South Florida Code Camp 2017
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
Your .NET applications may experience database or storage bottlenecks due to growth in transaction load. Learn how to remove bottlenecks and scale your .NET applications using distributed caching. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
Today I'm going to talk about how you can scale .NET apps with distributed caching. This talk is not about NCache. Although I will refer to NCache but the main purpose is to educate you about what the problems are and how you can solve them with caching.
What is Scalability
Okay! Just for completeness purposes, let's get over a few of the definition that I'm sure you know them already, but, let's first define what is scalability. Scalability is not high performance. High performance would be something if you had five users you have really good response time, that's a high-performance. Scalability is if you can maintain that same high performance under peak loads. So, if your application does not have high performance with five users then you have other issues. More than we can solve there.
Linear Scalability
Second, what is linear scalability. Linear scalability is more of a deployment definition.
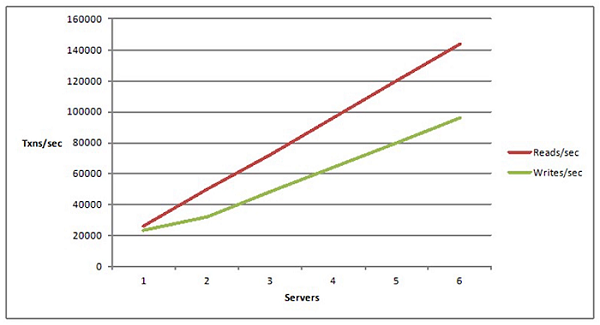
When you deploy your application in a multi-server environment, let's say, if you have a load balanced environment, your application is linearly scalable if you can just simply add more servers to get additional transaction capacity. So, if you had a thousand users with two servers, you had a third server you get, let's say, 1500 users and then as you add more servers you get 500 users each. I'm just saying hypothetically but that's a linear scalability. If you can achieve that then that's the goal because then you're, you never run into issues, for which I'm sure you were here to address.
Nonlinear Scalability
Nonlinear scalability is just the opposite of that which is that you've got an application architecture where you just can't buy more expensive hardware or more servers to solve that problem.
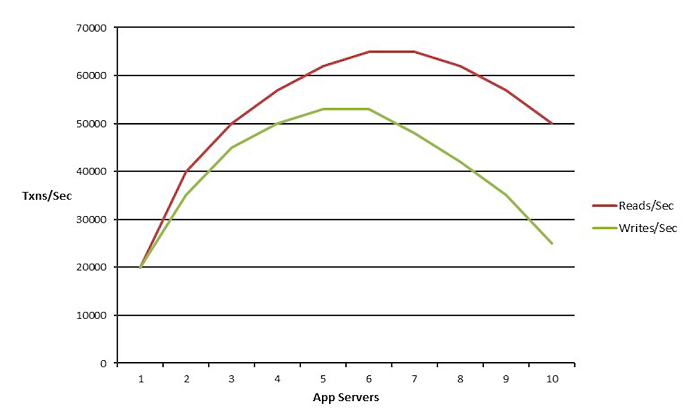
You have some fundamental bottlenecks so as you add more servers, your application, for a certain time, the performance or the transaction capacity goes up but, after that it actually slows down even if you add more servers. So, you definitely don't want nonlinear scalability.
What type of applications need scalability?
These are usually server-side applications.

These are web applications, ASP.NET, these could be web services WCF, these could be the back end for any IOT applications. We have a lot of different IOT devices talking to some sort of a back-end. This could be big data processing applications, although, big data processing is more of a Java activity. Because of Hadoop, .NET is not very big one big data processing but if you were doing big data processing, you would definitely need to scale and, any other server applications that don't fit into this category. I mean you may have a lot of batch processing, if you're a large corporation, you may have to get a certain number of things updated by midnight or by, before the next business day and, as you have more and more customers you have millions and millions of customers you, of course, need to scale that.
So, even those back-end applications, one good example could be that customers are, your bank and the customers are transferring funds from one account to another, that is usually processed in the backend in a batch mode at night. So, you have to contractually get that done within a certain time period. So, all of these applications, if they don't have scalability, you have major problems.
What is the scalability problem?
The application tier fortunately is not where the problem is. If you have most of these applications, the application tier you can add more servers, there's no big deal. It's the data storage that's the problem. And, when I use the word data storage, I mean relational databases, mainframe legacy data. That's where most of your data resides and they're the ones who cannot scale in the same way that the applications do. Now, NoSQL databases exist for one of the use cases is to scale, but, the problem with NoSQL databases, and again, we have a NoSQL database of our own called NosDB. It's an open source database. So, the limitation of NoSQL database is that you just cannot move all the data to it because they require you to move data away from your mainframe or your relational databases which for a variety of reasons, maybe technical, maybe business, you may not be able to do.
So, the relational databases are going to continue to be your main master data source. There are a lot of use cases where you can put a lot of the new data in NoSQL databases and when you do then they resolve the scalability bottleneck. But, majority of the cases, you can only do that for a subset of your data. Majority for data still needs to stay in your relational databases or in your legacy mainframe data sources. So, whatever problem you have to solve, this scalability, you have to solve it while continuing to work with relational databases or with your legacy mainframe. And, that's where a distributed cache actually resolves that problem. It allows you to continue using your relational databases mainframe data while removing all that bottleneck.
