Escalar aplicativos .NET no Microsoft Azure com cache distribuído
Webinar gravado
Por Ron Hussain
Saiba quais são os gargalos de escalabilidade para seus aplicativos .NET no Microsoft Azure e como você pode melhorar sua escalabilidade com cache distribuído.
Este webinar cobre:
- Visão geral rápida dos gargalos de desempenho em aplicativos .NET
- O que é cache distribuído e por que é a resposta no Azure?
- Onde em seu aplicativo você pode usar o cache distribuído?
- Quais são alguns recursos importantes em um cache distribuído?
- Alguns exemplos práticos de como usar um cache distribuído no Azure
Muito obrigado por participar. Deixe-me educá-lo rapidamente sobre o webinar. Em primeiro lugar, meu nome é Ron Hussain. Sou um dos especialistas técnicos da Alachisoft e serei seu apresentador para o webinar de hoje. Abordarei todos os detalhes técnicos necessários para dimensionar seus aplicativos .NET no Microsoft Azure com a ajuda de um sistema de cache distribuído na memória e usarei NCache como um produto de exemplo para isso. Esse é o nosso principal produto para cache distribuído. Nós somos o fabricante orgulhoso de NCache e usarei isso como um produto de exemplo. Mais deste webinar será apenas para ouvir, o que significa que falarei mais, mas você sempre pode participar. Você pode fazer quantas perguntas precisar. No lado direito da tela, há essa guia de perguntas e respostas. Se você expandir a guia de perguntas, poderá postar quantas perguntas precisar e, como eu disse, ficarei de olho nisso e responderei a todas as perguntas que vocês postarem nesta janela. Então, apenas para confirmação, se você puder confirmar usando a mesma guia de perguntas e respostas, confirme se você pode ver minha tela e se você pode me ouvir bem. Posso começar rapidamente. OK. Já posso ver algumas perguntas sendo postadas. Então, muito obrigado pela confirmação.
Vamos começar com isso. Olá a todos, meu nome é Ron Hussain como eu disse, sou um dos especialistas técnicos da Alachisoft e serei seu apresentador para o webinar de hoje. O tópico que escolhemos hoje é dimensionar aplicativos .NET no Microsoft Azure com a ajuda de um sistema de cache distribuído na memória. No Alachisoft temos vários produtos e o mais popular é NCache, que é um sistema de cache distribuído na memória para aplicativos .NET e Java. NCache será o produto principal, que usarei como exemplo, mas vou me ater ao básico do Microsoft Azure. Como usar NCache (Um Sistema de Cache Distribuído) no Microsoft Azure e aproveite-o em termos de escalabilidade, em termos de desempenho de aplicativos e confiabilidade geral do sistema em sua arquitetura. Então, já que você confirmou que pode ver minha tela, deixe-me começar com isso.
O que é escalabilidade?
Ok! antes de realmente passar para o tópico real. Vou falar sobre alguns conceitos básicos e vou começar com o que é escalabilidade? A escalabilidade é a capacidade de aumentar a carga transacional nos aplicativos e, ao mesmo tempo, você não diminui a velocidade de seus aplicativos. Por exemplo, neste ponto, se você estiver lidando com 1,000 solicitações, se a carga do aplicativo aumentar, mais usuários efetuarão login e começarão a usar seus aplicativos com mais intensidade do que a carga, por exemplo, aumentará de 1,000 para 10,000 solicitações por segundo. Agora você quer acomodar essa carga aumentada, quer lidar com essa carga aumentada e, ao mesmo tempo, não quer diminuir o desempenho de sua solicitação individual. Não deve acontecer de tal forma que um pedido esteja esperando para ser concluído e um pedido esteja em processo de conclusão, outros pedidos estão esperando por isso. Essas solicitações devem ser tratadas exatamente na mesma quantidade de tempo que estavam levando anteriormente. Mas, ao mesmo tempo, você quer essa escalabilidade, essa capacidade de lidar com mais e mais solicitações, carregar 10,000 solicitações por segundo ou 20,000 solicitações por segundo. Portanto, sem perder o desempenho, se você tiver a capacidade de aumentar sua carga transacional em seus aplicativos, isso é o que chamaríamos de Escalabilidade. E é nisso que vamos focar hoje.
O que é escalabilidade linear?
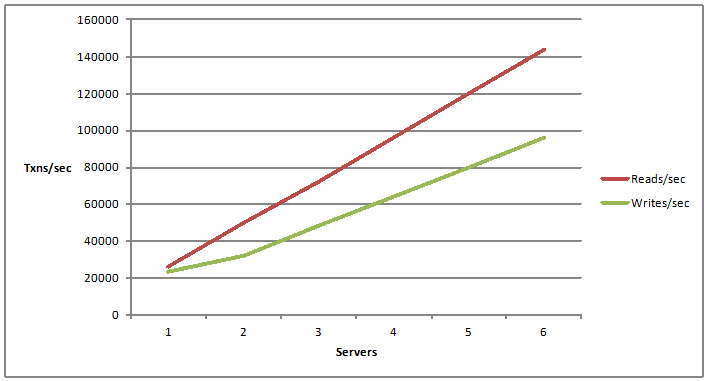
Há um termo associado chamado escalabilidade ilimitada. É escalabilidade linear. A escalabilidade linear está tendo um crescimento linear em sua capacidade de leituras e gravações por segundo. Por exemplo, se você adicionar mais servidores. Portanto, agora que você adiciona um servidor, tem uma certa capacidade de lidar com solicitações de operações de leitura e gravação. E se você adicionar outro servidor e depois adicionar mais servidores? A capacidade em que você pode adicionar mais servidores e, adicionando mais servidores, aumenta seus números de escalabilidade, obtém mais e mais alças de capacidade por sua arquitetura de aplicativo, é o que chamamos de escalabilidade linear.
Quais aplicativos precisam de escalabilidade?
Agora! A próxima pergunta seria: que tipo de aplicativos precisariam de escalabilidade. A resposta é muito simples. Qualquer aplicativo que possa ter que lidar com milhões de solicitações dos usuários. Se estiver lidando com uma grande carga de transações. Normalmente, temos aplicativos ASP.NET. Se houver front-end, por exemplo, um aplicativo de comércio eletrônico, talvez um aplicativo de reserva de companhias aéreas, qualquer coisa voltada para o público, mas com muito tráfego, esse aplicativo é o principal candidato à escalabilidade.
Então, poderíamos ter WCF para serviços da Web .NET e arquitetura orientada a serviços. Pode estar de volta ou pode ser serviços da Web de front-end, talvez consumidos por seus aplicativos da Web ou por aplicativos internos que você possa ter. Esses podem ter que processar uma enorme quantidade de solicitações, uma enorme quantidade de dados precisa ser buscada e entregue aos programas chamadores. Portanto, esses tipos de aplicativos também precisam de escalabilidade. E então você pode querer colocar algum tipo de infraestrutura, que possa lidar com a quantidade de carga de solicitação.
Então, temos aplicativos de big data. Este é um chavão comum nos dias de hoje. Muitos aplicativos, muitas arquiteturas estão se movendo em direção a isso, onde você pode ter que processar grandes quantidades de dados para distribuição em diferentes módulos, diferentes processos, mas no final, você estaria lidando com muitos dados, muitos solicitações, a fim de processar isso.
E então temos ótimos aplicativos de computação, onde você pode ter que processar uma enorme quantidade de cálculos através da distribuição em vários servidores baratos, esses são os aplicativos. Assim, em geral, qualquer aplicativo .NET ou aplicativo Java para esse assunto, que pode ter que lidar com um milhão de solicitações dos usuários ou dos programas de back-end, são os principais candidatos que precisam ter escalabilidade na arquitetura.
E, vamos nos concentrar em alguns deles uma vez, passamos para nossos casos de uso também. E, pessoal, estamos apenas no início deste webinar, para aqueles que acabaram de entrar, vou abordar alguns conceitos básicos em termos de cache distribuído. Vou falar sobre diferentes problemas que você enfrentaria e depois sobre soluções e também falarei sobre a implantação de um cache distribuído, como NCache no Microsoft Azure. Portanto, se houver alguma dúvida, sinta-se à vontade para digitar na guia de perguntas e respostas. E você sempre pode me dar seu feedback também. Se você quiser participar, pode usar novamente a mesma guia de perguntas e respostas.
Qual é o problema de escalabilidade?
Agora a próxima coisa, uma vez que definimos que temos, o que é escalabilidade? O que é escalabilidade linear e que tipo de aplicativos precisam de escalabilidade? O próximo e mais importante ponto deste webinar, que tipo de aplicativos ou que tipo de problemas de escalabilidade seus aplicativos enfrentariam? Onde exatamente está o problema de escalabilidade?
Agora, sua arquitetura de aplicativo, pode ser um aplicativo ASP.NET ou um serviço WCF, eles se expandem muito bem e já são lineares. Você pode colocar um balanceador de carga na frente e pode simplesmente adicionar mais e mais servidores de aplicativos ou servidores da Web, servidores de front-end da Web e já obtém escalabilidade linear de sua arquitetura. Então não tem problema aí. O problema real em relação ao armazenamento de dados, esses servidores de aplicativos ou servidores da Web, eles sempre conversam com algumas fontes de dados de back-end, como serviço de estado de bancos de dados ou pode ser qualquer sistema de arquivos de back-end ou fonte de dados herdada para esse assunto . Que não pode lidar com uma grande carga de transação e você não tem a capacidade de adicionar mais e mais servidores aqui. E este diagrama explica bem isso.
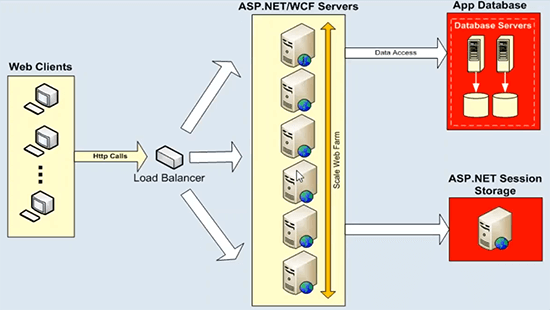
Onde temos armazenamento de dados tem um gargalo de escalabilidade. Temos o exemplo ASP.NET WCF aqui, mas você pode adicionar quantos servidores quiser, você começa com dois servidores, se sua carga aumentar, você pode adicionar outro servidor, colocar um balanceador de carga na frente e usar uniformemente todos os recursos nesta camada. Portanto, não há problemas. Mas essas caixas de aplicativos ou servidores front-end da Web sempre conversariam com algumas fontes de dados de back-end. E esta é uma implantação típica, onde temos servidores de banco de dados, que não são tão rápidos para começar, e então eles têm problemas de escalabilidade. Eles sufocariam sob uma enorme carga de transações e, em alguns casos, também seriam um único ponto de falha. Mas o mais importante é que esses servidores de banco de dados em qualquer arquitetura de aplicativo representam uma ameaça muito séria e isso é um gargalo de escalabilidade. Portanto, você perderia toda a escalabilidade alcançada nessa camada quando direcionar todas as suas solicitações de volta para alguns servidores de banco de dados. E o mesmo é o caso do estado da sessão ASP.NET. Se você usa um SQL Server ou servidor de estado de sessão para isso é porque ele fica acima disso. Sempre será um único servidor hospedando todos os seus dados de sessão e a sessão é um tipo de dados muito transacional e você precisa de uma fonte de dados muito escalável para lidar com essas solicitações. Então, esse é o principal desafio que estamos tentando resolver com a ajuda de um sistema de cache distribuído.
