Orlando Code Camp
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
Your .NET applications may experience database or storage bottlenecks due to growth in transaction load. Learn how to remove bottlenecks and scale your .NET applications using distributed caching. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
Today's talk is not about NCache, it's about distributed caching. I will refer to NCache as an example but the concepts are overall, so they apply to all the caches.
What is Scalability
Okay! Let's get a few definitions out of the way first. The first definition is Scalability. Scalability is not application performance. If you have five users and your application performs super-fast, your application is not scalable until it can have the same good performance with five thousand users, fifty thousand or five hundred thousand. So, scalability is about high performance under peak loads. People sometimes confuse performance with scalability. Your application may not have good performance with five users in which case caching was not going to help you, you have other issues to solve.
Linear Scalability
Linear Scalability is, if your application is architected in such a way that you can add more servers and by adding more servers you can increase the transaction capacity. Again, the scalability we're defining in terms of transaction capacity in terms of how many users how many transactions per second can your application handle. So, if your application can handle more linearly more transactions as you add more servers then your linearly scalable and our goal is to be a linear scale to have a linear scalability in our application.
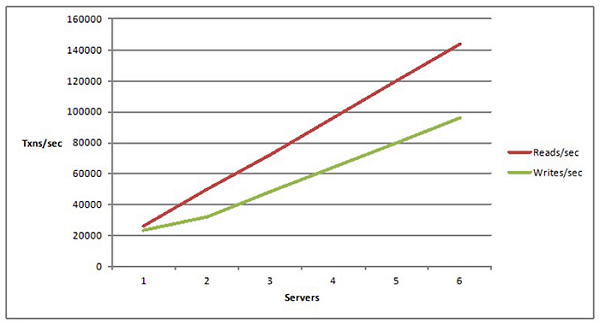
Non-Linear Scalability
And, we definitely do not want nonlinear scalability which is that your application is architected in such a way that after a certain point, it doesn't really matter if you add more servers your application is not going to increase in fact it's going to probably drop. That means there are some bottlenecks somewhere that have not been addressed.
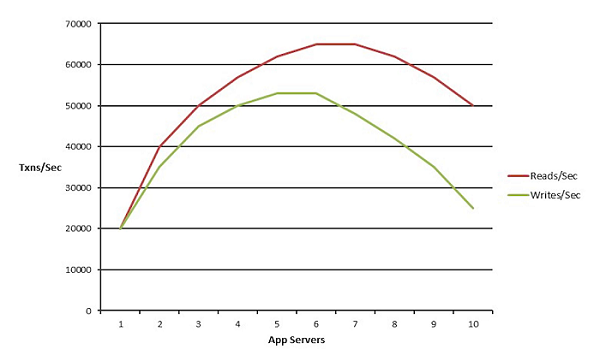
Which Apps Need Scalability?
So, why do we want scalability and which applications need scalability?

Usually, these are applications which are server-side applications. These are ASP.NET now ASP.NET core, Web Services, IOT backends, big data processing. Although big data processing is not common on .NET side, it is more at Java phenomena but it should be able to you should be able to do it with .NET as well but big data processing apps also needs scalability and any other server applications. For example, you may be a bank and you've got millions of customers and they call and change address or maybe issue or ask for a new card or maybe they transfer funds and you have to process all of those requests in a batch mode at night and there are some compliance requirements that you have to get them done before the next business day. So, as you get more and more of these, even your other batch processing applications need to be scalable. So, it's not just these applications. Any other applications that just need to process a lot of transactions in a compressed time and that compressed time in these cases is transactions per second and that compressed time in this case could be within that compliance requirement. So, if you have any of these applications that are high traffic or high transactions then you've come to the right talk.
Scalability Problem
So, where is the scalability problem? Why are we even having this conversation? It's definitely not in the application tier you your application tier scales very nicely, you have a load balancer and you can add more and more servers. Everything looks very nice. The problem really is in your database, your data storage. And, by that I mean relational databases or mainframe legacy data. And, you cannot scale these in the same fashion that you can scale the application tier. The reason is because the data in this is not distributed. The nature of the database is that it has to be all put together. And, the same goes with mainframe. So, the database might be very fast. It might be doing in memory caching in it on the server end but it's not scaling and NoSQL databases.
