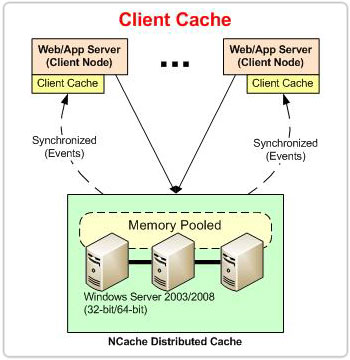
Client-Cache
NCache Clustertopologien sollen die beste Leistung und Skalierbarkeit für Ihre Anwendungen bieten. Aufgrund der wachsenden Geschäftsanforderungen müssen Anwendungen mehr Kundenanfragen und -daten verarbeiten. Das nahtlose Hinzufügen weiterer Knoten zum verteilten Cache sorgt für lineare Skalierbarkeit. Wie ein Hardware-Prozessor-Cache hebt der Client-Cache die Leistung Ihrer Anwendungen auf ein höheres Niveau, indem er den heißen Datensatz näher an Ihre Anwendung heranbringt, sogar innerhalb des Anwendungsprozesses mit InProc-Modus.
Betrachten Sie das Beispiel einer E-Commerce-Anwendung. Die Anwendung greift häufig auf den Produktkatalog und die Daten aktuell aktiver Benutzer zu. Solche Daten können im Client-Cache gespeichert werden, der auf der Client-Box ausgeführt wird. Einerseits steigert das Speichern dieser Daten im Client-Cache die Leistung der Anwendung, indem Zugriffe auf die Datenbank und den Cluster-Cache vermieden werden. Andererseits werden viele Lese-/Schreibvorgänge aus dem Cluster-Cache entlastet, indem der Cluster-Cache in die Lage versetzt wird, mehr Anfragen entgegenzunehmen. Und dieser Leistungsgewinn geht ohne Kompromisse bei der Datenkonsistenz einher. Der Client-Cache synchronisiert seine Daten mit dem Cluster-Cache. Wie der Client-Cache mit dem Cluster-Cache synchronisiert wird, wird in den folgenden Abschnitten erläutert.
Plug: Die Verwendung des Client-Cache ist recht einfach. Auf der Anwendungsseite sind keine Codeänderungen erforderlich. Es handelt sich um eine einfache Konfigurationsoption. Sie können einen Client-Cache über erstellen NCache Management Center oder im NCache unterstützte Powershell-Cmdlets. Sobald der Client konfiguriert wurde, wird er automatisch von den Clientanwendungen verwendet. Für bereits laufende Anwendungen ist ein Neustart der Anwendung erforderlich.
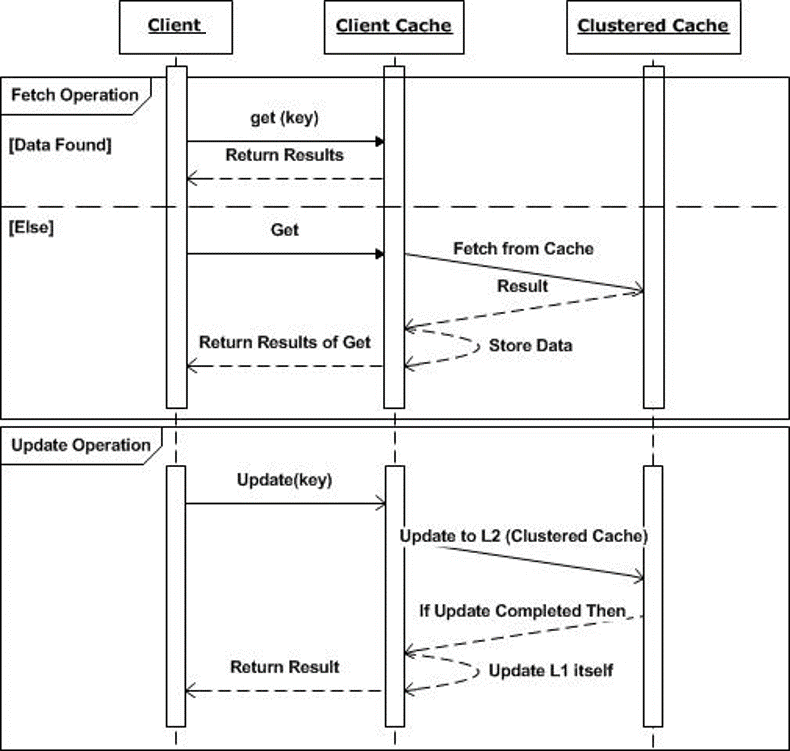
Alle CRUD-Operationen die Cache-Schlüssel als Eingabe verwenden, z Speichern, Erhalten Sie , Insert und Entfernen, werden über den Client-Cache weitergeleitet. Lesevorgänge suchen zunächst nach den Daten im Client-Cache. Der Client-Cache gibt die Daten zurück (falls gefunden). Andernfalls wird der Lesevorgang für den Cluster-Cache ausgeführt. Vom Cluster-Cache zurückgegebene Daten werden an die Anwendung zurückgegeben, nachdem sie dem Client-Cache hinzugefügt wurden. Daher wird der nächste Leseaufruf für dieselben Daten aus dem Client-Cache bereitgestellt. Bei Massenlesevorgängen werden nur die im Client-Cache fehlenden Daten aus dem Cluster-Cache abgerufen.
