Scale .NET Apps in Microsoft Azure with Distributed Cache
Recorded webinar
By Ron Hussain
Learn what are the scalability bottlenecks for your .NET apps in Microsoft Azure and how you can improve their scalability with distributed caching.
This webinar covers:
- Quick overview of performance bottlenecks in .NET applications
- What is distributed caching and why is it the answer in Azure?
- Where in your application can you use distributed caching?
- What are some important features in a distributed cache?
- Some hands on examples of using a distributed cache in Azure
Thank you very much for joining. Let me quickly educate you about the webinar. First of all, my name is Ron Hussain. I am one of the technical experts at Alachisoft and I’ll be your presenter for today's webinar. I'll cover all the technical details, that you need in order to scale out your .NET applications in Microsoft Azure with the help of an in-memory distributed caching system and I'll be using NCache as an example product for this. That's our main product for distributed caching. We're the proud maker of NCache and I'll be using that as an example product. More of this webinar is going to be listen-only, which means I'll be doing most of the talking but you can always Participate. You can ask as many questions as you need to. On the right side of your screen, there is this questions and answer tab. If you expand on the questions tab, you can post as many questions as you need to, and as I said, I'll keep an eye on this and I will answer all the questions that you guys would post in this window. So, just for the sake of confirmation, if you can confirm using the same questions and answer tab please confirm if you can see my screen and if you can hear me fine. I can quickly get started. Okay. I can already see some questions being Posted. So, thank you very much for the confirmation.
Let's get started with this. Hi everybody, my name is Ron Hussain like I said, I'm one of the technical experts at Alachisoft and I'll be your presenter for today's webinar. The topic that we have chosen today is scaling out .NET Applications in Microsoft Azure with the help of an in-memory distributed caching system. At Alachisoft we have various products and the most popular one is NCache, which is an in-memory distributed caching system for .NET and Java applications. NCache will be the main product, which I'll be using as an example but I'll stick to the basics of Microsoft Azure. How to use NCache (A Distributed Caching System) in Microsoft Azure and take advantage of it in terms of scalability, in terms of application performance, and overall system reliability into your architecture. So, since you've confirmed that you can see my screen, let me get started with this.
What is Scalability?
Okay! before I actually move on to the actual topic. I'll talk about some basic concepts and I'll start off with what is scalability? Scalability is the ability to increase the transactional load on the applications and at the same time you don't slow down your applications. For example, at this point, if you're handling 1,000 requests, if your application load grows more users log in and then start using your applications more heavily than load, for example, it grows from 1,000 to 10,000 requests per second. Now you want to accommodate that increased load, you want to handle that increased load and at the same time, you don't want to slow down your individual request performance. It should not happen in such a way that one request is waiting to be complete and one request is in the process of completion other requests are waiting for that. Those requests should be handled exactly at the same amount of time that they were previously taking. But at the same time, you want that scalability, that ability where you could handle more and more requests load 10,000 requests per second or 20,000 requests per second. So, without losing the performance, if you have the ability to increase your transactional load on your applications, that's what we would call Scalability. And that's what we'll focus on today.
What is Linear Scalability?
There's an associated term called unlimited scalability. It's linear scalability. Linear scalability is having linear growth in your reads and writes per second capacity. For example, if you add more servers. So, now that you add one server, you have a certain ability of handling requests for reads and writes operations. What if you add another server and then you add more servers? The ability where you could add more servers and by adding more servers, you grow your scalability numbers, you get more and more capacity handles by your application architecture, that's what we refer to as linear scalability.
Which Applications Need Scalability?
Now! The next question would be, what sort of applications would need scalability. The answer is very simple. Any application which may have to handle millions of requests from the users. If it's dealing with a huge transaction load. Typically, we have ASP.NET applications. If there are front-end, for example, an e-commerce application, an airline booking application maybe, anything which is public-facing but it has a lot of traffic, that application is the prime candidate for scalability.
Then, we could have WCF for .NET web services and service-oriented architecture. It could be back in or it could be front-end web services, maybe consumed by your web applications or by internal applications that you may have. Those may have to process a huge amount of requests, a huge amount of data needs to be fetched and delivered to the caller programs. So, these sorts of applications also need scalability. And then you might want to put some kind of infrastructure, which could handle the amount of request load.
Then, we have big data applications. This is a common buzzword these days. A lot of applications, a lot of architectures are moving towards it, where you may have to process huge amounts of data to distribution on different modules, different processes but towards the end, you would be dealing with a lot of data, a lot of requests, in order to process this.
And then we have great computing applications, where you may have to process a huge amount of computations through distribution on multiple inexpensive servers, those are the applications. So, in general, any .NET application or Java application for that matter, which may have to handle a million requests from the users or from the back-end programs, are the prime candidates which need to have scalability in the architecture.
And, we'll focus on some of these once, we move on to our use cases as well. And, guys we're just at the beginning of this webinar, for those of you who just joined, I'm just going to cover some basic concepts in terms of distributed caching. I'll talk about different problems that you would face and then solutions and also talk about the deployment of a distributed cache, such as NCache in Microsoft Azure. So, if there are any questions please feel free to type into the questions and answers tab. And you can always give me your feedback as well. If you want to participate, you can again use the same question and answer tab.
What is the Scalability Problem?
Now next thing, once we define that we have, what is scalability? What is linear scalability and what sort of applications need scalability? The next and then the most important point of this webinar, what sort of applications or what sort of scalability problems, your applications would face? Where exactly is the scalability problem?
Now, your application architecture, it could be an ASP.NET application or WCF service, these scale-out very nicely and these scale of linearly already. You can put a load balancer in front and you can simply add more and more app servers or web servers, web front end servers and you get linear scalability out of your architecture already. So, there's no issue over there. The actual issue in regards to data storage, these application servers or web servers, they would always talk to some back-end data sources, such as databases state service or it could be any back-end file system or legacy data source for that matter. Which cannot handle huge transaction load and you don't have the ability to add more and more servers at that here. And this diagram nicely explains this.
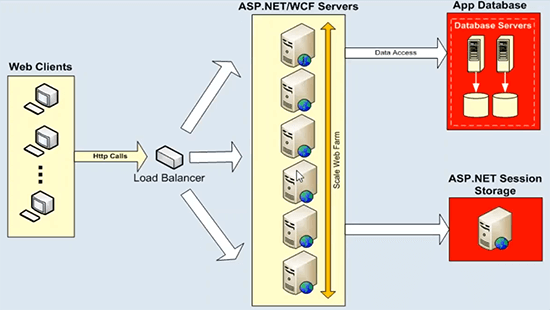
Where we have data storage has a scalability bottleneck. We have ASP.NET WCF example right here, but you can add as many servers as you want, you start out with two servers, if your load grows you can add another server, put a load balancer in front and then evenly use all the resources on this layer. So, there are no issues. But these application boxes or web front-end servers would always talk to some back-end data sources. And this is a typical deployment, where we have database servers, which are not that fast to start off, and then they have scalability issues. They would choke down under huge transaction load and then in some cases, they are also a single point of failure. But most importantly, these database servers in any application architecture, pose a very serious threat and that's a scalability bottleneck. So, you would lose all the scalability, that you achieve on this tier once you target all your requests back to some database servers. And same is the case for the ASP.NET session state. If you use a SQL Server or session state server for that is because it stays over that. It's always going to be a single server hosting all your session data and the session is a very transactional kind of data and then you need a very scalable data source to handle those requests. So, that's the main challenge that we are trying to address with the help of a distributed caching system.
The Solution: In-Memory Distributed Cache
The solution is very simple, like I said, you could use a scalable in-memory distributed caching system. Such as NCache to handle all the issues, that we've just talked about associated with data sources in regards to scalability.
The next thing, I'm quickly going to do is talk about some basics of the in-memory distributed caching system such as NCache. There are some important characteristics, that you would find in NCache and I expect that this would be part of most of our in-memory distributed caching systems, which are available. So, in this regard, so NCache if I have to define, what would be an in-memory caching system?
Dynamic Clustering
It is a cluster of multiple inexpensive cache servers, which are joined together, you can pull their memory as well as CPU capacity. So, they're joined together into a capacity and you're pulling their memory as well as CPU resources. So, physically it could be multiple servers, which are not that expensive once a web, simple web server configuration box would do, that's something that you could use for caching, and then those servers join together and formal logical capacity. So, from your application standpoint, you're just using one distributed cache but physically, it could have multiple servers working behind the scenes, pulling all the computational power and memory to come up with this in-memory distributed cache. So, that's the first and the most important characteristic that it's not this single server. It would have multiple servers working in combination with one another. So, we're already ahead of the database, where we would just have one server hosting all the data and handling all the requests.
