Mettre à l'échelle les applications .NET dans Microsoft Azure avec le cache distribué
Webinaire enregistré
Par Ron Hussain
Découvrez quels sont les goulots d'étranglement de l'évolutivité de vos applications .NET dans Microsoft Azure et comment vous pouvez améliorer leur évolutivité avec la mise en cache distribuée.
Ce webinaire couvre:
- Aperçu rapide des goulots d'étranglement des performances dans les applications .NET
- Qu'est-ce que la mise en cache distribuée et pourquoi est-ce la réponse dans Azure ?
- Où pouvez-vous utiliser la mise en cache distribuée dans votre application ?
- Quelles sont les fonctionnalités importantes d'un cache distribué ?
- Quelques exemples pratiques d'utilisation d'un cache distribué dans Azure
Merci beaucoup d'avoir participé. Permettez-moi de vous informer rapidement sur le webinaire. Tout d'abord, je m'appelle Ron Hussain. Je suis l'un des experts techniques de Alachisoft et je serai votre présentateur pour le webinaire d'aujourd'hui. Je couvrirai tous les détails techniques dont vous avez besoin pour faire évoluer vos applications .NET dans Microsoft Azure à l'aide d'un système de mise en cache distribué en mémoire et j'utiliserai NCache comme exemple de produit pour cela. C'est notre produit principal pour la mise en cache distribuée. Nous sommes le fier créateur de NCache et je vais l'utiliser comme exemple de produit. Une plus grande partie de ce webinaire sera en écoute seule, ce qui signifie que je parlerai principalement, mais vous pouvez toujours participer. Vous pouvez poser autant de questions que nécessaire. Sur le côté droit de votre écran, il y a cet onglet questions et réponses. Si vous développez l'onglet des questions, vous pouvez poster autant de questions que nécessaire, et comme je l'ai dit, je garderai un œil là-dessus et je répondrai à toutes les questions que vous auriez postées dans cette fenêtre. Donc, juste à titre de confirmation, si vous pouvez confirmer en utilisant le même onglet questions et réponses, veuillez confirmer si vous pouvez voir mon écran et si vous m'entendez bien. Je peux rapidement démarrer. D'accord. Je vois déjà certaines questions être postées. Donc, merci beaucoup pour la confirmation.
Commençons par ça. Salut tout le monde, je m'appelle Ron Hussain comme je l'ai dit, je suis l'un des experts techniques de Alachisoft et je serai votre présentateur pour le webinaire d'aujourd'hui. Le sujet que nous avons choisi aujourd'hui est la mise à l'échelle des applications .NET dans Microsoft Azure à l'aide d'un système de mise en cache distribué en mémoire. À Alachisoft nous avons divers produits et le plus populaire est NCache, qui est un système de mise en cache distribué en mémoire pour les applications .NET et Java. NCache sera le produit principal, que j'utiliserai comme exemple, mais je m'en tiendrai aux bases de Microsoft Azure. Comment utiliser NCache (A Distributed Caching System) dans Microsoft Azure et profitez-en en termes d'évolutivité, de performances applicatives et de fiabilité globale du système dans votre architecture. Donc, puisque vous avez confirmé que vous pouvez voir mon écran, laissez-moi commencer.
Qu'est-ce que l'évolutivité?
D'accord! avant de passer au vrai sujet. Je parlerai de quelques concepts de base et je commencerai par qu'est-ce que l'évolutivité ? L'évolutivité est la capacité d'augmenter la charge transactionnelle sur les applications et en même temps de ne pas ralentir vos applications. Par exemple, à ce stade, si vous gérez 1,000 1,000 requêtes, si la charge de votre application augmente, plus d'utilisateurs se connectent, puis commencent à utiliser vos applications plus intensivement que la charge, par exemple, elle passe de 10,000 10,000 à 20,000 XNUMX requêtes par seconde. Maintenant, vous voulez vous adapter à cette charge accrue, vous voulez gérer cette charge accrue et en même temps, vous ne voulez pas ralentir les performances de vos demandes individuelles. Cela ne devrait pas se produire de telle sorte qu'une demande attende d'être terminée et qu'une demande soit en cours d'achèvement, d'autres demandes attendent cela. Ces demandes doivent être traitées exactement dans le même laps de temps qu'elles prenaient auparavant. Mais en même temps, vous voulez cette évolutivité, cette capacité à gérer de plus en plus de requêtes chargeant XNUMX XNUMX requêtes par seconde ou XNUMX XNUMX requêtes par seconde. Donc, sans perdre les performances, si vous avez la possibilité d'augmenter votre charge transactionnelle sur vos applications, c'est ce que nous appellerions la scalabilité. Et c'est ce sur quoi nous allons nous concentrer aujourd'hui.
Qu'est-ce que l'évolutivité linéaire ?
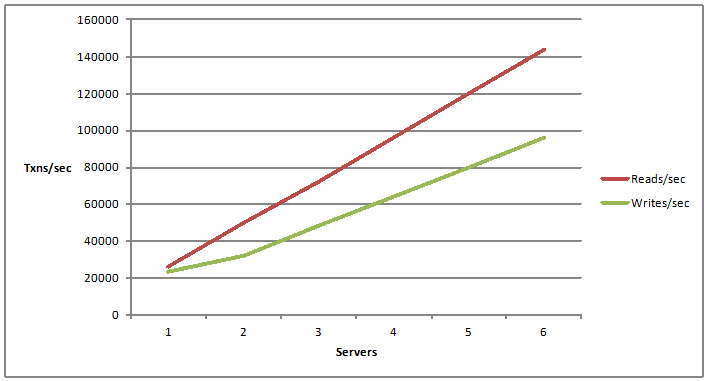
Il existe un terme associé appelé évolutivité illimitée. C'est une évolutivité linéaire. L'évolutivité linéaire correspond à une croissance linéaire de votre capacité de lectures et d'écritures par seconde. Par exemple, si vous ajoutez plus de serveurs. Ainsi, maintenant que vous ajoutez un serveur, vous avez une certaine capacité à gérer les demandes d'opérations de lecture et d'écriture. Que se passe-t-il si vous ajoutez un autre serveur et que vous ajoutez ensuite d'autres serveurs ? La possibilité d'ajouter plus de serveurs et en ajoutant plus de serveurs, vous augmentez vos chiffres d'évolutivité, vous obtenez de plus en plus de capacités par votre architecture d'application, c'est ce que nous appelons l'évolutivité linéaire.
Quelles applications ont besoin d'évolutivité ?
À présent! La question suivante serait de savoir quel type d'applications aurait besoin d'évolutivité. La réponse est très simple. Toute application qui peut avoir à gérer des millions de demandes des utilisateurs. S'il s'agit d'une charge de transaction énorme. En règle générale, nous avons des applications ASP.NET. S'il y a un front-end, par exemple, une application de commerce électronique, une application de réservation de compagnie aérienne peut-être, tout ce qui est destiné au public mais qui a beaucoup de trafic, cette application est le candidat idéal pour l'évolutivité.
Ensuite, nous pourrions avoir WCF pour les services Web .NET et l'architecture orientée services. Il pourrait être de retour ou il pourrait s'agir de services Web frontaux, peut-être consommés par vos applications Web ou par des applications internes que vous pourriez avoir. Ceux-ci peuvent avoir à traiter une énorme quantité de demandes, une énorme quantité de données doit être récupérée et livrée aux programmes appelants. Ainsi, ces types d'applications ont également besoin d'évolutivité. Et puis vous voudrez peut-être mettre une sorte d'infrastructure, qui pourrait gérer la quantité de charge de requête.
Ensuite, nous avons des applications de données volumineuses. C'est un mot à la mode courant de nos jours. Beaucoup d'applications, beaucoup d'architectures s'y dirigent, où vous pourriez avoir à traiter d'énormes quantités de données à distribuer sur différents modules, différents processus mais vers la fin, vous auriez affaire à beaucoup de données, beaucoup de demandes, afin de les traiter.
Et puis nous avons d'excellentes applications informatiques, où vous devrez peut-être traiter une énorme quantité de calculs via une distribution sur plusieurs serveurs peu coûteux, ce sont les applications. Ainsi, en général, toute application .NET ou application Java d'ailleurs, qui peut avoir à gérer un million de requêtes des utilisateurs ou des programmes back-end, sont les principaux candidats qui doivent avoir une évolutivité dans l'architecture.
Et, nous nous concentrerons sur certains d'entre eux une fois, nous passerons également à nos cas d'utilisation. Et, les gars, nous ne sommes qu'au début de ce webinaire, pour ceux d'entre vous qui viennent de nous rejoindre, je vais juste couvrir quelques concepts de base en termes de mise en cache distribuée. Je parlerai des différents problèmes auxquels vous seriez confrontés, puis des solutions et parlerai également du déploiement d'un cache distribué, comme NCache dans Microsoft Azure. Donc, s'il y a des questions, n'hésitez pas à taper dans l'onglet questions et réponses. Et vous pouvez toujours me donner votre avis également. Si vous souhaitez participer, vous pouvez à nouveau utiliser le même onglet de questions et réponses.
Qu'est-ce que le problème d'évolutivité ?
Ensuite, une fois que nous avons défini ce que nous avons, qu'est-ce que l'évolutivité ? Qu'est-ce que l'évolutivité linéaire et quel type d'applications a besoin d'évolutivité ? Le point suivant et le plus important de ce webinaire, à quel type d'applications ou à quel type de problèmes d'évolutivité vos applications seraient-elles confrontées ? Où est exactement le problème d'évolutivité ?
Maintenant, votre architecture d'application, il pourrait s'agir d'une application ASP.NET ou d'un service WCF, ceux-ci évoluent très bien et ceux-ci évoluent déjà de manière linéaire. Vous pouvez mettre un équilibreur de charge devant et vous pouvez simplement ajouter de plus en plus de serveurs d'applications ou de serveurs Web, de serveurs Web frontaux et vous obtenez déjà une évolutivité linéaire de votre architecture. Donc, il n'y a pas de problème là-bas. Le problème réel en ce qui concerne le stockage de données, ces serveurs d'applications ou serveurs Web, ils parleraient toujours à certaines sources de données back-end, telles que le service d'état des bases de données ou il pourrait s'agir de n'importe quel système de fichiers back-end ou d'une source de données héritée. . Ce qui ne peut pas gérer une charge de transaction énorme et vous n'avez pas la possibilité d'ajouter de plus en plus de serveurs ici. Et ce diagramme l'explique bien.
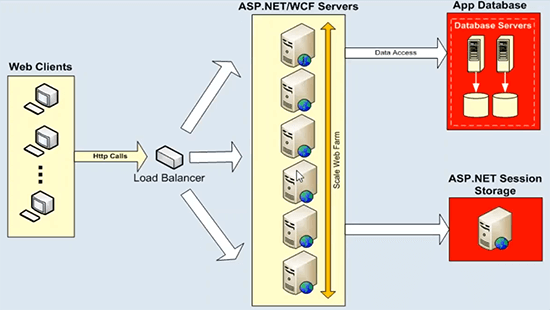
Là où nous avons le stockage de données, il y a un goulot d'étranglement d'évolutivité. Nous avons un exemple ASP.NET WCF ici, mais vous pouvez ajouter autant de serveurs que vous le souhaitez, vous commencez avec deux serveurs, si votre charge augmente, vous pouvez ajouter un autre serveur, mettre un équilibreur de charge devant, puis utiliser uniformément tous les ressources sur cette couche. Donc, il n'y a pas de problèmes. Mais ces boîtiers d'application ou ces serveurs Web frontaux communiqueraient toujours avec certaines sources de données principales. Et c'est un déploiement typique, où nous avons des serveurs de base de données, qui ne sont pas si rapides à démarrer, et puis ils ont des problèmes d'évolutivité. Ils s'étoufferaient sous une énorme charge de transactions et, dans certains cas, ils constitueraient également un point de défaillance unique. Mais surtout, ces serveurs de base de données dans n'importe quelle architecture d'application, représentent une menace très sérieuse et c'est un goulot d'étranglement d'évolutivité. Ainsi, vous perdriez toute l'évolutivité que vous obtenez sur ce niveau une fois que vous ciblez toutes vos requêtes vers certains serveurs de base de données. Et il en va de même pour l'état de session ASP.NET. Si vous utilisez un serveur SQL Server ou un serveur d'état de session pour cela, c'est parce qu'il reste au-dessus de cela. Il s'agira toujours d'un serveur unique hébergeant toutes vos données de session et la session est un type de données très transactionnel. Vous avez alors besoin d'une source de données très évolutive pour gérer ces demandes. C'est donc le principal défi que nous essayons de relever à l'aide d'un système de mise en cache distribué.
