis força você a usar apenas expirações que não são suficientes. Isso realmente o torna vulnerável ou o força a armazenar em cache dados somente leitura.
Sincronizar Cache com Banco de Dados Não Relacional
Você também pode sincronizar o cache com banco de dados não relacional. Então, se você tem um banco de dados legado, mainframe, você pode ter uma dependência personalizada que é o seu código que roda no servidor de cache e de vez em quando NCache chama seu código para monitorar sua fonte de dados e talvez você possa fazer chamadas de método da Web ou fazer outras coisas para monitorar a fonte de dados personalizada e dessa forma você pode sincronizar o item em cache com alterações de dados nessa fonte de dados personalizada. Então, a sincronização do banco de dados é uma razão muito poderosa, porque você deve usar NCache Acima de Redis porque agora você armazena em cache praticamente todos os dados. Considerando que, no caso de Redis você será forçado a armazenar em cache dados que são somente leitura ou onde você pode fazer suposições com muita confiança sobre o vencimentos.
Razão 2 – Pesquisa SQL
Razão número dois, ok. Agora que você, digamos, começou a usar a sincronização com o recurso de banco de dados e agora pode armazenar em cache praticamente muitos dados. Portanto, quanto mais dados você armazenar em cache, mais o cache começará a se parecer com um banco de dados e, se você tiver apenas a opção de buscar dados com base em chaves, que é o que Redis então isso é muito limitante. Então, você precisa ser capaz de fazer outras coisas. Então, você precisa ser capaz de encontrar dados de forma inteligente. NCache oferece várias maneiras pelas quais você pode agrupar dados e localizar dados com base em atributos de objeto ou com base em grupos e subgrupos ou pode atribuir tags, tags de nome. Portanto, todas essas são maneiras diferentes de recuperar coleções de dados. Por exemplo, se você emitir uma consulta SQL, deixe-me mostrar isso, digamos, eu vou fazer uma consulta SQL aqui. Então, eu quero encontrar, digamos, todos os clientes onde customer.city é Nova York. Então, vou emitir um estado SQL, direi clientes selecionados, você sabe, meu namespace completo, cliente onde this.City é ponto de interrogação e no valor que vou especificar New York como um valor e quando eu emitir essa consulta, obterei de volta uma coleção desses objetos de cliente que correspondam a esse critério.
Então, isso agora está se parecendo muito com um banco de dados. Então, o que isso significa é que você pode realmente começar a armazenar dados em cache. Você pode armazenar em cache conjuntos de dados inteiros, especialmente tabelas de consulta ou outros dados de referência em que seu aplicativo foi usado para emitir consultas SQL em relação aos do banco de dados e ao mesmo tipo de consultas SQL que você pode emitir em relação NCache. A única limitação é que pode fazer junções em caso de NCache mas muitos desses você não precisa realmente fazer as articulações. Pesquisa SQL torna o cache muito amigável para realmente pesquisar e encontrar os dados que você está procurando.
Agrupamento e subagrupamento deixe-me mostrar-lhe este o exemplo de agrupamento. Então, por exemplo, aqui você pode adicionar vários objetos e pode adicionar todos eles. Então, você está adicionando-os como um grupo. Então, esta é a chave, o valor, aqui está o nome do grupo, aqui está o nome do subgrupo e depois você pode dizer me dê tudo o que pertence ao Grupo Eletrônico. Isso lhe dá uma coleção de volta e você pode iterar sobre a coleção para obter suas coisas.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}Você também pode buscar as chaves com base no grupo. Você pode fazer outras coisas com base no grupo também. Portanto, grupos e tags funcionam de maneira semelhante. Crachás também são iguais às tags, exceto que é um conceito de valor-chave. Então, digamos, se você está armazenando em cache o texto de forma livre e você realmente deseja obter alguns dos metadados do texto indexado, então você pode usar o conceito de valor-chave com as tags de nome e dessa forma, uma vez que todas as tags de grupos e tags de nome que você tiver então você pode incluí-los em consultas SQL.
