Réplication WAN pour le déploiement multi-centres de données de NCache
Webinaire enregistré
Par Ron Hussain et Zack Khan
Ce webinaire vous montrera tout ce que vous devez savoir sur le NCache Fonction de pont pour la réplication WAN du cache dans les centres de données.
Voici ce que couvre ce webinaire :
- NCacheFonction de pont pour la réplication WAN
- NCache Topologie de pont (actif-actif, actif-passif, 3+ centres de données actifs-actifs)
- Fonctionnalités avancées du pont :
- Pontez la haute disponibilité et le basculement
- Résolveur de conflit dynamique
- Réplication parallèle et asynchrone en masse
- Optimisation de la file d'attente
- Fonction de file d'attente des sessions multi-sites
- Options de surveillance des performances/débogage du pont
Le sujet du webinaire d'aujourd'hui sera la réplication WAN pour un déploiement multi-centre de données utilisant NCache. Dans le webinaire d'aujourd'hui, nous allons couvrir NCachefonction de pont. Qui comprend également NCachede la topologie de pont, les fonctionnalités de pont avancées NCache a, la mise en file d'attente des sessions multi-sites, ainsi que les performances de pont et les options de surveillance du débogage.
Aujourd'hui, nous avons abordé un sujet très important. Plus précisément, pour les applications déployées dans plusieurs centres de données. Ceux-ci pourraient être pour diverses raisons. Par exemple, vous avez besoin d'un site DR, vous avez besoin d'un déploiement multi-centre de données actif-actif ou il peut s'agir d'une migration des données d'est en ouest dont vous avez besoin.
Donc, nous avons un Fonction de réplication WAN disponible, avec l'aide de notre topologie de pont et je couvrirai tous les détails. Comment utiliser la mise en cache d'objets lorsque la réplication WAN est activée. Utilisez-le pour les déploiements de centres de données actifs-passifs, actifs-actifs et actifs-actifs multiples. Donc, nous avons beaucoup à couvrir. Je crois que tout le monde peut voir mon écran et m'entendre bien. Si je peux obtenir des confirmations rapides via l'onglet questions et réponses de GoTo Meeting, ce serait vraiment bien et nous commencerons rapidement la présentation. Donc, veuillez confirmer, si tout le monde peut voir notre écran et ici tout va bien sans aucun problème.
Introduction à la NCache
Je vais donc commencer par les informations de base sur les raisons pour lesquelles vous avez besoin d'un système de mise en cache distribué comme NCache? Ainsi, généralement, c'est le goulot d'étranglement des performances et de l'évolutivité des applications qui permet le problème, qui limite vos applications à fonctionner de manière plus rapide et plus fiable.
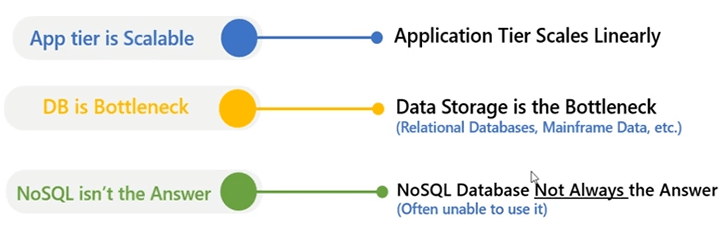
Votre niveau d'application est très évolutif. Vous pouvez avoir une application Web ou une application backend. Vous pouvez toujours créer une ferme Web ou une ferme de serveurs d'applications, où votre application peut être déployée sur plusieurs serveurs. Votre charge peut être répartie. Plusieurs serveurs permettent de répondre à toutes ces demandes d'application en parallèle, en combinaison les unes avec les autres, mais toutes ces applications doivent communiquer avec une base de données principale, ce qui est généralement une source de conflit. La base de données devient un goulot d'étranglement en termes de performances et d'évolutivité pour votre application, car vous ne pouvez pas non plus faire évoluer les serveurs de base de données et ses ressources très coûteuses. Donc, vous pouvez toujours évoluer, mais il y a une limite à combien vous pouvez faire évoluer un serveur de base de données ? NoSQL n'est généralement pas la solution car vous devez ré-architecturer votre application. Vous devez arrêter d'utiliser notre base de données relationnelle et commencer à utiliser un NoSQL source de données afin de l'utiliser et nous avons également un produit appelé NosDB qui est un NoSQL database mais nous projetons une manière différente de gérer cela et c'est par le biais d'un système de mise en cache distribué.
Donc, tout d'abord, la solution à ce problème d'évolutivité est très simple, que vous commenciez à utiliser un système de mise en cache distribué en mémoire. C'est super rapide parce que c'est en mémoire, par rapport au disque. Ainsi, les performances de votre application seront immédiatement améliorées dès que vous vous connecterez NCache.
Deuxièmement, c'est une équipe de serveurs. C'est un cluster de cache. Ce n'est pas seulement une source unique comme la base de données. Vous avez plusieurs serveurs joints dans un cluster de cache. Donc, c'est un stockage logique, vous savez, qui est regroupé par de nombreux serveurs que vous pouvez choisir d'ajouter. Cela le rend très évolutif par rapport à vos bases de données relationnelles. Vous pouvez commencer avec 2 serveurs et vous pouvez ajouter plus de serveurs au moment de l'exécution. Ainsi, cela le rend de plus en plus évolutif et en fait linéairement évolutif, où vous pouvez ajouter plus de serveurs et, par conséquent, vous continuez à augmenter votre capacité de traitement des demandes hors de NCache. Une bonne chose à propos NCache est que vous l'utilisez en plus d'une base de données principale, une base de données relationnelle. Il existe de nombreuses fonctionnalités qui complètent votre utilisation des données provenant d'une base de données principale. Ainsi, vous pouvez toujours utiliser NCache conjointement avec votre base de données relationnelle. Ce n'est pas un remplacement de vos sources de données relationnelles. Quelques chiffres d'évolutivité.
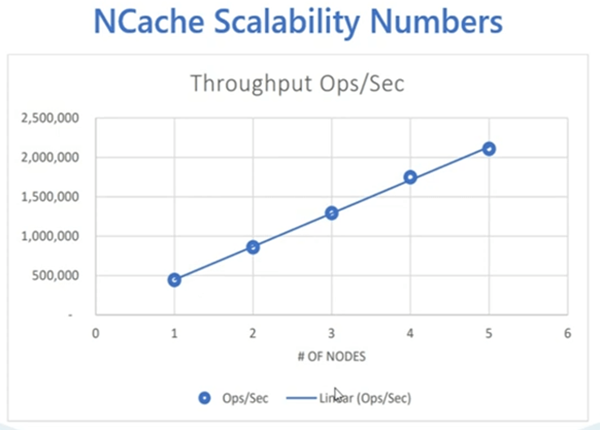
NCache est très évolutif, car vous ajoutez plus de serveurs NCache vous permet de traiter de plus en plus de demandes NCache groupe. Nous avons récemment effectué ces tests dans notre environnement QA. Nous utilisons notre laboratoire AWS, où nous avons continué à augmenter la charge et avons également continué à ajouter plus de serveurs et jusqu'à 5 NCache serveurs, qui est une configuration très courante pour notre cache distribué. Nous avons pu atteindre 2 millions de requêtes par seconde et c'était une tendance à la hausse où nous, chaque fois que nous ajoutions plus de serveurs, nous ajoutions plus de capacité au cluster de cache. Avec une taille d'objet moyenne de 1 kilo-octet, c'est le genre de performances que vous pouvez également attendre de NCache et avec un meilleur matériel, vous pouvez même étendre ces chiffres et obtenir un meilleur débit de performances de NCache. Au fait de ces repères, il y a un whitepaper et vidéo démonstration publiée également sur notre site Web. Donc, vous pouvez également y jeter un œil.
Quelques détails de déploiement. Comment un déploiement typique de NCache va ressembler.
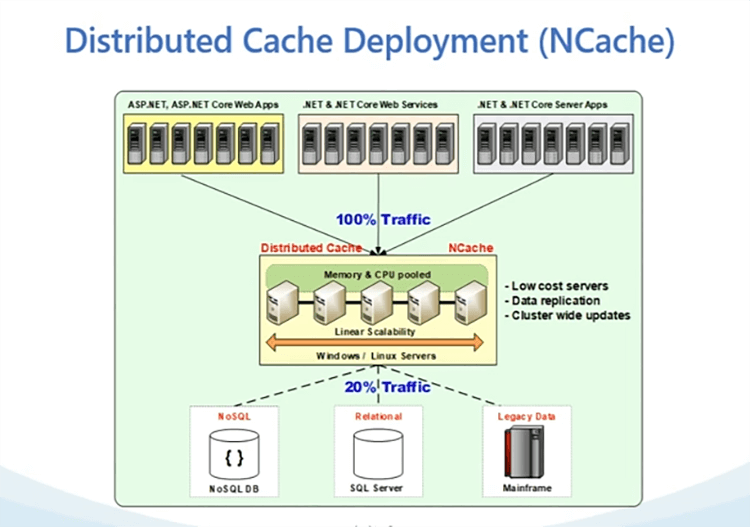
Voici un déploiement sur site unique de NCache. Comme vous pouvez le voir, nous avons un site unique et dans votre cas, ce dont nous parlons de l'aspect de la réplication WAN, nous aurions évidemment plus d'un déploiement, nous aurions un centre de données séparé, où nous aurions également NCache et les applications déployées.