La solution : cache distribué en mémoire
La solution est très simple, comme je l'ai dit, vous pouvez utiliser un système de mise en cache distribué en mémoire évolutif. Comme NCache pour gérer tous les problèmes dont nous venons de parler associés aux sources de données en ce qui concerne l'évolutivité.
La prochaine chose que je vais faire rapidement est de parler de quelques bases du système de mise en cache distribué en mémoire, comme NCache. Il y a quelques caractéristiques importantes, que vous trouverez dans NCache et je m'attends à ce que cela fasse partie de la plupart de nos systèmes de mise en cache distribués en mémoire, qui sont disponibles. Donc, à cet égard, donc NCache si je dois définir, quel serait un système de mise en cache en mémoire ?
Clustering Dynamique
Il s'agit d'un cluster de plusieurs serveurs de cache peu coûteux, qui sont réunis, vous pouvez extraire leur mémoire ainsi que la capacité du processeur. Ainsi, ils sont réunis en une capacité et vous tirez leur mémoire ainsi que les ressources du processeur. Donc, physiquement, il pourrait s'agir de plusieurs serveurs, qui ne sont pas si chers une fois qu'un simple boîtier de configuration de serveur Web ferait l'affaire, c'est quelque chose que vous pourriez utiliser pour la mise en cache, puis ces serveurs se rejoignent et forment une capacité logique. Ainsi, du point de vue de votre application, vous n'utilisez qu'un seul cache distribué, mais physiquement, plusieurs serveurs peuvent fonctionner en arrière-plan, tirant toute la puissance de calcul et la mémoire nécessaires pour créer ce cache distribué en mémoire. Donc, c'est la première et la plus importante caractéristique que ce n'est pas ce serveur unique. Il aurait plusieurs serveurs travaillant en combinaison les uns avec les autres. Donc, nous sommes déjà en avance sur la base de données, où nous n'aurions qu'un seul serveur hébergeant toutes les données et traitant toutes les requêtes.
La cohérence des données
La caractéristique suivante concerne la cohérence des données puisque nous avons affaire à plusieurs serveurs en coulisses, la question suivante serait de savoir comment gérerions-nous les mises à jour. Par exemple, les mêmes données sont mises à jour sur un ou deux serveurs ou s'il existe des répliques ou plusieurs copies de données sur différents serveurs. Ainsi, quelle que soit la topologie que vous utilisez, les données doivent être mises à jour de manière cohérente. Ainsi, une fois que vous avez mis à jour quoi que ce soit sur n'importe quel serveur de cache, toutes les mises à jour doivent être visibles pour tous les serveurs de mise en cache sur le cache distribué. Et au fait, j'utilise du visible, je n'utilise pas le terme réplication. La réplication est une autre caractéristique. Donc, par visible, je veux dire que, par exemple, vous obtenez un descripteur de requête par le serveur un, ces données sont mises à jour. Si la requête suivante est envoyée au serveur deux, si vous aviez également les mêmes données sur le serveur deux, vous devriez obtenir la valeur mise à jour et non la valeur obsolète du cache distribué.
Il s'agit donc d'une caractéristique très importante en termes de cache distribué, où toutes vos mises à jour de données doivent être appliquées de manière cohérente sur tous les serveurs de mise en cache. Et cela devrait être la responsabilité du cache distribué, pas votre application. L'architecture doit prendre en charge ce modèle.
Évolutivité linéaire
La prochaine chose, qui s'aligne sur notre sujet d'aujourd'hui, est la façon de procéder à une mise à l'échelle linéaire. Ainsi, le cache distribué doit évoluer linéairement pour la capacité transactionnelle ainsi que pour la capacité de mémoire. Cela devrait vous donner, où vous pouvez ajouter de plus en plus de serveurs de mise en cache et comme vous aviez plus de serveurs de mise en cache, vous atteignez une évolutivité linéaire. Je vous avais montré un graphique plus tôt. Donc, c'est à cela que je fais référence ici, où vous ajoutez de plus en plus de serveurs, vous devriez augmenter la capacité du nombre de demandeurs que vous pouvez gérer et en même temps, combien de données, combien de données peuvent être stockées dans le cache distribué linéairement. C'est donc une caractéristique très importante, qui vous donne une évolutivité linéaire hors du cache distribué et qui rend l'architecture globale de votre application très évolutive.
Réplication des données pour plus de fiabilité
Quatrième caractéristique importante. C'est la première option, vous pouvez choisir une topologie, qui prend également en charge la réplication. Vous disposez d'un cache distribué, qui réplique les données sur les serveurs pour plus de fiabilité. Si un serveur tombe en panne ou si vous devez le mettre hors ligne pour la maintenance, vous ne devriez pas vous inquiéter de la perte de données ou de l'arrêt d'une application. Voici donc quelques caractéristiques importantes du cache distribué. Je les couvrirai de plus en plus en détail dans les diapositives à venir, puis nous parlerons également du déploiement spécifique à Azure d'un cache distribué. Comment utiliser le cache distribué dans Microsoft Azure ? S'il vous plaît laissez-moi savoir s'il y a des questions jusqu'à présent. Veuillez utiliser l'onglet questions et réponses. Je vois des mains levées en général, go-to-meeting a ce problème, où il montre beaucoup de mains levées, mais s'il vous plaît, faites-moi savoir s'il s'agit réellement de questions. Veuillez taper dans l'onglet questions et réponses et je serai très heureux d'y répondre pour vous. Je pense que nous devrions continuer.
Voici le déploiement typique d'un cache distribué. Il s'agit d'un déploiement général, il n'est pas spécifique à Microsoft Azure.
NCache Déploiement dans Microsoft Azure
Je vais passer au déploiement de NCache dans Microsoft Azure juste après cela. Donc, généralement, cela peut être sur site ou dans le cloud, il n'y a pas beaucoup de choses qui changeront en ce qui concerne le déploiement de NCache se rend. C'est ainsi que vous déploieriez généralement NCache, où vous auriez une couche dédiée de mise en cache.
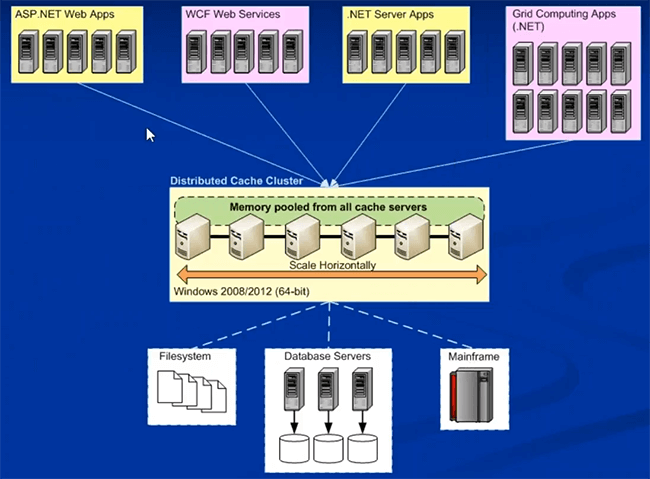
Il peut s'agir de boîtes physiques sur site, de machines virtuelles de boîtes hébergées ou de véritables machines virtuelles cloud, où vous obtenez simplement une machine virtuelle à partir du cloud, puis utilisez-la pour la mise en cache. Vous pouvez formuler un cache sur des boîtes de mise en cache dédiées séparées, c'est recommandé. Une plate-forme préférée est 64 bits et le seul prérequis pour NCache est .NET 4.0. Et puis vos applications, celles-ci peuvent également être sur site ou hébergées. Ceux-ci peuvent être déployés directement sur les serveurs dans IIS ou il peut s'agir de rôles Web ou de travail, en ce qui concerne Microsoft Azure. Ils peuvent tous se connecter à ce niveau de mise en cache pour les besoins en données. Vous pouvez avoir une installation séparée pour ceux-ci, une couche séparée pour ceux-ci, ou vous aurez également tout sur la même couche. Les deux modèles sont pris en charge. Mais une fois que vous avez présenté NCache dans l'architecture de votre application, une fois qu'elle est déployée pour la mise en cache d'objets ou pour la mise en cache de sessions, je couvrirai NCache cas d'utilisation une fois que nous nous dirigeons vers des cas d'utilisation.
Une fois que vous commencez à utiliser NCache, il enregistre vos voyages coûteux à travers le dos et les bases de données. Et puis cela vous donne une plate-forme très évolutive ici, où vous pouvez ajouter autant de serveurs que vous le souhaitez et vous pouvez évoluer. Maintenant, comparez cela avec le diagramme que je vous ai montré plus tôt.
Vous aviez une plate-forme très évolutive ici, mais c'était la principale source de discorde. La principale source de goulot d'étranglement d'évolutivité. Maintenant, si vous comparez cela, vous avez maintenant une plate-forme très évolutive entre votre couche d'application et votre base de données. Il s'agit d'une plate-forme très évolutive et vous disposez à nouveau d'une source de données en termes de cache distribué, qui est à nouveau très évolutive. Vous pouvez ajouter autant de serveurs que vous le souhaitez. Si votre charge augmente, vous n'avez pas à vous soucier de l'étouffement des sources de données back-end à ce moment-là. Vous pouvez ajouter autant de serveurs que vous le souhaitez et vous pouvez augmenter linéairement votre capacité de traitement des demandes à partir de NCache. Faites-moi savoir s'il y a des questions sur l'architecture de déploiement de NCache mais dans l'ensemble, c'est très simple.
Maintenant, la prochaine chose est de savoir comment déployer NCache dans Microsoft Azure. Donc, que j'utiliserai notre site Web. Je vais utiliser un diagramme à partir de là, alors, s'il vous plaît, soyez indulgent avec moi. Le déploiement dans Microsoft Azure n'est pas si différent de ce que nous avons sur site.
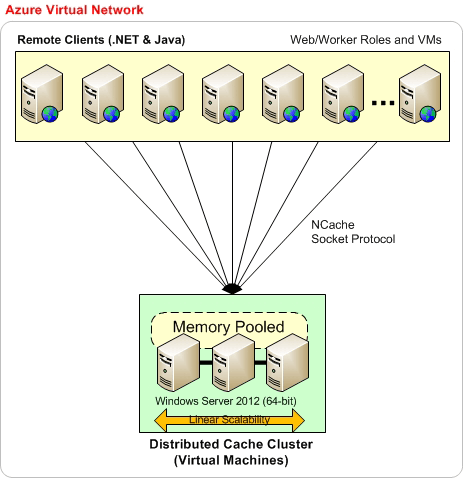
Donc, tout d'abord, il est recommandé qu'il s'agisse du déploiement de base, où vous avez tout sur le même réseau virtuel Microsoft Azure. Par exemple, vous créez un réseau virtuel, puis vous avez des machines virtuelles Microsoft Azure, le déploiement côté serveur se fera toujours sur des machines virtuelles. C'est donc le modèle que nous avons choisi pour NCache dans Microsoft Azure. Vous créez une VM ou en choisissant le même réseau virtuel vous créez tous vos déploiements de VM. Par exemple, vous pouvez commencer avec trois VMS comme indiqué ici, puis ajouter autant de machines virtuelles que nécessaire à cette couche de mise en cache. De préférence, nous souhaitons également que vos applications soient sur le même réseau virtuel Azure. Ainsi, tout peut faire partie du même réseau virtuel, c'est à ce moment-là que vous obtenez le plus de performances, puis de stabilité. NCache. Lorsqu'il n'y a pas d'exigences strictes à ce sujet, vous pouvez toujours avoir des applications déployées sur différentes machines virtuelles.
