NCache Surveillance de la santé et des performances
Webinaire enregistré
Par Ron Hussain
Ce webinaire vidéo est une introduction complète aux options et outils disponibles pour une santé optimale de vos applications exécutées à travers NCache.
Vous en apprendrez davantage sur les options d'alerte de santé et de performance pour le NCache Serveur et NCache Client (côté application), en particulier :
- NCache fonctionnalités d'alerte de santé : présentation et comment les utiliser
- NCache surveillance des performances : présentation et fonctionnalités
- Les outils intégrés pour la surveillance de la santé et des performances
- NCache surveillance via les ressources du système d'exploitation (Windows)
- NCache surveillance via des outils tiers
- Comment déboguer NCache problèmes de santé et de performance
Le sujet que nous avons choisi aujourd'hui est NCache surveillance de la santé et des performances. Donc, en gros, je couvrirai différentes options de surveillance dans NCache dans ce webinaire particulier et je vais l'aborder de deux manières différentes. Je parlerai des options liées à la santé que vous pouvez utiliser, puis de la surveillance des performances et des performances des applications ainsi que NCache performances côté serveur. C'est un NCache sujet basé donc je suppose que vous connaissez déjà quelques détails sur NCache et je partagerai également quelques détails de base, mais l'ordre du jour du webinaire d'aujourd'hui est que nous avons un sujet spécifique en main. C'est à propos de NCache et j'exposerai NCache fonctionnalités en matière de surveillance de la santé et des performances.
NCache Déploiement
Très bien! Donc, tout d'abord, un point de départ est NCache déploiement. Comme je l'ai dit, je suppose que NCache est déjà configuré, mais si ce n'est pas le cas, il s'agit d'un déploiement typique pour NCache.
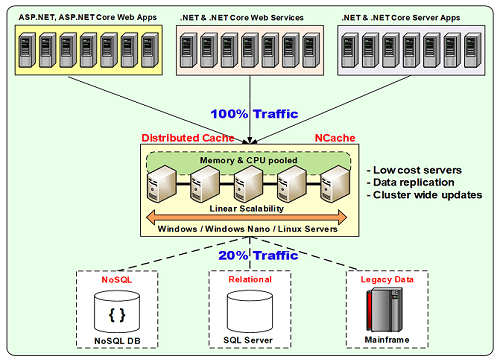
Nous avons un niveau serveur où plusieurs serveurs résident, puis nous avons un niveau application qui se connecte réellement à celui-ci dans un modèle client-serveur. Ainsi, vous pouvez utiliser un niveau de mise en cache distinct où les serveurs sont dédiés à la mise en cache, puis vos applications peuvent s'exécuter sur leur propre niveau respectif. Il peut s'agir d'applications Web ASP.NET, de formulaires Web ou de MVC, de services Web ASP.NET ou de services Web Java, de WCF ou de tout autre, ou de n'importe quelle application serveur principale qui se connecte toutes à NCache. Ainsi, chaque fois que vous avez un tel déploiement en main, où vous avez une mise en cache à partir de NCache puis vos applications se connectent à NCache, il pourrait y avoir plusieurs questions concernant ce qui est mis en cache ? Quel est le débit ? Qu'est-ce que les matrices de performance ? Quel est le gain de performances avec différentes tailles d'objets ou s'il y a des problèmes. Comment débugger ça ?
Donc, c'est tout ce que je vais couvrir aujourd'hui. Je vais parler de différents journaux, de différents événements liés à la santé que vous pouvez capturer et mettre en cache les fonctionnalités de surveillance en ce qui concerne la santé. Je parlerai des différents journaux de débogage que vous pouvez configurer et, en plus, je vous donnerai également une comparaison des performances afin que tout cela soit regroupé dans ce webinaire. Beaucoup de choses vont arriver et tout est pratique.
NCache Configuration requise pour le serveur
Sans plus tarder, commençons réellement et c'est NCache exigences du serveur. Nous couvrons généralement cela dans nos démos et webinaires réguliers. Donc, c'est 8 cœurs ou plus, c'est une configuration minimale recommandée pour NCache mais vous pourriez aussi avoir plus de cœurs. La RAM est selon votre cas d'utilisation, 16 Go ou plus. Il est pris en charge dans tous les environnements Windows ainsi que NCache La partie serveur est concernée, il est recommandé d'utiliser 2012 ou 2016, mais cela peut également fonctionner sur des versions plus anciennes telles que le système d'exploitation 2008, .NET 4.0 ou version ultérieure, 4.6.1 ou 4.6.2 ou 4.5. C'est le plus couramment utilisé. Et, remote clients peuvent être à nouveau sur n'importe quel framework dans n'importe quel environnement Windows. Tous les environnements 32 bits et 64 bits sont également pris en charge.
Environnement de configuration
Donc, cela dit, je vais rapidement sauter et commencer avec ça. Je vais rapidement créer un environnement de démonstration et pour cela j'utiliserai deux nœuds et quelques clients pour m'y connecter. Et, encore une fois, j'utiliserais l'hypothèse que je ne partagerais pas beaucoup de détails sur la façon de créer un cache, quelles sont les configurations, quelles sont les topologies. Je suppose que vous connaissez déjà ce détail. Si ce n'est pas le cas, dans ce cas, retrouvez nos webinaires architecturaux ou démos architecturales que nous organisons chaque mois dans le cadre de NCache ou dans le cadre de webinaires technologiques que nous organisons.
Donc, j'utiliserai l'application Web ASP.NET ainsi qu'une application console qui s'installe avec NCache c'est donc ce que j'ai en tête. Donc, en gros, c'est ce que je vais faire rapidement pour commencer avec ça. Je vais me connecter à mon environnement de développement. Il y a un cache que j'ai déjà configuré, je vais donc créer un nouveau projet, puis vous créez les caches. Donc, je vais juste créer un cache de démonstration et c'est le cache que j'utiliserai pour tous les aspects de surveillance liés aux performances et à la santé de NCache. Je choisirai le cache de réplique de partition, c'est notre plus populaire, donc je vous recommande de choisir également ceci, puis async qui est le mode de réplication entre les serveurs et encore demo1 et demo2.
Toutes ces étapes sont documentées en détail dans nos webinaires et démos existants que vous pouvez consulter sur notre site Web. C'est ainsi que vous spécifiez le port TCP du serveur pour la communication, puis la taille du cluster de cache. J'ai quelque chose en tête en termes d'être averti lorsque le cache est plein et comment réagir à cela. Et je vais simplement désactiver les expulsions pour le moment ou simplement le garder activé. En fait, désactivons-le parce que je montrerais en fait comment un cache devient plein et ce qui est nécessaire dans ce scénario. Les expulsions sont un moyen lorsque le cache est plein, il fait automatiquement de la place pour les nouveaux éléments en supprimant certains éléments du cache. Alors, ne faisons pas ça, choisissez la finition et cela a créé notre cache.
Je vais rapidement ajouter ma box en tant que client, c'est-à-dire mon ordinateur personnel ici même. je dois vérifier si NCache le service a démarré ou non. J'ai joué avec les environnements, alors s'il vous plaît, soyez indulgent avec moi. C'est peut-être... ouais ça a commencé donc je pense que ça s'est ajouté aussi donc, d'accord ! Alors, commençons réellement. Ainsi, notre environnement est mis en place. Ignorez le cache de test pour l'instant car je jouais avec. Concentrez-vous uniquement sur le cache de démonstration. J'ai cliqué dessus. Vous pouvez voir sur le volet de droite. Ce sont tous les paramètres de ce cache particulier. Ce n'est pas encore commencé. Donc, je vais rapidement démarrer cela pour que les deux serveurs soient démarrés. Lorsque vous utilisez simplement le bouton de démarrage à partir d'ici ou d'ici, il démarre en fait le cache sur tous les serveurs de mise en cache. Et, ensuite, je commencerai en fait par quelques étapes de base ; comment savoir que votre cache a démarré ? comment savoir qu'il est en bonne santé et comment savoir s'il montre de l'activité ? Donc, ce sont quelques étapes de base que nous allons suivre maintenant et ensuite nous allons construire dessus. Nous y progresserons en l'amenant à des niveaux étendus, à des niveaux avancés.
Ainsi, le cache a été démarré, donc la première étape que vous pouvez utiliser à partir du gestionnaire ou de la ligne de commande et d'ailleurs tout cela peut également être fait via la ligne de commande, donc ce n'est pas seulement les outils de l'interface graphique. Il existe des outils de ligne de commande qui sont également équipés par rapport à l'interface graphique. Je ferai un clic droit et afin de vérifier la santé du cluster de cache, j'ouvrirais une boîte de connectivité de cluster de vue.
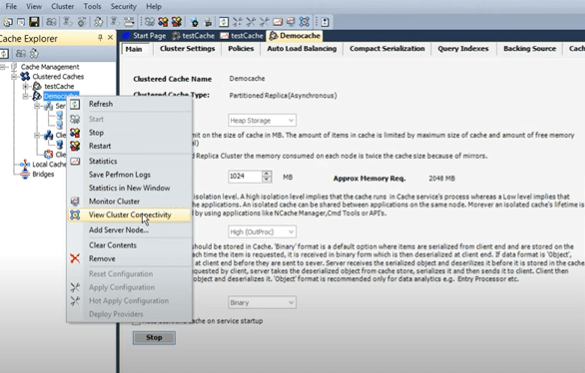
Cela me donne en fait une idée du statut entièrement connecté. Chaque serveur a un serveur actif et un serveur de sauvegarde. Permettez-moi de vous montrer un diagramme pour ce très rapide. Parce que j'ai choisi une topologie, nous avons donc ce cache de réplique de partition et une architecture est que vous avez une partition active là où il existe, puis il y a une partition passive où les répliques d'un autre service sont maintenues.
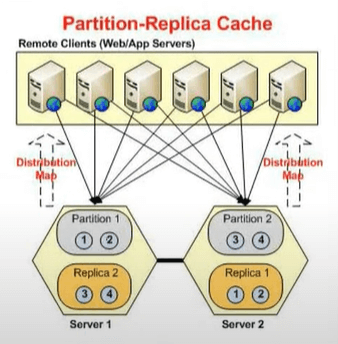
Ainsi, le dos actif du serveur un est ouvert sur le serveur deux et la sauvegarde active du serveur deux sur un. Ce sont des actifs, ce sont des passifs. Ceux-ci deviennent seulement actifs et cela descend, n'est-ce pas ? Donc, si cela tombe en panne, cela devient actif et si cela tombe en panne, la sauvegarde devient active. Ainsi, chaque serveur a deux partitions. Nous avons deux serveurs, nous aurions quatre partitions et c'est exactement ce que vous voyez ici.