A solução: cache distribuído na memória
A solução é muito simples, como eu disse, você pode usar um sistema de cache distribuído na memória escalável. Tal como NCache para lidar com todos os problemas sobre os quais acabamos de falar associados a fontes de dados em relação à escalabilidade.
A próxima coisa que farei rapidamente é falar sobre alguns conceitos básicos do sistema de cache distribuído na memória, como NCache. Existem algumas características importantes, que você encontraria em NCache e espero que isso faça parte da maioria dos nossos sistemas de cache distribuído na memória, que estão disponíveis. Então, nesse sentido, então NCache se eu tiver que definir, o que seria um sistema de cache na memória?
Clustering dinâmico
É um cluster de vários servidores de cache baratos, que são unidos, você pode puxar sua memória, bem como a capacidade da CPU. Então, eles são unidos em uma capacidade e você está puxando a memória deles, bem como os recursos da CPU. Então, fisicamente, poderia ser vários servidores, que não são tão caros, uma vez que uma caixa de configuração de servidor web simples faria, isso é algo que você poderia usar para armazenamento em cache e, em seguida, esses servidores se juntam e capacidade lógica formal. Então, do ponto de vista do seu aplicativo, você está usando apenas um cache distribuído, mas fisicamente, ele pode ter vários servidores trabalhando nos bastidores, puxando todo o poder computacional e memória para criar esse cache distribuído na memória. Então, essa é a primeira e mais importante característica que não é este único servidor. Teria vários servidores trabalhando em combinação uns com os outros. Então, já estamos à frente do banco de dados, onde teríamos apenas um servidor hospedando todos os dados e cuidando de todas as requisições.
A consistência dos dados
A próxima característica e isso é em relação à consistência dos dados, já que estamos lidando com vários servidores nos bastidores, a próxima pergunta seria: como lidaríamos com as atualizações. Por exemplo, os mesmos dados são atualizados em um ou dois servidores ou se houver réplicas ou várias cópias de dados em servidores diferentes. Portanto, independentemente da topologia usada, os dados devem ser atualizados de maneira consistente. Assim, depois de atualizar qualquer coisa em qualquer servidor de cache, todas as atualizações devem ser visíveis para todos os servidores de cache no cache distribuído. E a propósito, estou usando alguns visíveis, não estou usando o termo replicação. A replicação é outro recurso. Então, por visível quero dizer que, por exemplo, você obtém um identificador de solicitação pelo servidor um, que os dados são atualizados. Se a próxima solicitação for para o servidor dois, se você também tiver os mesmos dados no servidor dois, deverá obter o valor atualizado e não o valor antigo do cache distribuído.
Portanto, esta é uma característica muito importante em termos de cache distribuído, onde todas as suas atualizações de dados devem ser aplicadas de forma consistente em todos os servidores de cache. E isso deve ser responsabilidade do cache distribuído, não do seu aplicativo. A arquitetura deve suportar este modelo.
Escalabilidade Linear
A próxima coisa, que se alinha com nosso tópico hoje, é como dimensionar linearmente. Portanto, o cache distribuído deve ser dimensionado linearmente para capacidade transacional e de memória. Ele deve te entregar, onde você pode adicionar mais e mais servidores de cache e, como você tinha mais servidores de cache, você alcança escalabilidade linear. Eu tinha mostrado um gráfico antes. Então, é isso que estou me referindo aqui, onde você adiciona mais e mais servidores, você deve aumentar a capacidade de quantos solicitantes você pode manipular e, ao mesmo tempo, quantos dados, quantos dados podem ser armazenados no cache distribuído linearmente. Portanto, essa é uma característica muito importante, que oferece escalabilidade linear fora do cache distribuído e torna a arquitetura geral do aplicativo muito escalável.
Replicação de dados para confiabilidade
Quarta característica importante. Esta é a primeira opção, você pode escolher uma topologia, que também suporta replicação. Você tem um cache distribuído, que replica dados entre servidores para confiabilidade. Se algum servidor ficar inativo ou você precisar colocá-lo offline para manutenção, você não deve se preocupar com a perda de dados ou o aplicativo inativo. Então, essas são algumas características importantes do cache distribuído. Abordarei isso cada vez mais detalhadamente nos próximos slides e, em seguida, também falaremos sobre a implantação específica do Azure de um cache distribuído. Como usar o cache distribuído no Microsoft Azure? Por favor, deixe-me saber se há alguma dúvida até agora. Por favor, use o assunto da aba de perguntas e respostas. Eu vejo algumas mãos levantadas em geral, o go-to-meeting tem esse problema, onde mostra muitas mãos levantadas, mas por favor me avise se houver alguma dúvida. Digite na guia de perguntas e respostas e terei muito prazer em respondê-las. Acho que devemos continuar.
Aqui está a implantação típica de um cache distribuído. Esta é uma implantação geral, não é específica do Microsoft Azure.
NCache Implantação no Microsoft Azure
Vou passar para a implantação de NCache no Microsoft Azure logo depois disso. Então, normalmente pode ser on-premise ou pode ser na nuvem, não são muitas coisas que vão mudar na medida em que a implantação de NCache vai. É assim que você normalmente implantaria NCache, onde você teria uma camada dedicada de cache.
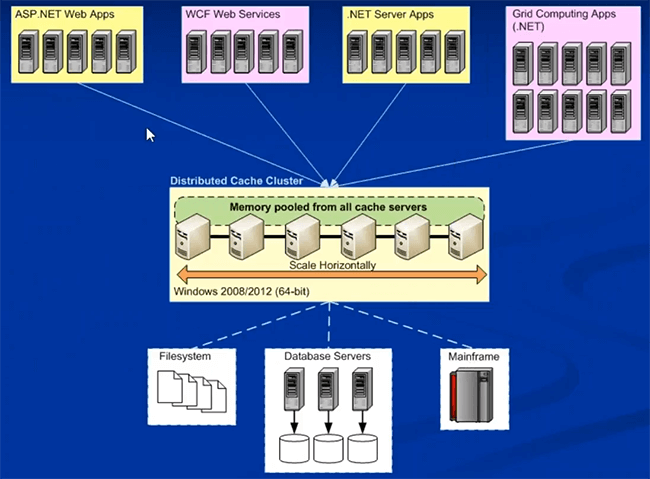
Podem ser caixas físicas no local, podem ser VMs de caixas hospedadas ou também podem ser VMs de nuvem reais, onde você apenas obtém uma VM da nuvem e depois a usa para armazenamento em cache. Você pode formular um cache em caixas de cache dedicadas separadas, que é recomendada. Uma plataforma preferencial é de 64 bits e o único pré-requisito para NCache é .NET 4.0. E então seus aplicativos, eles também podem ser locais ou hospedados. Eles podem ser implantados diretamente nos servidores no IIS ou podem ser funções da Web ou de trabalho, em relação ao Microsoft Azure. Todos eles podem se conectar a essa camada de cache para os requisitos de dados. Você pode ter uma instalação separada para estes, uma camada separada para estes, ou você terá tudo na mesma camada também. Ambos os modelos são suportados. Mas uma vez que você apresenta NCache em sua arquitetura de aplicativo, uma vez implantado para cache de objeto ou para cache de sessão, abordarei NCache casos de uso quando passamos para casos de uso.
Depois de começar a usar NCache, economiza suas viagens caras pelas costas e bancos de dados. E, em seguida, oferece uma plataforma muito escalável aqui, onde você pode adicionar quantos servidores quiser e aumentar a escala. Agora compare isso com o diagrama que mostrei anteriormente.
Você tinha uma plataforma muito escalável aqui, mas essa era a principal fonte de discórdia. A principal fonte de gargalo de escalabilidade. Agora, se você comparar isso, agora você tem uma plataforma muito escalável entre sua camada de aplicativo e banco de dados. Esta é uma plataforma muito escalável e, novamente, agora você tem uma fonte de dados em termos de cache distribuído, que também é muito escalável. Você pode adicionar quantos servidores desejar. Se sua carga aumentar, você não precisará se preocupar com as fontes de dados de back-end sendo bloqueadas nesse momento. Você pode adicionar quantos servidores quiser e pode aumentar linearmente sua capacidade de tratamento de solicitações de NCache. Deixe-me saber se houver alguma dúvida sobre a arquitetura de implantação do NCache mas no geral é bem simples.
Agora, a próxima coisa é como implantar NCache no Microsoft Azure. Então, que eu estarei usando nosso site. Vou usar um diagrama de lá, então, por favor, tenha paciência comigo. A implantação no Microsoft Azure não é tão diferente do que temos no local.
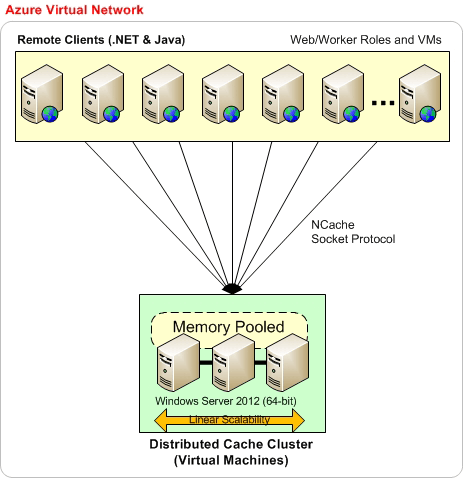
Então, antes de tudo, é recomendado que essa seja a implantação básica, onde você tem tudo na mesma rede virtual do Microsoft Azure. Por exemplo, você cria uma rede virtual e, em seguida, tem máquinas virtuais do Microsoft Azure, a implantação do lado do servidor sempre será em VMs. Então, esse é o modelo que escolhemos para NCache no Microsoft Azure. Você cria uma VM ou, ao escolher a mesma rede virtual, cria todas as suas implantações de VM. Por exemplo, você pode começar com três VMS conforme mostrado aqui e, em seguida, pode adicionar quantas VMs a essa camada de cache forem necessárias. De preferência, também queremos que seus aplicativos estejam na mesma rede virtual do Azure. Então, tudo pode fazer parte da mesma rede virtual que é quando você obtém a maior parte do desempenho e, em seguida, os benefícios de estabilidade de NCache. Quando não há requisitos rígidos sobre isso, você sempre pode ter aplicativos implantados em diferentes VMs.
Portanto, com base nesse modelo, sua arquitetura de aplicativo pode estar na própria VM, o que significa que seu aplicativo pode ser implantado diretamente no IIS, que você gerencia e, em seguida, assume o controle total ou pode ser eu mesmo a função Web do Azure ou as funções de trabalho. modelos são suportados no lado do aplicativo, mas NCache a implantação do lado do servidor sempre estará nas VMs. Então, é assim que você aplicaria NCache e eu vou te mostrar assim que passarmos para nossa parte prática.
Outro tipo de implantação é que você pode ter uma rede virtual específica do Azure para seu NCache VMs de servidor, onde todos os seus servidores fazem parte da mesma rede virtual. De preferência a mesma sub-rede também. E então seus aplicativos também podem estar em uma rede virtual separada. Nesse caso, você teria que ter algum tipo de portas encaminhadas no NCache rede virtual. Por exemplo, as portas privadas são mapeadas para a porta pública aqui e, em seguida, seus aplicativos usam essa porta pública para realmente se conectarem NCache. Você pode ter que realizar algumas configurações extras aqui, mas temos um documento de ajuda detalhado disponível para isso, mas funciona sem problemas. Você pode ter esse servidor de rede virtual acessando servidores de cache de outra rede virtual. E você pode até ter os aplicativos cache-a-cache com a ajuda do mesmo recurso.