Ainsi, sur la base de ce modèle, votre architecture d'application peut être sur les machines virtuelles elles-mêmes, ce qui signifie que votre application peut être déployée directement sur IIS que vous gérez vous-même, puis en prendre entièrement en charge ou que ce soit moi-même. les modèles sont pris en charge du côté de l'application, mais NCache le déploiement côté serveur se fera toujours sur les machines virtuelles. Donc, c'est comme ça que vous postuleriez NCache et je vous montrerai en fait une fois que nous passerons à notre partie pratique.
Un autre type de déploiement est que vous pourriez avoir un réseau virtuel Azure spécifique pour votre NCache les machines virtuelles de serveur, où tous vos serveurs font partie du même réseau virtuel. De préférence également le même sous-réseau. Et vos applications pourraient également se trouver sur un réseau virtuel séparé. Dans ce cas, vous devrez avoir une sorte de ports redirigés sur le NCache réseau virtuel. Par exemple, les ports privés sont mappés sur le port public ici, puis vos applications utilisent ce port public pour se connecter à NCache. Vous devrez peut-être effectuer des configurations supplémentaires ici, mais nous avons un document d'aide détaillé disponible pour cela, mais cela fonctionne sans aucun problème. Ce serveur de réseau virtuel peut accéder aux serveurs de mise en cache à partir d'un autre réseau virtuel. Et vous pourriez même avoir les applications cache à cache à l'aide de la même fonctionnalité.
Il s'agit donc d'un autre type de déploiement, mais l'approche préférée, celle recommandée, consiste à déployer tous vos serveurs de cache ainsi que les serveurs d'applications sur le même réseau virtuel Microsoft Azure. C'est à ce moment-là que vous tireriez le meilleur parti de NCache. S'il vous plaît laissez-moi savoir s'il y a des questions.
Nous avons également un guide de déploiement Azure disponible sur notre site Web si je pouvais vous emmener à l'assistance. En fait, laissez-moi aller à la documentation ici. Sur la documentation, nous avons un guide spécifique, un guide de déploiement qui couvre tous ces détails de manière très détaillée.
D'accord. Il y a une Question. Comment est NCache différent de Redis? D'accord. L'ordre du jour d'aujourd'hui consiste davantage à utiliser NCache ou en utilisant un système de mise en cache distribué dans Microsoft Azure. Nous avons un webinaire séparé sur Redis versus NCache. Où nous parlons de différentes fonctionnalités qui sont disponibles dans NCache et alors ne fait pas partie de Redis. Pour une réponse rapide à ce sujet, je vous recommande d'aller sur notre page de comparaisons ici, puis vous avez un Redis versus NCache. Vous pouvez vous inscrire rapidement pour cela et vous devriez alors pouvoir voir toutes les fonctionnalités, comparaison fonctionnalité par fonctionnalité de NCache versus Redis. Et en fait, nous avons aussi un webinaire juste pour ça, qui est un webinaire sur notre chaîne YouTube. Donc, si vous vous connectez simplement à YouTube, recherchez Alachisoft puis sous Alachisoft il y aura beaucoup de vidéos et l'une de ces vidéos aurait Redis sources NCache Titre. Il y a un webinaire séparé à ce sujet. J'espère que cela répond à votre question. Il y a plus de questions à ce sujet. D'accord. pour en revenir à, puisque nous avons couvert le déploiement, veuillez me faire savoir s'il y a des questions liées au déploiement et je serai très heureux de répondre à ces questions pour vous.
Utilisations courantes du cache distribué
La prochaine chose est de savoir comment utiliser le cache distribué ? Quels sont les espaces communs, où vous utiliseriez un système de mise en cache distribué comme NCache? Je viens d'énumérer trois des plus courants, mais ceux-ci peuvent être spécifiques à l'industrie, cela peut être spécifique à vos besoins, à vos cas d'utilisation, il peut s'agir de différentes façons d'utiliser NCache. Mais principalement ceux-ci sont divisés en ces trois catégories.
Mise en cache des données d'application
La première catégorie est la mise en cache des données d'application. Vous pouvez utiliser un système de mise en cache distribué comme NCache en tant que mise en cache des données d'application. Tout ce qui était auparavant présent dans la base de données et vos applications allaient dans les bases de données, maintenant vous pouvez le mettre dans NCache. Et vous pouvez obtenir un cache en mémoire plus rapide par rapport à la base de données pour accéder à toutes les données que vous aviez auparavant dans la base de données. Ainsi, vous améliorez les performances de votre application, puis, plus important encore, vous évoluez de manière linéaire là où la base de données ne parvient pas à le faire. Vous pouvez évoluer jusqu'à des niveaux spectaculaires. Vous pouvez gérer une énorme quantité de charges de transactions et vous pouvez ajouter autant de serveurs que vous le souhaitez. Et cela implique NCache API. Vous pouvez simplement ajouter des données dans une paire clé-valeur. La clé est une chaîne et la valeur est un objet autorisé par .NET, vous pouvez mettre en cache vos objets de domaine, collections, ensembles de données, images, tout type de données liées à l'application peut être mis en cache à l'aide de notre modèle de mise en cache d'objets. Et puis cela vous donnerait d'énormes avantages en termes de fonctionnalités, que nous offrons du côté de la mise en cache des données.
Cache fiable et évolutif pour les données spécifiques à ASP.NET
Le cas d'utilisation suivant concerne les applications spécifiques à ASP.NET. Par exemple, ASP.NET et il existe un moyen très simple de démarrer avec NCache. Nous avons trois options ici.
Stockage de sessions ASP.NET
Nous avons un stockage d'état de session ASP.NET. Vous pouvez l'utiliser dans les formulaires Web MVC ou ASP.NET ou toute application Web ASP.NET peut en faire usage. Sans aucun changement de code, vous pouvez stocker vos données de session dans un cache distribué. Et contrairement à la base de données ou au serveur d'état, il ne s'agira pas d'un serveur unique. Il pourrait avoir plusieurs serveurs. Donc, c'est très évolutif, c'est très fiable car nous avons des données de session répliquées sur tous les serveurs et vous en tirez également de très bonnes performances car elles sont en mémoire. Et tout sans aucun changement de code. Et avec NCache, nous avons également un déploiement de session multisite. Vous pourriez avoir deux centres de données, synchroniser vos sessions sans aucun changement de code. Voici donc quelques fonctionnalités étendues que vous pouvez utiliser. En dehors de notre prise en charge de l'état de session pour les applications ASP.NET, cela ne nécessite aucune modification du code.
ASP.NET View State Cache haute performance
La prochaine fonctionnalité à ce sujet est ASP.NET view state, il n'y a pas non plus d'option de changement de code. Pour ceux d'entre vous qui veulent savoir, quel est l'état d'affichage ? L'état d'affichage est la gestion de l'état côté client. Par exemple, si les états d'affichage ne sont appliqués que sur les formulaires Web, l'architecture MVC n'a plus votre état. Pour les formulaires Web ASP.NET, tous les contrôles, tous les boutons ou tous les widgets que vous avez sur vos pages, ceux-ci contribuent à créer l'état d'affichage, qui est renvoyé au navigateur en ce qui concerne notre réponse, l'état d'affichage est réuni pour le paquet de réponse, puis renvoyé au navigateur. Côté navigateur, il n'est jamais vraiment utilisé. Il reste simplement là et lorsque vous republiez, l'état d'affichage accompagne le paquet de requête sur le serveur et c'est à ce moment-là que vous utilisez réellement l'état d'affichage. Ainsi, il est toujours renvoyé au navigateur dans le cadre de la réponse, ramené au serveur dans le cadre de la demande, de sorte que vos paquets de demande et de réponse deviennent plus lourds. Il n'est jamais vraiment utilisé côté navigateur. Il est toujours utilisé côté serveur. Il consomme une grande partie de votre bande passante, en particulier sous une charge de transaction énorme.
Nous avons donc beaucoup de problèmes associés en termes de performances et d'utilisation de la bande passante. Avec NCache vous pouvez stocker vos états d'affichage côté serveur, vous pouvez le conserver côté serveur dans NCache, renvoyez un petit jeton factice au navigateur. Ainsi, vos états d'affichage deviennent plus petits, ce qui améliore vos coûts d'utilisation de la bande passante. Vous économisez beaucoup de bande passante là-dessus. Et puis en même temps, les petits paquets sont plus faciles à traiter. Votre demande et votre réponse, le package devient plus petit, ce qui contribue également à améliorer les performances de votre application. Ainsi, vous obtenez des performances et une réduction des coûts d'utilisation de la bande passante, une fois que vous commencez à utiliser notre ASP.NET view state fournisseur. Et c'est aussi une option sans changement de code pour NCache. Et vous pouvez très facilement l'utiliser dans Microsoft Azure.
Mise en cache de sortie ASP.NET
La troisième fonctionnalité importante ici est le fournisseur de mise en cache de sortie ASP.NET, pour ASP.NET MVC ainsi que pour les fermes Web. Si vous avez un contenu assez statique dans votre application sur quatre pages différentes pour différentes requêtes, au lieu de restituer et de réexécuter toutes ces requêtes, même si vous obtenez les mêmes données en réponse à ces requêtes, il est logique de les mettre en cache et puis utilisez la sortie mise en cache pour les requêtes suivantes. Si vous recevez à nouveau la même demande, ne passez pas par l'exercice et extrayez simplement le contenu du cache de NCache directement. Ainsi, nous vous permettons de stocker des sorties de page ASP.NET entières dans NCache et à utiliser pour les demandes ultérieures. Et ce n'est pas non plus un changement de code car cela permet d'économiser beaucoup de puissance de traitement, beaucoup de temps d'exécution, de nombreux avantages en termes de performances sont obtenus à l'aide de notre fournisseur de cache de sortie ASP.NET.
Ce sont donc trois aspects importants avec lesquels vous pouvez rapidement commencer. Ce sont toutes des options sans changement de code. La configuration peut prendre 10 à 15 minutes, puis vous pourrez commencer à voir tous les avantages dont nous venons de parler. Et dans Microsoft Azure, il n'y a pas vraiment de substitut à ceux-ci. Vous finiriez par utiliser les options par défaut, ce qui signifie que vous conserveriez tout dans le processeur de cette base de données. Et nous avons déjà parlé des problèmes qui y sont associés. Je vous recommande donc vivement de jeter un coup d'œil à ces fonctionnalités pour commencer, puis une fois que votre cas d'utilisation progresse, vous pouvez commencer à utiliser la mise en cache des données de notre application parallèlement. Le troisième cas d'utilisation important de NCache, j'y consacre beaucoup de temps afin de pouvoir transmettre l'importance d'utiliser un cache distribué dans vos architectures d'application. S'il vous plaît laissez-moi savoir s'il y a des questions à ce stade jusqu'à présent.
Partage de données d'exécution évolutif via la messagerie
Maintenant troisième cas d'utilisation important de NCache est que vous pouvez l'utiliser de manière évolutive et très fiable, de manière évolutive pour la plate-forme de partage de données d'exécution avec l'aide de notre support de messagerie. Semblable à la file d'attente MSN et au service de messagerie Java. Nous avons également une plateforme de messagerie. Puisque vous avez déjà des données dans le cache. Par exemple, certaines données sont ajoutées, vous avez des catalogues de produits, un produit est ajouté, mis à jour ou supprimé du cache, vous souhaitez être averti en fonction de cela, vous pourriez avoir notre système de propagation de notification d'événement, qui peut se propager puis notifier utiliser si les données changent dans le cache. Ainsi, il existe des messages au niveau des données, auxquels vous pouvez vous connecter et commencer à utiliser ces messages selon vos besoins, puis il peut également y avoir des messages d'application personnalisés, dans lesquels une application peut communiquer avec d'autres applications à l'aide de notre plate-forme de messagerie. Il s'agit donc d'un partage de données très puissant car une application peut partager des données avec une autre, puis il peut également s'agir d'un partage de messages entre différentes applications utilisant le même système de mise en cache distribué. C'est donc une fonctionnalité très puissante, beaucoup de gens ne la connaissent pas, mais elle est très puissante en termes de capacités qu'elle offre.