Você também pode emitir consultas LINQ. Se você estiver mais confortável com o LINQ, poderá emitir consultas LINQ. Então, no caso do LINQ, por exemplo, digamos, aqui está o seu NCache. Então, você faria uma NCache consulta com um objeto de produto. Dá-lhe um IConsultável interface e, em seguida, você pode emitir uma consulta LINQ como faria em qualquer coleção de objetos e, na verdade, está pesquisando o cache.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}Então, quando você executa essa consulta, quando você executa essa consulta, na verdade ela está indo para a camada de cache e pesquisando seus objetos. Então, você sabe, a interface disponível para você é muito simples, de uma forma muito amigável, mas nos bastidores ela está realmente armazenando em cache ou pesquisando todo o cluster de cache. Então, a razão número dois é que você pode pesquisar o cache, você pode agrupar dados por meio de grupos e subgrupos, tags e tags nomeadas e isso torna possível encontrar dados de maneira amigável, o que é algo que nenhum desses recursos existe em Redis.
Indexação de dados é outro aspecto disso, que quando você vai pesquisar com base nesses atributos, então é imperativo, é muito importante que o cache indexe, crie índices nesses atributos. Caso contrário, é um processo extremamente lento para encontrar essas coisas. Então, NCache permite criar indexação de dados. Por exemplo, cada grupo e subgrupo, tags, tags de nome são indexados automaticamente, mas você também pode criar índices em seus objetos. Assim, você poderia, por exemplo, criar um índice em seu objeto de cliente no atributo cidade. Então, o atributo cidade porque você sabe que vai pesquisar no atributo cidade. Você diz, eu quero indexar esse atributo e dessa forma NCache irá indexá-lo.
Razão 3 - Código do lado do servidor
A razão número três é que com NCache você pode realmente escrever código do lado do servidor. Então, o que é esse código do lado do servidor e por que isso é tão importante. Vamos ver isso. É read-through, write-through, write-behind e cache loader. Então, Leia é essencialmente o seu código que você implementa e é executado no servidor de cache. Então, na verdade, deixe-me mostrar como é uma leitura. Assim, por exemplo, se você implementar um IReadThruProvider interface.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}Esta interface tem três métodos. Existe um método init que é chamado quando o cache é iniciado e sua finalidade é conectar seu manipulador de leitura à sua fonte de dados e há um método chamado descarte que é chamado quando o cache é interrompido e dessa forma você pode se desconectar de sua fonte de dados e há um método load from source, que passa a chave e espera uma saída de um item de cache, um objeto de item de cache do provedor. Então, agora você pode usar a chave para determinar qual objeto você precisa buscar em seu banco de dados. Então, a chave, como eu disse, poderia ser cliente, ID do cliente 1000. Então, ele informa que o tipo de objeto é cliente, a chave é ID do cliente e o valor é 1000. Então, se você usar formatos como esse, você pode, com base nisso, você pode ir em frente e criar seu código de acesso a dados.
Portanto, esse manipulador de leitura realmente é executado nos servidores de cache. Então, você realmente implanta esse código em todos os servidores de cache. No caso de NCache é bem sem costura. Você pode fazer isso através de um NCache ferramenta de gerenciamento. Assim, você implanta esse manipulador de leitura nos servidores de cache e esse manipulador de leitura é chamado pelo cache. Digamos que seu aplicativo faça o cache.Obter e esse item não está no cache. NCache chama seu manipulador de leitura. Seu manipulador de leitura vai para seu banco de dados, busca aquele item, devolve-o para NCache. NCache coloca-o no cache e, em seguida, devolve-o ao aplicativo. Portanto, o aplicativo parece que os dados estão sempre no cache. Portanto, mesmo que não esteja no cache, o cache agora tem a capacidade de obter os dados do seu banco de dados. Esse é o primeiro benefício da leitura.
O segundo benefício da leitura é quando as expirações acontecem. Digamos que você tenha uma expiração absoluta. Você disse expirar este item daqui a 5 minutos ou 2 horas a partir de agora, nesse momento, em vez de remover esse item do cache, você pode dizer NCache para recarregar esse item automaticamente chamando o manipulador de leitura. E recarregar significa que o item nunca é removido do cache. Só é atualizado e isso é realmente importante porque muitas das tabelas de consulta de referência, você tem muitas transações apenas lendo esses dados e se esses dados forem removidos mesmo por um breve período de tempo, muitas transações no banco de dados será criado para buscar esses dados, simultaneamente. Então, se você pudesse apenas atualizá-lo no cache, seria muito melhor. Então, esse é um caso de uso.
