Six raisons pour lesquelles NCache est mieux que Redis
Webinaire enregistré
Par Iqbal Khan
Apprener comment Redis ainsi que NCache comparer les uns avec les autres au niveau des fonctionnalités. L'objectif de ce webinaire est de faciliter et d'accélérer votre tâche de comparaison des deux produits.
Le webinaire couvre les points suivants:
- Différents domaines fonctionnels du produit.
- Quel soutien faire Redis ainsi que NCache fournir dans chaque domaine de fonctionnalité ?
- Quels sont les points forts de NCache plus de Redis et vice versa?
NCache est un cache distribué In-Memory Open Source (licence Apache 2.0) populaire pour .NET. NCache est couramment utilisé pour la mise en cache des données d'application, le stockage d'état de session ASP.NET et le partage de données d'exécution de style pub/sub via des événements.
Redis est également un magasin de structure de données en mémoire Open Source (licence BSD) populaire utilisé comme base de données, cache et courtier de messages. Redis est très populaire sur Linux mais a récemment attiré l'attention sur Azure en raison de la promotion de Microsoft.
Vue d’ensemble
Salut tout le monde, je m'appelle Iqbal Khan et je suis un évangéliste de la technologie à Alachisoft. Alachisoft est une société de logiciels basée dans la baie de San Francisco et est le créateur du populaire NCache produit, qui est un cache distribué open source pour .NET. Alachisoft est aussi le créateur de NosDB, qui est une base de données open source no SQL pour .NET. Aujourd'hui, je vais parler de six raisons pour lesquelles NCache est mieux que Redis pour les applications .NET. Redis, comme vous le savez, est développé par Redis labs et il a été choisi par Microsoft pour Azure. La raison principale du choix était que Redis offre un support multiplateforme et de nombreuses langues différentes, tandis que NCache est purement axé sur .NET. Alors, commençons.
Cache distribué
Avant d'entrer dans les comparaisons, permettez-moi d'abord de vous donner une brève introduction de ce qu'est la mise en cache distribuée et pourquoi en avez-vous besoin et quel problème résout-elle. La mise en cache distribuée est en fait utilisée pour aider à améliorer l'évolutivité de vos applications. Comme vous le savez, si vous disposez d'une application Web ou d'une application de services Web ou de toute application serveur, vous pouvez ajouter d'autres serveurs au niveau application. Habituellement, les architectures d'application permettent de le faire de manière très transparente. Mais vous ne pouvez pas faire la même chose au niveau de la base de données, en particulier si vous utilisez une base de données relationnelle ou des données mainframe héritées. Vous pouvez le faire sans SQL. Mais vous savez, dans la majorité des cas, vous devez utiliser des bases de données relationnelles pour des raisons à la fois techniques et commerciales.
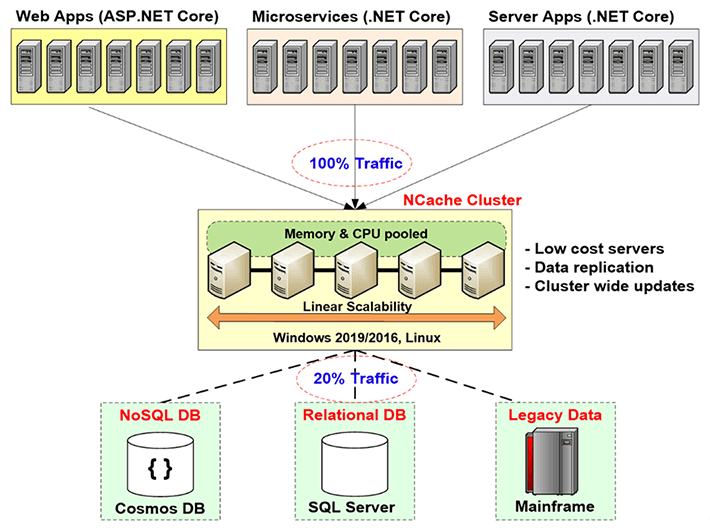
Donc, vous devez résoudre ce goulot d'étranglement d'évolutivité que les bases de données relationnelles ou le mainframe hérité vous donnent via la mise en cache distribuée, et la façon dont vous le faites est de créer un niveau de mise en cache entre le niveau d'application et la base de données. Ce niveau de mise en cache se compose de deux serveurs ou plus. Ce sont généralement des serveurs à bas prix. En cas de NCache, la configuration typique est une machine quadricœur à double processeur, avec 16 à 32 Go de RAM et une à deux cartes réseau, dont la vitesse est comprise entre 1 et 10 gigabits. Ces serveurs de mise en cache forment un cluster basé sur TCP en cas de NCache et de regrouper les ressources de tous ces serveurs en une seule capacité logique. De cette façon, au fur et à mesure que vous grandissez, le niveau application, disons si vous avez de plus en plus de trafic ou de plus en plus de charge de transaction, vous pouvez ajouter plus de serveurs au niveau application. Vous pouvez également ajouter d'autres serveurs au niveau de la mise en cache. En règle générale, vous conservez un rapport de 4 pour 1 ou de 5 pour 1 entre le niveau d'application et le niveau de mise en cache.
Ainsi, à cause de cela, le cache distribué ne devient jamais un goulot d'étranglement. Ainsi, vous pouvez commencer à mettre en cache les données d'application ici et réduire le trafic vers la base de données. L'objectif est qu'environ 80 % de votre trafic aille dans le cache et qu'environ 20 % du trafic, qui correspond généralement à vos mises à jour, aillent dans la base de données. Et si vous faites cela, votre application ne sera jamais confrontée à un goulot d'étranglement d'évolutivité.
Utilisations courantes du cache distribué
D'accord, en gardant à l'esprit cet avantage d'une mise en cache distribuée, parlons des différents cas d'utilisation que vous connaissez, des différentes situations dans lesquelles vous pouvez utiliser un cache distribué.
Mise en cache des données d'application
Le premier est la mise en cache des données d'application, qui est identique à ce que je viens d'expliquer où vous mettez en cache les données qui résident dans votre base de données, afin que vous puissiez améliorer les performances et l'évolutivité. La principale chose à garder à l'esprit pour la mise en cache des données d'une application est que vos données existent désormais à deux endroits. Il existe dans votre base de données qui est la source de données principale et il existe également dans le niveau de mise en cache et lorsque cela se produit, la chose la plus importante que vous devez garder à l'esprit est que, vous savez, le plus gros souci qui vient est, vous savez , le cache va-t-il devenir périmé ? Le cache va-t-il avoir une version plus ancienne des données, même si les données ont changé dans la base de données. Si cette situation se produit, alors bien sûr vous avez un gros problème, et beaucoup de gens à cause de cette peur des problèmes d'intégrité des données, ils ne mettent en cache que des données en lecture seule. Eh bien, les données en lecture seule constituent un très petit sous-ensemble des données totales que vous devez mettre en cache et représentent environ dix à quinze pour cent des données.