S'il vous plaît laissez-moi savoir s'il y a des questions. Voici quelques cas d'utilisation importants de NCache, que je couvrirai rapidement. Une fois que vous envisagez d'utiliser un cache distribué dans Microsoft Azure, il y a un concept très important, très important la scène à faire, je dirais.
Quelles données mettre en cache ?
Quel type de données doit être mis en cache ? Désormais, le cache distribué est généralement destiné aux données les plus facilement accessibles, où vous avez plus de lectures et d'écritures, puis ces données sont lues encore et encore pour les requêtes suivantes. J'ai classé les données en deux catégories différentes. Vous pourriez avoir des données permanentes, qui existent généralement dans la base de données, elles peuvent changer mais la fréquence des changements n'est pas si grande, c'est pourquoi je les ai divisées en données de référence et données transactionnelles. Mais nous avons des données permanentes et puis nous avons des données transitoires. Les données permanentes sont celles qui existent réellement dans la base de données et il est très important de les mettre en cache. Ainsi, vous réduisez vos déplacements coûteux vers les bases de données principales.
Et puis, nous avons des données transitoires qui sont des données temporaires, qui sont de courte longueur, peuvent être valides uniquement pour la portée de l'utilisateur actuel ou uniquement pour la portée du cycle d'application en cours d'ailleurs. Il peut s'agir de configurations utilisateur, de paramètres utilisateur, de sessions utilisateur ASP.NET, de la mise en cache de sortie d'état d'affichage. Il n'appartient généralement pas à la base de données, mais il est logique de le conserver dans le cache en fonction de la rapidité avec laquelle vous en avez besoin et du nombre de fois que vous en avez besoin une fois que vous l'avez mis en cache. Ensuite, ces données peuvent être divisées en d'autres catégories. Par exemple, lorsque les données sont principalement lues, plus de lectures que d'écritures ou un nombre égal de lectures ou d'écritures. Ainsi, la référence correspond à plus de lectures que d'écritures et les transactions sont aussi bien des lectures que des écritures.
Et puis, nous avons des données transitoires qui sont des données temporaires, qui sont de courte longueur, peuvent être valides uniquement pour la portée de l'utilisateur actuel ou uniquement pour la portée du cycle d'application en cours d'ailleurs. Il peut s'agir de configurations utilisateur, de paramètres utilisateur, de sessions utilisateur ASP.NET, de la mise en cache de sortie d'état d'affichage. Il n'appartient généralement pas à la base de données, mais il est logique de le conserver dans le cache en fonction de la rapidité avec laquelle vous en avez besoin et du nombre de fois que vous en avez besoin une fois que vous l'avez mis en cache. Ensuite, ces données peuvent être divisées en d'autres catégories. Par exemple, lorsque les données sont principalement lues, plus de lectures que d'écritures ou un nombre égal de lectures ou d'écritures. Ainsi, la référence correspond à plus de lectures que d'écritures et les transactions sont aussi bien des lectures que des écritures. Ainsi, vous pourriez envisager de mettre en cache toutes vos données de référence, ce sont généralement vos données permanentes qui appartiennent à la base de données. Essayez de le mettre dans le cache distribué et cachez-en autant que vous le pouvez, afin de ne pas revenir aux bases de données. Et vous en tirez la plupart des avantages en termes de performances. Et puis, vous devriez envisager de mettre en cache certaines de vos données de transaction, telles que l'état de session ASP.NET, l'état d'affichage et la mise en cache de sortie, car vous ne voulez pas perdre de performances lors de l'obtention de ces données transitoires ou de données transactionnelles à partir des sources de données principales. . Selon le nombre d'utilisateurs, si vous avez des millions d'utilisateurs connectés, pensez à un scénario où vous allez à la base de données deux fois par utilisateur, vous pourriez voir combien de temps vous passeriez à obtenir ces données à partir d'une source plus lente , à partir de la source de données principale. Obtenir du cache et pour cela, vous devriez certainement envisager de le mettre en cache dans le cache distribué.
Présentation de l'API de mise en cache
Voici à quoi ressemble la mise en cache. C'est une table de hachage comme Interface. Nous avons une clé basée sur une chaîne, puis nous avons un objet comme valeur. L'objet peut être n'importe quel objet de paramètre .NET. Vous pouvez avoir tout ce qui est autorisé par .NET, stocké en tant que cache d'objets. Alors que la clé de chaîne, vous pouvez créer une formation de clé significative. Par exemple, tous les employés avec l'ID d'employé 1000, un employé avec l'ID d'employé 1000 peuvent être stockés avec cette clé ici. Toutes les commandes de cet employé peuvent avoir cette clé, où vous avez les commandes des employés, puis l'ID de cet employé. Il pourrait également y avoir un paramètre d'exécution. Et puis, vous pourriez avoir une requête des employés. Par exemple, vous mettez en cache la requête responsable et l'argument était de trouver le code employés basé sur un titre égal à responsable. Ainsi, vous pouvez obtenir une collection stockée en tant qu'objet unique dans le cache. Donc, ce n'est qu'un exemple de la façon dont la clé de cache peut être formulée, mais vous pouvez proposer n'importe quelle technique de base de clé selon vos besoins. Ce n'est qu'un exemple, utilisez ce qui a le plus de sens pour votre application.
Les gars, s'il vous plaît laissez-moi savoir s'il y a des questions? Je ne vois pas beaucoup de questions aujourd'hui. S'il vous plaît laissez-moi savoir s'il y a des questions jusqu'à présent. Aussi, faites-moi savoir si je vais trop lentement ou trop vite sur une portion spécifique, afin que je puisse lui faire maintenir un rythme. Vous pouvez également me faire part de vos commentaires en utilisant le même onglet de réponse à la question et je passerai même plus de temps sur une fonctionnalité spécifique.
Les gars, s'il vous plaît laissez-moi savoir s'il y a des questions? Je ne vois pas beaucoup de questions aujourd'hui. S'il vous plaît laissez-moi savoir s'il y a des questions jusqu'à présent. Aussi, faites-moi savoir si je vais trop lentement ou trop vite sur une portion spécifique, afin que je puisse lui faire maintenir un rythme. Vous pouvez également me faire part de vos commentaires en utilisant le même onglet de réponse à la question et je passerai même plus de temps sur une fonctionnalité spécifique. D'accord. Il y a une question, qu'en est-il des données spatiales ? D'accord. Pouvons-nous également interroger ce type de données ? Oui. Absolument, nous avons un support d'interrogation très fort, cet objet peut être de n'importe quel type. Alors, laissez-moi vous dire que cela couvre toutes sortes de données que vous prévoyez de mettre en cache. Maintenant, ces données peuvent être interrogées en fonction de différents arguments, en fonction de différents paramètres que vous transmettez. En fait, nous avons un langage de requête objet très puissant, que j'ai prévu ici. Nous avons donc des requêtes parallèles à l'aide du langage de requête objet. Et vous pouvez exécuter des requêtes très flexibles à l'aide de notre langage de requête objet. Par exemple, il y a une question de votre part. Si nous voulons obtenir tous les sites à proximité de l'emplacement actuel, par exemple, oui. tu peux. Par exemple, vous avez toutes les données propagées dans le cache. Vous avez tous les menus, stockés dans le cache séparément en tant qu'objets distincts. À droite? Et puis vous pourriez avoir leurs attributs d'objet, qui peuvent également vous donner des informations de localisation. Ainsi, vous pouvez exécuter une requête qui indique de sélectionner tous les lieux, où le lieu est cet emplacement égal à cela. Ainsi, si les attributs d'objet contiennent ces informations, vous pouvez obtenir tous les enregistrements correspondants à partir du cache de distribution. C'est pourquoi une façon de le faire.
La deuxième façon de procéder consiste à transmettre les informations spatiales ou toutes les informations sur lesquelles vous devez interroger dans le cadre de ces objets sous la forme de balises. Vous stockez vos objets, puis vous stockez des mots-clés supplémentaires, qui sont ici sous forme de balises. Ce sont des identifiants qui identifient, qui font des collections logiques dans le cache. Ainsi, vous pouvez simplement utiliser l'API basée sur les balises, où vous dites obtenir par balise, puis vous obtenez toute la collection qui correspond aux résultats ou vous pouvez même exécuter une requête dans laquelle vous dites sélectionner les lieux où la balise est égale à, et la balise est essentiellement un emplacement que vous avez déjà ajouté, où la balise est égale à un emplacement XYZ et vous obtiendrez tous les enregistrements correspondants en fonction de ce critère. Ce sont donc les deux façons de gérer les requêtes, où vous pouvez ajouter des balises au-dessus de vos objets ou simplement vous fier aux attributs d'objet réels. Et puis exécutez SQL comme des requêtes de recherche sur eux. J'espère que cela répond à vos questions. S'il vous plaît laissez-moi savoir s'il y a plus de questions à ce sujet.
Il y a une autre question. Puis-je définir l'expiration de certains éléments mis en cache en fonction d'événements ? Par exemple, un enregistrement est mis en cache et il expire s'il est mis à jour dans la base de données. Absolument! nous avons deux types d'expirations. Nous avons, le temps est l'expiration et il existe deux types d'expirations, donc si le temps s'écoule, vous pouvez faire expirer des éléments et cette expiration peut également être basée sur la dépendance de la base de données. Par exemple, quelque chose change dans la base de données et cela répondrait à votre question. Par exemple, un enregistrement change dans la base de données, vous aviez un enregistrement dans le cache, qui dépendait de cela, dès que cet enregistrement de base de données change, la base de données peut envoyer une notification d'événement et l'élément dans le cache peut être automatiquement supprimé de l'avant de le cache. Ainsi, il peut être expiré dès qu'il expire dans la base de données. Donc, c'est exactement ce que nous proposons en termes de dépendances de bases de données relationnelles et la dépendance SQL couvrirait cela. J'apprécierais si nous pouvions parcourir rapidement une autre diapositive, puis passer à notre partie de mise en cache d'objets et cela devrait répondre à beaucoup de questions. S'il vous plaît faites le moi savoir, s'il y a d'autres questions sinon, je vais reprendre la présentation à partir du même moment.
Il y a une question. Pouvez-vous afficher un exemple de persistance et récupérer des données à partir du cache d'exemple ? Je vous recommande rapidement de regarder nos échantillons, qui viennent et commencent par NCache et ceux-ci sont également disponibles sur notre site Web. Donc, si je vous amène rapidement à nos échantillons, vous y allez et NCache. Je peux vous guider vers l'échantillon, qui gère cela exactement. Donc, nous avons la synchronisation de la base de données, puis nous avons des dépendances. Donc, ceux-ci devraient. Les poignées de dépendance, la dépendance SQL et la synchronisation de la base de données sont un autre type d'exemple, qui vous aide à gérer le scénario à l'aide de requêtes de lecture et d'écriture. J'espère que cela répondra à votre question. Merci beaucoup.
Il y a une autre question. Pouvons-nous interroger ceci pour trier les données ? Oui. nous avons regroupé par ordre par support. Ainsi, vous pouvez utiliser ces attributs avec la requête. Très bons gars! Merci beaucoup d'avoir envoyé ces questions. J'apprécie vraiment ceux-ci. Merci de les faire venir. Depuis, c'était prévu vers la fin de notre présentation et j'allais déjà les couvrir, mais c'est bien d'avoir toutes les questions qui arrivent, alors s'il vous plaît, continuez à les faire venir. Merci beaucoup.