Distributed Cache Deployment
So, here's a picture, if you had, if these are your relational databases legacy data, you can put a caching layer in between the application and the database.
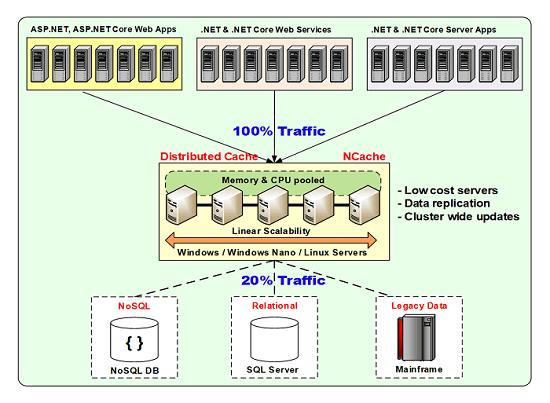
When you do that what happens, you start caching data that you're going to use frequently. And, about 80 percent of the time you don't even need to go to the database. And, the cache, because it's a distributed cache, you can add more and more servers, it scales in the same fashion as the application tier. So, you have a minimum of two cache servers here and, then you maintain a four to one or five to one ratio between the application tier and the caching tier. Now, that ratio can change depending on the nature of your operations. If each of your, let's say, if you had a web application, for every user click you do hundreds of cache calls then, of course, the ratio would change but, most of the time you don't make hundreds of cache calls.
A typical cache server is just a low-cost server. It's a web server type of a configuration, dual CPU, quad-core type of a box, it just has lots of memory. Lots of memory means 16 to 32 gig is pretty standard, more than 32 gig you usually don't have to do. Although, we have many customers who go up to 64 gig but we recommend that instead of having a lot more memory in each box just add more boxes. And, the reason is because the more memory you have in each box, the more powerful processor you have to have and then your box is starting to look more and more like a database which is not the intention. You want to keep this as low cost as possible.
Now, a distributed cache is an infrastructure that you want to put for all your applications. So, just like you have a database which is pretty much a common infrastructure, the new best practice is to have an in-memory distributed cache. It's also called an in-memory NoSQL key value store. And, have that as part of your infrastructure and architecture applications so you're always going to this store. So, you check the store before you go to the database. Once you have that infrastructure then all your applications automatically become scalable. So, you never have to worry about the databases becoming a bottleneck. And, the biggest problem with scalability or not being able to scale is that that's when your business is doing a lot of activity.
Let's say, you're an airline and you just did a special promotion for Hawaii. Everybody is logging in to your website on, I don't Know, Wednesday to start to purchase tickets. So, they're going to search for flights and they're going to buy tickets and, you have got like five times more traffic than you have had before and suddenly the site slows down, maybe it crashes and it can crash, of course, if your database gets overwhelmed but, even if it just slows down beyond acceptable limits, your cost to the business is very high because people will just leave. So, you really need to make sure that you plan for scalability that you never have that situation where your business wants to do more activity, they're able to generate business but you're not able to process within the application. And, if you have the right infrastructure then you'll never have that problem.
I'm just setting up the case on why you should use a distributed caching? What problem is solves and then we'll go into the details of how you actually use it. In addition to having more memory, you have usually, as I said, dual CPU, quad core configuration, 2 network cards one gigabit or more each. In case of NCache these are Windows boxes, in case of Redis these are Linux boxes, depending on if you have a .NET or a Java application. My focus here is .NET but for Java you also have distributed caches. They call them in-memory data grid, on the .NET side it's called a distributed cache.
Common Use Cases of Distributed Cache
Okay! So, now that we've kind of built the case on why you need to have distributed cache as part of your best practice infrastructure, both from an IT perspective but more importantly from a development perspective, you want to architect the application. The first question that comes to mind as well, how do I use this cache? What are the use cases? Where do I use them? I mean I know what type of applications I'm going to use them but what type of data I'm going to cache?

So, there are three main categories. Number one is what everybody understands which is application data caching.
Application Data Caching
So, in application data caching, you are caching data that exists in your database, you are caching it, that's what we just talked about. So, when you do that you're actually creating two copies of the data. One is in the database to the master and one is in the cache which is the temporary copy. When that happens, what's the main concern? What could go wrong when you have two copies? They could get out of sync. In fact, that is such a major fear in people's mind is that most people when you ask them what do you use caching for, they say well for read only data, I can't take a chance with my transactional data, with data that changes because what if that goes wrong. What if my customer withdraws that money twice from that same account then what's going to happen?
Well, if you cannot cache transactional data then the value of a distributed cache declines quite a bit because reference data is only twenty percent or thirty percent of the data. 80 percent or 70 to 80 percent of the data is your customers, your accounts, the activities, your transactional data, the data that changes every maybe 30 seconds, every one minute, data that you may be able to, keep in the cache for a very very short time. So, if you're not able to use a cache for transactional data then you've really restricted yourself. So, a good distributed cache must ensure that the cache and the database are always in sync. So that once you have that comfort that peace of mind that the cache is always in sync with the database, you can Cache practically everything and when you do that you really see a lot of the games.
