Six façons d'optimiser NCache Performance
Webinaire enregistré
Par Kal Ali et Sam Awan
NCache est un cache distribué en mémoire Open Source populaire pour .NET. Il vous aide à faire évoluer vos applications .NET en mettant en cache les données d'application et en réduisant les déplacements coûteux de la base de données. NCache évolue de manière linéaire en vous permettant d'ajouter davantage de serveurs de cache au cluster de niveau de mise en cache.
Apprenez à optimiser NCache performances en le configurant correctement et également en utilisant ses fonctionnalités d'amélioration des performances.
Ce webinaire couvre:
- Introduction à la NCache et son architecture
- Moyens courants NCache est utilisé
- NCache fonctionnalités d'amélioration des performances
- NCache options de configuration améliorant les performances
Vue d’ensemble
Aujourd'hui, nous allons présenter un webinaire sur six astuces pour améliorer NCache performance. Le mode de ce webinaire serait l'écoute uniquement. Vous aurez la possibilité de poser tout type de question que vous souhaitez. Il y a un onglet de questions et réponses sur le volet de droite. Vous pourrez taper vos questions et l'un de nous sera en mesure de répondre à ces questions pour vous. Pendant le webinaire, si vous avez des questions ou des préoccupations et si vous n'êtes pas en mesure de nous entendre, s'il vous plaît - encore une fois, vous pouvez utiliser la fenêtre de chat. Kal parlera de toute la partie technique de la présentation. S'il y a quelque chose qui n'est pas si technique ou lié aux ventes, vous pouvez m'adresser directement vos questions. Cela étant dit, je vais céder la parole à Kal et il va commencer la présentation.
Très bien. Merci Sam. Pourriez-vous simplement confirmer que vous pouvez voir mon écran, car je viens de commencer à le partager ? Oui, je vois parfaitement votre écran. D'accord, parfait. Alors, salut les gars, comme Sam vient de me présenter, je m'appelle Kal et le sujet du webinaire d'aujourd'hui est, Six façons d'optimiser NCache Performance.
Ainsi, dans le webinaire d'aujourd'hui, nous couvrirons certains détails généraux concernant NCache et aussi quelles fonctionnalités vous pouvez utiliser dans votre application pour optimiser les performances. Alors, NCache est déjà une solution performante. Il augmente vos performances pour vos applications rapidement, car il réduit vos déplacements vers la base de données. Mais, avec ces fonctionnalités, vous pouvez réellement améliorer cela encore plus et ces six astuces seront en fait basées sur des cas d'utilisation. Je vais présenter un cas d'utilisation à côté de chacun d'eux et en fonction de celui qui s'applique à votre scénario spécifique, vous pouvez certainement l'utiliser et voir comment cela fonctionne pour vous. Donc, nous allons couvrir de véritables démonstrations pratiques, vous savez, de différentes applications et selon cela, nous verrons comment dans différentes situations NCache fonctionne et comment ces fonctionnalités nous aident réellement. Je vais donc poursuivre la présentation maintenant.
Le problème de l'évolutivité
Donc, tout d'abord, parlons en fait du problème d'évolutivité que l'on rencontre dans la plupart des scénarios de déploiement. Donc, généralement, vous avez une ferme Web, qui se trouve derrière un équilibreur de charge et ce type de niveau, ce scénario est généralement très évolutif. Parce que, comme vous voyez qu'il y a plus de charge sur vos applications, vous pouvez simplement ajouter plus de serveurs à ce niveau et cela augmenterait en fait la capacité de votre environnement, en termes de charge totale qu'il peut prendre dans ou pour exemple le nombre total de requêtes qu'il peut accepter, disons, contre en une seconde.
Le véritable problème, le véritable goulot d'étranglement, réside là où ces applications doivent entrer en contact avec la source de données principale. Peut-être pour obtenir des données de référence, peut-être pour obtenir un autre type de données qui y sont stockées. Donc, fondamentalement, c'est là que se trouve le goulot d'étranglement. Généralement, la source de données principale est une base de données. Comme nous le savons tous, les bases de données sont excellentes pour le stockage, mais le problème réside dans le fait qu'elles sont généralement lentes car elles sont sur disque. Ils ont tendance à s'étouffer sous une charge de transactions élevée et ils ne sont pas très évolutifs.
La solution
Ainsi, dans de tels scénarios, les entreprises / organisations ont tendance à évoluer vers un NoSQL database, mais ce n'est pas l'approche optimale à ce stade. Parce que cela nécessite un changement architectural complet, non seulement au sein de votre application, mais également au sein de vos données réelles pour les rendre compatibles les unes avec les autres. Ainsi, dans de tels scénarios, une approche optimale serait un cache distribué en mémoire, tel que NCache, qui est plus rapide et plus évolutif, car tout est placé dans la mémoire. Donc, si on le compare à une base de données, dans ce cas il était présent sur le disque. Donc, maintenant nous avons tout présent dans la mémoire. C'est plus évolutif car le cache distribué est logiquement une seule unité mais en dessous vous avez plusieurs serveurs indépendants hébergeant ce cache en cluster.
C'est une topologie très évolutive. Vous pouvez ajouter ici autant de serveurs que vous le souhaitez. Comme vous le savez, ce qu'il fait, c'est qu'il regroupe non seulement les ressources de mémoire de tous ces serveurs, mais également la puissance de calcul de toutes ces ressources. Ainsi, à mesure que vous ajoutez plus de serveurs, cela augmente la capacité de votre cache en termes de données totales pouvant être stockées. Ainsi que le nombre total d'opérations ou la charge totale qu'il peut prendre.
Ainsi, lorsque vous constatez qu'il y a plus de charge sur votre ferme Web, vous pouvez également augmenter le nombre de serveurs sur votre cluster de mise en cache, ce qui rendrait ce niveau également évolutif. Ainsi, maintenant, votre niveau de mise en cache correspond aux demandes provenant de la batterie de serveurs Web. Donc, maintenant, cela aide réellement à supprimer cette partie non évolutive qui était présente avec la base de données. La meilleure partie à ce sujet est que ce n'est pas un remplacement pour une base de données. Vous pouvez l'utiliser en parallèle. Donc, ce qu'il fait, c'est que le cluster de cache se trouve juste entre vos applications et votre base de données. Vous pouvez toujours passer des appels directs. Mais, ce qu'il fait, c'est que vous pouvez faire NCache votre seule source de données et en utilisant cela, nous avons des fonctionnalités de couche d'accès aux données qui sont fournies avec ce cache, grâce auxquelles vous pouvez réellement, le cache peut réellement écrire des données sur les sources de données back-end ainsi qu'obtenir des données du back-end source d'information.
Ainsi, en utilisant cela, votre cache reste synchronisé avec les sources de données back-end. Ainsi, vous disposez de données à jour provenant d'une source plus rapide, car elles sont présentes dans la mémoire et constituent également une source plus évolutive. Donc, c'est un très bon compromis dans ce cas.
NCache Déploiement
Alors, parlons de la NCache déploiement dans ce schéma. Donc, ici, si vous pouvez voir cela, il s'agit essentiellement de vos serveurs d'applications ou de vos serveurs Web sur lesquels votre application est hébergée. Ils sont généralement assis derrière un équilibreur de charge. Auparavant, ils faisaient des appels directs aux sources de données back-end, comme une base de données, mais maintenant vous avez le niveau de mise en cache ici. Il s'agit du déploiement recommandé par nous, c'est que vous disposez d'un niveau de mise en cache dédié hébergeant vos caches en cluster.
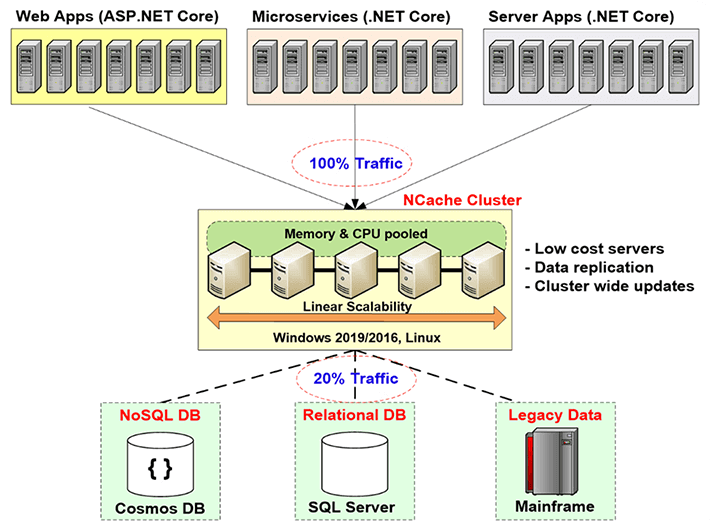
Donc, ce que font vos applications, elles le font NCache la seule source de données. Toutes leurs demandes d'obtention de données ou même une sorte de traitement sont effectuées directement sur le cache et si le cache ne l'a pas en utilisant ces fournisseurs de couche d'accès aux données, il peut en fait être récupéré dans les sources de données. Donc, c'est ce qu'il fait dans votre environnement. Ces serveurs, comme je l'ai mentionné plus tôt, il est recommandé d'être des serveurs dédiés et ce sont des serveurs très peu coûteux. La seule condition préalable à NCache dans ce cas est juste le .NET framework. Sur ces serveurs qui hébergent le cache du cluster, vous avez l'installation du serveur de cache, qui a la capacité d'héberger les caches du cluster et sur le client, sur ces boîtiers clients ici, qui sont vos serveurs d'application, vous avez le remote client installation, qui peut héberger des caches locaux et peut en fait aider à se connecter à des caches en cluster distants.
Voici à quoi ressemble le déploiement. Tout cela est évolutif linéairement. Au fur et à mesure que nous ajoutons un plus grand nombre de serveurs, augmentez la capacité totale du cache.
Trois utilisations courantes de NCache
Parlons des trois utilisations courantes de NCache. Je passe rapidement en revue toutes ces choses parce que je veux arriver à ces six façons et entrer dans les détails pour celles-ci, donc, s'il y a des questions, je peux certainement y répondre. Parlons donc des trois utilisations courantes de NCache.
-
Mise en cache des données d'application
Le premier est la mise en cache des données d'application. Donc, sur cette diapositive, nous parlions des trois utilisations courantes de NCache. Donc, le premier est la mise en cache des données d'application. Dans ce cas, en gros, ce que vous faites, c'est que vous introduisez le NCache API dans votre application et en utilisant cette API, vous pouvez ajouter des éléments et obtenir des éléments du cache et vous pouvez effectuer différentes opérations sur le cache, selon la manière dont elles sont requises. Et alors NCache a-t-il la capacité d'héberger, fondamentalement, vous pouvez mettre en cache n'importe quoi dans NCache. Il peut s'agir d'images, d'objets personnalisés, d'objets de domaine, de collections, en gros de n'importe quoi. Ainsi, tout ce qui est autorisé par .NET peut être mis en cache dans NCache et l'utilisation de vos applications en introduisant le NCache API, très simple à utiliser, très facile à utiliser, vous pouvez réellement effectuer différentes opérations sur le cache et réellement ajouter et récupérer des éléments.
ASP.NET, ASP.NET Core Cache haute performance
Le cas d'utilisation suivant concerne ASP.NET, ASP.NET Core mise en cache. Donc, tout d'abord, vous pouvez utiliser NCache en tant que fournisseur d'état de session. Peut être mono-site ou multi-sites. La prochaine est que vous pouvez avoir NCache stocker votre état d'affichage. C'est quelque chose qui est pré-MVC. Après cela, le concept d'état de vue n'était plus présent. Après cela, nous avons pour ASP.NET, nous avons le fournisseur de cache de sortie. NCache peut agir comme ça et ensuite pour ASP.NET Core applications, il peut s'agir de Core Response Caching. Donc, vous pouvez le faire avec NCache. NCache peut également agir comme un SignalR Backplane. Ainsi, toutes ces options qui viennent d'être couvertes dans le numéro 2 ne sont en fait aucune option de changement de code. Vous n'avez pas besoin d'apporter de modifications au code. Vous pouvez simplement mettre à jour le fichier de configuration de vos applications et utiliser ceux que vous pouvez réellement avoir NCache pour stocker tout ce que vous voulez stocker. Il peut s'agir de sessions, de l'état de la vue, de vos sorties ou même de la mise en cache de la réponse principale. Donc, en utilisant cela, vous pouvez avoir NCache stocker ces choses. Donc, fondamentalement dans ce cas, encore une fois aucune option de changement de code, très facile à utiliser. Quelques étapes sont nécessaires. Nous avons une documentation complète. Nous avons également des échantillons et en suivant ces étapes et cette documentation, même les échantillons, vous pouvez le configurer en 15 minutes. Vous pouvez tout mettre en place. Nous pouvons réellement le tester, voir comment cela fonctionne pour vous.
Partage de données Pub/Sub et Runtime via des événements
Le prochain est Pub / Sous-marin ainsi que Partage de données d'exécution via des événements. Donc, fondamentalement, dans ce cas, vous avez, disons, vous avez des applications sans serveur et vous voulez vous assurer qu'il y a une sorte de synchronisation entre elles, elles veulent transmettre certains messages, certaines données. NCache peut être utilisé comme un moyen juste pour cela. Vous pourriez avoir des éditeurs, vous pourriez avoir des abonnés et ils pourraient publier des messages. Les abonnés qui sont enregistrés auprès de ceux-ci, disons, les clients peuvent en fait les obtenir pour obtenir ces données de ceux de NCache dans ce cas.