Portanto, esse é outro tipo de implantação, mas a abordagem preferencial, a recomendada, é que você tenha todos os seus servidores de cache, bem como servidores de aplicativos implantados na mesma rede virtual do Microsoft Azure. É quando você obteria o máximo de benefícios de NCache. Por favor, deixe-me saber se houver alguma dúvida.
Também temos um guia de implantação do Azure disponível em nosso site, se eu puder levá-lo ao suporte. Na verdade, deixe-me ir para a documentação aqui. Na documentação, temos um guia específico, um guia de implantação que aborda todos esses detalhes em detalhes.
OK. Há uma pergunta. Como é NCache diferente Redis? OK. A agenda de hoje é mais de usar NCache ou usando um sistema de cache distribuído no Microsoft Azure. Temos um webinar separado sobre Redis contra NCache. Onde falamos sobre os diferentes recursos que estão disponíveis em NCache e depois não faz parte Redis. Para uma resposta rápida sobre isso, eu recomendo que você vá para nossa página de comparações aqui, e então você tem um Redis contra NCache. Você pode se inscrever rapidamente para isso e, em seguida, poderá ver todos os recursos, comparação de recurso por recurso NCache contra Redis. Aliás, também temos um webinar só para isso, que é um webinar no nosso canal do YouTube. Então, se você acabou de entrar no YouTube, procure Alachisoft e depois sob Alachisoft haverá muitos vídeos e um desses vídeos teria Redis fontes NCache título. Há um webinar separado sobre isso. Espero que isso responda sua pergunta. Há mais perguntas sobre isso. OK. voltando, já que cobrimos a implantação, informe-me se houver alguma dúvida relacionada à implantação e ficarei muito feliz em responder a essas perguntas para você.
Usos comuns do cache distribuído
A próxima coisa é como usar o cache distribuído? Quais são as áreas comuns, onde você usaria um sistema de cache distribuído como NCache? Acabei de listar três dos mais comuns, mas podem ser específicos para o setor, podem ser específicos para seus requisitos, casos de uso, podem ser diferentes maneiras de usar NCache. Mas principalmente estes são divididos nessas três categorias.
Cache de dados do aplicativo
A primeira categoria é o cache de dados do aplicativo. Você pode usar um sistema de cache distribuído como NCache como um cache de dados do aplicativo. Qualquer coisa que anteriormente estava presente no banco de dados e seus aplicativos estavam indo para os bancos de dados, agora você pode colocar isso em NCache. E você pode obter um cache na memória mais rápido em comparação com o banco de dados para acessar todos os dados que você tinha anteriormente no banco de dados. Assim, você melhora o desempenho do seu aplicativo e, o mais importante, dimensiona linearmente onde o banco de dados não consegue fazê-lo. Você pode escalar para alguns níveis dramáticos. Você pode lidar com uma enorme quantidade de cargas de transações e pode adicionar quantos servidores desejar. E isso envolve NCache API. Você pode simplesmente adicionar dados em um par de valores-chave. A chave é uma string e o valor é um objeto permitido .NET, você pode armazenar em cache seus objetos de domínio, coleções, conjuntos de dados, imagens, qualquer tipo de dado relacionado a aplicativos pode ser armazenado em cache usando nosso modelo de cache de objetos. E então isso lhe daria alguns benefícios enormes em termos de recursos, que estamos oferecendo no lado do cache de dados.
Cache confiável e escalável para dados específicos do ASP.NET
O próximo caso de uso é em torno de aplicativos específicos do ASP.NET. Por exemplo, ASP.NET e há uma maneira muito fácil de começar com NCache. Temos três opções aqui.
Armazenamento de sessão ASP.NET
Temos armazenamento de estado de sessão ASP.NET. Você pode usá-lo em formulários da Web MVC ou ASP.NET ou qualquer aplicativo da Web ASP.NET pode fazer uso disso. Sem nenhuma alteração de código, você pode ter seus dados de sessão armazenados em um cache distribuído. E ao contrário do banco de dados ou servidor de estado, não será um único servidor. Poderia ter vários servidores. Portanto, é muito escalável, muito confiável porque temos dados de sessão replicados em servidores e você obtém um desempenho muito bom também porque está na memória. E tudo sem qualquer alteração de código. E com NCache, também temos uma implantação de sessão em vários sites. Você pode ter dois data centers, sincronizar suas sessões sem nenhuma alteração de código. Então, esses são alguns recursos estendidos que você pode usar. Fora do nosso suporte de estado de sessão para aplicativos ASP.NET e isso não requer nenhuma alteração de código.
ASP.NET View State Cache
O próximo recurso sobre isso é ASP.NET view state, também não há opção de alteração de código. Para aqueles de vocês que querem saber, qual é o estado de visualização? O estado de exibição é o gerenciamento de estado do lado do cliente. Por exemplo, se os estados de visualização forem aplicados apenas em formulários da Web, a arquitetura MVC não terá mais seu estado. Para webforms ASP.NET, todos os controles, todos os botões ou todos os widgets que você tem em suas páginas, contribuem para a criação do estado de exibição, que é enviado de volta ao navegador em relação à nossa resposta, o estado de exibição é unido para o pacote de resposta e, em seguida, enviado de volta ao navegador. No lado do navegador, nunca é realmente usado. Ele só fica lá e quando você posta de volta o estado de visualização vem junto com o pacote de solicitação no servidor e é aí que você realmente usa o estado de visualização. Assim, ele sempre é enviado de volta ao navegador como parte da resposta, trazido de volta ao servidor como parte da solicitação, portanto, seus pacotes de solicitação e resposta ficam mais pesados. Nunca é realmente usado no lado do navegador. É sempre usado no lado do servidor. Ele consome muito da sua largura de banda especificamente sob uma enorme carga de transação.
Portanto, temos muitos problemas associados a ele em termos de desempenho e utilização de largura de banda. Com NCache você pode armazenar seus estados de visualização no lado do servidor, você pode mantê-lo no lado do servidor em NCache, envie um pequeno token fictício de volta ao navegador. Assim, seus estados de visualização ficam menores em tamanho, melhoram seus custos de utilização de largura de banda. Você economiza muita largura de banda nisso. E, ao mesmo tempo, pacotes menores são mais fáceis de processar. Sua solicitação e resposta o pacote fica menor e isso também contribui para melhorar o desempenho de sua aplicação. Assim, você obtém desempenho e redução no custo de utilização de largura de banda, assim que começar a usar nosso ASP.NET view state fornecedor. E esta também é uma opção sem alteração de código para NCache. E você pode usá-lo muito facilmente no Microsoft Azure.
Cache de saída ASP.NET
O terceiro recurso importante aqui é o provedor de cache de saída ASP.NET, para ASP.NET MVC, bem como para web farms. Se você tiver conteúdo bastante estático em seu aplicativo em quatro páginas diferentes para solicitações diferentes, em vez de rerenderizar e executar novamente todas essas solicitações, mesmo que você obtenha os mesmos dados em resposta a essas solicitações, faz sentido armazená-los em cache e em seguida, use a saída em cache para solicitações subsequentes. Se você receber a mesma solicitação novamente, não faça o drill e simplesmente retire o conteúdo do cache do NCache diretamente. Assim, permitimos que você armazene saídas de página ASP.NET inteiras em NCache e para ser usado para solicitações subsequentes. E isso também não é uma mudança de código porque economiza muito poder de processamento, muito tempo de execução, muitos benefícios de desempenho são alcançados com a ajuda de nosso provedor de cache de saída ASP.NET.
Portanto, esses são três aspectos importantes com os quais você pode começar rapidamente. Estas são todas as opções sem alteração de código. Pode levar de 10 a 15 minutos para configurar e, em seguida, você poderá começar a ver todos os benefícios que acabamos de discutir. E no Microsoft Azure, não há substituto para eles. Você acabaria usando as opções padrão, o que significa que você mantém tudo no processador neste banco de dados. E já falamos sobre quais são os problemas associados a eles. Portanto, eu recomendo que você dê uma olhada nesses recursos para começar e, depois que seu caso de uso progredir, você poderá começar a usar o cache de dados do aplicativo ao lado. O terceiro caso de uso importante de NCache, estou gastando muito tempo com isso para poder transmitir a importância de usar um cache distribuído em suas arquiteturas de aplicativos. Por favor, deixe-me saber se há alguma dúvida até agora.
Compartilhamento de dados em tempo de execução escalável por meio de mensagens
Agora terceiro caso de uso importante de NCache é que você pode usá-lo de maneira escalável e muito confiável, de maneira escalável para plataforma de compartilhamento de dados em tempo de execução com a ajuda de nosso suporte de mensagens. Semelhante à fila do MSN e ao serviço de mensagens Java. Também temos uma plataforma de mensagens. Desde que você já tenha dados no cache. Por exemplo, alguns dados são adicionados, você tem alguns catálogos de produtos, um produto é adicionado, atualizado ou removido do cache, você deseja ser notificado com base no nosso sistema de propagação de notificação de eventos, que pode propagar e notificar use se os dados forem alterados no cache. Portanto, existem mensagens de nível de dados, às quais você pode se conectar e começar a usar essas mensagens conforme necessário, e também pode haver algumas mensagens de aplicativos personalizados, onde um aplicativo pode conversar com outros aplicativos com a ajuda de nossa plataforma de mensagens. Portanto, é um compartilhamento de dados muito poderoso porque um aplicativo pode compartilhar dados com outro e também pode ser o compartilhamento de mensagens entre diferentes aplicativos usando o mesmo sistema de cache distribuído. Então, esse é um recurso muito poderoso, muitas pessoas não o conhecem, mas é muito poderoso em termos de capacidade que ele oferece.
Por favor, deixe-me saber se há alguma dúvida. Estes são alguns casos de uso importantes de NCache, que abordarei rapidamente. Uma vez que você planeja usar um cache distribuído no Microsoft Azure, há um conceito muito importante, muito importante a cena a fazer, eu diria.
Quais dados armazenar em cache?
Que tipo de dados que precisam ser armazenados em cache? Agora, o cache distribuído é geralmente para os dados mais facilmente acessados, onde você tem mais leituras e gravações e, em seguida, esses dados são lidos repetidamente para solicitações subsequentes. Eu categorizei os dados em duas categorias diferentes. Você poderia ter dados permanentes, que geralmente existem no banco de dados, eles podem mudar, mas a frequência de mudança não é tão grande, por isso eu os dividi em dados de referência e transacionais. Mas temos dados permanentes e depois temos dados transitórios. Os dados permanentes são aqueles que realmente existem no banco de dados e é muito importante que você os armazene em cache. Assim, você reduz suas viagens caras aos bancos de dados de back-end.
E então, temos dados transitórios que são dados temporários, que são de comprimento curto, podem ser válidos apenas para o escopo do usuário atual ou apenas para o escopo do ciclo de aplicação atual. Podem ser configurações do usuário, podem ser configurações do usuário, podem ser sessões ASP.NET do usuário, exibir o cache de saída do estado. Geralmente não pertence ao banco de dados, mas faz sentido mantê-lo no cache dependendo de quanto tempo você precisa dele e quantas vezes você precisa dele depois de armazená-lo em cache. Em seguida, esses dados podem ser divididos em outras categorias. Por exemplo, onde os dados são principalmente lidos, mais leituras do que gravações ou um número igual de leituras ou gravações. Portanto, a referência é mais leituras do que gravações e transações são leituras e gravações.