Although the one of the reasons people use NoSQL is for scalability of transactions, the other is for scalability of data in terms, let's say, you have terabytes and terabytes of data that NoSQL is much more suitable for that. And, that third reason people use it because JSON documents give this flexibility of schema. But, NoSQL databases are not always able to help you and the reason is because they require you to move data away from relational databases into a NoSQL database. What if you're not able to do that for a variety of reasons, both technical and business. Some of the data has to stay in your relational databases and in your legacy mainframe data. Although, NoSQL databases are great and we have a NoSQL database that we've launched last year ourselves called NosDB, as I mentioned, but they're not going to solve your problem unless you can put data in them. So, if you have to work with relational databases, you have to solve the scalability problem that they pose and that's where a distributed cache really comes in.
Distributed Cache Deployment
A distributed cache essentially is an in-memory distributed store.
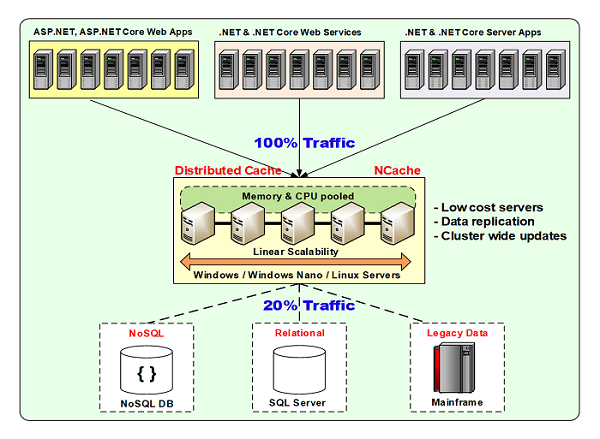
Logically speaking, it's just between the application tier and the data tier. Physically, it could be a bunch of separate VMs or it could sit on the same box as the application or some of it could be here some of it could be here and those are the things that we'll talk about. But logically, it is between the application tier and the database tier. And, the fundamental argument is that if you cache data you don't go to the database as frequently. Because, you don't go to the database it does not get all that load, so it does not become a bottleneck. If 80% of the time you can go to the caching tier and the caching tier does not have the bottleneck that a database does because it's also distributed just like a NoSQL database a caching tier is also distributing. It's a key/value. Actually, another word for a distributed cache is an in-memory NoSQL key value store because everything that you put in the distribute cache there's a key and there's a value which is your object. So, by doing that 80 percent of the time you're going here 20 percent of the time you're going to the database. Those 20 percent is mostly updates.
There’re some reads of course and those updates are also performing faster because there's no competition with read transactions and this is no longer bottleneck. Why? Because a distributed cache will form a cluster of two or more servers. These are not expensive boxes, these are not your database server type of boxes. These are typical web server configuration just like a four or eight core box just lots of memory. Lots means 16 to 32 gig is what we recommend to our customers. Some of our customers go more than 32 but we almost never recommend to go more than 64. It's better to add another box then to have more here. Because, if you add more memory then the processing power has to be upgraded. Why? Because a .NET application has this thing called garbage collection and the more memory you have to collect, the more garbage collector or the GC has to work and the CPU becomes a bottleneck in that case and your application starts to have issues. So, the sweet spot is 16 to 32 gig of memory in these VMs or physical box and most of our customers use VM's here. And, about 8 core as the hardware configuration and usually two network cards, one network card is for the clustering and one is for the clients to talk to it. The word client means your application server, so, it is not your clients. It is your application server that is the cache client.
So, a minimum of two cache servers and then a four to one or five to one ratio between the application tier and the caching tier. And, that ratio is based most on, what we've seen over the years and we've been in this space for over ten years, that if you're adding more servers here to add more activity then above our four to one or five to one ratio will give you a very good capacity. And of course, you add more servers for one of three reasons. You either need more storage because you have memory needs as we just talked about or you need more transaction capacity because you had two servers to start with and you kept adding boxes here until the discard maxed out. In a relational database, if that happens you’re stuck. You're hosed. In this case, all you do is add a third box until the capacity of the third box maxes out and then you add a fourth one and so and so forth. So, you can have as many boxes here as you can as you want. We have customers, that on average have about five to ten boxes here and some of our customers have 40 to 50 boxes here in the application tier and then they have accordingly. So, for a ten box or for a ten server application tier, you would have about three servers in the caching tier. So, that's how you do your planning.
So, the goal of the talk so far is to convince you that by having a caching tier you no longer will have a scalability bottleneck. So, whichever product whichever caching solution you use you must incorporate a caching tier in your application. So, you must architect your application to have a cache in your picture and that way you will never have the bottlenecks.
Use Cases of Distributed Cache
So, now that we are convinced that you should use the cache as a .NET developer, The next question that comes to mind is where should you use it? How should you use it?

And, the first use case is application data caching that I've been talking about up until now which is you have application data in a database and you cache it here, so you don't have to go to the database, this same thing.
