Lucene est une bibliothèque de moteur de recherche de texte intégral .NET qui contient de puissantes API pour créer des index de texte intégral et mettre en œuvre des technologies de recherche avancées et précises dans vos programmes. Lucene offre bien plus que ce que vous attendez des autres moteurs de recherche de texte car les choix proposés à l'utilisateur sont multiples. Il dispose d'un algorithme de recherche puissant et prend en charge un large éventail de requêtes de recherche.
Bien qu'aussi puissant que Lucene soit à lui seul, il n'est pas sans limites. Lucene s'exécute en cours de traitement dans l'application cliente et les applications Lucene écrivent généralement des données sur un fichier et les stockent sur le disque, ce qui entraîne une énorme allocation de mémoire. Cependant, il s'agit d'une solution autonome qui n'évolue pas à mesure que vos données augmentent, vous devez reconstruire des index Lucene entiers pour rechercher des données, ce qui est une tâche coûteuse et lente, qui peut entraîner un goulot d'étranglement des performances. Cela signifie que Lucene n'est pas évolutif et qu'il a un point de défaillance unique.
NCache Détails Télécharger NCache NCache Docs
Comment Distributed Lucene vous aide
NCache fournit une implémentation distribuée de Lucene qui rend les applications Lucene évolutives. NCache être distribué par nature avec Lucene offre une évolutivité d'écriture linéaire car les documents indexés par les applications sont automatiquement distribués entre les nœuds de cache où ils sont indexés séparément.
De même, Distributed Lucene offre également une évolutivité de lecture linéaire puisque les requêtes sont propagées sur chaque partition et les résultats sont fusionnés. Un nombre plus élevé de partitions offre une plus grande évolutivité en lecture et en écriture. Les index Lucene sont conservés sur le disque physique. Plus il y a de nœuds, plus l'évolutivité, les performances et la capacité de stockage sont élevées pour accueillir un grand nombre de documents Lucene et de données indexées.
NCache Détails Télécharger NCache Documents Lucene distribués
Comment fonctionne Lucene distribué
Lucène distribué contient plusieurs nœuds de serveur, chaque serveur de NCache dispose d'un module Lucene dédié. Les comportements et le fonctionnement de Lucene et Distributed Lucene sont similaires, à quelques changements près.
Le diagramme ci-dessous montre comment fonctionne le modèle Distributed Lucene.
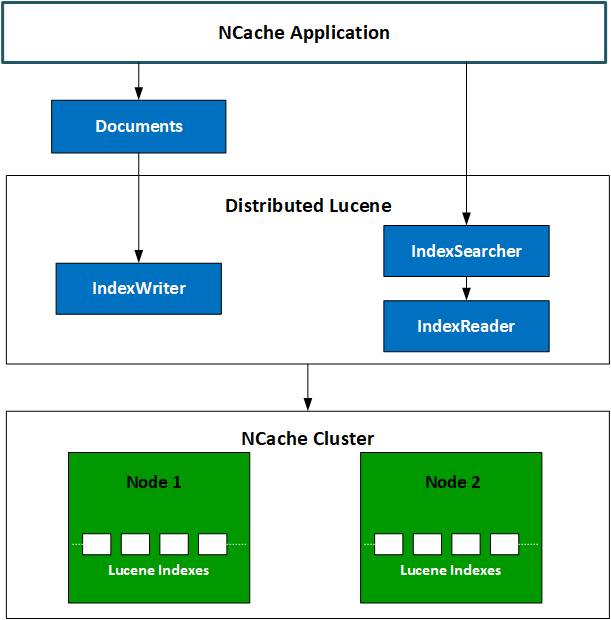
NCache Architecture Lucene distribuée
L'application client peut souhaiter indexer des documents ou interroger des documents indexés existants à l'aide de l'API Lucene. Ces interactions avec l'API agissent comme des appels de procédure à distance (RPC) entre le client et le serveur. Les appels d'API sont directement transmis aux modules Lucene attachés à chaque nœud de serveur. Les modules Lucene exécutent ces appels et, selon la nature des appels, l'une des actions suivantes a lieu :
- S'il s'agissait d'un appel de requête, les modules Distributed Lucene renvoient les résultats côté client, où tous ces résultats sont fusionnés et traités.
- S'il s'agissait d'un appel pour indexer un document, les modules Lucene distribués conservent ce document sur un lecteur de disque.
NCache Détails Documents Lucene distribués Cache Lucene distribué
Distribution de données
Une carte de distribution est générée par rapport au NCache cluster pour Lucene distribué. Cette carte contient des informations concernant la distribution du compartiment par rapport aux nœuds de cache. Ces buckets (100 buckets existent dans la carte) sont distribués dans le cluster selon une stratégie spécifique. L'ajout ou la suppression d'un nœud du cluster modifiera la carte de distribution et déclenchera le transfert d'état pour les nœuds de serveur en cours d'exécution, qui transfèrent des buckets avec des données indexées sur le nœud respectif.
Avoir 100 compartiments signifie qu'un index Lucene est divisé en 100 sous-index à travers le NCache groupe. Un compartiment unique contient un sous-index, qui est identique à un index Lucene dans Lucene.Net. Un nœud de serveur peut contenir plusieurs index, et chaque index de ce nœud de serveur contient des compartiments qui lui sont attribués en fonction de la stratégie de distribution du cluster. Les données à l'intérieur des index sont réparties uniformément via ces compartiments.