Schlüsselbasierte Schreiboperationen wie: Speichern und Insertwerden zunächst im Cluster-Cache ausgeführt. Nach erfolgreichem Abschluss werden die Daten zum Client-Cache hinzugefügt und dann an die Anwendung weitergeleitet. Andere Client-Cache-Instanzen werden über einen Hintergrunddatensynchronisierungsmechanismus aktualisiert später erklärt.
Der Client-Cache enthält nur eine Teilmenge der Cluster-Cache-Daten. Daher mögen alle anderen nicht schlüsselbasierten Vorgänge GetGroup, SQL-Abfragen und GetByTagsusw. werden direkt im Cluster-Cache ausgeführt.
Client Cache: Isolation Modes
Der Client-Cache wird auf dem Client-Knoten ausgeführt, auf dem Ihre Anwendungen ausgeführt werden. Abhängig von Ihren Leistungsanforderungen und der Anwendungsarchitektur können Sie einen der folgenden vom Client-Cache unterstützten Isolationsmodi auf Prozessebene auswählen.
In-Proc
Wie der Name schon sagt, wird der Client-Cache innerhalb des Anwendungsprozesses ausgeführt, wodurch die Kommunikation zwischen Prozessen entfällt. Benutzerdaten werden in Objektform gespeichert, um Deserialisierungskosten zu vermeiden. Dieser Modus bietet maximale Leistung für die Anwendung. Da der Client-Cache innerhalb des Anwendungsprozesses gehostet wird, werden die Daten im Client-Cache nicht von anderen Anwendungsinstanzen gemeinsam genutzt. Jede Instanz der Anwendung hostet eine dedizierte Client-Cache-Instanz. Obwohl der InProc-Modus den maximalen Prozess bietet, ist er nur geeignet, wenn:
Der Hot-Dataset der Anwendung ist nicht zu groß.
Die Anwendung verfügt auf jedem Clientknoten nur über wenige Instanzen mit ausreichend physischem Speicher. Denken Sie daran, dass jede Client-Cache-Instanz ihre Datenkopie enthält.
Der Anwendungslebenszyklus ist lang genug, um die Vorteile des Client-Cache zu nutzen. Denken Sie daran, dass der Lebenszyklus des Client-Cache vom Lebenszyklus der Anwendung abhängt. Wenn die Anwendung ausfällt, gehen auch alle Daten im Client-Cache verloren. Anwendungen mit kurzen Lebenszyklen würden heruntergefahren oder neu gestartet, bevor der Client-Cache vollständig gefüllt ist.
Jede Anwendung verfügt über einen eigenen Hot-Dataset, der sich von anderen Anwendungen unterscheidet.
OutProc
Dieser Modus bietet eine Isolierung auf Prozessebene für den Client-Cache. Der Client-Cache wird in seinem dedizierten Prozess auf dem Client-Knoten ausgeführt. Anwendungen kommunizieren über TCP-Sockets mit dem Client-Cache. Mehrere Anwendungsinstanzen können mit demselben Client-Cache kommunizieren und somit Daten gemeinsam nutzen. Obwohl InProc den OutProc-Modus hinsichtlich der Leistung übertrifft, bietet der OutProc-Modus seine eigenen Vorteile.
Mehrere Anwendungen, die auf demselben Client-Computer ausgeführt werden, kommunizieren mit demselben Client-Cache. Mehrere Anwendungen teilen Daten. Von einer Anwendung geladene oder aktualisierte Daten werden für andere Anwendungen verfügbar.
Ein Neustart der Anwendung führt nicht zu einem Datenverlust im Client-Cache.
Für die Ausführung des Client-Cache im OutProc-Modus sind weniger physische Ressourcen wie RAM und CPU erforderlich als im InProc-Modus, bei dem jeder Anwendungsprozess seine Kopie des Client-Cache hält.
Durch die Synchronisierung der Client-Cache-Daten (später erläutert) mit dem Cluster-Cache wird der Cluster-Cache weniger belastet, da Sie pro Client-Computer eine einzige Client-Cache-Instanz ausführen.