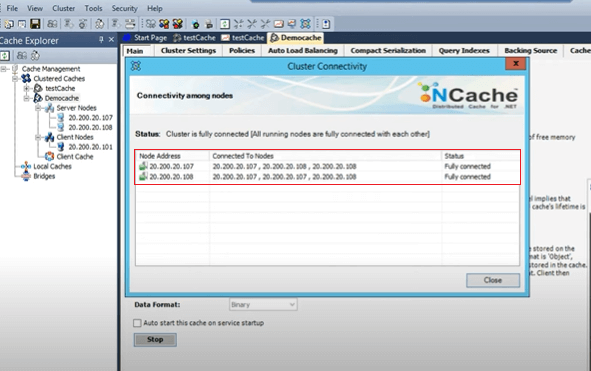
Ainsi, l'un est connecté à sa propre sauvegarde, les autres serveurs actifs et l'autre au service de sauvegarde. Et, le serveur deux est connecté à son propre 107 qui est l'autre serveur, la sauvegarde de l'autre serveur et sa propre sauvegarde. Vous savez que c'est dans un schéma croissant et c'est aussi entièrement connecté. Si vous voyez, permettez-moi maintenant de partager quelques détails. Le message d'état peut être non connecté ou partiellement connecté ou le service de cache n'est pas démarré. Donc, tout cela signifie qu'il y a un problème avec le cluster de cache, donc jusqu'à ce que vous voyiez l'état entièrement connecté, votre cache n'a pas démarré correctement. Donc, c'est le premier point de construction, lorsque vous créez un cache démarré, assurez-vous de vérifier l'état du cache entièrement connecté.
Et, cette sortie peut également être utilisée via les caches de liste. C'est un outil qui vient, permettez-moi de l'amener ici, ce cache. Et, si vous exécutez les caches de liste, avec /a si vous l'exécutez simplement, cela vous donnera simplement les informations locales que le cache de démonstration a démarré. Mais, si vous le faites simplement avec ce cache, par exemple, un commutateur, cela vous donne en fait cette taille de cluster pour 107 ports, 107:7802 pour la sauvegarde. 108:7807 et 708 et compter.
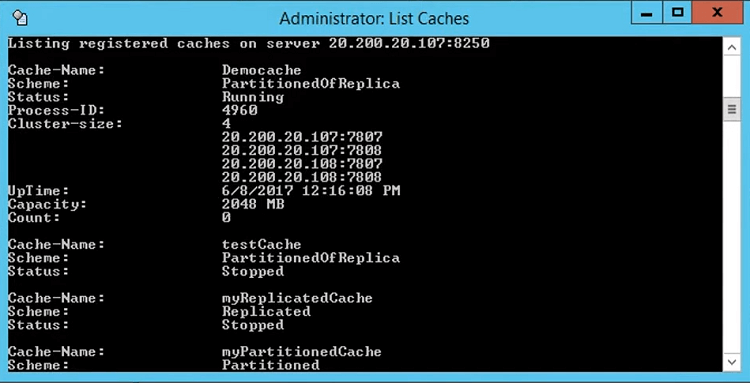
Donc, cela donne une indication saine de cela. Donc, vous devez rechercher ces informations si vous utilisez des caches de liste, sinon la connectivité du cluster de vue vous le donne d'une manière graphique.
Chaque cache a un processus d'hôte de cache, vous avez donc le processus de flux de cache pour le cache de démonstration ainsi que pour le cache de démonstration deux. Et, vous pouvez réellement voir si vous ajoutez un détail par exemple, à l'intérieur de la description de cela, vous pouvez également voir le cache associé. Je pense que c'est dans la ligne de commande, mais si vous ajoutez une colonne de ligne de commande ici, vous pouvez en fait voir le nom du cache. Mais, nous nous appuyons généralement sur les ID de processus parce que c'est ce qui compte pour nous et j'expliquerai plus à ce sujet dans les diapositives à venir. Donc, cela dit, notre cache semble être opérationnel, c'est donc notre premier point de construction.
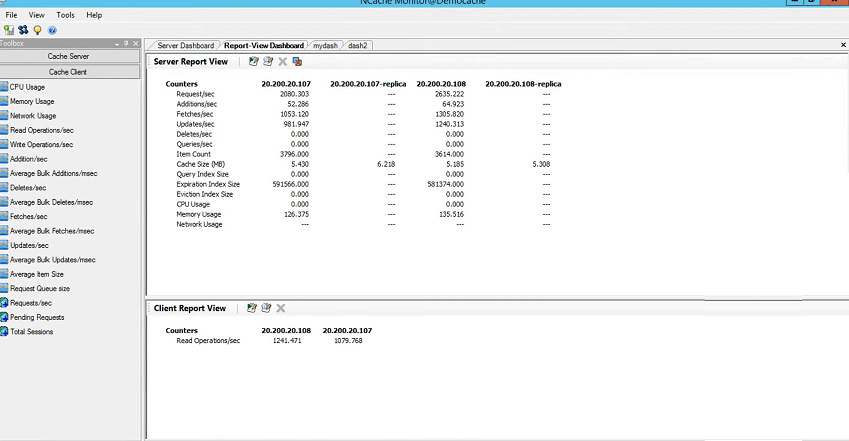
Ensuite, comment vérifier l'activité sur le cache, l'activité de base si le cache prend des requêtes ou non. Donc, pour cela, vous pouvez simplement cliquer avec le bouton droit de la souris et choisir les statistiques. Cela ouvrirait les compteurs perf-mon et ce sont des compteurs côté serveur que vous voyez dans le NCache manager, mais vous pouvez également voir les compteurs côté client, que je couvrirai en détail. J'ai un scénario que je vais vous montrer avec différentes tailles d'objets variables. Je vais vous montrer les moyennes côté client et comment celles-ci sont affectées. Donc, c'est quelque chose que j'ai aligné vers la fin de ce webinaire. Donc, ça arrive aussi. Mais, juste pour vous montrer le côté basique des choses, permettez-moi de l'amener ici, vous avez le cache de démonstration et la réplique du cache de démonstration et la réplique. Aucune activité n'est générée à ce stade car nous n'exécutons aucun test, nous devrons donc le faire et pour cela, je peux simplement exécuter, puisque j'ai ajouté ma boîte en tant que client, je vais exécuter la ligne de commande outil pour commencer avec cela.
Cela peut également prendre différents paramètres, mais pour l'instant, je vais simplement utiliser quelques valeurs de base et vous pouvez voir les demandes par seconde déjà entrantes. Donc, nous avons le serveur un qui prend les demandes, la sauvegarde ne prend pas les demandes mais le nombre est mis à jour mais le serveur deux prend les demandes afin que vous puissiez le voir ici, puis nous avons la sauvegarde du serveur deux qui est en fait une sauvegarde. Ainsi, une partition de sauvegarde est alignée. Donc, cela nous donne en fait une autre confirmation que le cache fonctionne correctement.
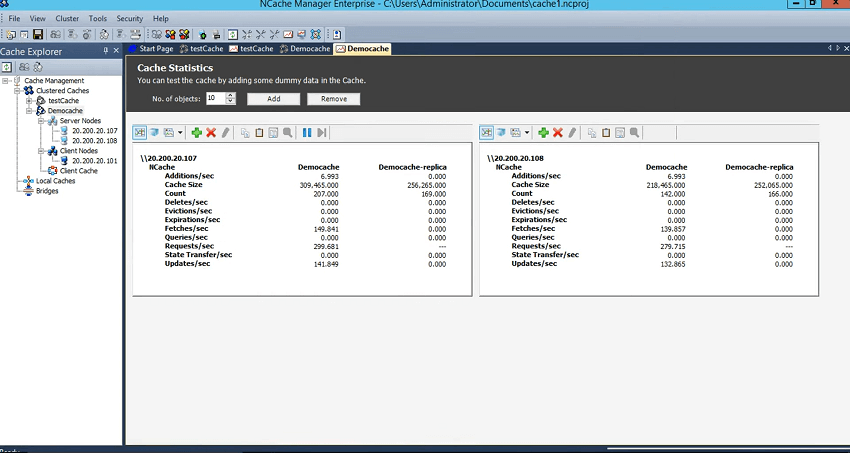
Les demandes sont équitablement réparties. Vous pouvez voir ce compteur de requêtes par seconde ici. Et nous avons également mis à jour les sauvegardes.
Donc, notre première étape, la surveillance de base en ce qui concerne la santé est quelque chose que nos murs autour de cela et ensuite nous pouvons avancer à partir de ce point, nous pourrions voir si quels sont les problèmes qui se posent avec le Cache. Nous pourrions être avertis et je donnerai plus de détails à ce sujet.
Options de surveillance
Je vais rapidement avancer et commencer avec les options de surveillance dans NCache. Donc, c'est ce que j'ai aligné. Hier, j'ai passé beaucoup de temps à les expliquer, puis j'ai reçu un retour selon lequel nous devrions nous concentrer davantage sur la partie pratique, sur le côté pratique des choses. Alors, c'est ce que je vais faire aujourd'hui. Comme je l'ai dit, je vais utiliser une version différente de ce webinaire aujourd'hui.
Surveillance à l'aide de PerfMon Counter
Nous avons donc des compteurs PerfMon. Nous avons le côté serveur et le côté client, je vais vous les montrer. Nous avons des entrées de journal d'événements et en utilisant ces entrées de journal d'événements, nous avons cet outil de surveillance qui vous donne des alertes. Nous avons ces alertes par e-mail qui vous donnent des alertes liées aux e-mails. Et vous pouvez également utiliser un outil tiers pour vous connecter à ces journaux d'événements. Donc, ceux-ci sont assez étendus et je dirais que le facteur le plus important en ce qui concerne l'aspect de la surveillance de NCache.
Surveillance à l'aide des journaux
Et puis nous avons les journaux. Il existe plusieurs façons de configurer les journaux. Nous avons des journaux côté serveur, des journaux côté client, il existe un outil distinct appelé analyseur de journaux. Ensuite, il y a un outil d'analyse de données avec l'aide de l'intégration du pavé de liaison, puis nous avons également les journaux de l'API qui peuvent réellement montrer combien de temps les appels individuels prennent et c'est juste une option plug-and-play. Et, comme je l'ai dit, nous avons des intégrations tierces que vous pouvez utiliser SCOM pour vous connecter à ces journaux, pour vous connecter à ces entrées de journal d'événements, puis nous avons AppDynamics ou tout autre outil tiers, puis vous pouvez utiliser NCache pour ça.
