Partition-Replica & Partitioned Topologies
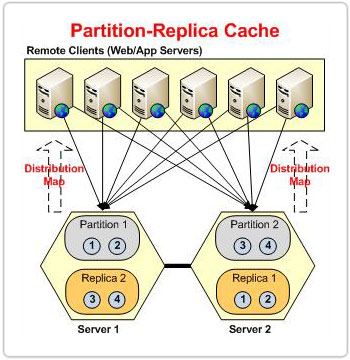
Partition-Replica is the most scalable and highly available caching topology in NCache. It scales storage and transactions linearly by distributing data across partitions and keeps a replica for each partition to achieve high availability without data loss.
In a cluster, if all server nodes have the same copy of data, it provides high availability for that data. That means the cluster can survive a few node failures without experiencing any data loss. However, this doesn't give scalability. When the data starts growing enormously, the design needs to reduce the extent of replication and start partitioning the data.
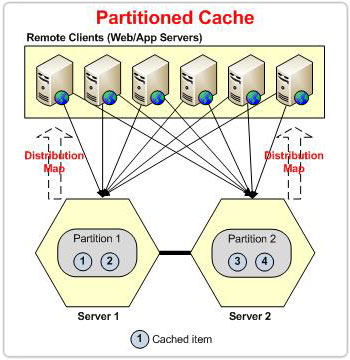
Partitioning means that you need to distribute your data among multiple nodes so that both the read and write data loading is distributed. As your data grows, you can add more server nodes in the cluster to hold more data. Each server node in a cluster is called a partition.
With partitioning the data, you can achieve scalability, but now the question is how is that data partitioned? A simple solution could be to assign data to a partition in a round-robin way, but how are we going to find a particular piece of data once it has been added to the store?
Through round-robin, we'll lose the ability to track the location of data. We need a better way of distributing the data, ensuring not only the equal distribution of data but also the ability to look it up fast.
Note
The only difference between the Partitioned and Partition-Replica topologies is that the former doesn't have replica caches, which makes it prone to data loss.
Hash-Based Data Partitioning for Partition Caches
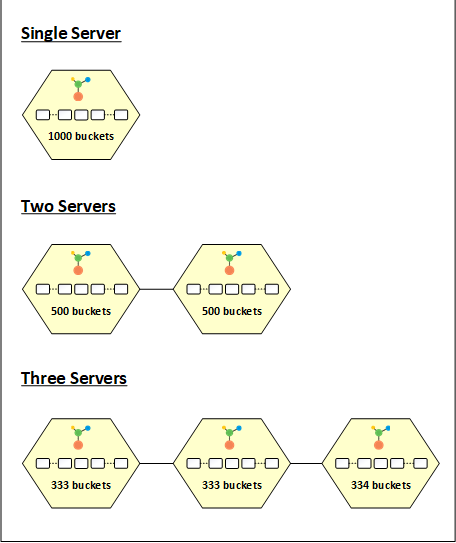
NCache divides data into multiple chunks and places these chunks in different partitions. These chunks are called buckets. There are a total of 1000 buckets that are divided equally between the nodes in the cluster. The idea here is to apply a hash function on the key of the item and mode it by the number of total buckets (1000 in this case) to get an owner bucket for this data.
Distribution Map
The coordinator server in the cluster has the responsibility to generate a map that contains the bucket distribution. This map is called the distribution map. The coordinator server shares this distribution map with the rest of the partitions in the cluster and with the connected clients. This method always gives you the same bucket address for an item, irrespective of the number of servers in the cluster. Even though the bucket may move from one partition to another at any stage, the bucket of an item can never change. That means, when a bucket moves, it takes all its data with it.
Distribution of Data According to The Distribution Map
When you start a cache cluster with a single partition, all 1000 buckets are assigned to this node. That means all data goes to this partition. When you start another node in the cluster, the buckets are equally distributed between the two partitions having 500 buckets each. Similarly, on the addition of a third node to the cluster, the buckets are again redistributed. In this case, the three nodes will have 333, 333, and 334 buckets respectively.