E então, temos dados transitórios que são dados temporários, que são de comprimento curto, podem ser válidos apenas para o escopo do usuário atual ou apenas para o escopo do ciclo de aplicação atual. Podem ser configurações do usuário, podem ser configurações do usuário, podem ser sessões ASP.NET do usuário, exibir o cache de saída do estado. Geralmente não pertence ao banco de dados, mas faz sentido mantê-lo no cache dependendo de quanto tempo você precisa dele e quantas vezes você precisa dele depois de armazená-lo em cache. Em seguida, esses dados podem ser divididos em outras categorias. Por exemplo, onde os dados são principalmente lidos, mais leituras do que gravações ou um número igual de leituras ou gravações. Portanto, a referência é mais leituras do que gravações e transações são leituras e gravações. Portanto, você pode considerar armazenar em cache todos os seus dados de referência, geralmente são seus dados permanentes que pertencem ao banco de dados. Tente trazê-lo para o cache distribuído e armazenar em cache o máximo que puder, para não voltar aos bancos de dados. E você obtém a maioria dos benefícios de desempenho necessários com isso. E então, você deve considerar o cache de alguns de seus dados de transação, como estado de sessão ASP.NET, estado de exibição e cache de saída, porque você não deseja perder desempenho ao obter esses dados transitórios ou dados transacionais das fontes de dados de back-end . Dependendo do número de usuários, se você tiver milhões de usuários logados, pense em um cenário em que você acessa o banco de dados duas vezes por usuário, você pode ver quanto tempo gastaria para obter esses dados de uma fonte mais lenta , da fonte de dados de back-end. Obtendo do cache e para isso você deve definitivamente considerar armazená-lo no cache distribuído.
Visão geral da API de cache
É assim que o cache se parece. É uma tabela de hash como Interface. Temos uma chave baseada em string e então temos um objeto como seu valor. O objeto pode ser qualquer objeto de parâmetro .NET. Você pode ter qualquer coisa que seja permitida pelo .NET, armazenada como cache de objeto. Considerando que a chave de string, você pode criar uma formação de chave significativa. Por exemplo, todos os funcionários com ID de funcionário 1000, um funcionário com ID de funcionário 1000 pode ser armazenado com essa chave aqui. Todos os pedidos desse funcionário podem ter essa chave, onde você tem os pedidos do funcionário e depois o ID desse funcionário. Pode haver um parâmetro de tempo de execução também. E então, você pode ter uma consulta de funcionário. Por exemplo, você armazena em cache a consulta responsável e o argumento foi encontrar os funcionários do código com base em um título igual a gerente. Assim, você pode obter uma coleção armazenada como um único objeto no cache. Portanto, este é apenas um exemplo de como a chave de cache pode ser formulada, mas você pode criar qualquer técnica de base de chave conforme necessário. É apenas um exemplo, use o que fizer mais sentido para sua aplicação.
Pessoal, por favor, deixe-me saber se há alguma dúvida? Não estou vendo muitas perguntas hoje. Por favor, deixe-me saber se há alguma dúvida até agora. Além disso, deixe-me saber se estou indo muito devagar ou muito rápido em uma parte específica, para que eu possa manter um ritmo. Você também pode me dar seu feedback usando a mesma guia de resposta de pergunta e eu gastarei mais tempo em um recurso específico.
Pessoal, por favor, deixe-me saber se há alguma dúvida? Não estou vendo muitas perguntas hoje. Por favor, deixe-me saber se há alguma dúvida até agora. Além disso, deixe-me saber se estou indo muito devagar ou muito rápido em uma parte específica, para que eu possa manter um ritmo. Você também pode me dar seu feedback usando a mesma guia de resposta de pergunta e eu gastarei mais tempo em um recurso específico. OK. Há uma pergunta, e os dados espaciais? OK. Podemos consultar esse tipo de dados também? Sim. Absolutamente, temos um suporte de consulta muito forte, esse objeto pode ser de qualquer tipo. Então, deixe-me dizer que isso abrange todos os tipos de dados que você planeja armazenar em cache. Agora, esses dados podem ser consultados com base em diferentes argumentos, com base em diferentes parâmetros que você passa. Na verdade, temos uma linguagem de consulta de objetos muito forte, que planejei aqui. Assim, temos consultas paralelas com a ajuda da linguagem de consulta de objetos. E você pode executar consultas muito flexíveis com a ajuda de nossa linguagem de consulta de objetos. Por exemplo, há uma pergunta sua. Se quisermos obter todos os locais próximos à localização atual, por exemplo, sim. você pode. Por exemplo, você tem todos os dados propagados no cache. Você tem todos os menus, armazenados no cache separadamente como objetos separados. Direita? E então você pode ter seus atributos de objeto, que também podem fornecer informações de localização. Então, você pode executar uma consulta que diz selecionar todos os locais, onde local é esse local igual a isso. Portanto, se os atributos do objeto tiverem essas informações, você poderá obter todos os registros correspondentes do cache de distribuição. É por isso que uma maneira de fazê-lo.
A segunda maneira de fazer isso é passar as informações espaciais ou todas as informações que você precisa consultar como parte desses objetos na forma de tags. Você armazena seus objetos e depois armazena palavras-chave adicionais, que estão aqui como tags. São identificadores que identificam, que fazem coletas lógicas no cache. Então, você pode usar a API baseada em tags, onde você diz obter por tag e, em seguida, obtém toda a coleção que corresponde aos resultados ou pode até executar uma consulta em que diz selecionar locais onde a tag é igual a e a tag é essencialmente um local que você já adicionou, onde tag é igual a um local XYZ e você obteria todos os registros correspondentes com base nesse critério. Então, essas são as duas maneiras pelas quais você pode lidar com consultas, onde você pode adicionar tags em cima de seus objetos ou apenas confiar nos atributos reais do objeto. E, em seguida, execute SQL como consultas de pesquisa neles. Espero que responda suas perguntas. Por favor, deixe-me saber se há mais perguntas sobre isso.
Há outra pergunta. Posso definir a expiração de determinados itens em cache com base em eventos? Por exemplo, um registro é cache e expira se for atualizado no banco de dados. Absolutamente! temos dois tipos de expirações. Temos, tempo é expiração e existem dois tipos de expiração, então se o tempo passar você pode expirar itens e essa expiração também pode ser baseada na dependência do banco de dados. Por exemplo, algo muda no banco de dados e isso responderia à sua pergunta. Por exemplo, um registro muda no banco de dados que você tinha um registro no cache, que era dependente disso, assim que esse registro do banco de dados muda, o banco de dados pode enviar uma notificação de evento e o item no cache pode ser removido automaticamente da frente de o cache. Portanto, ele pode ser expirado assim que expirar no banco de dados. Então, é exatamente isso que oferecemos em termos de dependências de banco de dados relacional e a dependência SQL cobriria isso. Eu apreciaria se pudéssemos passar rapidamente por outro slide e, em seguida, chegar à nossa parte de cache de objetos e isso deve responder a muitas perguntas. Por favor, deixe-me saber, se houver mais perguntas de outra forma, vou retomar a apresentação do mesmo trecho.
Há uma pergunta. Você pode mostrar um exemplo de persistência e recuperação de dados do cache de exemplo? Eu recomendaria rapidamente que você olhasse para nossas amostras, que vêm e começam com NCache e também estão disponíveis em nosso site. Então, se eu levá-lo rapidamente para nossas amostras, aqui vai e NCache. Eu posso guiá-lo para a amostra, que lida com isso exatamente. Então, temos sincronização de banco de dados e depois temos dependências. Então, esses devem. Identificadores de dependência, dependência SQL e sincronização de banco de dados são outro tipo de amostra, que ajuda a lidar com o cenário com a ajuda de solicitações de leitura e gravação. Espero que isso responda sua pergunta. Muito obrigado.
Há uma outra pergunta. Podemos consultar isso para classificar os dados? Sim. agrupamos por ordem de suporte. Então, você pode usar esses atributos junto com a consulta. Muito bom galera! Muito obrigado por enviar essas perguntas. Eu realmente aprecio estes. Por favor, continuem vindo. Como isso foi planejado para o final de nossa apresentação e eu já ia abordar isso, mas é bom ter todas as perguntas chegando, então, por favor, continuem. Muito obrigado.
NCache Arquitetura
Agora, a próxima coisa, eu irei rapidamente para a arquitetura. O cache distribuído é muito elástico em termos de adição ou remoção de servidores. Você pode adicionar quantos servidores quiser. Você pode colocar qualquer servidor offline. É baseado em cluster de cache baseado em TCP. É nosso próprio implementado um protocolo de perguntas. Não estamos usando nenhum cluster de terceiros ou do Windows. Mesmo no Microsoft Azure, você confiaria apenas em um endereço IP e porta e NCache cuidaria do resto. É uma arquitetura 100% peer-to-peer. Não existe um ponto único de falha, você pode colocar qualquer servidor offline e adicionar novos servidores e clientes não teria nenhum impacto. Você pode aplicar alterações dinamicamente a um cluster de cache em execução. Então essas configurações são dinâmicas de tal forma, que esses servidores estão em constante comunicação com os clientes. Qualquer servidor que caia ou um novo servidor seja adicionado é notificado imediatamente. Há um mapa na memória, que é propagado para o cliente e atualizado sempre que há uma alteração no cache. Portanto, esses mapas de informações de associação de cluster e mapa de informações de topologia de cache são atualizados assim que houver uma alteração no cluster de cache. Portanto, há um suporte a failover de conexão, além disso, se um servidor cair, os clientes automatizariam isso e os servidores fariam esse servidor sair e os nós sobreviventes se tornariam automaticamente disponíveis e os clientes se conectariam automaticamente. Então, em suma, não haveria nenhuma perda de dados ou qualquer tempo de inatividade de aplicativos no que diz respeito aos aplicativos clientes e, em seguida, existem quatro topologias diferentes que você pode escolher.
Topologias de cache
O modo ativo e passivo ou modo mestre ou escravo seria determinado com base nas topologias de cache. Como eu disse, é uma arquitetura peer-to-peer. Assim, cada servidor participa independentemente do cluster de cache. Portanto, não há dependência ou não há conceito de host principal como você tinha em AppFabric ou não há ativo ou passivo ou em termos de configuração ou em termos de gerenciamento de cluster. Cada servidor é 100% independente em termos de configuração, em termos de sua posição no cluster de cache. Mas existem diferentes topologias de cache e temos ativa e passiva, mas essas são baseadas nos dados do cache. Se os dados estão ativamente disponíveis, chamamos de ativos e se os dados são apenas backup, os clientes não estão conectados a eles, chamamos de passivos. Mas esse servidor passivo é novamente adicionado ao cache em arquitetura 100% peer-to-peer.
Há uma pergunta. Existe algum SDK para plataformas móveis, Android ou iOS para usar NCache em aplicativos móveis nativos? No momento, temos .NET e API Java, estamos trabalhando em uma API tranquila, então, se ela for lançada, tenho certeza que você poderá usá-la em aplicativos Android e iOS. Por favor, envie-me um e-mail sobre isso, envie-me uma solicitação sobre isso e eu encaminharei isso para a engenharia e retornarei rapidamente para você com os prazos sobre isso também.