App Data Caching
The one thing to keep in mind about this use case is that the data now exists in two places one is the master which is the database and one is the cache which isn't which is the other place. So, if your data exists in two places what will go wrong? If you have two copies of it the biggest concern is, is the cache going to be fresh, is the cache going to have the same version of data as the database because if the cache is not going to have the same version of data then you will be forced to cache read-only data. And, read-only data is about 10-15 percent of your total data. So, you're not really benefiting well. You are benefitting but you're not benefiting to the extent that you should to really make your application scalable.
So, in fact it's so much so that if you ask an average person what is a cache used for. They'd say well I'll just put my read-only data in it. Everybody's scared of caching transactional data. Your customers, your accounts or activities data that changes every 30 seconds, every one minute, every five minutes or in an unpredictable way. So, people are afraid to cache that for this reason because there are two copies of it and what if the cache does not know that you've changed it in the database. So, let's keep that in mind as we continue further.
ASP.NET Specific Caching
The second use case is, if you have an ASP.NET application, the most commonly known is the session state. And that's also, the anything in this one, the first example is session state. Sessions are something that by default, you have two storage options. One is InProc, the other is SQL, that Microsoft provides. On an on-prem there's also a state server but all three options have scalability problems. SQL server has performance issues. The same reason that we won't have caching to begin with. When you store sessions in SQL, they're stored as blobs. The relation is SQL like all relational databases was not designed for blob storage, it's for structured data. So, it does not perform. There are a lot of issues. Most of our customers when they go to NCache, the first use case is session state. That because that gets their immediate benefit. And, the really nice thing about session state is that there's no programming because there's a framework that Microsoft provides which allows a third-party cache like NCache to plug in and everything just here is stored in the cache.
The other aspect of ASP.NET is if you don't have the MVC framework, if you're in the pre MVC framework which a lot of ASP.NET applications still are, then there's a thing called view state. And, for those of you who don't know what view state is, it's an encrypted string that is sent by your web server to the browser only to be brought back on a post back. So, it could be hundreds of kilobytes of encrypted strength that just go and come back. And, when you multiply that by millions of transactions that your application is going to process, that's a lot of bandwidth at the minimum. And, bandwidth is not free by the way it's pretty expensive.
And, second of course is that but when you have to send that heavy of a payload your performance, your response time is slower. So, it would be much so much nicer if you just if you could just cache the view state on the server end send a small key, so when the post back happens, the key comes back and view state is fetched from the cache and presented to the page. So, that's the second use case. Again, same way, there's no programming involved, you just plug in a third-party cache like NCache.
The third use case is the ASP.NET output cache. This cache is the page output. If the page output does not change, Microsoft already has a framework that caches it in a local standalone InProc. It's better to put in a third distributed cache in place of it, so that in a web farm the first time a page output is cached, it's available to the entire web farm instead of every web server caching its own copy.
So, those are the three use cases for ASP.NET applications in addition to application data caching.
Now the nature of the problem here is completely different here. In this one you had two copies of the data. Here, the cache is the master store. So, you’re no longer storing sessions in the database. You're no longer storing view state anywhere else. So, the cache is the master store and it's an in-memory store. So, when an in-memory store is a master store what could go wrong? memory is volatile! Yeah. So, there's no persistence. So, a good distributed cache must replicate data across multiple servers to provide data reliability, so you don't lose that session. Because, you may be an airline and you did this special weekend promotion for Hawaii and you've got two or three times the traffic on to your website and they're people who've done all sorts of searches and they're about to hit the submit button and they lose their session. You may lose that customer with thousands of dollars in sales for each customer. So, you definitely don't want to lose the session. So, don't put sessions in a cache unless it does replication.
Runtime Data Sharing
The third use case is a runtime data sharing. This is something that a lot of people did not know for a long time. People use message queues for their for sharing the events across multiple applications. But, a distributed cache gives you a very simple and powerful data focused event mechanism where, think of this now as that like a service bus or like a message bus then these are your applications that can talk to each other through this. So instead of using MSMQ or RabbitMQ, which have their own benefits a cache is not here to replace them. But, if your need is more around data or if your need of messaging is more around data and within the same data center, a distributed cache gives you a simpler interface but more importantly it's more scalable. So, if you have a higher transaction application and again, this whole talk is about scalability.
So, although you could do all of this stuff with this regular message queues. When you go into a very high transaction environment they are not distributed in the same fashion that a distributed cache is. So, a distributed cache will allow you to do all of this. Let's say Pub/Sub type of a data sharing, there are event notifications, there's a continuous query feature that NCache has which also Java caches have, that Redis does not, with which you can just share data across applications in a very seamless fashion. And, here also the problem is similar to application the ASP.NET specific caching because although this data probably exists in a database but not in the form that you're sharing it.