Le véritable avantage réside dans le fait que vous pouvez commencer à mettre en cache les données transactionnelles. Ce sont vos clients, vos activités, votre historique, vous savez, toutes sortes de données qui sont créées au moment de l'exécution et qui changent très fréquemment, vous devez toujours mettre en cache ces données, mais vous devez les mettre en cache de manière à ce que le cache toujours reste frais. Donc, c'est le premier cas d'utilisation, et nous y reviendrons.
Mise en cache spécifique à ASP.NET
Le deuxième cas d'utilisation concerne la mise en cache spécifique à ASP.NET, où vous mettez en cache l'état de la session, l'état de la vue et si vous n'avez pas le framework MVC et une sortie de page. Dans cette situation, vous mettez en cache l'état de la session car un cache est un magasin beaucoup plus rapide et plus évolutif que votre base de données, où vous mettriez autrement en cache ces sessions ou les autres options proposées par Microsoft et, dans ce cas, les données sont transitoire. Transitoire signifie qu'il est de nature temporaire. Il n'est nécessaire que pendant une courte période de temps, après quoi vous le jetez simplement et les données n'existent que dans le cache. Le cache est le magasin principal. Ainsi, dans ce cas d'utilisation, le souci n'est pas que le cache doive être synchronisé avec la base de données, mais plutôt que si un serveur de cache tombe en panne, vous perdez une partie des données. Parce que tout est stockage en mémoire et que la mémoire, comme vous le savez, est volatile. Ainsi, un bon cache distribué doit fournir des stratégies de réplication intelligentes. Ainsi, chaque élément de données existe dans plus d'un serveur. Si un serveur tombe en panne, vous ne perdez aucune donnée, mais la réplication a un coût associé, un coût de performance. Donc, la réplication doit être super rapide, c'est ce que NCache fait, d'ailleurs.
Partage de données d'exécution
Le troisième cas d'utilisation est le cas d'utilisation du partage de données d'exécution, où vous utilisez le cache essentiellement comme une plate-forme de partage de données. Ainsi, de nombreuses applications différentes sont connectées au cache et peuvent partager des données dans un modèle Pub/Sub. Ainsi, une application produit les données, les met dans le cache, déclenche un événement et les autres applications qui ont enregistré un intérêt pour cet événement seront notifiées, elles peuvent donc aller consommer ces données. Donc, il y a aussi d'autres événements. Il y a des événements basés sur des clés, des événements au niveau du cache, il y a une fonction de requête continue qui NCache possède. Il existe donc plusieurs façons d'utiliser un cache distribué comme NCache pour partager des données entre différentes applications. Dans ce cas également, même si les données sont créées à partir des données de la base de données, la forme sous laquelle elles sont partagées peut n'exister que dans le cache. Vous devez donc vous assurer que le cache réplique les données. Ainsi, le souci est le même que pour la mise en cache ASP.NET. Ce sont donc les trois cas d'utilisation courants pour une utilisation du cache distribué. S'il vous plaît, gardez ces cas d'utilisation à l'esprit lorsque je compare les fonctionnalités qui NCache fournit ce qui Redis ne fait pas.
Raison 1 - Garder le cache frais
Donc, la première raison, pourquoi vous devriez utiliser NCache plus de Redis est-ce, NCache vous offre des fonctionnalités très puissantes pour garder le cache à jour. Comme nous en avons parlé, si vous ne pouvez pas garder le cache à jour, vous êtes obligé de mettre en cache des données en lecture seule et si vous mettez en cache des données en lecture seule, vous savez, ce n'est pas le véritable avantage. Vous devez donc pouvoir mettre en cache à peu près toutes vos données. Même les données qui changent toutes les 10 à 15 secondes.
Expirations absolues / Expirations glissantes
Ainsi, la première façon de garder le cache à jour consiste à passer par les expirations. L'expiration est quelque chose que les deux NCache ainsi que Redis fournir. Ainsi, par exemple, il y a une expiration absolue où vous dites au cache de faire expirer ces données après 10 minutes ou 2 minutes ou 1 minute. Passé ce délai, le cache supprime ces données du cache et vous faites une supposition, vous dites, vous savez, je pense qu'il est prudent de conserver ces données dans le cache aussi longtemps parce que je ne pense pas que ça va changement dans la base de données. Donc, sur la base de cette supposition, vous dites au cache d'expirer les données.
Voici à quoi ressemble l'expiration. Je vais juste vous montrer quelque chose. En cas de NCache, lorsque vous installez NCache au fait, vous savez, cela vous donne un tas d'échantillons. Ainsi, l'un des exemples s'appelle les opérations de base que je l'ai ouvert ici. Donc, dans les opérations de base, permettez-moi de vous donner rapidement, voici ce qu'une application .NET typique utilisant NCache ressemble à.
Vous faites le lien avec NCache lors de l'exécution NCache.Web assembly alors vous utilisez le NCache.Durée espace de noms, NCache.Web.Caching namespace puis au début de votre application, vous vous connectez avec le cache. Toutes les caches sont nommées.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Si vous voulez savoir comment créer une cache, veuillez regarder notre vidéo de démarrage. C'est disponible sur notre site Web. Mais, disons que vous êtes connecté à ce cache, vous avez donc un handle de cache. Maintenant, vous créez vos données, qui sont un tas d'objets, puis vous faites cache.Ajouter. cache.Ajouter a une clé qui est une chaîne et la valeur réelle qui est votre objet, puis dans ce cas, vous spécifiez une expiration absolue d'une minute. Donc, vous dites expirer cet objet dans une minute et en disant que vous dites NCache faire expirer cet objet. Donc, c'est comme ça que fonctionne l'expiration qui bien sûr, comme je l'ai dit, Redis vous fournit également.
Synchroniser le cache avec la base de données
Mais, le problème avec l'expiration est que vous faites une supposition qui peut ne pas être correcte, peut ne pas être exacte. Alors, que se passe-t-il si les données changent avant cette minute avant ces cinq minutes que vous avez spécifiées. C'est donc là que vous avez besoin de cette autre fonctionnalité appelée synchroniser le cache avec la base de données. C'est la caractéristique qui NCache a et Redis n'a pas.