Ainsi, un exemple typique serait une application de chat de groupe. Peut-être que vous avez des membres du groupe, tous connectés au même cache, ils sont en fait dans une discussion de groupe. L'un des membres poste un message, tous les autres membres de ce groupe recevront une notification de ces données qu'elles ont été ajoutées. Donc, ce n'est qu'un exemple de base et nous avons également des notifications pilotées et une requête continue.
Donc, ce sont les choses qui NCache vous offre réellement et ce qui est essentiellement utilisé par la plupart de nos clients.
NCache Architecture
Parlons en fait de la NCache Architecture maintenant. Expliquons-nous comment cela fonctionne? Donc en gros NCache est une architecture 100% peer-to-peer. Il n'y a pas de point de défaillance unique et il n'y a pas de maître-esclave ou de règle de majorité ou de concept similaire au sein de NCache. Les serveurs peuvent être ajoutés et supprimés à la volée. Le cache n'a pas besoin d'être arrêté et il continuerait à fonctionner correctement. Même dans le cas où si l'un des serveurs tombe en panne, essentiellement dans un scénario imprévu, le cluster ne tombe pas en panne, le cluster complet ne tombe pas en panne. Il démarre la logique de récupération, entre les serveurs pour redisrendre hommage à ces données ou obtenir les données de l'une des sauvegardes et côté client, les clients basculent en fait leurs connexions vers les serveurs restants présents dans le cluster.
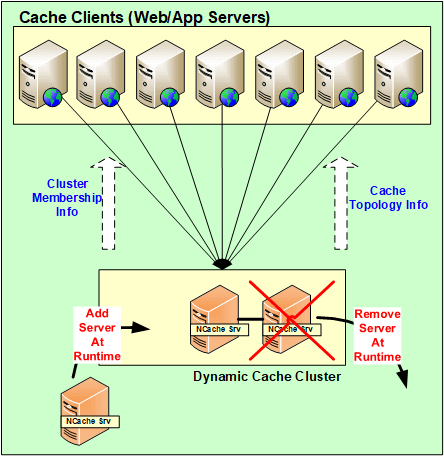
Ainsi, en utilisant cela, les données ne sont en fait pas perdues et les clients auxquels leurs connexions sont réellement, ils basculent vers les autres serveurs. Ainsi, ils continuent à faire des requêtes même si l'un des serveurs est tombé en panne. Ainsi, tant que vous avez un serveur opérationnel, votre demande sera traitée.
Ainsi, toutes ces modifications, toutes ces modifications de configuration des serveurs étant ajoutées, supprimées à la volée pour des scénarios imprévus, toutes ces modifications sont en fait propagées dans tout le cluster. Ainsi, toutes ces configurations sont en fait dynamiques. Toute mise à jour au sein du cluster et en termes de configuration est mappée sur tous les serveurs présents dans le cluster et les clients en sont également automatiquement informés.
NCache Configuration requise
Serveurs de cache
Parlons-en le NCache Configuration requise. Donc, généralement en termes de, disons, si vous parlez de cœurs, plus il y en a, mieux c'est. Mais, d'une manière générale, nous recommandons d'avoir plus de 8 cœurs. Les trois principales choses qui NCache utilise le processeur, les ressources réseau et la mémoire. Le CPU est utilisé pour gérer essentiellement les requêtes qui arrivent, ou peut-être que s'il y a du code côté serveur qui a été configuré pour faire ce genre d'opérations, c'est pourquoi le CPU est utilisé. Deuxièmement, la RAM est utilisée uniquement pour le stockage et peut-être une surcharge impliquée après le stockage des données et les ressources du réseau sont utilisées pour maintenir la communication. Par exemple, de la communication serveur à serveur, puis de la communication client à serveur. Donc, vous avez ces deux options, puis les serveurs Windows recommandés sont 2012, 2016. Le seul prérequis de NCache is .NET framework, sinon, il est pris en charge dans tous les environnements Windows.
Remote Clients
En termes de remote clients, le seul prérequis est d'avoir .NET 4.0 ou supérieur et votre client serait en fait pris en charge. Vous pouvez avoir NCache sur ces serveurs.
Environnement de configuration
Donc, maintenant que nous avons parlé des différentes choses, la base, vous savez, l'introduction concernant NCache, parlons de la façon dont nous pouvons configurer l'environnement. Ainsi, chaque fois que nous avons des clients qui évaluent notre produit, ce que nous leur disons, nous leur donnons cinq étapes pour travailler avec NCache. Le premier est de télécharger une nouvelle copie du NCache Enterprise à partir du site Web et la seconde est d'installer NCache au sein de votre environnement. j'ai NCache déjà installé sur deux de mes machines. Ce sont en fait des boîtiers distants demo1 et demo2. Et, sur ces boîtes une fois que j'ai installé NCache, j'obtiens un outil de gestion de NCache appelé NCache manager. En utilisant cet outil, je peux réellement créer des caches, les configurer et effectuer différentes opérations et même Stack monitoring est impliqué dans cette affaire.
Créer un cache via NCache Gérante
Alors, allons-y et ouvrons le NCache gestionnaire ici. J'ai juste besoin de chercher NCache et ça revient automatiquement. Donc, une fois que vous l'ouvrez, c'est la vue que vous obtenez. Donc, maintenant, ce que nous devons faire, c'est créer un nouveau cache en cluster. Pour le créer, cliquez avec le bouton droit sur les "Clustered Caches", cliquez sur "Create New Clustered Cache".
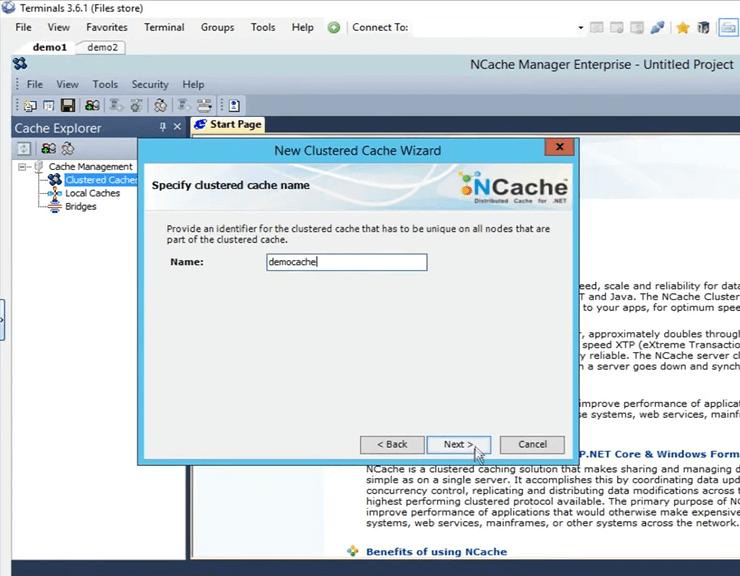
Donc, ici, ce que je dois faire, c'est que je dois lui donner un nom. Je vais aller de l'avant et lui donner un nom "démocache". Tous les caches doivent être nommés. Je vais juste garder ça. Je vais cliquer sur suivant.
Ce sont les quatre topologies proposées par NCache Je vais garder "Partitioned Replica" sélectionné car c'est le plus recommandé et le plus populaire parmi tous nos clients. C'est très évolutif, très fiable.
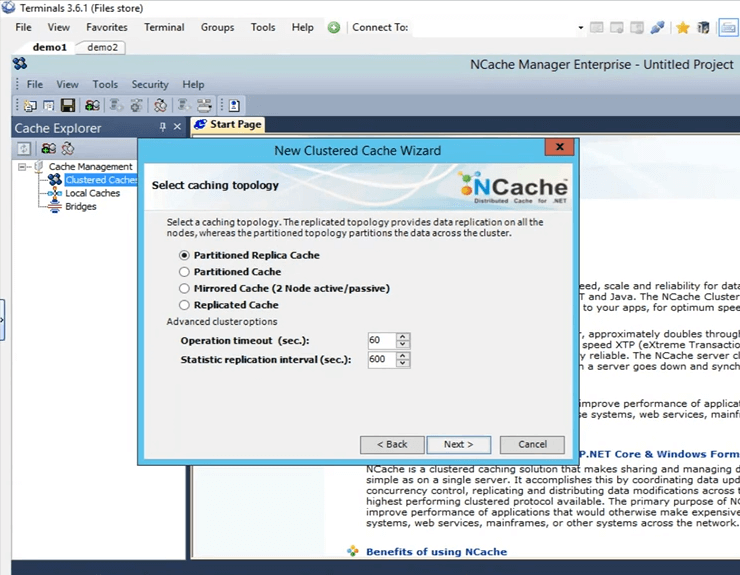
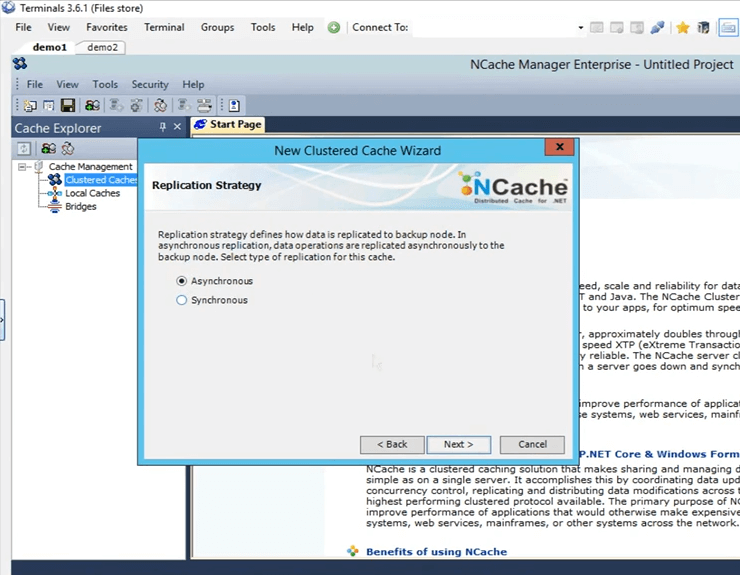
Il s'agit de la stratégie de réplication entre la partition active et la partition de sauvegarde dans le cas d'une réplique partitionnée. Je vais le garder sur Async, car c'est plus rapide.
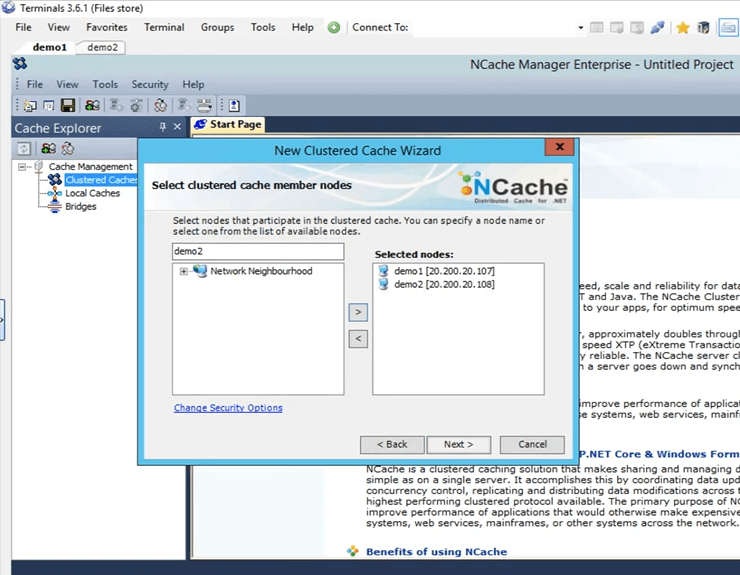
C'est ici que je spécifie ces serveurs qui vont héberger ce cache en cluster. Donc, ici, je vais spécifier demo1 et demo2. Ce sont les deux cases que j'ai, 107 et 108 et cliquez sur suivant.
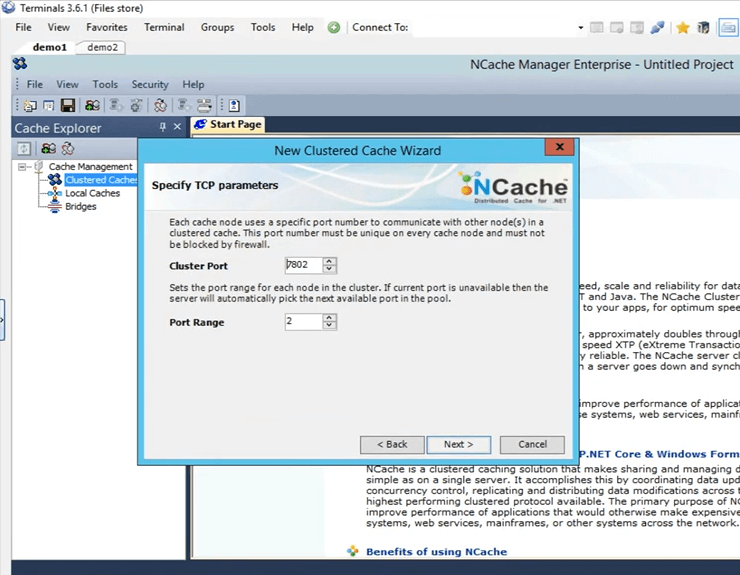
Il s'agit du port de cluster sur lequel le cluster communique. Il est récupéré automatiquement.