Data Consistency
The next characteristic and this is in regards to data consistency since we're dealing with multiple servers behind the scenes, the next question would be, how would we handle updates. For example, the same data gets updated on one or two servers or if there are replicas or there are multiple copies of data on different servers. So, regardless of what topology you use, the data should be updated in a consistent manner. So, once you update anything on any cache server, all updates should be visible to all the caching servers on the distributed cache. And by the way, I'm using some visible, I'm not using the term replication. Replication is another feature. So, by visible I mean that for example, you get a request handle by server one, that data is updated. If the next request goes to server two, if you had the same data on server two as well, you should get the updated value not the stale value from the distributed cache.
So, this is a very important characteristic in terms of distributed cache, where all your data updates should be consistently applied on all caching servers. And this should be the responsibility of the distributed cache, not your application. The architecture should support this model.
Linear Scalability
The next thing, which aligns with our topic today, is that how to linearly scale. So, the distributed cache should linearly scale-out for transactional as well as for memory capacity. It should give you away, where you can add more and more caching servers and as you had more caching servers, you attain linear scalability. I had shown you a graph earlier on. So, that's what I'm referring to over here, where you add more and more servers, you should increase the capacity of how many requesters you can handle and at the same time, how many data, how much data can be stored in the distributed cache linearly. So, that's a very important characteristic, which gives you linear scalability out of distributed cache and that makes your overall application architecture very scalable.
Data Replication for Reliability
Fourth important characteristic. This is option one, you can choose a topology, which also supports replication. You have a distributed cache, which replicates data across servers for reliability. If any server goes down or you need to take it offline for maintenance, you should not be worried about having any data loss or application down. So, these are some important characteristics of distributed cache. I will cover these in more and more detail in the coming slides and then we'll also talk about Azure-specific deployment of a distributed cache. How to use the distributed cache in Microsoft Azure? Please let me know if there are any questions so far. Please use the questions and answers tab matter. I see some raised hands generally, go-to-meeting has this issue, where it shows a lot of raised hands but please let me know if they’re actually any questions. Please type into the questions and answer tab and I'll be very happy to answer those for you. I think we should continue.
Here is the typical deployment of a distributed cache. This is a general deployment, it's not specific to Microsoft Azure.
NCache Deployment in Microsoft Azure
I'll move to the deployment of NCache in Microsoft Azure right after this. So, typically it could be on-premise or it could be cloud, they're not a lot of things that will change as far as the deployment of NCache goes. This is how you would typically deploy NCache, where you would have a dedicated layer of caching.
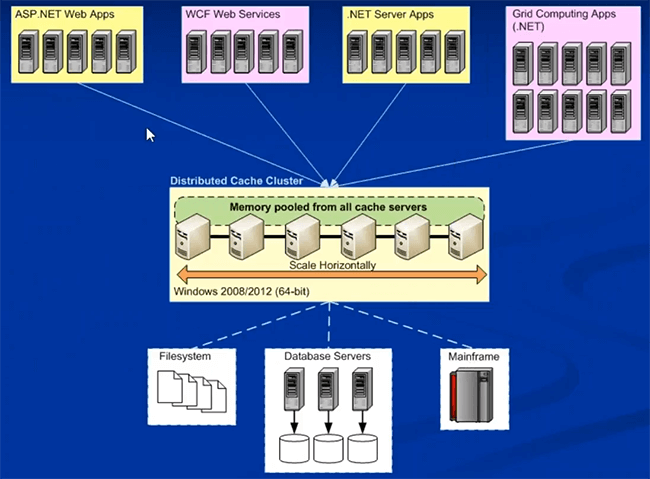
These could be physical boxes on-premise, these could be hosted boxes VMs, or these could be actual cloud VMs as well, where you just get a VM from the cloud and then use that for caching. You can formulate a cache on separate dedicated caching boxes, that's recommended one. A preferred platform is 64-bit and the only prerequisite for NCache is .NET 4.0. And then your applications, these could also be on-premise or hosted. These could be deployed directly on the servers in IIS or these could be web or worker roles, in regards to Microsoft Azure. They can all connect to this caching tier for the data requirements. You could have separate installation for these, separate layer for these, or you will just have everything on the same layer as well. Both models are supported. But once you introduce NCache into your application architecture, once it's deployed for object caching or for session caching, I'll cover NCache use cases once we move towards use cases.
Once you start using NCache, it saves your expensive trips through the back and databases. And then it gives you a very scalable platform right here, where you can add as many servers as you want and you can scale up. Now compare this with the diagram that I showed you earlier.
You had a very scalable platform right here, but this was the main source of contention. The main source of scalability bottleneck. Now, if you compare this, now you have a very scalable platform in between your application layer and database. This is a very scalable platform and again now you have a data source in terms of distributed cache, which is again very scalable. You can add as many servers as you want. If your load grows, you don't have to worry about back-end data sources being choked at that time. You can add as many servers as you want and you can linearly grow your request handling capacity out of NCache. Let me know if there are any questions on the deployment architecture of NCache but overall, it is very straightforward.
Now, the next thing is how to deploy NCache in Microsoft Azure. So, that I'll be using our website. I'll use a diagram from there, so, please bear with me. Deployment in Microsoft Azure is not that different from what we have on on-premise.
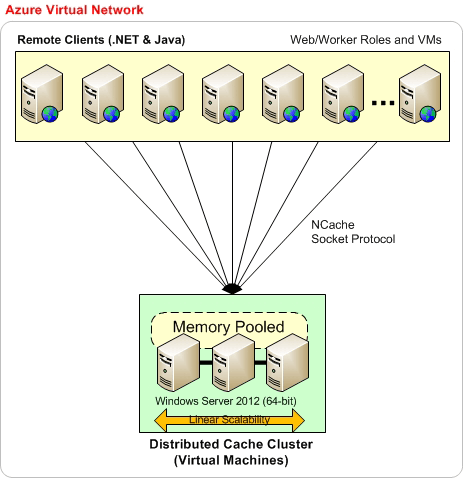
So, first of all, it's recommended that this is the basic deployment, where you have everything on the same Microsoft Azure virtual network. For example, you create a virtual network and then you have Microsoft Azure virtual machines, server-side deployment is always going to be on VMs. So, that's the model that we've chosen for NCache in Microsoft Azure. You create a VM or in choosing the same virtual network you create all your VM deployments. For example, you can start out with three VMS as shown here and then you can have as many VMs added onto this caching layer as needed. Preferably we also want your applications to be on the same Azure virtual network. So, everything can be part of the same virtual network that's when you get most of the performance and then stability benefits out of NCache. When there are no hard requirements on this, you could always have applications deployed on different VMs.
So, based on this model, your application architecture can be on VM themselves, which means your application can be deployed directly on IIS which you manage yourself and then, take full charge of it or it could be myself Azure web role or worker roles both models are supported on the application side but NCache server-side deployment is always going to be on the VMs. So, that's how you would apply NCache and I'll actually show you once we move on to our hands-on portion.
Another kind of deployment is that you could have one specific Azure virtual network for your NCache server VMs, where all your servers are part of the same virtual network. Preferably same subnet as well. And then your applications could be on a separate virtual network as well. In that case, you would have to have some kind of ports forwarded on the NCache virtual network. For example, private ports are mapped onto the public port here and then your applications use this public port to actually get connected to NCache. You may have to perform some extra configurations here, but we have a detailed help document available for that, but it works without any issues. You could have this virtual network server accessing caching servers from another virtual network. And you could even have the cache-to-cache applications with the help of the same feature.
So, this is another kind of deployment but the preferred approach, the recommended one, is that you have all your cache servers as well as application servers deployed on the same Microsoft Azure virtual network. That's when you would get the most benefits out of NCache. Please let me know if there are any questions.
We have an Azure deployment guide available on our website as well if I could take you to support. Actually, let me go to the documentation here. On the documentation, we have a specific guide, a deployment guide that covers all these details in great detail.
Okay. There's a Question. How is NCache different from Redis? Okay. Today's agenda is more of using NCache or using a distributed caching system in Microsoft Azure. We have a separate webinar on Redis versus NCache. Where we talk about different features that are available in NCache and then not part of Redis. For a quick answer on this, I would recommend that you go to our comparisons page right here, and then you have a Redis versus NCache. You can quickly sign up for this and then you should be able to see all the features, feature by feature comparison of NCache versus Redis. And as a matter of fact, we also have a webinar just for this, which is a webinar on our YouTube channel. So, if you just log into YouTube, look for Alachisoft and then under Alachisoft there will be a lot of videos and one of those videos would have Redis sources NCache title. There's a separate webinar on that. I hope this answers your question. There are more questions on this. Okay. coming back to, since we've covered deployment, please let me know if there are any deployment-related questions and I'll be very happy to answer those questions for You.
Common Uses of Distributed Cache
Next thing is how to use distributed cache? What are the common areas, where you would use a distributed caching system like NCache? I have just listed down three of the most common ones but these could be specific to the industry, this could be specific to your requirements, use cases, it could be different ways you could use NCache. But primarily these are divided into these three categories.