And, I'll go into a lot more detail on that.
ASP.NET Specific Caching
The second use case is when you have an ASP.NET application, there are certain ASP.NET specific things that you can cache. And, the nice thing about this category is there's no programming needed on your part because Microsoft has a framework where a cache will just plug in. Number one is the session state. Every ASP.NET application has to have session state, pretty much. Some people specially programmed not to use it which is not a good idea. You should use a session makes your life a lot easier.
A session is a very good candidate for caching because if you store a session in the database, you run into the same problems that databases are not designed for storing blobs which is what a session is. So, the performance is really slow and more importantly the scalability just goes away. For the same reason that you want to do application data caching, you want to put the sessions also not in the database. You want to put them in the distributed cache.
The second is a view state. If you are not using the MVC framework, if you're still on the old ASP.NET framework then view state. For those of you who don't know what a view state is, a view state is an encrypted string which could be as small as a hundred bytes or it could be hundreds of kilobytes that is generated and sent to the browser only to come back when you do a post back. So, it's a pretty expensive trip. It, of course, slows down your performance because a lot more data is going. And, also increases your bandwidth costs because when you host your application, the pipe above this is not free. So, when your customers access your web application, you're paying for the bandwidth here. So, a view state, when you multiply that by the millions and millions of requests or the transactions that your users or customers are going to make, it's a lot of extra cost that you don't want to incur. So, that's a very good candidate for caching. So, you cached it on the server and just send a small key that next time a post bad occurs the key comes back and before the page gets executed, the view state is fetched from the cache.
The third is the output cache which is another part of ASP.NET framework that if your page output is not changing, why execute it the next time? Because every time you execute the page it's going to consume CPU, memory and all the other resources including your databases. So, it's much better to just, return the output of the last execution that could be the entire page or it could be part of the page. So, for all these three you just plug in a distributed cache without any programing. Now I'll show you that. But, the nature of this problem is very different than the application.
In the application data we had two copies of the data, right? So, the issue was synchronization. Here, you have only one copy and that is being kept in an in-memory store. So, what's the biggest concern when you keep something like that in an in-memory store and that's the only copy. That too! Or, if any server goes down you just lost that cache. So, for any of this to be stored in the cache. Just imagine that same airline that I just went through and I spent half an hour finding the perfect airline combination and I'm just about to hit submit and the session is lost, not a good experience because the web server just went down.
So, for this, how do you solve that problem when you have an in-memory and you have that concern? You have redundancy. You have more than one copy of the data. So, a good distributed cache must allow you to do data replication. Without data replication in an intelligent and high-performance manner, your cache again becomes much less useful.
Runtime Data Sharing Thru Events
The third use case is something that most people don't know or it's starting to become more popular is that you can use, you have this very scalable in-memory infrastructure. You can use it for runtime data sharing through events, it says sort of like a messaging but a much simplified version of it and it's in a single data center type of an environment where you can have multiple applications use the cache as a way to do Pub/Sub type of a data sharing. So, one application puts something in the cache, fires an event and the consumers who are interested in that data received that event and they can go and consume that data.
So, instead of putting that in the database or putting that in a MSM queue type of a situation which has its own purpose. A cache is not there to replace MSM queue but, in many situations, it's a much simpler and especially much faster and more scalable infrastructure to do event-based data sharing. So, if you have a need where you have multiple applications that need to share data with each other at runtime then you should definitely consider this as a feature, a very important feature.
ASP.NET Specific Caching
I'm just going to quickly show you the ASP.NET caching, how you do that. It's very very simple and I'm going to actually use… So, I've got some sample code. So, for example, if I were to… So, I have this ASP.NET application. All you have to do is go to the web.config, in case of NCache and again it's going to be pretty much the same for all caches. The first thing that you have to do is add an assembly. So, this assembly is the session state provider. So, ASP.NET framework has a session state provider interface that a distributed cache has to implement. NCache has implemented it and this loads the assembly into your application.
So, once you've done that the next thing that you have to do is go to the session state tag. In fact, and make sure that the mode is custom and the timeout make sure is whatever your timeout wants to be. In case of NCache then you just put this line. Other caches have a similar type of information. So, you just have.. In case of NCache all you need to do is make sure that your cache is named and I'll actually show you what that means. But, with just this much change in your application, you can basically start storing your sessions. So, you make that change in every web.config in the application tier, of course, you make sure that a cache exists. And then, once you've done that you can actually start to put sessions in the cache.
Hands-on Demo
I'm going to quickly show you a cache cluster. So, for example, I have these... uh, I've got these Azure VMs where I've got demo1 and demo2 as are my cache server VMs and demo client is like the application Server. So, that's the clients. A cache client is your application server box. So, I'm going to…
Create a Cache Cluster
And, I have logged into, let's say, I've logged into demo client and I'm going to use this, in case of NCache and again I'm going to use this tool called NCache manager. It's a graphical tool. Let’s you configure the caches from a single place. I will come here and I'll say create a new clustered cache. All caches are named in NCache. So, I'm going to name my cache as demo cache. I'm not going to go into any of the details of these properties.I will pick my replication strategy to be partitioned replica. And, I'll pick an asynchronous replication. I do my first cache server. I'll do my second cache server here. So, I'm going to build a two-node cache cluster. I'm just going to pick everything. So, that's the TCP port on which the cache cluster is formed, you can change it if there's a port conflict. I'm going to specify how much memory my cache server is going to use for cache. I have it as one gig, of course, yours is going to be a lot more.