So, you've probably transformed it into some of the form before you're trying to share it so that transformed form is being kept in the cache. So, you don't want to lose that data so a cache must replicate data. Actually, even for application data caching, although technically, you could, if you lose some data because one cache server goes down and you did not replicate. You could technically reload that data from the database. There's no problem except there's a performance hit because, whatever let's say, if it was 16 gig of data that you lost, now you have to go through 16 gig of database hits which you don't want to do. So, most of our customers, even for application data caching, choose to replicate because memory is so cheap. They don't want to even take that performance hit. With these two, of course, you have to have it but in this one they it's a sort of it's good to have.
Hands-on Demo
Okay, before we move forward about how to do this, I want to first show you what a cache looks like. I'm going to use NCache as the example here.
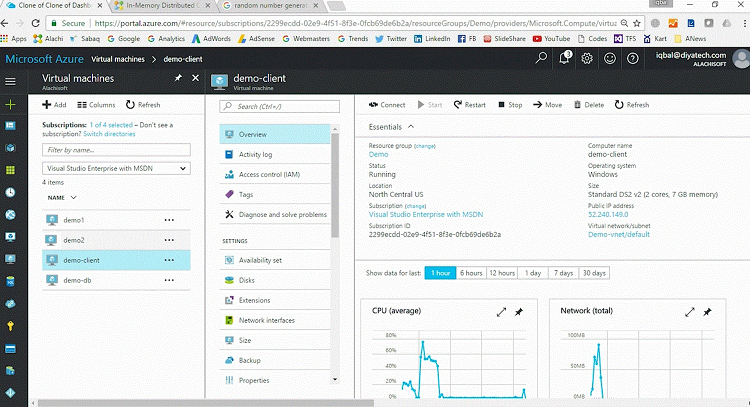
Setting up an Environment
So, I have in the azure I've got three VMs demo1, demo2 and demo-client. demo1 and 2 are going to be my cache server VMs and demo-client is my application server VM. In your case, let's say you'll have two cache VMs and then four to five, four to one or five to one ratio of the client VMs.
So, I am logged in to demo client and I'm going to use this tool that NCache has called NCache manager. So, I have it started here. I'm going to come here and say create a new clustered cache.
Create a Clustered Cache
All caches in NCache are named, so I'm just going to name it democache, I'm not going to go into the details of what each of these mean I will talk about this in a bit but I will pick a partitioned replica topology. In case of NCache, a topology means how is the data stored and replicated? A partitioned replica topology is something that.. if I were to come back if I were to come here, think about this as a two-node cache cluster that would put about to create.
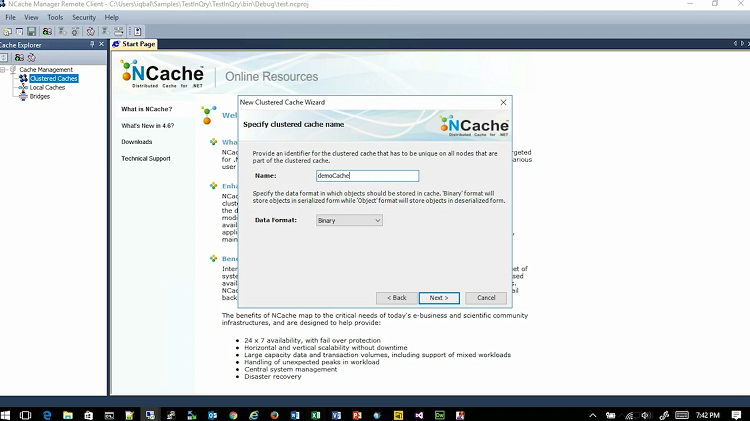
If it's a partitioned replica then every server is going to have one partition. So, there'll be a total of two partitions. In case of NCache, the entire cache has about a thousand buckets, so about half of them will go to partition one, half of them going to partition two.
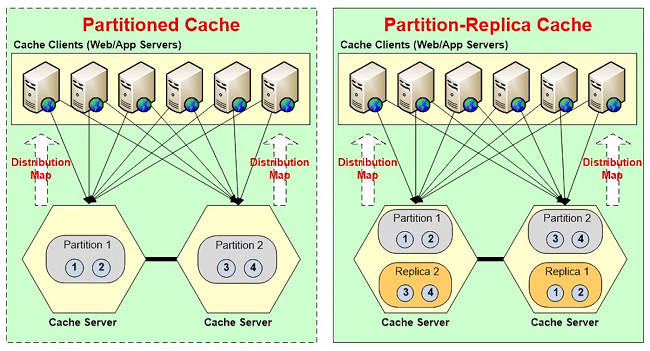
Each partition is backed up onto a different server that is called a replica. The replica in case of NCache is passive which means that no client talks to the replicas, only the partition talks to the replicas. And, the replica becomes active only when the when its primary partition or when the partition goes down.