Agora temos quatro topologias de cache diferentes.
Cache espelhado
Temos espelhado, que é ativo/passivo. Vou passar rapidamente por estes porque esta não é a nossa agenda hoje. Eu quero focar mais na nossa parte prática. Então, vou lhe dar um vislumbre de quais topologias diferentes NCache Ofertas. Temos quatro topologias diferentes. Cache espelhado, é um ativo-passivo de dois nós. Você tem todos os clientes conectados ativos e então temos um servidor de backup aqui. Se o ativo for desativado, os backups se tornarão automaticamente ativos. E esses clientes fazem failover automaticamente. Isso é recomendado para configurações menores, muito bom para leituras, muito bom para direita e também é muito confiável.
Cache replicado
Então temos Replicado, é um modelo ativo-ativo. Assim, ambos os servidores estão ativos, mas os clientes são distribuídos. Portanto, se você tiver seis funções da Web ou funções de trabalho no Microsoft Azure, com balanceamento de carga uniforme, algumas se conectarão ao servidor um e outras se conectarão ao servidor dois. E temos um modelo de sincronização aqui.
No espelhado, tínhamos assíncrono, então o desempenho das leituras também era muito rápido. Em replicado sempre temos um modelo de sincronização. Então, temos uma cópia inteira do cache em cada servidor e esses servidores possuem os mesmos dados e de forma sincronizada todas as atualizações são aplicadas em todos os servidores. Por exemplo, você atualiza o item de servidor número dois no servidor um, ele é aplicado no servidor dois de maneira sincronizada somente depois que a operação é concluída. Mas reads, que são aplicados localmente no servidor onde o cliente está conectado. Então, as leituras são muito rápidas muito escaláveis, as gravações são muito consistentes, eu diria porque se você alterar algo aqui você sempre teria essa alteração aqui também só essa operação seria concluída. Portanto, para transações de dados confiáveis para atualizações, para desempenho super rápido, essa é uma topologia muito boa, se você perder o servidor um, esses clientes farão failover para o servidor dois e se você perder o servidor dois, esses clientes farão failover. Portanto, não há perda de dados, nem rejeição de aplicativos.
Cache Particionado
Em seguida, particionamos o cache, onde particionamos os dados e particionamos com a replicação. Então, temos dados particionados, onde você pode ter dois ou mais servidores conforme necessário e os dados são divididos automaticamente em todos os servidores. Alguns dados iriam para o servidor um e alguns dados iriam para o servidor dois. Os mapas de distribuição de moedas já estão cientes, onde existem dados no cache, eles identificariam o servidor e usariam esse servidor para ler e gravar dados. Mais servidores significam mais cópias de leitura do cache, mais gravações, mais servidores para ler dados, mais servidores para gravar dados. Portanto, esses servidores contribuem para o desempenho geral, a escalabilidade geral. Portanto, mais servidores significam mais escalabilidade fora do cache. Partitioned não tem nenhum backup.
Cache de réplica de partição
Temos partições com réplicas, onde você pode fazer backup de cada partição em outro servidor em uma partição de réplica passiva. Por exemplo, o backup de um está no servidor dois e o backup do servidor dois está no servidor um. Portanto, não há perda de dados, se o servidor um cair ou se você precisar colocar o servidor offline. Os backups são disponibilizados de uma só vez. E isso também é muito linearmente escalável, na verdade, é nossa topologia mais escalável em termos de números de desempenho.
Deixe-me mostrar rapidamente alguns números de referência para apoiar isso. Por favor, deixe-me saber se há alguma dúvida? Como eu disse, vou rapidamente percorrer essas topologias para economizar algum tempo aqui.
Aqui está o cache espelhado com dois nós. Replicado muito bom para leituras, as gravações não são tão escaláveis, mas você pode ver o ponto aqui porque tem natureza de sincronização de atualizações e partição com leituras, bem como escalabilidade de gravações. Réplicas particionadas com leituras e gravações, também possuem backups para que você obtenha backups juntamente com desempenho e escalabilidade. E também particionamos réplicas com a réplica de sincronização.
Cache de cliente
Há mais alguns recursos também, por exemplo, também suportamos o cache local próximo ao cliente sem nenhuma alteração de código, você também pode ativar o cache no lado do seu aplicativo. E esse cache estaria em sincronia com o cache do servidor, recomendado principalmente para o tipo de referência de dados. Portanto, se você tiver mais leituras do que gravações, convém ativá-lo e isso proporcionaria melhorias de desempenho super-rápidas em seu aplicativo existente. Ele salva suas viagens pela rede em um cache distribuído. Isso já está salvando suas viagens para trás em bancos de dados, mas você pode até salvar essa viagem onde você precisa atravessar a rede usando um cache de cliente. Você só precisa desligá-lo. E você pode até chegar no processo ao seu aplicativo para economizar ainda mais a serialização e a comunicação entre processos. E NCache gerencia toda a sincronização. Se algo mudar aqui, será propagado aqui, bem como em outros caches de clientes e vice-versa. É um recurso muito bom para começar. Eu já cobri benchmarks de desempenho.
Replicação WAN de Cache Distribuído
Em seguida, temos suporte à replicação de WAN também no Microsoft Azure. Por exemplo, se você tem dois data centers, um em Nova York e outro talvez na Europa certo, então você pode até ter transferência de dados de um data center para outro. Você pode ter um cluster de cache aqui e com a ajuda de nossa ponte, que também é copiada com os nós ativos-passivos, você pode transferir dados para a ponte e, em seguida, a ponte pode transferi-los para o site de destino. Isso pode ser ativo-passivo para o cenário de DR ou pode ser ativo-ativo também.
OK. Há uma pergunta. Posso usar o cache do cliente em um sistema desconectado que é um aplicativo móvel sem conectividade de rede temporária? Essa é uma pergunta muito boa. A questão é que posso usar o cache do cliente em modo desconectado. Já falamos sobre isso; este foi um pedido de recurso por um dos clientes e, em seguida, discutimos longamente. Então, há um requisito específico que você está interessado. Já temos alguns planos, já discutimos isso e, desde então, já tivemos um pedido semelhante a esse. Se você pudesse me enviar um e-mail sobre isso, quero que o cache do cliente seja usado para o meu caso de uso e quero que seja usado mesmo no modo desconectado. Ficarei muito feliz em passar isso para a engenharia, porque eles já estão discutindo e eles fornecem isso. Muito obrigado.
OK. Aguardo seu e-mail nesse caso. Neste ponto, o cache do cliente caminha em combinação com o cache do servidor. Se isso cair, o cache do cliente será sincronizado com um cache do servidor, portanto, isso também perderá todos os dados. Mas estamos planejando usar um modo desconectado, onde mesmo que a conexão do servidor caia, o cache do cliente permanece funcionando e também enfileira algumas operações para serem executadas em um estágio posterior.
Demonstração prática
Em seguida, mostrarei rapidamente uma demonstração prática. Como funciona o produto real? Temos pouco tempo restante, creio que temos dez minutos. Então, darei rapidamente uma visão geral do Azure. O que você precisa essencialmente para começar NCache é que você planeja a implantação para NCache.
A primeira coisa que você precisa é criar uma rede virtual do Azure. Você vem para o Microsoft Azure, cria uma rede virtual. Você pode usar a criação rápida ou a criação personalizada e, por exemplo, se eu escolher a criação rápida, posso dizer NCache VM. Esta seria uma rede virtual que usarei para NCache e então eu poderia simplesmente criar essa rede virtual. Você pode apenas apresentar detalhes específicos sobre a rede virtual, conforme necessário. Ou você pode ter uma rede virtual já em seu ambiente que gostaria de usar para NCache implantações. Então, esse é o nosso primeiro passo. Eu tenho algumas redes virtuais que já estão criadas. Então, eu posso simplesmente ir em frente e ir para a próxima etapa.
O próximo passo seria criar NCache máquinas virtuais. Você só precisa criar uma máquina virtual que possa ter NCache pré-instalado, você pode simplesmente instalar NCache pegue nossa imagem de VM do Microsoft Azure do Azure marketplace isso é para NCache professional mas se você estiver interessado em NCache enterprise, você pode simplesmente usar o servidor de imagem simples 2012. Instalar NCache em cima dela e, em seguida, salve essa imagem para um estágio posterior e, em seguida, carregue-a, cada vez que você precisar gerar uma nova VM para NCache implantação do servidor. Então, da galeria, eu poderia escolher apenas uma Imagem, por exemplo, o servidor de 2012. Eu poderia escolher em seguida, apenas dar-lhe algum nome. Por exemplo, demo 3. Eu vou escolher algum nível de servidor e então eu poderia apenas preencher algumas informações conforme necessário.

Estas são etapas específicas do Azure. Então, eu tenho certeza que você estaria familiarizado com isso. A próxima coisa que é a mais importante é se você deseja criar um novo cloud service ou use o que já está lá. Por exemplo, se eu usar o benchmark, ele também pegará automaticamente a rede virtual. Mas você pode criar suas VMs para estarem lá por conta própria cloud services também para isso você pode optar por criar um novo cloud service. Mas você ainda, eu recomendaria, que você escolha uma rede virtual para todas as suas VMs de servidor e, em seguida, isso deve ser o mesmo para todas as VMs de servidor para NCache. Assim, você obtém mais desempenho do sistema no que diz respeito à comunicação servidor a servidor. Então, vou escolher esse benchmark, e com base nisso eu poderia escolher o próximo.
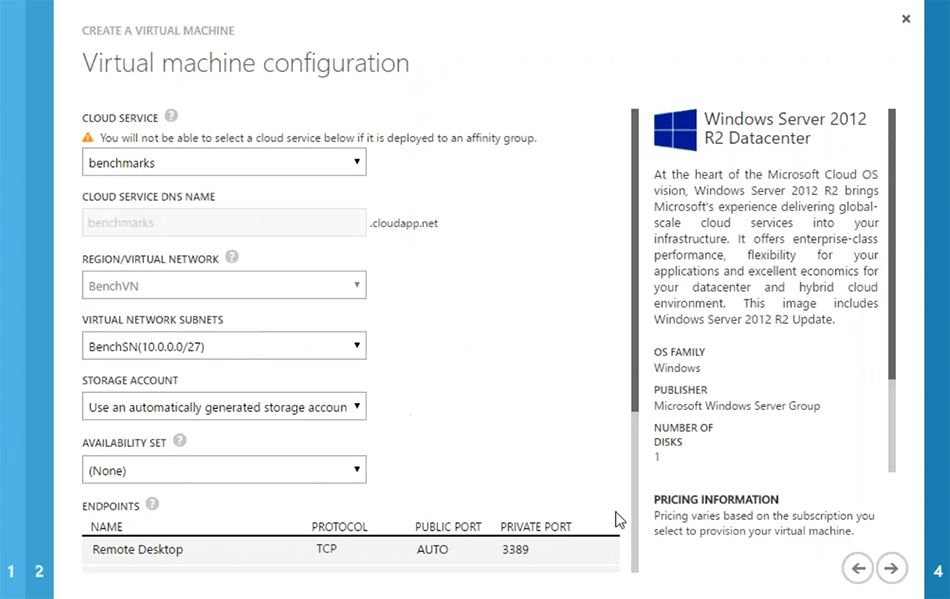
Você pode preencher alguns detalhes específicos sobre a rede, se necessário. Mas no geral, isso é tudo que eu preciso. Então, eu poderia apenas... Ok. O servidor em nuvem que escolhi não suporta esse tipo de máquina virtual. Então, eu só preciso escolher criar um novo cloud service com isso. OK. Então, vou apenas dizer para que ele aprove e pronto. Então, é assim que isso iria. Só vou cancelar isso. Eu já tenho esses servidores aqui e, de fato, posso logar rapidamente em alguns servidores, que já configurei. Por favor tenha paciencia comigo. Deixe-me mostrar como você pode começar a criar um cache, configurá-lo e testá-lo rapidamente em seu ambiente. Temos cerca de dez minutos. Então, quero aproveitar ao máximo. E pessoal, por favor, sintam-se à vontade para postar quantas perguntas precisarem. Sempre respondo perguntas enquanto estou preparando o ambiente.
