Ein häufiger Albtraum unter Entwicklern und Softwarearchitekten ist der Absturz ihres einzigen Webservers bzw. ihrer einzigen Datenquelle, wodurch Tausende verbundener Clients, Anwendungen und wertvoller Daten verloren gehen. Mit Hilfe einer verteilten, lastausgeglichenen Caching-Schicht wie z NCache Sie können Ihre Anwendungsebene hochgradig skalierbar und verfügbar machen. Mit zunehmender Transaktionslast können Sie weitere Server hinzufügen. Die verteilte Architektur stellt sicher, dass es keinen Single Point of Failure gibt.
NCache ist ein In-Memory verteilt Datenspeicher, der optimale Leistung für Ihre Anwendungen bietet. Das NCache Cluster ist Selbstheilung und dynamisch. Es enthält Knoten, die die Last automatisch untereinander ohne Benutzereingriff bei jeder Cluster-Aktualisierung ausgleichen.
NCache Details NCache Docs Partitioniertes Replikat
Dieser Blog gibt Ihnen einen kurzen Überblick darüber, wie NCache bietet Skalierbarkeit und Leistung bei 100 % Verfügbarkeit. Für das Verständnis NCache Architektur im Detail, können Sie sich dieses Video ansehen:
Aufrechterhaltung der Hochverfügbarkeit in NCache Cluster
NCacheDie verteilte und replizierte Architektur von gewährleistet 100 % Betriebszeit auch wenn ein Knoten unerwartet ausfällt. NCacheDie Peer-to-Peer-Architektur von und die Laufzeiterkennung von Clustern und Clients ohne Benutzereingriff gewährleisten eine solch hohe Verfügbarkeit. Darüber hinaus, NCache bietet intelligente Failover-Unterstützung, sodass der Cluster immer für alle verbundenen Clients verfügbar bleibt.
Peer-to-Peer-Architektur
NCache bietet dynamisches Cache-Clustering mit Peer-to-Peer-Architektur wo es keinen Single Point of Failure gibt. Ein Cache-Cluster hat miteinander verbundene Server und enthält einen Koordinator (oberster Serverknoten), der die Mitgliedschaften im Cluster verwaltet. Wenn der Koordinator ausfällt, wird die Rolle an den nächstranghöchsten Server im Cluster weitergegeben. Es stellt sicher, dass es bei der Verwaltung der Cluster-Mitgliedschaft keinen Single Point of Failure gibt.
Laufzeiterkennung innerhalb von Cluster und Clients
Cluster:
Sobald ein Server startet, muss er mindestens einen anderen Server im Cluster kennen. Der Server enthält eine Liste mit mehreren Cache-Servern und versucht, sich mit jedem von ihnen zu verbinden. Sobald es eine Verbindung zu einem Server herstellt, fragt es diesen Server nach dem Cluster-Koordinator und fordert den Koordinator auf, ihn der Mitgliederliste des Clusters hinzuzufügen.
Der Koordinator fügt diesen neuen Server zur Laufzeit dem Cluster hinzu und informiert die anderen verbundenen Server, dass ein neuer Server dem Cluster beigetreten ist. Außerdem informiert er den neuen Server über alle Mitglieder des Clusters. Der neue Server baut dann eine TCP-Verbindung mit allen Servern im Cluster auf.
Client:
Sobald der Client eine Verbindung zu einem Cache-Server herstellt, erhält er zur Laufzeit die folgenden Informationen von diesem Server:
- Informationen zur Clustermitgliedschaft
- Caching von Topologieinformationen
- Karte der Datenverteilung
Der Client verwendet diese Informationen, um zu bestimmen, mit welchen Cache-Servern eine Verbindung hergestellt werden soll und wie auf den Cache basierend auf der Caching-Topologie zugegriffen werden soll.
Laufzeiterkennung innerhalb von Cluster und Clients
In NCache, erfolgt die Erkennung von Cluster und Client während der Laufzeit auf folgende Weise:
Cluster:
Da ein Cluster eine Sammlung von Knoten ist, muss ein Server nach dem Start mindestens einen anderen Server im Cluster kennen. Der Server enthält eine Liste mit mehreren Cache-Servern und versucht, sich mit jedem von ihnen zu verbinden. Sobald es sich mit einem Server verbindet, fragt es diesen Server nach dem Cluster-Koordinator und bittet den Koordinatorknoten, ihn der Mitgliederliste des Clusters hinzuzufügen.