Ainsi, avec notre déploiement de cache distribué, comme indiqué dans le diagramme, parlons de la façon dont un déploiement typique ressemble. Nous avons donc à nouveau une équipe de serveurs. Nous avons 4 à 5 serveurs affichés dans le diagramme, c'est là que votre cluster de cache est hébergé et comme vous pouvez le voir, il se situe entre votre application et votre base de données. L'idée ici est que vous utilisez ces sources en combinaison les unes avec les autres, pour la mise en cache d'objets mais pour la mise en cache de session, le cache devient votre principale source de données. Ainsi, toutes vos sessions peuvent être stockées dans NCache et vous n'avez pas à aller ailleurs. Un modèle de déploiement très flexible est disponible. NCache peut être hébergé sur place. Il peut s'agir de boîtes physiques ou virtuelles. Il peut également s'agir d'un nuage. Il peut s'agir d'un cloud public ou privé. Cela pourrait également être sur Azure AWS, car nous avons des images de marché disponibles pour ces deux fournisseurs de cloud. Mais, en général, tout serveur qui a Windows ou Linux et seul prérequis pour NCache est .NET ou .NET Core Cadre. Donc, ce sont des prérequis. C'est juste .NET et .NET Core qui NCache a besoin comme pré-requis. Si cela est disponible, NCache est très flexible pour être déployé sur Windows ainsi que sur des environnements Linux et comme je l'ai dit, cela pourrait aussi être n'importe quel environnement, vous pouvez utiliser Docker et vous pouvez également héberger NCache dans le cluster Kubernetes et cela ouvre de nombreuses autres plates-formes. Vous pouvez l'utiliser dans OpenShift. Vous pouvez l'utiliser dans le service Azure Kubernetes. Vous savez, le service Elastic Kubernetes également. Donc, toutes ces plates-formes, vous savez, sont équipées et NCache est équipé pour être déployé sur toutes ces plateformes.
Il existe deux options de déploiement. La première est que vous allez avec le niveau de cache dédié, comme indiqué dans le diagramme et le second est, et dans dédié vos applications s'exécutent sur des boîtes séparées et NCache s'exécute sur un niveau dédié distinct. Nous avons également un niveau partagé, une approche également disponible, où vous pouvez également exécuter NCache à côté de vos boîtes de candidature. Ainsi, où que vos applications soient hébergées NCache peut être hébergé dessus. Donc, je crois que c'est assez simple. Dans un déploiement multicentre de données, vous auriez plus d'un centre de données et vous auriez le même déploiement pour NCache sur l'autre centre de données également, que nous couvrirons dans les diapositives à venir et au fait, s'il y a des questions, vous pouvez toujours poster cette question dans notre onglet questions et réponses et Zack et moi garderons, vous savez, garderons un soyez attentifs à toutes ces questions qui vont être postées et nous serons très heureux de répondre à toutes ces questions pour vous. En parlant de questions, puisque vous en avez parlé tout à l'heure, j'en ai une que j'aimerais soulever, c'est très simple, vous mentionniez Kubernetes maintenant. Donc, la question était, nous allons parler des ponts et de cela en général, y a-t-il des exigences de système d'exploitation pour tout cela ? Êtes-vous capable de l'exécuter sous Linux ? Absolument. NCache est très souple. Comme vous pouvez le voir, même sur notre diagramme de déploiement. Tu peux voir NCache est pris en charge sur les serveurs Windows et Linux. Ainsi, sur les serveurs Linux, vous avez juste besoin .NET Core libération de NCache et nous avons un serveur ainsi qu'un client pour ceux-ci. Donc, si vous voulez courir NCache serveurs sur .NET sous Linux en utilisant .NET Core c'est possible et vos applications pourront toujours utiliser notre .NET Core publier et être déployé sur Windows ainsi que Linux, donc, oui. Génial. Je vais vous laisser parcourir le reste et je poserai les questions plus tard.
Déploiement multi-datacenter de NCache
Donc, nous parlerons ensuite du déploiement multi-datacenter de NCache. Maintenant, si votre application est déployée sur plusieurs centres de données, ou il se peut que vous ayez un site actif et que nous ayons ensuite un site passif pour les scénarios DR. Par exemple, le site actif tombe en panne et votre application nécessite que vous soyez toujours opérationnel, s'il s'agit d'une application critique, elle est importante pour votre entreprise. Avoir un temps d'arrêt au niveau du site est quelque chose qui aurait un impact sur votre entreprise.
NCache cluster est conçu de telle manière qu'il est déjà équipé de fonctionnalités de haute disponibilité et de fiabilité des données. Ainsi, au niveau d'un site unique, si un ou deux serveurs tombent en panne, par exemple, si vous perdez un Serveur, NCache est équipé pour gérer cette panne sans aucun problème. Mais aujourd'hui, nous parlons de si nous, que se passe-t-il si nous obtenons une panne au niveau du site ? Ou, nous devons arrêter le site pour maintenance, le site entier étant en panne. Donc, tous les serveurs sont en panne. NCache est même équipé pour gérer ce scénario et c'est ce que nous prévoyons de couvrir aujourd'hui. Parlons donc de la raison pour laquelle nous avons besoin de la réplication WAN ?

Généralement, lorsque vos applications ont besoin d'une haute disponibilité, un site unique peut devenir un point de défaillance unique. Si votre site tombe en panne, vous perdez toutes les données et vous pouvez potentiellement obtenir des temps d'arrêt sur les utilisateurs de votre application et cela pourrait avoir un impact sur votre entreprise, nous l'avons déjà établi. Les applications multi-régions sont lentes si elles doivent se parler sur le WAN. Par exemple, vous avez un centre de données déployé, votre application déployée dans un centre de données qui se trouve dans la région des États-Unis, puis vous avez une autre application qui est déployée en Europe ou dans toute autre région asiatique, par exemple. Ainsi, dans ce cas, si vos bases de données d'application sont situées sur l'un des centres de données, le site distant doit traverser le réseau. Ainsi, la vitesse de votre réseau aurait un impact sur la latence de cet autre site. Vous savez, pour gérer ce scénario, vous répliquez généralement également vos sources de données sur le WAN et c'est ce que nous recommandons pour NCache aussi bien que NCache devrait être reproduit. Mais, étant donné que vous êtes, vous avez une source de données commune, le site distant doit passer par le WAN et cela pourrait potentiellement avoir un impact sur les performances car les données ne sont pas locales pour ce site, la distance entre les centres de données aurait également un impact sur votre débit . Il n'y a qu'une quantité limitée de données que vous pouvez transmettre entre les sites. Cela peut donc limiter votre capacité de traitement des demandes.
Donc, ce sont deux problèmes si vous avez des applications multirégionales et si les deux applications sont actives. La réplication des données au niveau de la demande est également coûteuse. Par exemple, vous ne répliquez pas la base de données entière et vous avez une source de données hébergée sur un centre de données. Maintenant, une requête qui va sur notre emplacement distant, un emplacement géographique qui est éloigné, à votre base de données. Une réplication au niveau de la requête pour chaque donnée, vous savez, unité de requête qui arrive à notre source de données, cela va être extrêmement coûteux et cela consommerait beaucoup de bande passante et de ressources. Donc, vous avez besoin d'un mécanisme actif, où vous avez des données disponibles localement et c'est pourquoi vous avez besoin d'une réplication WAN du cache nécessaire. Ainsi, vos données d'un centre de données sont répliquées sur le réseau vers l'autre site.
Quelques cas d'utilisation. Pourquoi, vous savez, où exactement pouvez-vous utiliser la réplication WAN ?
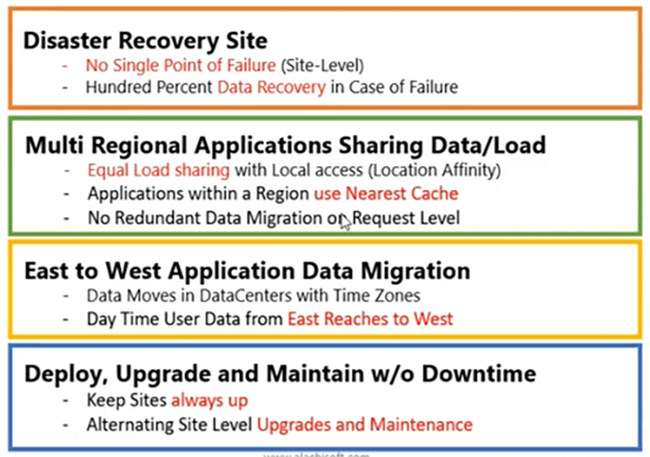
Le plus courant, que nous rencontrons, est le site de reprise après sinistre. Vous avez un site actif, qui sert votre principal cas d'utilisation commerciale. C'est là que votre trafic est généré et géré. Et si tout le site tombe en panne ? Vous avez besoin d'une option de secours, à droite. Ainsi, ce site DR devrait déjà disposer de données. Sinon, il n'aurait pas ces exigences en matière de données traitées s'il devait retourner sur le site qui est déjà en panne, n'est-ce pas. Donc, vous avez besoin que les données soient mises à disposition sur le site DR, de sorte qu'il soit déjà opérationnel. Il vous suffit de transférer votre trafic vers ce site DR. Vous ne devriez rien faire d'autre, simplement acheminer votre trafic vers le site de reprise après sinistre et cela devrait fonctionner avec la même valeur de performance, les mêmes matrices de performance que vous aviez avec le site actif. Ainsi, une récupération à 100% des données en cas de panne est possible, avec l'aide de NCache Réplication WAN.