So, for example, here let me quickly show you what this means. I'm just going to go to this part.
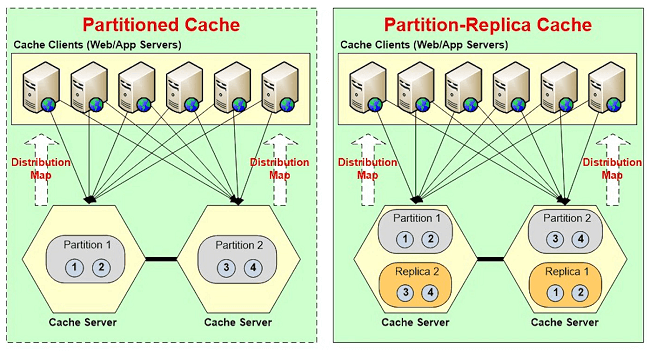
So, think of this as a cache server and this has another cache server. So, partition 1 exists here. Partition 1 is essentially a collection of buckets. Partition 2 is got its own box. So, there's a in case of NCache are about thousand buckets that get distributed between how many partitions you have. Every server has one partition and every server the partition is replicated on a different server. So, if you had three servers, you'll see that partition 1 is backed up here. Partition 2 is backed up here. Partition 3 is backed up here. The replicas are not active in case of NCache. They become active only if the main partition goes down.
So, what I'm specifying there is the size of a partition. So, in case of partition replica, if I specify, let's say, 1 gig here, it's going to actually use 1 gig for the partition and 1 gig for the replica. So, a total of 2 gigs. So, if you have, let's say, a 16 gig of memory what you want to do is leave about two or two-and-a-half gig for the operating system and other processes and the rest you can use. So, for 16 gigs you can easily use 13 gig. So, do a half and half. So, it's a six and a half gig partition size and, of course, you can have 32 gig and again you leave three gigs out and you have 29 gig half and a half,14 and a half gig partition size. And, then as you want more storage, instead of adding more memory just to add more servers because it's easier to manage. It keeps things much more scalable. So, I'm going to just hit next here.
The next is my eviction policy. I'm not going to go into those details. And, I'm going to now add client node. Once I've done that I'm going to start a cache. I'm going to start a cache and I wanted to show you this part because that's what's going to make sense about the rest of the talk. So, it's starting these two cache nodes.
Simulate Stress and Monitor Cache Statistics
So, I'm going to open up a bunch of monitoring tools and I'm going to actually run this tool called stress test tool.
It's a command line. It's a console that actually starts to do activity on the cache. Now, this is like it's simulating your application. So, if you if you look at it your application is putting sessions in the cache every session is one object. So, you're adding. So, the cache count got 177, on this box 172 and 35. So, it's going to be almost even and then it's better backed up onto a different…
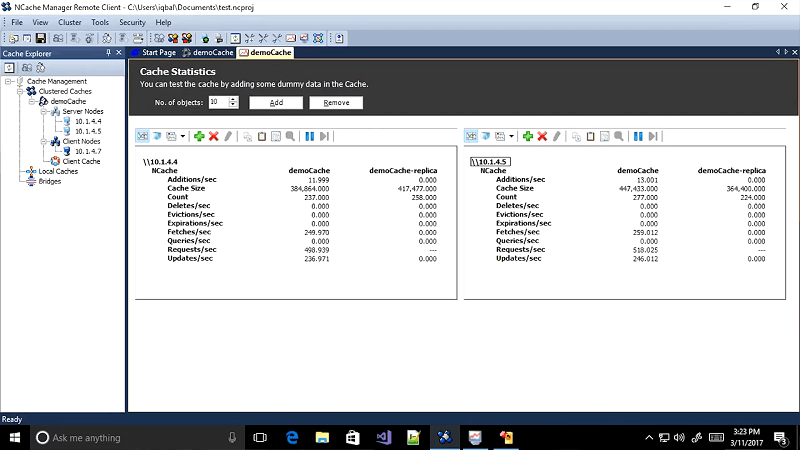
This one is backed up here this one is backed up here. So, as you can see the replication is happening automatically. Your application does not have to worry about. All you did is created this cluster and on the application tier you just modify the Web.config and everything else happens automatically. You can, of course, monitor this stuff but the cache is named. So, in our case I named the cache as demo cache. You can name it, in fact you can have multiple caches. The most common configuration that we've seen with our customers is that they have three caches. One cache they will call it, let's say, object cache. So, it's their main transactional cache. One cache they will call it session cache. So, it will put all the sessions in that cache. The third cache they'll call it reference cache. So, they'll put more of the reference data in the reference cache.