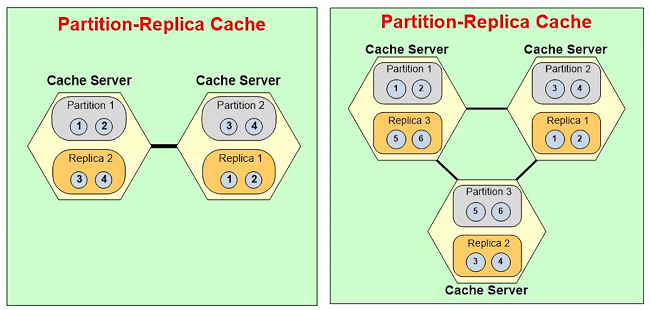
Which means, let's say, if this server were to go, let's say, if we had a three-node cluster and partition let's say server three went down, partition three is down now. So, replica three will automatically become partition three, so that you don't lose any data. So, partitioned replicas gives you this storage and replication strategies. It essentially tells you that data has to be replicated. There's a synchronous and an async replication also. So, anyway, so I'll come back to this but I wanted to just show you what that means. So, I'm going to pick an asynchronous replication between partition and the replicas. Then I will specify my cache server, so the first one is demo1, second one is demo2. Now, everything that I'm saying in case of NCache, you can script it completely, so that can be automated. I will leave all the default. That's the TCP port on which the cache clusters formed. I'm going to specify how much memory I want the cache to use on this server and the cache will not use more than this memory. So, whatever I specify here is this times two because. There's a partition and there's a replica.
So, this is the size of a partition. So, in your case it's going to be a lot more than this of course because, if you have 16 gigs in a cache server you should leave about 2 to 2.5 gigs for operating system and other processes and allocate the rest. So, let's say, from a 16 gig you have 13 and a half gig left, but 13 and a half divided by 2 would be a partition size and then NCache will make sure that it does not use more than this memory. So, when that much memory is consumed the cache is considered full in case of NCache. And, then NCache has one of two options. One, you can tell NCache will reject any new additions of the data until some of the data automatically expires or you can do what this thing called eviction. So, NCache gives you three eviction algorithms LRU, LFU and priority FIFO. So, you can say in this case, evict 5% of the cache.
So now I want to talk about this a little bit in the context of, let's say that you're storing in each of the use case here. If you're doing application data caching, eviction is perfectly OK. There's no problem. You just used up the memory that you had evict some of the least recently used and then make room for new data. So, it becomes like a moving window, right? So, as you use more and more data the older one is removed and the new one. So, that's the most commonly used. But, what if it's a session? If the cache is being used to store sessions, you don't want evictions. Why don't you want it eviction? Because, the session might still be active. It might not have gone through that 20 minutes or whatever your timeout is. If that's the case and you still evict the session, you are forcing that same problem we just talked about which is that a user hasn't logged out but you're kicking. So, what you need to do is, do your capacity planning. In case of NCache, you can do that very easily, can see how much memory an average session is consuming and then do your capacity planning. Extrapolate how much memory is going to be used. Do the capacity that this other session storage will never be evicted. Application data storage or application data cache can be evicted, no problem. But, the session cache should not be evicted. It should only expire when the user no longer uses the session.
So, I'm going to just say finish and I have a two-node cache cluster. I will come here and I will add a client node. In my case I only have one client node as I said. I think I probably don't have the cache so we started. I need that service so the NCache manager can talk to this and do the configuration. Okay! Now that I've done this, I'm going to come here and say start the cache. So now by starting the cache, NCache is building a cluster between these two boxes, to that TCP.
Simulate Stress and Monitor Cache Statistics
So, that you don't actually then get into the details of which boxes have what data and whether the cluster. You just know that there's a democache. Whenever you connect to that cache, your application will automatically connect to all the servers in case of partitioned replicas. So, NCache takes care of all the details and I'm going to come here and say view statistics and these are some PerfMon counters on so that you can see what NCache will do but once you start to use it. I will also start this tool called NCache monitor. And, it's is like a dashboard style tool. And, in case of NCache, you have this option of using a stress test tool which allows you to very quickly simulate your application usage without any programming.
