Cargas de pico, falhas, interrupções do sistema são altamente prováveis de fazer parte de seu cluster de cache e não é algo para se preocupar. No entanto, não ter nenhuma solução alternativa para essas situações definitivamente é! A resiliência a falhas contra esses fatores causadores de risco é o principal requisito do cluster de cache para que a recuperação de cenários de falha seja sempre útil. Em algumas situações, a perda de dados pode ser insignificante e pode ser tratada facilmente, mas em alguns casos em que estão envolvidos dados de missão crítica, a proteção e a disponibilidade de dados não podem ser colocadas como um requisito secundário.
NCache NÃO PERDE SEUS DADOS!
NCache, sendo um armazenamento em cache de dados distribuído na memória, fornece uma arquitetura onde a alta disponibilidade de dados é garantida sob cargas de pico ou tempo de inatividade. Seus dados permanecem 100% disponíveis mesmo em situações desastrosas, como um nó deixando permanentemente o cluster. NCache é arquitetado para lidar com a adição ou remoção em tempo de execução de um nó de servidor.
Você também pode modificar as configurações de cache em tempo de execução com os principais recursos aplicáveis. Com a arquitetura ponto a ponto, NCache salva você com o maior problema de “ponto único de falha”. O suporte a failover não é fornecido apenas no cluster de cache, mas também nos clientes conectados ao cache. Faz NCache altamente dinâmico e extremamente confiante para reivindicar nenhuma perda de dados. Vejamos a figura abaixo para entender NCachedisponibilidade.
A etapa 1 mostra um cluster conectado onde os clientes estão conectados com o NCache cluster com arquitetura ponto a ponto.
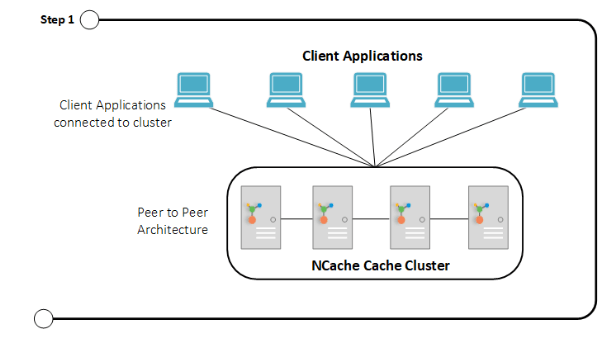
Etapa 1: clientes conectados a NCache
A Figura 2 mostra um nó saindo do cluster de cache devido a qualquer desastre.
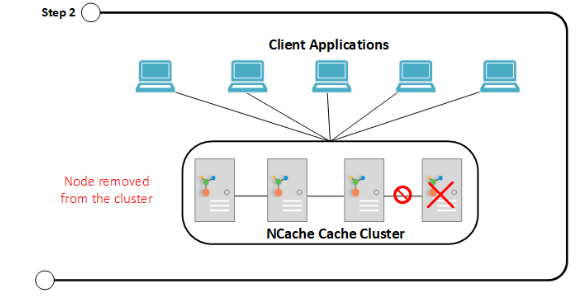
Etapa 2: nó do servidor removido
A figura abaixo mostra que o cluster de cache equilibrou os dados entre os nós restantes e os clientes permanecem conectados ao cluster de cache.
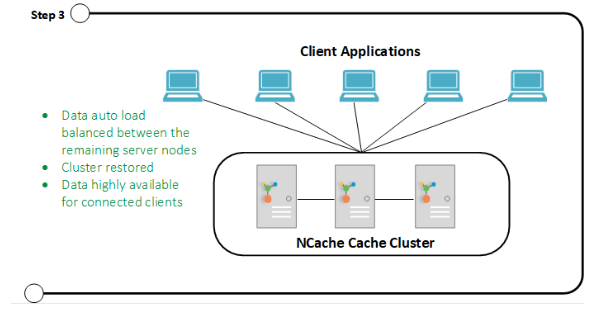
Etapa 3: cluster restaurado
Topologias de cache
NCache fornece diferentes topologias para armazenamento de dados para que você possa armazenar os dados de acordo com sua própria necessidade. Observe as topologias abaixo:
- Topologia espelhada: Como o nome sugere, espelhado topologia significa um cluster com dois nós, sendo um deles o nó ativo espelhado com o nó passivo.
- Topologia replicada: In replicado topologia, cada nó tem os mesmos dados replicados nele.
- Cache Particionado: Dentro particionado topologia, cada nó do servidor tem uma partição e os dados são divididos igualmente entre o nó e sua partição.
- Partição do cache de réplica: Partição de réplica topologia é a topologia mais rápida, pois mantém a réplica de cada partição. Cada partição é replicada em um servidor diferente e as réplicas são passivas, o que significa que os clientes não podem se conectar a elas.
Vamos agora discutir as topologias de armazenamento em cache wrt de disponibilidade de dados. Cada topologia, conforme mencionado, possui características diferentes. Topologia replicada garante que os dados sejam replicados em todos os nós, mantendo assim os dados 100% disponíveis. Dentro Topologia Particionada, se um único nó estiver inativo, alguma parte dos dados será perdida. No entanto, em Réplica particionada topologia, como toda partição possui uma réplica, se um nó for perdido, os dados serão redistributado entre os nós restantes. Isso torna a topologia POR a mais eficiente em relação à disponibilidade de dados. A topologia de réplica particionada assíncrona tem replicação de dados em segundo plano que pode causar perda de dados, no entanto, com a topologia POR síncrona, não ocorre perda de dados, pois a replicação ocorre por meio do aplicativo cliente.
