Les applications modernes traitent et génèrent de gros volumes de données. La possibilité qu'un seul serveur Web / source de données tombe en panne, entraînant la perte d'applications et de données inestimables, est un cauchemar courant chez les développeurs de logiciels. Cependant, vous pouvez obtenir une haute disponibilité des données si tous les nœuds de serveur ont une copie identique des données - cela implique qu'il n'y aura pas de perte de données si quelques nœuds échouent dans le cluster. Mais que se passe-t-il lorsque les données commencent à augmenter de manière significative ? Dans de tels cas, vous devez rappeler la réplication et commencer à partitionner les données.
NCache étant une solution de mise en cache distribuée et en mémoire, elle offre une évolutivité, des performances et une disponibilité élevées pour les applications gourmandes en données. Il met en avant le POR (Réplique partitionnée) topologie pour diviser les données en plusieurs blocs (buckets) et les placer dans différentes partitions. Afin de répartir uniformément les charges de lecture et d'écriture, les données sont partitionnées sur plusieurs nœuds. Cela résout le problème initial de l'évolutivité en divisant les données, mais comment exactement les données sont-elles partitionnées de manière égale ? Ce blog vise à vous informer sur la façon dont le partitionnement des données se déroule dans NCache.
Partitionnement basé sur le hachage pour une distribution égale des données
Plus souvent qu'autrement, diverses applications utilisent la stratégie round-robin pour affecter des données à différentes partitions. Bien que cette approche garantisse une distribution uniforme, elle présente un défi lorsqu'il s'agit de localiser des éléments de données spécifiques. La recherche et la récupération de données peuvent devenir chronophages et inefficaces sans aucun moyen de suivre l'emplacement des articles.
Pour résoudre ce problème, NCache incorpore Partitionnement basé sur le hachage. Les données sont divisées en plusieurs compartiments qui sont ensuite dispersés sur plusieurs partitions. L'objectif est de répartir uniformément les buckets sur les nœuds du cluster afin d'optimiser les performances et d'assurer une haute disponibilité. Pour y parvenir, NCache utilise une technique de hachage qui mappe chaque élément de données à un compartiment spécifique en fonction de la clé de l'élément. Maintenant, pour déterminer le propriétaire du seau, vous devez appliquer la fonction de hachage sur la clé de l'élément et la modifier par le nombre total de seaux - nous avons 1000 seaux au total.
Qu'est-ce qu'une carte de distribution ?
Le serveur coordinateur est essentiel dans un cluster de cache distribué car il supervise la distribution des buckets et garantit que chaque élément est affecté à un bucket particulier en fonction de sa clé. Pour ce faire, le serveur coordinateur crée un carte de répartition y compris la distribution de compartiment et la distribue à toutes les autres partitions du cluster, ainsi qu'à tous les clients connectés.
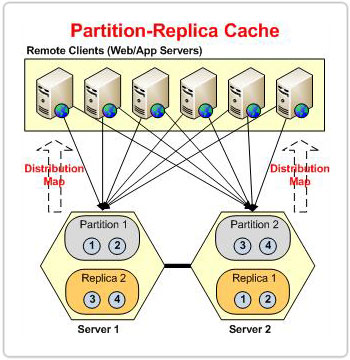
Figure 1 : Partitions sur la base de la carte de distribution dans la topologie POR
Peu importe le nombre de serveurs dans le cluster, NCache s'assure que chaque élément reçoit une adresse de compartiment cohérente via cette méthode. C'est parce que le carte de répartition reste constant, même si le nombre de serveurs dans le cluster change. Par conséquent, même si un compartiment se déplace d'une partition à une autre à n'importe quelle étape, l'adresse de compartiment d'un élément reste la même. Cela garantit que les données restent intactes et qu'aucune donnée n'est perdue lors des mouvements de godet.