C'est la taille qui est configurée sur chaque boîte. Donc, il y aura 2 Go de taille totale, un sur le serveur1 et un sur le serveur2.
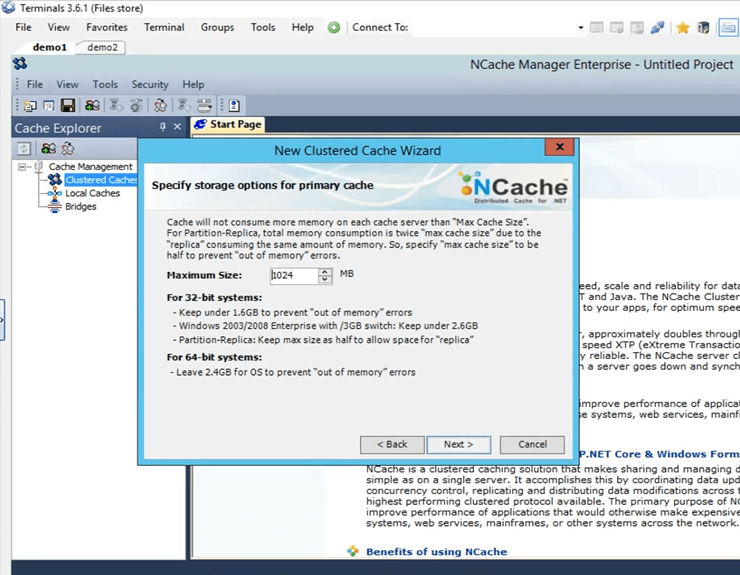
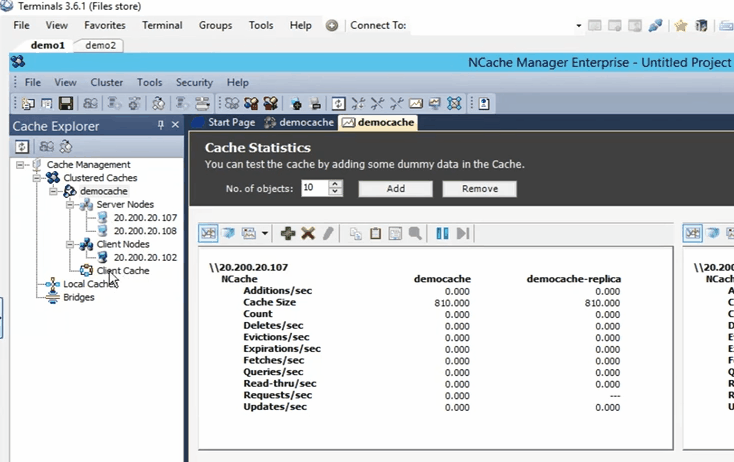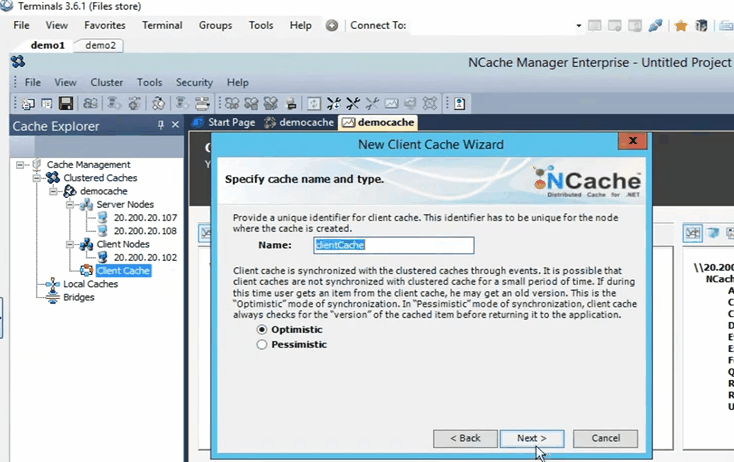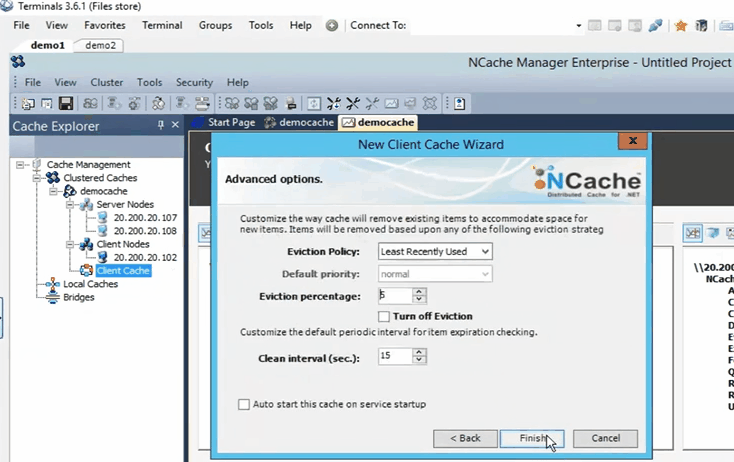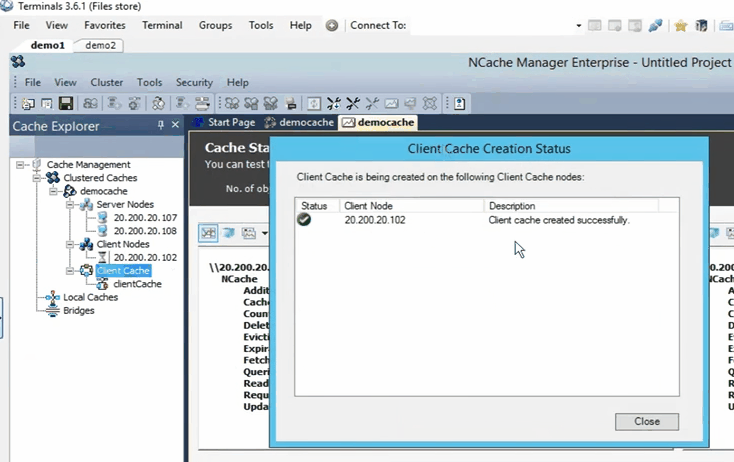
Ce sont quelques options avancées. Peut-être que si vous avez un scénario plein de cache, le cache peut automatiquement supprimer des éléments du cache. S'il s'agit de données sensibles, vous pouvez en fait désactiver l'expulsion, afin que les éléments ne soient pas supprimés d'eux-mêmes et vous avez également la possibilité de démarrer automatiquement le cache dès qu'il démarre, dès que la machine démarre. Donc, je vais juste cliquer sur terminer et cela crée en fait mon cache.
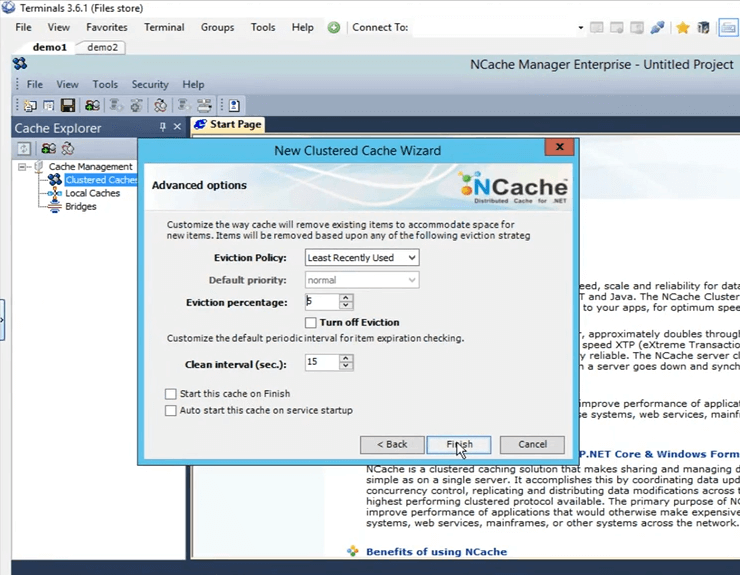
Donc, c'était aussi simple que cela de créer un cache. J'ai le cache configuré maintenant. Si je fais juste un clic gauche sur le nom du cache, cela ouvre tous ces différents onglets ici à travers lesquels je peux encore faire quelques changements ou configurations si besoin est à ce stade.
Donc, la prochaine chose que je vais faire, c'est ajouter ma boîte personnelle en tant que remote client. Pour ce faire, faites un clic droit sur le nom du cache et cliquez sur ajouter un nœud.
Et, ici je vais juste donner l'IP de ma box perso, c'est 102 et maintenant c'est ajouté.
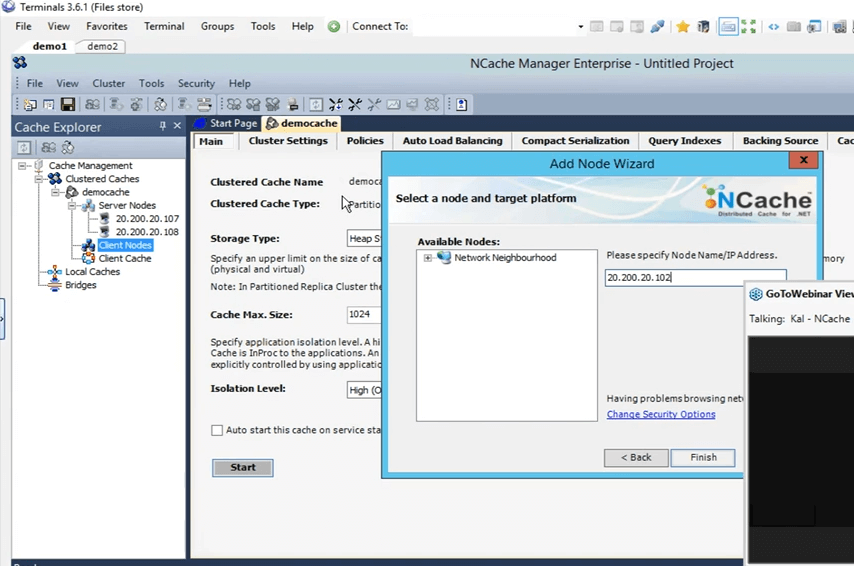
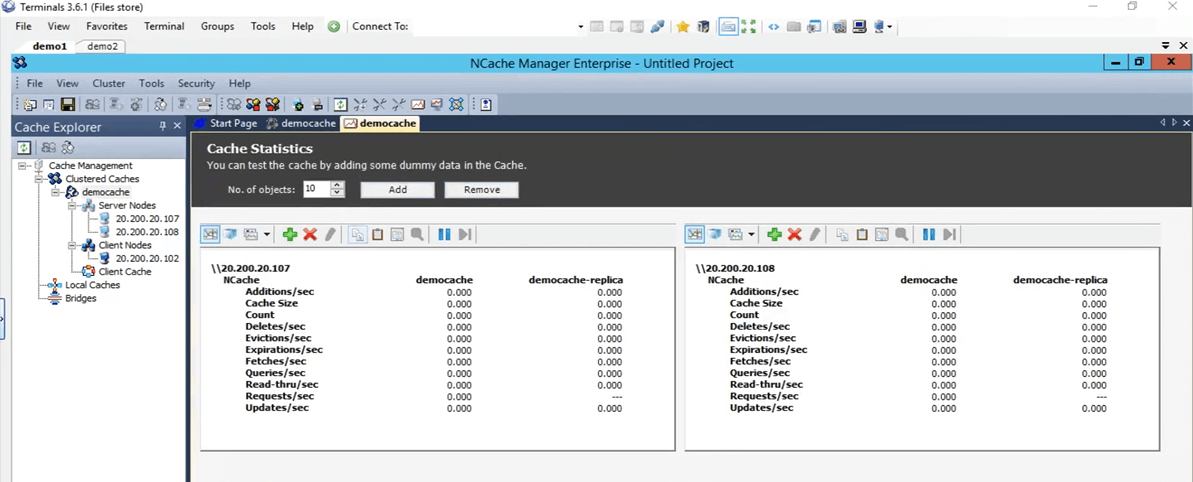
Donc, une fois qu'il est ajouté, je vais juste faire un clic droit sur le nom du cache et cliquer sur démarrer. Donc, maintenant, le cache est démarré sur les boîtes 107 et 108. Une fois qu'il est opérationnel, je vais ouvrir les statistiques et je vais également vous montrer un outil de surveillance de NCache appelé NCache monitor, qui entre dans des détails très approfondis en ce qui concerne la vérification de choses fondamentalement différentes qui se passent dans le cache. Donc, le cache est opérationnel maintenant. Pour ouvrir les statistiques, faites un clic droit sur le nom du cache et cliquez sur les statistiques.
Donc, c'est ce que ça va faire apparaître toutes ces statistiques pour ces deux cases 107 et 108.
Alors, maintenant, ouvrons réellement le outil de suivi de NCache. Pour l'ouvrir, cliquez avec le bouton droit sur le nom du cache et cliquez sur le cluster de surveillance.