So, for example, I'm going to say stress test tool democache so it's going to do one get one put and stuff like that. And suddenly, now you'll see that this tool is talking to both of the cache servers and it's doing about 700 requests per second on each box, about 7 to 800 even up to a thousand. Let's say I want to increase the load. So, I want to launch one more stress test tool.
This is like you would do with your application. I mean, when you want to test you you’ll with your application, you'll run your application with some stress testing tool and then you'll keep adding more and more stress and then you want to see whether the whole system works. So, right now you're just testing the cache component of it. Most of our customers what they do when they evaluate NCache, they do this benchmarking. So, once they've configured that everything in their environment, even though we have published our benchmarks they don't. I mean they verify everything in their own environment. So, as you add more and more of this, you'll see that this load has just doubled.
Let me go one more stress test tool. You'll see that it keeps going up. Right there, see! So, I can keep adding more and more stress test tools, until I can either max out my client CPU. So, I've gone to about 50 percent on my application server. So, I can definitely add more stress tests tools. Once I max out that client, I will add one more client. So, that's how I can. So, even right now, for example, we're doing about 5,000 requests per second with just three stress test tool. So, with this and then you can also monitor for example here all of this stuff. So, with this you can actually see what a cache looks like. And now, let's go into more from a dev perspective.
ASP.NET Specific Caching
So, now that you know what a cache looks like, let's see how to use that cache within your application. So, for ASP.NET, as I said the first thing that you should do is use the cache for sessions. Why? Because it's the easiest. There's no programming, there's no effort you can do it. I just showed you how fast you can configure a cache with interest of NCache, let's say if I were to come here and I go into some of the sample code should have had them opened already but I don't. So, here's an ASP.NET application for you to use NCache with ASP.NET for sessions. You have to just go and modify web.config. So, I've got the web.config. The first thing you have to do is add this assembly line at assembly. NCache, this session store provider is NCache assembly that has implemented the ASP.NET session store provider interface. So, this is what allows NCache to plug in. So, you can just copy the line here and then you just come to the session state tag, which is right here. In case of NCache, you just copy that tag. Make sure that this the mode is custom because that's what allows that third party cache to plug in. The timeout is what you want it to be and then the only thing that you need in case of NCache is to make sure the cache name is specified.
So, once you have installed NCache then on the cache servers you install the server portion, on the application server you install the client portion of NCache, you create the cache like we just did and you update this and that's all. That's all the effort you need to start using NCache and then every session is one object in the cache. When you do that in that PerfMon counter, you'll see how many sessions you're seeing. What happens typically, our customers create three caches. So, we just made one cache here, right? So, our customers will make three caches. One of the caches is for sessions. So, they have a separate cache for sessions. One of the cache and two caches are for application data. One is what they call the reference data. The other is the transactional data. Transactional data is something that changes very frequently. And, the reason they do that is because of some of the other features that I'll go into. But, on the same VM’s, you can have more than one cache created. So, that's all you have to do for the session state storage, it's very easy, no programming needed and then you’re all good to go.
App Data Caching
But, if you want to do application data caching, unfortunately in the .NET space EF core now finally provides an architecture where you can plug in a third-party cache.

NCache also supports it. But, until EF6 including EF6, the architecture did not really support plugging in a third-party cache. NHibernate for a long time supported that architecture. So, for NHibernate NCache can plug in without any programming. So, even application data caching with minimum features, you can just do without doing any API calls. But, for most part, you have to be mentally prepared there for application data caching, you will have to do programming. But it's a very simple API. This API looks very much like an ASP.NET cache object. You connect with the cache with a cache name.
Let me just quickly show you what this looks like. Let me open… I ran into some Azure VM issues. I start this other stuff other at this all open. So, let's say that I've got this really basic console application. The first thing that you have to do is link two of the NCache assemblies, one is NCache.Runtime, the other is NCache.Web. NCache.Web is the actual API that you're calling. Then you link these two or you use these two namespaces again NCache.Runtime and then .Web.Caching. At the beginning of your application, you connect to the cache based on a name and you get a cache handle just like for database. Of course, in an ASP.NET application you'll probably do it in the global.ASAX in the application start or the InIt method. Then you just create your object and you do Cache.Add. The Cache.Add will use a key, some sort of string. This is not a good key, your key needs to be much more specific and then here's your object and that's it. You make that call and behind the scenes now this is going. Let's say, if you had that partitioned replica topology, what's going to happen is your application is connected. So, every box is connected all the cache servers. So, you just did a Cache.Add right? So, Cache.Add will go and look at the distribution map which is like the bucket map. Every bucket has a key value range in terms of a hash key value range in terms of what keys can go into this bucket. So, it's going to use that bucket map to know which server it should go and talk to because it's connected to all of them, right?