Les applications multi-régionales peuvent partager des données ainsi que les charger. Maintenant, avec les sites actifs-actifs, si vous avez une région aux États-Unis et une dans une autre partie du monde, par exemple, l'Europe ou l'Asie. Si vous le souhaitez, vous savez, la demande de, vous savez, un centre de données doit être géré en fonction de l'affinité d'emplacement, vous pouvez y parvenir. Désormais, un utilisateur d'Asie peut se connecter à un site de cette région, le plus proche de cette région, et il peut également utiliser le cache là-bas et ce cache est synchronisé avec l'autre cache qui se trouve dans la région des États-Unis. Donc, tout utilisateur qui rebondit. Par exemple, vous devez gérer le débordement ou répartir la capacité. Certains des utilisateurs doivent maintenant rebondir vers la région des États-Unis car la région de l'Asie est complètement étouffée, vous pouvez donc toujours le faire. Ainsi, au niveau du site, vous pouvez équilibrer la charge de votre demande, en fonction de la capacité que ce site gère à ce moment et à ce moment précis. Depuis, les données de cache sont déjà répliquées dans les centres de données et nous parlerons de la façon d'y parvenir, ainsi, vos applications multirégionales sont efficacement capables de partager leurs données d'application et également de partager la charge de la demande et elles peuvent également avoir un partage de charge égal. . Aucune migration de données redondantes n'est effectuée. C'est juste basé sur la requête qui rebondit d'un centre de données à l'autre et vous pouvez toujours obtenir ces données à partir du cache qui y est déjà connecté.
La migration des données d'application d'est en ouest est un autre cas d'utilisation. Par exemple, les marchés asiatiques commencent plus tôt que, vous savez, les marchés occidentaux, n'est-ce pas. Ainsi, la tendance de vos données suit généralement d'est en ouest. Ainsi, votre site oriental peut avoir notre cache configuré et avec le fuseau horaire, les données se déplacent entre le centre de données vers la région occidentale et elles atteignent l'ouest. Ainsi, si vous avez des données répliquées dans les centres de données, les données de cache, la région ouest serait en mesure de tirer parti de toutes les données mises à disposition par la région est. Ainsi, vous pouvez rendre disponible la migration des données d'est en ouest et le cas d'utilisation de la maintenance est le troisième.
Quatrième, où nous pouvons déployer la mise à niveau et la maintenance sans aucun temps d'arrêt. Cela devient un cas d'utilisation très urgent, avec NCache aussi bien. Ainsi, si vous envisagez de mettre à niveau, vous pouvez effectuer des mises à niveau entre les anciennes et les nouvelles versions, en utilisant notre topologie de pont. Lorsque des données plus anciennes, les données de version peuvent être transmises à la version la plus récente avec la fonction de mises à niveau en direct. Cela peut être entre sites, par exemple, vous pouvez utiliser un site et répliquer activement les données sur le site passif et vous pouvez mettre à niveau, déployer un nouveau code, maintenir les performances, la maintenance sur le site actif et vous avez toutes les données mises à disposition et votre le trafic peut d'ailleurs être acheminé vers le site passif. Ainsi, les deux sites peuvent toujours être opérationnels sans aucun temps d'arrêt ni aucune perte de données d'application.
NCache Pont pour la réplication WAN
Alors, parlons de la façon de gérer cela? Le nom de la fonction est NCache pont. Cela fait partie du même produit. Vous n'avez pas besoin d'installation séparée pour cela. NCache Enterprise est équipé de NCache topologie de pont et parlons-en.
Donc, notre cache, NCache La fonction de pont vous permet de répliquer le cache dans les centres de données.

Il est basé sur un modèle de réplication asynchrone. Il n'entraîne aucune dégradation des performances côté application. Vos applications de cache sont connectées en actif au cache sur un centre de données. Par exemple, vous avez des clients ici et vous pouvez ensuite créer un pont qui est également une file d'attente active-passive et qui transmettrait les données aux autres sites de manière asynchrone.
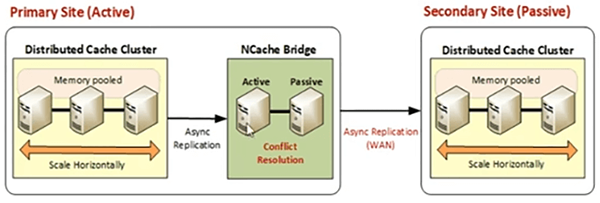
Donc, il est basé sur la réplication asynchrone, il n'y a donc pas de dégradation des performances dans la réplication des données. C'est très fiable. Il est tolérant aux pannes. Il détecte automatiquement les échecs de connexion. Il se reconnecte automatiquement. Des options de nouvelle tentative automatique sont disponibles, de sorte que le pont est également sauvegardé sur la file d'attente active-passive.
Il existe donc un serveur Active Bridge, puis un serveur Passive Bridge également. Si le serveur Active Bridge tombe en panne, le Passif reprendra et démarrera toutes les opérations de réplication sans aucun délai. C'est très facile à configurer, vous n'avez besoin d'aucun changement de code, vous n'avez pas besoin d'installations supplémentaires. Il fait partie du même produit, l'Enterprise et il offre son propre support de surveillance et de gestion, qui est intégré dans le même NCache Enterprise produit et il prend en charge plusieurs topologies que je vais couvrir ensuite.
Nous avons donc trois grandes topologies.

Nous avons Actif-Passif. Où nous avons un site actif et ensuite nous avons un site passif. Le site passif accepte également les demandes des clients, mais le flux de données passe d'actif à passif. Ainsi, si vous avez des exigences de site DR, vous pouvez utiliser un site pour être actif, connecté au pont, puis vous pouvez avoir un autre site passif. Le site actif transmet des données au site passif. C'est donc une transmission à sens unique. Le terme passif signifie essentiellement que le site passif ne transmet pas de données à l'actif. Il est toujours en cours d'exécution et vous avez des applications clientes qui en profitent. Donc, ce n'est pas quelque chose qui est arrêté par quelque moyen que ce soit. La migration d'est en ouest peut être réalisée avec un passif actif. Votre maintenance et un cas d'utilisation de mise à niveau peuvent être gérés à l'aide de l'actif-passif.
La topologie active-active est, lorsque vous avez une application déployée sur deux emplacements géographiques différents et que vous souhaitez que les données du site 1 soient mises à disposition sur le site 2 et que les données du site 2 soient mises à disposition sur le site 1. Si votre application a besoin d'exigences de partage de données entre sites géographiques, vous pouvez cibler actif-actif où vous avez des utilisateurs actifs sur les deux centres de données. Les clients sont connectés aux deux centres de données et il y a une réplication bidirectionnelle entre deux sites différents, puis nous avons 3, 2+ ou 3+ topologie active-active, où nous avons un serveur d'enchères principal, mais il transmet des données à tous sites et ces sites transmettent également des données à tous les autres sites. Ainsi, une mise à jour doit être appliquée sur tous les centres de données et vice-versa.
Donc, voici notre actif-passif.
En cela, nous avons un pont, qui est une file d'attente, qui est également active-passive. Nous avons un cluster de cache sur le site 1, qui ne fait, vous savez, que gérer les demandes des clients. Nous avons 3 serveurs ici. Il est connecté au pont. Bridge réside également sur l'un des sites. Ou, dans certains cas, vous pouvez avoir un pont actif sur le site 1 et un serveur de pont passif sur le site 2. C'est également possible, mais nous vous recommandons généralement de déplacer le pont sur l'un des sites de votre architecture de déploiement. Le deuxième site est un site passif et encore une fois par passif, il fonctionne toujours. C'est juste que le site passif ne réplique pas les données vers le site actif. C'est une transmission de données à sens unique et c'est tout ce que cela signifie quand nous disons qu'il s'agit d'un site passif. Vous pouvez essentiellement exécuter des applications clientes ici et elles sont entièrement fonctionnelles même dans cet état. Donc, c'est une réplication de données, active passive, donc, si ce serveur tombe en panne, la passive s'active et c'est automatique. Aucune modification de code n'est nécessaire. Je vais vous montrer comment configurer le pont, une fois que nous aurons progressé dans notre partie pratique. Donc, c'est assez simple.
Une question est arrivée et elle a à voir avec cet actif-passif, c'est principalement si vous avez un site actif et un site passif, comment activez-vous le site passif ? Est-ce un processus manuel ? Le site est-il arrêté ? Comment tu fais ça? D'accord, donc, si j'ai bien compris cette question, le site passif en termes de comment nous l'activons ? Il est déjà activé. Il est en cours d'exécution et si nous arrêtons ce site ou si nous voulons déplacer le trafic ici, c'est la charge de trafic de votre application que vous devez déplacer vers ce site. Donc, vous avez des serveurs d'applications ici, vous avez des serveurs d'applications ici, toutes les données que vous avez vont être transmises ici et les utilisateurs de ce site peuvent avoir les données mises à disposition à partir du cache lui-même. Désormais, vous pouvez toujours acheminer votre trafic vers le site passif et vous pouvez obtenir toutes les données mises à disposition. Ainsi, aucune étape n'est nécessaire pour l'activer. Cependant, si vous souhaitez que ce site commence également à transmettre des données vers le site actif, vous pouvez le rendre actif en utilisant nos outils GUI. Donc, en termes de réplication, si vous voulez que cela réplique les données vers l'actif, vous pouvez toujours le rendre actif et c'est un processus d'exécution. Ainsi, vous pouvez simplement avec une ligne de, en un clic dans l'outil GUI, vous pouvez y parvenir ou vous pouvez utiliser notre outil PowerShell pour y arriver. Mais si votre question concerne l'activation du nœud passif. S'il y a une étape manuelle pour que les applications clientes s'y connectent et puissent utiliser les données, il est déjà en cours d'exécution. Vos applications commencent à l'utiliser si vous commencez à acheminer le trafic vers ce cluster de cache. Donc, dans votre équilibreur de charge. Vous désactivez ce site et acheminez tout votre trafic vers le site disponible, qui est déjà opérationnel et vous pouvez obtenir/profiter de toutes les données qui sont répliquées.
