NCache est une solution d'optimisation des performances qui offre évolutivité et haute disponibilité. Il fournit diverses topologies de mise en cache pour fournir une évolutivité linéaire ainsi que la cohérence et la fiabilité des données. Ces topologies sont conçues pour répondre aux différents besoins de mise en cache des applications fonctionnant dans un petit environnement de mise en cache à deux serveurs vers d'énormes clusters de cache avec des centaines de serveurs de cache.
Voici les caractéristiques des topologies de mise en cache qui NCache propose:
Cache répliqué
La topologie garantit la fiabilité des données grâce à la réplication des données sur plusieurs serveurs de cache. Le Cache répliqué est extrêmement rapide et évolutif pour les opérations de lecture. Mais, il n'est pas très évolutif pour les opérations d'écriture, car elles sont synchrones avec tous les serveurs du cluster. La topologie est destinée aux petits environnements de mise en cache où le nombre d'opérations de lecture est supérieur au nombre d'opérations d'écriture. Voici un bref aperçu du fonctionnement de la topologie du cache répliqué.
Comment fonctionne la topologie de cache répliqué ?
La topologie de cache répliqué offre une haute disponibilité des données et prend en charge l'ajout et la suppression dynamiques de serveurs sans arrêter le cache existant.
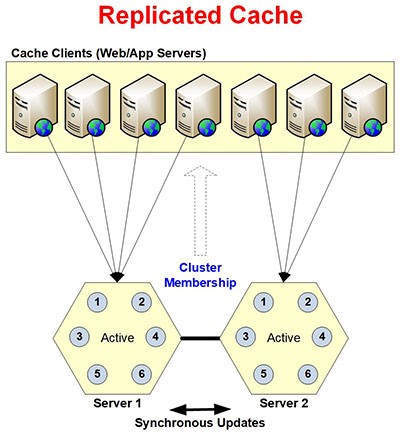
Figure 1 : Architecture de la topologie de mise en cache répliquée
Contrairement aux topologies de partition et de réplique de partition, chaque application cliente se connecte à un seul nœud de serveur en fonction d'un algorithme d'équilibrage de charge déterminé par les serveurs de cache. Lorsque le serveur connecté tombe en panne, l'application cliente se connecte au serveur suivant dans la liste.
Topologie de cache en miroir
La Cache en miroir est un cluster de cache actif/passif à 2 nœuds conçu pour les petits environnements de mise en cache. La topologie offre la fiabilité et la disponibilité des données grâce à la réplication/mise en miroir asynchrone du nœud actif au nœud passif.
Comment fonctionne la topologie de cache en miroir ?
Dans la topologie Mirrored Cache, les nœuds clients se connectent uniquement au nœud serveur actif dans le cluster, pour toutes les opérations de lecture et d'écriture. Si le nœud de serveur actif tombe en panne, les applications clientes se connectent automatiquement au nœud précédemment passif. Cette prise en charge du basculement garantit que le cache miroir est toujours opérationnel. La topologie offre une mise en miroir asynchrone pour les opérations d'écriture qui aide à améliorer les performances de l'application car plusieurs écritures sont effectuées en tant qu'opération BULK sur le nœud de serveur passif.
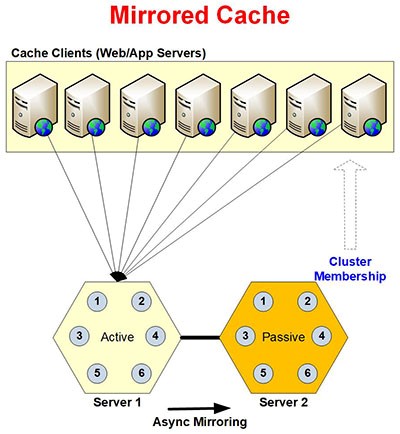
Figure 2 : Architecture de la topologie de mise en cache en miroir
Cache partitionné
Il s'agit de l'une des topologies de mise en cache les plus rapides et les plus évolutives proposées par NCache. La topologie est aussi efficace pour les opérations de lecture que d'écriture. Il atteint une évolutivité linéaire en ajoutant des serveurs au cluster. Vous trouverez ci-dessous un bref aperçu du fonctionnement de la topologie de cache partitionné.
Comment fonctionne la topologie de cache partitionné ?
Dans la topologie de cache partitionné, le cache est divisé en portions lors de l'exécution avec une seule partition pour chaque serveur de cache. Ces partitions forment collectivement un cache en cluster avec 1000 XNUMX buckets, également répartis dans toutes les partitions. Le cluster crée une carte de distribution qui contient le mappage des compartiments dans différentes partitions. Cette carte assure une communication significative entre les nœuds client et serveur.
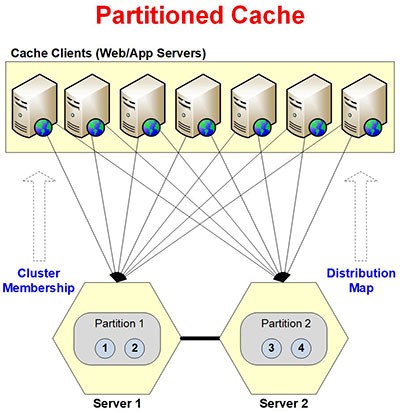
Figure 3 : Architecture de la topologie de mise en cache partitionnée
La topologie offre également une haute disponibilité des données en connectant toutes les applications clientes aux serveurs de cache. Pour que l'application puisse obtenir les données requises même si le serveur connecté tombe en panne, en sollicitant les autres serveurs.