And, it's going to go and let's say you were adding item number three here. It's going to go and add item number three here and if you had enabled async replication the application will go back and application is done. The cache will now, this partition knows it needs to replicate this here. So, it will asynchronously, in a bulk operation, replicate this to the other box and you'll immediately have that item in two places. So, that's what that Cache.Add did under the covers.
Okay, I'm going back and forth because I wanted to just sort of so that kind of give you an overview but a cache looks like, how to create it, what an API looks like.
App Data Caching Features
Now, let's go into what are the issues that you have to solve in using the cache for application data caching.
Keep Cache Fresh
We talked about that keeping the cache fresh, right? So, how do you keep the cache fresh? How do you make sure that a cache is fresh?

The most common and the one that everybody supports including Redis is expiration. The absolute expiration. So, when you're adding something to the cache, let's say, even here you specify an expiration here, which is let's say you're saying expire this after one minute. When you say this in case of NCache, NCache will create indices on the server and we'll monitor that data and will expire this after one minute. So, actually it's that, it'll actually specifies an absolute date time value that was one minute from now. NCache knows that on that day time value it needs to expire that item. So, that is how the cache automatically takes care of making sure that data is removed. And, what does that mean really? That means that you're saying to the cache that I really don't feel comfortable keeping this data for more than a minute or more than five minutes because I think somebody's going to change it in the database. So, it's only safe to keep it in the cache for that long. There's another expiration called sliding expiration which sounds like the same but its purpose is totally different. The sliding expiration is used mainly for clean up. So, if you have sessions you use the sliding expiration to clean up after nobody is using this session. So, when somebody logs out after 20 minutes of inactivity the session will be considered expired. So, it'll be automatically removed.
Using Database DependenciesBut, that has nothing to do with keeping the cache fresh. The absolute expiration is the one that keeps the cache fresh. But, there's a big problem with absolute expiration. And, the problem is that you're making a guess that it's safe to keep the data for that in the cache for that long and that guess is not always accurate. So, what do you do in that case? Then, in that case you have to have the ability for the cache to synchronize itself. If it notices a change in the database, that means the cache has to know what is your database. That means the cache has to have a relationship between the cached item and something at some data in the database that you have to tell the cache and that's where there's this thing called SQL cache dependency in ADO.NET that NCache uses, which is SQL dependency and this is also called Oracle dependency, which actually works in a very simple way. But, it's a really powerful feature. And, we come here. I'm going to just use the SQL dependency. So, when you're adding something to the cache, you do the same Cache.Add, right? You have a cache key. Now, instead of the value you specify cache item which is NCache’s own data structure and in there it contains the value but it contains also, this thing called SQL cache dependency.
This SQL cache dependency is NCache’s own class but it maps to the ADO.NET SQL cache dependency. Notice, it has a connection string here and then it has a SQL statement. So, the SQL statement in this case is mapping to one row in the product table. So, what's really happening here? I mean, you are actually running this code right here. Your database is here, so you're asking the cache cluster to now connect with the database based on that connection string that you just passed it, based on that connection string and you're passing in the SQL server and you're saying please connect with my SQL server database. And, monitor SQL server to notify you, you being the cache server, if there are any changes that occur to this data set. That means if this row is either updated or deleted. If that happens, the SQL server sends a database notification to the client which is in this case is the cache server. One of these. And, then what do the cache server do? The cache server removes that item from the cache. Removing means that since it's no longer in the cache your application is forced to go and get it from the database which has the latest copy now. So, while expiration is an educated guess, this is no guess. This is an actual predictable synchronization, where it makes sure that the cache is always consistent with the database.
Now, in case of NCache, there are three different ways that you can do this. One is SQL dependency which uses database events, which is like real time. The other is NCaches own DB dependency which he uses polling and that's for those databases that don't have event notification mechanism or even for SQL server, if you think that you have too many of SQL dependencies and for every SQL dependency a SQL cache dependency is created in SQL server which is a extra data structure. Think about if you had hundreds of thousands of these created, your SQL server is going to choke. So maybe it's not a good idea if you have a lot of SQL dependencies to have that way of synchronizing. Then maybe DB dependency is much better where in one call it can synchronize thousands of rows because it has a polling table that it monitors.
