Alors que les données ont été inventées comme "la nouvelle monnaie", Apache Lucene est devenu un moteur de recherche en texte intégral populaire, largement utilisé dans les applications pour incorporer une recherche de texte flexible sur des quantités importantes de données textuelles. Lucène utilise indexation inversée, réduisant considérablement le temps nécessaire pour trouver des documents liés à un terme particulier.
NCache Détails Lucène distribué NCache Docs
Cependant, il s'agit d'une solution autonome qui n'évolue pas à mesure que vos données augmentent - vous devez reconstruire des index Lucene entiers pour rechercher des données, ce qui est une tâche coûteuse et lente, devenant un goulot d'étranglement des performances. Bien qu'il existe maintenant quelques solutions basées sur Java et REST pour répondre à la recherche en texte intégral évolutive, il manque toujours une solution de recherche en texte intégral évolutive qui puisse naturellement s'intégrer dans la pile .NET.
Utilisation de Lucene distribué avec NCache pour .NET
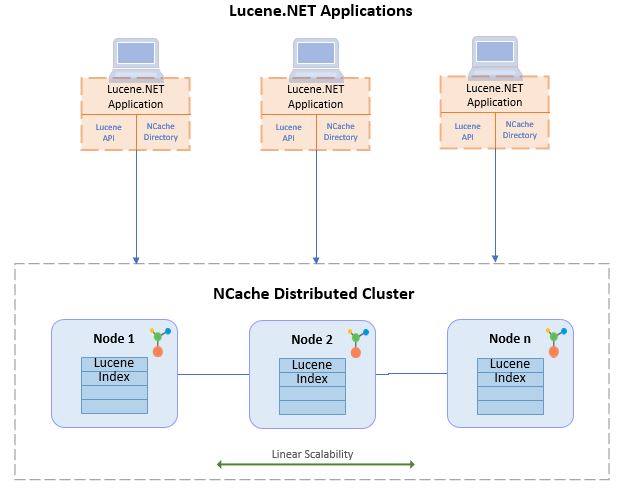
NCache, un magasin de données en mémoire .NET puissant et populaire, a implémenté l'API Lucene.NET native sur son architecture distribuée. Comme il s'agit de l'API Lucene.NET standard, aucune modification de code n'est nécessaire pour l'utiliser de manière évolutive avec NCache.
NCache utilise également ce Lucene.NET pour créer des index dans un environnement dynamiquement évolutif pour permettre recherches en texte intégral distribuées. Les résultats de ces recherches fusionnent avant d'être renvoyés à votre application.
NCache Détails Fonctionnement du Lucène distribué Composants Lucene et aperçu
Cela améliore le Lucene autonome en une solution de recherche en texte intégral rapide et linéairement évolutive.
NCache Détails Lucene distribué pour la recherche d'entreprise Lucène distribué
Utilisation de Lucene dans les applications .NET
Considérons un site de commerce électronique qui contient des informations sur des milliers de produits, de commandes et de détails sur les clients. Par conséquent, l'indexation de tous les attributs, en particulier les champs non textuels (qui ne sont pas utilisés lors de la recherche), n'est pas une approche judicieuse, car elle épuise la mémoire cache.
Par exemple, notre document pour un produit ressemble à ceci :
|
1 2 3 4 5 6 7 8 9 |
{ “ID”: “ABC34”, “Name”: “Tupperware”, “Description”: “Microwaveable, dishwasher-friendly, reusable Tupperware in three sizes”, “RetailPrice”: 15.00, “Discount”: 3.00 } |
Désormais, nous savons que nos clients effectuent des recherches en texte intégral sur la description du produit, qui est un champ du document. Alors, que se passe-t-il si nous indexons uniquement les champs qui peuvent être recherchés et avons une clé qui fait référence à son document correspondant dans le magasin de persistance, par exemple une base de données ou un système de fichiers ? De cette façon, une fois que vous recherchez un type de produit spécifique, disons "Tupperware compatible lave-vaisselle", tous les produits dont la description correspond à ces termes apparaîtront avec leur ProductID comme clé de document, et l'ensemble du document peut alors être récupéré à partir de l'index persistant.
Pour utiliser Lucene distribué dans vos applications existantes, il vous suffit de spécifier NCacheRépertoire lors de l'ouverture d'un répertoire. Cela nécessite le NCache nom du cache et le nom de l'index. L'extrait de code suivant ouvre un répertoire sur un cache LuceneCache dans NCache et un index nommé ProductIndex.
|
1 2 3 4 5 6 7 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string index = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, index); |
Lucene fournit un langage de requête étendu, qui interprète une chaîne donnée en une requête Lucene. Cela peut être fait sur un terme, plusieurs termes, des caractères génériques ou même des mots flous. Pour en savoir plus sur les requêtes Lucene, lisez Documents de requête Lucene.