Comment démarrer avec Lucene distribué
Lucene distribué fonctionne exactement comme Lucene. L'un des principaux avantages de l'utilisation de Lucene distribué est qu'il vous donne la même API que Lucene. En tant qu'utilisateur Lucene, vous obtenez l'évolutivité que vous souhaitez avec un module complémentaire d'un changement de code sur une seule ligne. Vous n'avez qu'à utiliser NCache Annuaire et votre application est prête à partir. Il y a très peu de changements de comportement et d'API dans Lucene distribué qui sont répertoriés dans le Documentation.
Examinons de plus près ces étapes d'un point de vue technique, et l'étape principale consiste à remplacer le package Lucene.NET Nuget de votre bibliothèque par le package Distributed Lucene Nuget. Lucène.Net.NCache.
Connexion à NCache Annuaire
NCache Directory, comme son nom l'indique, est une classe de base pour stocker les index afin de rendre les index évolutifs. Ainsi, la première étape consiste à se connecter avec le NCache Annuaire.
Ci-dessous est le code qui vous connecte à un cache nommé lucèneCache et ouvre le répertoire fourni sur tous les serveurs.
|
1 2 3 4 5 6 7 8 9 |
// Specify the cache name that is used for Lucene string cache = "LuceneCache"; // Specify the index name to create the indexes string indexName = "ProductIndex"; // Create a directory and open it on the cache and the index path NCacheDirectory ncacheDirectory = NCacheDirectory.Open(cache, indexName); |
NCache Détails API distribuée Lucene Geo-Spatial Initialiser Lucene distribué
Indexer les données dans Lucene distribué
Une fois le répertoire initialisé, IndexWriter crée des documents sur l'index avec le même mécanisme que dans Lucene.NET en utilisant AddDocument méthode. Lorsque le document est rédigé, IndexWriter.Commit est appelée pour conserver le document et le rendre consultable.
Lucene distribué vous permet d'ouvrir plusieurs écrivains sur le même répertoire pour une indexation parallèle. L'exemple de code ci-dessous montre comment vous pouvez indexer vos documents avec Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// Create an instance of the writer IndexWriter indexWriter = new IndexWriter(ncacheDirectory, new IndexWriterConfig(LuceneVersion.LUCENE_48, new WhitespaceAnalyzer(LuceneVersion.LUCENE_48))); // Indexing // Add the products information that is to be indexed Product[] products = FetchProductsFromDB(); foreach (var prod in products) { // Create a document and add fields to it Document doc = new Document(); doc.Add(new TextField("ProductID", prod.ProductID, Field.Store.YES)); doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO)); doc.Add(new TextField("Category", prod.Category, Field.Store.YES)); doc.Add(new TextField("Description", prod.Description, Field.Store.YES)); // Writer is created previously indexWriter.AddDocument(doc); } // Calling commit on the writer saves all the write operations indexWriter.Commit(); // Dispose the objects after indexing indexWriter?.Dispose(); ncacheDirectory?.Dispose(); |
NCache Détails Facettes Lucene distribuées Indexation Lucene distribuée
Recherche dans Lucene distribué
Recherche peut être effectuée après l'indexation des données. La IndexSearcher utilise l' IndexReader pour récupérer les résultats. La IndexSearcher est chargé de rechercher les données en fonction des requêtes données. Lucene fournit un large éventail de requêtes et Lucene distribué prend en charge toutes les requêtes Lucene.
L'exemple de code ci-dessous montre comment vous pouvez rechercher vos documents indexés avec Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Open a new reader instance IndexReader reader = DirectoryReader.Open(ncacheDirectory); // A searcher is open to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify analyzer type Analyzer analyzer = new WhitespaceAnalyzer(version); // Create a query parser and parse the query with the parser //Specify the searchTerm and the fieldName QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, "Category", analyzer); Query query = parser.Parse("Beverages"); // Returns the top 10000 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs; indexSearcher?.Dispose(); reader?.Dispose(); |
NCache Détails Compteurs Lucene distribués Recherche Lucene distribuée
Utiliser des index Lucene natifs avec Lucene distribué
Si vous avez déjà une application .NET utilisant Lucene, il est probable que vous ayez construit un grand index Lucene. NCache Fournit le Importer-LuceneIndex applet de commande, qui permet aux utilisateurs d'importer un index Lucene existant dans NCache Lucene distribué sans avoir à reconstruire les index.
Cet exemple de commande charge l'index Lucene natif à partir de C:\Index à un magasin Distributed Lucene démoCache.
|
1 |
Import-LuceneIndex -CacheName demoCache -Path C:\Index -Server 20.200.21.11 |
NCache Détails Documents Lucene distribués Importer des index Lucene
Conclusion
Lucene est un moteur de recherche très efficace pour effectuer des recherches en texte intégral sur vos données, mais il manque d'évolutivité. NCache peut être utilisé avec Lucene pour le rendre évolutif avec très peu d'effort. Lucene distribué évolutif rend votre application non seulement plus rapide, mais vous aide également à faire face à l'inconvénient majeur d'un point de défaillance unique. NCache peut être facilement branché à votre application .NET avec un changement de code sur une seule ligne, alors considérez-le comme la meilleure option possible pour votre application Lucene évolutive.