Alors, NCache le fait de plusieurs façons. Le numéro d'abord est Dépendance SQL. La dépendance SQL est une fonctionnalité de SQL Server via ADO.NET, où vous spécifiez essentiellement une instruction SQL et vous dites à SQL Server et dites, vous savez, veuillez surveiller cet ensemble de données et si cet ensemble de données change, cela signifie que n'importe quelle ligne est ajoutée , mis à jour ou supprimés qui correspondent aux critères de cet ensemble de données, veuillez m'en informer. Ainsi, la base de données vous envoie une notification de base de données et vous pouvez ensuite prendre les mesures appropriées. Alors, la façon NCache Est-ce que c'est, NCache utilisera la dépendance SQL et il existe également une dépendance Oracle qui fait la même chose avec Oracle. Ils fonctionnent tous les deux avec des événements de base de données. Alors, NCache utilisera la dépendance SQL. Laissez-moi vous montrer ce code ici. Donc, je vais juste aller au code de dépendance SQL. Encore une fois, de la même manière que vous liez avec certains des assemblages. Vous obtenez le descripteur de cache et maintenant que vous ajoutez des éléments, je vais simplement passer à ceci, passer à la définition. Donc, maintenant que vous ajoutez ces données, dans le cadre de l'ajout, vous spécifiez une dépendance SQL. Ainsi, la dépendance au cache est un NCache classe qui prend une chaîne de connexion à votre base de données. Il faut une instruction SQL. Donc, disons, dans ce cas, vous dites, je veux que l'instruction SQL soit où l'ID de produit est cet ID. Ainsi, puisque vous mettez en cache un objet produit, vous le faites correspondre à la ligne correspondante dans la table des produits. Alors, tu dis, tu dis NCache pour parler au serveur SQL et utiliser la dépendance SQL afin que le serveur SQL puisse surveiller cette instruction, et si ces données changent, le serveur SQL le notifie NCache.
Ainsi, maintenant le serveur de cache est devenu un client de votre base de données. Ainsi, le serveur de cache a demandé à votre serveur SQL de bien vouloir m'informer si cet ensemble de données change et lorsque cet ensemble de données change, le serveur SQL informe le serveur de cache et le NCache Le serveur supprime ensuite cet élément du cache et la raison pour laquelle il le supprime est qu'une fois qu'il est supprimé la prochaine fois que vous en aurez besoin, vous ne le trouverez pas dans le cache et vous serez obligé de l'obtenir à partir de la base de données. Donc, c'est comme ça que vous le rafraîchissez. Il existe un autre moyen de recharger automatiquement l'élément dont je parlerai dans un instant.
Ainsi, la dépendance SQL permet NCache pour vraiment synchroniser le cache avec la base de données et avec la dépendance Oracle, cela fonctionne exactement de la même manière, sauf qu'il fonctionne avec Oracle au lieu du serveur SQL. La dépendance SQL est vraiment puissante mais elle est aussi bavarde. Donc, disons, si vous avez 10,000 100,000 éléments ou 100,000 XNUMX éléments, vous allez créer XNUMX XNUMX dépendances SQL, ce qui augmente les performances de la base de données du serveur SQL, car pour chaque dépendance SQL, la base de données du serveur SQL crée une structure de données et le serveur pour surveiller ces données et c'est une surcharge supplémentaire.
Donc, si vous avez beaucoup de données à synchroniser, il est peut-être préférable de ne dépendre que de la base de données. Les dépendances de base de données sont notre propre fonctionnalité où, au lieu d'utiliser une instruction SQL et des événements de base de données, NCache tire réellement la base de données. Il y a une table spéciale que vous créez et qui s'appelle NCache Synchronisation de la base de données, puis vous modifiez vos déclencheurs, de sorte que vous alliez mettre à jour un indicateur d'affilée, correspondant à cet élément mis en cache, puis NCache extrait cette table de temps en temps, disons toutes les 15 secondes environ par défaut, puis vous pouvez, vous savez, s'il trouve une ligne qui a été modifiée, il invalide les éléments mis en cache correspondants du cache. Ainsi, ces deux éléments et bien sûr la dépendance à la base de données peuvent fonctionner sur n'importe quelle base de données. Ce n'est pas seulement SQL Server, Oracle mais aussi si vous avez un DB2 ou MySQL ou d'autres bases de données.
Ainsi, la combinaison de ces fonctionnalités vous permet d'être vraiment sûr que votre cache sera toujours synchronisé avec la base de données et que vous pouvez mettre en cache à peu près toutes les données. Il existe une troisième méthode qui est une procédure stockée CLR, de sorte que vous pouvez réellement implémenter une procédure stockée CLR. De là, vous pouvez faire un NCache appel. Ainsi, vous appelez la procédure stockée à partir du déclencheur de base de données. Disons que vous avez une table client et que vous avez un déclencheur de mise à jour ou de suppression ou même un déclencheur d'ajout en fait. Dans le cas d'une procédure CLR, vous pouvez également ajouter de nouvelles données. Donc, c'est la procédure CLR qui est appelée par le déclencheur et la procédure CLR fait NCache appels et de cette façon, la base de données ajoute les données ou met à jour les données dans le cache.
Ainsi, ces trois manières différentes permettent NCache être synchronisé avec la base de données et c'est une raison très puissante d'utiliser NCache plus de Redis car Redis vous oblige à n'utiliser que des expirations ce qui n'est pas suffisant. Cela vous rend vraiment vulnérable ou vous oblige à mettre en cache des données en lecture seule.
Synchroniser le cache avec la base de données non relationnelle
Vous pouvez également synchroniser le cache avec une base de données non relationnelle. Donc, si vous avez une base de données héritée, un ordinateur central, vous pouvez avoir une dépendance personnalisée qui est votre code qui s'exécute sur le serveur de cache et de temps en temps NCache appelle votre code pour aller surveiller votre source de données et vous pouvez peut-être effectuer des appels de méthode Web ou faire d'autres choses pour aller surveiller la source de données personnalisée et de cette façon, vous pouvez synchroniser l'élément mis en cache avec les modifications de données dans cette source de données personnalisée. Ainsi, la synchronisation de la base de données est une raison très puissante, pourquoi vous devriez utiliser NCache plus de Redis car maintenant vous cachez pratiquement toutes les données. Alors qu'en cas de Redis vous serez obligé de mettre en cache des données en lecture seule ou dans lesquelles vous pouvez faire des suppositions en toute confiance sur le expirations.