NCache Outils de surveillance – Démo
Aujourd'hui, je vais juste utiliser la démo réelle des différentes avenues, alors commençons par NCache outils de surveillance qui sont installés avec NCache. Maintenant que vous avez configuré une requête, laissez-moi passer à un autre client et utilisons en fait une boîte de serveur. Le serveur peut également utiliser un client pour que vous puissiez réellement le voir. Exécutons un outil de test de stress à partir d'ici, puis exécutons également un outil de test de stress à partir d'ici afin que nous ayons une charge significative, je dirais qu'il s'agit d'une charge importante en ce qui concerne les demandes par seconde. Et, vous pourriez voir environ quinze cents requêtes par seconde et maintenant plus de deux mille requêtes, entre deux et trois mille requêtes par seconde sur le serveur un et le serveur deux.
Maintenant, les exigences de surveillance de base pour le temps réel ainsi que pour la journalisation peuvent être couvertes par notre outil de surveillance. Vous n'avez pas besoin de chercher ailleurs, vous n'avez pas besoin de consulter les journaux, vous n'avez pas besoin d'accéder à vos journaux d'événements ou de vous connecter à des outils tiers. Il y a un outil qui est installé avec NCache Je vous recommande donc de l'utiliser tel quel et je vous ferai une démonstration rapide de cet outil particulier.
Tableaux de bord de surveillance préconfigurés
Je vais cliquer avec le bouton droit de la souris et choisir le cluster de moniteurs, ce qui ouvrira le NCache outil de surveillance fourni avec NCache. Maintenant, ce qui est bien, c'est qu'il surveille vos serveurs ainsi que les clients et qu'il n'est pas nécessaire que ce soit l'un des serveurs ou des clients, cela pourrait être une troisième boîte dans votre réseau. Il n'est pas nécessaire que ce soit l'un des déploiements de cache.
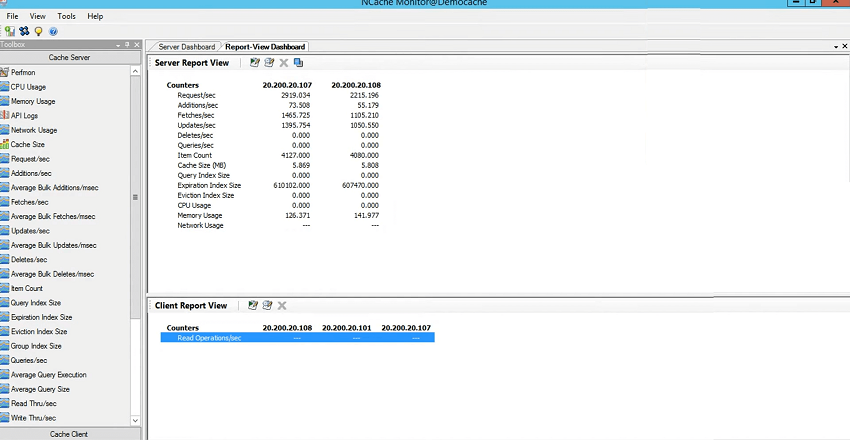
Donc, nous avons 107, 108 et 3 clients. Ma boîte a certaines règles donc elle ne permet pas la surveillance à distance mais vous pourriez voir les compteurs 108 et 107 et tout ce que vous avez à faire est d'aller à la vue, assurez-vous que ces tableaux de bord serveur et client sont cochés. Ma boîte serait une erreur qui est attendue. Mais, vous pourriez voir la même boîte de connectivité indiquant l'état entièrement connecté et, en passant, s'il y avait un changement, cela le changerait en temps réel. C'est la beauté de cet outil de surveillance qu'il affiche tous les statuts en temps réel.
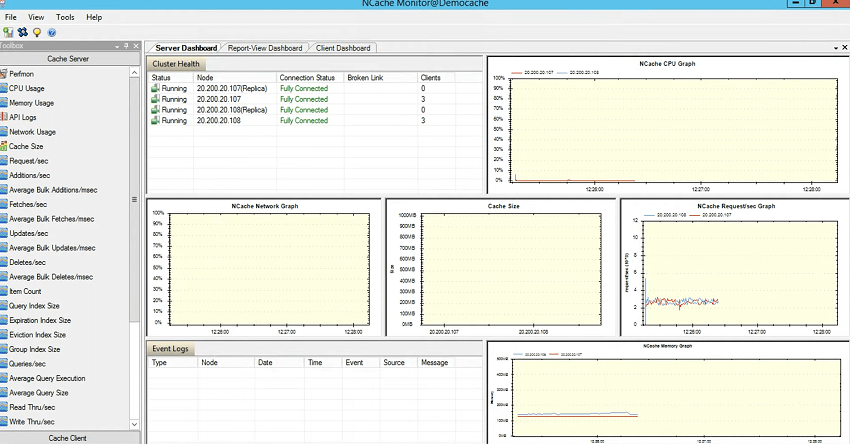
Le graphique CPU, pour le serveur CPU 1 et le serveur 2 sont listés ici. Graphique du réseau, s'il y avait une activité réseau qui serait affichée ici. Graphique de la taille du cache, puis graphique des demandes par seconde. Donc, il n'y a pas d'activité énorme en cours à ce stade en ce qui concerne la taille et le réseau, vous voyez donc des valeurs presque nulles, mais en ce qui concerne les demandes par seconde, vous pouvez voir que c'est un facteur de milliers, donc environ 3,000 108 requêtes par seconde par le serveur un ainsi que par le serveur deux. Et, nous avons aussi la mémoire qui monte. Donc, cela explique en fait que le serveur un et le serveur deux utilisent et qu'il y a trois clients qui y sont connectés et que vous pouvez également voir le tableau de bord client. Ainsi, 107 et XNUMX sont des clients et vous voyez qu'ils envoient des demandes de lecture et qu'il y a également une activité.
Tableaux de bord de surveillance personnalisés
Cela couvre donc l'aspect de surveillance en temps réel de certains tableaux de bord préconfigurés. Mais, vous n'avez pas à compter sur ces derniers. Vous pouvez réellement prendre une longueur d'avance et vous pouvez créer vos propres tableaux de bord et c'est là que le plaisir commence. Je dirai simplement, mon tableau de bord, permettez-moi de faire une chose, juste pour le rendre plus robuste, permettez-moi de vous montrer une autre façon d'ouvrir l'outil de surveillance. Vous ouvrirez également l'outil de surveillance à partir d'ici directement. Tout ce que vous avez à faire est de choisir le serveur et ce sera également un serveur distant et vous n'avez qu'à spécifier le nom du cache. Donc, c'est une autre façon de spécifier et maintenant vous pouvez voir la même chose et maintenant nous avons deux clients parce que j'ai fermé un client. Maintenant, vous verriez en fait plus d'activité en ce qui concerne la demande de CPU car nous n'avons que deux serveurs et deux clients.
De retour, vous pouvez créer vos propres tableaux de bord dans NCache outil de suivi. Et, soit dit en passant, ce sont tous des compteurs Perf-mon. Je vais également vous montrer l'outil de surveillance des performances où vous pouvez également obtenir la même chose en utilisant la surveillance des performances de Windows. Donc, si vous êtes à l'aise avec cela, utilisez-le. Si vous souhaitez simplement utiliser NCache outil de surveillance qui est installé avec NCache, c'est un autre excellent choix. Et, soit dit en passant, c'est une vue en temps réel. Permettez-moi de créer ce tiret. Ainsi, créer votre propre tableau de bord signifie que vous auriez un panneau vide, utilisons la colonne 2 par 2 et cela serait utilisé pour l'un des compteurs de perf-mon que vous voyez sur le côté gauche de l'écran. vous avez l'utilisation du processeur côté serveur, les journaux d'événements, la santé du cluster, les opérations d'écriture, le nombre d'éléments et jusqu'à présent tout va bien. Tout est répertorié ici, puis vous avez également les compteurs côté client.
Ainsi, il vous offre une surveillance personnalisée côté serveur et côté client et, en plus, cela vous donne également un contrôle des performances que vous pouvez réellement faire glisser et déposer ici. Ainsi, vous pouvez ajouter n'importe quel compteur de performances. Il peut s'agir de compteurs de performances Windows, de mémoire, de mémoire cellulaire .NET, de CPU, de tout type de compteurs liés aux performances ou de compteurs liés à la santé pour NCache peut être ajouté ici. Et, je vais en parler en détail. Très bien! Donc, je vais juste créer un autre tiret pour que nous ayons deux tableaux de bord. Appelons-le tiret deux et disons que 2 par 2 est la taille. C'est la norme.
D'accord! Alors, tant qu'on y est, je vais vous montrer rapidement un premier tableau de bord et je vais vous montrer les processus clients qui y sont connectés. Ainsi, cela vous donne un aperçu de tous les processus clients qui sont actuellement connectés à mon cache. Ainsi, vous pouvez venir ici, utiliser cette fenêtre, utiliser l'adresse IP du client, l'ID de processus, le port auquel il est connecté, l'adresse IP du serveur auquel il est connecté et les octets envoyés et reçus. Ainsi, si vous constatez une activité intense de l'une des applications clientes, vous pouvez également voir la connexion ici. Il pourrait y avoir une connexion interrompue. Vous verriez toujours un ID de processus connecté à tous les serveurs, donc 4016 est connecté à 107, 4016 est également connecté à 108. Ainsi, s'il y a des problèmes de connexion, par exemple, votre processus de travail a démarré, il y avait trois serveurs dans le cache et l'un des processus de travail n'a pas pu se connecter au serveur 3, alors comment le savoir ?
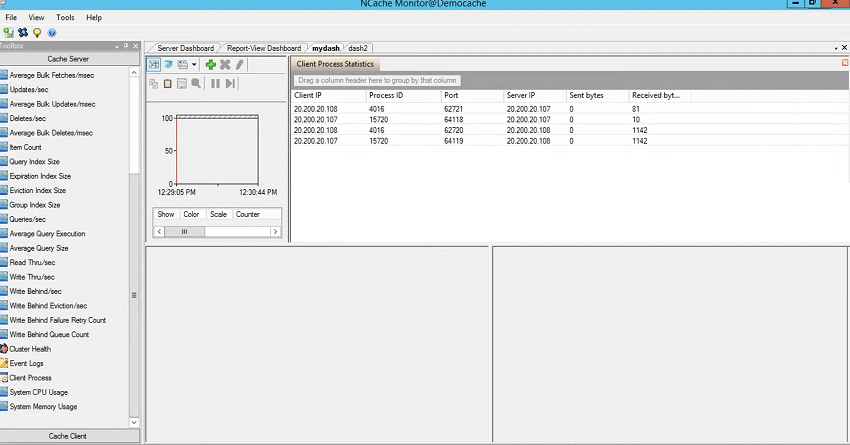
Tout d'abord, il y a des événements qui se déclenchent et j'en parlerai bientôt, c'est donc une manière explicite d'être notifié. Mais, vous voyez s'il y a un comportement anormal, s'il y a une lenteur ou s'il y a une quantité étendue de requêtes car, si un serveur n'est pas connecté par le client, le client enverrait des requêtes à d'autres serveurs et ceux-ci redirigeraient cette requête à cet autre serveur et cela peut prendre du temps. Ainsi, vous pouvez accéder à cet écran, puis choisir l'adresse IP, vous pouvez le démarrer avec l'ID de processus, puis voir s'il existe une connexion qui n'est pas répertoriée ici.