Similarly, when a partition leaves the cluster, the bucket distribution changes. For example, when a partition leaves a three-node cluster, the 333 or 334 buckets owned by that partition are redistributed among the remaining two nodes. Whenever there is a change in the distribution, it triggers a state transfer to rebalance the data between nodes, according to the bucket distribution.
Random Data Distribution
This method of partitioning gives you a fair amount of randomness to ensure that the data is partitioned equally between the buckets and partitions. However, with this method of partitioning, you lose control over which data should be assigned to which partition. Mostly, you would not care about where your data goes. But, in some cases, you might want the related data to be co-located. For this, you can use Location Affinity, where a hash function is applied on some part of the key instead of the whole key.
Balanced Data Distribution
Whenever buckets are redistributed between the nodes, NCache ensures that the buckets are redistributed in such a way that the size of data each partition receives is almost the same. Each partition shares the stats of the buckets it owns, at a configurable interval, with other partitions in the cluster. This helps in generating a balanced distribution map when needed, which is fair in terms of the data each partition gets. The balancing is based on the size of the data instead of the number of items. This balancing is usually ensured at the time of bucket redistribution as a result of a node leaving or joining.
Automatic and Manual Data Load Balancing
However, there is a slight chance that you may observe one or more partitions in a cluster are skewed and are receiving more load than the rest. In this case, you have an option to manually balance the data of a particular node which ensures that the data on that node is equal to the average size of data each partition receives. Then there is also a feature called 'Auto Data Load Balancing' that does the job automatically in the background. This feature is disabled by default because, if used without caution, it can cause frequent bucket redistribution and hence, unwanted state transfers between the partitions.
Size of Data Per Partition
The size of data each partition can hold is equal to the configured cache size. For example, if the configured cache size is 2GB, and the cluster size is of three partitions, the total amount of cache size on this cluster is 6GB.
So, with this topology, you're not only distributing the read and write load between the servers, but you are also increasing the capacity with every new server added to the cluster.
Partition-Replica
Now that we have covered how the Partition-Replica topology scales transaction load and storage capacity. Let's talk about how it handles high availability. Each node in the cluster has a backup of another partition that acts as a passive partition called a replica. In case of a node failure, the cache cluster knows that the data owned by the lost partition is still available in its replica. So, the client applications continue to run smoothly as the data owned by the lost partition is still served by the cluster through this replica.
The client applications directly communicate with the active partitions only. Each partition is then responsible for replicating its data to its respective replica.
Even though the degree of replication in this topology is not as much as you have in the Replicated Topology, having one backup at least ensures you that in case of a node failure, your data is still safe. As long as there aren't simultaneous node failures, the data in this topology is safe, which covers most of the scenarios.
Every cluster node has an active and a replica, and both active and replica instances exist in the same cache process on every cluster node.
Due to the existence of the replica instance on every cache node, it requires the same memory size as that of the active cache instance. This means that every Partition-Replica cache node requires double memory against its configured cache size.
All the client's added data is stored in the active node, from where it is then replicated to its dedicated replica, which is on some other node in the cluster. This arrangement of replica nodes ensures that data is not lost when an active node goes down.
Replica Selection Strategy
NCache automatically selects the replica node on the basis of the order in which the nodes are joining the cache cluster. The replica of the first node is present on the server node that has joined the cluster after the first node, and so on. And, the replica of the last node is placed on the first server node (coordinator server) of the cache cluster.
This whole replica selection process is automatic. Whenever a server node leaves the cache cluster, or a new node joins the cache cluster, the replicas are also reassigned according to the updated membership map.
Single Node Memory Consumption
Each server node (active and replica) keeps a record of the configured cache size and ensures that stored data never exceeds the specified memory limit. There are two special scenarios where this memory limit check works differently. They are explained below:
- Only one node is in a running state, and data is being added to it. The active cache instance can use twice the specified cache size to hold the data as its replica is of no use.