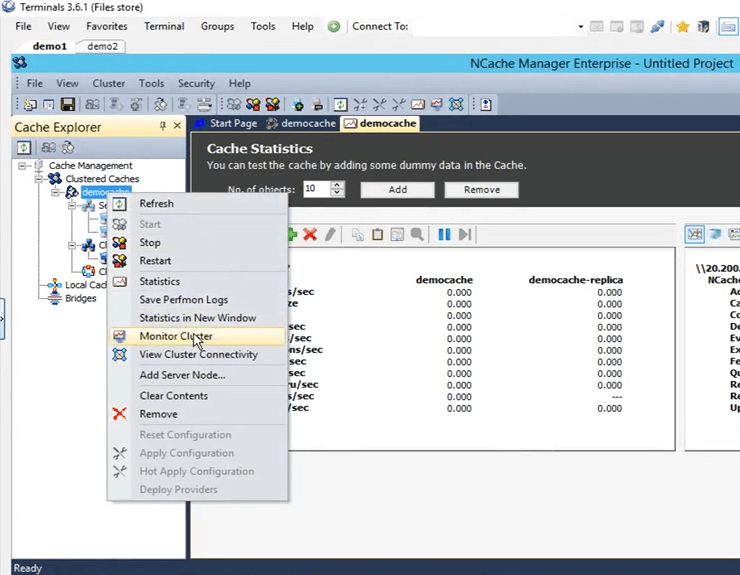
Les NCache moniteur va maintenant s'ouvrir, ce qui nous donnera deux tableaux de bord préconfigurés, à savoir le tableau de bord du serveur et le tableau de bord de la vue de rapport. Ainsi, en utilisant cela, vous pouvez avoir une assez bonne idée de ce qui se passe dans le cache. Si nous voyons ici, c'est, par exemple, la taille du cache, qui est actuellement consommée, puis c'est le graphique des requêtes par seconde. Ainsi, cela vous donne beaucoup de détails différents qui se déroulent actuellement dans le cache et vous pouvez utiliser ces détails pour peut-être déboguer certains scénarios ou aller au fond des choses si vous rencontrez des problèmes.
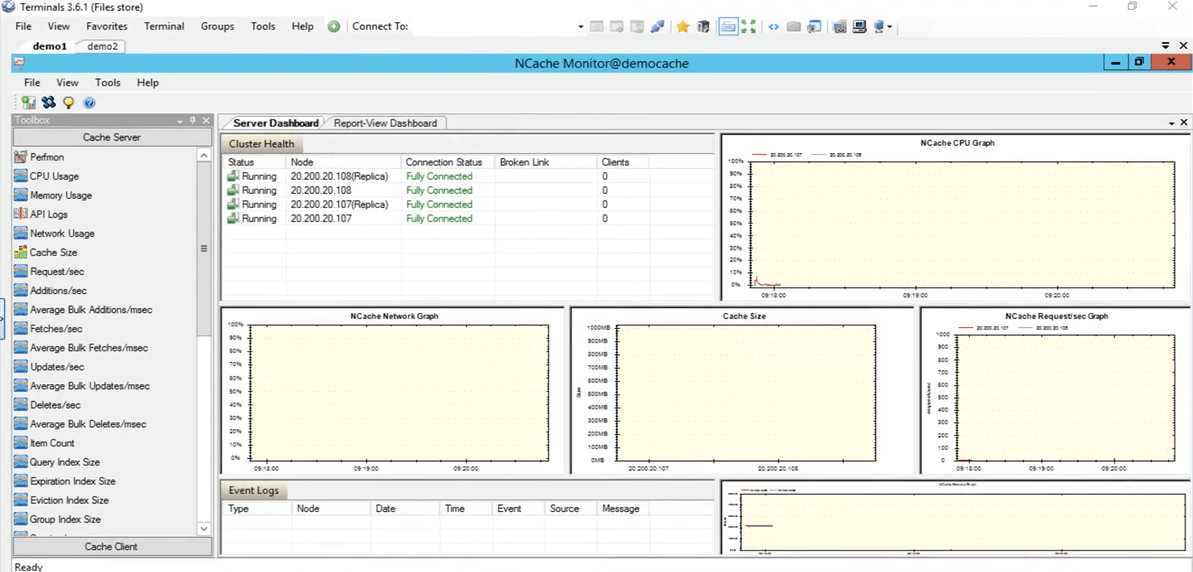
Je vais donc revenir rapidement sur NCache manager et ici, vous pouvez également créer votre propre tableau de bord personnalisé. Si vous souhaitez examiner certaines choses qui ne sont pas préconfigurées ici, vous pouvez également le faire. Vous avez des contrôles présents ici sous la catégorie de serveur de cache, puis également sous la catégorie de clients de cache. Vous pouvez également créer vos propres tableaux de bord personnalisés pour ne voir que les éléments qui vous intéressent réellement. Revenons donc à la NCache gestionnaire. Tout s'affiche à zéro car nous n'avons aucune application en cours d'exécution sur ce cache.
Simuler le stress et surveiller les statistiques du cache
Donc, en fait, testons-le rapidement en exécutant une application. Donc, j'ai le PowerShell ouvert ici. Éclaircissons-le en fait. Ouvrons en fait un nouveau. Bon, j'ai un PowerShell qui s'ouvre. Donc, ce que je vais faire, c'est exécuter l'application de l'outil de contraintes pour ajouter une charge fictive à mon cache en cluster, afin de simuler une activité. Donc, en utilisant cette activité, nous allons également la surveiller à travers le NCache gestionnaire, ainsi que, par l'intermédiaire du NCache moniteur, voyez comment cela fonctionne pour nous.
Alors exécutez cet outil de test de stress. Je dois le retaper. Tuons d'abord le processus. En attendant, si vous avez des questions, n'hésitez pas à les poster dans l'onglet questions et réponses. Kal, je ne pense pas que nous ayons de questions pour le moment. D'accord, parfait. Une raison pour laquelle il ne cueille pas. Je suis de retour Ouaip. Désolé, j'allais juste dire que, les gars, cette session est enregistrée. Donc, quelle que soit la raison, si vous n'êtes pas en mesure d'assister à la session complète ou si vous avez manqué la partie initiale, vous pourrez vérifier cet enregistrement. Je crois que nous allons le publier plus tard dans la semaine ou au début de la semaine prochaine. Ainsi, vous pourrez continuer et parcourir à nouveau la session complète.
Donc, ce que je fais en ce moment, c'est que je suis allé directement dans ce répertoire, pour y ouvrir l'invite de commande et exécuter l'outil de test de stress. D'accord, voyons voir, ouais, c'est ramassé, je vais juste continuer et lui donner le nom de stresstesttool.exe, puis le cache de démonstration. Donc, maintenant, ce qu'il ferait, c'est qu'il ajouterait des données factices au cache. Si nous revenons ici, nous devrions voir une activité sur ces deux boîtes en ce moment. Le voilà. Donc, nous voyons une certaine activité arriver sur ces deux boîtes 107 et 108.
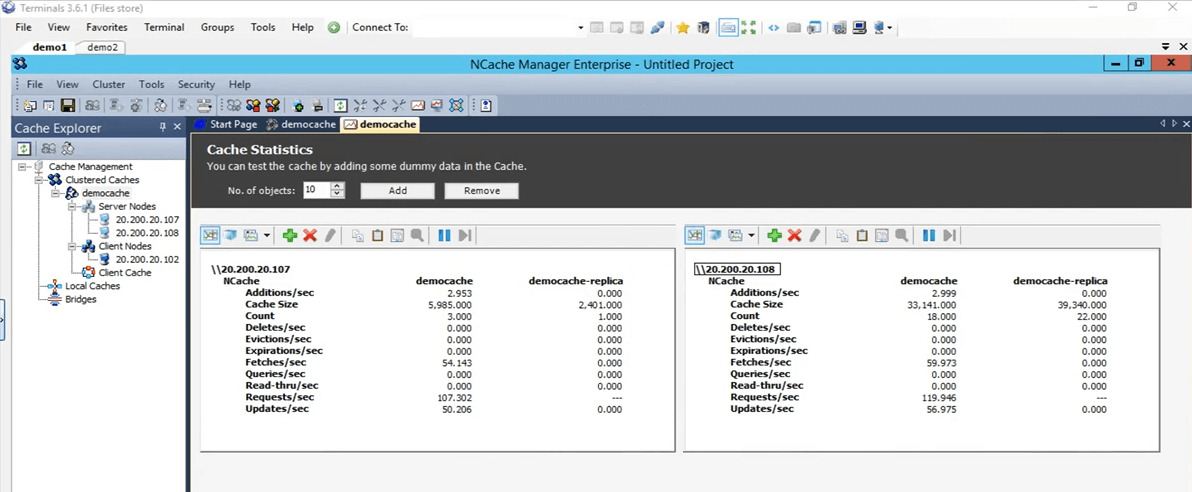
Dans la topologie que nous avons choisie réplique partitionnée, chaque client dispose d'une connexion à tous les nœuds de serveur présents dans le cluster, c'est pourquoi il se connecte aux deux serveurs. Si nous arrivons au NCache moniteur, nous pouvons voir qu'il y a un client connecté contre 108 et un contre 107. Si vous regardez le NCache demande par seconde graphique, nous pouvons voir qu'il y a une activité en cours.
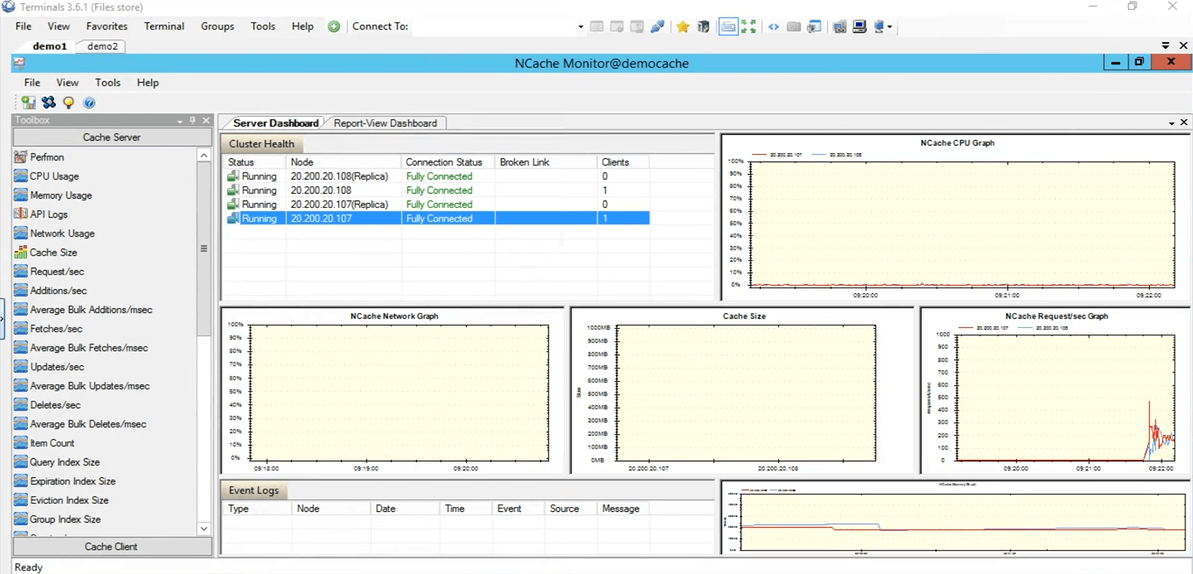
Donc, ce test était juste pour vérifier si tout est, le cache est configuré correctement, tout fonctionne très bien et cela a été testé. Je vais donc arrêter l'application de l'outil de test d'effort. Maintenant, revenons au NCache gestionnaire. Allons-y et vidons ce cache, afin que, pour notre test ultérieur, il n'y ait aucun élément présent dans le cache. Donc, tout s'affiche à 0. Revenons à la présentation. Donc, notre environnement est maintenant configuré et tout est prêt. Ce que nous pouvons faire maintenant, c'est que nous pouvons passer aux diapositives.
NCache Astuces – Optimisation des performances
Parlons donc des six façons que nous allons utiliser pour optimiser les performances, une par une. Juste pour réitérer NCache, le cache de cluster est déjà une fonctionnalité de performance qui, vous le savez, améliore vos performances au sein de votre application, vos déplacements de base de données sont réduits et vous trouvez ensuite des données provenant d'une source plus rapide qui est un cache distribué en mémoire. Mais ces fonctionnalités vont en fait vous aider à améliorer ces performances en fonction de votre cas d'utilisation spécifique.
- Cache Client
Donc, le premier dont nous allons parler est cache client. Ce qu'il fait, c'est qu'il réduit essentiellement vos déplacements vers le cache en cluster réel.
- Appels groupés
Ensuite, nous parlerons des appels en bloc, qui réduisent les déplacements vers le cache de telle sorte que vous n'effectuez qu'une seule opération et que vous n'utilisez qu'un seul appel et que plusieurs opérations en retour seront traitées côté serveur.
- Compression
Ensuite, vous avez aussi compression. Peut-être que si la taille de votre objet est supérieure, vous pouvez l'utiliser pour réduire la taille totale de l'objet qui est ajouté ou récupéré. En règle générale, nous vous recommandons de décomposer l'objet en une taille plus petite, mais dans le cas où ce n'est pas possible, vous pouvez utiliser la fonction de compression.