NCache Architecture
Ensuite, je passerai rapidement à l'architecture. Le cache distribué est très élastique en termes d'ajout ou de suppression de serveurs. Vous pouvez ajouter autant de serveurs que vous le souhaitez. Vous pouvez mettre n'importe quel serveur hors ligne. Il est basé sur le clustering de cache basé sur TCP. C'est notre propre mis en œuvre un protocole de question. Nous n'utilisons aucun cluster tiers ou Windows. Même dans Microsoft Azure, vous vous baseriez simplement sur une adresse IP et un port et NCache s'occuperait du reste. C'est une architecture 100% peer-to-peer. Il n'y a pas de point de défaillance unique, vous pouvez mettre n'importe quel serveur hors ligne et ajouter de nouveaux serveurs et clients n'aurait aucun impact. Vous pouvez appliquer dynamiquement des modifications à un cluster de cache en cours d'exécution. Ensuite, ces configurations sont dynamiques de telle manière que ces serveurs sont en communication constante avec les clients. Tout serveur en panne ou tout nouveau serveur ajouté est immédiatement notifié. Il y a une carte en mémoire, qui est propagée au client et qui est mise à jour chaque fois qu'il y a un changement dans le cache. Ainsi, ces informations d'appartenance au cluster de cartes et la carte d'informations de topologie de cache sont mises à jour dès qu'il y a un changement dans le cluster de cache. Donc, il y a un support de basculement de connexion, à côté de cela si un serveur tombe en panne, les clients l'automatiseraient et les serveurs feraient partir ce serveur et les nœuds survivants deviendraient automatiquement disponibles et les clients se connecteraient automatiquement. Donc, en bref, il n'y aurait pas de perte de données ni de temps d'arrêt d'application en ce qui concerne les applications clientes, puis il existe quatre topologies différentes parmi lesquelles vous pouvez choisir.
Topologies de mise en cache
Le mode actif et passif ou le mode maître ou esclave serait déterminé en fonction des topologies de mise en cache. Comme je l'ai dit, c'est une architecture peer-to-peer. Ainsi, chaque serveur participe indépendamment au cluster de cache. Donc, il n'y a pas de dépendance ou il n'y a pas de concept d'hôte principal comme vous l'aviez dans AppFabric ou il n'y a pas d'actif ou passif ou en termes de configuration ou en termes de gestion de cluster. Chaque serveur est 100% indépendant en termes de configuration, en termes de position dans le cluster de cache. Mais il existe différentes topologies de mise en cache et nous avons des topologies actives et passives, mais celles-ci sont basées sur les données du cache. Si les données sont activement disponibles, nous les appelons actives et si les données ne sont que des sauvegardes, les clients n'y sont pas connectés, nous les appelons passives. Mais ce serveur passif est à nouveau ajouté dans le cache en architecture 100% peer-to-peer.
Il y a une question. Existe-t-il un SDK pour les plates-formes mobiles, Android ou iOS à utiliser NCache dans les applications mobiles natives ? Pour le moment, nous avons .NET ainsi que l'API Java, nous travaillons sur une API reposante, donc, si cela est publié, je suis à peu près sûr que vous pourrez l'utiliser à partir d'applications Android et iOS. S'il vous plaît, envoyez-moi un e-mail à ce sujet, envoyez-moi une demande à ce sujet et je le soumettrai à l'ingénierie et je vous reviendrai rapidement avec les délais à ce sujet également.
Nous avons maintenant quatre topologies de mise en cache différentes.
Cache en miroir
Nous avons mis en miroir, qui est actif/passif. Je vais les parcourir rapidement car ce n'est pas notre ordre du jour aujourd'hui. Je veux me concentrer davantage sur notre partie pratique. Je vais donc vous donner un aperçu des différentes topologies NCache Des offres. Nous avons quatre topologies différentes. Mirrored Cache, c'est un actif-passif à deux nœuds. Vous avez tous les clients connectés actifs, puis nous avons un serveur de sauvegarde ici. Si active tombe en panne, les sauvegardes deviennent automatiquement actives. Et ces clients basculent automatiquement. Ceci est recommandé pour les petites configurations, très bon pour les lectures, très bon pour la droite et c'est aussi très fiable.
Cache répliqué
Ensuite, nous avons Répliqué, c'est un modèle actif-actif. Ainsi, les deux serveurs sont actifs mais les clients sont distribués. Ainsi, si vous avez six rôles Web ou rôles de travail dans Microsoft Azure, à charge équilibrée, certains se connecteront au serveur un et d'autres se connecteront au serveur deux. Et nous avons un modèle de synchronisation ici.
En miroir, nous avions une synchronisation asynchrone, donc les performances de lecture étaient également très rapides. En répliqué, nous avons toujours un modèle de synchronisation. Ainsi, nous avons une copie complète du cache sur chaque serveur et ces serveurs ont les mêmes données et de manière synchronisée toutes les mises à jour sont appliquées sur tous les serveurs. Par exemple, vous mettez à jour l'élément de serveur numéro deux sur le serveur un, il est appliqué sur le serveur deux de manière synchronisée uniquement lorsque cette opération est terminée. Mais les lectures, qui sont appliquées localement sur le serveur auquel le client est connecté. Ainsi, les lectures sont très rapides, très évolutives, les écritures sont très cohérentes, je dirais parce que si vous modifiez quelque chose ici, vous aurez toujours ce changement ici aussi, seule cette opération se terminera. Ainsi, pour une transaction de données fiable pour les mises à jour, pour des performances ultra-rapides, il s'agit d'une très bonne topologie à avoir, si vous perdez le serveur un, ces clients basculeraient vers le serveur deux et si vous perdez le serveur deux, ces clients basculeraient. Ainsi, il n'y a pas de perte de données, pas de rebond d'application.
Cache partitionné
Ensuite, nous avons un cache partitionné, où nous avons des données partitionnées, puis nous avons partitionné avec réplication. Ainsi, nous avons des données partitionnées, où vous pouvez avoir deux serveurs ou plus selon vos besoins et les données sont automatiquement divisées sur tous les serveurs. Certaines données iraient au serveur un et d'autres au serveur deux. Les cartes de distribution des pièces sont déjà au courant, là où les données existent dans le cache, elles identifieraient le serveur et utiliseraient ce serveur pour lire ainsi que pour écrire des données. Plus de serveurs signifie plus de copies de lecture du cache, plus d'écriture, plus de serveurs à partir desquels lire des données, plus de serveurs sur lesquels écrire des données. Ainsi, ces serveurs contribuent aux performances globales, à l'évolutivité globale. Ainsi, plus de serveurs signifient plus d'évolutivité hors du cache. Partitionné n'a pas de sauvegardes.
Cache de Partition-Réplica
Nous avons des partitions avec des répliques, où vous pouvez sauvegarder chaque partition sur un autre serveur dans une partition de réplique passive. Par exemple, la sauvegarde d'un est sur le serveur deux et la sauvegarde du serveur deux sur le serveur un. Ainsi, il n'y a pas de perte de données, si le serveur XNUMX tombe en panne ou si vous devez mettre le serveur hors ligne. Les sauvegardes sont rendues disponibles en une seule fois. Et c'est aussi très linéairement évolutif, en fait, c'est notre topologie la plus évolutive en termes de performances.
Permettez-moi de vous montrer rapidement quelques chiffres de référence pour étayer cela. S'il vous plaît laissez-moi savoir s'il y a des questions? Comme je l'ai dit, je vais rapidement parcourir ces topologies pour gagner du temps ici.
Voici un cache en miroir avec deux nœuds. Répliqué très bien pour les lectures, les écritures ne sont pas si évolutives, mais vous pouvez voir le point ici car il a la nature de synchronisation des mises à jour et de la partition avec les lectures ainsi que l'évolutivité des écritures. Réplicas partitionnés avec lectures et écritures, cela a également des sauvegardes afin que vous obteniez des sauvegardes parallèlement aux performances et à l'évolutivité. Et puis nous avons également des répliques partitionnées avec la réplique de synchronisation.
Cache Client
Il existe également quelques fonctionnalités supplémentaires, par exemple, nous prenons également en charge la mise en cache locale proche du client sans aucun changement de code, vous pouvez également activer la mise en cache côté application. Et ce cache serait synchronisé avec le cache du serveur, principalement recommandé pour le type de données de référence. Donc, si vous avez plus de lectures que d'écritures, vous voudrez peut-être l'activer et cela vous donnera des améliorations de performances ultra-rapides en plus de votre application existante. Il enregistre vos déplacements sur le réseau dans un cache distribué. C'est déjà enregistrer vos trajets vers l'arrière dans des bases de données mais vous pouvez même enregistrer ce trajet là où vous devez traverser le réseau en utilisant un cache client. Il vous suffit de l'éteindre. Et vous pouvez même le faire dans le processus de votre application pour économiser davantage la sérialisation et la communication inter-processus. Et NCache gère toute la synchronisation. Si quelque chose change ici, il est propagé ici ainsi que dans d'autres caches clients et vice versa. C'est une très bonne fonctionnalité pour commencer. J'ai déjà couvert les critères de performance.
Réplication WAN du cache distribué
Ensuite, nous avons également la prise en charge de la réplication WAN dans Microsoft Azure. Par exemple, si vous avez deux centres de données, l'un à New York et l'autre peut-être en Europe, vous pourriez même avoir un transfert de données d'un centre de données à un autre. Vous pouvez avoir un cluster de cache ici et avec l'aide de notre pont, qui est également sauvegardé avec les nœuds actifs-passifs, vous pouvez transférer des données vers le pont, puis le pont peut à son tour les transférer vers le site cible. Cela pourrait être actif-passif pour le scénario DR ou pourrait également être actif-actif.
D'ACCORD. Il y a une question. Puis-je utiliser le cache client dans un système déconnecté qui est constitué d'applications mobiles sans connectivité réseau temporaire ? C'est une très bonne question. La question est de savoir si je peux utiliser le cache client en mode déconnecté. Nous en avons parlé; il s'agissait d'une demande de fonctionnalité par l'un des clients, puis nous en avons longuement discuté. Donc, il y a une exigence spécifique qui vous intéresse. Nous avons déjà des plans, nous en avons déjà discuté, et depuis, nous avons déjà eu une demande similaire à celle-ci. Si vous pouviez simplement m'envoyer un e-mail à ce sujet, je souhaite que le cache client soit utilisé pour mon cas d'utilisation et je souhaite qu'il soit utilisé même en mode déconnecté. Je serai très heureux de transmettre cela à l'ingénierie, car ils en discutent déjà et il se trouve qu'ils fournissent cela. Merci beaucoup.
D'accord. J'attends votre mail dans ce cas. À ce stade, le cache du client marche en combinaison avec le cache du serveur. Si cela tombe en panne, le cache client car il se synchronise avec un cache serveur, donc si cela perdrait également toutes les données. Mais nous prévoyons d'utiliser un mode déconnecté, où même si la connexion au serveur tombe en panne, le cache client reste opérationnel et il met également en file d'attente certaines opérations à effectuer ultérieurement.
Démonstration pratique
Ensuite, je vais rapidement vous montrer une démo pratique. Comment fonctionne le produit réel ? Il nous reste peu de temps, je crois qu'il nous reste dix minutes. Je vais donc rapidement vous donner un aperçu d'Azure. Ce dont vous avez essentiellement besoin pour commencer NCache est que vous planifiez le déploiement pour NCache.
La première chose dont vous avez besoin est de créer un réseau virtuel Azure. Vous venez à Microsoft Azure, créez un réseau virtuel. Vous pouvez simplement utiliser la création rapide ou la création personnalisée, puis, par exemple, si je choisis la création rapide, je peux simplement dire NCache VM. Ce serait un réseau virtuel que j'utiliserai pour NCache et puis je pourrais simplement créer ce réseau virtuel. Vous pouvez simplement fournir des détails spécifiques sur le réseau virtuel selon vos besoins. Ou vous avez peut-être déjà un réseau virtuel dans votre environnement que vous aimeriez utiliser pour NCache déploiements. Donc, c'est notre première étape. J'ai quelques réseaux virtuels qui sont déjà créés. Donc, je peux simplement aller de l'avant et passer à l'étape suivante.