Application Data Caching
The first category is application data caching. You can use a distributed caching system like NCache as an application data caching. Anything which previously was present in the database and your applications were going to the databases, now you can put that in NCache. And you can get an in-memory faster cache in comparison to the database for accessing all the data that you previously had in the database. So, you improve your application performance, and then most importantly you linearly scale out where the database fails to do so. You can scale out to some dramatic levels. You can handle a huge amount of transactions loads and you could add as many servers as you want. And this involves NCache API. You could just add data in a key-value pair. Key is a string and value is .NET permitted object, you could cache your domain objects, collections, datasets, images, any sort of application-related data can be cached using our object caching model. And then this would give you some huge benefits in terms of features, that we're offering on the data caching side.
Reliable & Scalable Cache for ASP.NET Specific Data
The next use case is around ASP.NET specific applications. For example, ASP.NET and there's a very easy way to get started with NCache. We have three options here.
ASP.NET Session Storage
We have ASP.NET session state storage. You could use it in MVC or ASP.NET webforms or any ASP.NET web application can make use of this. Without any code changes, you can have your session data stored in a distributed cache. And unlike database or state server, it's not going to be a single server. It could have multiple servers. So, it's very scalable, it's very reliable because we have session data replicated across servers and you get very good performance out of it as well because it's in memory. And everything without any code changes. And with NCache, we have a multi-site session deployment as well. You could have two data centers, sync your sessions without any code changes. So, these are some extended features that you can make use of. Out of our session state support for ASP.NET applications and this does not require any code changes.
ASP.NET View State Caching
The next feature on this is ASP.NET view state, that's also no code change option. For those of you who want to know, what view state is? View state is client-side state management. For example, if view states are only applied on web forms, MVC architecture does not have your state anymore. For ASP.NET webforms, all the controls all the buttons or all the widgets that you have on your pages, those contribute towards creating View state, which is sent back to the browser in regards to our response, the view state is joined together to the response packet and then sent back to the browser. On the browser side, it's never really used. It just stays there and when you post back the view state comes along with the request packet on the server and that's when you actually use the view state. So, it's always sent back to the browser as part of the response, brought back to the server as part of the request, so, your request and response packets become heavier. It's never really used in the browser side. It's always used on the server-side. It eats up a lot of your bandwidth specifically under huge transaction load.
So, we have a lot of issues associated with it in terms of performance and in terms of bandwidth utilization. With NCache you can store your view states on the server-side, you could keep it on the server side in NCache, send a small dummy token back to the browser. So, your view states become smaller in size, improve your bandwidth utilization costs. You save a lot of bandwidth on that. And then at the same time, smaller packets are easier to process. Your request and response the package becomes smaller and then that also contributes towards improving the performance of your application. So, you get performance and reduction in bandwidth utilization cost, once you start using our ASP.NET view state provider. And this is also a no code change option for NCache. And you can very easily use it in Microsoft Azure.
ASP.NET Output Caching
The third important feature here is the ASP.NET output caching provider, for ASP.NET MVC as well as for web farms. If you have fairly static content within your application on four different pages for different requests, instead of re-rending and re-executing all those requests, even though you get the same data in response to those requests, it makes sense to cache them and then use the cached output for subsequent requests. If you get the same request again, don't go through the drill and then simply get the cache content out of NCache directly. So, we allow you to store entire ASP.NET page outputs in NCache and to be used for subsequent requests. And this is also no code change because it saves a lot of processing power, a lot of execution time, a lot of performance benefits are achieved with the help of our ASP.NET output cache provider.
So, these are three important aspects that you can quickly get started with. These are all no code change options. May take 10-15 minutes to set up and then, you could start seeing all the benefits that we've just discussed. And in Microsoft Azure, there's not really any substitute for these. You would end up using default options, which means that you keep everything in processor in this database. And we've already talked about what are the issues associated with those. So, I would highly recommend that you have a look at these features to start off and then once your use case progresses, you could start using our application data caching alongside. The third important use case of NCache, I'm spending a lot of time on these so that, I am able to convey the significance of using a distributed cache in your application architectures. Please let me know if there are any questions at this point so far.
Scalable Runtime Data Sharing Thru Messaging
Now third important use case of NCache is that you could use it in a scalable and in a very reliable, in scalable manner for runtime data-sharing platform with the help of our messaging support. Similar to MSN queue and Java messaging service. We also have a messaging platform. Since you already have data in the cache. For example, some data gets added, you have some product catalogues, a product gets added, updated, or removed from the cache, you want to get notified based on that you could have our event notification propagation system, which can propagate and then notify use if data changes in the cache. So, there are data level messages, that you can hook on to and start using those messages as needed, and then there could be some custom application messages as well, where one application can talk to other applications with the help of our messaging platform. So, it's very powerful data sharing because one application can share data with other and then it could also be message sharing between different applications using the same distributed caching system. So, this is a very powerful feature, a lot of people don't know of it but it's very powerful in terms of capability that it offers.
Please let me know there are any questions. These are some important use cases of NCache, which I'll quickly cover. Once you plan on using a distributed cache in Microsoft Azure, there's a very important concept, very important the scene to make I would say.
What Data to Cache?
What sort of data that needs to be cached? Now distributed cache is usually for most readily accessed data, where you have more reads and writes and then that data is read again and again for subsequent requests. I've categorized data in two different categories. You could have permanent data, which usually exists in the database, it may change but the frequency of change is not that great, that's why I have further divided it into reference and transactional data. But we have permanent data and then we have transient data. Permanent data is the one, which really exists in the database and it's very important that you cache it. So, that you reduce your expensive trips to the backend databases.
And then, we have transient data which is temporary data, which is short length, may be valid only for the scope of the current user or only for the scope of the current application cycle for that matter. It could be user configurations, it could be user settings, it could be user ASP.NET sessions, view state output caching. It usually does not belong in the database but it does make sense to keep it in the cache depending upon how soon you need it and how many times you need it once you cache it. Then this data can further be divided into other categories. For example, where the data is mostly read, more reads than writes or an equal number of reads or writes. So, reference is more reads than writes and transactions are reads as well as writes.
And then, we have transient data which is temporary data, which is short length, may be valid only for the scope of the current user or only for the scope of the current application cycle for that matter. It could be user configurations, it could be user settings, it could be user ASP.NET sessions, view state output caching. It usually does not belong in the database but it does make sense to keep it in the cache depending upon how soon you need it and how many times you need it once you cache it. Then this data can further be divided into other categories. For example, where the data is mostly read, more reads than writes or an equal number of reads or writes. So, reference is more reads than writes and transactions are reads as well as writes. So, you could consider caching all your reference data, this is usually your permanent data that belongs in the database. Try bringing it in the distributed cache and cache as much of it as you can, so that you don't go back to the databases. And you get most of the performance benefits that are needed from this. And then, you should consider caching some of your transaction data, such as ASP.NET session state, view state and output caching because you don't want to lose performance on getting this transient data or transactional data from the back-end data sources. Depending upon number of users, if you have millions of users logged in, think of a scenario where you're going to the database two times per user, you could see how much time you would be spending in getting that data from a slower source, from the backend data source. Getting from the cache and for that you should definitely consider caching it in the distributed cache.
Overview of Caching API
This is how caching looks like. It's a hash table like Interface. We have a string-based key and then we have an object as its value. Object could be any .NET parameter object. You could have anything which is permitted by .NET, stored as object cache. Whereas string key, you could come up with a meaningful Key formation. For example, all the employees with employee ID 1000, an employee with employee ID 1000 can be stored with this key right here. All the orders of that employee can have this key, where you have employee orders and then ID of that employee. There could be a runtime parameter as well. And then, you could have employee query. For example, you cache the responsible query and the argument was finding the code employees based on a title equals to manager. So, you could get a collection stored as a single object in the cache. So, this is just an example of how the cache key can be formulated but you can come up with any key foundation technique as needed. It is just an example, use what makes more sense to your application.
Guys, please let me know if there are any questions? I'm not seeing a lot of questions today. Please let me know if there are any questions so far. Also, let me know if I'm going too slow or too fast on a specific portion, so that I can make it maintain a pace. You could also give me your feedback using the same question answer tab and I will spend more time on a specific feature even.
Guys, please let me know if there are any questions? I'm not seeing a lot of questions today. Please let me know if there are any questions so far. Also, let me know if I'm going too slow or too fast on a specific portion, so that I can make it maintain a pace. You could also give me your feedback using the same question answer tab and I will spend more time on a specific feature even. Okay. There's a question, what about spatial data? Okay. Can we query that sort of data as well? Yes. Absolutely, we have a very strong querying support, this object can be of any type. So, let me tell you that the this covers all sort of data that you would plan on caching. Now that data could be queried based on different arguments, based on different parameters that you pass on. As a matter of fact, we have a very strong object query language, which I have planned right here. So, we have parallel queries with the help of object query language. And you could run very flexible queries with the help of our object query language. For example, there's a question from you. If we want to get all the venues near up current Location, for instance, yes. you can. For example, you have all the data propagated in the cache. You have all the menus, stored in the cache separately as separate objects. Right? And then you could have their object attributes, which can give you a location information as well. So, you can run a query which says select all the venues, where venue is that location equals to this. So, if the object attributes have this information you could get all the matching records from the distribute cache. That's why one way of doing it.