L'autre façon serait le nombre de clients. Ainsi, l'un des serveurs serait ici aurait moins de clients répertoriés dans cette fenêtre par rapport aux autres. Donc, c'est un outil important que je voulais montrer, puis vous pouviez voir des récupérations personnalisées par seconde, des ajouts par seconde, puis sur le tiret deux, vous pouviez passer du côté client, puis vous pouviez voir l'utilisation du réseau de l'utilisation du processeur client du client que vous ne voyez généralement pas dans les tableaux de bord préconfigurés.
Donc, c'est encore une fois pour la surveillance en temps réel. Qu'en est-il des données historiques ? Qu'en est-il de la journalisation ? Donc, cela est également intégré à cet outil. Donc, vous pourriez en fait venir ici et commencer à vous connecter et cela serait en fait, puis vous pourriez également planifier une journalisation et vous pouvez également choisir d'afficher des répliques ici, si c'est une exigence, puis il y a quelques options que vous pouvez jouer . Par exemple, choisissez le taux d'échantillonnage, utilisez le graphique, puis utilisez les journaux d'événements que vous souhaitez réellement voir dans le cache. Donc, cela vous donne la surveillance en temps réel comme je l'ai mentionné. Si le chargement des demandes arrive, vous les verrez. Ensuite, vous pouvez développer ce moment particulier. Le temps qu'il faut pour remplir, puis la fenêtre de ces tableaux de bord individuels qui peuvent également être modifiés et, comme je l'ai dit, il y a un support de connexion pour aller avec.
Donc, cela couvre la démo de base de NCache outil de surveillance et je vous ai donné quelques détails sur certains cas d'utilisation tels que la vérification de la santé, la vérification de la connectivité du client, la requête. La demande serait également ajoutée ici et vous verriez également l'activité sur le serveur. Donc, c'est votre client et c'est votre serveur qui affiche la charge de la demande et en plus vous avez les statistiques et la connectivité du processus client de connectivité, puis vous avez également l'activité du client en ce qui concerne l'utilisation du réseau et du NCP. Vous ne verriez pas le réseau utiliser assez fortement car il n'est pas très intensif pour le moment ou il pourrait y avoir des problèmes d'autorisation que ce tableau de bord n'est pas publié, mais nous allons examiner cela. Mais, jusqu'ici tout va bien, tout semble comme il se doit. Nous avons une certaine activité et les clients et les serveurs interagissent les uns avec les autres de manière saine. Des questions jusqu'à présent ? Ainsi, cela complète notre NCache démo de l'outil de surveillance qui est installé avec NCache.
Très bien! Donc, je vais juste fermer l'outil de surveillance et je vais continuer à faire fonctionner l'outil de test de résistance. Je devrais également utiliser une application Web, mais c'est quelque chose que je ferai plus tard.
Journal des événements et alertes par e-mail - Démo
Ensuite, je vais vous montrer quelques alertes liées à la santé et pour cela, je dois expliquer les entrées du journal des événements qui font partie de votre système, puis sont régulièrement mises à jour chaque fois que vous avez un événement. Alors, allons dans le journal des événements Windows. NCache.. c'est en fait fortement droits et c'est spécifique à l'un des événements. Par exemple, nous avons démarré un cache et chaque journal d'événements pour un système est spécifique à son propre serveur, la vue du cache, les événements de NCache service ou l'hôte de cache pour ce serveur, nous avons donc démarré le cache. La première chose est qu'un processus séparé est lancé, de sorte que c'est ce qui s'est passé ici.
Journalisation de l'Observateur d'événements Windows
Le journal des événements suivant est qu'il s'agit d'un joint de réplique, il a donc démarré et ce joint de réplique, puis vous auriez également démarré le cache de démonstration avec succès sur le cache. Et, puis 108 joint au cache 108 réplique joint au cache et puis ce sont des messages de configuration que nous pouvons ignorer et c'est à peu près tout. Ceux-ci ne sont pas liés à NCache mais en ce qui concerne ces messages, il devrait vous donner des informations complètes sur le journal des événements. Et, permettez-moi de simuler rapidement notre scénario où nous utilisons réellement un cache de test ici et c'est pourquoi c'est ici que je vais juste démarrer l'un des caches. Puisque je suis sur 107, je vais donc commencer 107 et vous verrez des journaux d'événements se propager à ce sujet. Alors, attendons une fois que cela se termine. Alors, ça a commencé. Encore une fois, vous pouvez utiliser une connectivité de cluster de vue et vous pouvez voir qu'un seul service n'a pas démarré mais qu'il n'a aucun statut, il n'est pas connecté car le cache est arrêté, n'est-ce pas? Ainsi, vous pouvez le faire et vous pouvez également le surveiller séparément si nécessaire à l'aide du cluster de moniteurs.
Maintenant, revenons aux journaux d'événements. Donc, maintenant que nous avons fait cela, ils devraient démarrer le cache de test, mais avant que le processus de cache de test ne soit lancé, nous avons 107 répliques. Donc, ce qui se passe, c'est que chaque fois que vous démarrez un cache, le processus de cache est lancé, il y a donc une entrée de journal des événements pour cela, puis il y a une réplique, la boîte réelle démarre, le cache démarre et sa réplique rejoint le cluster de cache. Et, vous avez les informations ajoutées dans le cadre de celui-ci et il y a un ensemble de collecteurs de données qui est réellement lancé mais actuellement ma machine .. Je les ai désactivés, c'est pourquoi nous y arrivons et le cache de test a démarré avec succès c'est l'événement qui vous devriez être intéressé et après cela, votre candidature. Ensuite, il existe des ID d'événement auxquels vous pouvez vous connecter et utiliser n'importe quel autre outil ou utiliser NCache surveillez cela ou l'un des outils pour être averti à ce sujet. Donc, ce sont des journaux d'événements.
Maintenant, puisque ceux-ci sont publiés sur Windows, chaque fois que votre cache démarre, il s'arrête et je vais vous montrer que j'y ajoute un autre nœud. Vous ne serez pas averti via les journaux d'événements et si j'arrête le cache, je serais averti via les journaux d'événements. Si votre cache est plein, vous serez averti. Si le transfert d'état démarre, des problèmes de réseau se produisent, si deux services interrompent la connectivité, chaque fois que vous auriez ces événements mis à jour et que vous le prendriez réellement à partir de là. Donc, encore une fois 107 a rejoint. Le cache a démarré avec succès et maintenant 108 a rejoint le cache de test et la réplique 108 a rejoint le cache de test. Donc, ce sont des événements qui sont à nouveau enregistrés et l'ID d'événement reste le même mais le message est important. Donc, vous êtes prévenu. Et, j'arrêterai rapidement le cache et vous verrez les journaux d'événements se remplir à nouveau.
Ainsi, la majeure partie de notre surveillance par des tiers concerne ces derniers. Donc, maintenant que nous avons arrêté le cache, je vais à nouveau effectuer une actualisation et vous verrez des informations et ce sont des avertissements, n'est-ce pas ? Parce que votre réplique se joint, puis le nœud un ou deux a quitté le cache de test. Donc, c'est une situation alarmante parce que vous l'avez arrêté ou cela pourrait être quelque chose qui se dégrade tout seul. Donc, dans ce cas, vous seriez averti.
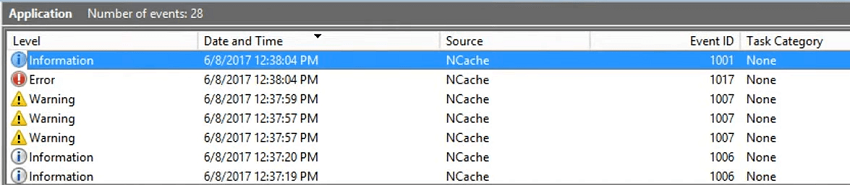
Et puis nous avons une autre réplique 108 en panne, puis la réplique principale 107 est tombée en panne. Et, alors c'est une autre entrée que vous devriez ignorer et tester l'arrêt du cache avec succès. Ainsi, dans un scénario normal, lorsque vous l'arrêteriez, vous obtiendriez également cet événement sécurisé. Bien qu'il y ait des avertissements, mais s'il baisse, vous verrez le niveau de verbosité, le niveau d'erreur ne changera pas en erreur. Ce ne serait plus un avertissement ou ce ne serait plus une information. Notre processus distinct de cache de test a également été arrêté.
Donc, ce sont les informations que vous devriez examiner en utilisant les verrous d'événements Windows et s'il existe une surveillance tierce. Par exemple, nous avions un client qui utilisait la dynamique des applications et nous l'avons aidé à activer ces événements. Donc, tout ce qu'ils avaient à faire était d'activer et de mettre en cache la journalisation des événements en utilisant l'ID d'événement afin que vous puissiez nous contacter. Nous vous donnerons une liste de tous les événements qui NCache journaux et vous le prenez à partir de là. Utilisez également un outil de surveillance tiers pour surveiller et mettre en cache. Donc, je vais fermer ça.
Alertes E-mail
Maintenant, revenons à notre NCache fonctionnalités, nous exposons, nous envoyons des informations dans les journaux d'événements, mais nous n'avons pas attendu là-bas, nous avons également implémenté notre propre système d'alerte et qui était basé sur ces fonctionnalités, cela s'appelle des alertes par e-mail. Maintenant, tout ce que vous avez à faire est d'activer l'alerte par e-mail sur un cache et vous pouvez également le faire sur un cache en cours d'exécution. Et, je peux mettre mes coordonnées ici, par exemple, Ron@alachisoft.com. C'est quelque chose que je dois vérifier à partir d'ici, c'est smtp.gmail.com. J'utilise juste mon personnel… et je fournirai également le port. gardons cette information. Et, j'utiliserai simplement mon login. Je vais utiliser un destinataire.