La prochaine étape serait de créer NCache machines virtuelles. Il vous suffit de créer une machine virtuelle qui peut avoir NCache pré-installé, vous pouvez simplement installer NCache prendre notre image de machine virtuelle Microsoft Azure à partir du Azure marketplace c'est pour NCache professional mais si ça t'intéresse NCache enterprise, vous pouvez simplement utiliser le serveur plain image 2012. Installer NCache dessus, puis enregistrez cette image pour une étape ultérieure, puis chargez-la, chaque fois que vous devez générer une nouvelle machine virtuelle pour NCache déploiement du serveur. Ainsi, dans la galerie, je pourrais simplement choisir une image, par exemple, le serveur 2012. Je pourrais choisir la prochaine sur ce juste lui donner un nom. Par exemple, démo 3. Je choisirai un niveau de serveur, puis je pourrais simplement remplir certaines informations si nécessaire.

Il s'agit d'étapes spécifiques à Azure. Donc, je suis sûr que vous seriez familier avec cela. La prochaine chose qui est la plus importante est que si vous voulez créer un nouveau cloud service ou utilisez celui qui est déjà là. Par exemple, si j'utilise le benchmark, il détectera également automatiquement le réseau virtuel. Mais vous pouvez créer vos machines virtuelles pour qu'elles soient présentes à part entière cloud services ainsi pour cela vous pouvez choisir de créer un nouveau cloud service. Mais je vous recommande quand même de choisir un réseau virtuel pour toutes vos machines virtuelles de serveur, puis cela devrait être le même pour toutes les machines virtuelles de serveur pour NCache. Ainsi, vous obtenez plus de performances du système en ce qui concerne la communication de serveur à serveur. Donc, je vais juste choisir cette référence, et sur cette base, je pourrais simplement choisir la suivante.
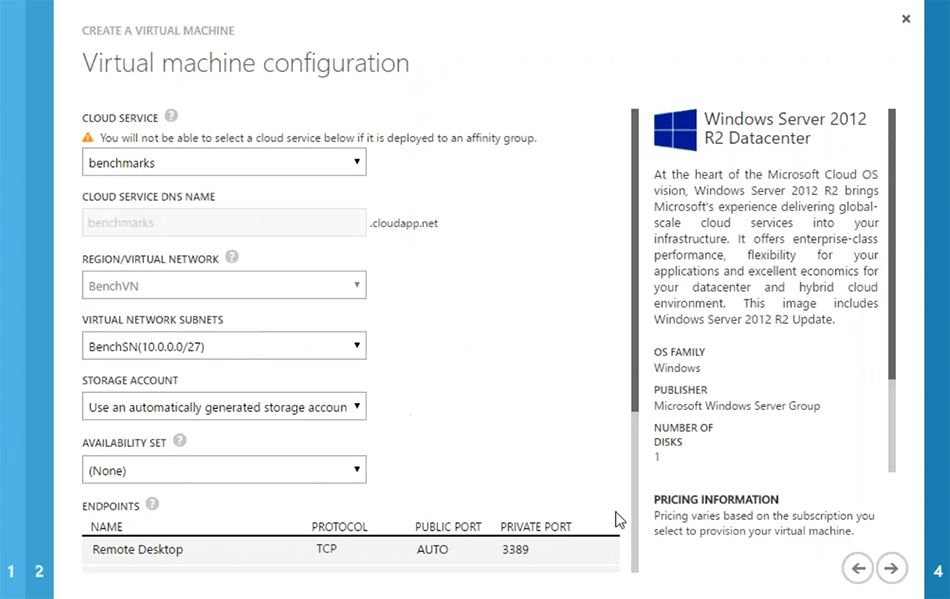
Vous pouvez remplir certains détails spécifiques autour du réseau si nécessaire. Mais dans l'ensemble, c'est tout ce dont j'ai besoin. Donc, je pourrais juste... D'accord. Le serveur cloud que j'ai choisi ne supporte pas ce type de machine virtuelle. Donc, je dois juste choisir de créer un nouveau cloud service avec ça. D'accord. Alors, je dirai juste pour qu'il approuve et voilà. Donc, c'est comme ça que ça se passerait. Je vais juste annuler ça. J'ai déjà ces serveurs ici et en fait, je peux me connecter rapidement sur quelques serveurs que j'ai déjà configurés. Restez avec moi. Laissez-moi vous montrer comment commencer à créer un cache, à le configurer et à le tester rapidement dans votre environnement. Nous avons environ dix minutes. Donc, je veux en profiter pleinement. Et les gars, n'hésitez pas à poster autant de questions que nécessaire. Je réponds toujours aux questions pendant que je prépare l'environnement.
D'accord. J'ai déjà ces serveurs. Je peux me connecter rapidement à ceux-ci. Nous les utilisons déjà pour certains tests, je pense que j'ai foiré le mot de passe ici, veuillez être indulgent avec moi. Voilà! D'ACCORD! Voilà! alors j'ai cette démo 2 ici. Donc, ce sont mes deux boîtes, voilà. D'ACCORD! J'ai donc ces deux boîtes déjà configurées qui font partie du même réseau virtuel dans Microsoft Azure.
Il y a une question. Ai-je nécessairement besoin d'une machine virtuelle ou puis-je utiliser un serveur d'applications Azure ? qu'en est-il du docker ? Nous n'avons pas encore de support Docker. Je peux vérifier avec l'ingénierie s'ils travaillent sur un. En ce qui concerne le modèle de serveur, pour NCache vous devez avoir une machine virtuelle sur Microsoft Azure. L'application virtuelle pourrait être un modèle de service, il pourrait s'agir d'un cloud service, il peut s'agir d'un rôle Web, d'un rôle de travail ou d'une véritable machine virtuelle sur laquelle votre application est déployée. Mais le NCache la partie serveur doit être une machine virtuelle et, comme je l'ai dit, le moyen le plus simple serait de créer une image de machine virtuelle préconfigurée de NCache. Conservez-le dans la galerie, puis chargez-le lorsque vous devez en générer une nouvelle instance. Vous pouvez même choisir la même chose pour la mise à l'échelle automatique, où vous avez les modèles de VM disponibles, NCache installé activé et configuré, vous générez simplement ces nouvelles machines virtuelles, lorsque votre nœud atteint une certaine limite.
Il y a une autre question. Vous avez peut-être déjà mentionné, existe-t-il un cryptage et une compression pour la réduction des données en termes d'utilisation de la bande passante et je crois que vous posez des questions sur le cryptage et la compression. Oui! ces deux fonctionnalités sont disponibles sans aucun changement de code. Vous pouvez crypter vos données pour la transmission de données sensibles, les données peuvent être cryptées, puis les données peuvent également être compressées. Donc, ceux-ci font partie de NCache Support. Merci beaucoup d'avoir posé ces questions. S'il vous plaît laissez-moi savoir s'il y a d'autres questions.
Mise en place d'un environnement
Je veux rapidement vous montrer le produit réel en action. Donc, la prochaine chose que vous devez faire est d'aller sur notre site Web et d'installer NCache soit la version cloud, qui est juste ici, qui est le cloud professionnel, c'est disponible chez Microsoft Azure marketplace également ou téléchargez simplement l'édition Enterprise standard et installez-la sur vos machines virtuelles Microsoft Azure. J'ai déjà fait l'installation d'Enterprise. Donc, la première étape est terminée. Maintenant, la deuxième étape consiste à créer un cache sans nom et pour cela, vous pouvez lancer un NCache outil de gestion qui est installé avec NCache. Ainsi, vous pouvez simplement tout gérer à partir de l'un des VMS selon vos besoins ou vous pouvez simplement le gérer à partir d'un serveur distinct qui a accès à ces serveurs sur le réseau.
Créer un cache en cluster
L'étape suivante consiste à créer un cache nommé. je vais vite le faire. C'est ce qu'on appelle le cache de démonstration.
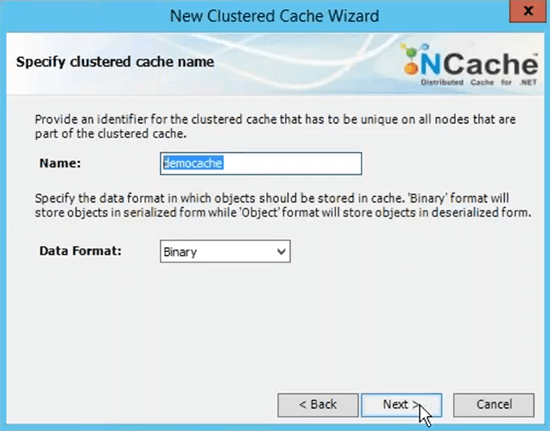
C'est le nom que vous utiliserez pour toutes vos applications clientes afin d'utiliser ce cache. Vous pourrez vous référer à ce nom pour aller de l'avant et récupérer les données du cache. Je choisirai la topologie de cache de réplica partitionné car c'est celle qui est la plus recommandée.
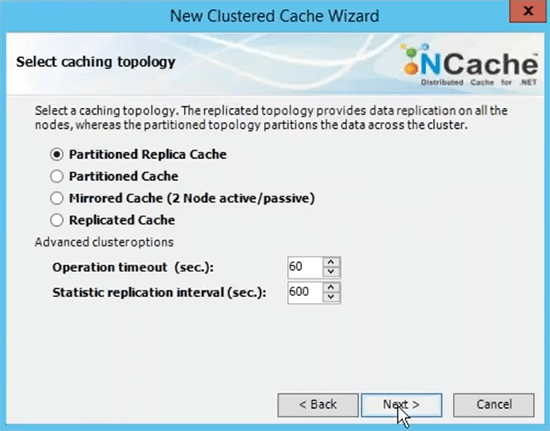
Je vais choisir ensuite sur ce choix Async comme option de réplication car c'est plus rapide. Le serveur 1 et regardez qu'il utilise l'adresse IP privée des serveurs et c'est pourquoi je vous recommande de mesurer le réseau virtuel en termes de déploiement de serveur à serveur. Ainsi, ils sont accessibles sur les adresses IP internes et vous avez une communication très rapide entre les serveurs.
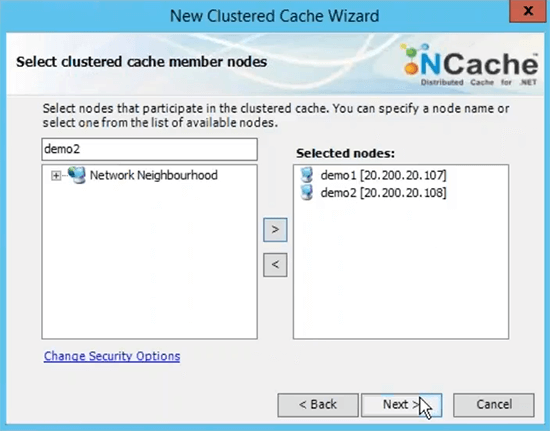
Le port TCP pour la communication par défaut Azure VMS a un pare-feu ouvert. Donc, je vous recommande de l'éteindre ou au moins de frapper NCache ports de communication sur le pare-feu. Et puis la taille du cache par serveur est basée sur la mémoire basée sur les données, que vous prévoyez d'avoir dans le cache. Donc, si vous avez besoin de deux Go de taille de cache, trouvez simplement la bonne quantité de mémoire spécifiée ici. Ceci est juste une limite supérieure, si le cache devient plein, vous avez deux options, vous pouvez soit rejeter les nouvelles mises à jour, ce qui signifie qu'aucune donnée ne peut être ajoutée, vous obtiendrez une exception ou vous pouvez activer les expulsions où vous pouvez simplement spécifier un pourcentage d'expulsion et ces algorithmes peuvent contrôler la quantité d'éléments pouvant être supprimés à l'aide de ces algorithmes afin de faire de la place pour les nouveaux éléments. Ainsi, si votre cache est plein, les expulsions sont activées, certains éléments seront automatiquement supprimés et vous pourrez ajouter d'autres éléments. Je choisis juste de terminer avec le réglage par défaut.