Donc, actif-actif, c'est à nouveau basé sur le même principe. Où nous avons des ponts en cours d'exécution sur l'un des sites.
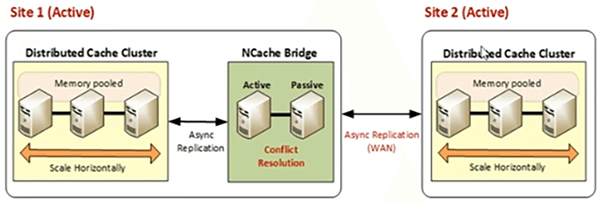
Nous avons le cache 1, le cache 2. Les deux sites sont actifs et même la topologie passive peut être activée, en cliquant avec le bouton droit de la souris et en la rendant active. Dans ce cas, les données du cache du site 1 sont transmises au site 2, de manière asynchrone du cache au pont. et du pont au cache, puis de la même manière, le site 2 transfère également les données vers le site 1.
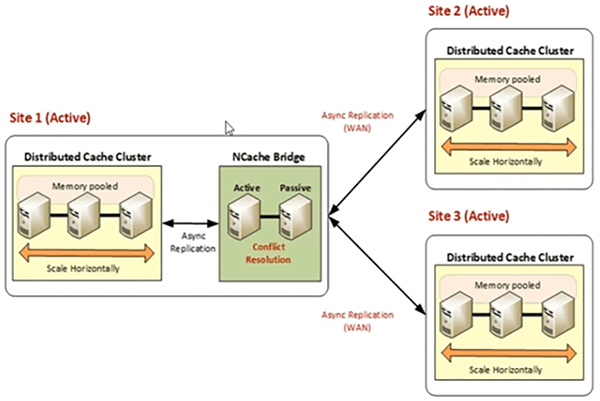
3+ centres de données actifs-actifs, où nous avons trois ou plus actif-actif, où nous avons l'un des sites comme serveur de pont. Nous pouvons également avoir un site de repli pour le bridge. Nous pouvons également avoir un site de pont de secours. Mais, en général, nous aurions l'un des sites qui hébergerait, qui hébergerait un pont, puis ce site transmet des données à d'autres sites et de même, le site 2 transfère des données au site 1 via le pont et au site 3. Et pour les actifs -active, nous avons une résolution de conflit basée sur le temps, donc la dernière mise à jour l'emporte. Toutes les structures de données que nous utilisons sont sans conflit. Ce sont des types de données sans conflit. Il n'y a pas de conditions de concurrence ou de problèmes de cohérence des données, car la dernière mise à jour sera appliquée sur le cluster de cache à tous les niveaux. Alors, NCache gère s'il y a deux mises à jour pour la même clé, NCache évaluerait cela et vous permettrait également de construire votre propre résolution de conflit, si c'est une exigence. Elle est donc gérée dans le cadre de NCache topologies.
Alors, voici un aperçu rapide de nos configurations de pont.

Nous avons NCache configuration du pont. NCache Bridge est le nom et puis nous avons LondonCache environnement 1, de sorte que vous pouvez également avoir plusieurs caches avec le même nom. NewYorkCache et ceux-ci sont connectés.
Démonstration pratique NCache
Alors, laissez-moi vous montrer tout cela en action, comment configurer un pont ? Comment démarrer avec, puis nous vous montrerons les applications de mise en cache d'objets et de mise en cache de session. Avant que vous en parliez Ron, j'ai posé une question juste sur la diapositive précédente avec le code et la question est de savoir quels sont les changements de code qui sont impliqués afin de configurer le pont ? Doivent-ils écrire du code pour que les données soient répliquées via le pont ? Pas du tout. Nous n'avons pas besoin de code. C'est juste une configuration. Ainsi, vous avez le cache 1 sur le centre de données 1 et le cache 2 sur le centre de données 2. Vous configurez simplement le pont et toutes les données déjà ajoutées par vos applications dans NCache, va être répliqué automatiquement via bridge. Il est donc de la responsabilité de bridge de prendre en charge toute la réplication. Vous n'avez pas besoin d'écrire de code explicitement pour que les données soient répliquées dans les centres de données et lorsque nous disons les types de données, la résolution des conflits, c'est quelque chose qui est également implémenté par défaut, qui est basé sur le temps mais si vous voulez implémenter le vôtre résolution de conflits, si vos exigences commerciales sont que vous évaluez des objets, dans le cas où plusieurs mises à jour arrivent, dans ce cas, vous pouvez implémenter cette interface. Mais en ce qui concerne la réplication des données, c'est la responsabilité de bridge. Vous n'avez pas besoin d'écrire de code pour cela.
Créer des caches
Alors, laissez-moi commencer rapidement, je vais créer un cache.
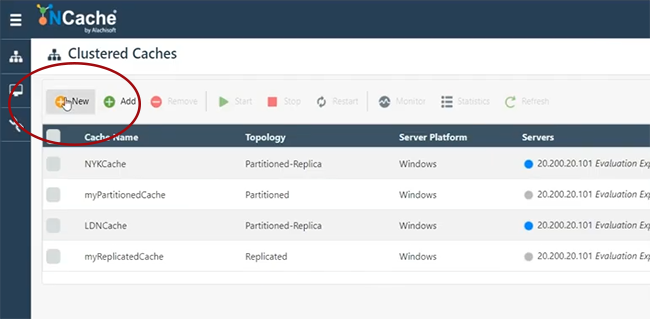
Disons que je vais nommer site1cache ou laissez-moi l'utiliser ici SiteOneCache. Ceci est juste pour vous donner une idée de la façon de démarrer rapidement et de pouvoir créer le pont. Je vais tout garder par défaut, car NCache l'architecture couvre tous ces détails.
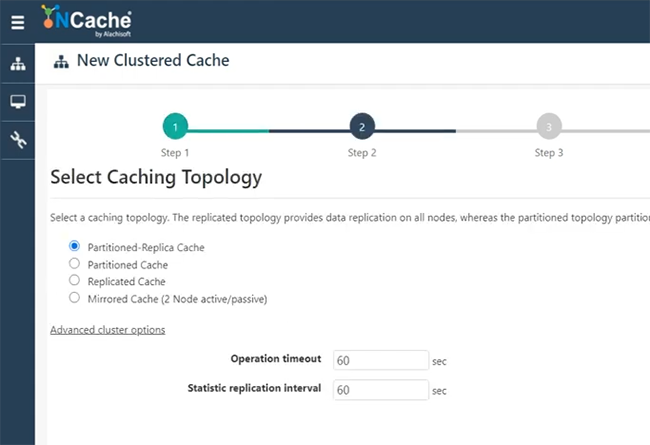
Je vais donc les parcourir rapidement. Partition du cache de réplique, n'importe quel cluster. Réplication asynchrone de la topologie. Je vais choisir 101 et voyons si je peux choisir 102, si c'est disponible. Ce sont mes deux serveurs, pour héberger le pont. Je vais garder tout cela par défaut. Démarrez ceci et le démarrage automatique également. Finir. Donc, mon cache est sur 101 et 102, qui va être créé. Voyons comment cela se passe, puis je créerai un autre cache qui serait sur un ensemble de serveurs distinct, puis j'hébergerai le pont et vous montrerai comment tout cela fonctionnerait. À droite. Nous avons donc SiteOneCache entièrement configuré. Comme vous pouvez le voir, cela a également commencé.
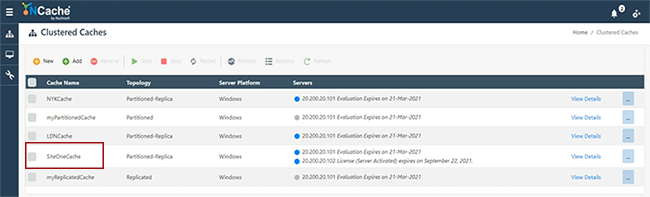
Maintenant, je vais continuer et créer en fait, je vais créer un autre cache, qui est SiteTwoCache. Je pense que je peux l'utiliser. Je jouais avec tout à l'heure. Gardez tout simple et cette fois, je vais donner un ensemble de serveurs distinct, afin que nous le représentions comme un site distinct. Gardez tout par défaut et d'ailleurs notre pont vous permet d'avoir une gestion à distance de tous les sites, à partir des outils de gestion et monétaires vous permettent de gérer réellement tous les sites avec le pont, à partir d'un emplacement central. Donc, si vous avez accès au réseau. S'il existe une liaison WAN disponible entre votre SiteOne et SiteTwo, vous pouvez essentiellement tout gérer. Donc, nous avons SiteTwoCache ici. SiteOneCache ici. 101 102 représentant SiteOneCache. 107 et 108 représentant SiteTwoCache. Maintenant, et ceux-ci sont également lancés.