- In a multi-node cluster, when all other nodes leave the cluster, and only one node remains alive, data from its replica cache instance is transferred to the active cache instance. The free memory from the replica is then consumed by the active cache to accommodate the data received from the replica.
Replication Strategies
The Partition-Replica topology has two replication strategies to replicate the data from the active server node to the replica node:
Async replication: In this mode, background queues are used to replicate the data without blocking the client operations. Every write operation is queued, and dedicated background threads pick the data from this queue in chunks and replicate it to the replica instance. This replication strategy suits the application that tends to do frequent writes but doesn't want to wait for the replications to be completed before their next cache operation. However, there is a chance of data loss if a node leaves abruptly. In this case, queued operations that were not replicated will be lost.
Sync replication: With the synchronous replication mode, every write operation from the client is replicated to the replica before returning control to the client application. This replication mode ensures that both the active and replica cache instances have the same copy of the user data. If the replication fails on the replica instance, that item is removed from the active and replica cache instances.
Operation Behavior
Eviction, Expiration, Write-through/Write-behind, etc., are controlled by the active node. Whenever an active node removes an item from it on the basis of any of the mentioned features, it replicates it to its replica to remove the previously stored data from it. Similarly, Write-through/Write-behind operations are only performed from the active cache.
In Partition-Replica topology, the clients are directly connected with each server node, but only with its active partitions/instances. Albeit, there are a few situations in which the clients interact with the replica instances temporarily through cluster calls. They are explained below:
- During state transfer, when a node leaves the cluster, the client operations intended for the leaving node are served from its replica.
- When a cluster is in maintenance mode, all operations intended for the node under maintenance are served from its replica during the maintenance period.
State Transfer
State transfer is a process to auto-transfer/copy the data between the cache nodes. State transfer is triggered when a new node joins the cluster, or any current node leaves the cluster. Node leave/join also causes membership change in the cluster.
When a node receives the updated distribution map, it verifies the existence of the buckets (that were assigned to it) in its local environment. The assigned buckets that don't exist in the node's local environment are pulled one by one from other nodes. So, depending on the number of server nodes in the cache cluster, multiple buckets are transferred during state transfer.
State transfer is triggered in the following three major scenarios:
On Node Join
When a new node joins the cache cluster, the coordinator server generates a new distribution map to distribute the buckets from the current nodes to the newly joined node. And, after receiving the distribution map, the newly joined node pulls the buckets from the current nodes. During this state transfer, the newly joined node pulls one bucket at a time. After receiving one bucket, it pulls the next bucket, and so on, until it fetches all of its assigned buckets from other nodes, according to its distribution map.
On Node Leave
Similarly, state transfer is triggered when a cache node leaves the cache cluster. The coordinator server redistributes its buckets among the active nodes of the cluster. In this case, the active nodes pull the data from the leaving node's replica.
On Auto Data-Load Balancing
The Partition-Replica topology has a feature of Auto Data Load Balancing in which it continuously monitors the distribution of data among cluster nodes. And, if the data distribution is not within the expected distribution range (60% to 40%), it automatically triggers the auto data load balancing. In this case, the coordinator server regenerates a new distribution map and redistributes the buckets in such a way that all cluster nodes will have data of equal size.
Note
Data load balancing can also be performed manually from the NCache Management Center.
Whatever the reason for state transfer, this whole process is automatic and seamless. And, during state transfer, especially when a server node leaves the cache cluster, all client operations that were intended for the leaving node, are served from its replica through cluster operations.
Replicas also perform state transfer from their active nodes just like other active nodes. Replicas pull their assigned buckets from their active nodes to fetch the copy of data at the time of state transfer. However, this state transfer only takes place on bucket reassignment. Otherwise, data is replicated to the replicas through the replication mechanism.
Different Ways to Monitor State Transfer
NCache provides multiple ways to monitor state transfer in the cache cluster. They are explained below:
- Cache Logs: Whenever state transfer is triggered and stopped, it is logged in the cache logs of the cluster. Cache logs exist under the %NCHOME%/bin/log folder.
- Custom Counters: NCache also publishes custom counters that are viewable on Windows and Linux.