Topologie du cache de réplication de partition
Il s'agit de la topologie de mise en cache la plus populaire dans NCache. Comme il offre aux utilisateurs le meilleur des deux mondes, avec une évolutivité linéaire et une grande fiabilité des données. Cette topologie est presque aussi évolutive que la topologie partitionnée et offre des performances prometteuses et une haute disponibilité des données avec des modes de réplication synchronisés et asynchrones. Voici un bref aperçu du fonctionnement de cette topologie.
Comment fonctionne la topologie du cache de réplication de partition ?
Parallèlement à la création de partitions dynamiques, la topologie crée également des répliques dynamiques de ces partitions sur différents nœuds de serveur - qui servent de sauvegarde en cas d'échec de connexion ou de scénario de panne de nœud. Dans ces cas, NCache obtient les données du nœud de réplique et redislui rend hommage. Cependant, ces répliques limitent l'évolutivité du cluster, car chaque nœud de serveur ajouté sera divisé en partitions actives et répliques.
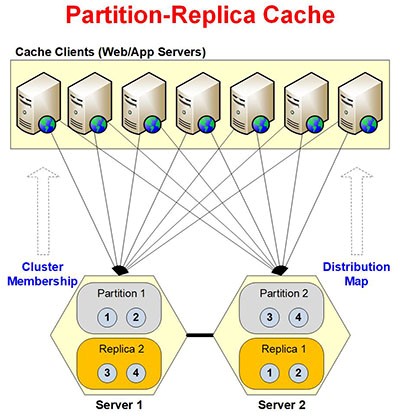
Figure 4 : Architecture de la topologie de mise en cache de partition-réplication
La topologie propose deux modes de réplication ; synchronisé et asynchrone. Dans la réplication asynchrone, toutes les répliques seront créées en arrière-plan, ce qui entraînera des retards de performances nuls. Mais cela implique un léger risque de perte de données lorsque la réplique est en panne, car les données n'y atteindront pas. Pour éviter une telle perte, la topologie offre également une réplication synchronisée où il y a création de répliques à l'exécution et chaque opération ayant échoué sur la réplique sera également considérée comme ayant échoué sur la partition. La topologie fournit une connectivité complète au serveur pour garantir une haute disponibilité des données.
Topologie du cache client
Dans le Cache Client topologie, le cache réside très près de votre application et vous permet de mettre rapidement en cache les données du cache distribué. Le cache Client peut également être considéré comme un « cache sur le dessus du cache ». Il convient aux applications intensives en lecture, mais si votre application doit effectuer un nombre égal d'opérations de lecture et d'écriture, elle fonctionnera plus lentement, car les opérations d'écriture nécessiteront la mise à jour des données à deux endroits.
Bien que le cache client soit local, il n'est pas autonome car il est toujours synchronisé avec le cache en cluster. Cette synchronisation garantit que les données du cache client sont toujours mises à jour. Voici un aperçu des principales caractéristiques de la topologie du cache client.
Comment fonctionne la topologie du cache client ?
Le cache client existe en mode InProc (à l'intérieur de votre processus) ou en mode OutProc (local au serveur Web/d'application). Dans les deux cas, cela améliore les performances de votre application. Le mode InProc vous permet de mettre en cache des objets sur votre "tas d'application", ce qui vous donne "InProc Speed" un autre cache distribué. La meilleure chose à propos du cache client est qu'il n'implique aucun changement de code dans votre application. Au lieu de cela, vous le branchez simplement via un changement de configuration.
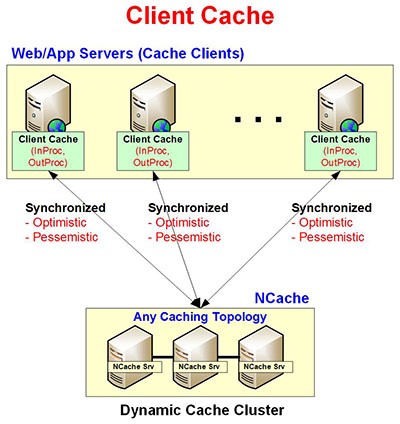
Figure 5 : Architecture du cache client
La topologie offre une synchronisation des données optimiste et pessimiste. La synchronisation par défaut dans le cache client est optimiste, où NCache client suppose que toutes les données dont dispose le cache client sont la dernière copie. Dans une synchronisation pessimiste, le client de cache vérifie d'abord le cache en cluster s'il possède une version plus récente d'un élément mis en cache. Si tel est le cas, le client le récupère, le place dans le cache client et le renvoie à l'application client.
Conclusion
NCache offre une variété de topologies de mise en cache pour répondre aux différents besoins de mise en cache de ses clients. Tous sont distribués, hautement évolutifs et fiables. En fonction de la taille de vos données, de la nature des opérations que vous devez effectuer et du nombre de transactions que vous devez effectuer, vous pouvez choisir l'une des topologies mentionnées. Pour en savoir plus sur NCache topologies n'hésitez pas à télécharger 60 jours d'essai gratuit de NCache.