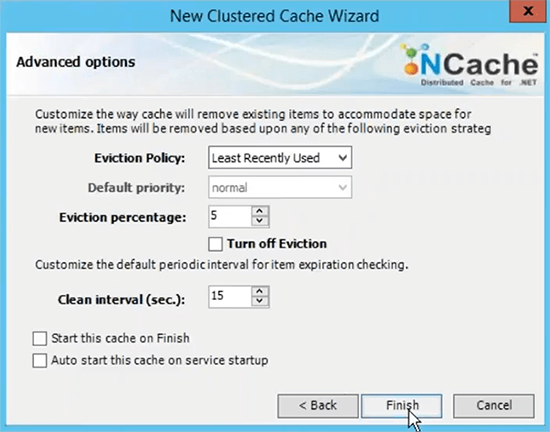
Ensuite, cela termine notre étape 2, où nous avons configuré le cache dans le volet de droite, il y a tous les paramètres liés à ce cache. L'étape 3 consiste à ajouter le nœud client, je pourrais simplement ajouter la démo 3, mais comme nous n'avons que deux serveurs, je vais également ajouter ces deux boîtes en tant que clients. L'étape 4 consiste à démarrer et à tester ce cluster de cache, pour cela je vais simplement cliquer avec le bouton droit de la souris et choisir cela et cela démarrerait ce cache sur tout mon serveur de mise en cache et d'ailleurs ces nœuds clients sont en fait mes rôles Web ou VM, où mon application est déployée.
Donc, c'est pourquoi je vous ai recommandé de tout garder sur le même réseau également. Ainsi, vous pouvez simplement les gérer à partir de NCache Gestionnaire. Et faites un clic droit dans les statistiques, cela ouvrirait les compteurs perf-mon. Le cache a démarré, certains paramètres sont grisés et ne peuvent pas être modifiés pendant l'exécution du cache, mais vous pouvez toujours modifier certains paramètres, tels que vous pouvez activer la compression, cliquer avec le bouton droit et choisir des configurations d'application ferme. Vous demandera d'abord d'enregistrer le projet. Donc, je vais juste faire ça et ensuite appliquer les configurations. Voilà.
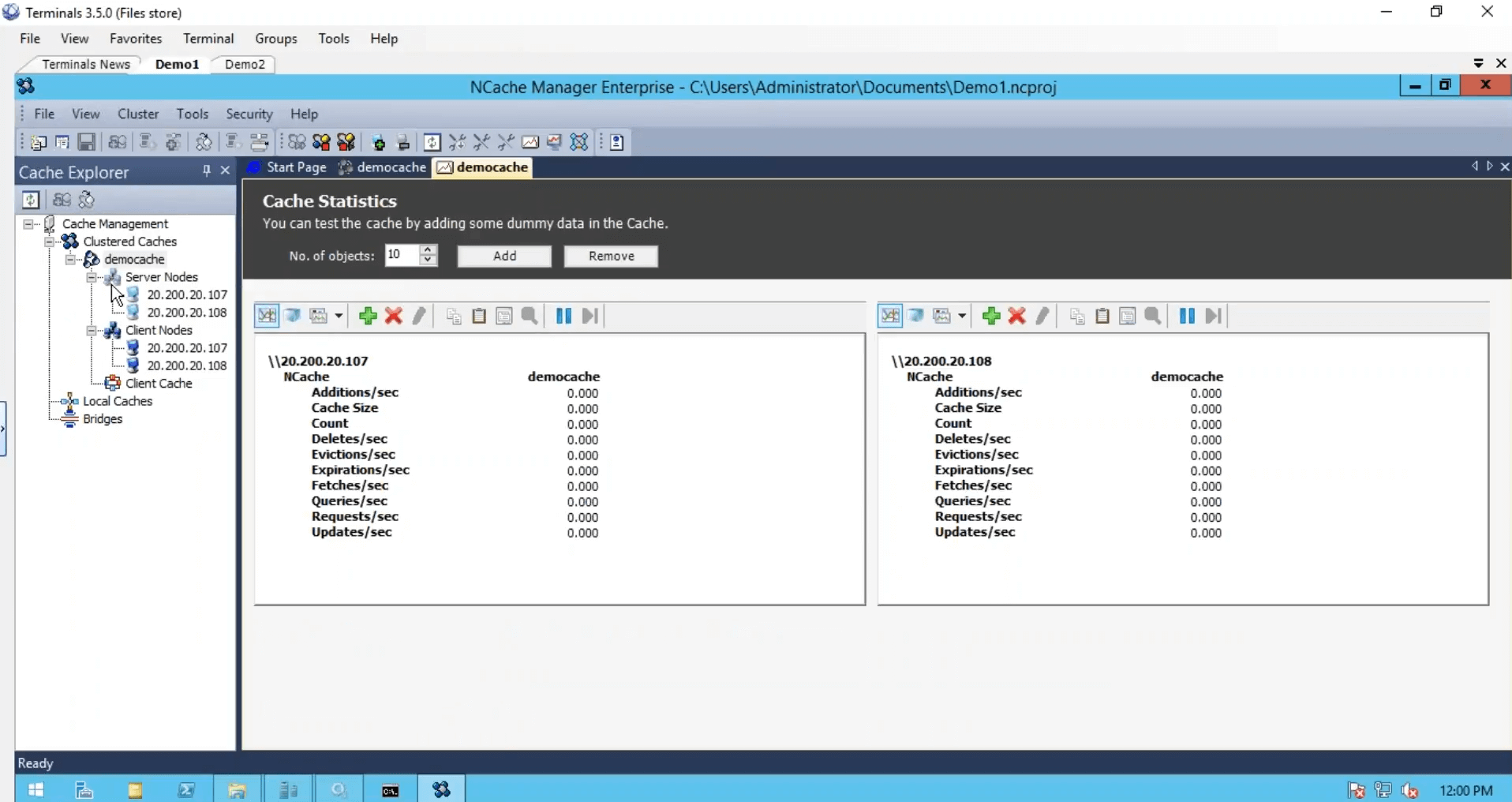
Maintenant que le cache a été configuré, les clients ont été configurés. Nous avons terminé avec trois étapes, nous avons installé NCache.
Simuler le stress et surveiller les statistiques du cache
Nous avons créé le cache, nous avons configuré les clients, nous avons terminé du point de vue de la configuration mais nous avons juste besoin de démarrer et d'exécuter ce cluster de cache et pour cela, je vais juste utiliser un outil de test de stress, qui est installé avec NCache. Et exécutez-le contre mon cache. Donc, que je pouvais voir une activité aussi. Je vais également me connecter à ma deuxième boîte et exécuter également cette application basée sur la console. Donc, cela et avant, j'exécute la deuxième instance en regardant le compteur de demandes par seconde. Nous avons environ un millier de requêtes par seconde générées par une instance d'outil de test de résistance.
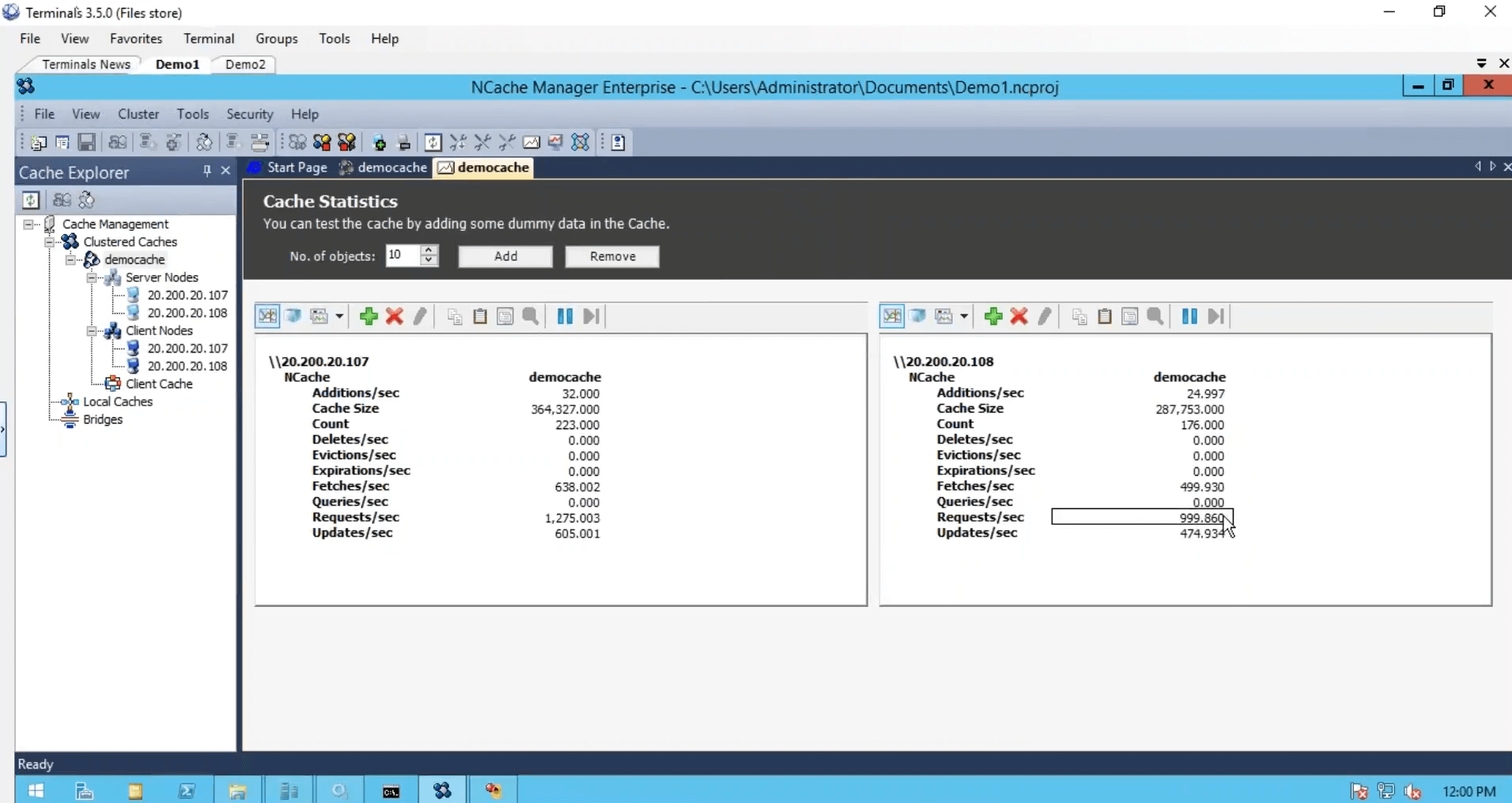
Sur le deuxième serveur, je vais juste exécuter ceci. Donc, nous avons un peu plus de charge et nous remarquons que le compteur de demandes par seconde a presque doublé. Deux mille requêtes par seconde.