- Mises à jour asynchrones
Nous avons également des mises à jour asynchrones. Donc, en les utilisant, votre application n'attend pas que l'opération soit effectuée. Peut-être que vous pouvez créer une tâche distincte pour cela, puis en fonction de cela, vous pouvez vous permettre que les données soient ajoutées d'elles-mêmes et s'il y a une sorte de mise à jour que vous souhaitez récupérer, peut-être que les données ont été ajoutées ou non ou s'il y en a était un problème, vous pouvez simplement vous inscrire pour un rappel contre cela.
- Sérialisation compacte
Le prochain est sérialisation compacte. Ainsi, par exemple, si vous avez des objets personnalisés, des objets de domaine, qui ne sont pas marqués comme sérialisables et dans un cache distribué, puisqu'il est complètement hors processus, tous les objets devront être sérialisés. Ainsi, si vous avez ce scénario où vous ne pouvez pas vous permettre de modifier le code dans votre environnement mais que vous avez également besoin que vos objets personnalisés ou vos objets de domaine soient sérialisables, vous pouvez utiliser la fonctionnalité de sérialisation compacte de NCache pour les marquer tous comme sérialisables, puis en utilisant cela, vous pouvez réellement continuer à utiliser NCache au sein de votre environnement. C'est une option sans changement de code. Juste quelque chose que vous pouvez comprendre à partir de l'interface graphique et vous avez tout configuré.
- Cartes réseau doubles
Et puis finalement nous avons le cartes réseau doubles fonctionnalité. Donc, si vous voulez séparer essentiellement le trafic de la communication client à serveur et de la communication serveur à serveur, séparer les ressources réseau, vous pouvez le faire avec NCache. Ce n'est que dans le cas où vous avez, où vos, vous savez, vos ressources réseau sont réellement étouffées par le trafic excédentaire qui arrive. Ce n'est que dans ces scénarios que nous le recommandons. Mais, si vous ne voyez pas que ces ressources sont maximisées à ce stade, vous pouvez en fait conserver la même carte d'interface réseau pour les deux types de communications.
Démo
Alors, effectuons en fait notre premier test, dans lequel nous allons ajouter des éléments dans le cache et récupérer des éléments du cache et nous allons l'utiliser comme base avec l'API de base que nous avons. Encore une fois, il est déjà optimisé, mais nous allons l'utiliser comme référence et exécuter différentes fonctionnalités par-dessus et voir comment elles fonctionnent pour nous.
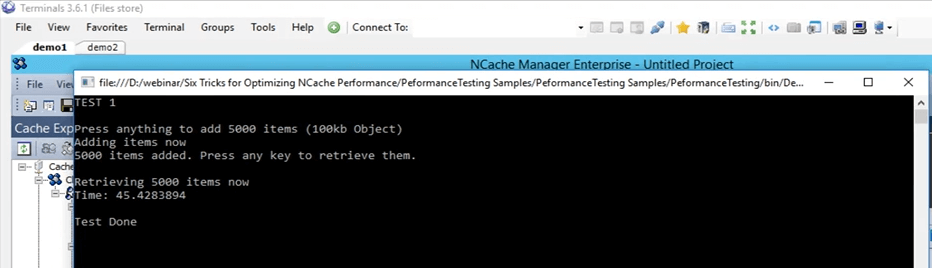
Donc, le premier, revenons en fait à cet échantillon ici. Donc, c'est un exemple que je peux également fournir ce code. C'est ce que nous allons utiliser pour vous montrer la ligne de base que nous allons couvrir. Donc, nous sommes dans le test 1. Dans le test 1, nous ajoutons essentiellement 5,000 100 éléments dans le cache de taille 5000 Ko, puis nous allons récupérer ces éléments dans le cache. Ce test nous donnera juste le temps qu'il faut pour tout ce code, cette partie de récupération va prendre. Dans cette partie de récupération, la boucle s'exécute en fait 5000 fois, car XNUMX éléments doivent être récupérés et dans les diapositives suivantes, nous allons expliquer comment différentes fonctionnalités peuvent réellement aider dans ce cas.
...
try
{
cache = NCache.InitializeCache(args[0]);
cache.Clear();
Console.WriteLine("TEST 1\n");
Console.WriteLine("Press anything to add " + objectsCount + " items (100kb Object)");
Console.ReadKey();
Console.WriteLine("Adding items now");
for (int i = 0; i < objectsCount; i++)
{
cache.Insert(key + i, obj1);
}
Console.WriteLine(objectsCount + " items added. Press any key to retrieve them.");
Console.ReadKey();
Console.WriteLine("\nRetrieving " + objectsCount + " items now");
datetime1 = DateTime.Now;
...Alors, exécutons cela. Vérifions d'abord que tout est correctement paramétré. Oui, démocache test 1 et je vais lancer ça. Donc, encore une fois, c'est le test numéro un, juste pour avoir une base de référence sur l'apparence des chiffres. Je vais appuyer sur Entrée. Il va commencer à ajouter des éléments dans le cache. Si nous revenons au NCache directeur, c'est ici, nous voyons qu'il y a une activité en cours. Donc, il ajoute des éléments dans le cache. Puisqu'il y a deux serveurs dans la partition de la topologie de réplique, les données sont ajoutées sur ces deux serveurs, sont ajoutées sur le serveur 1 qui est 107 et également sur le serveur 2. Ainsi, les données vont être divisées. Au total, le nombre total d'éléments dans le cache sera de 5,000 XNUMX.
Donc, dans ce cas, attendons qu'il soit terminé et une fois qu'il est terminé, nous pouvons en fait noter ce nombre et l'utiliser pour notre comparaison pour les fonctionnalités ultérieures avec lesquelles nous allons tester. C'est presque terminé, nous avons déjà ajouté environ 4,000 XNUMX articles.
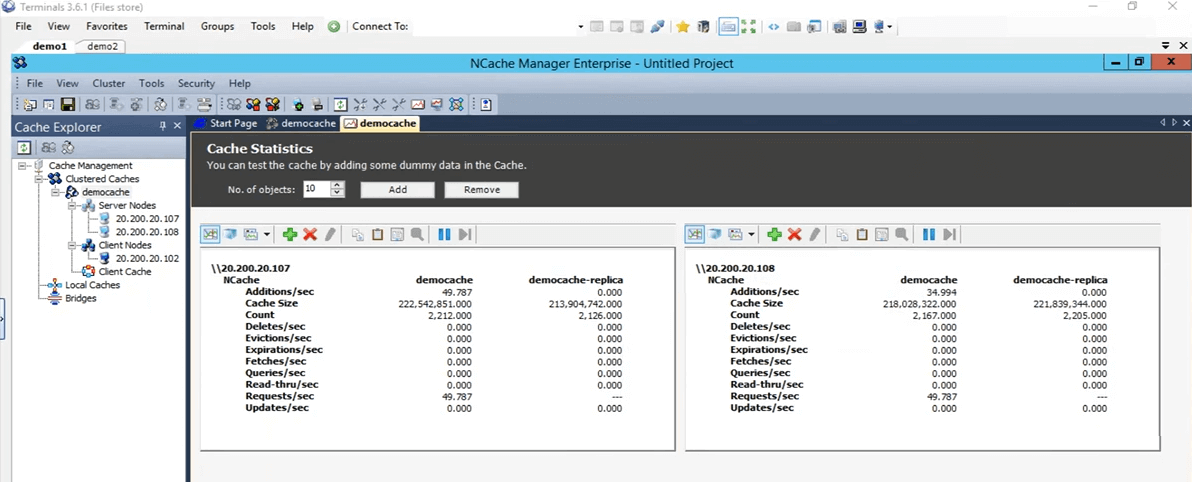
Gardez à l'esprit qu'il s'agit d'un objet de 100 Ko, ce qui est assez important pour, vous savez, les tests, mais c'était juste pour vous montrer à quoi ressemblent les différentes choses. Je pense qu'ils sont tous ajoutés, oui, ils sont tous ajoutés. Le compteur s'est effectivement arrêté. Si on clique sur Entrée, ça a pris, si on clique sur Entrée ça va commencer à récupérer ces éléments du cache et si tu reviens ici ça va afficher l'heure une fois que c'est fait. Ainsi, nous pouvons voir que les récupérations par seconde augmentent réellement et que les demandes par seconde augmentent également pour ces deux serveurs. Donc, cela vous montre en fait qu'il y a un peu d'activité en cours pour récupérer ces éléments dans le cache. Une fois qu'il aura récupéré tous les 5000 éléments du cache, il affichera le minuteur à l'écran et en utilisant ce minuteur, nous allons le définir comme référence pour nos prochains tests.
Cache client (près du cache)
Alors, parlons en fait du suivant. La prochaine, la fonctionnalité que nous allons utiliser en premier est le cache client. Alors, laissez-moi vous expliquer ce qu'est un cache client ? Un cache client est essentiellement un cache local, présent sur les boîtiers clients et ces boîtiers clients, ce qu'il fait, c'est qu'il réduit vos déplacements vers le cache en cluster. Le cache client est un sous-ensemble des données des caches en cluster. Il va conserver une copie locale avec lui-même des données des caches en cluster. Il reste synchronisé avec le cache du cluster.
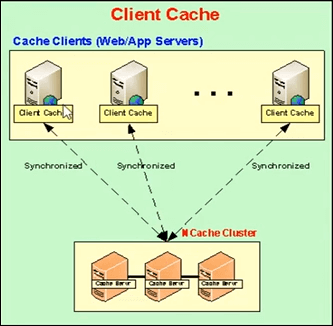
Ainsi, toutes les mises à jour effectuées sur le cache client sont propagées sur le cache en cluster et vice versa. Ainsi, il reste mis à jour avec le cache en cluster et ce qu'il fait, c'est que si votre application essaie de récupérer certains éléments du cache, elle fournit, si elle a ces éléments localement présents ici, elle partage simplement ces données ou ces éléments à droite sur-le-champ à partir d'une source locale.
Revenons en fait à cela. D'accord, il a fallu environ 45 secondes pour faire cette opération. Ainsi, une fois que nous utilisons le cache client, nous pouvons réellement voir comment cela affecte ce scénario. Je vais cliquer sur Entrée. On va garder ce souvenir, ce nombre qui est de 45 secondes.
Donc, nous parlions déjà du cache client. Donc, comme je l'ai mentionné plus tôt, vous avez essentiellement deux options. Vous pouvez soit exécuter le cache client en tant qu'InProc ou OutProc, c'est quelque chose que vous pouvez comprendre. Dans le cas d'OutProc, un processus séparé va s'exécuter, qui va rester, qui va rester synchronisé avec le cache en cluster.
Le processus OutProc est généralement recommandé lorsque vous avez un scénario de jardin Web dans lequel plusieurs applications ou plusieurs instances des applications s'exécutent sur le même boîtier. Ainsi, ils auraient une ressource commune à gérer, c'est-à-dire le cache client, un processus distinct en cours d'exécution. La deuxième option est un cache InProc et elle est recommandée dans le cas où vous avez un scénario de ferme Web, où vous avez généralement une ou deux applications exécutées sur le même boîtier.
Dans le cas de l'un, ce qui se passe, c'est que le cache client réside dans le processus des applications. Donc, dans ce cas, puisque cela fait partie du même processus, de nombreux frais généraux sont en fait supprimés. Dans ce cas, la surcharge de sérialisation, la surcharge de communication inter-processus, sont toutes supprimées et augmentent considérablement les performances.
Dans le cas d'OutProc, ce que vous mettez en cache, c'est que l'application obtient ces données d'une source locale, qui est présente sur la même boîte. Ainsi, un voyage réseau est en fait réduit. Donc, cela augmente un peu les performances et nous pouvons en fait le voir tout à l'heure.
Donc, dans ce que nous allons faire, nous allons créer un cache client, d'abord en tant que OutProc, puis en tant qu'InProc et nous allons voir à quoi ressemblent les numéros. Et dans le scénario actuel, si vous vous en souvenez, cela a pris 45 secondes avec des get normaux.
Kal, j'ai une question ici et la question est que toutes les fonctionnalités dont nous parlons font-elles partie du même produit ? Donc, je suppose qu'ils parlent d'éditions.
Oui, certains d'entre eux ne sont disponibles que dans l'entreprise, mais je peux partager comparaison des éditions document qui couvre en fait chaque détail pour chacun d'eux. Donc, peut-être que cela vous permettrait d'obtenir les détails exacts que vous recherchez.
Et, je vais saisir cette occasion et demander à tout le monde s'il y a des questions pour le moment ? Non, nous n'avons pas de questions, alors, s'il vous plaît, continuez à parler.
Cache client hors processus
Donc, je vais continuer et effacer le contenu du cache. Ils sont terminés maintenant. Donc, maintenant, je vais continuer et créer un cache client. Ainsi, dans le NCache manager, vous avez écrit le cache client ici. Faites un clic droit ici et cliquez sur créer un nouveau cache client. Donc, ici, je vais garder le même nom. Il est défini sur le cache client. Gardez tout par défaut. Ensuite, il est défini sur OutProc maintenant, mais nous le changerons en InProc plus tard. Cliquez sur Suivant. La taille qu'il a définie sur un gig. Je vais le garder comme ça. Je peux en fait changer cela en celui que je veux et certains autres paramètres avancés qui étaient également présents lors de la création d'un cache de cluster. Donc, maintenant, le cache client est en fait configuré sur ma boîte personnelle, c'est-à-dire 102.