Je vais simplement m'envoyer un e-mail et je dirai simplement le démarrage du cache ou l'arrêt du cache. La taille devient pleine. Le cluster entre dans un cerveau divisé, il se brise. Le transfert d'état, qui est un processus chaque fois qu'un nœud rejoint ou quitte l'autre serveur doit soit redislui rendre hommage ou rendre les sauvegardes actives. Donc, c'est le scénario. Nœud joint ni nœud à gauche, n'est-ce pas ? Ainsi, vous pourriez être averti et tout ce que vous avez à faire est de venir ici et d'appliquer les configurations.
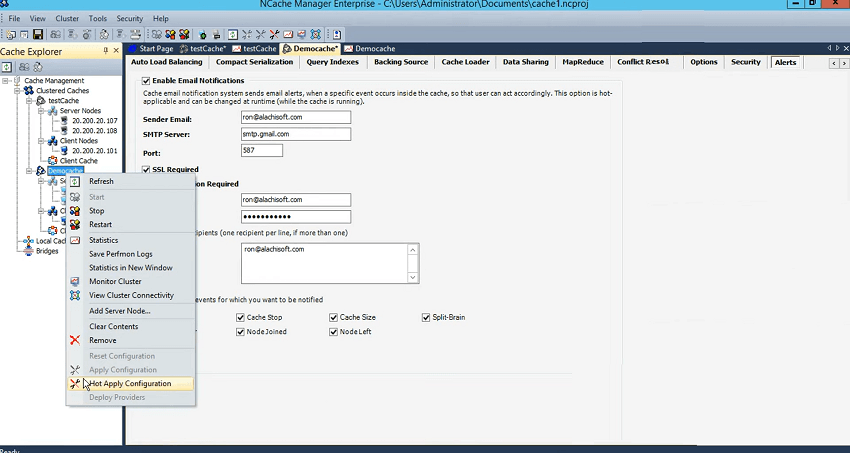
Je ne ferais pas cela pour mon cache. Cette cache ici. Je l'ai déjà fait pour le cache de test et tous les événements configurés. Je dirai simplement appliquer les configurations et je vous montrerai cela à l'aide d'un exemple. Alors, je vais juste commencer ça, non ? Je n'ai commencé que 107 et je ramènerai les journaux d'événements et si je l'actualise, il y a quelques informations donc démarré avec succès. 107 a rejoint. Le cache de test a démarré avec succès. Et, vous pouvez ignorer le message d'erreur.
Qu'en est-il de l'alerte par e-mail ? Donc, pour cela, je vais devoir revenir sur ma machine, juste ici, et j'attends qu'un email soit lancé. Veuillez ignorer celui-ci. Ainsi, vous obtiendrez le même événement sous la forme d'alertes par e-mail, mais cette fois NCache consomme ces événements et envoie une alerte par e-mail aux destinataires qui s'y sont abonnés. Donc, vous avez pu voir que... Première alerte, en fait, il y a beaucoup d'alertes. Donc, nous avons 107 rejoint le cache de test, alors j'utiliserai simplement cette fenêtre, ici. Pas besoin de l'ouvrir. Démarré avec succès. 108 ont rejoint. En fait, ce sont d'anciens événements, alors laissez-moi simplement utiliser 1133, ouais ce sont ceux-là parce que ces alertes étaient ouvertes, donc je faisais des tests sur cette base.
D'accord! Alors, concentrons-nous sur 1133. Ainsi, 107 répliques ont rejoint, puis le test du cache a démarré avec succès. Donc, je reviendrai ici et démarrerai rapidement 108 et vous montrerai que cela déclencherait en fait une alerte par e-mail et des entrées de journal d'événements, côte à côte. Maintenant, c'est notre propre SMTP implémenté mais dans les coulisses, nous utilisons les journaux d'événements, n'est-ce pas ? Donc, vous pouvez aussi le faire. Encore une fois, je vais juste rafraîchir ici. Il y a des entrées, non ? Donc, 106 et 106 se sont à nouveau connectés deux fois et si je reviens ici et que je fais un envoi reçu ici, je devrais pouvoir recevoir deux autres e-mails ou même plus parce que j'ai également un transfert d'État et d'autres événements. S'il y avait des données dans le cache, vous auriez également ces événements. Alors, voilà. Donc, 108 test Cache a démarré Test Cache a démarré avec succès et c'était pour 108, n'est-ce pas ? Donc, je fais juste un envoi reçu une fois de plus pour m'assurer qu'il n'y a plus d'e-mails.
Ainsi, vous pouvez informer vos administrateurs système en cas de problème et simuler un problème. Et si le nœud deux tombe en panne, n'est-ce pas ? Ou, s'il y avait une rupture de connexion. Nous ne pouvons pas vraiment simuler une rupture de connexion ici, mais nous pouvons simuler une panne de nœud et je viens de le faire. Donc, tout d'abord, cela vous montrerait l'événement dans le journal des événements. Il y a des avertissements, non ? Et, voyons si l'alerte par e-mail capte les taquineries ou non. J'espère que c'est assez simple. Je ne fais que mettre en évidence certaines des fonctionnalités de base que vous pouvez simplement utiliser et obtenir le moniteur d'environnement en ce qui concerne la santé. Ainsi, vous pouvez réellement voir que le nœud est parti et que le journal des événements 107, 107 a été généré. Ainsi, vous pouvez mettre une liste de destinataires ici, selon vos besoins ou il peut s'agir d'un groupe, mais assurez-vous de spécifier un destinataire par ligne. Très bien?
Donc, l'autre devrait être support@alachisoft.com ou ça pourrait être kal@alachisoft.com. Donc, pour que vous puissiez réellement le prendre à partir de là. C'est aussi simple que cela de démarrer avec les alertes par e-mail. NCache outil de surveillance. Nous avons couvert les journaux d'événements. Nous avons couvert NCache alertes courrier électronique.
NCache Journaux - Démo
Suivant est NCache logs c'est quelque chose qui est un sujet légèrement avancé mais je vais passer autant de temps que possible sur les logs et nous pourrons partir de là.
Je vais arrêter ce cache car le cache de test est celui que j'utilise et en attendant, pendant que cela s'arrête, laissez-moi simplement ouvrir une application. Je suis désolé pour la structure des dossiers. Je l'ai copié depuis un autre environnement, alors... D'accord ! Alors, permettez-moi d'ouvrir mon studio visuel. Je n'en ai pas besoin pour cette section mais je vais juste la garder ouverte pour que je sois prêt pendant que j'attends que le cache soit arrêté et vous montre les capacités de journalisation à l'intérieur NCache. Ouvrez un site Web. C'est terriblement lent pour une raison quelconque. Je l'attends en attendant laissez-moi revenir ici. Je pense que c'est parce que le studio visuel n'aurait pas dû faire ça. Quoi qu'il en soit, laissez-moi voir si je peux le fermer. Très bien! Donc, pour en revenir à cela, nous avons arrêté le cache de test, n'est-ce pas ?
Donc, je vais vous montrer les capacités de journalisation dans NCache. Ainsi, les journaux sont conservés et ce sont des journaux de cache. Je peux juste me débarrasser de ceux-ci, au moins ceux-ci. Les caches qui sont arrêtés, démarrés, vous pourrez désormais les supprimer. Donc, je vais juste recommencer, ce sont les caches en cours d'exécution, ne supprimez pas vos fichiers journaux. Je viens de le faire pour cette démo particulière. Je vais démarrer un nœud ici et vous montrer les fichiers journaux qui sont créés côté serveur et vous donner quelques détails à ce sujet. Comprendre les fichiers journaux nécessiterait des informations avancées sur le clustering et sur le cadre de NCache. Donc, je vais juste parler de quelques bases.
Analyse des journaux à l'aide de l'outil LogViewer
Maintenant que nous avons créé un cache, démarré le cache de test et la réplique, je l'ai lancé, je vais donc profiter de cette occasion pour ouvrir également les journaux dans la visionneuse de journaux. Donc, si vous allez dans la corbeille, Outils, GUI, il y a cet outil de visualisation de journal qui est installé avec NCache. Vous pouvez utiliser n'importe quel bloc-notes, WordPad, bloc-notes ++, mais c'est quelque chose qui peut réellement vous aider à le trier avec la lecture, l'horodatage, le niveau d'enregistrement, puis à identifier le message également. Alors, je vais juste ouvrir. Il vous emmène dans le même répertoire. Je vais ouvrir le cache de test ici et vous pourrez voir tous les journaux qui s'y trouvent. Donc, nous avons… et c'est un outil très intéressant d'ailleurs. Vous pourriez utiliser différents champs et nœuds, n'est-ce pas ? Et, ensuite, vous pouvez fournir un filtre basé sur cela. Ainsi, un filtre est spécifié ici.
Journaux côté serveur
Donc, je vais juste vous montrer quelques détails de base. Nous avons des paramètres de fonctionnement, 107, 7805. Les répliques seraient toujours 7806. Quel que soit le port que vous spécifiez, le suivant est pour la réplique. Donc, il installe la vue, c'est le premier serveur. Ainsi, 7805 est le seul serveur. Ainsi, chaque fois qu'un serveur démarre, il communique avec la couche de clustering et obtient la vue. Ainsi, il s'installe en s'utilisant lui-même comme coordinateur et vous voyez que 7805 107 utilise sa propre vue. L'ID de vue est 0, puis le membre a rejoint l'événement. Ce sont encore des journaux d'événements qui sont liés. Et, ensuite, vous voyez beaucoup de messages d'information ici, puis la réplique doit avoir rejoint ici. 7805 et vous pouvez voir maintenant qu'il a rejoint 107 avec 7806. Ainsi, la réplique a rejoint.
Ainsi, chaque serveur démarre, il essaie de savoir quels autres serveurs sont disponibles. S'il n'y a pas de serveurs disponibles, il démarrera en tant que premier serveur, puis il démarrera sa réplique et créera un cluster de cache à un nœud. Et, ensuite, vous verrez un cache, des événements de transfert d'état, puis une initialisation du cache. Il a commencé avec succès. Donc, ici, avant cet événement, si vous voyez des messages d'erreur comme ceux-ci, ne vous inquiétez pas car il essaie de se connecter à d'autres serveurs et ces autres serveurs peuvent ne pas encore être là car 108 n'est pas encore démarré. Donc, il a essayé de s'y connecter mais il n'a reçu aucune réponse et à ce stade, je reviendrai ici rapidement et j'utiliserai l'outil de test de résistance, une nouvelle instance de celui-ci. Je vais également vous montrer l'événement de connectivité client. Et, au fait, tous les journaux d'événements, toutes les fenêtres, les alertes par e-mail que nous avons configurées sont toujours intactes, n'est-ce pas ?