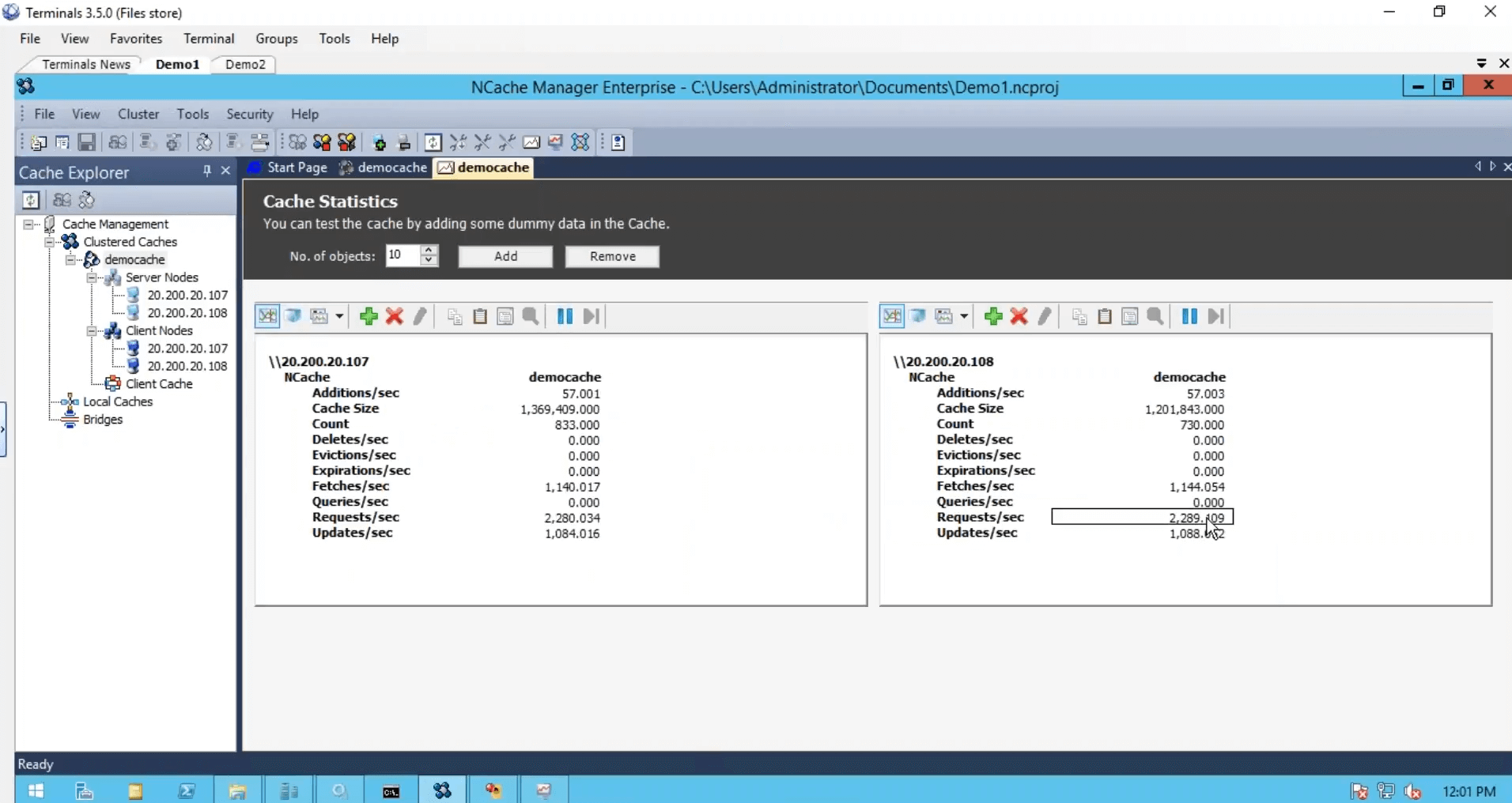
Bien que j'ai exécuté une instance à partir de cette boîte, elle utilisait toujours les deux serveurs. J'ai exécuté une autre instance où l'application utilisait également les deux serveurs en combinaison l'un avec l'autre, puis nous avons cet outil de surveillance, qui nous donne la santé, le processeur, la demande, la taille, le réseau et différentes matrices du côté serveur comme avec nous du côté client.
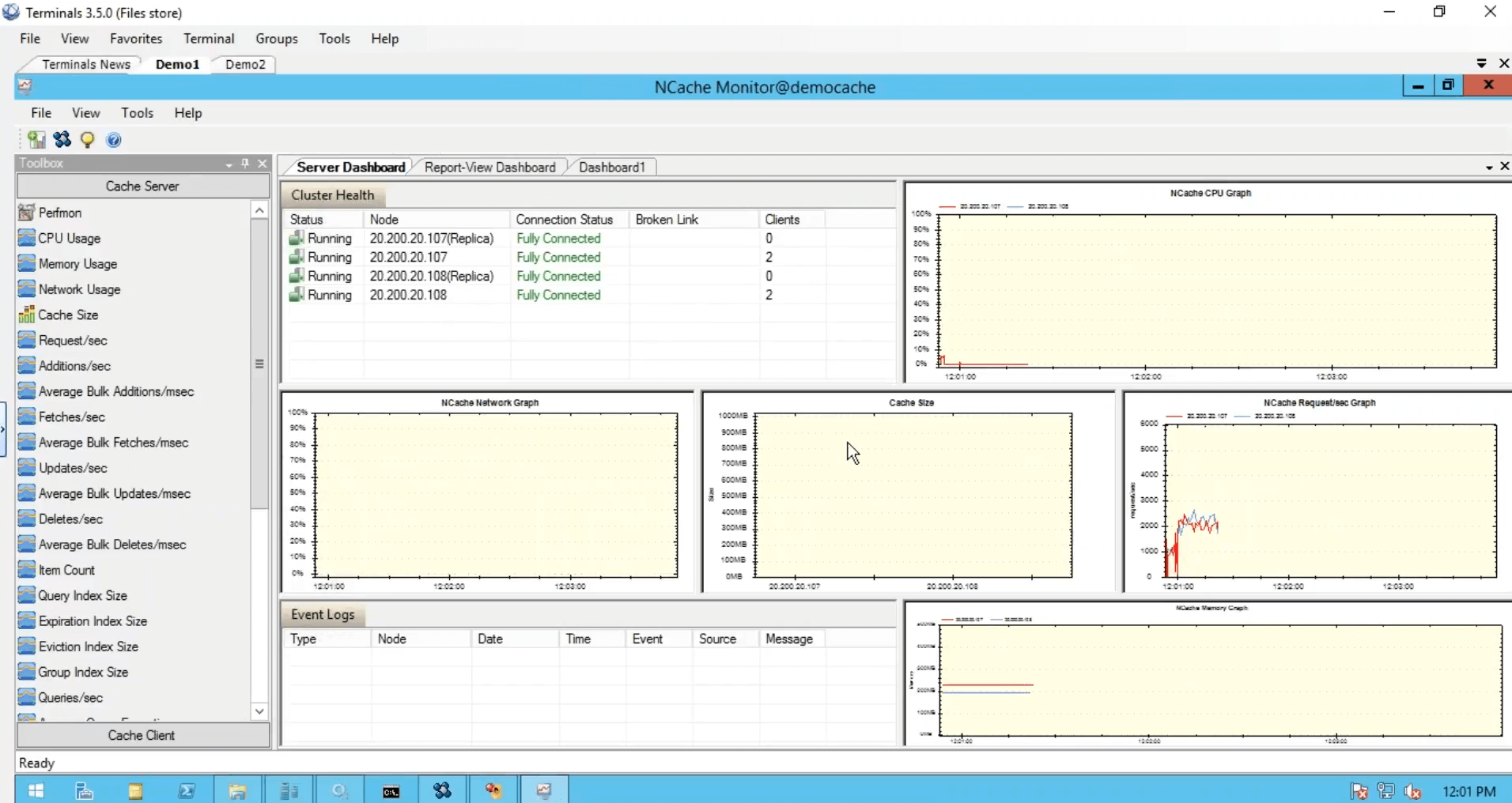
Et vous pouvez également créer vos propres tableaux de bord comme je l'ai fait ici. Je suis désolé les gars à cause des contraintes de temps, j'ai dû être un peu rapide vers cela, mais c'était cinq étapes simples pour commencer NCache. Notre cache est opérationnel.
Utilisez NCache Échantillons
La prochaine chose est d'utiliser le cache dans vos applications réelles et pour cela, vous pouvez simplement vous référer rapidement à notre NCache échantillons. Par exemple, si vous souhaitez utiliser des opérations de base, voici l'exemple. Si vous souhaitez utiliser l'état de session, vous pouvez utiliser cette application d'état de session ASP.NET. Nous avons également des exemples d'état d'affichage et de mise en cache de sortie disponibles dans cette liste. Alors, profitez-en et reportez-vous à ceci pour utiliser NCache dans les applications réelles.
Il y a une question. Puis-je configurer deux niveaux de cache, un plus grand égal à 200 Go sur un état persistant et un plus petit égal à 1 Go plus volatil en mémoire, et avoir une mémoire de niveau 1 synchronisée avec un sous-ensemble d'objets de mémoire couramment référencés à partir du cache de niveau 2 ? C'est possible. Vous avez deux questions. La première question est de savoir si vous pouvez créer deux caches différents avec deux mémoires différentes. Oui. Vous pouvez, la plupart de nos clients créer un cache pour les données statiques et un autre cache pour les données dynamiques. Donc, c'est quelque chose que vous pouvez faire et vous pouvez créer des configurations complètement différentes pour ces deux caches.
La question suivante est, est-il possible de synchroniser les données entre ces deux caches ? Oui. Tu peux. Il y a cette dépendance de synchronisation du cache. Cette fonctionnalité est disponible en privé, mais je peux partager quelques détails sur la façon de les implémenter et vous pourriez également avoir une dépendance de synchronisation entre deux caches différents. Cette même fonctionnalité est ce que nous utilisons des caches en nature partout où nous avons un cache client, qui est un cache et il est synchronisé avec le cache en cluster configuré sur d'autres serveurs. Donc oui. Pour répondre à votre question, oui, vous pouvez avoir deux caches différents et vous pouvez également avoir une synchronisation entre les données de ces deux caches.
Je vais vous résumer rapidement, il y a beaucoup d'augmentations de cache d'objets dont vous pouvez profiter, celles-ci font partie de NCache prise en charge de la mise en cache des objets, puis nous avons déjà couvert l'état d'affichage de la session ASP.NET. Il existe également des intégrations tierces. Donc, c'est essentiellement la fin de notre webinaire. Je m'excuse d'avoir parcouru quelques éléments en raison de contraintes de temps, mais pour réitérer, nous avons couvert quelques détails de base sur les problèmes d'incapacité, parlé de la mise en cache de distribution en mémoire dans la solution, parlé du déploiement dans Microsoft Azure, différents cas d'utilisation , prise en charge du clustering, prise en charge de la topologie dans NCache. Nous avons eu une démonstration pratique spécifique sur la façon de démarrer dans Microsoft Azure en ce qui concerne NCache va.
S'il vous plaît laissez-moi savoir, comment avez-vous aimé la présentation? Comment avez-vous aimé le produit en général ? Donnez-moi votre avis à ce sujet. Il y a certaines choses que vous pouvez faire vers la fin. Vous pouvez aller sur notre site Web et vous pouvez télécharger un essai de 30 jours de NCache. Vous pouvez également choisir notre édition cloud, qui est NCache professional cloud, il est disponible sur Microsoft Azure. Nous avons aussi un client. Ensuite, vous pouvez même utiliser vos machines virtuelles Azure pour aller avec le produit Enterprise Edition si vous en avez besoin. Vous pouvez entrer en contact avec notre équipe d'assistance en vous rendant sur la page d'assistance. Il y a quelques coordonnées que vous pouvez contacter avec le support à support@alachisoft.com.Vous pouvez demander une démonstration du produit si nécessaire et vous pouvez également contacter notre équipe commerciale pour obtenir des informations sur les prix. Donc, nous sommes déjà à notre marqueur d'une heure donc je pense qu'il est temps de dire au revoir. S'il vous plaît laissez-moi savoir s'il y a des questions même après cette démo. Vous pouvez me contacter par e-mail ou par téléphone et je serai très heureux de répondre à toutes vos questions. Merci beaucoup les gars. Ce fut un plaisir de présenter NCache webinaire aujourd'hui. S'il vous plaît laissez-moi savoir comment avez-vous aimé le produit, comment avez-vous aimé la présentation et nous pouvons toujours le prendre à partir de là. Merci beaucoup pour votre temps, tout le monde.