O segundo caso de uso é com sincronização de banco de dados. Então, quando a sincronização do banco de dados acontece e esse item está sendo removido, em vez de removê-lo, por que não recarregá-lo do banco de dados e é isso NCache vontade. Você pode configurar NCache, então, quando a sincronização do banco de dados for iniciada, o NCache em vez de remover esse item do cache, ele chamará seu manipulador de leitura para recarregar uma nova cópia dele. Novamente, da mesma forma que a expiração, esse item nunca é removido. Ele nunca é removido do cache. Portanto, a leitura é um recurso realmente poderoso.
Outro benefício do read-through é que ele simplifica seus aplicativos, porque você está movendo cada vez mais se persistir o código na camada de cache e se tiver vários aplicativos acessando os mesmos dados, tudo o que eles precisam fazer é fazer um cache.Obter. UMA cache.Obter é uma chamada muito simples, em seguida, fazer um tipo de codificação ADO.NET adequado.
Portanto, a leitura simplifica o código do aplicativo. Ele também garante que o cache sempre tenha os dados. Ele faz recarga automática em expirações e sincronizações de banco de dados.
O próximo recurso é o write-through. Write-through funciona exatamente como read-through, exceto que é para atualização. Deixe-me mostrar como é a escrita. Então, isso foi lido. Deixe-me apenas ir para escrever. Então, você implementa um manipulador write-through. Novamente, você tem um método init. Você tem um método de descarte, assim como a leitura, mas agora você tem um método de gravação em fonte de dados e um método de gravação em massa em fonte de dados. Então, isso é algo que é diferente de ler.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Então, no caso de write-through, você sabe, você pega o objeto e a operação também e essa operação pode ser um Add, pode ser um Update ou pode ser um Delete, certo. Porque você poderia fazer um cache.Adicionar, cache.Inserir, cache.Excluir, e tudo isso resultará em uma chamada de gravação. Isso agora pode ir e atualizar os dados no banco de dados.
Da mesma forma, se você fizer uma operação em massa, atualização em massa, uma atualização em massa no banco de dados também poderá ser feita. Portanto, a gravação também tem os mesmos benefícios da leitura, pois pode simplificar o aplicativo porque está movendo cada vez mais o código de persistência para a camada de armazenamento em cache.
Mas também há um recurso write-behind que é uma variação do write-through. Com o write-behind é basicamente, você atualiza o cache e o cache atualiza sua fonte de dados de forma assíncrona. Basicamente, ele atualiza mais tarde. Assim, seu aplicativo não precisa esperar.
Write-behind realmente acelera seu aplicativo. Porque, você sabe, as atualizações do banco de dados não são tão rápidas quanto as atualizações de cache. Então, você sabe, você pode usar um write-through com um recurso write-behind e o cache é atualizado imediatamente. Seu aplicativo volta e faz seu trabalho e, em seguida, o write-through é chamado de maneira write-behind e atualiza o banco de dados e, é claro, se a atualização do banco de dados falhar, o aplicativo será notificado.
Portanto, sempre que você criar uma fila, existe o risco de que, se esse servidor cair, essa fila seja perdida. Bem, em caso de NCache a fila write-behind também é replicada para mais de um servidor e, dessa forma, se algum servidor de cache ficar inativo, sua fila write-behind não será perdida. Então, é assim NCache garante alta disponibilidade. Portanto, write-through e write-behind são recursos muito poderosos. Eles simplificam o código do aplicativo e também no caso de write-behind eles aceleram o aplicativo porque você não precisa esperar que o banco de dados seja atualizado.
O terceiro recurso é o carregador de cache. Há muitos dados que você prefere pré-carregar no cache, para que seus aplicativos não precisem ir para o banco de dados. Se você não possui um recurso de carregador de cache, agora precisa escrever esse código. Bem, não apenas você precisa escrever esse código, mas também executá-lo em algum lugar como um processo. É a execução como um processo que realmente se torna mais complicado. Então, no caso de um cache loader, você apenas registra seu cache. Você implementa uma interface de carregador de cache, registra seu código com NCache, NCache chama seu código sempre que o cache é iniciado e dessa forma você pode garantir que o cache seja sempre pré-carregado com essa quantidade de dados.
Então, esses três recursos são: read-through, write-through, write-behind e cached loader, esses são recursos muito poderosos que apenas NCache tem. Redis não possui tais recursos. Então, em caso de Redis você perde toda essa capacidade que NCache prevê o contrário.