And, the reason they create a separate cache for transactional data versus the reference data is because for reference data you want to use this feature called Client Cache where you want to cache.
Client Cache for Even Better Performance
I'm actually jumping all over so please forgive me if I'm confusing things. If you have reference data, actually let me step back one more. prior to having distributed caches people had this, ASP.NET cache object. ASP.NET cache object was a local InProc cache. It was within the application process, super-fast, Right? If you're keeping stuff on your own heap nothing can match that performance. As soon as you go into a distributed cache, it's different, it's an auto process cache. What people don't realize is your performance actually drops.
We've got many customers who initially get baffled and said, well I was supposed to get a performance boost and my performance dropped from an ASP.NET cache up there it's much slower now, because they have to serialize the object. If you have a large object, serialization is a pretty significant cost and that's a cost that you have to incur independent of any specific cache. And, as soon as you go out of process cache your performance is much slower than a local InProc cache. But, it's still faster than the database. It's almost 10 times faster than the database but almost you can say 10 times slower than the InProc cache.
So, what happens is people want to gain that benefit of that InProc cache. Well, for data that is not changing very frequently, there's a feature called Client Cache. Some people call it Near Cache especially on the Java side.
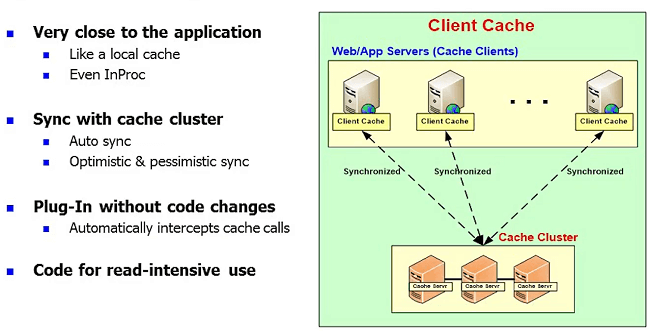
This feature, essentially, it's a local cache. It's like your InProc ASP.NET cache. It sits within the application process or it can be just local OutProc cache which is not as fast as InProc but still faster than going to the caching tier. But, the difference is that this cache knows about the caching tier. This Client Cache is the cache on top of the cache and it is synchronized. So, you don't have to worry about that biggest issue that we talked about which is how do you keep the cache synchronized with the database. Well, now you have three copies of the data. One in the database, one in the caching tier, one in the Client Cache. Of course, the Client Cache is a subset of the caching tier. The caching tier is a subset of the database. But, whatever it is, it has to be synchronized. So, by having a Client Cache, it is again an InProc, it keeps stuff in an object form instead of a serialized form. It keeps it on your heap. So, you get the same benefit of the local InProc ASP.NET cache object but with all the other benefits of scalability because, this client cache will be a small subset. You can specify how big it should be. It will never cross that threshold.
So, you may have one gig in each client cache and you may have 32 gigs in the caching tier and the database probably has a lot more than that. Anyway, so even by having one gig because it's a moving window, right? So, whatever you're doing you keep. Some of the data will stay for a long time, some of the data will stay for maybe a few minutes but within that time you'll make hundreds of calls and not have to go to the caching tier and, of course, not having to go to the database. So, a Client Cache is a really powerful feature when you have that turned on. You do that for more reference data. So, in case of NCache, you can specify a client cache through configuration change. There's no extra programming but it is mapped to a specific cache. So, that's why our customers typically have three caches; object cache, session cache and reference cache. For reference cache they use a Client Cache, for the other two they don't.
Easy to Configure Client Cache
Now, why don't they do a Client Cache with the session cache? Actually, because the performance slows down. The reason is because this is only better if you do a lot more reads and writes. Because, what happens in case of a write? You do a write here and then you do write here and then then you do a write on the database. So, you're doing the write in three places. So, it doesn't add any value if you have to do more writes. You update your copy and then you update this only and then this notifies all the other Client Caches to go and update themselves. It's a delayed update, not that it's only a millisecond or two delayed but, it's still a delayed update in case of a Client Cache. There's no replication between the Client Caches. The Client Cache only synchronizes itself with the caching tier and the caching tier then propagate the updates to other Client Caches. Only if the other cache has that data. Because, in case of Client Cache, every Client Cache has different data based on your usage pattern.
Where to use Client Cache
So, let's step back, in case of reference data, every Client Cache has its own set of data So, let's say 1 to 1000, 500 to 1500 and so on. So, there's some overlap between each but they're not identical copies. What is common is that they're all subsets of this cache. So, when I update item number, let's say, 700 in this cache, it's going to go an update in the cache and the cache will know which other Client Caches have that items and they'll immediately be updated in their other caches. But, only if they all have it. So, it's not really replicated because they're not identical copies in case of Client Cache. In case of sessions, what I was actually trying to explain is, in case of session you'll have to update the Client Cache and the clustered cache, two places for no added value because for sessions you do one read and one write. So, at the time of web request, you do the read at the end of the page you do the write.
So, the write now has to be done in two places and the read is going to be done in the client cache. So, the performance actually drops if you use Client Cache with sessions or with other write intensive operations but the performance tremendously improves if you use it for more read intensive operations. Did that make sense?