Alors, permettez-moi de le fermer et de revenir et, comme je l'ai dit, vous pouvez également l'ouvrir via le bloc-notes ++. Ouvrez simplement le même outil avec le bloc-notes. Maintenant, le même fichier journal est ouvert mais cette fois depuis que nous avons également démarré un client, vers la fin, vous verrez également une boîte connectée au client. Permettez-moi de l'apporter ici. Ainsi, il y a démo à l'IP de la Box, le nom de la box, l'interface graphique et un ID de processus est connecté au cache. Ainsi, un serveur et vous verriez le client connecté. Maintenant, un scénario pourrait être celui de savoir s'il y a un problème dans le cache. Ainsi, vous verriez des messages d'erreur après ce point, c'est une indication de leur message d'erreur. Le message d'erreur avant ceci n'est qu'une découverte. Donc, ceux-ci sont assez normaux jusqu'à ce que vous voyiez beaucoup de tels messages d'erreur. Vous verrez quelques erreurs mais ce ne sont que des messages de découverte.
Maintenant, je vais juste démarrer ce cache et je vais vous montrer les logs de ce serveur ainsi que les logs du serveur et vous montrer comment cela change. Maintenant, cela a été lancé, donc tout ce que j'ai à faire est de revenir ici, voyons s'il se rafraîchit, ce n'est pas le cas, donc je vais juste revenir ici et jeter un œil au journal de ce serveur. Donc, maintenant 108 a été lancé. Ainsi, vous verriez un peu plus d'activité. Où était la dernière entrée ? Permettez-moi d'y jeter un coup d'œil. D'accord! Donc, nous avions cela comme une entrée de perte, n'est-ce pas ? Maintenant, rejoignez l'autorisation de 108 et il a commencé à se joindre. 107 a installé une vue qui a 107, 107 et 108. Et, maintenant, la réplique 108 se joindrait également et vous auriez alors une autre vue qui aurait 107, 107 réplique 108, 108 réplique. Et, vous verriez le transfert d'état commencer et se terminer, donc tout s'est bien passé avec cela. Ainsi, un nouveau serveur s'est joint à nous et tout cela est enregistré dans les journaux d'événements, comme indiqué précédemment.
Maintenant, je vais juste vous montrer les fichiers journaux du serveur 2 afin que vous ayez quelques détails à ce sujet. Comment l'autre serveur… parce que l'autre serveur a démarré et qu'il y en a un qui était déjà là. Donc, je vais vous montrer les fichiers journaux qui commencent généralement par la date de modification afin que vous ayez le dernier fichier en haut. J'espère que oui. Où est le cache de test ? Voilà! Il existe également d'autres caches en cours d'exécution sur cette boîte. Je pense que l'heure ne s'affiche pas correctement, mais laissez-moi jeter un coup d'œil. Très bien! Donc, de toute façon, utilisons ceci comme exemple parce que je manque de temps. Donc, cela prendrait du temps. Ainsi, 108 a commencé et, à ce moment-là, il a effectivement demandé. Donc, ça devait être comme un nœud unique, n'est-ce pas ? Mais, dans ce cas, vous verriez en fait l'autorisation de jointure. Donc, en fait, je ne l'utiliserais pas. Je ne peux pas consulter le fichier journal pour cela, d'accord !
Je sais ce qui se passe. Je regarde le dossier du fichier journal local, donc il doit y avoir les fichiers journaux de se produit, n'est-ce pas? Alors, regardez la date de modification et c'est le fichier journal réel. Je m'en excuse. Très bien! Donc, maintenant, 108 a commencé et vous pouvez voir qu'il a réellement essayé mais qu'il a échoué, vous verrez donc des messages d'erreur ici. Il y a eu cette erreur car ce n'est pas celle-là, sa réplique n'est pas là donc ce n'est pas la première. Donc, vous voyez là 107, c'est déjà commencé donc ça lui a donné la vue et puis les transferts d'état ont commencé. Ce sont des informations sur les compartiments, puis les membres rejoignent le cluster de cache, d'accord !
Donc, c'est aussi simple que cela de jeter un œil aux fichiers journaux mais, comme je l'ai dit, ceux-ci peuvent devenir complexes en fonction du cas d'utilisation, en fonction des problèmes que vous rencontrez et nous avons également les fichiers journaux de réplique. Donc, c'est bien qu'elle partage ses erreurs avec nous et nous pourrions en fait vous aider à mieux comprendre. Ainsi, sur chaque serveur avec les délais, vous pouvez voir les problèmes notés dans les fichiers journaux. Je reviens rapidement. Il me reste encore un peu de temps, alors laissez-moi vous montrer un autre scénario où... et laissez-moi voir si je peux ouvrir l'outil de surveillance.
Journaux d'API
Maintenant, il existe un autre type de fichier journal qui se trouve à l'intérieur de l'outil de surveillance, donc pour ce cache particulier, utilisons-le. Créons un nouveau tableau de bord.
Très bien! s'il y a un scénario où vos serveurs prennent plus de temps pour traiter certaines requêtes ou s'il y a une lenteur, comment y remédier ? Donc, une façon est de regarder les compteurs de performance de votre application ainsi que le NCache perf-mon counters qui est la section suivante de la dernière section pour être honnête. Mais, ce fichier journal peut en fait vous aider à identifier que nous avons ces journaux d'API. Donc, si vous ouvrez simplement l'outil de surveillance et faites glisser et déposez les journaux de l'API, il utilise les Préférences, il enregistre en fait les informations ici, donc je dirai simplement activer la journalisation des fichiers, l'activer et ensuite je pense l'exécuter.
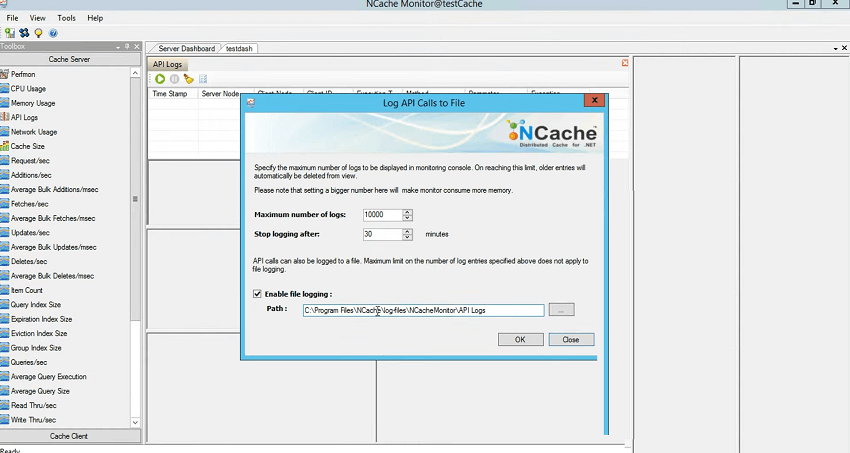
Donc, vous devez simuler le test, disons que votre test prend 15 minutes et que vous reproduisez le problème ou dans votre environnement de production s'il y a un moment précis où vous voyez une lenteur ou vous n'êtes pas sûr de l'application qui cause la lenteur, quel appel est causant de la lenteur, quelle est la méthode dans l'application qui cause la lenteur, vous pouvez en fait l'identifier à l'aide des journaux de l'API. Donc, tout ce que vous avez à faire est de l'exécuter. Il viderait toutes les informations, puis vous l'arrêteriez une fois le problème reproduit, puis vous l'examineriez à travers ceci, où vous voyez l'horodatage. nœud serveur. client d'où provient cette demande, l'ID du client et l'heure d'exécution. Donc, ce temps d'exécution est le facteur le plus important ici. À ce stade, c'est en moins de millisecondes, mais que se passe-t-il si nous simulons la charge et disons à nouveau l'outil de test de stress en utilisant le scénario où le cache de test pour / M 1 024, et cela utiliserait certainement une valeur plus grande, n'est-ce pas ? Vous pouvez voir 0.03, n'est-ce pas ? 0.07 donc… Permettez-moi de fermer les autres outils de contraintes. Ouais! Vous pouvez le voir maintenant, le temps a passé, n'est-ce pas ? 0.02, non ? Et, vous pouvez réellement voir toutes les erreurs qui sont enregistrées côté serveur.
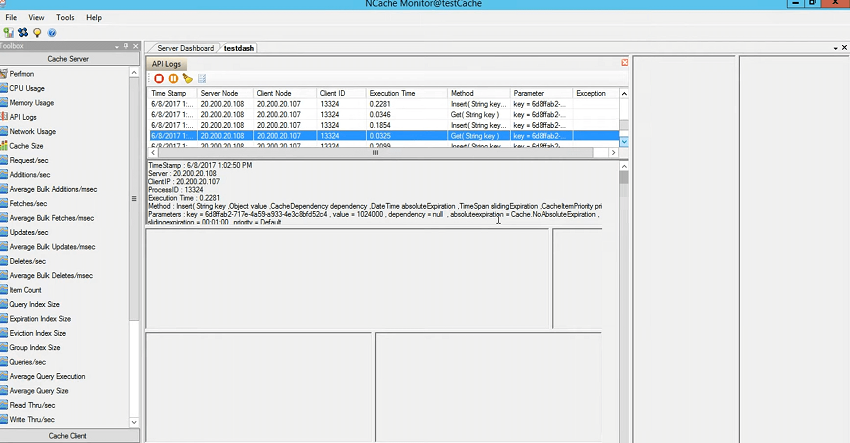
Ainsi, tout échec, échec est quelque chose d'évident qui peut être consigné dans les fichiers journaux, mais la lenteur peut être cartographiée à l'aide de cette fonctionnalité. Et, si je vous ramène ici, dans ce dossier API logs, il y a un fichier log qui garde la trace historique des données. Ainsi, les premières moyennes sont de 0.02, 0.01, puis vers la fin, vous verriez des valeurs augmentées, n'est-ce pas ? Cela vous donne donc une indication par rapport au temps que cet appel particulier est lent. Je dois vérifier la méthode, puis vous devez établir une corrélation avec celle-ci dans votre application. Donc, je pense que c'est quelque chose qui peut être utilisé, nous l'utilisons tout le temps pour déboguer nos environnements clients. Vérifiez l'heure, demandez-leur de reproduire le problème devant nous, activez les journaux, puis en plus, cela peut également être couplé avec les journaux côté client. Dans votre installation client, vous pouvez spécifier les journaux, par exemple, si je vais à la partie client de NCache sur la machine cliente où se trouve le serveur Web, il y a cette activation des journaux, n'est-ce pas ?