Note
Wenn der OutProc-Client-Cache ausgefallen ist, führt die Anwendung direkt Vorgänge im Cluster-Cache aus. Wenn der Client-Cache erneut gestartet wird, wird automatisch eine Verbindung zum Client-Cache hergestellt. Sie können dieses Verhalten ändern, indem Sie Folgendes festlegen skip-client-cache-if-unavailable Flagge in client.ncconf. Wenn das Flag auf gesetzt ist false, Cache-Vorgänge schlagen fehl, wenn der Client-Cache ausgefallen ist.
Synchronizing Data With Cluster Cache
Trotz einer einfachen Plug & Play-Einrichtung können wir die Tatsache nicht ignorieren, dass der Client-Cache eine Kopie der Cluster-Cache-Daten enthält. Änderungen an den Daten in einem Cluster-Cache sollten an den Client-Cache weitergegeben werden. Für einen bestimmten Cluster-Cache können mehrere Client-Caches vorhanden sein, die entweder im InProc- oder OutProc-Modus ausgeführt werden. Von der Clientanwendung vorgenommene Datenänderungen werden auf der Client-Cache-Instanz durchgeführt, mit der die Anwendung verbunden ist. Daher wird diese Instanz des Client-Cache automatisch synchronisiert. Andere Instanzen des Clientcaches sind sich dieser Änderungen jedoch nicht bewusst. Die an den Cluster-Cache-Daten vorgenommenen Änderungen werden mit diesen Client-Cache-Instanzen über einen unten erläuterten Mechanismus zur Hintergrunddatensynchronisierung synchronisiert:
Wenn Daten zum Client-Cache hinzugefügt werden, registriert er eine Datenänderungsbenachrichtigung beim Cluster-Cache für die angegebenen Daten.
Der Cluster-Cache verfolgt jeden einzelnen
CacheItemdass ein Client-Cache die an den Daten vorgenommenen Änderungen speichert und überwacht.Wenn Daten aktualisiert/entfernt Aus dem Cluster-Cache zeichnet der Cluster-Cache diese Änderungen auf.
Ein dedizierter Hintergrund-Worker-Thread prüft die Datenänderungen jede Sekunde und bestimmt, welche Client-Caches über die Änderungen benachrichtigt werden sollen. Es sendet eine Benachrichtigung an die betroffenen Client-Caches, dass Daten geändert wurden.
Ein weiterer dedizierter Hintergrund-Worker-Thread, der im Client-Cache ausgeführt wird, ist für die Synchronisierung von Datenänderungen mit dem Cluster-Cache nach Erhalt der Datenänderungsbenachrichtigung verantwortlich. Sobald es die Benachrichtigung erhält, fordert es den Cluster-Cache an und bittet um Datenaktualisierungen. Wir nennen diesen Synchronisationsmechanismus Client-Cache-Polling.
Dieser im Client-Cache ausgeführte Arbeitsthread fragt alle 10 Sekunden die Datenänderungen ab, wenn er keine Benachrichtigung vom Cluster-Cache erhalten hat, um die Fälle zu behandeln, in denen er aufgrund eines Verbindungsverlusts zwischen dem Client-Cache und dem Cluster-Cache möglicherweise eine Benachrichtigung verpasst hat.
Dieser leistungsstarke Synchronisierungsmechanismus stellt sicher, dass die Client-Anwendungen immer mit den neuesten Daten aus dem Client-Cache versorgt werden und bietet zusätzliche Leistung und Skalierbarkeit.
Synchronisationsmodi
Neben dem Hintergrunddatensynchronisierungsmechanismus unterstützt der Client-Cache die folgenden zwei Synchronisierungsmodi.
Optimistische Synchronisierung
Dies ist der Standardsynchronisierungsmodus des Client-Cache. Wenn eine Anwendung Daten aus dem Client-Cache abruft und der Client-Cache diese Daten speichert, werden die Daten einfach an die Anwendung zurückgegeben. Die Synchronisierung erfolgt im Hintergrund, wie oben erläutert.
Pessimistische Synchronisation
Der Hintergrundsynchronisierungsmechanismus eignet sich für die meisten Anwendungen und bietet der Anwendung optimale Leistung und Skalierbarkeit. Für Anwendungen, die sensibler sind und sicherstellen möchten, dass sie immer mit den neuesten Daten versorgt werden, ist der pessimistische Modus jedoch genau das Richtige für sie. Wenn in diesem Modus eine Anwendung Daten aus dem Client-Cache abruft und der Client-Cache diese Daten speichert, überprüft der Client-Cache die Elementversion mit dem Cluster-Cache. Wenn im Cluster-Cache eine aktualisierte Datenversion gefunden wird, wird diese abgerufen und im Client-Cache aktualisiert. Somit wird garantiert, dass die Anwendung die neueste Version erhält CacheItem.
Siehe auch
Cache-Topologien
Dynamisches Clustering
Lokaler Cache
Cache-Client
Bridge für die WAN-Replikation