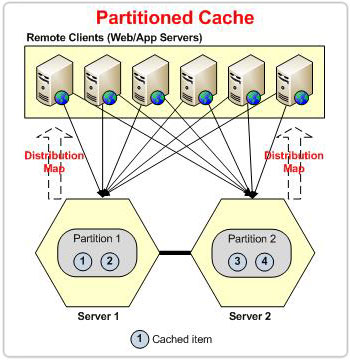
Figure 2 : Partition sur la base de la carte de distribution dans la topologie de partition
En cas de topologie partitionnée, chaque fois qu'un nœud quitte le cluster, le cluster subit une perte de données. Les compartiments appartenant au nœud sortant seront tous perdus. Cependant, en cas de POR, la réplique est présente sur un autre nœud qui sera redissur la base de la carte de distribution – évitant la perte de données.
Répartition des données basée sur une carte de répartition
Les données sont réparties de manière égale entre tous les nœuds du cluster de cache grâce à la stratégie de distribution dynamique des buckets proposée par NCache. Les 1000 XNUMX compartiments sont attribués au nœud lorsque vous démarrez un cluster de cache, ce qui entraîne le stockage de toutes les données dans une seule partition. Pour fournir les meilleures performances et l'équilibrage de charge, les compartiments sont ensuite répartis de manière égale dans les partitions lorsque d'autres nœuds sont ajoutés au cluster.
Les 1000 seaux, par exemple, sont divisés également entre les deux partitions lorsqu'un deuxième nœud est ajouté au cluster, donnant à chaque division 500 seaux. De même, lorsqu'un troisième nœud entre dans le cluster, les buckets sont redistributaire, donnant à chaque partition 333, 333 et 334 seaux, en conséquence.
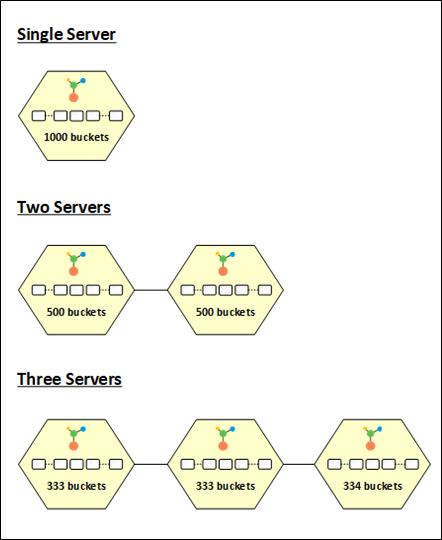
Figure 3: NCache Répartition par godet
La distribution des buckets se modifie une fois de plus si une partition quitte le cluster. Pour maintenir une distribution uniforme des données, par exemple, lorsqu'une partition quitte un cluster à trois nœuds, les 333 ou 334 compartiments qui appartiennent à cette partition sont dispersés sur les deux nœuds restants. NCacheLe mécanisme de transfert d'état de entre en jeu pour rééquilibrer les données entre les nœuds chaque fois que la distribution du compartiment change, garantissant que les données sont distribuées de manière optimale conformément à la distribution du compartiment. De même, le client reçoit également la carte de distribution qui informe sur les nœuds de serveur en cours d'exécution et leurs distributions basées sur le hachage.
Équilibrage de charge de données
Tandis que redisdes buckets tributaires autour des nœuds du cluster de cache, NCache adopte une stratégie centrée sur les données pour s'assurer que la quantité de données que chaque partition reçoit est équilibrée. Pour ce faire, chaque partition du cluster échange périodiquement les statistiques des buckets qu'elle possède avec les autres partitions du cluster. Cela permet de créer un équilibre carte de répartition qui tient compte de la quantité de données que chaque partition possède. NCache équilibre automatiquement les données pour s'assurer que chaque partition reçoit une part égale de données. Il permet également d'équilibrer les données manuellement. Vous pouvez en savoir plus à ce sujet ici.
Conclusion
En conclusion, l'utilisation de la ROP pour diviser les données en NCache est une technique utile pour améliorer la vitesse et l'évolutivité des applications. Vous pouvez garantir que les données sont toujours disponibles et réduire la possibilité de goulots d'étranglement des performances en divisant les données en plus petits morceaux et en les répartissant sur de nombreux nœuds de cache.