So, the biggest value of a distributed cache, the fast the quickest and the biggest is session state. Almost every application has it. I just created a two-node cache cluster and you saw how long it took, maybe two minutes, in case of a NCache. So, it's really easy to create a cache cluster, of course, you want to do your testing and stuff. But, it's really easy. There's no engineering effort. When there's no engineering effort, your schedules are much easier to deal with. You only have to do sanity testing to go through. I would strongly recommend, if you're going to start using a distributed cache, use it for sessions state in the beginning as the first step and then jump into the object caching which we'll talk about in a minute.
Application Data Caching
So, we've talked about the session caching. Let's quickly go into the application data caching. Here's what a typical NCache API looks like which it looks a lot similar to ASP.NET cache if you notice, there's a connection.
Cache cache = NCache.InitializeCache("myCache");
cache.Dispose();Employee employee = (Employee) cache.Get("Employee:1000");
Employee employee = (Employee) cache["Employee:1000"];
bool isPresent = cache.Contains("Employee:1000");cache.Add("Employee:1000", employee);
cache.AddAsync("Employee:1000", employee);
cache.Insert("Employee:1000", employee);
cache.InsertAsync("Employee:1000", employee);
cache["Employee:1000"] = employee;
Employee employee = (Employee) cache.Remove("Employee:1000");
cache.RemoveAsync("Employee:1000");So, you connect with the cache based on the name and you just create a cache with the name. That's why I gave you that demonstration so that you would understand what that meant. And, this cache handle is something that you preserve just that you would preserve a database handle. And, then you use that Cache handle to do a Cache.Get. Every Get, every operation, it has a key. A key is a string in case of NCache and then you format the key based on what you're doing with it. So, in case of an individual object, a good practice is to just specify the class name, maybe the attribute name and the value. And then you can get that. So, there's a Get and Get.Contains, Add, AddAsync. Async means don't wait.
Well, what happens is, underneath it, there's de-serialization happening on the client end. So, the client, we're going to do a Cache.Add, let's say, you're giving it an object, it's an employee object, it's going to serialize it based on either the standard .NET serialization or the custom NCache serialization. And, then create that into byte array and send the byte array to the Cache. NCache does more than that because you may need to index certain attributes. It extracts the values of those. Yeah it will. It will. It immediately. Yeah! Every object that you Cache has to go through serialization.
So, as soon as you turn the application on, it it's going to throw exceptions. If you're using ASP.NET cache object, you don't have to serialize. So, you can pretty much Cache everything and a lot of the time what happens is your own objects are may be easier to serialize but you may be using some third party. Let's say, previously the data table object didn't use to be serialized but now it is. So, if you're using third-party objects which are not serializable you have no control. So, you can't catch them if you're going to use a distributed cache. In case of NCache, we have our own custom serialization where you can identify those objects. NCache then creates the serialization code for you at runtime and compiles it in memory. So, that allows you to use also those objects which are not serializable. But, this serialization happens immediately. So, your application will not work if it is not using proper serialization.
Async essentially says don't wait for the cache to be updated. So, I can continue. I trust the cache will add this thing. So, they don't unlock the database where the updates can fail on data integrity issues. A cache does not have data integrity issues. It only fails when you have crashes. When you are out of memory or something else happens. So, you can pretty much rest assured that whatever you're adding, you're going to most likely add it in the cache. So, Async still gives you a further boost. So, the API looks very straightforward as you can see.
Keeping Cache Fresh
So, when you do application data caching, how do you keep the cache fresh? This is really really important. There are different ways that you can cache.

Using Time based Expirations
Expirations, almost all caches support expirations. There's an absolute expiration where you get this specify for every item, here's how long I feel comfortable for it to stay in the cache, this could be anywhere from 15 seconds to, hours and days and weeks. And, that's for application data caching. There's another expiration called sliding expiration which is not for synchronizing the cache with the database. It is for cleanup. So, that ASP.NET, all the transient data that we talked about, well, what happens when you're done with that data? You shouldn't have to worry about cleaning it up. So, you can specify a sliding expiration and say if nobody uses this data for this long, let's say, in case of sessions 20 minutes, if nobody uses the session for that 20 minutes, remove it from the cache. So, that's more of a cleanup.
What are the risks in expiration? Expiration is actually, you're making a guess. You're saying, I think I'm okay with five minutes but, there's no guarantee that nobody's going to update that data in the database in that time especially if you have other applications or other processes updating the database. So, expirations are good only in limited use cases.
Using Database Depedencies
Another very important feature is that you may have an unexpected or unpredictable updates in the database. If that is the case then the cache should have the ability to synchronize itself with the database. So, the cache should know about your database. It should become a client of your database and monitor your database for any changes. There's a feature in ADO.NET called SQL dependency. Has anybody seen that?