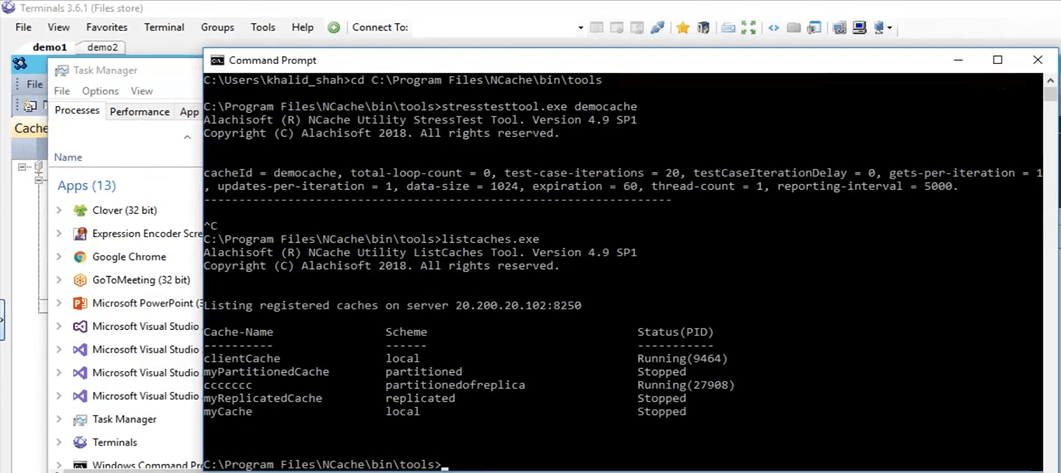
Un moyen rapide de vérifier cela serait d'exécuter simplement l'outil de listes de caches, présent dans ma boîte personnelle, une fois que j'ai installé NCache et en utilisant cet outil, il me permet en fait de savoir lequel NCaches sont en cours d'exécution sur ma boîte personnelle à ce stade. Donc, ici, si je viens ici, exécutons en fait les caches de liste. D'accord, il affiche les caches présents sur ma boîte personnelle, c'est-à-dire 102. Je pense qu'à l'arrière, il essaie toujours de l'activer pour une raison quelconque. Oui, il semble être activé là-bas. Donc, si vous venez ici, nous pouvons voir que le cache client. Ainsi, le cache client est un cache local ici et il est en cours d'exécution. Donc, il fonctionne sur ma boîte personnelle à ce stade et nous pouvons réellement l'utiliser maintenant.
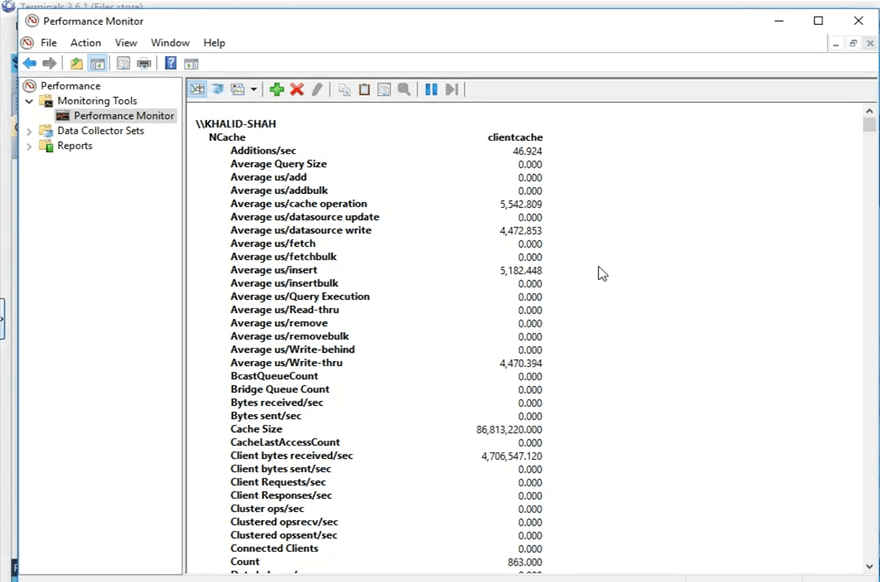
Donc, avant que je continue, alors, qu'est-ce que NCache fait, c'est qu'il publie ces compteurs qui sont même affichés à l'écran en ce moment. Ainsi, ils peuvent être visualisés via le moniteur de performances de Windows. Ce que je vais faire, c'est ouvrir le moniteur de performances Windows et ouvrir les compteurs du cache client que je vais utiliser.
Donc, je vais, à partir de ma boîte personnelle, je vais chercher un PerfMon qui surveille les performances ici, et en utilisant ce que je vais faire, je vais ouvrir le NCache catégorie et recherchez mon cache spécifique qui était le cache client et ouvrez les compteurs pour ceux-ci. Donc, il est ouvert maintenant et je vais ouvrir un tout nouveau moniteur de performances, pour rechercher la catégorie de NCache. Ça y est et j'ai ici le cache client tel qu'il est présent ici. Je vais cliquer sur ajouter et je vais cliquer sur OK. Je vais changer la vue en vue de rapport. Donc, maintenant, ce sont les compteurs. Tout s'affiche à 0 en ce moment car il n'est pas utilisé. C'est un processus distinct qui s'exécute car nous l'avons défini sur OutProc.
Voyons à quoi ressemblent les chiffres maintenant, depuis ma boîte personnelle. Je vais exécuter l'application, même code, je ne fais aucune sorte de changement de code. Les fonctionnalités de cache du client ne modifient pas le code, comme je l'ai mentionné précédemment, il vous suffit de l'activer ou de le désactiver, selon votre choix, puis il sera automatiquement récupéré. Donc, si je clique sur le bouton de démarrage, même code, même tout, même le même test, il va commencer à ajouter ces éléments une fois que je clique sur "Entrée". D'accord, donc, une fois que j'ai cliqué sur entrer, il a commencé à ajouter ces éléments. Si vous revenez au NCache manager, nous voyons que sur le cache groupé les éléments sont ajoutés. Si vous ouvrez le NCache moniteur, c'est celui-ci, oui, celui-ci, nous voyons qu'il y a un peu d'activité qui se passe ici aussi, et c'est ce que j'expliquais au départ. Lorsque vous avez configuré le cache client, il utilise et lorsque vous ajoutez des éléments dans le cache, le cache client obtient également une copie et le cache en cluster obtient également une copie.
Ce cas d'utilisation est généralement recommandé lorsque vous avez, par exemple, un ratio de lectures sur écriture de 80 % à 20 % ou même un ratio de lectures sur écriture de 70 % à 30 %. Ceci est généralement recommandé dans les scénarios où vous avez beaucoup de lectures, peut-être des données de référence à partir de données statiques que vous avez dans votre environnement et c'est là que vous verriez de grandes améliorations de performances lorsque vous avez activé un cache client.
Donc, gardez à l'esprit, le premier test avec juste l'API get exécutée en boucle, nous avons eu 45 secondes pendant lesquelles il a pu obtenir ces éléments du cache. Mais, en utilisant maintenant ce cache client, il trouverait toutes ces données dans une source locale, dans un processus séparé qui s'exécute sur la même boîte et nous allons voir comment cela fonctionne pour nous. Donc, si nous faisons défiler vers le bas ici, nous pouvons voir qu'il s'agit du décompte du cache client. Ce nombre doit aller jusqu'à 5,000 5,000 car il s'agit d'une source unique. Ainsi, tous les 5,000 XNUMX éléments vont être présents ici sur le cluster et ils vont être répartis entre tous les nœuds du serveur. Donc, nous attendons juste que ces éléments atteignent XNUMX XNUMX, puis nous allons exécuter la deuxième partie du test qui consiste à récupérer ces éléments dans le cache en cluster.
Donc, une autre chose à remarquer serait qu'une fois que nous aurions récupéré les éléments du cache, les appels n'iraient pas vers le cache groupé, ils seraient tous interceptés par le cache client qui est actuellement localement et c'est ce que je vais montrer vous de ces compteurs, ici. Ainsi, ces compteurs affichent les compteurs du cache client, mais si vous en arrivez là, ils affichent les compteurs côté serveur pour le cache en cluster. Cliquons sur entrer ici et il va commencer à récupérer ces éléments du cache. Donc, encore une fois juste pour vous montrer qu'aucune carte n'est déplacée ici. Donc, il n'y a pas d'appel à venir ici. Si vous ouvrez celui-ci, nous pouvons voir que cette activité se déroule ici. Il y a certaines récupérations en cours. Ainsi, le cache client est actuellement très utilisé et c'est tout l'intérêt d'avoir un cache client dans les scénarios où vous avez plus de lectures que d'écritures. Ainsi, après quelques secondes, nous devrions voir ici les résultats du temps qu'il a fallu pour vous montrer 5,000 100 éléments de taille 45 Ko à partir du scénario de cache client. Donc, ici, vous pouvez voir que de 33 secondes, il est passé à XNUMX secondes dans le cas où vous avez un cache client OutProc activé dans votre environnement.
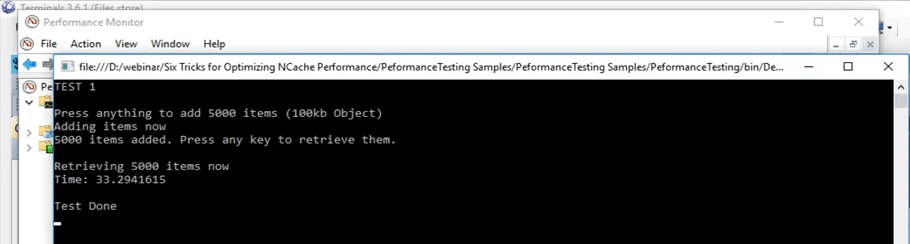
Donc, vous pouvez voir que c'est une grande amélioration. C'est plus de 10 secondes que vous pouvez voir et en termes d'applications c'est un gros moment. Donc, cela nous a montré une grande amélioration dans ce cas.
Cache client en cours
Donc, je vais continuer et créer un cache client In-Proc maintenant et en utilisant ce cache client InProc, nous allons voir comment cela fonctionne pour nous par rapport à ces 45 secondes pour le test réel, 33 secondes pour le test OutProc du cache client. Donc, tout d'abord, je vais aller de l'avant et supprimer ce cache. Maintenant c'est supprimé. Je vais créer un nouveau cache. Encore une fois, je vais juste taper InProc à côté et je vais cliquer sur suivant et je vais garder le niveau d'isolement pour être InProc, garder tout par défaut et je vais cliquer sur terminer. Donc, maintenant, cela est créé sur ma boîte personnelle et je vais exécuter exactement le même test. En fait, effaçons d'abord les données du cache.
Donc, maintenant, mêmes tests, mêmes arguments, et je viens de commencer. Donc, maintenant, il va à nouveau effectuer exactement le même test. 5000 éléments dans le cache de taille 100 Ko, puis il va récupérer ces éléments à l'aide du cache client InProc du client. Le concept reste exactement le même. Une fois que votre application ajoute des éléments dans le cache, vous devez également l'ajouter dans le cache client qui est présent dans le même processus, car nous l'exécutons maintenant en tant que In Proc. Ainsi, il ajoute également ces éléments dans le cache du client et il les ajoute également au cache en cluster. Donc, une fois que c'est fait, je vais cliquer sur entrer maintenant. Ainsi, une fois qu'il récupère ces éléments, il va trouver tous ces éléments dans le local, au cours du même processus.
Donc, maintenant, sans aucune surcharge impliquée, telle que la communication et la sérialisation inter-processus, la désérialisation, tout cela est complètement supprimé maintenant. Il obtiendrait les données directement à partir d'une source locale et nous verrions à quel point le cache client fonctionne réellement avec un mode InProc pour ce scénario spécifique. Donc, il ne reste plus qu'à attendre que les éléments soient ajoutés. Si nous revenons ici, nous devrions voir des compteurs monter et descendre. Nous pouvons certainement voir cela.
Donc, en attendant, les gars, s'il y a des questions, n'hésitez pas à me le faire savoir. Sam garde un œil sur l'onglet du dock des questions. Il va m'informer s'il y a des questions.
Donc, la prochaine chose que j'ai mentionnée plus tôt dans la liste sera les opérations en masse. Donc, nous n'allons tester qu'avec un seul, c'est-à-dire en utilisant l'API en masse. Mais, il existe différents concepts de différentes choses qui fonctionnent exactement de la même manière que les opérations en bloc et nous allons couvrir tout cela en théorie dans cette présentation. Voyons en fait combien d'éléments sont ajoutés. Ainsi, environ plus de 3000 articles ont déjà été ajoutés. Donc, nous attendons juste que le marqueur 5000 complet atteigne et après cela, nous allons voir comment cela fonctionne. Bon, je suis resté sur le premier. Donc, j'attends juste que les opérations soient effectuées dans le dos. En attendant, je parle juste de la première chose ici dans le cas des opérations en vrac.
Ainsi, le concept de base de l'opération en bloc consiste simplement à limiter votre nombre réel d'appels entrant dans le cache en cluster. Ainsi, au lieu d'effectuer toutes ces choses dans une boucle, comme nous l'avons déjà fait, nous pouvons en fait effectuer ces mêmes appels dans le cadre d'une seule opération. Ainsi, une seule opération envoyée au cache en cluster, puis plusieurs opérations contre cela peuvent être effectuées. Donc, si vous partagez en cas de vrac, vous devez connaître les clés. Ainsi, par exemple, vous venez de fournir les clés et les objets réels que vous souhaitez ajouter, juste un seul appel et en utilisant que tous ces éléments vont être réellement ajoutés dans le cache groupé à l'arrière.