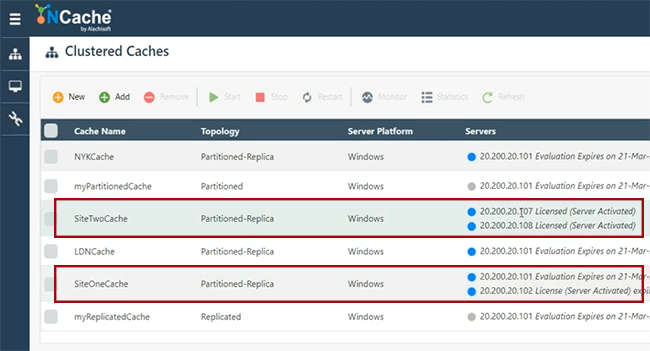
Si je clique sur les statistiques, vous pouvez voir qu'il n'y a pas encore d'objets ajoutés ici. Les données ne sont pas ajoutées dans SiteOneCache ou SiteTwoCache, donc tout va bien. Je lancerais simplement ceci. Je pense que j'ai un problème d'autorisations pour examiner ce compteur. Je pense que je peux, d'accord. Ainsi, vous pouvez voir qu'il n'y a pas encore d'articles disponibles. Je vais maintenant relier ces deux caches à l'aide d'un pont, que je configurerai ensuite.
Créer un pont
Donc, ici, nous allons créer un pont.
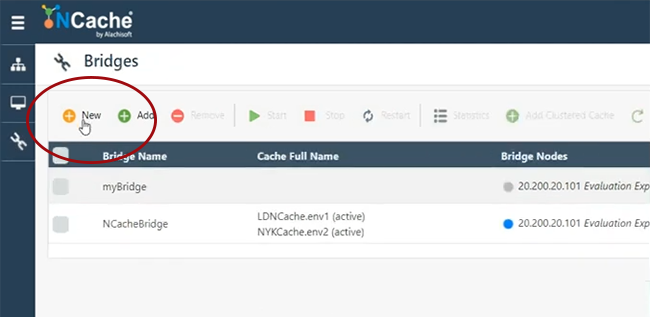
Alors, je dirai simplement NCacheDémoBridge.
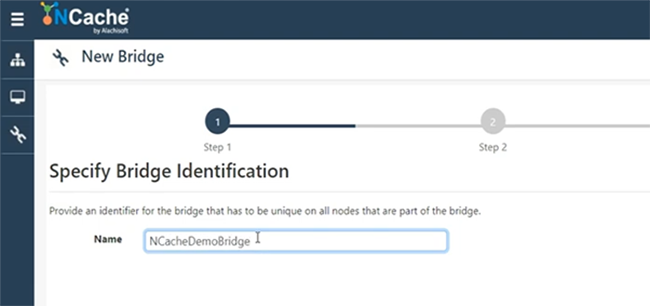
Vous pouvez trouver n'importe quel nom et pont peut être sur n'importe quel serveur. Par exemple, sur 107. Laissez-moi juste donner ma boîte, voilà. Alors, permettez-moi de créer un pont sur 101 et 102. J'ai des problèmes d'autorisations. Alors, laissez-moi juste voir si je peux ajouter 107, sinon, je n'utiliserai qu'un seul serveur pour le pont. Cela nécessite l'ouverture de certains ports. Donc, je pense que tous ces ports sont ouverts sur ma machine. Alors, permettez-moi d'utiliser 101 pour l'instant. Un serveur suffit. Le serveur de sauvegarde n'est pas là mais nous pouvons toujours l'ajouter et je garderai tout par défaut et choisirai Terminer. Démarrage automatique du pont, quand il démarre, c'est aussi une possibilité, puis si je clique sur Afficher les détails sur le pont, par exemple, si je clique ici, cela ouvrira tous les paramètres du pont que nous avons. Ici, vous pouvez spécifier, vous pouvez ajouter plus de nœuds au pont, si nécessaire et vous pouvez également ajouter plus de caches, qui agiraient comme actifs ou passifs. Donc, si je clique sur Ajouter, pour une raison quelconque, cela ne me permet pas d'ajouter. S'il vous plaît, supportez-moi. Je peux glisser une question en attendant. Bien sûr, s'il vous plaît allez-y. Bien sûr, oui, un vient d'arriver. C'est assez simple, il s'agit de savoir comment assurer la transmission sécurisée des données ? Nous avons des fonctionnalités de cryptage disponibles. Donc, si vous avez activé le cryptage ou la sécurité au niveau du cache, le pont obéira à cela. Ainsi, toute transmission transmise entre CacheOne et CacheTwo sera cryptée, si le cryptage et la sécurité sont désactivés, activés. Nous avons donc également des fournisseurs de chiffrement conformes AES, DES, FIPS. Nous prenons également en charge TLS 1.2. Nous avons donc la sécurité au niveau du transport, ainsi que des fonctionnalités de cryptage de la sécurité au niveau de la charge utile. Ainsi, vous pouvez profiter de ces fonctionnalités.
Ajouter des caches au pont
Très bien, donc, je vais sélectionner l'un des caches, SiteOneCache ici, à droite. Donc, je peux choisir qu'il soit actif ou passif. Je vais aller avec Actif et choisir Terminer.
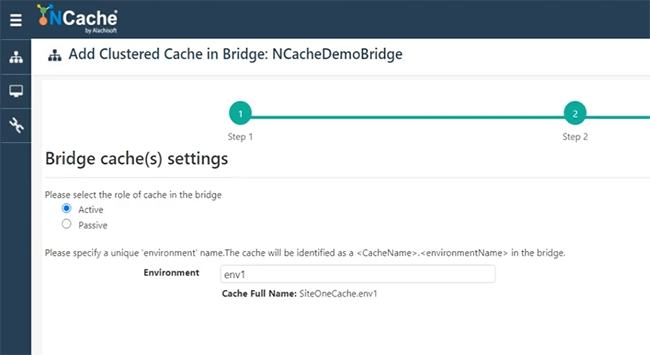
Ainsi, SiteOneCache est ajouté sous le pont. Maintenant, je vais ajouter le deuxième cache, qui provient de la boîte 107. J'espère que je suis en mesure d'ouvrir le gestionnaire de contrôle de service. Je suis. Sélectionnez-le, SiteTwoCache. Rendons-le à nouveau actif. Si vous choisissez Passif, ce sera le cache du site un au site deux, mais si vous choisissez actif, c'est entre le site un et le site deux et entre le site deux et la réplication des données du site un. Choisissons la finition.
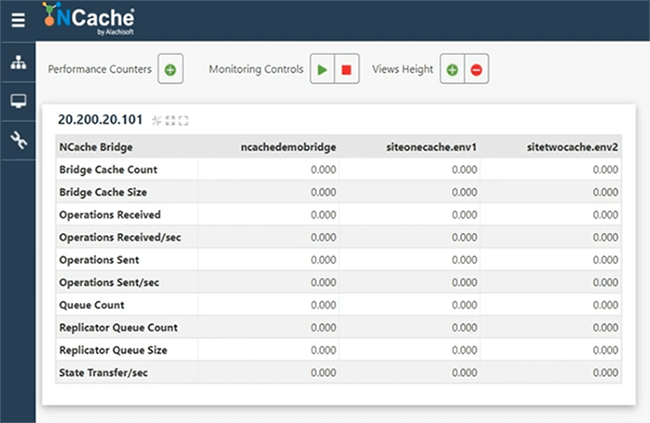
Surveiller les statistiques du pont
Ainsi, vous pouvez également consulter les compteurs de pont. Par exemple, si je viens ici et que j'ouvre les statistiques du pont à partir d'ici, je peux toujours voir les compteurs du pont également. Permettez-moi de commencer en fait cela en premier. Pour une raison quelconque, le système n'est pas très réactif, alors, s'il vous plaît, soyez patient et laissez-moi ouvrir la fenêtre des statistiques. Alors, voici notre pont. Rien n'est encore reproduit parce que nous n'avons aucune charge du tout.
Donc, je vais juste simuler une charge en exécutant un outil de test de stress, siteonecache.
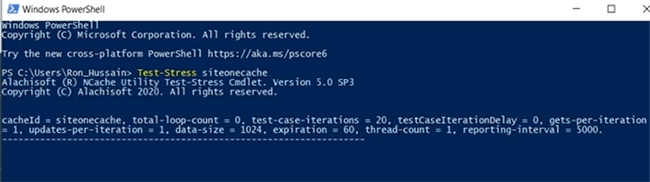
Puisque nous avons des compteurs disponibles, nous aurions un client connecté et commencerions à simuler. Bien que nous l'ayons exécuté uniquement pour SiteOneCache, dès qu'il se connecte. Restez avec moi. Alors, permettez-moi d'ouvrir le moniteur pour vérifier s'il est effectivement connecté au cache ou non. Je pense que c'est. Donc, le pont a une certaine activité, donc, ce qui suggère que le pont prend maintenant les demandes. L'environnement est un peu morose aujourd'hui. Je m'excuse pour cela, mais examinons comment cela se passe. OK, donc, puisque le pont montre de l'activité. La taille du cache de pont augmente, les opérations reçues puis reçues par seconde montrent une activité. Donc, cela signifie essentiellement qu'il réplique les données sur plusieurs sites. Voilà. Donc, nous avons SiteOneCache ici.