The second way of doing it is that, you pass on the spatial information or all the information that you need to query on as part of those objects in the form of tags. You store your objects and then you store additional keywords, which are right here as tags. These are identifiers which identify, which make logical collections in the cache. So, you could just use the tag-based API, where you say get by tag and then you get the entire collection which matches the results or you can even run a query where you say select venues where tag equals to, and tag is essentially a location that you've already added, where tag equals to a XYZ location and you would get all the records matching based on that criteria. So, these are the two ways, you can handle queries, where you could add tags on top of your objects or just rely on actual object attributes. And then perform SQL like search queries on them. I hope that answer your questions. Please let me know if there are more questions on this.
There's another question. Can I set expiration of certain cached items based on events? For example, a record is cache and it expires, if it is updated in the database. Absolutely! we have two kinds of expirations. We have, time is expiration and there are two types of expirations, so if time elapses you can expire items and this expiration can also be based on database dependency. For example, something changes in the database and that would answer your question. For example, a record changes in the database you had a record in the cache, which was dependent on that, as soon as that database record changes, database can send an event notification and item in the cache can automatically be removed from the front from the cache. So, it can be expired as soon as it expires in the database. So, that's exactly what we offer in terms of relational database dependencies and SQL dependency would cover this. I would appreciate if we could quickly go through other slide and then come to our object caching portion and this should answer a lot of questions. Please let me know, if there are more questions otherwise, I'm going to resume the presentation from the same bit.
There is a question. Can you show a sample persist and retrieve data from the sample cache? I would quickly recommend that you look at our samples, which come and start with NCache and those are available on our website as well. So, if I quickly take you to our samples, here you go and NCache. I can guide you towards the sample, which handles this exact. So, we have database synchronization and then we have dependencies. So, these should. Dependency handles, SQL dependency and database synchronization are another kind of sample, which helps you handle the scenario with the help of reads and writes request. I hope this would answer your question. Thank you very much.
There's one other question. Can we query this to sort the data? Yes. we have grouped by an order by support. So, you could use those attributes alongside the query. Very good guys! Thank you very much for sending these questions. I really appreciate these. Please keep them coming. Since, this was planned towards the end of our presentation and I was already going to cover these but it's good to have all the questions coming in, so please keep them coming. Thank you very much.
NCache Architecture
Now next thing, I'll quickly go to the architecture. The distributed cache is very elastic in terms of adding or removing servers. You could add as many servers as you want. You can take any servers offline. It's based on TCP based cache clustering. It's our own implemented a question protocol. We're not using any third party or Windows clustering. Even in Microsoft Azure you would just rely on an IP address and port and NCache would take care of the rest. It's 100% peer-to-peer architecture. There's no single point of failure, you can take any server offline and add new servers and clients would not have any impact. You can dynamically apply changes to a running cache cluster. Then these configurations are dynamic in such a way, that these servers are in constant communication with the clients. Any server going down or new server getting added is notified right away. There's an in-memory map, which is propagated to the client and which gets updated each time there's a change in the cache. So, these maps cluster membership information and cache topology information map, these get updated as soon as there's a change in the cache cluster. So, there's a connection failover support, alongside that if a server goes down, clients would automatic that and servers would make that server leaving and the surviving nodes automatically become available and clients would automatically connect. So, in short it would not have any data loss or any application downtime as far as client applications are concerned and then there are four different topologies, that you can choose from.
Caching Topologies
The active and passive mode or master or slave mode would be determined based on the caching topologies. Like I said, it's a peer-to-peer architecture. So, each server is independently participating in the cache cluster. So, there's no dependency or there's no concept of lead host as you had in AppFabric or there's no active or passive or in terms of configuration or in terms of cluster management. Every server is 100% independent in terms of configuration, in terms of its position in the cache cluster. But there are different caching topologies and we have active and passive but those are based on the data in the cache. If data is actively available, we call it active and if data is just backup, clients are not connected to it, we call it passive. But this passive server is again added in the cache in 100% peer-to-peer architecture.
There is a question. Is there any SDK for mobile platforms, android or iOS to use NCache in native mobile apps? At the moment we have .NET as well as Java API, we're working on restful API so, if that gets released, I'm pretty sure you would be able to use it from android as well as iOS apps. Please do send me an email on that, send me a request on that and I'll put that forward to engineering and I'll quickly get back to you with the timelines on that as well.
Now we have four different caching topologies.
Mirrored Cache
We have mirrored, which is active/passive. I'm going to quickly skim through these because this is not our agenda today. I want to focus more on our hands-on portion. So, I'll give you a glimpse of what different topologies NCache Offers. We have four different topologies. Mirrored Cache, it's a two-node active-passive. You have all the clients connected active and then we have a backup server right here. If active goes down backups automatically become active. And these clients automatically failover. This is recommended for smaller configurations, very good for reads, very good for right and it's also very reliable.
Replicated Cache
Then we have Replicated, it's an active-active model. So, both servers are active but clients are distributed. So, if you have six web role or worker roles in Microsoft Azure, evenly load-balanced, some would connect to server one and some would connect to server two. And we have a sync model here.
In mirrored we had async, so reads performance was very fast as well. In replicated we always have a sync model. So, we have an entire copy of cache on each server and these servers have the same data and in a synchronized manner all updates are applied on all servers. For example, you update server item number two on sever one, it gets applied on server two in a sync manner only then that operation complete. But reads, that are applied locally on the server where the client is connected. So, reads are very fast very scalable, writes are very consistent, I would say because if you change something here you would always have that change here as well only that operation would complete. So, for reliable data transaction for updates, for superfast performance this is a very good topology to have, if you lose server one, these clients would failover to server two and if you lose server two, these clients would failover. So, there's no data loss, no application bouncing.
Partitioned Cache
Then we have partitioned cache, where we have data partitioned and then we have partitioned with replication. So, we have data partitioned, where you could have two or more servers as needed and data is automatically divided on all servers. Some data would go to server one and some data would go on to server two. The distribution maps of coins are already aware, where data exists in the cache, they would pinpoint the server and use that server for reading as well as writing data. More servers mean more reading copies out of the cache, more writing, more servers to read data from, more servers to write data to. So, these servers contribute towards overall performance, overall scalability. So, more servers mean more scalability out of the cache. Partitioned does not have any backups.
Partition-Replica Cache
We have partitions with replicas, where you could have each partition backed up on another server in a passive replica partition. For example, so one’s backup is on server two, and sever two’s backup is on server one. So, there's no data loss, if server one goes down or if you need to take the server to offline. The backups are made available at one time. And this is also very linearly scalable, as a matter of fact, it's our most scalable topology in terms of performance numbers.
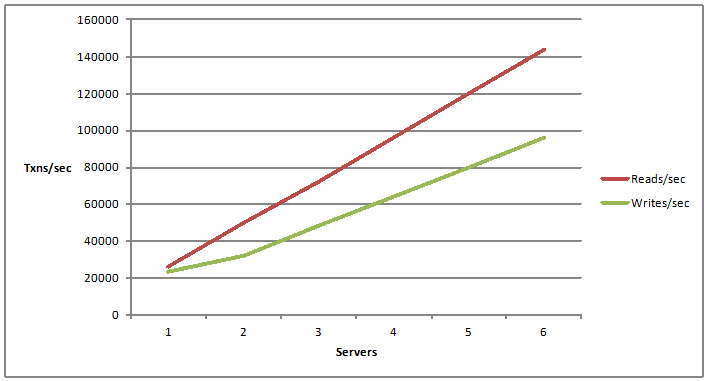
Let me quickly show you some benchmark numbers to support this. Please let me know if there are any questions? Like I said I am quickly going to skim through these topologies to save some time here.
Here is mirrored cache with two nodes. Replicated very good for reads, writes are not that scalable but you could see the point here because it has sync nature of updates and partition with reads as well as writes scalability. Partitioned replicas with reads as well as writes, this also has backups so you get backups alongside performance and scalability. And then we have partitioned replicas with the sync replica as well.
Client Cache
There are a few more features as well, for example, we also support local near client caching without any code changes, you can turn on caching on your application side as well. And this cache would be in sync with the server cache, mostly recommended for reference type of data. So, if you have more reads than writes, you might want to turn it on and this would give you super-fast performance improvements on top of your existing application. It saves your trips across the network to a distributed cache. This is already saving your trips to the back in databases but you can even save this trip where you have to go across the network by using a client cache. You just need to turn it off. And you can even make it in the process to your application to further save serialization and inter-process communication over. And NCache manages all the synchronization. If something changes here, it gets propagated here as well as in other client caches and vice versa. It's a very good feature to start off. I already covered performance benchmarks.