Der Koordinator fügt diesen neuen Server zur Laufzeit dem Cluster hinzu und informiert die anderen verbundenen Server, dass ein neuer Server dem Cluster beigetreten ist. Es aktualisiert auch den neuen Server über alle Mitglieder des Clusters. Der neue Server baut dann a TCP-Verbindung mit allen Servern im Cluster.
Client:
Sobald der Client eine Verbindung zu einem Cache-Server herstellt, erhält er zur Laufzeit die folgenden Informationen von diesem Server:
- Informationen zur Clustermitgliedschaft
- Caching von Topologieinformationen
- Karte der Datenverteilung
Der Client verwendet diese Informationen, um zu bestimmen, mit welchen Cache-Servern eine Verbindung hergestellt werden soll und wie auf den Cache zugegriffen werden kann Caching-Topologie.
Failover-Unterstützung
Da die NCache Cluster ist selbstheilend und bietet Failover-Unterstützung innerhalb des Clusters und für die Clients, wenn ein Server zur Laufzeit hinzugefügt oder entfernt wird.
- Cluster-Failover-Unterstützung: Der Cluster ordnet sich automatisch neu an, indem er seine Verbindungen zu den anderen Servern bei jeder Clusteraktualisierung aktualisiert.
- Client-Failover-Unterstützung: Die Clients verbinden sich automatisch mit einem anderen Server im Cluster, wenn die Serververbindung getrennt wird. Wenn ein Server hinzugefügt wird, aktualisieren sich die Clients in ähnlicher Weise selbst und können sich mit dem neuen Server verbinden.
Weitere Einzelheiten zu Hochverfügbarkeitsfunktionen finden Sie in unserem Blog Hohe Verfügbarkeit versprochen mit NCache.
Caching-Topologien Selbstheilendes dynamisches Clustering NCache Architektur
Wartungsmodus
NCache unterstützt Wartungsmodus für seine Partitioniert nach Replikat Topologie. Obwohl die POR-Topologie selbst eine hohe Verfügbarkeit mit einer Replikation jedes Knotens gewährleistet. Falls Sie jedoch ein Upgrade oder ein Patch-Update für den Cache ausführen müssen, müssen Sie jeden Cluster-Knoten einzeln stoppen. Das Stoppen eines Cache-Knotens löst jedoch a aus staatliche Übertragung innerhalb des gesamten Cache-Clusters, was zu einer übermäßigen Nutzung von Ressourcen wie Netzwerk und CPU führt und die Cache-Verfügbarkeit drastisch beeinträchtigt.
Das NCache Der Wartungsmodus behebt dieses Problem, indem er Ihnen die Möglichkeit gibt, einen Knoten zur Wartung anzuhalten. Sobald ein Knoten ist gestoppt, wird der Cluster darüber informiert, dass jede Zustandsübertragung für einen bestimmten Timeout-Zeitraum angehalten werden soll. Wenn ein Cluster gewartet wird, fungiert die Replik dieses Knotens als aktiver Knoten und bedient die Client-Datenanforderungen. Sobald der Knoten selbst wieder dem Cluster beitritt, fordert er Daten von seinem Replikatknoten an. Im Wesentlichen erspart der Wartungsmodus Ihrem Cluster die Kosten eines teuren Zustandsübertragungsprozesses.
NCache Details NCache Docs Wartungsmodus NCache Docs
Laufzeit-Skalierbarkeit von erreichen NCache Cluster
Da NCache speichert Ihre Daten und bietet erweiterte Funktionen wie z Pub/Sub-Nachrichten und Abfrageausführung, können Sie damit rechnen, dass Sie an Speicher- oder Rechengrenzen stoßen, wenn sich alle Ihre Transaktionen auf nur einem Server befinden. Deshalb NCache bietet eine nahtlose lineare Skalierung, um steigende Anforderungen/Sek. zu verarbeiten und mehr Daten zu speichern.