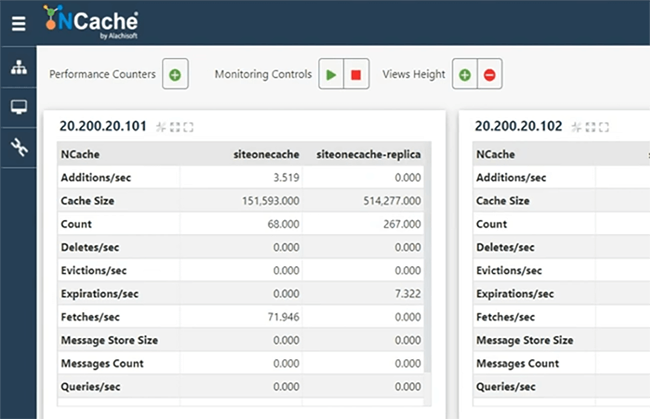
Si nous ouvrons le, permettez-moi de me connecter à notre environnement de démonstration, afin que nous voyions la vue correcte des compteurs à partir de là. Je pense que cela devrait également nous aider à examiner tous les problèmes liés aux autorisations, car le chargement prend énormément de temps et je ne peux pas non plus voir l'activité du compteur. Très bien. Alors, permettez-moi de lancer ce gestionnaire Web ici. Voilà. Ainsi, bien qu'il n'affichait pas de compteurs plus tôt, sur l'écran local, mais lorsque je me suis connecté à SiteTwoCache à partir de ce serveur, le gestionnaire Web est parfaitement en mesure de voir tous les compteurs. Donc, nous comptons activement être répliqués. Je n'ai jamais exécuté d'outil de contraintes dans deux caches, mais il obtient activement des données ici. Maintenant, si j'arrête cela ou même si je continue à fonctionner, je peux également exécuter un outil de stress pour SiteTwoCache et cela répliquerait également les données sur mon SiteOneCache. Donc, cela termine nos tests. Je pense que je devrais également m'en tenir à la télécommande de cet environnement, afin que nous puissions voir l'activité séparément sur les deux environnements. Donc, je vais simplement utiliser siteonecache à partir d'ici, pont à partir d'ici et sitetwocache à partir de là.
Je vais maintenant couvrir certains cas d'utilisation liés à l'application. Alors, s'il vous plaît laissez-moi savoir s'il y a des questions? C'est juste une question assez basique, mais c'était surtout quels environnements supportons-nous ? Encore une fois, je sais que vous en avez mentionné quelques-uns plus tôt, mais je me suis dit que vous pouviez simplement les énumérer tous. Comme je l'ai dit, la seule condition préalable pour NCache est .NET ou .NET Core. Vous pouvez utiliser NCache sur les environnements Windows et Linux, où qu'ils soient disponibles. Cela peut être sur site, cela peut être un environnement cloud, cela peut être Azure, AWS, Google Cloud ou tout autre. Il peut également s'agir d'un environnement hébergé. Il est disponible dans Docker, via Docker Container et vous pouvez utiliser Docker Images pour héberger votre cache et vos applications. Kubernetes est également pris en charge. OpenShift, Kubernetes Service, a mentionné Azure Kubernetes Service, Elastic Kubernetes Service. Ainsi, partout où vous pouvez utiliser Docker, vous pouvez utiliser NCache là-bas et cela se résume à un simple fait que si vous avez .NET Core ou .NET installé, c'est le seul prérequis pour NCache ainsi que NCache peut essentiellement fonctionner sur toutes ces plates-formes, sur tous ces serveurs.
Exécuter un exemple d'application
Alors, laissez-moi courir, bien que j'utilise ce pont ici, j'ai un autre pont qui est disponible. Alors, permettez-moi de lancer une autre application, qui se trouve juste ici. C'est une application Web à charge équilibrée. Nous l'avons conçu de telle manière que nous pouvons acheminer une demande sur un centre de données et si ce centre de données est en panne, la demande suivante ira à l'autre centre de données. Donc, cela vous donnerait essentiellement une idée de la façon de gérer la reprise après sinistre, si vous avez NCache pont activé et vous obtenez toutes vos données mises à disposition.
Donc, tout d'abord, je lancerais ceci à partir d'ici, là où nous avons, laissez-moi simplement ouvrir cela à partir de cette fenêtre, ici même. Alors, permettez-moi de commencer avec l'exemple de mise en cache d'objets. Bon, alors, laissez-moi juste diriger ce LondonCache échantillon, puis permettez-moi également d'ouvrir l'autre échantillon qui est disponible. Je vais donc commencer avec Visual Studio. Exécution des échantillons. Ainsi, dès que ces exemples seraient exécutés, je vous montrerais que vous pouvez essentiellement utiliser la mise en cache d'objets et la demande d'acheminement entre les centres de données selon les besoins.
Ainsi, cela vous donnerait une représentation visuelle des données ajoutées à partir d'un centre de données et récupérées à partir d'un autre et vice versa via notre pont. Très bien, donc, ceci utilise un LondonCache que j'ai configuré ici. Si je vous montre très vite. Donc, nous avons un LondonCache et nous avons NewYorkCache. Donc, deux caches représentant deux centres de données, puis nous avons un pont qui est NCache pont. Il a LondonCache comme CacheOne actif et NYCache comme second. Donc, je vais arrêter le pont pour l'instant. Vous montrer ces deux caches séparément, puis je vais simuler des données et vous montrer comment cela fonctionne dans le cache. Alors, laissez-le s'exécuter et dès qu'il se charge et que cela utilise NYKCache, alors, laissez-moi également le faire tourner. Maintenant que vous savez comment configurer le pont, il est très simple de connecter ces deux caches ensemble en exécutant l'outil de gestion sur n'importe quel boîtier et de pouvoir configurer ce pont. Restez avec moi. Cela ferait tourner certaines instances. C'est terriblement lent aujourd'hui, je m'en excuse. Donc, son événement construit est terminé, donc, il simulera cela sous peu. Bon, c'est donc notre Main.aspx et à l'intérieur de celui-ci, je charge juste quelques objets dans le cache. C'est tout ce que je fais. Par exemple, dans le, à droite, donc, si je vous montre le Main.aspx, il charge en fait certains des objets dans le cache. Donc, l'idée ici est que nous frapperions le site de la région de Londres, puis nous frapperions la région de New York, puis je vous montrerai comment synchroniser les données ajoutées de la région de Londres à New York et vice versa et une représentation visuelle rendrait tout beaucoup plus clair en comparaison. Donc, nous avons les deux côtés en place et en cours d'exécution. Permettez-moi d'en ouvrir un ici et l'autre ici. Maintenant, si j'ajoute disons 10 éléments, ce que cela permet. 10 éléments sont ajoutés. Si je récupère à partir du même cache, cela montre que ces données sont ajoutées à partir de la région britannique et que les clients britanniques sont affichés ici.
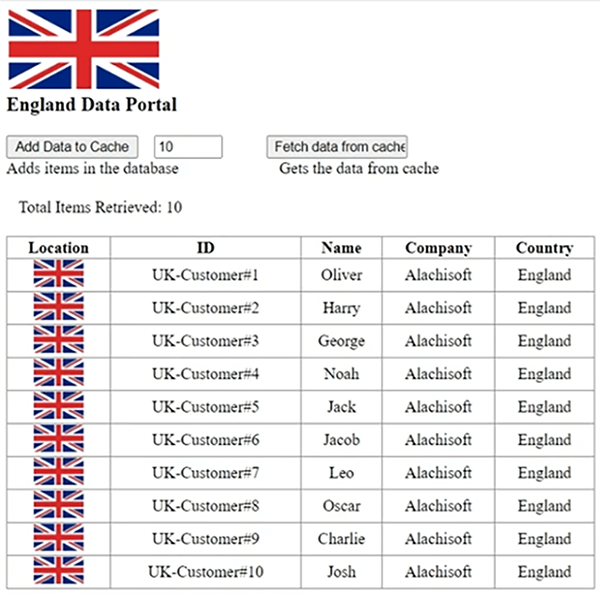
De même, si j'ajoute des données du portail de Londres, aux États-Unis, cela ajoute 10 éléments, puis vous voyez tous ces 10 éléments, mais que se passe-t-il si, si l'utilisateur rebondit et qu'il a besoin que les données des deux régions soient disponibles simultanément ? Donc, ce n'est pas encore possible. Permettez-moi d'ajouter 5 éléments supplémentaires ici, de sorte que ce soit différent en termes de nombres. Donc, nous avons environ 15 articles ici et 10 articles ici. Donc, en un seul clic, si j'active ce pont, d'accord, et que j'ouvre les statistiques, la première chose que fait ce pont, vous savez, est en fait de répliquer toutes les données qui sont déjà dans les caches.
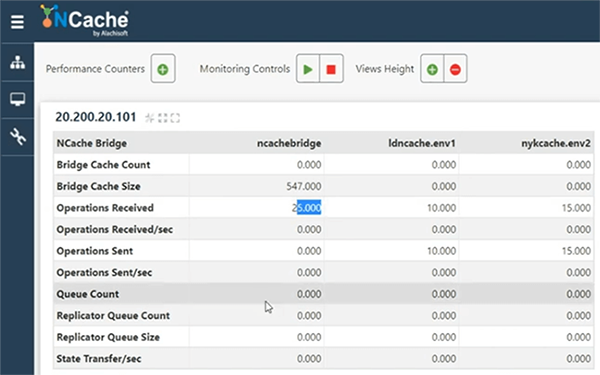
Ainsi, les caches sont déjà connectées, dès que nous avons démarré le pont. Nous avons répliqué le pont, répliquant 25 éléments. Donc, c'est exactement ce que nous avons ajouté. Donc, si j'ouvre les comptoirs de, laisse-moi ouvrir le LondonCache, ainsi que NewYorkCache et les statistiques ouvertes. Pour une raison quelconque, cela prend du temps, mais cela finira par s'ouvrir. Maintenant, nous avons des statistiques ici.