- Perfmon-based Counters: On Windows, NCache also publishes the state transfer counters through the Windows Perfmon tool.
- Windows Event Logs: State transfer related info/events are also published on the Windows event logs.
- Email Alerts: State transfer specific email alerts can be configured on their initiation and stoppage.
Once state transfer monitoring starts, the coordinator continuously queries all nodes in the cluster for their State Transfer status for as long as the cluster remains in State Transfer, with a 30 second interval between successive requests. Each node returns the elapsed time since it last carried out any State Transfer-related activity. If this duration exceeds 3 minutes, the State Transfer is considered stuck on that node. When a stuck State Transfer is detected, the coordinator unsets the State Transfer flag to allow cluster activities such as node join and leave.
Cluster Membership Change and Distribution Map Synchronization
As previously discussed, when a node joins or leaves the cluster, a cluster membership change occurs. As part of this process, the cluster generates an updated distribution map reflecting the new set of active nodes. Since synchronization across nodes does not occur simultaneously, there is a short period during which some nodes may be ready with the updated distribution map while others are still outdated.
Transition State for Consistency
To ensure consistency during membership changes, the cluster enters a transition state, during which:
- The last stable (cached) distribution map continues to be provided to clients.
- The updated distribution map is not shared externally until all nodes are completely synchronized.
For example, in a two-node cluster where a third node is being added, the cluster continues operating with the two-node distribution map until all three nodes are fully synchronized. Once synchronization completes, the coordinator exits the transition state and shares the updated three-node distribution map.
Once the coordinator verifies that all nodes have successfully received and applied the updated HashMap, it marks the cluster as out of the transition state. Each node then switches its cached reference to the new HashMap. The coordinator then notifies the clients of the HashMap change and instructs all cluster nodes to begin State Transfer.
This guarantees consistency between client and server during cluster membership updates.
Socket Reconnection Timeout
In a clustered environment, if the connection between two server nodes breaks, NCache automatically attempts to re-establish the connection. These reconnection attempts occur at the socket level. However, socket timeout behavior is operating-system dependent and can vary across environments. To control this behavior, NCache provides a dedicated Socket Reconnection Timeout, which defines the time required to establish a socket connection between two nodes. By default, the Socket Reconnection Timeout is set to 10 seconds, with a minimum value of 5 seconds and a maximum of 30 seconds.
This timeout ensures that cluster-level connection recovery happens within this controlled window. When two servers lose connectivity, client connected to those servers might also be affected, especially if a server becomes isolated from the rest of the cluster. To prevent internal cluster reconnection attempts from interfering with client connectivity, this timeout is set in accordance with the Client Graceful Window, and is carefully selected to provide sufficient time for server nodes to attempt reconnection without negatively impacting the client grace interval.
If a socket connection attempt does not succeed within the configured timeout:
- The attempt is terminated.
- A retry is initiated.
Important
By default, 2 reconnection retries are performed with a 2 second sleep interval.
To configure this flag, please see Server Connectivity docs.
MembershipChangeInException
MembershipChangeInException may occur at the node level when a start, stop, join, or leave operation takes place while state transfer is in progress. However, at cache level, you will face this exception on cache start. If required, a node join can be forced even during state transfer, allowing the operation to proceed while maintaining cluster consistency.
Client Connectivity
As explained in partitioning, the data is distributed among all servers in the cluster. Unlike other topologies, the client for Partitioned topologies needs to connect with all partitions, where each partition contains a subset of the total data.
The client receives a distribution map on the connect call, which educates the client about the running server nodes and their hash-based distributions. The client connects to all the server nodes to get complete data from the cache. The client gets an updated map on every cluster membership change to maintain connectivity after the completing of the transition phase. The client also receives a notification on member leave/join and resets connectivity according to the received map.
The client intelligently performs the read/write operations directly on the server node containing the key according to the hash-based distribution map it receives. For all operations where the key is not known, like SQL search, GetByTag, etc, the client broadcasts the request to all the server nodes and combines their respective responses.