OK. Eu já tenho esses servidores. Eu posso fazer logon rapidamente para estes. Já estamos usando isso para alguns testes, acho que errei a senha aqui, por favor, tenha paciência comigo. Ai está! OK! ai está! então eu tenho esse Demo 2 aqui. Então, essas são as minhas duas caixas. OK! Então, eu tenho essas duas caixas já configuradas que fazem parte da mesma rede virtual no Microsoft Azure.
Há uma pergunta. Preciso necessariamente de uma VM ou posso usar um servidor de aplicativos do Azure? cadê o docker? Ainda não temos suporte do docker. Posso verificar com a engenharia se eles estão trabalhando em um. No que diz respeito ao modelo de servidor, para NCache você precisa ter uma VM no Microsoft Azure. A aplicação virtual pode ser de modelo de serviço, pode ser uma cloud service, pode ser uma função da Web, pode ser uma função de trabalho, pode ser a VM real onde seu aplicativo está implantado. Mas o NCache a parte do servidor tem que ser uma VM e, como eu disse, a maneira mais fácil seria criar uma imagem de VM pré-configurada de NCache. Mantenha-o na galeria e carregue-o, quando precisar gerar uma nova instância dele. Você pode até escolher o mesmo para dimensionamento automático, onde você tem os modelos de VM disponíveis, NCache instalado ativado e configurado, você apenas gera essas novas VMs, quando seu nó cresce até um certo limite.
Há outra pergunta. Você já deve ter mencionado, existe criptografia e compactação para redução de dados em termos de utilização de largura de banda e acredito que você esteja perguntando sobre criptografia e compactação. Sim! esses dois recursos estão disponíveis sem nenhuma alteração de código. Você pode criptografar seus dados para transmissão de dados confidenciais, os dados podem ser criptografados e, em seguida, os dados também podem ser compactados. Então, isso faz parte NCache Apoio, suporte. Muito obrigado por fazer essas perguntas. Por favor, deixe-me saber se há mais perguntas.
Configurando um Ambiente
Eu rapidamente quero mostrar a você o produto real em ação. Então, a próxima coisa que você precisa fazer é ir ao nosso site e instalar NCache ou a versão em nuvem, que está aqui, que é a nuvem profissional, está disponível no Microsoft Azure marketplace também ou apenas baixe o Enterprise Edition regular e instale-o em suas VMs do Microsoft Azure. Já fiz a instalação do Enterprise. Então, o primeiro passo está completo. Agora, o segundo passo é criar um cache sem nome e, para isso, você pode iniciar um NCache ferramenta de gerenciamento que vem instalada com NCache. Portanto, você pode gerenciar tudo de um dos VMS conforme necessário ou também gerenciá-lo de um servidor separado que tenha acesso na rede a esses servidores.
Criar um cache clusterizado
A próxima etapa é criar um cache nomeado. Eu vou fazer isso rapidamente. É chamado de cache de demonstração.
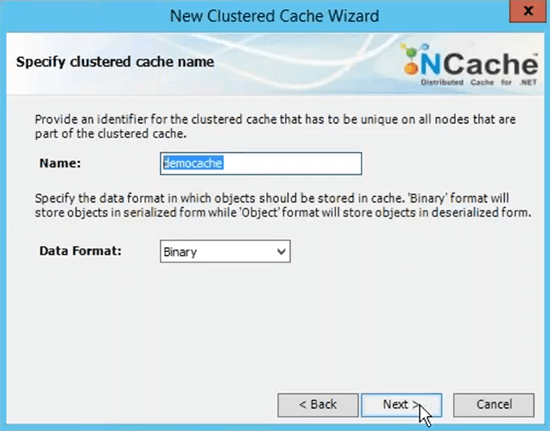
Este é o nome que você usará para todos os seus aplicativos cliente para usar esse cache. Você seria capaz de se referir a esse nome para ir em frente e buscar dados do cache. Vou escolher a topologia de cache de réplica particionada porque essa é a mais recomendada.
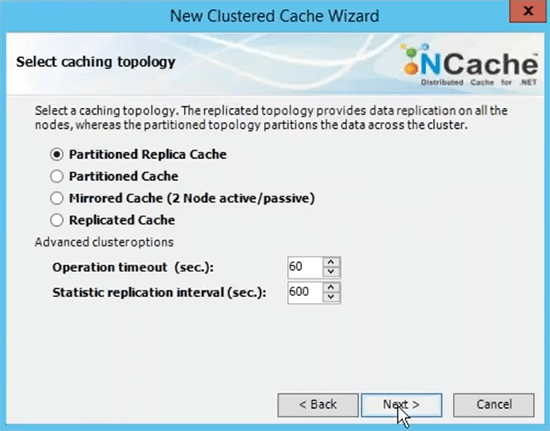
Eu vou escolher em seguida escolher Async como uma opção de replicação porque é mais rápido. Servidor 1 e veja se está usando o IP privado dos servidores e é por isso que recomendei que você meça a rede virtual em termos de implantação de servidor para servidor. Então, que eles sejam acessíveis nos IPs internos e você tenha uma comunicação muito rápida entre os servidores.
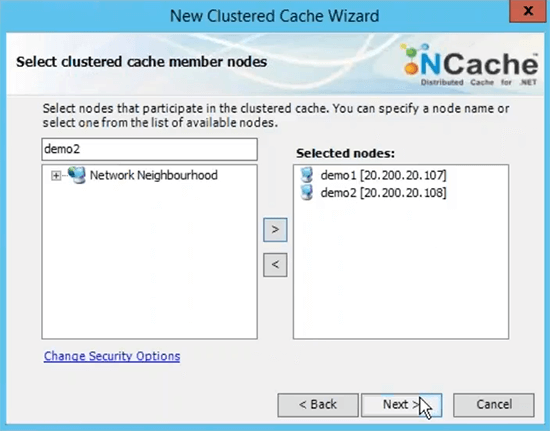
Porta TCP para comunicação por padrão Azure VMS tem firewall aberto. Então, eu recomendo que você desligue isso ou pelo menos dê um soco NCache portas para comunicação no firewall. E então o tamanho do cache por servidor é baseado na memória baseada nos dados, que você planeja ter no cache. Portanto, se você precisar de dois gigas de tamanho de cache, basta encontrar a quantidade certa de memória especificada aqui. Este é apenas um limite superior, se o cache ficar cheio, você tem duas opções, você pode rejeitar novas atualizações, o que significa que nenhum dado pode ser adicionado, você receberia uma exceção ou você pode ativar os despejos onde você pode apenas especificar uma porcentagem de despejo e esses algoritmos podem controlar quantos itens podem ser removidos usando esses algoritmos para liberar espaço para os novos itens. Portanto, se seu cache ficar cheio, os despejos forem ativados, alguns itens serão removidos automaticamente e você poderá adicionar mais itens. Eu apenas escolho terminar com a configuração padrão.
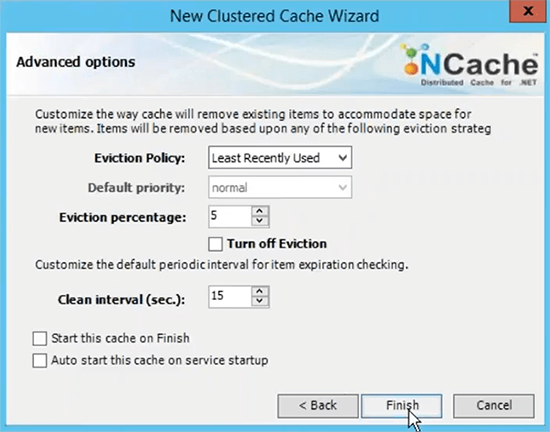
Em seguida, isso conclui nossa etapa 2, onde temos o cache configurado no painel direito, todas as configurações relacionadas a esse cache. O passo 3 é adicionar o nó do cliente, eu poderia apenas adicionar o demo 3, mas como temos apenas dois servidores e vou adicionar essas duas caixas como clientes também. A etapa 4 é iniciar e testar esse cluster de cache, para isso, basta clicar com o botão direito do mouse e escolher isso e isso iniciaria esse cache em todo o meu servidor de cache e, a propósito, esses nós clientes são realmente minhas funções da Web ou VMs, onde meu aplicativo está implantado.
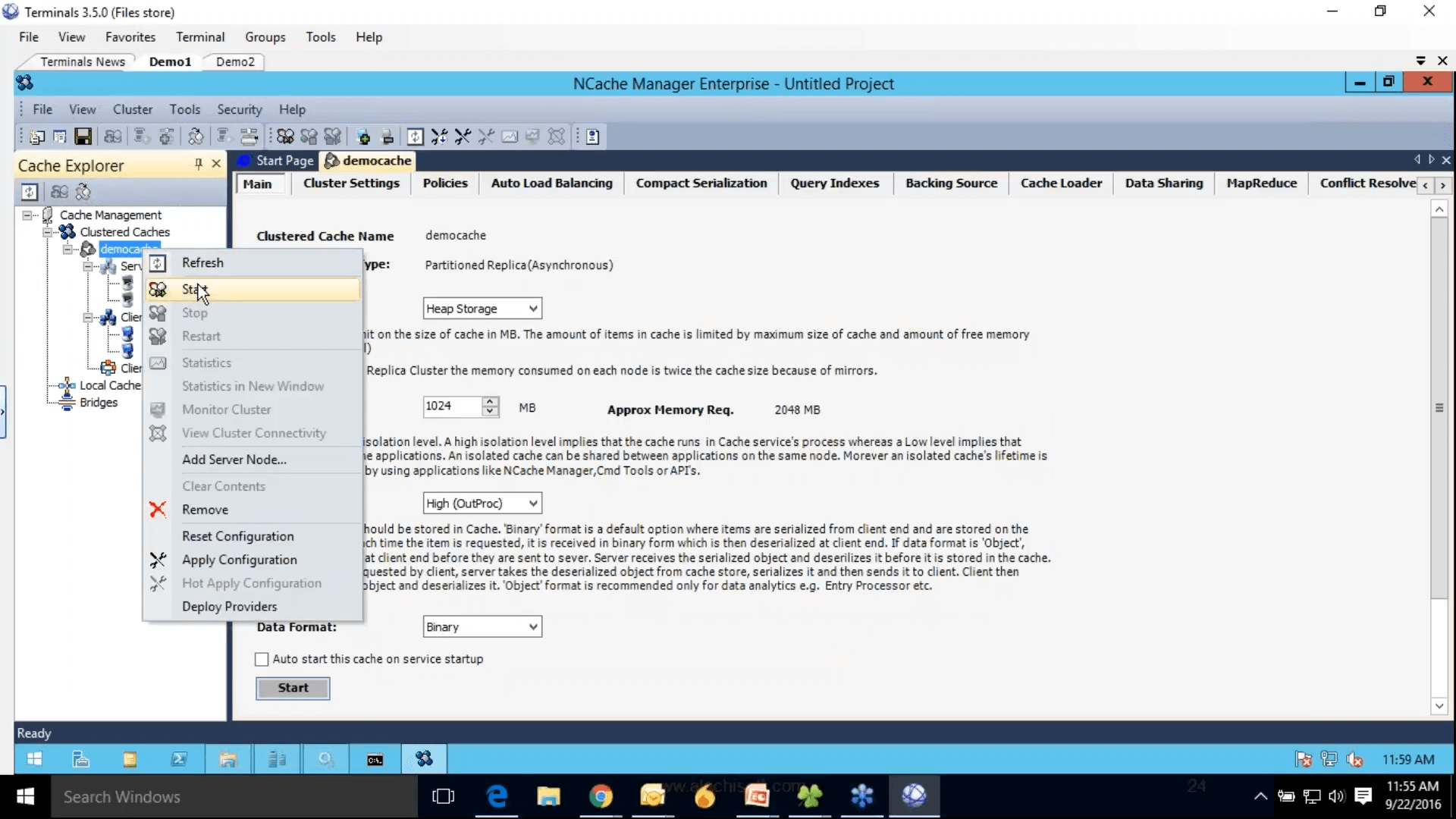
Então, é por isso que eu recomendei que você mantenha tudo na mesma rede também. Então, que você poderia apenas gerenciá-los de NCache Gerente. E clique com o botão direito do mouse nas estatísticas, isso abriria contadores perf-mon. O cache iniciou algumas das configurações estão acinzentadas, o que não pode ser alterado enquanto o cache está em execução, mas você ainda pode alterar algumas das configurações, como ativar a compactação, clicar com o botão direito do mouse e escolher configurações de aplicação rígida. Vai pedir para você salvar o projeto primeiro. Então, eu vou fazer isso e, em seguida, aplicar configurações difíceis. Ai está.