So, SQL dependency is what NCache uses to become a client of your SQL server or your Oracle database. So, in case of SQL server you can use the, the SQL dependency the SQL server ADO.NET Feature that NCache uses to get events from the database. The Cache, NCache becomes a client of your database. It receives events and then based on that it does its own thing. In some cases you don't have events. So, let's say, if you had db2 or MySQL, they don't have events. So, then the cache should be able to do polling. NCache also supports the polling based. So, you do the same thing, you cache this item in the cache and you said this maps to this row in this table and then NCache will do the polling and then if that data changes it will again either remove it from the cache or reload a new copy. But, this feature, it gives you a lot of comfort.
Again, that same thing that I was talking about which is that you want to make sure that Cache is always synchronized with the database. Expiration is good enough for only a small subset of the use cases.
So, you will get a cache miss if you don't do an auto reload. So, when you when the SQL dependency fires up, it removes, NCache removes the item from the cache. So, if your application then wants it, it's gonna be a cache miss and then you'll be forced to go and get a new copy from the database. If you don't want a cache miss which is in many of the e-commerce applications because they are reading data so frequently that they didn't want anything to increase the load on the database, so, you would actually use the SQL dependency with this feature called read through.
Actually, I need to show you some code otherwise it starts to get very boring. So, let me quickly show you. So, I have just a very simple console application. In case of NCache, all you have to do is add some assemblies here. So, there's NCache.Runtime and NCache.Web. Then you specify some namespaces these two and then you connect to the Cache and you've got your Cache handle and, then you create an object and then you do Cache.Add. And, you specify key. This is not a good key. I meant to change it, but, your key should have the actual value in it. So, you do a Cache.Add and you specify the object.
In this case, I'm also using an absolute expiration of one minute. So, you specify the absolute expiration and that's it. That's all you do to add this to the Cache. Next time you need it, you'll just do a Cache.Get, specify the same key and you'll get the object back. Very very straightforward for an absolutely expiration. You could do the same thing for sliding expiration. Although, instead of specifying an absolute value you have to specify an interval like 10 minutes or 20 minutes. SQL dependency is what I wanted to show you. What it looks like. There! So, the same type of an application. You just need to add these two here and you specify the namespaces and then when you go and add the stuff to the Cache that's when you specify SQL dependency.
Let me just go to the definition of it. So, I'm going to be adding this to the Cache here. So, I've got my key which is what I showed you last time. Now instead of adding the object I'm going to add a Cache item. That's an NCache structure. So, it stores the actual object and it'll also store a SQL dependency. So, NCache has a Cache dependency Object. So, I do a new SQL Cache dependency. That's an NCache class which internally maps to SQLs servers SQL dependency. So, you pass it a connection string and the connection string is your SQL server connection string and you pass it a SQL statement. So, here in my case, I specified select this where product ID is whatever my value is. So, I'm just mapping it to one row in the product table. And, by specifying this that much, I have now just told NCache to become a client of the SQL server. And, remove this item if this changes, if this row changes in the database.
So, it depends on what the SQL statement is. So, if the sequence method contains only one row it maps to do only one row and that's what it's going to be. Usually you can't do joins in this and that's the limitation of the SQL dependency feature in ADO.NET but, for a single table you can easily do this. So, that's how you would do the…
So, SQL server has this thing called SQL broker. So, it actually, creates a data set or a data structure on the SQL server end to monitor these data sets. So, all the SQL dependencies that you create, SQL server creates data structures to go and monitor the data sets. And, based on that it sends you a SQL notification.
So, you do have to configure this on the SQL server end because it's a security thing also so your DB has to get involved in configuring the SQL server but, it's pretty straightforward. I mean there's no programming or anything needed on the server and just a configuration. All the stuff is taken care of by the client side.
Read-through & Write-through
Okay! So, we've done the SQL dependency. I wanted to show you so if you don't want to remove this item from the cache, you can do a reload through a read-through. So, read-through is another very very powerful feature.

Read-through is a server-side code. Actually, read through is your code that runs on the cache cluster. So, you actually register your code and it runs on the cache cluster. It is called bi NCache. And, the value of a read-through… let me first show you what read-through looks like and I'll show you what the value is, I mean why do you want to do the read-through. So, here's what a typical read-through looks like. It's an IReadThrough interface. You do an InIt so that you can connect to your data sources. You do a dispose, of course, and then there's a load from source. It passes your key and it expects and a cache items back. So, cache item contains your object and a bunch of other things that you can specify expirations and other things inside it. Very simple interface.
This is called by NCache So, you implement this interface and you register your assembly. In case of NCache, you register your assembly with the Cache and now when you do a Cache.Get and that item does not exist in the cache, cache will actually, NCache will call your read-through to go and get it from your data sources. Your data source could be a database, it could be a mainframe, any data source. So, by having a read-through you can ensure that a cache always has the data and as far as what the application sees. So, that's one benefit.
The second benefit is the reload that… So, you can actually combine read through. So, you can on expiration and database synchronization, when the item was otherwise going to be removed from the cache and you don't want it to remove because you're just going to reload it again anyway. So, why not have the cache reload it for you that way because if you, just think of this, you've got millions of items in the cache and they're all expiring all the time, right? Because that's how you've configured it. And, you have an e-commerce and a really high traffic application and every time something expires, you have a lot of simultaneous requests for it. They'll all go to the database. So, suddenly the database traffic has gone up for no reason, even though you just, you don't need it in the cache anyway.