Raison 2 - Recherche SQL
Raison numéro deux, d'accord. Maintenant que vous avez, disons, vous avez commencé à utiliser la synchronisation avec la fonction de base de données et maintenant vous pouvez mettre en cache pratiquement beaucoup de données. Ainsi, plus vous cachez de données, plus le cache commence à ressembler à une base de données, puis si vous n'avez que la possibilité de récupérer des données en fonction de clés, c'est ce que Redis fait alors c'est très limitant. Donc, vous devez être capable de faire d'autres choses. Donc, vous devez être capable de trouver des données intelligemment. NCache vous donne un certain nombre de façons de regrouper des données et de rechercher des données en fonction des attributs d'objet ou en fonction de groupes et de sous-groupes ou vous pouvez attribuer des balises, des balises de nom. Donc, ce sont toutes des façons différentes de récupérer des collections de données. Par exemple, si vous deviez émettre une requête SQL, laissez-moi vous montrer que, disons, je fais une requête SQL ici. Donc, je veux aller chercher, disons, tous les clients où client.ville est New York. Donc, je vais émettre un état SQL, je dirai sélectionner des clients, vous savez, mon espace de noms complet, client où this.City est un point d'interrogation et dans la valeur que je vais spécifier New York comme valeur et quand je émettez cette requête, je vais récupérer une collection de ces objets client qui correspondent à ces critères.
Donc, cela ressemble maintenant beaucoup à une base de données. Donc, cela signifie que vous pouvez réellement commencer à mettre les données en cache. Vous pouvez mettre en cache des ensembles de données entiers, en particulier des tables de recherche ou d'autres données de référence où votre application a été utilisée pour émettre des requêtes SQL contre celles de la base de données et le même type de requêtes SQL que vous pouvez émettre contre NCache. La seule limitation est qu'il peut faire des jointures en cas de NCache mais pour beaucoup d'entre eux, vous n'avez pas vraiment besoin de faire les joints. Recherche SQL rend le cache très convivial pour vraiment rechercher et trouver les données que vous recherchez.
Regroupement et sous-groupement laissez-moi vous montrer cet exemple de regroupement. Ainsi, par exemple ici, vous pouvez ajouter un tas d'objets et vous pouvez tous les ajouter. Donc, vous les ajoutez en tant que groupe. Donc, c'est la clé, la valeur, voici le nom du groupe, voici le nom du sous-groupe et ensuite vous pourrez dire plus tard donnez-moi tout ce qui appartient au groupe électronique. Cela vous donne une collection et vous pouvez parcourir la collection pour récupérer vos affaires.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}Vous pouvez également récupérer les clés en fonction du groupe. Vous pouvez également faire d'autres choses en fonction du groupe. Ainsi, les groupes et les balises fonctionnent de la même manière. Étiquettes de nom sont également les mêmes que les balises, sauf qu'il s'agit d'un concept de valeur clé. Donc, disons, si vous mettez en cache du texte de forme libre et que vous voulez vraiment que certaines des métadonnées du texte soient indexées, vous pouvez donc utiliser le concept de valeur clé avec les balises de nom et de cette façon une fois que les balises de groupe et les balises de nom que vous avez vous pouvez alors les inclure dans les requêtes SQL.
Vous pouvez également émettre Requêtes LINQ. Si vous êtes plus à l'aise avec LINQ, vous pouvez émettre des requêtes LINQ. Ainsi, dans le cas de LINQ, par exemple, disons, voici votre NCache. Ainsi, vous feriez un NCache requête avec un objet produit. Cela vous donne une IQueryable interface, puis vous pouvez émettre une requête LINQ comme vous le feriez contre n'importe quelle collection d'objets et vous recherchez en fait le cache.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}Ainsi, lorsque vous exécutez cette requête, lorsque vous exécutez cette requête, elle va en fait au niveau de mise en cache et recherche vos objets. Donc, vous savez, l'interface à votre disposition est très simple, d'une manière très conviviale, mais dans les coulisses, il s'agit en fait de mettre en cache ou de rechercher l'ensemble du cluster de cache. Donc, la raison numéro deux est que vous pouvez rechercher dans le cache, vous pouvez regrouper des données dans des groupes et des sous-groupes, des balises et des balises nommées et cela permet de trouver des données de manière conviviale, ce qui n'existe dans aucune de ces fonctionnalités. Redis.
Indexation des données est un autre aspect de cela, que lorsque vous allez chercher sur la base de ces attributs, alors il est impératif, il est vraiment important que le cache indexe, il crée des index sur ces attributs. Sinon, c'est un processus extrêmement lent pour trouver ces choses. Alors, NCache permet de créer une indexation des données. Par exemple, chaque groupe et sous-groupe, balises, balises de nom sont automatiquement indexés mais vous pouvez également créer des index sur vos objets. Ainsi, vous pourriez, par exemple, créer un index sur votre objet client sur l'attribut ville. Donc, l'attribut city parce que vous savez que vous allez chercher sur l'attribut city. Vous dites, je veux indexer cet attribut et de cette façon NCache va l'indexer.
Raison 3 - Code côté serveur
La troisième raison est qu'avec NCache vous pouvez réellement écrire du code côté serveur. Alors, quel est ce code côté serveur et pourquoi est-ce si important. Regardons ça. Il s'agit d'un chargeur de lecture, d'écriture, d'écriture différée et de cache. Alors, lire à travers est essentiellement votre code que vous implémentez et qui s'exécute sur le serveur de cache. Alors, laissez-moi vous montrer à quoi ressemble une lecture. Ainsi, par exemple, si vous implémentez un IReadThruProvider interface.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}Cette interface a trois méthodes. Il existe une méthode init qui est appelée lorsque le cache démarre et son objectif est de connecter votre gestionnaire de lecture à votre source de données et il existe une méthode appelée dispose qui est appelée lorsque le cache est arrêté et de cette façon vous pouvez vous déconnecter de votre source de données et il y a une méthode load from source, qui vous transmet la clé et attend une sortie d'un élément de cache, un objet d'élément de cache de fournisseur. Ainsi, vous pouvez maintenant utiliser la clé pour déterminer quel objet vous devez extraire de votre base de données. Ainsi, la clé, comme je l'ai dit, pourrait être le client, l'ID client 1000. Ainsi, cela vous indique que le type d'objet est le client, la clé est l'ID client et la valeur est 1000. Donc, si vous utilisez des formats comme celui-ci, vous pouvez, sur cette base, vous pouvez aller de l'avant et trouver votre code d'accès aux données.