WAN Replication of Distributed Cache
Then we have WAN replication support as well in Microsoft Azure. For Example, if you have two data centers, one in New York and the other maybe in Europe right, so you could even have data transfer from one data center to another. You could have a cache cluster here and with the help of our bridge, which is also backed up with the active-passive nodes you can transfer data to the bridge and then the bridge can in turn transfer it to the target site. This could be active-passive for the DR scenario or could be active-active as well.
OKAY. There's a question. Can I use the client cache in a disconnected system that is mobile apps with temporary no network connectivity? That's a very good question. The question is that can I use the client cache in a disconnected mode. We've talked about it; this was a feature request by one of the clients and then we actually discussed it at length. So, there is a specific requirement that you're interested in. We already have some plans, we have already discussed this, and since, we already have had a request similar to this. If you could just send me an email on that, I want client cache to be used for my use case and I want it to be used even in disconnected mode. I will be very happy to pass this on to engineering because they're already discussing it and they happen to provide this. Thank you very much.
Okay. I'll be waiting for your email in that case. At this point, the client cache walks in combination with the server cache. If this goes down client cache since it syncs with a server cache so if this would also lose all the data. But we're planning to use a disconnected mode, where even if the server connection goes down, the client cache remains up and running and it also queues up some operations to be performed at a later stage.
Hands-on Demo
Next thing, I'll quickly show you a hands-on demo. How does the actual product work? We have a short time left I believe we have ten minutes. So, I'll quickly give you an Azure overview. What you essentially need in order to get started with NCache is that you plan the deployment for NCache.
The first thing, that you need is that you create an Azure virtual network. You come to Microsoft Azure, create a virtual network. You could just use quick create or custom create and then, for example, if I choose quick create, I can just say NCache VM. This would be a virtual network that I'll be using for NCache and then I could just create this virtual network. You could just come up with any specific details about the virtual network as needed. Or you may have a virtual network already in your environment that you would like to use for NCache deployments. So, that's our first step. I have a few virtual networks which are already created. So, I can just go ahead and go to the next step.
The next step would be to create NCache virtual machines. You just need to create a virtual machine that can have NCache pre-installed, you could just install NCache take our Microsoft Azure VM image from the Azure marketplace that is for NCache professional but if you're interested in NCache enterprise, you could simply use plain image 2012 server. Install NCache on top of it and then save that image for a later stage and then load it, each time you need to spawn a new VM for NCache server deployment. So, from the gallery, I could just choose an Image, for example, the 2012 server. I could choose next on this just give it some name. For example, demo 3. I will choose some server tier and then I could just fill in some information as needed.

These are Azure specific steps. So, I'm pretty sure you would be familiar with this. The next thing which is the most important one is that whether you want to create a new cloud service or use the one which is already there. For example, if I use the benchmark it would automatically pick up the virtual network as well. But you could create your VMs to be there in their own cloud services as well for that you could choose to create a new cloud service. But you would still, I would recommend, that you choose a virtual Network for all your server VMs and then that should be the same for all server VMs for NCache. So, that you get more performance out of the system as far as server-to-server communication goes. So, I'm just going to choose this benchmark, and based on that I could just choose next.
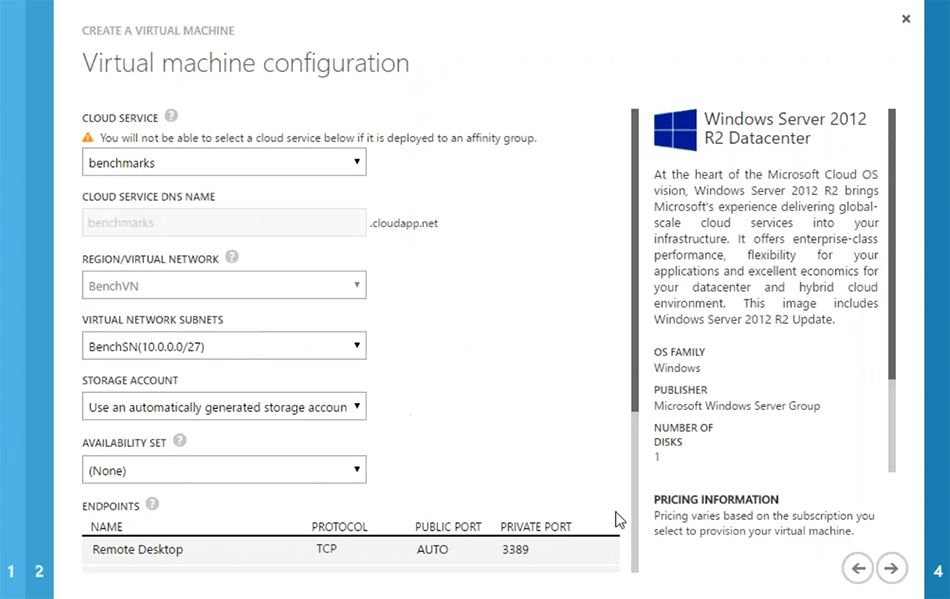
You could fill in some specific details around network if needed. But overall, this is all I need. So, I could just... Okay. The cloud server that I've chosen does not support this kind of virtual machine. So, I just need to choose create a new cloud service with that. Okay. So, I will just say so that it approves and there you go. So, that's how this would go. I'm just going to cancel on this. I already have these servers right here and as a matter of fact, I can quickly log onto few servers, which I already have configured. So, please bear with me. Let me show you, how you could get started with creating a cache and configuring in and quickly testing it in your environment. We have about ten minutes. So, I want to make full use of it. And guys please feel free to post as many questions as you need to. I always answer questions while I'm preparing the environment.
Okay. I already have these servers. I can quickly log on to these. We've been using these for some testing already, I think I messed up the password right here, please bear with me. There you go! OKAY! there you go! then I have that Demo 2 right here. So, these are my two boxes there you go. OKAY! So, I have these two boxes already configured which are part of the same virtual network in Microsoft Azure.
There's a question. Do I need a VM necessarily or can I use an Azure app server? what about docker? We do not have any docker support as yet. I can check with engineering if they're working on one. As far as server model is concerned, for NCache you need to have a VM on Microsoft Azure. Virtual application could be of service model, it could be a cloud service, it could be a web role, it could be a worker role, could be actual VM where your application is deployed. But the NCache server portion has to be a VM and like I said the easiest way would be that you create a pre-configured VM image of NCache. Keep it in the gallery and then load it, when you need to spawn a new instance of it. You could even choose the same for auto-scaling, where you have the VM templates available, NCache installed activated and configured, you just spawn those new VMs, when your node grows to a certain limit.
There's another question. You may have mentioned already, is there encryption and compression for data reduction in terms of bandwidth utilization and I believe you are asking about encryption and compression. Yes! these two features are available without any code changes. You can encrypt your data for sensitive data transmission, data can be encrypted and then the data can be compressed as well. So, these are part of NCache support. Thank you very much for asking these questions. Please let me know if there are any more questions.
Setting up an Enviornment
I quickly want to show you actual product in action. So, next thing that you need to do is go to our website and install NCache either the cloud version, which is right here, which is professional cloud, it's available in Microsoft Azure marketplace as well or just download the regular Enterprise Edition and install it on your Microsoft Azure VMs. I've already done Enterprise installation. So, step one is complete. Now step two is to create unnamed cache and for that you could launch an NCache manager tool that comes installed with NCache. So, you could just manage everything from one of the VMS as needed or you could just manage it from a separate server altogether as well which has access on the network to these servers.
Create a Clustered Cache
The next step is to create a named cache. I'm quickly going to do it. It's called demo cache.
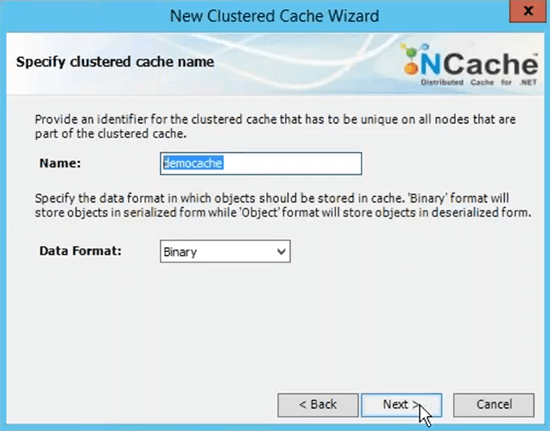
This is the name that you will be using for all your client applications in order to use this cache. You would be able to refer to this name in order go ahead and fetch data from the cache. I'll choose partitioned replica cache topology because this is most recommended one.