NCache Web Manager macht die Skalierung Ihrer Umgebung so einfach wie das Klicken auf Schaltflächen, und voila, Sie haben einen dynamischen Cluster mit zusätzlichen Knoten, ohne Ihre Clients zu stoppen. Das folgende GIF zeigt, wie einfach es ist, Ihren Cluster dynamisch zu skalieren NCache:
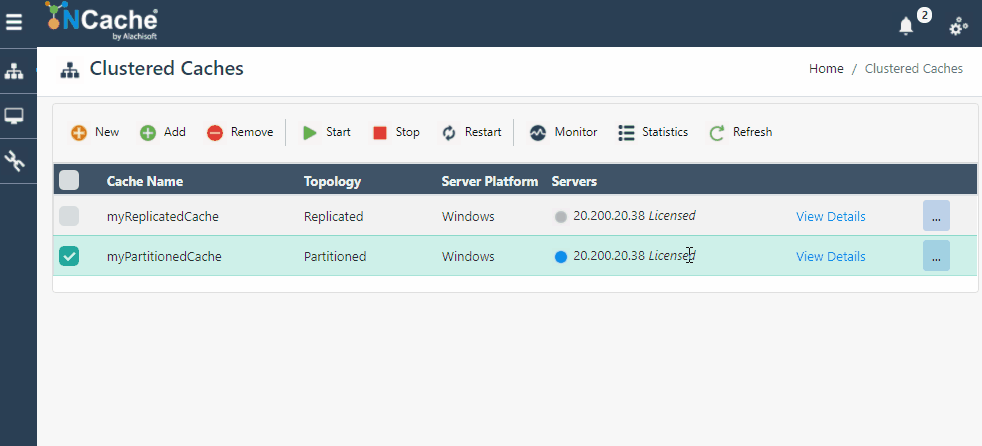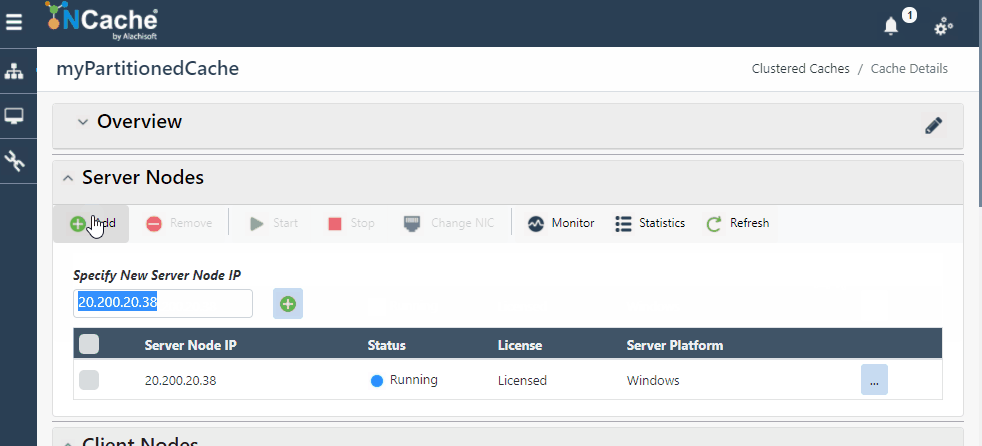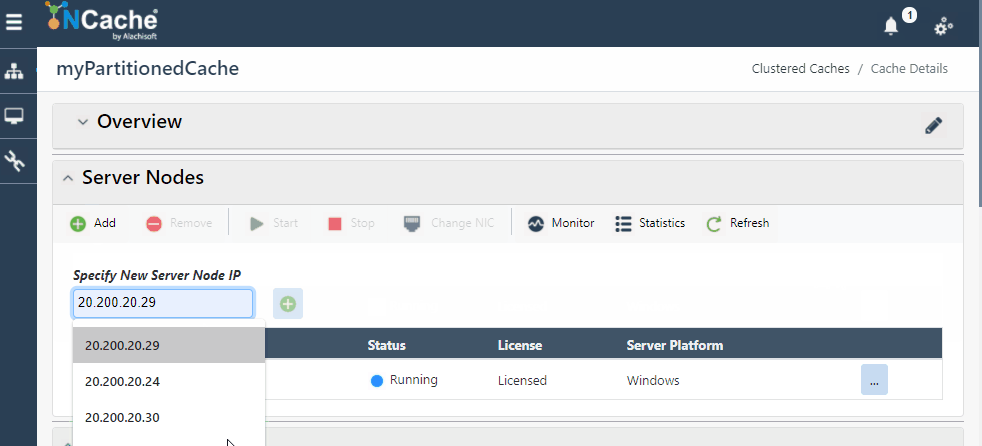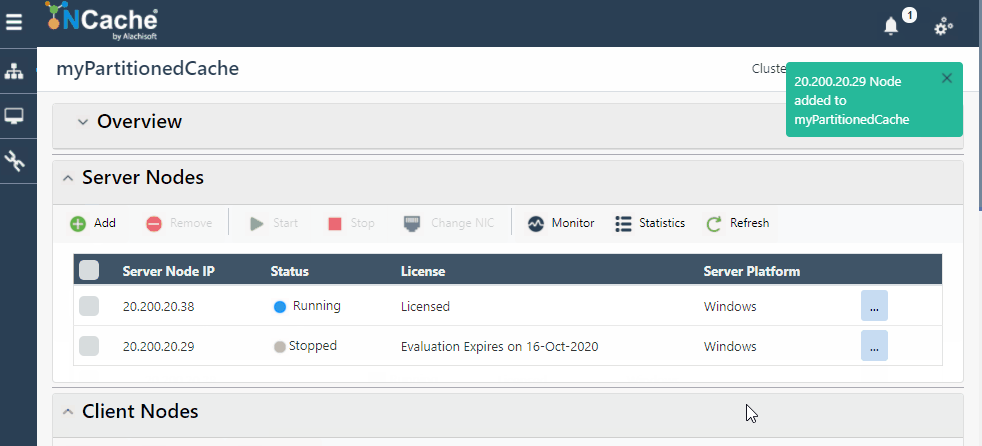
Abbildung 1: Serverknoten hinzufügen in NCache Cluster
Parallele Operationen
NCache hat eine dynamischer Cluster Dadurch erhalten Clients die erforderlichen Daten in nur einem Hop, da die Clients innerhalb des Clusters ohne Benutzereingriff effektiv gehandhabt werden. Darüber hinaus werden die Client-Operationen gesendet und parallel auf allen Knoten ausgeführt. Die Ergebnisse von jedem Knoten werden zu einem einzigen Ergebnis kompiliert, wodurch die Operationen skalierbar werden. Aufgrund der Parallelität wird auch die Leistung der Transaktionen verbessert.
Pipelining
Mit der Pipelining, NCache reduziert den Netzwerk-Overhead, indem mehrere Client-Operationen kombiniert werden, die in einem TCP-Aufruf an den Server gesendet werden. In ähnlicher Weise erhält der Client die Operationsergebnisse in einem einzigen Block in einem Aufruf. Es hilft, den Betrieb zu skalieren.