Ainsi, ce gestionnaire de lecture continue s'exécute en fait sur les serveurs de cache. Ainsi, vous déployez réellement ce code sur tous les serveurs de cache. En cas de NCache c'est assez homogène. Vous pouvez le faire via un NCache outil de gestion. Ainsi, vous déployez ce gestionnaire de lecture sur les serveurs de cache et ce gestionnaire de lecture est appelé par le cache. Disons que votre application fait le cache.Obtenir et cet élément n'est pas dans le cache. NCache appelle votre gestionnaire de lecture. Votre gestionnaire de lecture directe accède à votre base de données, récupère cet élément, le renvoie à NCache. NCache le met dans le cache puis le restitue à l'application. Ainsi, l'application donne l'impression que les données sont toujours dans le cache. Ainsi, même si ce n'est pas dans le cache, le cache a la capacité d'aller maintenant chercher les données de votre base de données. C'est le premier avantage de la lecture continue.
Le deuxième avantage de la lecture est que lorsque les expirations se produisent. Disons que vous aviez une expiration absolue. Vous avez dit expirer cet élément dans 5 minutes ou 2 heures à partir de maintenant, à ce moment-là, au lieu de supprimer cet élément du cache, vous pouvez dire NCache pour recharger cet élément automatiquement en appelant le gestionnaire de lecture. Et le rechargement signifie que cet élément n'est jamais supprimé du cache. C'est seulement mis à jour et c'est vraiment important parce que beaucoup de tables de recherche de référence, vous avez beaucoup de transactions qui lisent simplement ces données et si ces données sont supprimées même pendant une brève période, beaucoup de transactions contre la base de données sera créé pour récupérer ces données, simultanément. Donc, si vous pouviez simplement le mettre à jour dans le cache, c'est beaucoup mieux. Donc, c'est un cas d'utilisation.
Le deuxième cas d'utilisation concerne la synchronisation de la base de données. Ainsi, lorsque la synchronisation de la base de données se produit et que cet élément est supprimé, au lieu de le supprimer, pourquoi ne pas le recharger à partir de la base de données et c'est ce qui est NCache sera. Vous pouvez configurer NCache, de sorte que lorsque la synchronisation de la base de données démarre, le NCache Au lieu de supprimer cet élément du cache, il appellera votre gestionnaire de lecture pour aller en recharger une nouvelle copie. Encore une fois, de la même manière que l'expiration, cet élément n'est jamais supprimé. Il n'est jamais supprimé du cache. Ainsi, la lecture est une fonctionnalité vraiment puissante.
Un autre avantage de la lecture directe est qu'elle simplifie vos applications, car vous déplacez de plus en plus si vous persistez du code dans le niveau de mise en cache et si vous avez plusieurs applications qui accèdent aux mêmes données, tout ce qu'elles ont à faire est de faire un cache.Obtenir. A cache.Obtenir est un appel très simple, puis effectue un type de codage ADO.NET approprié.
Ainsi, la lecture simplifiée simplifie votre code d'application. Il s'assure également que le cache contient toujours les données. Il recharge automatiquement les expirations et les synchronisations de bases de données.
La fonctionnalité suivante est l'écriture directe. L'écriture immédiate fonctionne exactement comme la lecture immédiate, sauf que c'est pour la mise à jour. Laissez-moi vous montrer à quoi ressemble l'écriture continue. Donc, cela a été lu. Permettez-moi d'écrire. Ainsi, vous implémentez un gestionnaire d'écriture immédiate. Encore une fois, vous avez une méthode init. Vous avez une méthode dispose, tout comme la lecture continue, mais vous avez maintenant une méthode d'écriture dans la source de données et vous avez une méthode d'écriture en masse dans la source de données. Donc, c'est quelque chose qui est différent de lire à travers.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Ainsi, en cas d'écriture immédiate, vous savez, vous obtenez également l'objet et l'opération et cette opération peut être un ajout, une mise à jour ou une suppression, n'est-ce pas. Parce que tu pourrais faire un cache.Ajouter, cache.Insérer, cache.Supprimer, et tout cela se traduira par un appel en écriture immédiate. Cela peut maintenant aller mettre à jour les données dans la base de données.
De même, si vous effectuez une opération en bloc, une mise à jour en bloc, une mise à jour en bloc de la base de données peut également être effectuée. Ainsi, l'écriture immédiate présente également les mêmes avantages que la lecture immédiate, à savoir qu'elle peut simplifier l'application car elle déplace de plus en plus le code de persistance dans le niveau de mise en cache.
Mais, il existe également une fonction d'écriture différée qui est une variante de l'écriture directe. Avec l'écriture différée, vous mettez à jour le cache et le cache met ensuite à jour votre source de données de manière asynchrone. Fondamentalement, il le met à jour plus tard. Ainsi, votre candidature n'a pas à attendre.
Write-behind accélère vraiment votre application. Parce que, vous savez, les mises à jour de la base de données ne sont pas aussi rapides que les mises à jour du cache. Donc, vous savez, vous pouvez utiliser une écriture immédiate avec une fonction d'écriture différée et le cache est mis à jour immédiatement. Votre application revient en arrière et fait son travail, puis l'écriture immédiate est appelée en écriture différée et elle met à jour la base de données, et bien sûr si la mise à jour de la base de données échoue, l'application est notifiée.
Ainsi, chaque fois que vous créez une file d'attente, il y a un risque que si ce serveur tombe en panne, cette file d'attente soit perdue. Eh bien, en cas de NCache la file d'attente d'écriture différée est également répliquée sur plusieurs serveurs et de cette façon, si un serveur de cache tombe en panne, votre file d'attente d'écriture différée n'est pas perdue. Alors, c'est comme ça NCache garantit une haute disponibilité. Ainsi, l'écriture directe et l'écriture différée sont des fonctionnalités très puissantes. Ils simplifient le code de l'application et en cas d'écriture différée, ils accélèrent l'application car vous n'avez pas à attendre que la base de données soit mise à jour.
La troisième fonctionnalité est le chargeur de cache. Il y a beaucoup de données que vous préféreriez précharger dans le cache, afin que vos applications n'aient pas à accéder à la base de données. Si vous n'avez pas de fonctionnalité de chargeur de cache, vous devez maintenant écrire ce code. Eh bien, non seulement vous devez écrire ce code, mais vous devez également l'exécuter quelque part en tant que processus. C'est le fonctionnement en tant que processus qui devient vraiment plus compliqué. Ainsi, dans le cas d'un chargeur de cache, il vous suffit d'enregistrer votre cache. Vous implémentez une interface de chargeur de cache, vous enregistrez votre code avec NCache, NCache appelle votre code chaque fois que le cache est démarré, et de cette façon, vous pouvez vous assurer que le cache est toujours préchargé avec autant de données.