Agora o cache foi configurado, os clientes foram configurados. Terminamos com três etapas, instalamos NCache.
Simule o estresse e monitore as estatísticas de cache
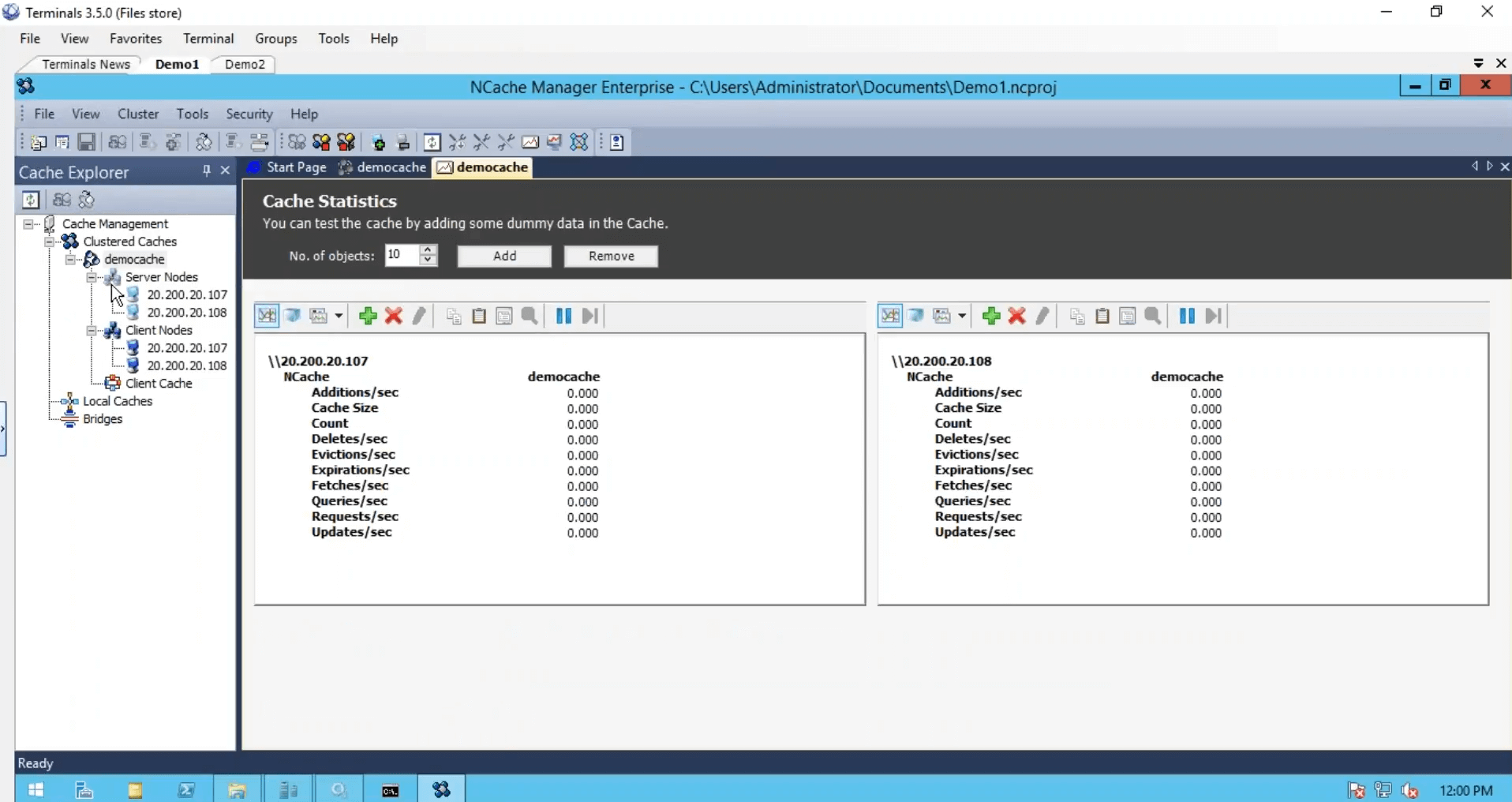
Criamos o cache, configuramos os clientes, terminamos do ponto de vista da configuração, mas só precisamos iniciar e executar esse cluster de cache e, para isso, usarei uma ferramenta de teste de estresse, que vem instalada com NCache. E execute-o no meu cache. Então, que eu pudesse ver alguma atividade também. Também vou fazer logon na minha segunda caixa e executar esse aplicativo baseado em console. Então, isso e antes, eu executo a segunda instância e vejo o contador de solicitações por segundo. Temos cerca de mil solicitações por segundo geradas por uma instância da ferramenta de teste de estresse.
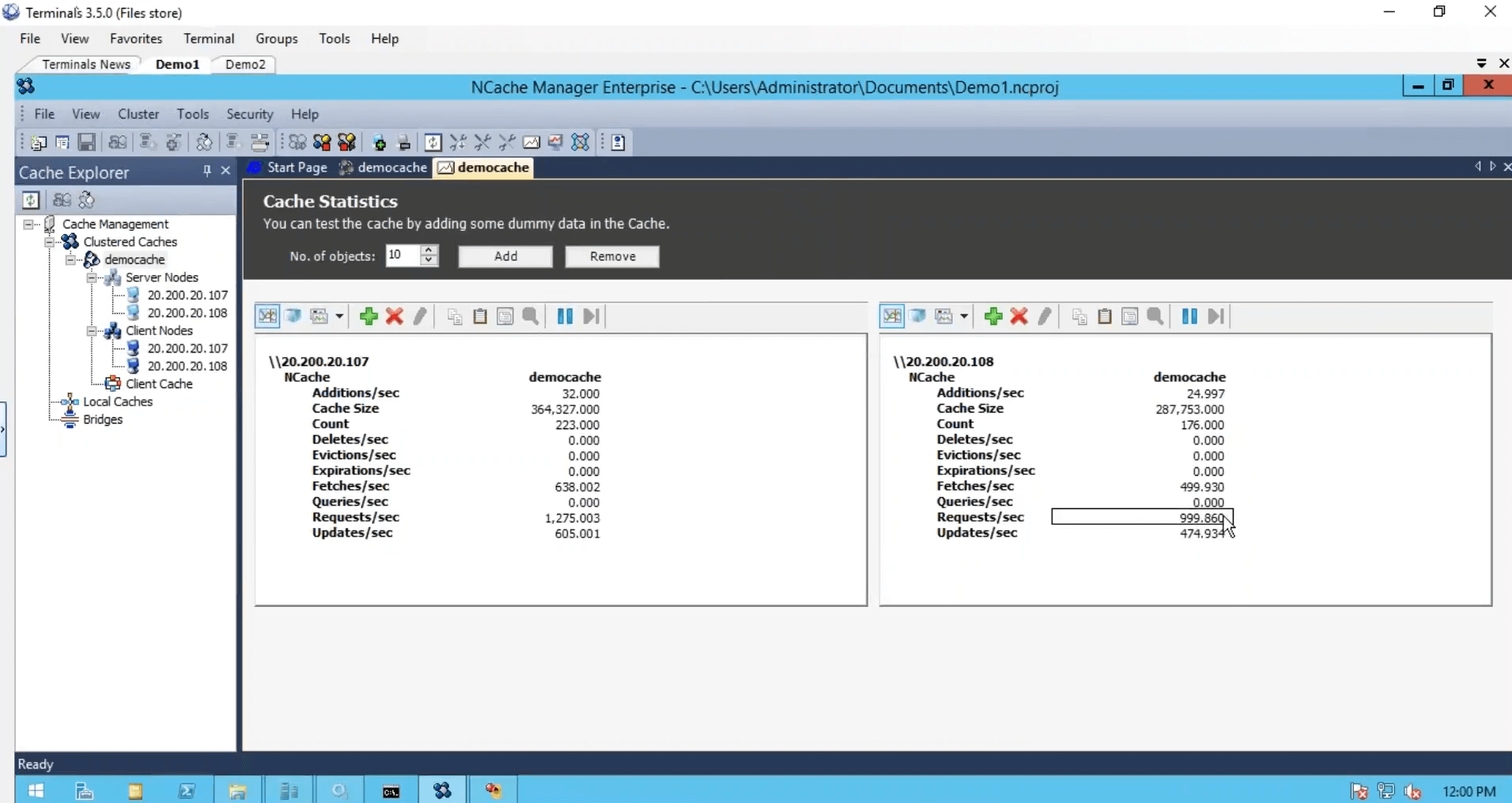
No segundo servidor, vou apenas executar isso. Então, temos um pouco mais de carga e notamos que o contador de solicitações por segundo quase pulou para o dobro. Duas mil solicitações por segundo.