Razão 4 – Cache do Cliente (Perto do Cache)
A razão número quatro é Cache de cliente. O cache do cliente é um recurso muito poderoso. Na verdade, é um cache local que fica na caixa do servidor de aplicativos, mas não é um cache isolado. É local para seu aplicativo. Pode ser In-Proc. Portanto, esse cache do cliente pode ser objetos mantidos como em seu heap e em caso de NCache se você escolher a opção In-Proc que NCache mantém os dados e o formulário do objeto. Não de forma serializada, no cache do cliente. No cache clusterizado, ele o mantém em um formato serializado. Mas, no cache do cliente, ele o mantém em forma de objeto. Por quê? Portanto, toda vez que você o busca, não precisa desserializá-lo em um objeto. Então, ele acelera as buscas ou o obtém muito mais.
Um cache de cliente é um recurso muito poderoso. É um cache em cima de um cache. Portanto, uma das coisas que você perde quando passa de um cache In-Proc autônomo para um cache distribuído é que em um cache distribuído o cache mantém os dados em um processo separado, mesmo em um servidor separado e há um processo entre comunicação acontecendo, há uma serialização e desserialização acontecendo e isso diminui seu desempenho. Assim, em comparação com um cache de forma de objeto In-Proc, um cache distribuído é pelo menos dez vezes mais lento. Portanto, com um cache de cliente, você obtém o melhor dos dois mundos. Porque, se você não tiver o cache do cliente, se você tiver apenas um cache isolado autônomo, haverá muitos outros problemas sobre o tamanho do cache, e se esse processo ficar inativo? Então você perde o cache e como você mantém o cache sincronizado com as alterações em vários servidores. Todas essas questões são abordadas por NCache em seu cache de cliente.
Assim, você obtém o benefício desse cache In-Proc autônomo, mas está conectado ao cluster de armazenamento em cache. Portanto, o que for mantido nesse cache do cliente, também estará no cache do cluster e, se algum cliente o atualizar aqui, a camada de cache notificará o cache do cliente. Para que ele possa ir e se atualizar, imediatamente. Então, é assim que você garante ou fica seguro de que o cache do cliente sempre será sincronizado com a camada de cache, que é sincronizada com o banco de dados.
Então, no caso de NCache um cache de cliente é algo que se conecta sem qualquer programação extra. Você faz as chamadas de API como se estivesse falando com a camada de cache e o cache do cliente apenas se conecta a uma alteração de configuração e um cache do cliente oferece um desempenho 10 vezes mais rápido. Esta é uma característica que Redis não tem. Então, apesar de todas as alegações de desempenho que Redis tem, você sabe, eles são um produto rápido, mas também é NCache. Assim, NCache está frente a frente no desempenho com Redis sem o cache do cliente. Mas quando você ativa o cache do cliente, NCache é 10 vezes mais rápido. Então, esse é o benefício real de usar um cache de cliente. Então, esta é a razão número quatro para usar NCache Acima de Redis.
Razão 5 - Suporte a vários datacenters
A razão número cinco é que NCache fornece um suporte multi-datacenter. Você sabe, hoje em dia, se você tem um aplicativo de alto tráfego, as chances são muito altas de que você já esteja executando isso em vários datacenters para recuperação de desastres DR ou para dois datacenters ativos-ativos para balanceamento de carga ou combinação de DR e balanceamento de carga , você sabe, ou talvez seu balanceamento de carga geográfico. Então, você sabe, você pode ter um data center em Londres e Nova York ou conhecer Tóquio ou algo assim para atender ao tráfego regional. Sempre que você tem vários datacenters, você sabe, os bancos de dados fornecem replicação porque sem isso você não seria capaz de ter vários datacenters. Porque seus dados são os mesmos em vários datacenters. Se os dados não forem os mesmos, você sabe, é um separado, não há problema, mas em muitos casos os dados são os mesmos e não apenas isso, mas você deseja descarregar parte do tráfego de um datacenter para o outro de forma contínua. Então, se você tem o banco de dados replicando nos datacenters, por que não o cache? Redis não fornece nenhum desses recursos, NCache fornece recursos muito poderosos.