Topologias de cache Agrupamento dinâmico de autocura NCache Arquitetura
Arquitetura ponto a ponto em NCache
A arquitetura ponto a ponto significa que não há conceito de nó mestre ou escravo em NCache. Um cluster é formado por um conjunto bem definido de servidores e cada servidor está conectado a todos os outros servidores no cluster de cache. Existe um nó coordenador que é responsável por gerenciar todo o cluster. Um nó coordenador é o nó mais antigo em relação aos nós que se juntam ao cluster. Se um nó coordenador deixar o cluster, o próximo nó mais antigo se tornará o nó coordenador. O nó coordenador também compartilha toda a informação da distribuição de dados nos outros nós para que o próximo nó coordenador já saiba tudo sobre a distribuição de dados.
A distribuição de dados ocorre com base em buckets. Um único bucket é a unidade mínima de distribuição de dados. Todos os buckets são distribuídos uniformemente entre os nós no cluster de cache.
Por exemplo, um cluster de cache com dois nós e 1000 buckets de dados mantém 500 buckets de dados em cada nó. NCache distribui os dados com base em um mapa de distribuição. O mapa de distribuição mapeia os buckets com os nós nos quais os buckets residem.
O processo de transferência de dados de um nó para outro é chamado transferência de estado. Ele transfere o bucket de dados por bucket do existente (nó de origem) para o novo nó (atribuído). O tempo durante o qual a transferência de estado ocorre, todas as operações com falha/relacionadas a um determinado bucket são direcionadas para o nó de origem até que todo o processo de transferência de estado ocorra. Uma vez concluído o processo de transferência de estado, todos os nós são informados sobre a conclusão da transferência de estado.
Descoberta de tempo de execução no cluster e nos clientes
NCache se destaca em disponibilidade de dados por seus recursos dinâmicos. Se um nó se juntar ao cluster de cache, todos os nós servidor e cliente recebem essa informação em tempo de execução, fazendo com que a distribuição de dados ocorra. O nó coordenador certifica-se de que um novo servidor ingressou no cluster de cache e adiciona o novo nó de servidor na lista de nós do cluster de cache. Ele também informa a todos os outros nós de servidor sobre um novo nó de servidor entrando no cluster de cache. Depois disso, o novo nó do servidor adquire uma conexão TCP com todos os outros nós do servidor. Portanto, o novo servidor não tem informações sobre os nós de servidor de cache existentes até que tenha ingressado no cluster de cache.
Da mesma forma, os clientes de cache também são descobertos em tempo de execução. Um cliente ao se conectar ao cluster de cache não precisa saber sobre todo o cluster de cache e todos os nós do servidor. Ele só precisa das informações de um único servidor de cache em execução. Ele usa essa conexão para ver a quais servidores de cache se conectar. A seguir estão as informações vitais que o cliente é atendido após o estabelecimento da conexão:
- Mapa de distribuição de dados: o mapa que contém as informações de quais dados residem em qual nó do servidor para que possam ser acessados facilmente.
- Topologia de cache: As informações sobre a topologia de cache para determinar a qual servidor de cache se conectar.
- Informações de associação de cluster: as informações sobre os membros do cluster, como um novo nó entrando no cluster ou um nó existente saindo de um cluster.
- Informações relativas compressão ou criptografia.
- Informações de serialização: Binário ou JSON.
Clustering dinâmico Recuperação automática de cérebro dividido Modo de Manutenção
Suporte a failover de conexão
NCache cluster é um cluster dinâmico de autocorreção e lida com qualquer failover em tempo de execução. Dois tipos de suporte a failover são fornecidos por NCache:
- Suporte a failover no cluster: Se um servidor de cache sair do cluster a qualquer momento, o cluster de cache se recuperará com muita eficiência da perda de um servidor de cache. Para explicar melhor, isso significa que o cluster de cache divide os buckets de dados entre os nós restantes do servidor de cache e atualiza todos os nós do servidor de cache sobre a nova distribuição.
- Suporte de Failover no Cliente: Semelhante aos servidores de cache, os clientes de cache também se ajustam de acordo com os outros servidores de cache existentes. Se um cliente estiver conectado a um servidor de cache e a conexão for perdida devido à indisponibilidade do nó do servidor, todos os clientes conectados a ele serão movidos automaticamente para outros nós existentes.
Modo de Manutenção
O modo de manutenção é outro recurso orientado ao usuário fornecido por NCache. Conforme discutido anteriormente, a transferência de estado ocorre em cada nó que sai ou entra no cluster. Em cenários em que um nó de servidor deixa o cluster para evitar a transferência de estado desnecessária, o modo de manutenção é útil. Ele oferece o controle para interromper um nó para manutenção e economizar para o cluster o custo de um processo de transferência de estado caro. Enquanto um nó está em manutenção, todas as operações são atendidas a partir do nó de réplica. Assim que o nó se junta novamente ao cluster, ele sincroniza o estado com o nó de réplica.
Conclusão
A disponibilidade de dados é o maior desafio ao lidar com dados de cache. NCache é rico em recursos de ponta para lidar com a disponibilidade de dados a todo custo, proporcionando controle imediato de danos em situações desastrosas. Não só isso, NCache tem uma arquitetura muito escalável que fornece não apenas alta disponibilidade, mas também permite dimensionar seu cluster de cache linearmente. Então, é seguro dizer que NCache é a melhor camada de cache que sua arquitetura de aplicativo precisa.
NCache Adicionar ao carrinho Baixar NCache Comparação de edições