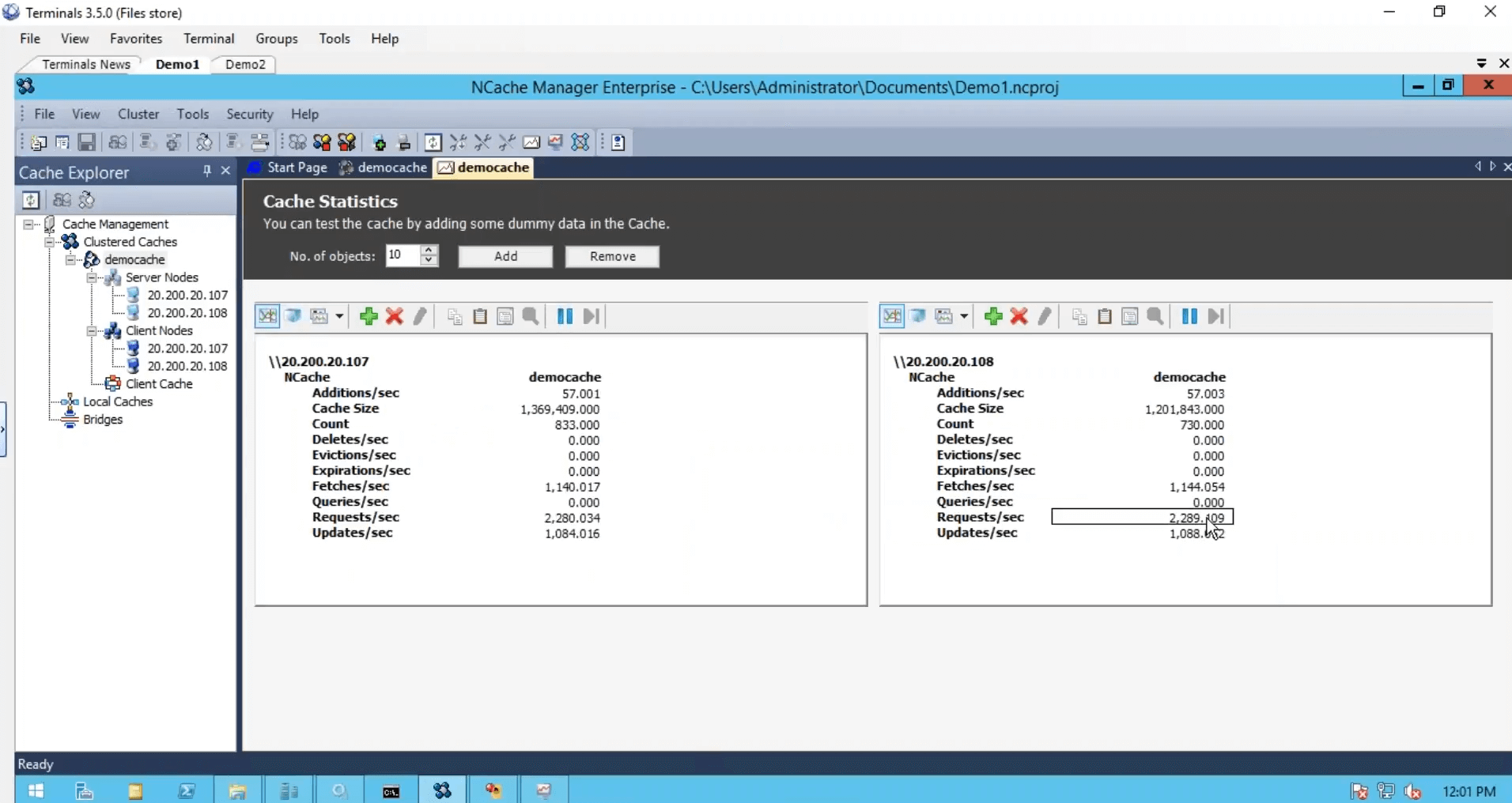
Embora eu tenha executado uma instância desta caixa, ela ainda estava usando os dois servidores. Eu executei outra instância em que o aplicativo também estava usando os dois servidores em combinação um com o outro e, em seguida, temos essa ferramenta de monitoramento, que nos fornece saúde, CPU, solicitação, tamanho, rede e matrizes diferentes do lado do servidor, como conosco do lado do cliente.
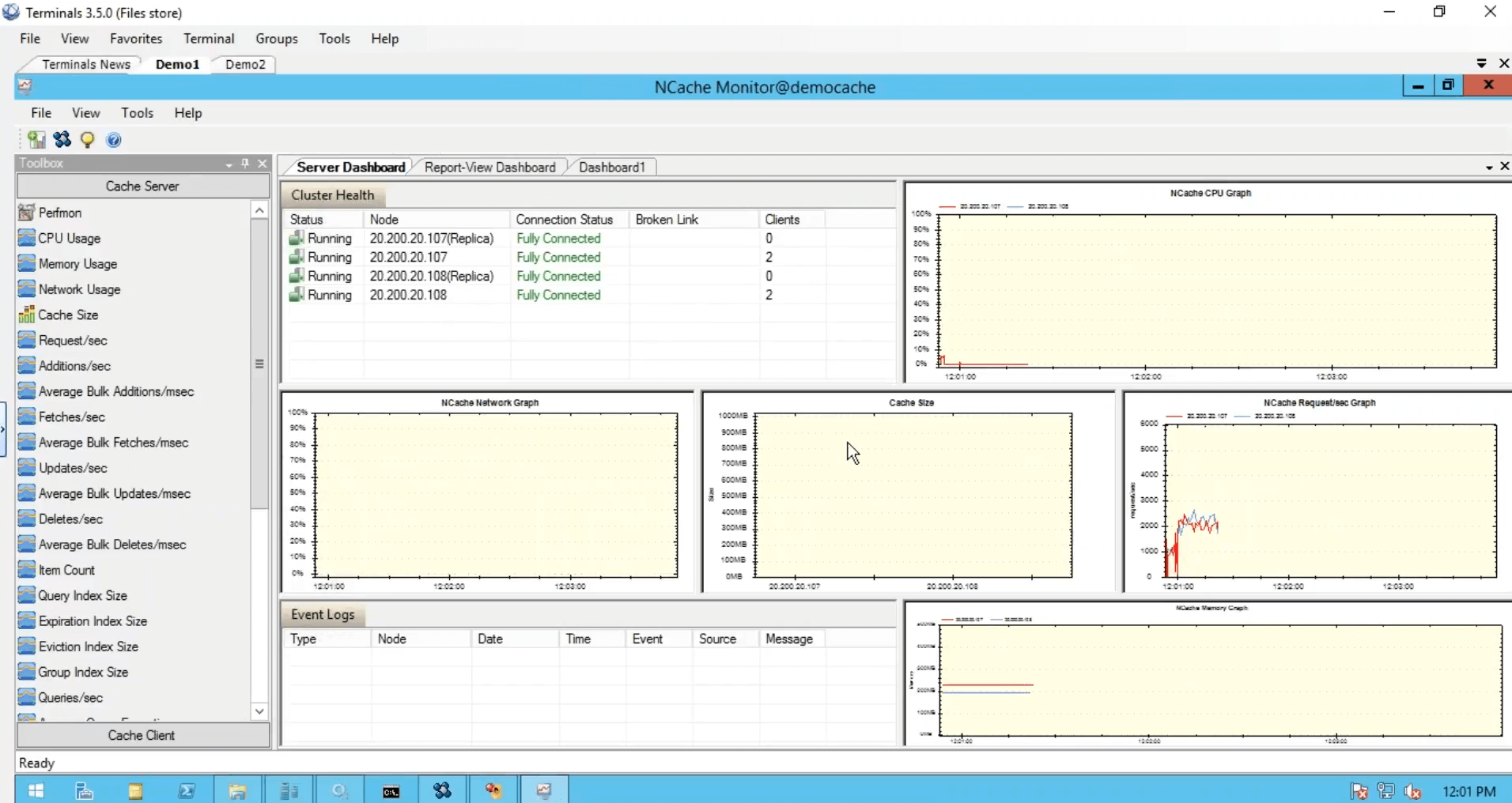
E você também pode criar seus próprios painéis como eu fiz aqui. Desculpe pessoal por causa de limitações de tempo, tive que ser um pouco rápido para isso, mas foram cinco passos simples para começar NCache. Nosso cache está funcionando.
Use NCache amostras
A próxima coisa é usar o cache em seus aplicativos reais e, para isso, você pode consultar rapidamente nosso NCache amostras. Por exemplo, se você deseja usar operações básicas, este é o exemplo. Se você quiser usar o estado de sessão, poderá usar este aplicativo de estado de sessão ASP.NET. Também temos exemplos de estado de exibição e cache de saída disponíveis nesta lista. Portanto, aproveite-os e consulte-o para usar NCache em aplicações reais.
Há uma pergunta. Posso configurar dois níveis de cache, um maior igual a 200 GB em um estado persistente e um menor igual a 1 GB mais volátil na memória e ter uma memória de nível 1 sincronizada com um subconjunto de objetos de memória comumente referenciados do cache de nível 2? Isso é possível. Você tem duas perguntas. A primeira pergunta é se você pode criar dois caches diferentes com duas memórias diferentes. Sim. Você pode, a maioria de nossos clientes criar um cache para dados estáticos e outro cache para dados dinâmicos. Então, isso é algo que você pode fazer e pode criar configurações completamente diferentes para esses dois caches.
A próxima pergunta é: existe a possibilidade de sincronizar dados entre esses dois caches? Sim. Você pode. Existe essa dependência de sincronização de cache. Esse recurso está disponível em particular, mas posso compartilhar alguns detalhes de como implementá-los e você também pode ter uma dependência de sincronização entre dois caches diferentes. Esse mesmo recurso é o que usamos em caches em espécie onde quer que tenhamos cache de cliente, que é um cache e é sincronizado com o cache clusterizado configurado em outros servidores. Então sim. Para responder sua pergunta sim, você pode ter dois caches diferentes e também pode ter sincronização entre os dados nesses dois caches.
Vou resumir rapidamente para você, há muitos aumentos de cache de objetos que você pode aproveitar, eles fazem parte do NCache suporte ao cache de objetos e, em seguida, já abordamos o estado de exibição da sessão ASP.NET. Existem algumas integrações de terceiros também. Então, este é essencialmente o fim do nosso webinar. Peço desculpas por executar alguns bits por causa de restrições de tempo, mas apenas para reiterar, abordamos alguns detalhes básicos sobre problemas de incapacidade, falamos sobre o cache de distribuição na memória na solução, falamos sobre a implantação no Microsoft Azure, diferentes casos de uso , suporte de cluster, suporte de topologia dentro NCache. Tivemos uma demonstração prática específica sobre como começar a usar o Microsoft Azure até NCache vai.
Por favor, deixe-me saber, como você gostou da apresentação? Como você gostou do produto em geral? Dê-me o seu feedback sobre isso. Há algumas coisas que você pode fazer no final. Você pode ir ao nosso site e baixar uma avaliação de 30 dias do NCache. Você também pode escolher nossa edição em nuvem, que é NCache professional cloud, está disponível no Microsoft Azure. Temos um cliente também. Em seguida, você pode até usar suas VMs do Azure para acompanhar o produto Enterprise Edition, se necessário. Você pode entrar em contato com nossa equipe de suporte acessando a página de suporte. Existem alguns detalhes de contato que você pode entrar em contato com o suporte em support@alachisoft.com.Você pode solicitar uma demonstração do produto conforme necessário e também entrar em contato com nossa equipe de vendas para obter informações sobre preços. Então, já estamos no nosso marcador de uma hora, então acho que é hora de dizer adeus. Por favor, deixe-me saber se houver alguma dúvida, mesmo após esta demonstração. Você pode entrar em contato por e-mail ou por telefone e ficarei muito feliz em ver qualquer dúvida de vocês. Muito obrigado rapazes. Foi um prazer apresentar NCache webinar hoje. Por favor, deixe-me saber como você gostou do produto, como você gostou da apresentação e sempre podemos continuar a partir daí. Muito obrigado pelo seu tempo, a todos.