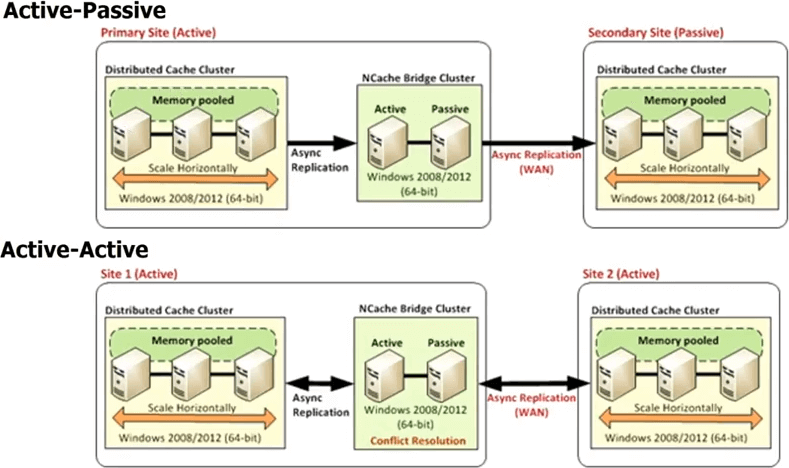
Então, no caso de NCache todos os datacenters terão seu próprio cluster de cache, mas há um topologia de ponte entre. Essa ponte basicamente conecta os clusters de cache em cada datacenter, para que você possa replicar de forma assíncrona. Então, você pode ter uma ponte ativa-passiva, onde isso é um datacenter ativo, isso é passivo. Você também pode ter uma ponte ativa-ativa e também estamos liberando mais de duas configurações de datacenter ativo-ativo ou ativo-passivo, onde você pode ter, digamos, três ou quatro datacenters e o cache será replicado para todos eles de forma ativa-ativa ou ativa-passiva. Em um ativo-ativo, porque as atualizações estão sendo feitas de forma assíncrona ou a replicação foi feita de forma assíncrona, existe a possibilidade de conflito de que o mesmo item foi atualizado em ambos os datacenters.
então, NCache fornece dois mecanismos diferentes para lidar com essa resolução de conflito. Um é chamado de vitórias na última atualização. Onde o último item foi atualizado, é aplicado a ambos os lugares. Então, digamos, você atualiza um item aqui, outro usuário atualiza o item aqui. Ambos agora para começar a propagar para o outro cache. Então, quando eles chegam à ponte, a ponte percebe que eles foram atualizados em ambos os lugares. Então, ele verifica o timestamp e qualquer timestamp que tenha sido o último, ele aplica essa atualização para o outro local e descarta a atualização que foi feita pelo outro local. Então, é assim que a última atualização ativa-ativa ganha a resolução de conflitos. Se isso não for suficiente para você, você poderá implementar um manipulador de resolução de conflitos. Esse é o seu código. Então, a bridge vai realmente em caso de conflito chamar seu código, passar as duas cópias dos objetos, então você pode fazer uma análise baseada em conteúdo e então com base nessa análise você pode determinar qual objeto é mais apropriado para ser atualizado, para ser aplicado a ambos os datacenters. A mesma regra se aplica se você tiver mais de dois datacenters.
Assim, um suporte a vários datacenters é um recurso muito poderoso NCache dá-lhe fora da caixa. Assim que você comprar NCache, está tudo lá, Redis não tem e se você planeja ter vários datacenters ou mesmo se deseja apenas ter flexibilidade, mesmo que não tenha vários datacenters hoje, mas deseja ter a flexibilidade de poder ir para vários datacenters, você comprar um banco de dados hoje que não suporta replicação? Você provavelmente não faria isso, mesmo se tivesse apenas um datacenter. Então, por que ir com o cache que não suporta a replicação da WAN. Então, este é um recurso muito poderoso de NCache.
Então, até agora falamos principalmente dos recursos que um bom cache distribuído deve ter. NCache, você sabe, brilha. Ele ganha de mãos dadas Redis. Redis é um cache simples muito básico.
Razão 6 – Plataforma e Tecnologia (para aplicativos .NET)
.NET e Windows vs Linux
A razão número seis é provavelmente uma das razões mais importantes para você, ou seja, plataforma e tecnologia. Se você tem um aplicativo .NET, você prefere ter a pilha .NET completa. Tenho certeza que você gostaria, você não gostaria de misturar .NET com Java ou Windows com Linux, na maioria dos casos. Em alguns casos, você sabe, você pode, mas na maioria dos casos as pessoas que estão desenvolvendo aplicativos .NET preferem usar a plataforma Windows e preferem que toda a pilha seja .NET, se possível. Nós vamos, Redis não é um produto .NET. É um produto baseado em Linux que foi desenvolvido em C/C++.

