Replica Cache Topology
In un cluster, se tutti i nodi del server hanno la stessa copia dei dati, ci garantisce un'elevata disponibilità. Ciò significa che il cluster può sopravvivere ad alcuni errori di nodo senza perdere dati. Per questo scopo, NCache provides the Replicated Topology to ensure that use
Note:
Questa funzionalità è disponibile anche in NCache Professional.
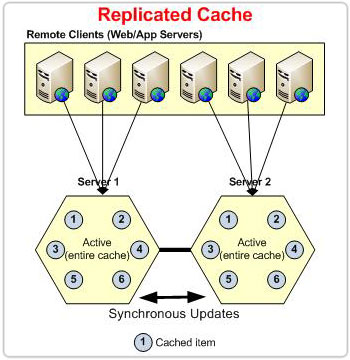
Sincronizza replica
Ogni volta che un client esegue un'operazione di scrittura (aggiunge, aggiornamenti, o rimuove), questa operazione viene trasmessa in broadcast in tutto il cluster per replicarla su tutti i server cache prima di restituire il controllo al client. Il server che riceve le operazioni dal client è responsabile della trasmissione di queste operazioni. Durante questo processo, un token di sequenza viene prelevato dal server coordinatore e associato all'operazione corrente per garantire che questa operazione venga eseguita su tutti i server nella stessa sequenza per ottenere la coerenza dei dati.
Se un'operazione di scrittura trasmessa non riesce su qualsiasi server cache, l'errore viene trasmesso anche a tutti i server cache per rimuovere questi dati. Questo viene fatto per ottenere la coerenza dei dati in tutto il cluster, il che significa che se i dati sono presenti nella cache, tutti i server hanno gli stessi dati.
Poiché la replica viene eseguita in modo sincrono, questa topologia non è adatta per le operazioni di scrittura poiché più server richiedono più tempo per la replica dei dati su tutti i server cache prima di restituire il controllo all'applicazione di scrittura. Si consiglia di limitare la dimensione del cluster a 3 server se non si desidera riscontrare alcun peggioramento nelle prestazioni delle operazioni di scrittura.
Ruolo del Server Coordinatore
Il server Coordinator (il nodo del server più anziano) esegue più attività come trasferimento di stato, operazioni di scrittura dietro, invalidazioni dei dati come Scadenze ed dipendenze, ecc. Dopo aver deciso di rimuovere uno qualsiasi degli elementi dalla cache, chiede a tutti gli altri nodi di rimuovere anche questi elementi dal loro archivio cache. Quando il server coordinatore lascia il cluster, il successivo server più senior diventa il server coordinatore e riprende le sue responsabilità.
Operazioni di lettura completamente scalabili
Poiché tutti i server hanno gli stessi dati e i client sono distribuiti tra tutti i server cache. Quindi, ogni server fornisce gli stessi dati ai client. Più server nel cluster significano che più richieste di lettura dei dati vengono servite contemporaneamente.
Bilanciamento del carico di connessione
La topologia replicata ha una caratteristica speciale bilanciamento automatico delle connessioni client tra i server per condividere il carico dei dati tra i server cache. Quando un client si connette a un server, questo server verifica che anche tutti gli altri nodi del server abbiano lo stesso numero di client. Se altri server hanno meno client, rifiuta con garbo la richiesta di connessione del client e la reindirizza agli altri server. In questo modo, tutti i server hanno lo stesso numero di client e nessun server è sovraccaricato da più client rispetto agli altri server cache.
Connettività del cliente
Nella topologia replicata, un client è connesso solo a un server di un cluster alla volta. Se il server connesso non funziona, il client si connette automaticamente con un altro server del cluster senza alcun intervento umano.
Trasferimento di Stato
Un trasferimento di stato viene attivato all'unione e all'uscita del nodo nella topologia replicata. Il trasferimento di stato attivato quando un nodo lascia il cluster non fa molto, poiché tutti i nodi hanno gli stessi dati. Ma, al momento dell'unione del nodo, un nodo appena unito chiede al server coordinatore di fornire tutti i dati memorizzati nella cache per sincronizzarsi con il resto del cluster.
Vedere anche
Topologie partizionate
Topologia specchiata
Cluster di cache
Cache locale