Donc, ces trois fonctionnalités read-through, write-through, write-behind et cached loader, ce sont des fonctionnalités très puissantes qui ne NCache a. Redis n'a pas de telles fonctionnalités. Ainsi, en cas de Redis vous perdez toute cette capacité qui NCache en dispose autrement.
Raison 4 - Cache client (près du cache)
La quatrième raison est Cache Client. Le cache client est une fonctionnalité très puissante. C'est vraiment, c'est un cache local qui se trouve dans la boîte de votre serveur d'applications, mais ce n'est pas un cache isolé. Il est local à votre application. Il peut s'agir d'In-Proc. Ainsi, ce cache client pourrait être des objets conservés comme sur votre tas et en cas de NCache si vous choisissez l'option In-Proc qui NCache conserve la forme des données et de l'objet. Pas sous une forme sérialisée, dans le cache client. Dans le cache groupé, il le conserve sous une forme sérialisée. Mais, dans le cache client, il le conserve sous forme d'objet. Pourquoi? Ainsi, chaque fois que vous le récupérez, vous n'avez pas à le désérialiser en un objet. Ainsi, cela accélère les récupérations ou les obtient beaucoup plus.
Un cache client est une fonctionnalité très puissante. C'est une cache au-dessus d'une cache. Ainsi, l'une des choses que vous perdez lorsque vous passez d'un cache In-Proc autonome à un cache distribué est que dans un cache distribué, le cache conserve les données dans un processus séparé, même sur un serveur séparé et il y a un inter processus communication en cours, il y a une sérialisation et une désérialisation en cours et cela ralentit vos performances. Ainsi, par rapport à un cache de formulaire d'objet In-Proc, un cache distribué est au moins dix fois plus lent. Ainsi, avec un cache client, vous obtenez le meilleur des deux mondes. Parce que, si vous n'avez pas le cache client, si vous avez juste un cache isolé autonome, il y a beaucoup d'autres problèmes concernant la taille du cache, que se passe-t-il si ce processus tombe en panne ? Ensuite, vous perdez le cache et comment maintenez-vous le cache synchronisé avec les modifications sur plusieurs serveurs. Toutes ces questions sont traitées par NCache dans son cache client.
Ainsi, vous bénéficiez de ce cache In-Proc autonome, mais vous êtes connecté au cluster de mise en cache. Ainsi, tout ce qui est conservé dans ce cache client se trouve également dans le cache en cluster et si l'un des clients le met à jour ici, le niveau de mise en cache en informe le cache client. Pour qu'il puisse aller se mettre à jour, immédiatement. C'est ainsi que vous vous assurez ou que vous êtes assuré que votre cache client sera toujours synchronisé avec le niveau de mise en cache qui est ensuite synchronisé avec la base de données.
Ainsi, en cas de NCache un cache client est quelque chose qui se branche simplement sans aucune programmation supplémentaire. Vous effectuez les appels d'API comme si vous parliez au niveau de mise en cache et le cache client se branche simplement sur un changement de configuration et un cache client vous offre des performances 10 fois plus rapides. C'est une caractéristique qui Redis n'a pas. Ainsi, malgré toutes les affirmations de performance qui Redis a, vous savez, ils sont un produit rapide, mais c'est aussi NCache. Alors, NCache est en tête à tête dans la performance avec Redis sans le cache client. Mais lorsque vous activez le cache client, NCache est 10 fois plus rapide. C'est donc le véritable avantage d'utiliser un cache client. C'est donc la quatrième raison d'utiliser NCache plus de Redis.
Raison 5 - Prise en charge de plusieurs centres de données
La raison numéro cinq est que NCache fournit un Support Multi-Datacenter. Vous savez, de nos jours, si vous avez une application à fort trafic, il y a de fortes chances que vous l'exécutiez déjà dans plusieurs centres de données, soit pour la récupération après sinistre, soit pour deux centres de données actifs-actifs pour l'équilibrage de charge ou une combinaison de DR et d'équilibrage de charge. , vous savez, ou peut-être son équilibrage de charge géographique. Donc, vous savez, vous pouvez avoir un centre de données à Londres et à New York ou vous connaissez Tokyo ou quelque chose comme ça pour répondre au trafic régional. Chaque fois que vous avez plusieurs centres de données, vous savez, les bases de données assurent la réplication car sans cela, vous ne pourriez pas avoir plusieurs centres de données. Parce que vos données sont les mêmes dans plusieurs centres de données. Si les données n'étaient pas les mêmes, vous savez, c'est séparé, il n'y a pas de problème, mais dans de nombreux cas, les données sont les mêmes et non seulement cela, mais vous voulez pouvoir décharger une partie du trafic d'un centre de données à l'autre de manière transparente. Donc, si la base de données est répliquée dans plusieurs centres de données, pourquoi pas le cache ? Redis ne fournit pas de telles fonctionnalités, NCache fournit des fonctionnalités très puissantes.
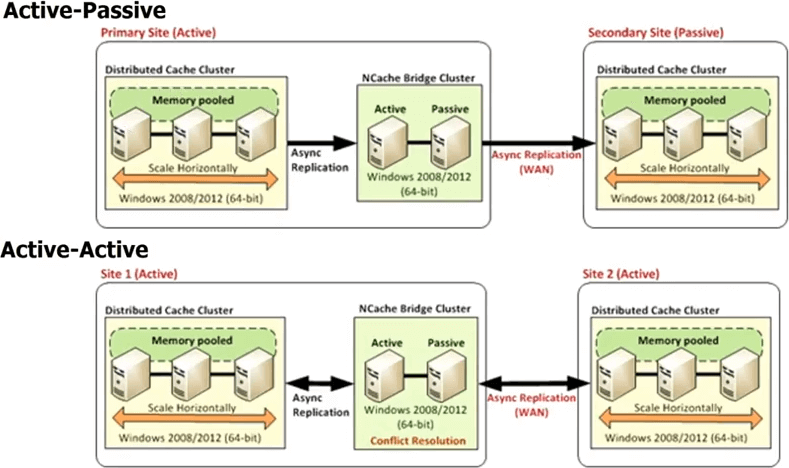
Ainsi, en cas de NCache vous avez tous les centres de données qui auront leur propre cluster de cache, mais il y a un topologie de pont entre. Ce pont connecte essentiellement les clusters de cache dans chaque centre de données, afin que vous puissiez répliquer de manière asynchrone. Ainsi, vous pouvez avoir un pont actif-passif, où il s'agit d'un centre de données actif, c'est passif. Vous pouvez également avoir un pont actif-actif et nous publions également plus de deux configurations de centre de données actif-actif ou actif-passif, où vous pouvez avoir, disons, trois ou quatre centres de données et le cache sera répliqué sur chacun d'eux soit de façon active-active, soit de façon active-passive. Dans un actif-actif, parce que les mises à jour sont effectuées de manière asynchrone ou que la réplication a été effectuée de manière asynchrone, il existe un risque de conflit si le même élément a été mis à jour dans les deux centres de données.