L'extrait de code suivant crée un IndexReader sur le répertoire, qui est utilisé par IndexSearcher. Les données sont analysées et tokenisées sur la base de StandardAnalyzer. Les 50 premiers hits du résultat sont renvoyés à l'application. Notez que l'analyseur doit être le même que celui utilisé lors de la création de l'index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// The 'applyAllDeletes' is true so all enqueued deletes are applied on writer IndexReader reader = DirectoryReader.Open(indexWriter, true); // A searcher is opened to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify the searchTerm, fieldName and analyzer string searchTerm = "Beverages"; string fieldName = "Category"; // Note that the analyzer should be same as the one used during index creation Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); // Create a query parser to parse the query QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, fieldName, analyzer); Query query = parser.Parse(searchTerm); // Returns the top 50 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 50).ScoreDocs; reader.Dispose(); |
Charger des données pour créer un index distribué
Avec Lucene, vous pouvez créer des index et y charger des données selon vos besoins. Les index nécessitent un analyseur, qui analyse et segmente les données en fonction de vos besoins - il peut s'agir d'espaces, de non-lettres, de ponctuation, etc. Une fois que vous avez créé un rédacteur pour votre index Lucene, vous pouvez créer des documents et y ajouter des champs. Ce document est ensuite indexé dans NCache comme un index distribué une fois que vous appelez Commit(). Pour plus de détails sur les analyseurs Lucene, consultez Docs de l'analyseur Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string indexPath = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, indexPath); // The same analyzer is used as for the reader Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); // Create indexWriter on NCache directory IndexWriter indexWriter = new IndexWriter(directory, config); Product[] products = FetchProductsToIndex(); foreach (var product in products) { Document doc = new Document { new StoredField("id", product.ID), new TextField("name", product.Name, Field.Store.YES), new TextField("description", product.Description, Field.Store.YES), new StringField("category", product.Category, Field.Store.No), new StoredField("retail_price", product.RetailPrice), }; indexWriter.AddDocument(doc); } indexWriter.Commit(); </code><br /><br /><a href="/ncache/">NCache Details</a> <a href="/resources/docs/ncache/prog-guide/lucene-ncache.html#working-of-distributed-lucene">Working of Distributed Lucene</a> <a href="/blogs/geospatial-indexes-for-distributed-lucene-with-ncache/">GeoSpatial Indexes for Distributed Lucene</a> |
Constat NCache pour Lucene distribué ?
En utilisant NCache pour distribué Lucene vous offre les avantages suivants :
- Extrêmement rapide et linéairement évolutif : NCache est un magasin de données distribué en mémoire, donc la construction distribué Lucène en plus, il offre les mêmes performances optimales pour vos recherches en texte intégral. De plus, à cause de NCacheDans l'architecture distribuée de , l'index Lucene est partitionné sur tous les serveurs du cluster. Cela le rend évolutif car vous pouvez ajouter plus de serveurs en déplacement à mesure que votre charge de données augmente, et les index Lucene sont automatiquement redisrendu hommage sans aucune intervention du client.
- Réplication des données pour la fiabilité et la haute disponibilité : Avec NCacheDans la topologie de partition de réplica, l'index Lucene n'est pas seulement partitionné sur tous les serveurs, mais chaque partition est également répliquée sur un autre serveur du cluster. Par conséquent, si un serveur tombe en panne, la réplique de la partition sert toutes les requêtes pour t/resources/docs/ncache/admin-guide/distributed-lucene-counters.htmlhat index, garantissant la fiabilité. De même, si un nœud de serveur tombe en panne, NCache s'auto-guérit dynamiquement en réajustant les données dans les nœuds restants, sans aucun temps d'arrêt ni impact sur votre index Lucene, garantissant une haute disponibilité.
Conclusion
Pour résumer, la recherche en texte intégral est désormais devenue fondamentale dans presque toutes les entreprises, grâce au puissant moteur de recherche Lucene. Mais à mesure que les données augmentent, la reconstruction des index peut causer plus de dégâts que de gain et c'est là qu'une solution .NET distribuée en mémoire telle que NCache Tout ce qu'il faut, c'est un changement de code d'une ligne dans votre application Lucene existante, et le tour est joué, vous avez le meilleur des deux mondes en tant que mécanisme de recherche en texte intégral distribué en mémoire.