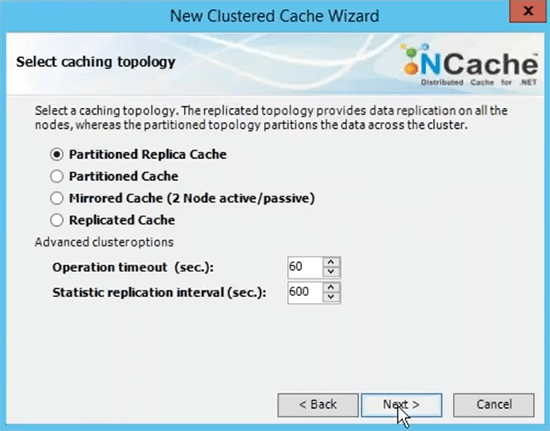
I'm going to choose next on this choose Async as a replication option because it's faster. Server 1 and look it's using the private IP of the servers and that's why I recommended that you measure virtual network in terms of server-to-server deployment. So, that they are accessible on the internal IPs and you have a very fast communication going on between servers.
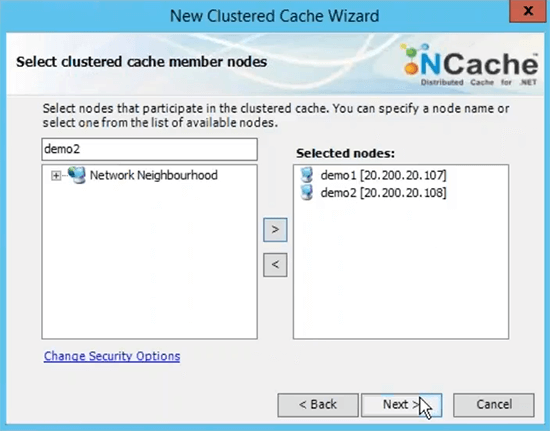
TCP port for communication by default Azure VMS have firewall opened. So, I would recommend that you turn that off or at least punch NCache ports for communication on the firewall. And then the size of the cache per server is based on the memory that is based on data, that you plan on having in the cache. So, if you need two gigs of cache size, just come up with the right amount of memory specified here. This is just an upper limit, if the cache becomes full you have two options, you can either reject new updates which means no data can be added, you would get an exception or you can turn on evictions where you can just specify an eviction percentage and these algorithms can control, how much items can be removed using these algorithms in order to make room for the new items. So, if your cache becomes full, evictions are turned on, some items would automatically be removed and you would be able to add more items. I just choose to finish with the default setting.
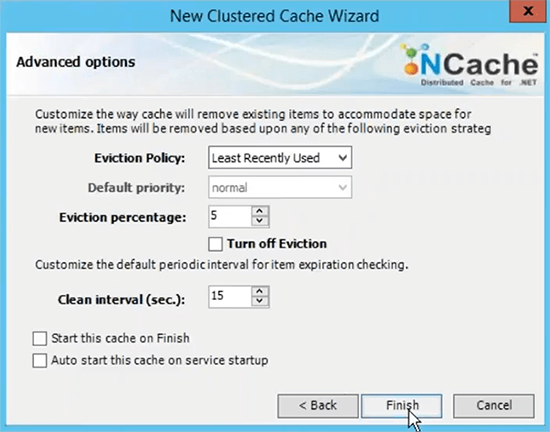
Then this completes our step 2, where we have cache configured in the right pane there are all the settings which are related to this cache. Step 3 is to add the client node I could just add demo 3 but since we only have two servers and I'm just going to add these two boxes as clients as well. Step 4 is to start and test this cache cluster, for that I'll just right-click and choose that and this would start this cache on all my caching server and by the way these client nodes are actually my web roles or VMs, where my application is deployed.
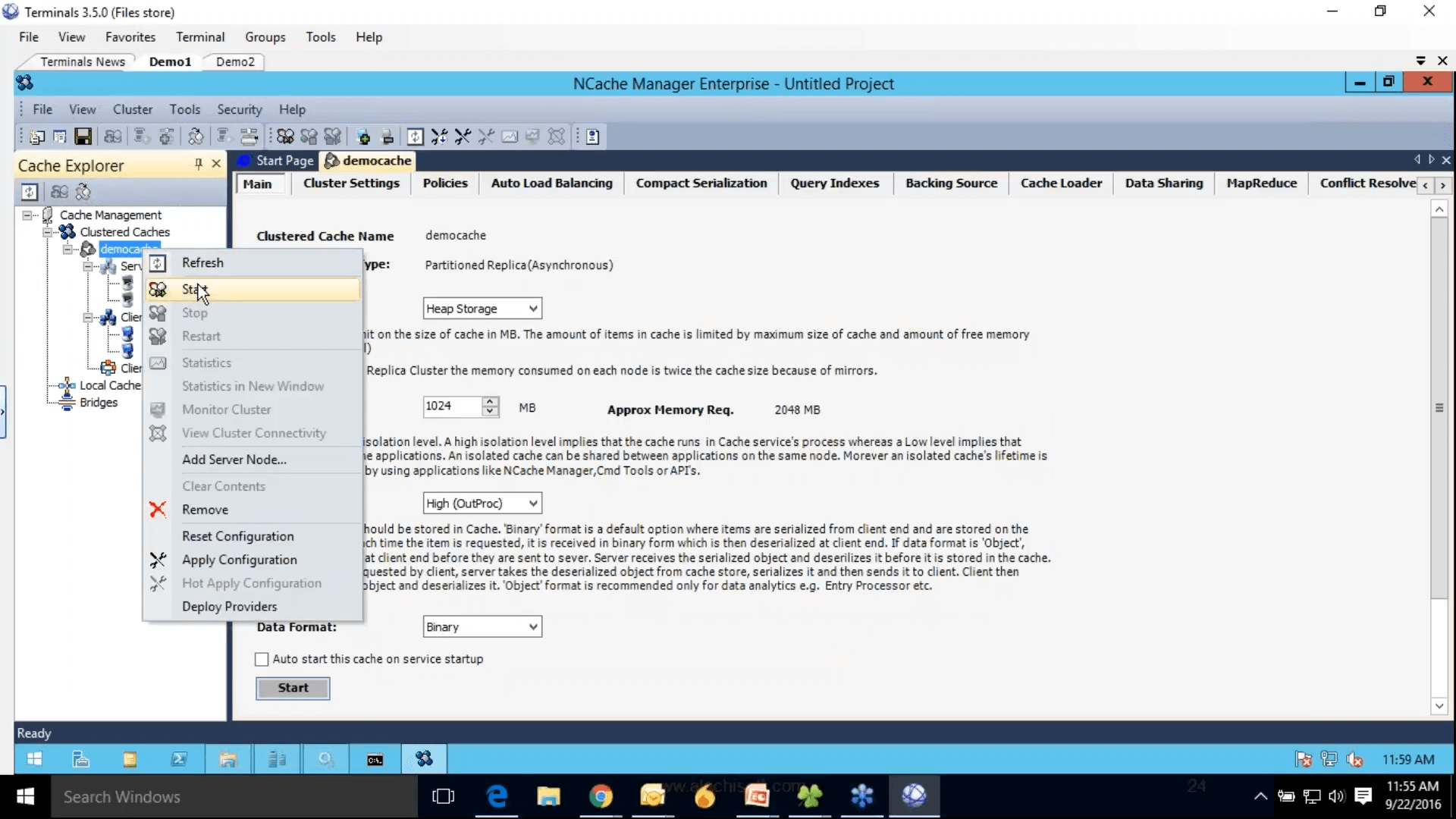
So, you just that's why I recommended that you keep everything on the same network as well. So, that you could just manage them from NCache Manager. And right-click into statistics this would open perf-mon counters. Cache has started some of the settings are greyed out which cannot be changed while cache is running but you can still change some of the settings, such as you can turn on compression, right-click and choose hard apply configurations. Will ask you to save the project first. So, I'm just going to do that and then hard apply configurations. There you go.