Alors, NCache fournit deux mécanismes différents pour gérer cette résolution de conflit. L'un est appelé la dernière mise à jour gagne. Là où l'élément a été mis à jour en dernier, est appliqué aux deux endroits. Donc, disons que vous mettez à jour un élément ici, un autre utilisateur met à jour l'élément ici. Les deux commencent maintenant à se propager vers l'autre cache. Ainsi, lorsqu'ils arrivent au pont, le pont se rend compte qu'ils ont été mis à jour aux deux endroits. Ainsi, il vérifie ensuite l'horodatage et, quel que soit l'horodatage le plus récent, il applique cette mise à jour à l'autre emplacement et supprime la mise à jour effectuée par l'autre emplacement. C'est ainsi que la dernière mise à jour active-active remporte la résolution des conflits. Si cela ne vous suffit pas, vous pouvez implémenter un gestionnaire de résolution de conflits. C'est votre code. Ainsi, en cas de conflit, le pont appellera votre code, transmettra les deux copies des objets, afin que vous puissiez effectuer une analyse basée sur le contenu, puis sur la base de cette analyse, vous pourrez alors déterminer quel objet est le plus approprié pour être mis à jour, pour être appliqué aux deux centres de données. La même règle s'applique si vous avez encore plus de deux centres de données.
Ainsi, un prise en charge de plusieurs centres de données est une fonctionnalité très puissante NCache vous donne hors de la boîte. Une fois que vous achetez NCache, tout y est, Redis ne le fait pas et si vous prévoyez d'avoir plusieurs centres de données ou même si vous voulez simplement avoir la flexibilité, même si vous n'avez pas plusieurs centres de données aujourd'hui mais que vous voulez avoir la flexibilité de pouvoir accéder à plusieurs centres de données, le feriez-vous acheter aujourd'hui une base de données qui ne prend pas en charge la réplication ? Vous ne le feriez probablement pas, même si vous n'avez qu'un seul centre de données. Alors, pourquoi opter pour le cache qui ne prend pas en charge la réplication WAN. Il s'agit donc d'une fonctionnalité très puissante de NCache.
Donc, jusqu'à présent, nous avons principalement parlé des fonctionnalités qu'un bon cache distribué doit avoir. NCache, vous savez, brille. Il gagne haut la main Redis. Redis est un cache simple très basique.
Raison 6 - Plate-forme et technologie (pour les applications .NET)
.NET et Windows contre Linux
La sixième raison est probablement l'une des raisons les plus importantes pour vous, à savoir la plate-forme et la technologie. Si vous avez une application .NET, vous préféreriez avoir la pile .NET complète. Je suis sûr que vous voudriez, vous ne voudriez pas mélanger .NET avec Java ou Windows avec Linux, dans la plupart des cas. Dans certains cas, vous savez, vous pouvez, mais dans la plupart des cas, les personnes qui développent des applications .NET préfèrent utiliser la plate-forme Windows et préfèrent que toute leur pile soit .NET, si possible. Hé bien, Redis n'est pas un produit .NET. C'est un produit basé sur Linux qui a été développé en C/C++.

Laissez-moi vous montrer peu. Ici se trouve le Redis site Web de labs qui est la société qui fabrique Redis. Si vous allez sur la page de téléchargement, vous verrez qu'ils ne vous donnent même pas d'option Windows. Ainsi, malgré le fait que Microsoft les ait choisis pour Azure, ils n'ont absolument aucune intention de prendre en charge Windows. Ainsi, dans la mesure où Redis Labs est concerné, Redis est uniquement pour Linux. Microsoft open Technology Group a porté Redis sur Windows. Il existe donc une version Windows de Redis disponible. Il est open source et n'est pas pris en charge mais, vous savez, il est bogué et instable et la preuve est dans le pudding mais que Microsoft lui-même ne l'utilise pas dans Azure. Alors le Redis que vous utilisez dans Azure est en fait un Linux basé Redis et non la base Windows. Ainsi, si vous souhaitez incorporer Redis dans votre pile d'applications, vous allez mélanger de l'huile avec de l'eau, vous savez. Alors qu'en cas de NCache tout est natif .NET. Vous avez Windows. Vous avez 100 % .NET. NCache a été développé en C Sharp (C#). Il est certifié pour Windows Server 2012 R2 et chaque fois qu'une nouvelle version du système d'exploitation arrive, il est certifié pour cela. Vous savez, nous allons bientôt lancer l'ASP.NET Core Support. Nous avons donc officiellement un client .NET. Nous avons également un client Java officiellement. Donc, je pense que si vous utilisez NCache et encore NCache est également open source. Donc, si vous n'avez pas l'argent, optez pour la version open source de NCache. Mais, si votre projet est important, optez pour la version Enterprise qui vous offre plus de fonctionnalités et prend en charge les deux. Mais, je vous recommande fortement d'utiliser NCache si vous avez une application .NET pour la combinaison .NET et Windows.
Assistance sur site
Le deuxième avantage que NCache vous donne, si vous n'êtes pas dans le cloud, disons que vous n'avez pas décidé de passer au cloud, vous hébergez votre propre application, donc, c'est essentiellement sur site. Donc, c'est bien dans votre propre centre de données Redis qui est disponible par Microsoft est dans Azure uniquement. Donc, tout ce qui est sur site, donc, il y a un Redis qui est disponible sur site par Redis Labs mais ce n'est que Linux et le seul sur site sur Windows est l'open source, celui qui n'est pas pris en charge et celui qui est bogué et instable et celui qui est tellement bogué que Microsoft lui-même ne l'utilise pas dans Azure.