If, in any case, the client fails to connect to any server node of the cluster, it does not mean it fails to write and retrieve information from that server node. For this purpose, it uses the other server nodes that it is connected to, which on its behalf requests the unreachable server node to perform operations. For example, if the client fails to connect with node1 and wants to get a key that resides in node1, it sends the request to node2, which re-routes to node1 and returns the response.
Client Grace Window
If in any case, the client fails to connect to any server node of the cluster, it does not immediately fail the operation. Instead, the client maintains a reconnection window (Client Grace Window) of 60% of the configured request timeout (i.e., 54 seconds by default). During this period, the client continues attempting to re-establish connections and queues all incoming requests temporarily. If connectivity is restored within this time, the queued operations are forwarded to the appropriate node and processed normally. If the connection cannot be restored within the grace window, the queued up operations will be failed, the client throws a connection-related exception and will have to wait for an updated map.
Maintenance Mode
When patching or upgrading hardware/software is required on an NCache server, you may not encounter application downtime. However, stopping a cache node triggers state transfer within the entire cache cluster resulting in excessive use of resources like Network, CPU, and memory. This state transfer process can be costly depending on the size of the cache data and the cluster. A typical workflow of upgrade involves restarting the cache node at a time, which requires two state transfers, one at node leave and the other at node join.
Maintenance mode is introduced to avoid these costly state transfers during maintenance on cache servers. Once a cache server is stopped for maintenance for a specified time, the replica of the node under maintenance becomes active temporarily and starts entertaining client requests. When the node (which was under maintenance) rejoins after its maintenance has concluded within the specified time, the state transfer is initiated for this node to synchronize it with the cache cluster.
The cluster exits the maintenance mode in three different states. If the maintenance node joins the cache cluster within the specified time, state transfer is initiated to synchronize the state of the cluster, and the cluster exits the maintenance mode. If the maintenance node fails to rejoin the cache cluster within the specified time, the cluster considers the node to be down, exits the maintenance mode, generates a new map, and starts the state transfer. Apart from the success and failure, there is another anomaly that exits the maintenance mode, i.e., when a node leaves. If the cluster is in the maintenance mode and any node other than the maintenance node leaves, the cluster exits the maintenance mode, and it may lead to data loss.
Split-Brain Recovery
The term Split-Brain refers to a state where one cache cluster splits into multiple sub-clusters. Cache servers in a cluster communicate through TCP. Hence, any network glitch or problem can cause a loss of communication between the servers present in a cluster. If the communication loss between the servers extends beyond a certain time, the membership map will change according to the connectivity between the servers. This results in the formation of multiple sub-clusters. These sub-clusters are called splits. We call it Split-Brain as the sub-clusters can not communicate with each other, similar to how the halves of the brain can't communicate with each other in split-brain syndrome.
All the sub-clusters are healthy and process the data they contain. Moreover, clients can connect to these sub-clusters for further read/write operations. The client receives a membership map from cluster servers to update connectivity. Here, the client can connect to any sub-cluster depending on the first map received.
Split-Brain is detected only when the communication between servers resumes, and it is discovered that all servers are up and running but not part of a single cluster. Two or more splits are possible depending on the communication loss between servers. Once Split-Brain is detected, the recovery process initiates. All splits recover one by one until all the sub-clusters merge.
The Split-Brain recovery process initiates right after its detection. It takes two healthy splits, identifies their coordinator servers, decides the winner and loser split on the basis of cluster size, acquires a lock on the loser split to restrict client activity on that cluster, and cluster membership changes. After this, all clients are redirected to the winner cluster split, and all nodes of the loser split are restarted one by one to join the winner cluster. All loser splits merge with the winner cluster split in the same way and the cluster becomes healthy again.
Data loss is expected in Split-Brain recovery as the cluster splits into multiple sub-clusters, data loss occurs because multiple nodes in a cluster leave simultaneously. The sub-clusters can entertain client requests in a state of Split-Brain, these operations may be lost if the split to which the client is connected is a loser split which is restarted to join the main cluster.