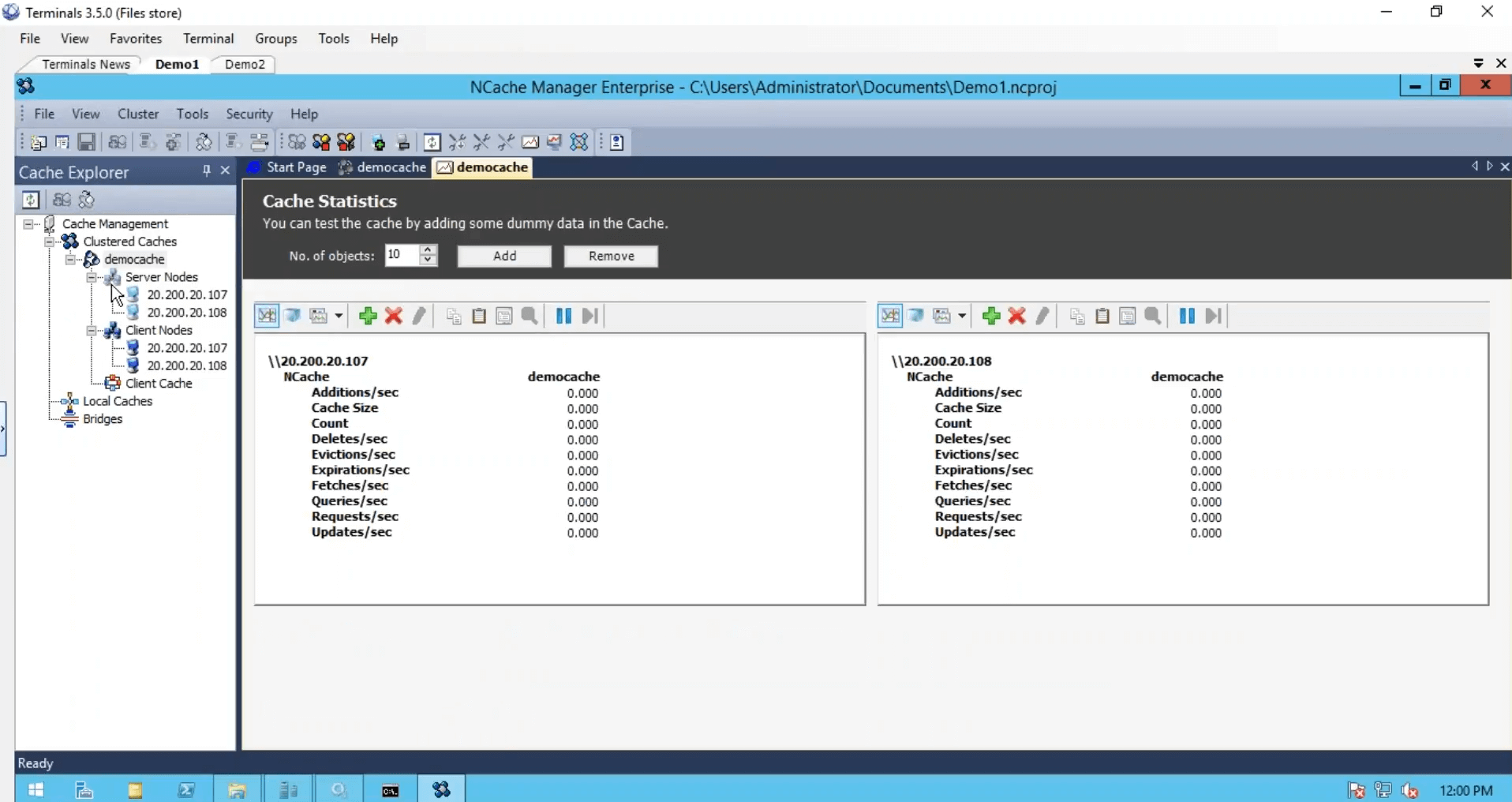
Now cache has been configured, clients have been configured. We're done with three steps, we've installed NCache.
Simulate Stress and Monitor Cache Statistics
We've created the cache, we configured the clients, we're done from the configuration standpoint but we just need to start and run this cache cluster and for that, I'll just use a stress testing tool, which comes installed with NCache. And run it against my cache. So, that I could see some activity as well. I'm also going to log on to my second box and run this console-based application as well. So, that and before, I run the second instance look at the requests per second counter. We have about a thousand requests per second generated by one instance of stress test tool.
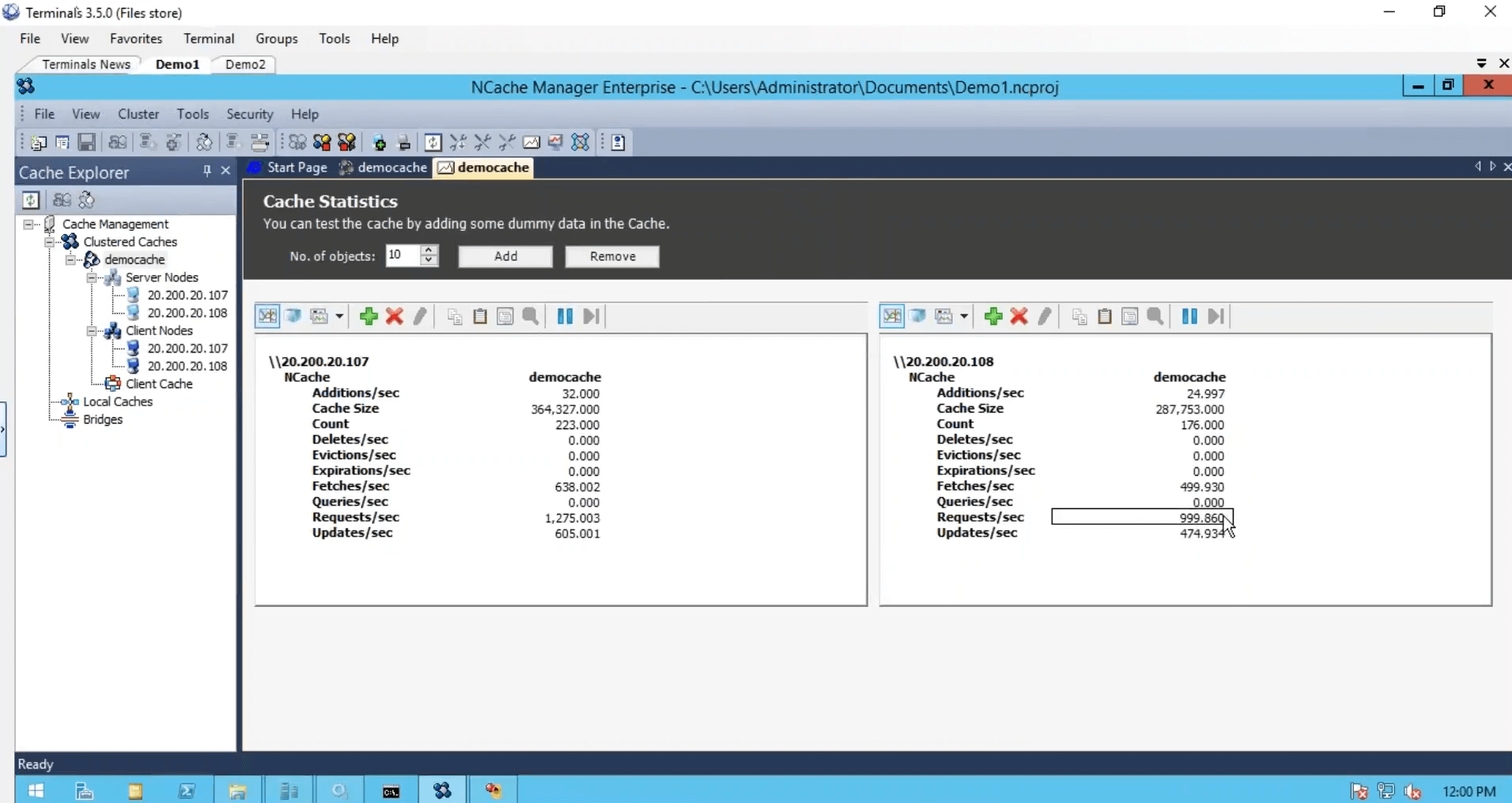
On second server, I'm just going to run this. So, that we have some more load and notice the requests per second counter has almost jumped to double. Two thousand requests per second.