Deixe-me mostrar-lhe um pouco. Aqui está o Redis labs site que é a empresa que faz Redis. Se você for para a página de download, verá que eles nem oferecem uma opção do Windows. Portanto, apesar do fato de a Microsoft os ter escolhido para o Azure, eles não têm absolutamente nenhuma intenção de oferecer suporte ao Windows. Então, tanto quanto Redis Labs está preocupado, Redis é apenas para Linux. O grupo de tecnologia aberta da Microsoft portou Redis para o Windows. Portanto, existe uma versão para Windows do Redis acessível. É de código aberto e não é suportado, mas, você sabe, é problemático e instável e a prova está no pudim, mas a própria Microsoft não o usa no Azure. Então o Redis que você usa no Azure é, na verdade, um baseado em Linux Redis e não a base do Windows. Então, se você quiser incorporar Redis em sua pilha de aplicativos, você vai misturar óleo com água, você sabe. Considerando que, no caso de NCache tudo é .NET nativo. Você tem o Windows. Você tem 100% .NET. NCache foi desenvolvido em C Sustenido (C#). Ele é certificado para Windows Server 2012 R2 e toda vez que uma nova versão do sistema operacional chega, ele é certificado para isso. Você sabe, em breve estaremos lançando o ASP.NET Core Apoio, suporte. Então, temos um cliente .NET oficialmente. Também temos um cliente Java oficialmente. Então, eu acho que se você usar NCache e de novo NCache também é de código aberto. Então, se você não tem dinheiro, vá com a versão de código aberto do NCache. Mas, se o seu projeto for importante, vá com a versão Enterprise, que oferece mais recursos e oferece suporte a ambos. Mas, eu recomendo que você use NCache se você tiver um aplicativo .NET para a combinação .NET e Windows.
Suporte no local
O segundo benefício que NCache dá é, se você não está na nuvem, digamos, você não decidiu migrar para a nuvem, você está hospedando seu próprio aplicativo, então, é essencialmente no local. Então, está em seu próprio datacenter bem Redis que está disponível pela Microsoft está apenas no Azure. Então, qualquer coisa que esteja no local, então, há um Redis que está disponível no local por Redis Labs, mas isso é apenas Linux e o único local no Windows é o código aberto, aquele que vem sem suporte e aquele que é bugado e instável e aquele que é tão bugado que a própria Microsoft não o usa no Azure.

Considerando que, no caso de NCache você pode continuar a usar o código aberto que é gratuito, o que não é suportado, é claro, se você não tiver dinheiro. Mas, é tudo .NET nativo ou se você tem um projeto que é importante para o seu negócio então pelo Enterprise Edition que tem mais recursos e vem com suporte e é uma licença perpétua. É bastante acessível, você sabe, possuí-lo e também oferecemos suporte 24 horas por dia, 7 dias por semana, caso isso seja importante para você.
Portanto, é totalmente suportado em um local. A maioria dos nossos clientes que são clientes high-end ainda está usando NCache em uma situação no local. NCache está no mercado há mais de 10 anos. Então, é um produto realmente estável.
Suporte Cloud
No que diz respeito ao suporte à nuvem, Redis oferece um modelo de serviço na nuvem, que é a Microsoft implementou um Redis serviço. Nós vamos, Redis service significa que você não tem acesso aos servidores de cache. Você sabe, é uma caixa preta para você. Não há código do lado do servidor. Então, toda a leitura, escrita, escrita, o carregador de cache, a dependência personalizada e um monte de outras coisas, você não pode fazer com Redis. Você sabe, você só tem a API básica do cliente e, como eu disse, você sabe, no Azure, a Microsoft oferece a você o Redis como um serviço.