Objekt-Pooling
Beim Objekt-Pooling wird die NCache Der Server bündelt die Objekte und verwendet sie wieder, um zu verhindern, dass der Garbage Collector immer wieder aufgerufen wird. Die Garbage Collection ist eine leistungsintensive Aufgabe, daher führt die Verringerung der Notwendigkeit, den GC aufzurufen, zu einer höheren Leistung und Skalierbarkeit Ihrer Umgebung.
Client-Cache
NCache bietet Client-Cache, ein Cache auf dem Cache, der sich dort befindet, wo sich die Anwendung befindet. Da der Client-Cache zwischen Anwendung und Cluster-Cache liegt, wird er automatisch synchronisiert und steigert die Leistung, insbesondere bei Lesevorgängen. Die Verwendung eines Client-Cache reduziert den Netzwerk-Overhead.
Weitere Einzelheiten finden Sie im Blog: Skalierbarkeitsarchitektur in NCache – Ein Einblick
NCache Details Clientseitige Operationen Pipelining ein NCache
Zusammenfassung
NCache, da es ein .NET-Natives ist verteiltes Caching Lösung, fügt sich nahtlos in Ihren Anwendungsstapel ein. Es steigert die Leistung enorm durch Objekt-Pooling, parallele Operationen und den Client-Cache, der sich neben Ihrer Anwendung befindet. Abgesehen davon, dass es skalierbar ist, hält es auch jederzeit eine 100%ige Betriebszeit aufrecht, um sicherzustellen die hohe Verfügbarkeit von Daten und Kunden.