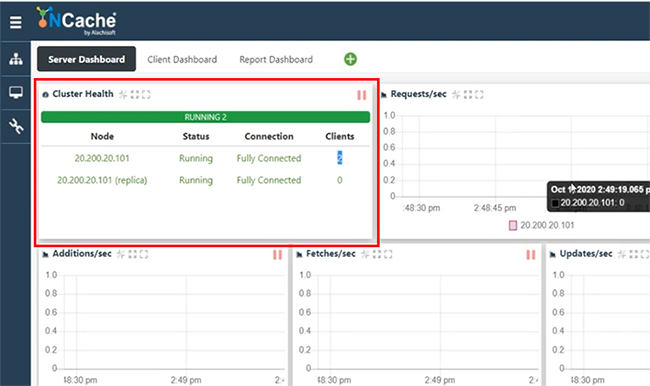
Nous avons des clients connectés et nous avons la valeur de comptage affichée ici. Donc, il affiche environ 25 articles et c'est ce que vous voyez également sur le NewYorkCache. Revenant maintenant à mon application, je garderais la même application en cours d'exécution, mais cette fois, je ne ferais que récupérer les données d'ici et je m'attends à voir tous les éléments du cache. Ainsi, les 25 éléments, Londres, ainsi que les éléments américains récupérés ici parce que le pont a répliqué les données de CacheOne vers CacheTwo et CacheTwo vers CacheOne. Ainsi, 15 éléments ici sont maintenant ajoutés avec 10 éléments supplémentaires à 25 éléments ensemble et si je récupère les données du cache, l'USCache, je vois également tous les éléments de la région des États-Unis. Donc, encore une fois, c'est une transmission bidirectionnelle. Cela pourrait être plus que deux. Il pourrait être actif-passif. Où la transmission unidirectionnelle peut être effectuée ou active-active comme indiqué dans l'exemple d'application.
Maintenant, tout nouvel élément ajouté, disons, 20 éléments supplémentaires ajoutés, disons et vous récupérez d'ici, vous obtenez 45 éléments et si je récupère ces éléments d'ici, vous verriez 45 éléments ici. Donc, c'est en instantané. Tous les éléments ajoutés ici ici, disons, ajouter des données sur le, cela augmenterait le nombre de 45 à 68, mais si je récupère des données à partir d'ici, j'obtiens les mêmes éléments mis à disposition à partir d'ici. Alors, voyez à quelle vitesse il réplique les données entre différents sites. Donc, ces deux caches le sont, et ces caches fonctionnent également sur plusieurs serveurs au moment où nous parlons. Donc, cela termine notre démonstration de mise en cache d'objets.
Réplication des sessions ASP.NET dans les centres de données
Permettez-moi également de vous montrer comment gérer cela si vous utilisez des sessions ASP.NET. En multi-sites, vous savez, vous pouvez également avoir des sessions ASP.NET. Ainsi, par exemple, si cela passe par un équilibreur de charge, j'ajouterais simplement quelques éléments, c'est une application distincte. Nous avons deux serveurs Web, le serveur Web du site un et le serveur Web du site deux, hébergeant la même application dans tous les centres de données. Donc, je vais juste ajouter quelques éléments. Donc, dès qu'il ajoute et laissez-moi arrêter le pont une fois de plus. Si je regarde le panier. Donc, nous avons ajouté un élément. Disons ajouter quelques éléments supplémentaires. Donc, nous avons quelques articles mis à disposition. Maintenant, si je vais sur IIS, vous savez, le site de Londres. Permettez-moi de commencer cela aussi, d'accord. Ramenez ici, vous avez, j'espère vraiment qu'il frappera le site de Londres en priorité. Nous n'avons aucun élément là-bas, alors voyons où cela se termine, puis nous connecterons le pont et vous montrerons que toutes les données que vous ajoutez à partir du site un sont mises à disposition sur le site deux et vice versa. La première demande est généralement lente. Je viens de lancer l'application, voilà. Donc, si nous arrivons ici, nous obtenons 0 articles retournés. Ainsi, ces deux sites ne sont pas synchronisés, bien que votre session utilisateur rebondisse d'un site à l'autre, chaque fois que nous démarrons ou arrêtons le site.
Maintenant, je tournerais simplement sur le pont, sur les mêmes lignes, comme nous l'avons fait plus tôt. À droite. Donc, ça tournerait et ça va commencer. Encore une fois, je vais voir les statistiques. Donc, 69 éléments sont là, vous savez, ils proviennent du test précédent. Mais maintenant, si je reviens sur mon site ici. À droite. Recommençons. Nous avons ajouté quelques éléments. Continuons à faire ça. Par coïncidence, si celui-ci ou s'il tombe en panne à cause d'une panne de courant ou si vous le faites tomber, si je fais tomber le site de Londres, le seul site est, vous savez, le site de New York est toujours opérationnel, donc, si je cliquez simplement sur afficher le panier, les mêmes éléments de données sont mis à disposition à partir du portail américain et des données ont été ajoutées à partir du site britannique. Ainsi, vous pouvez voir les données rebondir d'un site à l'autre et votre utilisateur récupère toujours les données. Maintenant, si même le site revient, vous savez, revient en ligne, il pourra à nouveau récupérer toutes les données de session du cache.
Sessions ASP.NET multi-sites
De même, nous avons des sessions ASP.NET multi-sites. C'est une fonctionnalité distincte. Nous recommandons donc le pont pour vos scénarios de mise en cache d'objets, où nous avons beaucoup de transmission de données en coulisses entre deux caches et nous l'avons vu pour la mise en cache d'objets ainsi que pour la mise en cache de session.

Mais pour la mise en cache de session, nous avons également un cas d'utilisation de mise en cache de session ASP.NET multi-sites. Donc, si je n'utilise pas le pont. Je peux toujours relier ces deux sites ensemble et c'est grâce à une fonctionnalité distincte qui est disponible et pour cela, je vais simplement arrêter le pont. Dès que ça s'arrêtera, je reviendrai ici. Permettez-moi juste d'effacer le contenu, de sorte que nous recommençons et c'est en fait une meilleure façon de synchroniser votre cache pour la mise en cache de session. Raisons à cela, la session est une donnée très transactionnelle. Donc, vous ne voulez pas que vos données de session soient répliquées, même si votre utilisateur ne rebondit pas d'un site à l'autre, n'est-ce pas. Donc, si votre utilisateur est principalement sur un site et parce qu'il s'agit d'un utilisateur humain ayant des sessions ASP.NET. Donc, dans ce cas, il s'agit de données transactionnelles qui sont de nature transitoire, elles ne seraient pas nécessaires sur l'autre site. C'est uniquement basé sur l'utilisateur qui est là et si vous finissez par changer votre utilisateur d'un site à l'autre, cela pourrait être géré avec une réplication des données à la demande. Vous n'avez pas besoin de répliquer toutes les données de session. Par exemple, un débordement se produit lorsqu'un site atteint plus de capacité qu'un autre et que vous souhaitez que les utilisateurs en débordement se rendent sur l'autre site et qu'ils aient déjà créé un objet de session ici. Donc, vous n'avez pas besoin de toutes les sessions là-bas. Vous avez juste besoin des sessions de cet utilisateur particulier. Donc, afin de répondre à ce scénario, nous vous déconseillons d'activer le pont.
Donc, pour cela, nous avons une autre fonctionnalité appelée NCache Séance multi-sites. Ainsi, le fournisseur d'état des sessions ASP.NET multi-régions vous permet de réaliser tout cela, sans utiliser de pont.
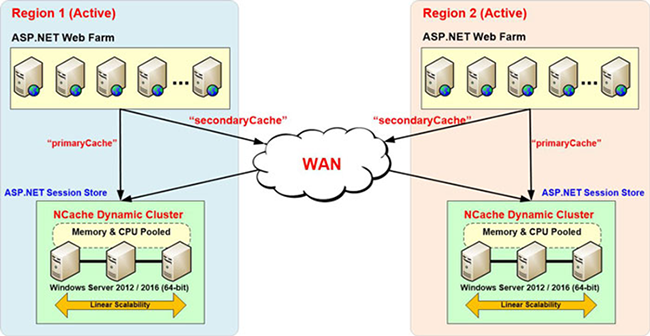
Ainsi, vous avez le cache du site un, qui a des sessions et nous avons le cache du site deux et le site un a l'adresse du cache principal, puis l'adresse du cache de sauvegarde dans la région et de même le cache du site deux a un concept principal et de sauvegarde. Ainsi, si un utilisateur rebondit d'un site à un autre, vos clients de cache qui sont vos serveurs d'application, iraient sur l'autre site à la demande et ils obtiendraient les données de session mises à disposition à partir de là et tout ce dont il a besoin, ce sont des informations sur le cache d'un autre site. , par exemple, nous avons un cache principal et un cache secondaire, Londres, New York et vous pouvez avoir plusieurs caches de sauvegarde. Ainsi, au cas où l'utilisateur de Londres rebondirait sur le site de New York, il reviendrait à LondonCache et récupérait les données et les y conservait et afin de démontrer que je recommencerais avec une application de cache. Par exemple, j'ajoute des données ici, encore une fois, cela utilise LondonCache. Ajoutez des éléments ici. N'oubliez pas que j'ai effacé le contenu du cache, donc nous n'avons aucun élément ici et de la même manière, laissez-moi simplement ouvrir le LondonCache statistiques. Donc, nous n'avons aucun élément ici, jusqu'à ce que la première demande arrive. Disons, ajoutez. Donc, nous avons deux éléments, avec le même nom bien sûr. Ainsi, une session est créée ici. Il n'est pas encore répliqué sur le site de New York, mais nous avons activé la fonction de session multisite. Nous n'avons pas besoin de pont pour cela, car nous voulons que la réplication de session à la demande soit effectuée. Nous avons fait ces configurations, où nous avons un cache principal et un cache secondaire, puis nous avons un fournisseur d'état de session branché.