Alors qu'en cas de NCache vous pouvez soit continuer à utiliser l'open source qui est gratuit, qui n'est bien sûr pas pris en charge, si vous n'avez pas l'argent. Mais, tout est .NET natif ou si vous avez un projet important pour votre entreprise, alors par le Edition pour Entreprise qui a plus de fonctionnalités et est livré avec un support et c'est une licence perpétuelle. C'est assez abordable, vous savez, de le posséder et nous vous offrons également une assistance 24 heures sur 7, XNUMX jours sur XNUMX, au cas où cela serait important pour vous.
Il est donc entièrement pris en charge sur site. La plupart de nos clients qui sont des clients haut de gamme utilisent encore NCache dans une situation sur site. NCache est sur le marché depuis plus de 10 ans. Donc, c'est un produit vraiment stable.
Support Cloud
En ce qui concerne le support cloud, Redis vous donne un modèle de service dans le cloud, c'est-à-dire que Microsoft a implémenté un Redis un service. Hé bien, Redis service signifie que vous n'avez pas accès aux serveurs de cache. Vous savez, c'est une boîte noire pour vous. Il n'y a pas de code côté serveur. Donc, toutes les lectures, écritures, écritures derrière, le chargeur de cache, la dépendance personnalisée et un tas d'autres choses, vous ne pouvez pas faire avec Redis. Vous savez, vous n'avez que l'API client de base et comme je l'ai dit, vous savez, sur Azure, Microsoft vous donne le Redis en tant que service.
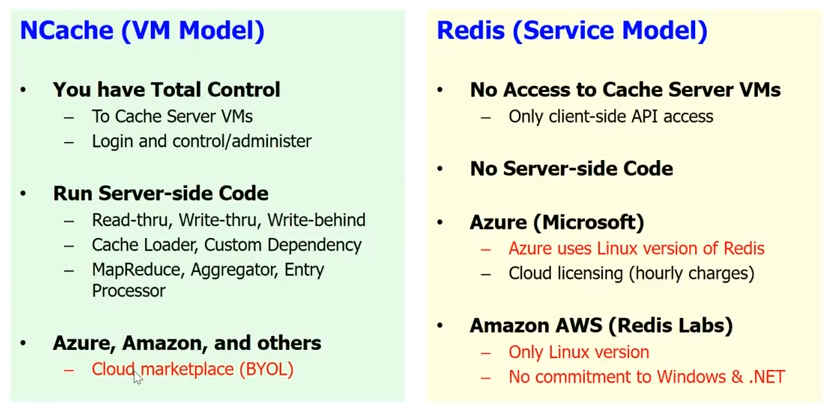
NCache, nous avons intentionnellement choisi un modèle de machine virtuelle. Parce que nous voulons que le cache soit proche de votre application et que vous ayez un contrôle total sur le cache. C'est quelque chose de très important car nous avons de nombreuses années d'expérience et nous savons que nos clients sont très sensibles. Même un petit, disons, si vous utilisez le Redis en tant que service et vous devez faire un saut supplémentaire pour accéder au cache à chaque fois, cela tue tout simplement le but d'avoir un cache. Alors qu'en cas de NCache vous pouvez l'avoir dans le cadre de la VM. Vous pouvez avoir le cache client. Il est vraiment intégré au déploiement de votre application. Ainsi, vous pouvez faire tout le code côté serveur.
NCache fonctionne aussi sur Azure. Il tourne sur Amazon AWS et aussi d'autres leaders plateformes cloud dans le modèle BYOL. Donc, vous obtenez essentiellement votre machine virtuelle. En fait, vous avez le NCache sur le marché. Vous obtenez un NCache VM et vous nous achetez la licence et vous commencez à utiliser NCache.
Donc, des approches très différentes. Mais c'est l'approche qui est prévue si votre application est vraiment importante et que vous voulez contrôler l'application, chaque aspect de celle-ci et ne pas avoir à compter sur quelqu'un d'autre pour gérer une partie de votre infrastructure au niveau de l'application. C'est une chose de gérer les machines virtuelles et le matériel en dessous, mais à mesure que vous montez de plus en plus haut, vous perdez ce contrôle et bien sûr en cas de mise en cache, en cas de NCache, ce n'est pas seulement ce contrôle mais aussi beaucoup de fonctionnalités que vous perdriez si vous optiez pour le modèle de service.
Ainsi, la raison numéro 6 est la technologie de la plate-forme. Pour les applications .NET, NCache est une option beaucoup plus appropriée que Redis. je ne dis pas Redis est une mauvaise option mais je pense que pour les applications .NET NCache est une option beaucoup plus supérieure que Redis.
NCache HISTOIRE
Permettez-moi de vous donner un bref historique de NCache. NCache existe depuis le milieu de 2005. Donc, ce sont les 11 ans, vous savez, NCache est été sur le marché. C'est le plus ancien cache .NET du marché. 2015 Janvier, nous sommes devenus open source. Donc, nous sommes maintenant sous licence Apache 2.0. Notre Edition pour Entreprise est construit sur notre open source. Ainsi, l'open source est une version stable et fiable. Il a beaucoup de fonctionnalités. Bien sûr, Enterprise a plus de fonctionnalités mais l'open source est un produit très utilisable. L'essentiel est que si vous n'avez pas l'argent, optez pour l'open source. Si votre application métier est importante et que vous avez le budget, optez pour l'Enterprise Edition. Il est livré avec un support et vous offre également plus de fonctionnalités.
Nous avons des centaines de clients, à peu près dans tous les secteurs possibles nécessitant une mise en cache. Donc, nous avons des clients du secteur financier, nous avons Walmart, un autre secteur de la vente au détail. Nous avons les compagnies aériennes, nous avons l'industrie de l'assurance, la voiture/l'automobile, dans toutes les industries.
Voilà, c'est la fin de mon exposé. S'il vous plaît, allez-y et téléchargez l'édition Enterprise de NCache. Permettez-moi de vous emmener sur notre site Web. Donc, essentiellement, allez à la page de téléchargement et je vous recommande fortement de télécharger l'édition Enterprise. Même si vous finissez par utiliser l’édition open source, téléchargez l’édition Enterprise. Il s'agit d'un essai entièrement fonctionnel de 30 jours, que nous pouvons facilement prolonger et jouer avec.
Si vous voulez aller de l'avant et télécharger l'open source, allez-y et téléchargez l'open source. Vous pouvez également aller sur GitHub et vous pouvez voir NCache sur le GitHub. Veuillez nous contacter si vous voulez que nous fassions comme un démo personnalisée. Parlez peut-être de l'architecture de votre application, répondez à vos questions. Merci beaucoup d'avoir regardé cette conversation.