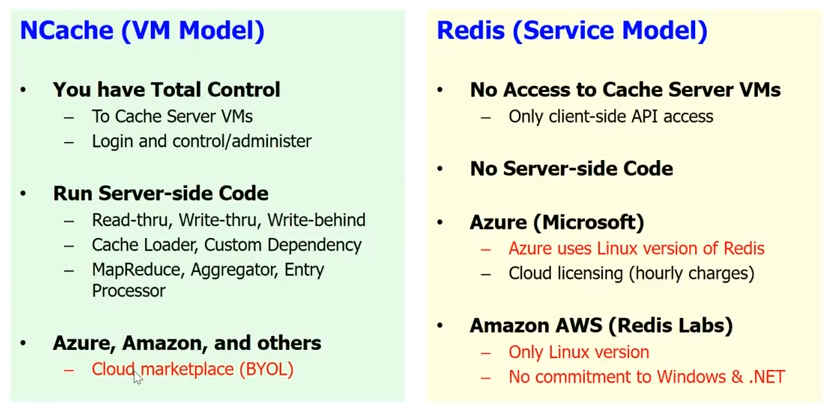
NCache, escolhemos intencionalmente um modelo de VM. Porque queremos que o cache fique próximo da sua aplicação e que você tenha total controle sobre o cache. Isso é muito importante porque temos muitos anos de experiência e sabemos que nossos clientes são muito sensíveis. Mesmo um pequeno, digamos, se você usar o Redis como um serviço e você tem que fazer um salto extra para chegar ao cache todas as vezes, isso acaba com todo o propósito de ter um cache. Considerando que, no caso de NCache você pode tê-lo como parte da VM. Você pode ter o cache do cliente. Ele está realmente embutido na implantação do seu aplicativo. Assim, você pode fazer todo o código do lado do servidor.
NCache também corre em Azul. Corre em Amazon AWS e também outros líderes plataformas na nuvem no modelo BYOL. Então, você basicamente obtém sua VM. Na verdade, você tem o NCache no mercado. Você recebe um NCache VM e você compra a licença de nós e começa a usar NCache.
Então, abordagens muito diferentes. Mas essa é a abordagem pretendida se seu aplicativo for realmente importante e você quiser controlar o aplicativo, todos os aspectos dele e não precisar depender de outra pessoa para gerenciar uma parte de sua infraestrutura no nível do aplicativo. Uma coisa é gerenciar VMs e o hardware por baixo, mas à medida que você começa a subir cada vez mais, perde esse controle e, claro, no caso de cache, no caso de NCache, não é apenas esse controle, mas também muitos recursos que você perderia se optasse pelo modelo de serviço.
Então, o motivo número 6 é a tecnologia da plataforma. Para aplicativos .NET, NCache é uma opção muito mais adequada do que Redis. eu não estou dizendo Redis é uma opção ruim, mas acho que para aplicativos .NET NCache é uma opção muito mais superior do que Redis.
NCache HISTÓRIA
Deixe-me apenas dar-lhe uma breve história de NCache. NCache existe desde meados de 2005. Então, esses são os 11 anos, você sabe, NCache está no mercado. É o cache .NET mais antigo do mercado. 2015 Janeiro, nos tornamos open source. Então, agora somos licença Apache 2.0. Nosso Enterprise Edition é construído em cima do nosso código aberto. Portanto, o código aberto é uma versão estável e confiável. Tem muitos recursos. Claro, o Enterprise tem mais recursos, mas o código aberto é um produto muito útil. O básico é que, se você não tem dinheiro, vá com o código aberto. Se o seu aplicativo de negócios for importante e você tiver orçamento, escolha a Enterprise Edition. Ele vem com suporte e também oferece mais recursos.
Nós temos centenas de clientes, praticamente em todos os setores possíveis que precisam de armazenamento em cache. Então, temos clientes do setor financeiro, temos Walmart, outro setor de varejo. Temos companhias aéreas, temos indústria de seguros, automóveis/automóveis, em todos os setores.
Então, esse é o fim da minha conversa. Por favor, vá em frente e baixe a Enterprise Edition do NCache. Deixe-me realmente levá-lo ao nosso site. Então, essencialmente, vá para o página de download e eu recomendo fortemente que você baixe a Enterprise Edition. Mesmo se você acabar usando a edição de código aberto, baixe a Enterprise Edition. É um teste de 30 dias totalmente funcional, que podemos facilmente estender e brincar com ele.
Se você quiser ir em frente e baixar o código aberto, vá em frente e baixe o código aberto. Você também pode acessar o GitHub e ver NCache no GitHub. Entre em contato conosco se você quiser que façamos como um demonstração personalizada. Talvez fale sobre sua arquitetura de aplicativo, responda suas perguntas. Muito obrigado por assistir a esta palestra.