Journaux côté client
Ainsi, chaque cache a cet indicateur d'activation des journaux client que vous pouvez activer. Donc, cela créerait également un fichier journal du côté client, un fichier journal similaire à celui que vous avez vu. Donc, je pense que cela aide du côté de la journalisation des choses. Je prendrai 10 minutes de plus, puis je conclurai sur les compteurs de performance car c'est la section la plus importante que nous ayons.
NCache Surveillance des performances (scénarios)
Comment faire le suivi des performances avec le NCache? J'espère que ce n'est pas trop d'informations. Je suis resté basique, mais les scénarios correspondent à vos cas d'utilisation quotidiens.
Surveillance en temps réel via PerfMon
Maintenant, pour en revenir à la surveillance des performances, NCache vous donne deux types de compteurs. Ce sont des compteurs PerfMon, vous pouvez donc simplement dire PerfMon et espérer que le moniteur de performances se trouve à l'intérieur NCache et permettez-moi de fermer ici et d'exécuter un stress très rapide sur cet outil afin de gagner du temps. Donc, si j'ouvre le compteur de performance, nous avons NCache catégorie, non ? En dessous de NCache catégorie, nous avons tous les compteurs dont nous avons besoin. Les moyennes sont très importantes. Cela vous donne le temps moyen pour ajouter, récupérer, insérer dans le cache. Donc, je vais utiliser tout cela, n'est-ce pas ? Et, choisissez Ajouter et choisissez OK, puis je vous montrerai ces moyennes de performances.
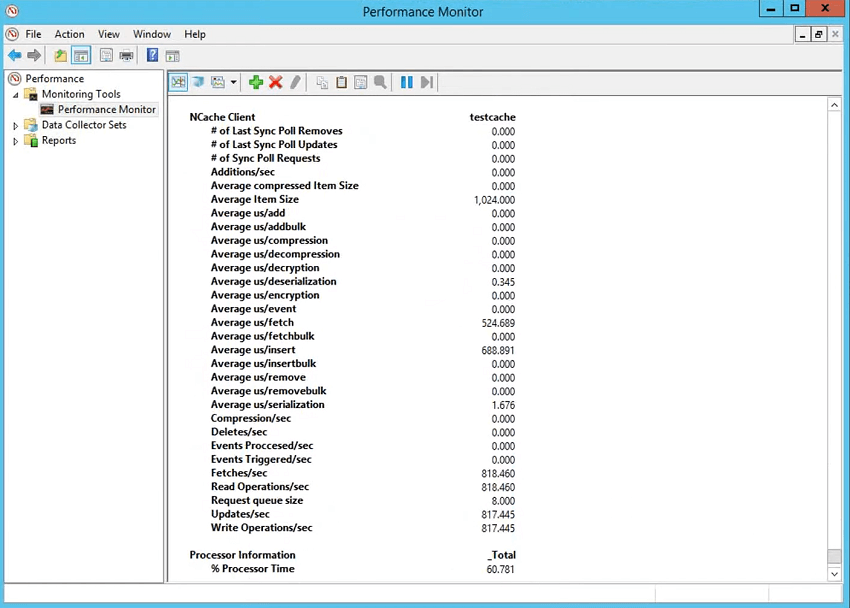
Ainsi, vous voyez que la microseconde moyenne pour l'extraction est de 27 microsecondes, la microseconde moyenne pour l'insertion est de 65 environ. Mais qu'en est-il du client ?
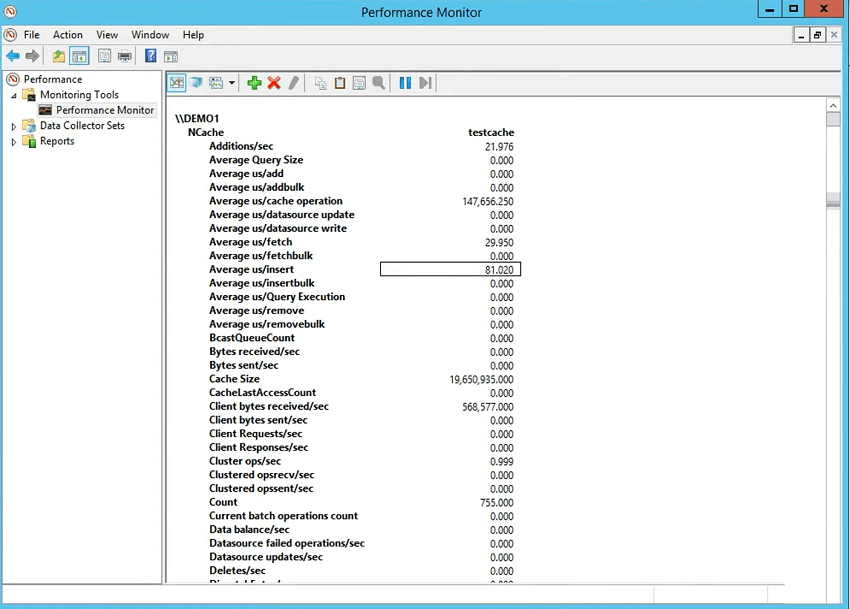
Examinons donc les compteurs côté client qui indiquent combien de temps il faut pour terminer une opération. Alors, tu choisis NCache catégorie client, choisissez test Cache pour le client, puis vous choisissez ajouter. Donc, en dessous, vous verriez NCache également la section client et c'est la plus importante car cela vous donne la NCache estimation des artistes interprètes ou exécutants côté client. Il vous donne la taille de l'élément donc c'est 1024 Il vous donne une microseconde moyenne par récupération 718 et c'est le temps total et l'application pris dans votre application pour sérialiser, si la compression est activée pour compresser, si le cryptage est activé pour crypter puis l'envoyer à travers le fil, a été stocké là-bas afin que le temps du serveur soit inclus, puis il est revenu puis désérialisé. Donc, c'est le temps d'une opération. Pour la récupération, il s'agit simplement de désérialisation. Pour l'insertion, il s'agit également de cette sérialisation et vous pouvez en fait voir la microseconde moyenne par sérialisation pour les insertions et la microseconde moyenne par désérialisation pour les récupérations.
Et, vous pouvez également activer les journaux autour de ceux-ci et c'est ce que je ferais en fait, en ce moment. Je vais voir si je peux ouvrir, pour une raison quelconque, nous devrions vous laisser tomber, mais voyons si je peux le faire. Et, dans ce scénario particulier, ce que j'ai en tête, c'est que j'ai une application Web qui est… D'accord ! cela fait quelque chose de si… J'ai une application Web que j'espérais… OKAY ! Il y a une question. Ces NCache compteurs accessibles à distance ? Bien sûr! J'accède tout le temps aux compteurs du serveur ainsi qu'aux clients, donc si vous avez accès à ces serveurs à distance, l'accès perf-mon est autorisé. Vous pouvez réellement le faire. Donc, pas de problème. Ainsi, c'est généralement un serveur en tant que serveur de surveillance qui s'occupe de toutes ces tâches. J'aurais dû ouvrir le studio visuel au préalable et générer l'application, mais je ne l'ai pas fait, c'est donc ce qui cause le problème. J'espère que cela fonctionnera cette fois. Voilà! Je pense que nous n'en sommes pas là en fait. Alors, permettez-moi de mettre le répertoire de mon projet… S'il vous plaît, soyez indulgent avec moi. Je vais juste prendre une minute. C'est une partie très intéressante. J'ai vraiment envie de le montrer. voyons si cela est capté. Voilà!
Journalisation des ensembles de collecteurs de données PerfMon
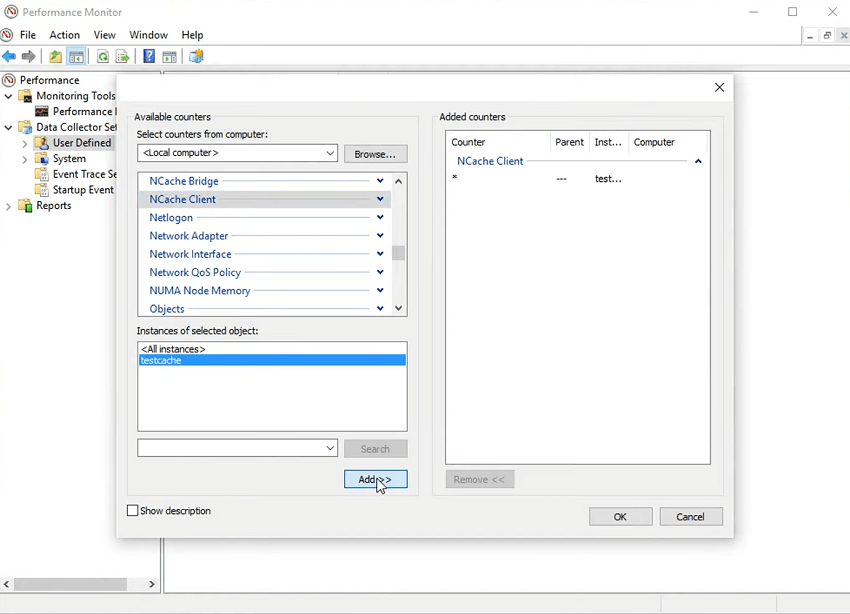
Maintenant, cette application est conçue de telle manière que je vais expérimenter différentes tailles d'objets, n'est-ce pas ? Et, sur cette base, je vais enregistrer les compteurs de performances et vous montrer comment la taille de l'objet augmente et les performances baissent. Donc, cela présenterait en fait un cas d'utilisation dans votre application, comment être averti ou comment savoir quand il y a un problème d'application. Donc, ce que je vais faire, c'est que je vais commencer la journalisation, n'est-ce pas ? Donc, je vais juste utiliser un outil de stress pour vérifier si je peux me connecter à mon cache. Je vais juste prendre cinq dix minutes de plus, alors faites-moi savoir si nous sommes d'accord sur le temps. S'il y a des problèmes, nous pouvons toujours le faire. Donc, je pense que nous sommes bons là-dessus. Je l'ai juste exécuté pour que nous ayons… Donc, cela devrait en fait démarrer mon application. Voilà! Et, maintenant, je vais utiliser ma machine ici. Et, je vais commencer la journalisation des compteurs de perf-mon et pour cela, vous pouvez utiliser l'ensemble de collecteurs d'utilisateurs. Pour la surveillance en temps réel, les compteurs de perf-mon sont là, non ? Sur lesquels vous pouvez réellement cliquer ici et les ajouter dans la vie. Mais cela n'aide vraiment pas à résoudre un problème. Lorsque l'application fonctionne lentement, comment y remédier ?