So, since that keeps happening all the time you'll see a lot of spike in the database traffic despite having of cache. So, that's where, by having a reload means that it is never removed from the cache. It just gets updated. So, your applications will never go to the database. They'll keep getting the old copy up and until the point that you update it. So, you've suddenly removed or taken care of that issue where even though you had the cache you were seeing a lot of spikes in the database traffic because of the expirations or the database synchronization. So, by having the cache reload this through the read-through, really really makes it very powerful.
The other benefit of read through, of course, is that you're centralizing, you're simplifying the application tier because more and more of the database access is done by the cache. So, if you have multiple applications, accessing the same data, you can truly centralize the data access within the caching tier. Of course, you can't do it for all data but for a lot of the data you can.
Write-through works in the same fashion as read-through. Let me just go to the write-through. It works in the same fashion. It's got a write-through provider, again InIt, disposed and now instead of load it's a write to data source and it's got another type of bulk write. Write-through, one benefit is the same as read through which is you centralize everything. Second benefit is that you can do a write- behind which is that you update the cache which is, as I said, ten times faster than the database and then you ask the cache to go and update the database. And, the write-behind is essentially the same as write-through but, done in an asynchronous fashion. It's a queue that gets created and it gets processed. That queue is also replicated in case of NCache. So, none of the updates are lost if any one server goes down. But, the write- behind really speeds up the application because, I mean, you already made it faster by caching to doing all the reads, right? So, about 70 to 80 percent of the reads are now or the transactions are going to the cache anyway. Why not also speed up the writes? If you can do it in a write-behind fashion, if you can afford to do an async write. If the data is too sensitive where you cannot afford then you do a write-through then you only get the first benefit which is centralization of the code. The second benefit of faster performance comes only if you can do async.
Conclusion
The whole idea is that when you start to do caching, don't think of a cache that's just a simple key value here, I mean, my whole purpose of this was first to convince you that you really need a distributed cache as part of your infrastructure and the application architecture. If you want the applications to scale, you must incorporate this independent of which caching product you use, I mean, you just, you should have It. Currently for .NET folks, the options in the market are NCache which is an open source and also commercial. There's Redis that Microsoft has made available on Azure at least. On Azure it's a managed cache service, outside of it you have to install it and it mainly installs on Linux unless you use the open-source unsupported version. On the Java side, there's a lot more options on the caching. So, that was the first of all.
Second goal you should understand, it's not a simple key value. You want to make sure that you can Cache all sorts of data and handle all sorts of situations that's where you get the real benefit. And, I haven't even gotten to the other part because I'm actually, running out of time which was, for example, how do you do runtime data sharing and what are some of the architectural things that you want to make sure that the cache is always dynamic so you can configure things. It's part of your data center, it's part of your production environment. So, any cache that does not let you make changes at runtime is not a good cache to pick because. Then you'll be stuck with a lot of down times then, we have customers that have scheduled down times once a year, you know. So, some of our customers don't even have that because they have such a high availability.
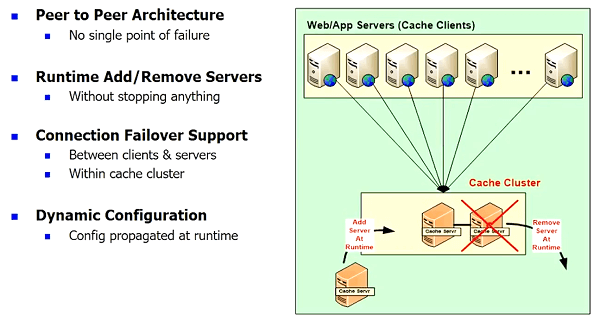
They want to even upgrade the cache itself a new version without a downtime. So, I mean, it depends on what are your business requirements. But, all of those things have to be factored in, a lot of people have multiple data centers now. At least for DR purposes and then also for geographical load balancing, if you have that, you expect your database to replicate, right?
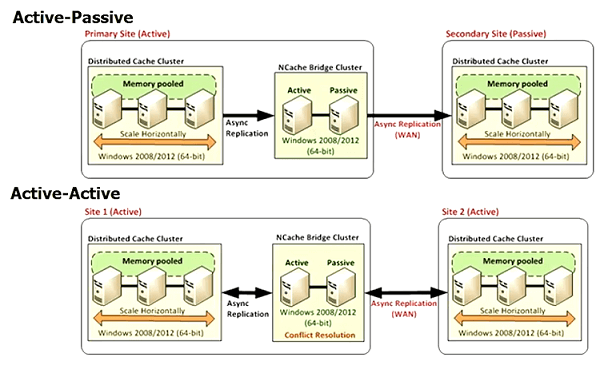
So, why shouldn't the cache be able to support multiple data centers? Because, the less a cache can do the more you would have to do. That's the bottom line. Because, your application needs will not change, the cache has to accommodate. So, keep all that in mind.
So, there's a comparison between NCache and Redis.

They're both open source. NCache also has Enterprise Edition. So, basically if your .NET, NCache fits in very nicely. In the NCache, N stands for .NET, bottom line, I mean that's how committed we are to .NET.