And, there's a third way which is to actually just write a CLR stored procedure have it called by your trigger. So, if you have an update, insert, update or delete trigger, call this CLR procedure. And, the CLR procedure takes the data from that row, constructs that .NET object that your application is using and it stores it in the cache. Now, this is where an async API is very useful because you don't want to wait within the database transaction for a cache to be updated. It just slows down the database transactions which tend to timeout very quickly. So, it’s really advisable that if you're going to implement this mechanism that you use the async methods to go and update the data.
So, those are the three ways that you can synchronize the cache. This feature is really important because this allows you to make sure that the cache will always be fresh without which you're just making a guess. And, the same way you can synchronize the cache with non-relational databases. There's a custom dependency feature that NCache has which is your code that NCache calls that you can go and monitor your custom data store. Your custom data source could be a cloud storage. It could be whatever, it's just a whatever code you can go and check. So, keeping the cache fresh is really important and these are the ways that you can ensure that.
Read-through and Write-through
So, the next feature is read-through and write-through.

Read-through is basically, it's again your code. Now, all these features that I'm talking about NCache has them but they're not NCache only. Java caches all have them. Redis may or may not have them. So, that's what you need to do it if you if you want to do a detailed, if you want to know whether what Redis has or not, in case of NCache just come here and just go to the comparisons and there's a Redis versus NCache feature comparison. This is based on their documentation and caches documentation. So, you can actually download this and go through all of these features. So, read-through basically is your code that sits on the cache server. So, it looks like this. So, it is that you implement. So, let me just show you that interface so the read-through interface looks like… So, here's a read-through interface here, right? Hand cursor in NCache and there's an InIt which connects to your data source, dispose and there's a load method. So, load gives you a key and you give back an object based on whatever data you got. And, then you can specify when it should expire and stuff. The same thing goes with write -through is that you have InIt and dispose and then there's a write to source. So, the write could either be add, update or delete. Where do you use read-through write -through and why are they so important?
Read-through, first of all, so the way it works, lets you have a Cache.Get and the cache does not have the data. Cache will call your read-through to go and get it from the database. That's one benefit. Second benefit is that you can combine read-through with expiration and database synchronization. So, instead of removing that from the cache you reload it. Write-through is works the same way except there's a write-behind which means that you only update the cache in that the cache update your database. So, your updates also become superfast. So, wherever the database performance becomes a bottleneck you have a cache to kind of bail you out. Once you have the read-through, write-through implemented, you can consolidate all the persistence code or most of it in the caching tier and you can benefit from both of these feature that we just talked about.
Data Grouping & Searching Data
So, once you're keeping the cache fresh and you're also doing the read-through write-through, you're now starting to cache a lot of data. So, the cache is no longer just a key value store. I mean it's not convenient to fetch everything as a key.

You have to be able to search. You have to be able to do SQL search. So, you have to be able to do what you are used to doing with the database.

If a cache does not allow you to do SQL searching then it becomes very limiting and the same way because you cannot do joins in a cache because it's a distributed cache there are other features grouping and sub grouping and tags which allow you to group data and fetch it all in one call.
So again, making it easy for you to find data in the cache is really important if you're going to cache a lot of data. So, those features are very important.
Distributed Cache Features
I'm just going to quickly go through a few, one feature that I really wanted to touch is called near cache or client cache.
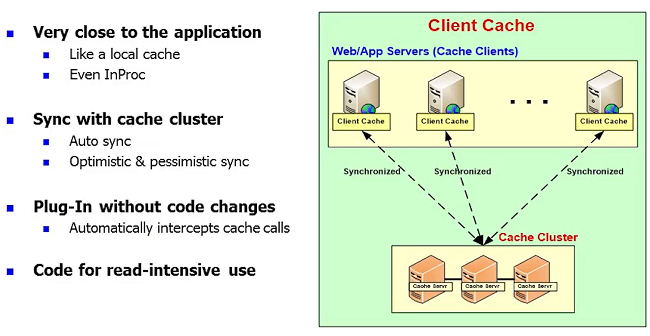
As soon as those people who are used to doing standalone InProc cache, when they move to a distributed cache suddenly their performance drops because they're going across the network. They have to go through serialization and suddenly the performance is no longer fast. Many of our customers complain, well, I was expecting my performance to go up, it has actually dropped. And, the reason is because you cannot compete with the standalone InProc cache which has the object stored on your heap. So, if you have a client cache feature that essentially is exactly a local cache which keeps that object local but it is connected to the clustered cache.
Again, this is a feature that NCache has and most of the Java caches have that will really give you that same fast performance without losing the thing.
For NCache, you can go to our website and download it's an open source cache. So, you can download the open source cache or the Enterprise Edition and, as I said, you can get all the comparisons between NCache and Redis on that.