Donc, je viens de créer un ensemble de collecteurs de données, n'est-ce pas ? Test 11, c'est ça ? J'ai créé manuellement, j'utilise des compteurs de performances et j'utiliserai l'intervalle d'échantillonnage pour être d'une seconde et j'ajouterai NCache compteurs clients pour être précis car c'est ma boîte d'application. Vous pouvez également utiliser une autre chose. Permettez-moi d'ajouter NCache compteurs, NCache client. Permettez-moi d'utiliser l'outil de contraintes une fois de plus pour que ce cache de test soit lancé. Voilà! Ajoutez et je peux fermer l'outil de contraintes maintenant, choisissez d'accord et en attendant, j'espère… D'accord ! Quelque chose s'est passé avec ça.
En tous cas! Donc, je vais rapidement choisir suivant sur cette navigation et choisir un emplacement convivial que je peux choisir, par exemple, utilisons ceci et choisissons OK, Suivant, Enregistrer et Fermer. Et, donc le test 11 a été créé. Vous pourriez en fait venir ici et démarrer l'ensemble de collection et, entre-temps, pour une raison quelconque, mon application Web ne fonctionnait pas. Donc, je vais juste le lancer une fois de plus. Intéressant… D'accord ! Sur le point de montrer ce qui s'est passé. En fait, j'aurais dû le lancer. C'est ce que j'ai fait hier et ça a très bien fonctionné donc je vais juste essayer. Je pense que j'ai un problème de mode pipeline, donc ça ne fonctionnera pas avec ça, donc je vais simplement sauter ça. Ce que je peux faire, c'est que je peux vous montrer les données que j'ai utilisées hier. Donc, si je viens ici, la conception est telle que nous avons trois types de tests, n'est-ce pas ? 10 Ko, 50 Ko, 100 Ko et 10 500 Ko, donc si vous passez par l'objet de 10 Ko, il simule en fait la charge de Get et Inserts de 10 Ko, donc je l'ai exécuté pour 10 Ko, 50 Ko, 100 Ko, 500 Ko et alors je vais enregistrer les compteurs, non ? Donc, à l'intérieur de E, testez-en un.
D'accord! Voilà! Donc, j'ai exécuté ce test et je voulais vraiment montrer les problèmes, donc si je dis simplement contrôle + A, masquez les compteurs sélectionnés, puis pour le cache de test, cela consomme également tous les autres compteurs. Donc, vous vérifiez d'abord la taille moyenne de l'élément, donc le premier test a été exécuté pour 1 kilo-octet 10 kilo-octets à nouveau pour 10 kilo-octets puis pour 50 kilo-octets puis 400 kilo-octets, puis vers la fin, je l'ai exécuté pour 500 kilo-octets. Donc, cela explique la taille de l'article.
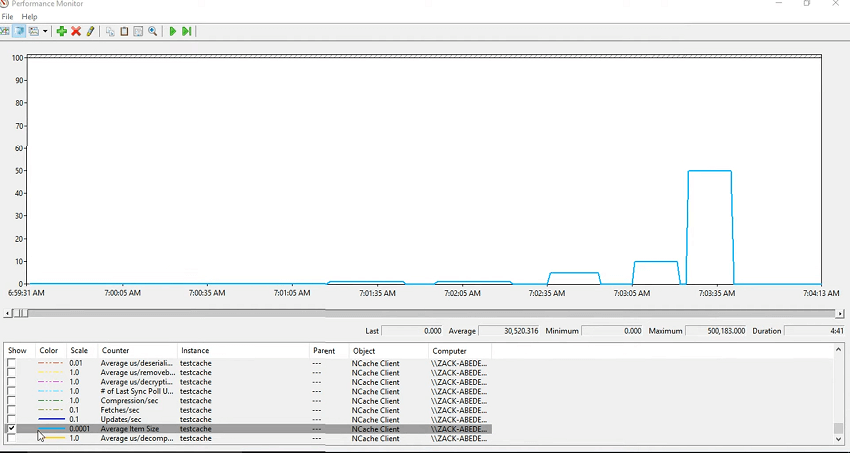
Voyons maintenant le temps moyen qu'il a fallu pour la récupération. Il existe donc un compteur appelé microseconde moyenne par extraction. Donc, vous avez pu voir qu'il a fallu que cela augmente sur une période de temps, n'est-ce pas ? Donc, récupérez puis idem pour ceux-ci car c'est la même chose et ensuite, lorsque vous avez ajouté la taille de l'élément, elle a augmenté. Le temps nécessaire pour récupérer cet élément augmente également avec lui. Mais, qu'en est-il du, puisque vous le récupérez, il devrait donc y avoir une surcharge de désérialisation. Donc, c'est couvert ici. Ainsi, la plupart du temps est réellement consacré à la désérialisation de cela afin que vous puissiez réellement tracer la désérialisation à côté de cela. Donc, ceux-ci ont passé la plupart du temps dans la désérialisation et c'est pourquoi c'est lent.
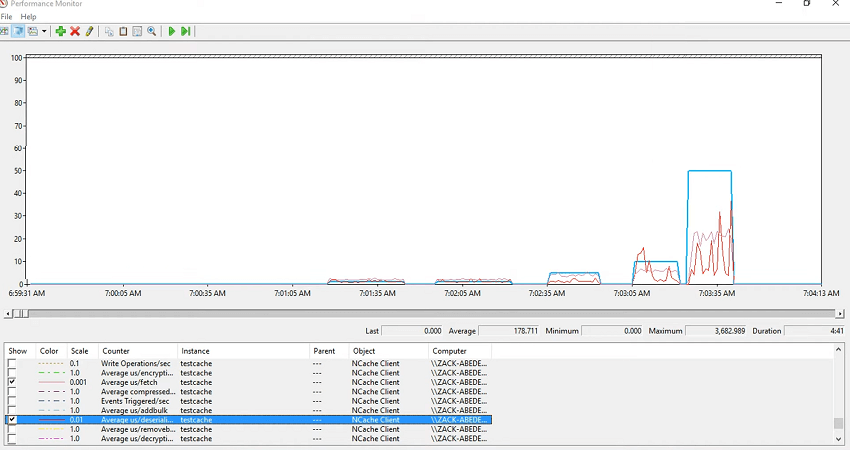
Maintenant, je vais juste regarder les moyennes d'inserts, la microseconde moyenne par insert et vous pourriez voir que cela varierait également avec… Et voilà ! Ainsi, l'insertion prend un certain temps et au fur et à mesure que vous ajoutez la taille de l'article, l'insertion prend du temps. Donc, dans votre application, si vous voyez que l'application ralentit, n'est-ce pas ? Donc, vous enregistrez ces compteurs et vous vérifiez simplement si c'est la sérialisation, c'est la désérialisation, c'est la récupération ou c'est l'insertion ou c'est la suppression ou c'est la taille de la file d'attente des demandes qui augmente réellement. Ainsi, chaque fois qu'il y a une activité, il y a des éléments dans la taille de la file d'attente des demandes et vous verriez que ceux-ci seraient effacés à chaque fois que vous traiteriez cela. Donc, pour les insertions, regardons la microseconde moyenne par sérialisation, c'est donc la surcharge. Permettez-moi de le rendre rouge et coloré et vous pourrez voir que c'est la sérialisation qui a en fait un impact sur les moyennes.
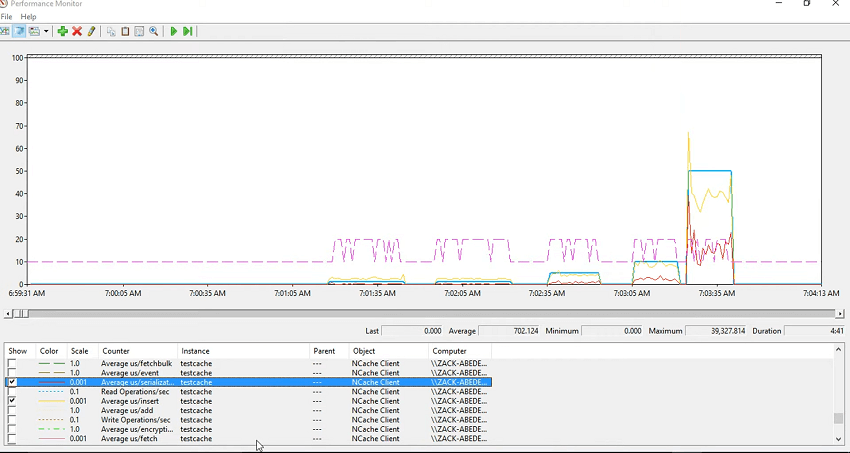
Ainsi, la microseconde moyenne globale par insertion, extraction, suppression, côté client, vous donne une estimation des performances de votre application et, en même temps, vous pouvez enregistrer ces compteurs, puis y jeter un coup d'œil. Malheureusement, je n'ai pas pu exécuter mon application, mais cela date d'hier. J'ai eu un webinaire hier où je l'ai exécuté avec succès et nous l'avons exécuté avec 10 Ko à nouveau 10 Ko, 50 Ko, 100 Ko et 500 kilo-octets. Ainsi, nous pourrions voir la différence variable entre les performances et c'est un moyen de résoudre tous les problèmes de performances que vous vérifiez et cachez les compteurs et cela doit être couplé avec vos compteurs d'application afin que vous ayez toujours besoin que vos compteurs d'application soient sélectionnés à côté de cela.
Par exemple, vous pourriez voir des compteurs ASP.NET pour une application Web, n'est-ce pas ? Applications ASP.NET. En règle générale, pour la mémoire .NET CLR, nous voyons également s'il existe une application de conflit de mémoire qui peut tomber en panne. Ainsi, vous pouvez enregistrer les compteurs système, puis enregistrer NCache compteurs comme je l'ai fait, puis prenez-le à partir de là pour terminer nos sections de surveillance des performances.
Conclusion
Nous sommes à environ cinq minutes au-dessus de notre marqueur de temps habituel. J'espère que ça va à cause des problèmes. Il s'agit d'un webinaire pratique, donc on s'attend à ce que vous voyiez de tels problèmes, mais juste pour résumer, nous avons créé un cache, nous vous avons montré le NCache outil de surveillance, santé, entrées du journal des événements, alertes par e-mail, NCache logs, outil d'analyse de logs, logs API côté client, puis je vous ai également montré les compteurs perf-mon qui sont disponibles côté serveur. Les compteurs côté serveur sont là pour les statistiques côté serveur et les compteurs côté client sont là pour les statistiques côté clients. Je n'ai pas passé beaucoup de temps à expliquer ces compteurs. J'aurais dû le faire, mais je le ferai lors de notre prochain webinaire sur le même sujet.
Et, vers la fin, je vous ai montré comment identifier les problèmes en utilisant les pointes ou en utilisant la journalisation du compteur perf-mon avec le NCache. J'espère que c'était instructif, c'était intéressant.