Donc, c'est juste basé sur les paramètres du fournisseur d'état de session, NCache est capable de gérer le cas d'utilisation de session multi-site sans utiliser de pont et c'est à la demande, donc, c'est beaucoup plus efficace en ce qui concerne les données de session. Donc, ce que je ferais maintenant, je renverrais la demande de session à un autre site en allant sur IIS et j'arrêterais complètement le site de Londres. Bien sûr, je garderais le cache opérationnel et si je le récupérais maintenant. Tout d'abord, il obtiendrait les données du site américain. Les mêmes articles seraient mis à disposition à partir de là et dès qu'il serait terminé, j'ajouterais un autre article et apporterais le LondonCache sauvegarder en ligne. Il s'agit donc d'une réplication à la demande, ce que j'essaie de démontrer. Alors, voyons comment ça se passe. Disons, permettez-moi d'ajouter quelques éléments. Alors, permettez-moi de remettre ce site en ligne. Puisqu'il est collant au site de Londres. Donc, maintenant que j'ai ramené l'utilisateur américain sur le site de Londres, voyons comment ça se passe. Ainsi, les mêmes éléments sont également disponibles sur le site de Londres et les éléments de données ont été ajoutés à partir de la région des États-Unis. Si j'ajoute un élément supplémentaire ici, je pourrais également ajouter ces éléments ici. Permettez-moi de simuler cet échec une fois de plus en arrêtant ce site et voyons s'il rebondit également de l'autre côté. Je pense qu'il y a eu des problèmes liés à la configuration auparavant, mais maintenant que ce site est arrêté. Permettez-moi de voir le panier. J'attends, voilà. Ainsi, la même session est maintenant disponible sur le site américain et rappelez-vous que je n'ai pas de pont configuré ici pour cette fonctionnalité, c'est juste la session multi-site. Le pont est arrêté. Il réplique toujours les données, mais c'est à la demande. Donc, cela le complète en fait.
Pour la mise en cache d'objets et moins de données transactionnelles, de données de référence et de données statiques, nous vous recommandons d'activer le pont et de tirer parti de la réplication active entre les centres de données, mais la session est un cas d'utilisation transactionnel qui a une combinaison de requêtes de lecture et d'écriture. Donc, c'est très lourd pendant que vous mettez à jour les données d'un centre de données à l'autre, les données ont déjà changé sur le centre de données principal et l'utilisateur de la session ne rebondit pas d'un centre de données à l'autre. Ce ne serait que sur un seul site à un moment donné. Vous n'avez donc pas besoin d'une réplication active des données. Vous pouvez avoir une réplication à la demande. Lorsqu'il rebondit de la région un à la région deux, vous devriez pouvoir obtenir les données de session à partir de là et s'il rebondit vers la région un, vous devriez à nouveau pouvoir obtenir les données de session mises à disposition et pour cela, nous vous recommandons d'utiliser notre fonctionnalité de session multi-sites sans pont.
Il y a quelques fonctionnalités avancées dont je parlerais rapidement.
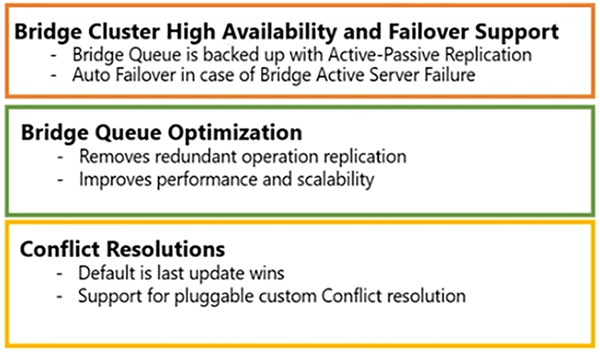
Bridge est hautement disponible. La prise en charge du basculement y est intégrée, tout serveur pont en panne ne subira aucun temps d'arrêt. La file d'attente du pont est très optimisée. C'est rapide. De plus, vous pouvez activer certaines fonctionnalités d'optimisation de la file d'attente, ce qui la rendrait encore plus optimale.

La résolution des conflits y est intégrée. La dernière mise à jour l'emporte, mais si vous souhaitez implémenter votre propre résolution de conflit, vous pouvez utiliser un gestionnaire et vous inscrire auprès de NCache. Ainsi, cette interface peut être appelée, en cas de conflit entre deux clés, où deux mises à jour se produisent en même temps. Alors, NCache vous donnerait le contrôle et vous pouvez vérifier la version de cet élément et décider lequel gagne.
Gestion des sinistres au moment de l'exécution. Zack a d'abord demandé comment rendre le site passif actif, il vous suffit d'acheminer le trafic vers le passif.

Si le site actif tombe en panne et qu'il n'y a pas de temps d'arrêt et que la resynchronisation automatique se produit si l'actif revient. En mode actif-actif, le trafic est acheminé vers les deux sites. Tout site en panne n'aurait pas d'impact, il vous suffit de rediriger le trafic vers l'actif et si l'actif l'autre actif revient en ligne, la resynchronisation se fait automatiquement. Il n'y a aucun retard, aucune intervention manuelle nécessaire. Dans deux ou trois cas actifs-actifs ou plus, si un site actif sans pont tombe en panne, il vous suffit d'utiliser le trafic vers n'importe quel autre site et il n'y aura pas de temps d'arrêt ni de perte de données. Au cas où le site actif du pont tombe en panne, par exemple, si nous avons un site de pont ici.
Si cela tombe en panne, nous avons également une option de site de pont de secours. Ainsi, vous pouvez activer ce site de pont et pour cela, vous pouvez spécifier le pont de sauvegarde pour récupérer la réplication. Ainsi, la réplication s'arrêterait si l'ensemble du site du pont tombait en panne, mais nous avons également la possibilité de sauvegarder le site du pont.
Donc, je veux couvrir ces aspects très rapidement. Je pense que ça devrait suffire pour l'instant. Des questions jusqu'à présent ? Zack, tu peux le récupérer ici. Bien sûr, je sais, nous utilisons la dernière minute ou les deux ici, alors je vais juste ajouter une question qui est arrivée sur ce que vous venez de réviser. Cela avait à voir avec la résolution de conflits et je crois que la question est de savoir quels sont les exemples de résolution de conflits où nous aurions besoin de la mettre en œuvre ? D'accord. En règle générale, la plupart de vos résolutions de conflits sont gérées par défaut, où vous n'avez rien à implémenter. La résolution des conflits basée sur le temps est tout ce dont vous avez besoin. En supposant que vous exécutez des sites actifs-actifs et que vous avez besoin de données d'un centre de données à l'autre, vous avez besoin de mises à jour d'un centre de données à l'autre. Ainsi, la dernière mise à jour gagne. Mais, dans le cas où les données sont plus spécifiques et que vous souhaitez avoir une valeur des données, cela déterminerait quel objet doit être conservé dans le pont. Par exemple, il existe une certaine version ou certaines informations ou un certain numéro de séquence dans la définition d'objet, par exemple, il existe un attribut de version d'un objet. Donc, s'il y a un conflit, vous ne voulez pas que cet objet soit manqué. Donc, vous vérifiez cet objet via le code, vérifiez la version, laquelle doit être conservée, donc, en fonction de la dernière version ou de la dernière version par rapport au temps, elle pourrait être basée sur la version. Il pourrait même être basé sur la valeur de l'objet. Par exemple, il existe un enregistrement de base de données et vous avez un objet qui représente cette base de données et qui a une heure modifiée. Donc, ce n'est pas la mise à jour du cache, c'est une mise à jour de la base de données, mais cette heure de mise à jour fait partie de cet objet et si cet objet a été ajouté en premier, puis un autre objet écrase, vous ne voulez pas cette dernière mise à jour sur la base de données à perdre, n'est-ce pas ? Donc, s'il y a quelque chose à l'intérieur de l'objet et que vous devez prendre une décision en fonction des valeurs d'attribut, vous devez implémenter vous-même la résolution de conflit pour cela. Mais comme je l'ai dit, la plupart des résolutions de conflits seront gérées par défaut via notre option de base de temps par défaut. Ainsi, quelle que soit la dernière mise à jour, elle sera appliquée en tant que dernière mise à jour sur l'élément et cela ne se produit que, rappelez-vous que cette logique de résolution de conflit n'entrera en jeu que s'il y a deux mises à jour ajoutées simultanément dans la file d'attente sur le pont. Bon, donc, le pont reçoit deux mises à jour en même temps. Alors, lequel choisir ? Le site un a ajouté ou mis à jour un élément et le site deux a également ajouté ou mis à jour le même élément. Ainsi, bridge doit maintenant décider lequel conserver dans le cache ou dans la file d'attente et c'est ce qui est également répliqué sur le site un et le site deux. Parce que l'un doit vaincre l'autre. Ainsi, la résolution des conflits basée sur le temps est mise en œuvre par défaut et cela vous permettrait de résoudre la plupart de vos cas.
Je vous laisse, y a-t-il autre chose que nous allons aborder ? Je pense que nous sommes bons. En ce qui concerne le contenu. D'accord. La démonstration est terminée. Très bien, nous nous précipitons ici à la dernière minute, alors, merci à tous ceux qui sont venus. Si vous avez des questions concernant ce webinaire spécifique, n'hésitez pas à nous envoyer un e-mail à support@alachisoft.com Rendez-vous sur notre site Web et téléchargez un essai gratuit de 2 mois NCache Enterprise et utilisez-le dans votre environnement. Si vous souhaitez obtenir de l'aide pour l'intégrer, vous pouvez contacter support@alachisoft.com et si vous avez d'autres questions sur si vous voulez acheter NCache ou pour obtenir des informations sur les licences, n'hésitez pas à contacter sales@alachisoft.com.