Donc, je pense qu'ils devraient être faits, oui, ils sont presque finis maintenant. Si nous revenons ici, alors, tous ces éléments sont maintenant ajoutés. Je vais cliquer sur entrer et nous pouvons voir que tous ces éléments sont maintenant récupérés. C'est très étonnant à voir parce que beaucoup de frais généraux ont maintenant été supprimés. Donc, c'était extrêmement rapide. Donc, dans le cas où nous réitérons ce que nous avons fait lors du test initial, avec le test de base, cela a pris 45 secondes, avec le cache client OutProc, cela a pris environ 33 secondes. Mais, dans le cas du cache client InProc, tout ce temps est descendu à 0.1 seconde dans ce cas.
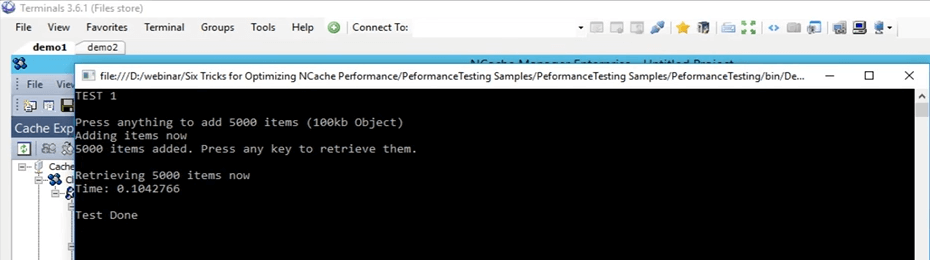
Donc, c'est le degré d'amélioration que vous pouvez voir avec un cache client InProc si votre cas d'utilisation correspond à celui que nous avons ici. C'est donc une grande amélioration que vous pouvez voir si vous avez plus de lectures et plus d'écritures en cours.
Donc, je vais juste cliquer sur entrer. Alors, ça se rapproche. Je vais supprimer ce cache client ici et le nettoyer également. Bon, revenons à la présentation. Donc, ici, donc, nous parlions d'opérations en vrac.
Obtention groupée (basée sur la clé)
Ainsi, dans le cas d'opérations en bloc, la première est qu'une fois que vous ajoutez, si vous avez beaucoup d'éléments que vous souhaitez ajouter ou même récupérer dans le cache, il vous suffit de lui fournir la liste en conséquence et en utilisant un seul appel, vous pouvez effectuer toutes ces opérations sur le cache. Donc, généralement, si vous avez une taille d'objet plus grande, nous vous recommandons de le décomposer en plusieurs objets, puis d'utiliser les fonctionnalités qui NCache fournit pour les regrouper ou même les obtenir ou les ajouter dans le cache. Ainsi, l'API en bloc peut être utilisée dans ces scénarios. Le second est, par exemple, si vous ne connaissez pas les clés de ces éléments, puisque le vrac était une opération basée sur les clés, vous devez donc connaître toutes les clés.
Requêtes de recherche SQL/LINQ
Dans les requêtes de recherche de type SQL ou LINQ, si vous ne connaissez pas les clés, vous pouvez en fait effectuer une recherche sur certains critères. Par exemple, si vous avez ajouté des produits dans le cache, vous pouvez en fait extraire plusieurs produits du cache en fonction de certains critères. Donc, disons, je lance une requête avec le nom 'SELECT produit WHERE produit.prix > 10 ET produit.prix < 100'. Ainsi, tous les produits qui satisfont réellement à ces critères spécifiques et qui sont présents dans le cache me seraient en fait retournés. Donc, dans ce cas, je n'ai pas spécifié de clés, j'ai juste spécifié avec les critères, et ils m'ont été retournés.
Groupes et sous-groupes
La suivante est de savoir si vous pouvez créer des collections logiques dans le cache. Je vais les couvrir tous les deux ensemble, en tant que groupes, sous-groupes, puis balises également. Donc, vous pouvez le faire. Ainsi, par exemple, si vous avez des clients et leurs commandes placées dans le cache, vous pouvez en fait regrouper toutes les commandes ensemble. Puisqu'il y a des éléments séparés dans le cache, vous pouvez également conserver des collections, mais nous vous recommandons de les décomposer, car généralement, une fois que vous obtenez un élément du cache, vous n'avez pas besoin de l'objet complet, vous avez besoin d'une certaine valeur. Donc, si vous le décomposez en plusieurs objets, vous pouvez l'utiliser de manière plus efficace. Ainsi, en utilisant ces fonctionnalités de collecte logique, vous pouvez essentiellement regrouper des éléments dans le cache. Ainsi, toutes les commandes d'un certain client peuvent être regroupées et en un seul appel. Disons qu'en groupe, vous pouvez faire un get par groupe ou dans le cas des tags pour obtenir par tag, juste fourni avec l'identifiant du client et tous ces éléments associés présents dans le cache vous seraient effectivement restitués. Encore une fois, dans ce cas, vous n'avez pas besoin de connaître les clés, vous avez juste besoin de connaître la certaine valeur de chaîne qui est un groupe ou une balise et sur cette base, elle vous a été renvoyée, puis elle prend également en charge les requêtes parallèles.
Opérations en masse - Démo
Passons donc à l'exemple d'opérations en bloc réel. Donc, si vous revenez à ce test, ici. C'est le test en masse, c'est-à-dire le test 2 et nous allons réellement l'exécuter. Commençons en fait d'abord, puis nous pourrons entrer dans les détails de ce qu'il fait. Donc, je viens de le changer pour tester 2 maintenant et je l'ai commencé. Donc, ce que fait ce test, c'est qu'il ajoute fondamentalement 10,000 10 éléments de taille XNUMX Ko dans le cache en ce moment. Tout d'abord, il ne fait qu'une insertion de base consistant à ajouter ces éléments dans le cache, puis il récupère tous ces éléments et enregistre également le temps des ajouts et la partie de récupération.
Console.WriteLine("TEST 2\n");
Console.WriteLine("Press anything to add " + objectsCountBulk + " items (10kb Object)");
Console.ReadKey();
Console.WriteLine("Adding items now");
datetime1 = DateTime.Now;
for (int i = 0; i < objectsCountBulk; i++)
{
cache.Insert(key + i, obj2);
}
datetime2 = DateTime.Now;
Console.WriteLine(objectsCountBulk + " items added. Time to add " + objectsCountBulk + " items in a loop: " + (datetime2 - datetime1).TotalSeconds);
Console.WriteLine("\nPress any key to retrieve them.");
Console.ReadKey();Ainsi, une fois que cela est fait, nous obtenons une base de référence du temps qu'il a fallu pour ajouter 10,000 10 éléments de taille 10,000 Ko dans le cache, puis il démarre les opérations en masse. Dans ces opérations en bloc, il ajoute tous ces XNUMX XNUMX éléments dans le cache avec le même appel et récupère à nouveau avec un seul appel, ainsi que la liste des clés et la liste des objets prédéfinies.
Ok, je vais cliquer sur entrer. Il va commencer à ajouter ces éléments dans le cache. Si nous revenons au NCache directeur, nous voyons qu'il y a un peu d'activité en cours ici. Ces éléments sont maintenant ajoutés dans ces deux serveurs qui sont actuellement présents.
Même si vous regardez le cluster de moniteurs, nous pouvons voir un client connecté ici, un client connecté là-bas, puis nous voyons qu'il y a un peu d'activité dans ces graphiques. Ainsi, en utilisant cela, vous pouvez en fait avoir une assez bonne idée de ce qui se passe dans le cache, de ce qui est utilisé, de ce qui n'est pas utilisé à ce stade et de la quantité d'utilisation. C'est presque fait tous les 10,000 10,000 articles, je pense maintenant ajoutés. Oui, ils le sont et je vais appuyer sur Entrée pour récupérer ces 37 10,000 éléments. Donc, tout d'abord, il a fallu environ 30 secondes pour ajouter ces éléments dans le cache. Maintenant, ce qu'il fait, c'est qu'il lit ces 10,000 10,000 éléments du cache. Donc, si vous voyez, ici, nous pouvons voir qu'il y a des récupérations par seconde sur ces deux nœuds de serveur. Ainsi, les articles sont actuellement récupérés en ce moment. Donc, il va maintenant chercher dans une boucle en ce moment. Gardez à l'esprit qu'une fois qu'il aura terminé, il commencera le test en masse. Donc, sur la base de ce test en masse, nous comparerons ces deux chiffres et verrons comment ils affectent réellement. Donc, ici, il a fallu environ 10 secondes pour récupérer ces 37 10,000 éléments et avec l'API en masse, les ajouts ont été terminés et cela devrait bientôt être fait avec la partie de récupération, je pense, oh oui, il faut appuyer sur ENTER. Ok, attendons en fait qu'il soit terminé et ensuite je pourrai vous montrer à quoi ressemblent toutes ces choses. Donc, maintenant c'est complet. Donc, juste pour passer ce test, il a ajouté 30 10,000 éléments de taille 5 Ko dans le cache à l'aide d'une boucle et a pris environ XNUMX secondes. Pour récupérer ces XNUMX XNUMX éléments, il a fallu environ XNUMX secondes, toujours en boucle. Avec le test en bloc, il a ajouté ces XNUMX XNUMX éléments dans le cache et cela a pris environ XNUMX secondes.
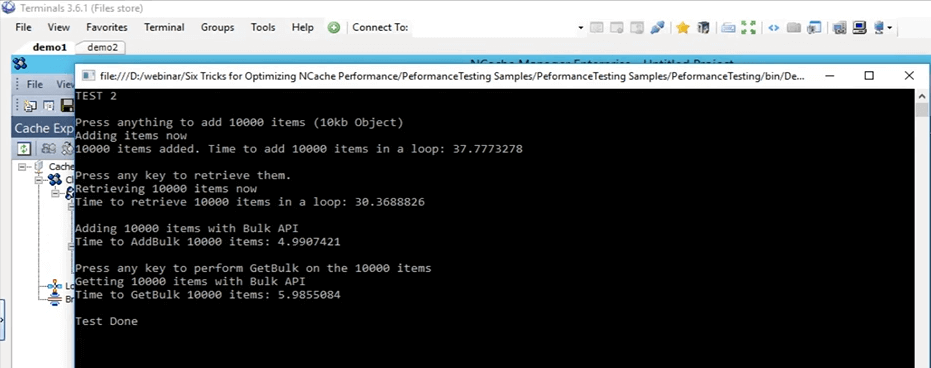
Donc, c'est un grand écart entre 37 secondes et 5 secondes et pour récupérer ces éléments dans le cache, il a fallu environ, disons, 6 secondes. Donc, une grosse différence encore entre 6 secondes et 30 secondes. Donc, c'est le degré d'amélioration que les opérations en bloc peuvent réellement apporter à vous et à votre application et en utilisant cela, vous n'avez pas besoin d'exécuter le même appel encore et encore. Vous n'avez pas besoin d'accéder au cache en cluster à chaque fois. Vous pouvez essentiellement créer une collection de toutes les opérations que vous devez effectuer, en utilisant l'API en masse, vous pouvez simplement les ajouter dans le cache.
Compression - Démo
Donc, maintenant, notre test en masse est réellement terminé. Revenons donc à la présentation. Donc, le prochain est le test de compression. Encore une fois, comme je l'ai mentionné plus tôt, nous recommandons généralement de décomposer l'objet en une taille plus petite, mais si vous n'avez pas cette option disponible, ce que vous pouvez faire, c'est que vous pouvez réellement compresser, vous pouvez en fait définir un certain seuil. Tout objet supérieur à cela ne serait pas compressé à une taille plus petite. Activons en fait la compression sur notre environnement dès maintenant. Alors, tout d'abord, allons-y et vidons le cache. C'est fait. La compression est quelque chose qui peut être fait à la volée. Ainsi, le cache n'a pas besoin d'être arrêté. Donc, si je fais un clic gauche sur le nom du cache, ça va ouvrir toutes ces différentes configurations. Si je vais ici et que j'ouvre des options ici, ce que je dois faire, c'est simplement cliquer sur cette option pour activer la compression. Je vais le mettre à 50 Ko. Ainsi, tout ce qui dépasse 50 Ko sera compressé. Faites un clic droit sur le nom du cache et cliquez sur appliquer les configurations. Toutes ces configurations vont maintenant être appliquées sur le cluster. Ainsi, tout objet supérieur à celui-ci serait en fait compressé.
Donc, je vais exécuter le même test que nous avons initialement fait et c'était le test 1. Revenez au test 1, enregistrez-le et je vais appuyer sur run (démarrer). Attendons qu'il démarre, puis je donnerai plus de détails sur la façon dont la compression aide réellement dans différents scénarios. Ainsi, comment fonctionne la compression, c'est qu'une fois que le client envoie ces éléments au cache, il les envoie sous forme compressée. Ainsi, la compression aide, une fois que l'élément voyage sur le réseau, il est de plus petite taille et une fois qu'il reste dans le cache groupé, il prend également moins de place.