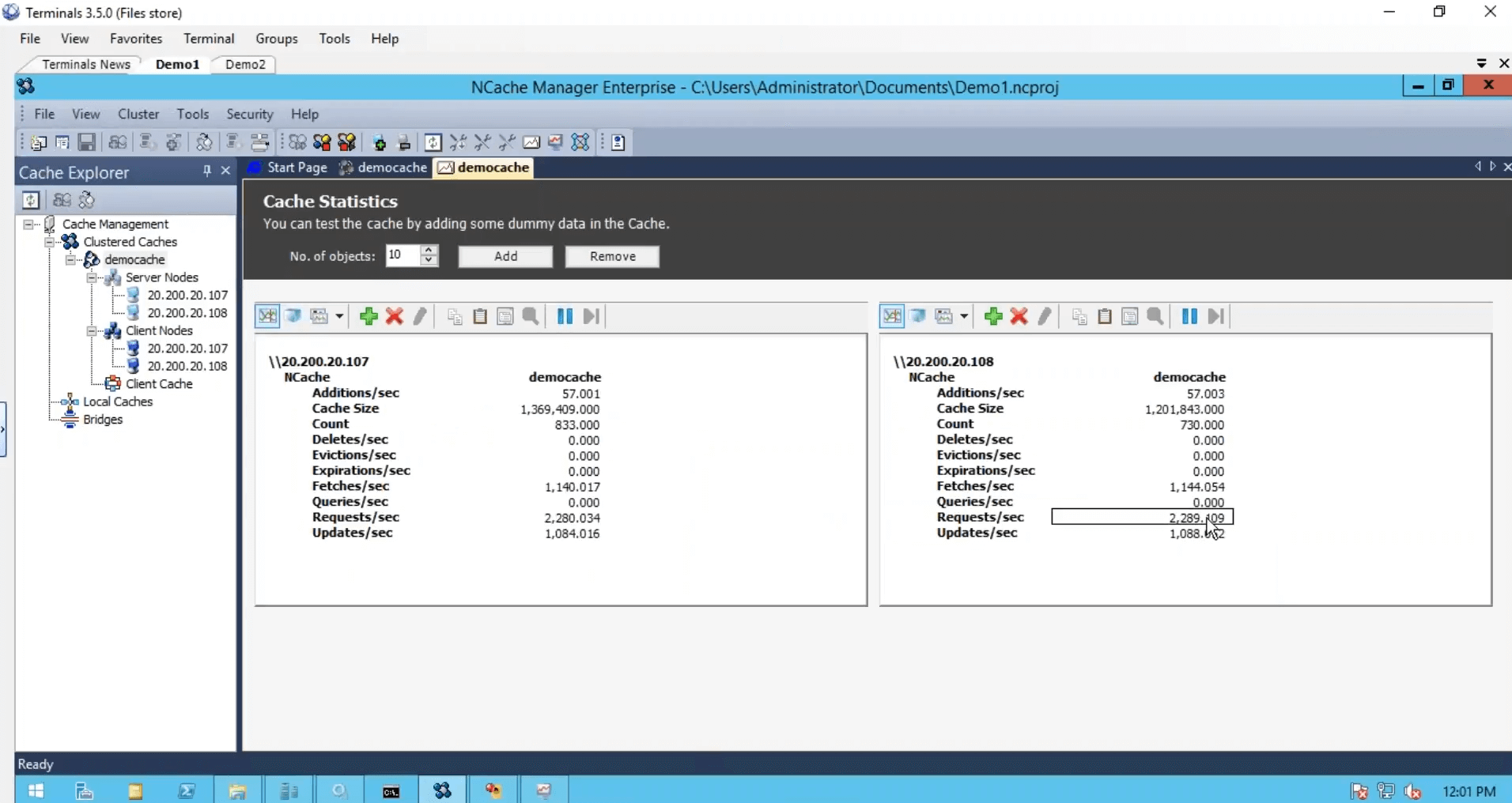
Although I have run one instance from this box, it was still using both servers. I ran another instance that application was also using both servers in combination to one other and then we have this monitoring tool, which gives us health, CPU, request, size, network, and different matrices from the server-side as with us from the client-side.
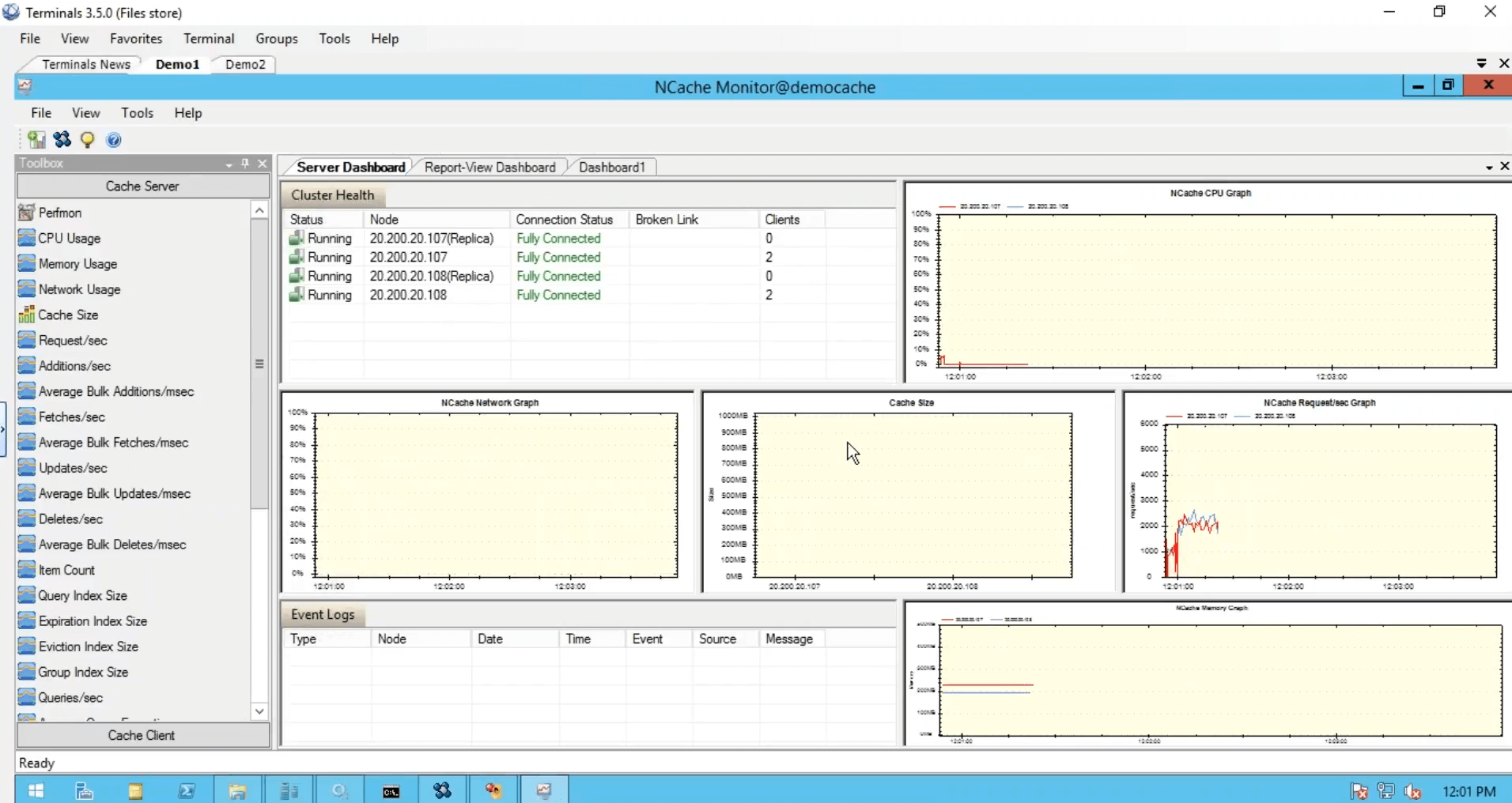
And you could also, create your own dashboards as I've done right here. I'm sorry guys because of time constraints, I had to be a little bit quick towards this but this was a simple five simple steps to getting started with NCache. Our cache is up and running.
Use NCache Samples
Next thing is to use cache in your actual applications and for that, you could just quickly refer to our NCache samples. For example, if you want to use basic operations, this is the sample. If you want to use session state, you could use this ASP.NET session state Application. We also have view state and output caching samples available in this list. So, take advantage of these and refer to this for using NCache in actual applications.
There's a question. Can I configure two levels of cache, one bigger equals 200 GB on a persistent state and one smaller equal to 1 GB more volatile in memory, and have a level 1 memory synced with a subset of the memory commonly referenced objects from level 2 cache? This is possible. You have two questions. The first question is whether you can create two different caches with two different memories. Yes. You can, most of our clients create one cache for static data and another cache for dynamic data. So, that's something that you can do and you can create completely different configurations for these two caches.
The next question is, is it a possibility to synchronize data between these two caches? Yes. You can. There is this cache sync dependency. That feature is privately available but I can share some details of how to implement those and you could have a sync dependency between two different caches as well. This same feature is what we use in-kind caches wherever we have client cache, which is a cache and it's synced with the clustered cache configured on other servers. So Yes. To answer your question yes you can have two different caches and you could also have synchronization between data in those two caches.
I'll quickly sum it up for you, there are a lot of object cache increases that you can take advantage of, these are part of NCache object caching support and then we already covered the ASP.NET session’s view state. There are some third-party integrations as well. So, this essentially is the end of our webinar. I apologize for running through a few bits because of time constraints but just to reiterate, we've covered some basic details about inability issues, talked about in-memory distribute caching in the solution, talked about the deployment in Microsoft Azure, different use cases, clustering support, topology support within NCache. We had a specific hands-on demo on how to get started in Microsoft Azure as far as NCache goes.
Please let me know, how did you like the presentation? How did you like the product in general? Give me your feedback on this. There are some things that you can do towards the end. You can go to our website and you could download a 30-Day trial of NCache. You could also choose our cloud edition, which is NCache professional cloud, it's available on Microsoft Azure. We have a client as well. Then you could even use your Azure VMs to go with the Enterprise Edition product if you need to. You can get in touch with our support team by going to the support page. There are some contact details you can get in touch with support at support@alachisoft.com.You can request a product demo as needed and you can also get in touch with our sales team for pricing information. So, we're already, at our one-hour marker so I think it's time to say goodbye. Please let me know if there are any questions even after this demo. You can get in touch via email or through phone and I'll be very happy to see any questions from you guys. Thank you very much, guys. It was a pleasure presenting NCache webinar today. Please let me know how did you like the product, how did you like the presentation and we can always take it from there. Thank you very much for your time, everybody.