Kal, je voulais juste vous rappeler qu'il nous reste 10 minutes avant la fin de la session, alors, rythmez-vous en conséquence. D'accord, d'accord merci. Des questions à ce stade ? Non, on dirait que tout le monde va bien. En fait, nous avons deux confirmations, jusqu'ici tout va bien, donc, tout va bien. D'accord, parfait. Merci.
Bon, alors, je parlais de la compression comment ça aide. Donc, dans le cas où il y a deux choses, tout le parcours réseau d'un objet de plus petite taille va évidemment être plus rapide que celui d'une taille plus grande et une fois que cet objet est placé dans le cache, cliquez sur Entrée pour qu'il commence à récupérer ces éléments . Ainsi, une fois qu'il est placé dans le cache, il est également plus petit. Ainsi, il consomme moins d'espace. Le temps total de traitement de cet article est également réduit. C'est ainsi que la compression aide dans votre scénario. Il y a une surcharge impliquée du côté client lors de l'ajout. Mais, toute l'amélioration nette que nous remarquerons en ce moment est en fait supérieure à cela. Donc, tout le temps qu'il faut pour, vous savez, toutes les opérations ont été trouvées sur ces objets va en fait être beaucoup plus rapide. Ainsi, le test 1 effectué avec compression a pris environ 26 secondes.
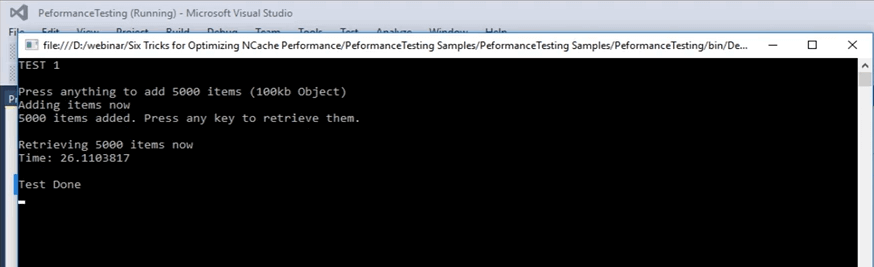
Si vous vous souvenez au départ, lors de notre premier test sans rien, sans fonctionnalités spéciales impliquées, juste l'API de base, cela a pris 45 secondes, je crois. Donc, il y a une grande différence entre 45 secondes et 26 secondes. Donc, c'est à quel point la compression aide réellement, et si ces opérations sont encore plus étendues, il y aurait encore plus de différence dans ce cas. Donc, cela aide beaucoup dans ce cas.
Opérations asynchrones - Démo
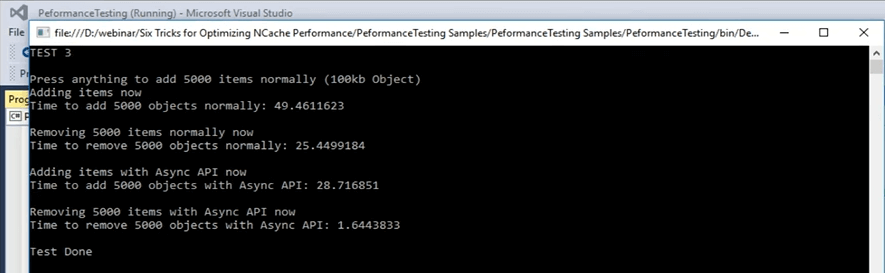
Passons donc au scénario suivant que nous avons, à savoir les mises à jour asynchrones. Les mises à jour asynchrones sont essentiellement votre application n'attend pas. Vous pouvez configurer une tâche distincte pour cela et cette tâche va effectuer ces opérations. Vous pouvez configurer des rappels pour obtenir uniquement les informations si l'élément a été ajouté ou s'il n'a pas été ajouté pour n'importe quel scénario. Vous pouvez également le configurer. Je vais maintenant passer rapidement à l'échantillon et je pense qu'il s'agit du test numéro 3, mais je peux le confirmer rapidement. D'accord, c'est le test numéro 3 pour les mises à jour asynchrones. Commençons réellement et ensuite nous pourrons examiner les détails du code. Dès que je pourrai reprendre le contrôle, je vais ouvrir le fichier de code et vous montrer ce qui se passe dans le test numéro 3 qui concerne les mises à jour asynchrones. Commencé maintenant. Donc, dans les mises à jour asynchrones, c'est le test numéro 3, ce qui se passe, c'est qu'il ajoute d'abord un élément dans le cache en utilisant uniquement l'appel d'insertion de base, puis une fois l'ajout de ces éléments terminé, il les supprime à nouveau dans une partie d'un boucle. Ainsi, chaque clé est supprimée en une seule itération.
...
else if (args[1].Equals("test3"))//ASYNC API TEST
{
Console.WriteLine("TEST 3\n");
Console.WriteLine("Press anything to add " + objectsCount + " items normally (100kb Object)");
Console.ReadKey();
Console.WriteLine("Adding items now");
try
{
cache = NCache.InitializeCache(args[0]);
datetime1 = DateTime.Now;
for (int i = 0; i < objectsCount; i++)
{
cache.Insert(key + i, obj1);
//cache.InsertAsync(key + i, obj1, OnItemAdded, "", "");
}
...Je vais cliquer sur Entrée. Il ajoute 5,000 100 éléments dans le cache de taille XNUMX Ko et il le fait normalement. Par normalement ici, je veux dire juste une simple insertion, puis il supprime ces éléments avec à nouveau dans une partie de la boucle. Donc, en utilisant cela, nous allons voir combien de temps cela prend pour cette partie, puis nous allons ensuite utiliser les appels asynchrones pour les ajouts, les insertions asynchrones, puis pour les supprimer. Pendant qu'il ajoute ces éléments, revenons en arrière et voyons à quoi ils ressemblent. Donc, dans ce cas, il s'agit simplement d'une suppression de base pour supprimer ces éléments. Dans la partie de test asynchrone, ce qu'il fait, c'est qu'il fait l'appel d'insertion asynchrone. Ainsi, le client n'attend pas, il passe simplement l'opération dans la file d'attente. La file d'attente ne signifie pas que ça va être un processus lent, le client ne l'attend pas et c'est fait comme un joli, vous savez, comme un processus d'arrière-plan mais c'est fait assez rapidement. Parce que beaucoup d'opérations dans le cache sont en fait effectuées de manière asynchrone.
...
datetime2 = DateTime.Now;
Console.WriteLine("Time to remove " + objectsCount + " objects normally: " + (datetime2 - datetime1).TotalSeconds);
Console.WriteLine("\nAdding items using Async API now");
datetime1 = DateTime.Now;
for (int i = 0; i < objectsCount; i++)
{
//cache.Insert(key + i, obj1);
cache.InsertAsync(key + i, obj1, OnItemAdded, "","");
}
datetime2 = DateTime.Now;
Console.WriteLine("Time to add " + objectsCount + " objects with Async API: " + (datetime2 - datetime1).TotalSeconds);
Console.WriteLine("\nRemoving " + objectsCount + " items with Async API now");
...Laisse moi te donner un exemple. Ainsi, par exemple, si la réplication est évoquée, si vous vous souvenez du processus de création du cache, nous l'avons défini comme asynchrone. Donc, en utilisant cela, beaucoup d'entre eux sont effectués en arrière-plan. Ils sont très fiables. C'est juste que votre application, le processus principal, la tâche principale n'en est pas affectée. Ainsi, il a fallu environ 49 secondes pour ajouter ces éléments dans le cache pour ajouter ces éléments dans le cache. Maintenant, il supprime en fait ces 5,000 5,000 articles. Maintenant, une fois cela fait, nous allons voir comment les appels asynchrones prennent. Ainsi, il doit déplacer 25 49 articles. Il a fallu environ 49 secondes pour supprimer ces éléments et maintenant il ajoute des éléments avec l'appel asynchrone et nous allons voir quelle différence nous obtenons entre 28 secondes et le nombre que nous allons obtenir maintenant en termes de quand nous ' re ajouter des éléments dans le cache. Le voilà. Ainsi, de 25 secondes, il a été réduit à 1.6 secondes dans la partie des ajouts et dans le cas de la suppression de ces éléments, il est passé de 25 secondes à XNUMX seconde. Donc, c'est la quantité de performances que nous pouvons réellement voir une fois que cela est impliqué. Donc, vous pouvez voir qu'il y a une grande différence. Il y a environ XNUMX secondes de différence entre la suppression d'éléments d'un appel de suppression de base et d'un appel de suppression asynchrone. C'est donc quelque chose que vous pouvez attendre de ce type de fonctionnalités offertes par NCache.
Cartes réseau doubles - Démo
Revenons en fait à la présentation. Nous avons couvert l'asynchrone et le suivant est la sérialisation compacte. Donc, encore une fois, cela est couvert dans les scénarios où vous n'avez pas le luxe de faire une mise à jour dans le code et en utilisant cela, vous pouvez réellement marquer toutes ces classes comme sérialisables. Kal avec ce commentaire, il nous reste environ 3 minutes, donc… D'accord, d'accord. Je vais juste le couvrir rapidement. Donc, les deux dernières choses qui restaient étaient, l'une est la sérialisation compacte et l'autre, c'est que nous avons la fonction de double carte réseau. Donc, comme je l'ai mentionné plus tôt, si vous voyez que vos ressources réseau sont maximisées, par défaut, le type de communication, la communication serveur à serveur et la communication client à serveur, les deux se produiront sur la même carte d'interface réseau. Mais, si vous voyez que vos ressources réseau sont maximisées, vous pouvez séparer le type de communication entre le client et le serveur, puis la communication entre le serveur et le serveur. C'est une tâche très simple au sein du NCache gestionnaire. Si vous venez ici, pour le sélectionner, faites un clic droit ici et cliquez sur sélectionner NIC.
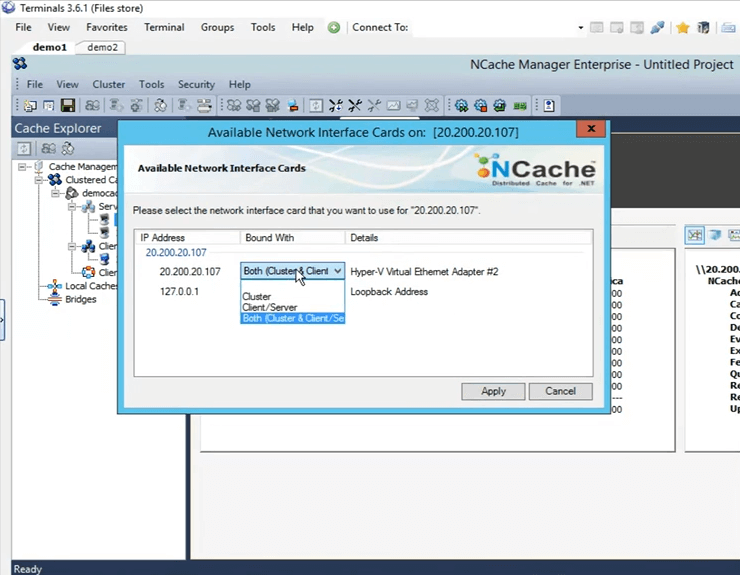
Une fois que vous avez sélectionné NIC, vous pouvez en fait spécifier la communication que vous souhaitez avoir sur cette certaine adresse IP. Depuis, je n'en ai qu'un, j'ai ces options disponibles. Si j'ai plusieurs adresses IP, je peux en fait la sélectionner sur-le-champ. Donc, je vais juste cliquer sur annuler.
Nous n'avons pas eu l'occasion de faire la démonstration de sérialisation compacte par manque de temps, mais je peux en fait partager cet échantillon avec vous et vous pouvez le tester et voir comment cela fonctionne pour vous. Sam à vous. Parfait. Eh bien, merci beaucoup pour votre temps Kal.
Y a-t-il des questions avant de conclure la session d'aujourd'hui ? Je vais juste donner une minute pour voir s'il y a des questions. Ok, donc, il y a une question.
Pouvez-vous s'il vous plaît partager le lien où vous allez partager cette présentation ? Donc, Kal, je suppose qu'il serait disponible sur notre site Web, n'est-ce pas ?
Oui, il va être disponible et j'ai noté leur e-mail là-bas. Donc, ce que je peux faire, c'est que je peux leur envoyer un e-mail, dès qu'il est téléchargé. D'accord. En fait, nous avons une autre question.
Pouvons-nous programmer une présentation, ok, alors, pouvons-nous programmer une démo pour notre équipe ?
Oui absolument. Vous pouvez certainement programmer une démo. Vous pouvez contacter notre équipe d'assistance support@alachisoft.com ou notre équipe commerciale sales@alachisoft.com et faites-nous savoir quelles sont vos préférences de temps et nous serons plus qu'heureux de programmer une session personnalisée pour vous.
D'accord, Kal, je vais continuer et conclure. Je ne pense pas que nous ayons d'autres questions. Merci à tous d'avoir rejoint et assisté à la session d'aujourd'hui, nous l'apprécions. Comme je l'ai dit, si vous avez des questions, veuillez contacter notre équipe d'assistance ou pour les questions liées aux ventes, contactez notre équipe de vente. Nous serons là pour vous aider. N'hésitez pas à nous appeler. Vous pouvez également nous joindre directement par téléphone. C'est sur notre site web. Jusqu'à la prochaine fois, merci beaucoup et bonne soirée, au revoir.