Boston Code Camp 31
Optimize ASP.NET Core Performance with Distributed Cache
By Iqbal Khan
President & Technology Evangelist
ASP.NET Core is fast becoming popular for developing high traffic web applications. Learn how to optimize ASP.NET Core performance for handling extreme transaction loads without slowing down by using an Open Source .NET Distributed Cache. This talk covers:
- Quick overview of ASP.NET Core performance bottlenecks
- Overview of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important distributed cache features
- Hands-on examples using Open Source NCache as the distributed cache
Okay thank you, everybody, can everybody hear me fine? Okay, I forgot to include the slide, thanking all the sponsors. I'm just going to go to the website and show you the logos of all the sponsors. we’re one of them by the way, so, I'll show this at the end as well. That's what the organizers told us. So, I'm going to go over this topic and I would like to keep this conversation more interactive if possible. So, if you have any questions please feel free to stop me. Let me just make sure everything is recording.
So, today's topic is how do you optimize ASP.NET core application performance with distributed caching? I'm going to use an open-source product called NCache. How many here, have heard of NCache before? That's a good number. Okay, I'm going to use NCache as an example. This talk is not about NCache, it's about ASP.NET Core performance and how you can use caching? So, I'm sure you were here because the ASP.NET core has become popular, it's becoming popular, it's the new clean lightweight architecture, it's the cross-platform technology, the rearchitecting of .NET is open source, there's a lot of ASP.NET legacy applications that are also moving to ASP.NET core. ASP.NET core is going to be the main technology with which you would be developing web applications in .NET.
So, more and more people now are developing applications that need scalability. So, ASP.NET core of course also needs scalability. Let me quickly define what scalability is? I'm sure most of you know this already but for completeness purposes, I'm going to define this.
What is Scalability?
Scalability is if you have an application, that has a really good response time, it performs really good with five users, if you can maintain that same performance with five thousand, fifty thousand, five hundred thousand users then your application is scalable. If your application is not performing well with five users, then you have other problems that we're not going to go into here. So, I'm going to talk about how you can maintain that good performance from five users to fifty thousand or five hundred thousand users.
Linear scalability
Linear scalability means that your application is architected in such a way that you can just add more servers in production as your load grows and as you add more servers, your transaction capacity grows and that's what gives you that good performance if you are able to maintain linear scalability. If you're not able to maintain linear scalability then there's some sort of a bottleneck, that your application will face pretty soon as you add more servers, pretty soon it will not matter if you add more servers or not and you're going to just hit a bottleneck, there is and I'll talk about the bottleneck.
Following Applications Need Scalability
So, which applications need scalability? Generally, server applications, these are web applications, ASP.NET core, web services, which are used by other web applications. Web services could be independent applications that are being used by external applications or they could be part of web applications that you're developing, either way, if they're high transaction, they are also going to need scalability.
Microservices is becoming a hot new buzzword now, this is how you want a rearchitect your application. Microservices are going to also their server-side technology, they're used in high transaction applications and will need scalability. For any other server applications, a lot of large organizations have batch processing in the backend and they need to do workflow in the backend. A bunch of backend server applications that just need to try to handle a lot of transactions, they are also going to need scalability. So, if your company or if you are engaged in any of these types of applications and you want to have that good performance, this is the talk for you.
The Scalability Problem
So, now that we've established that you got that these applications need scalability, is there a scalability problem? Yes, there is and it's not in the application tier, the ASP.NET core application you can very easily add more servers as the transaction load grows, and usually, you have a load balancer in front of the application tier, that directs the traffic evenly to all the servers and as you have more and more users, you just add more boxes, no problem there. The problem of course is the data storage or the databases. These are your relational databases, your mainframe and this is one of the reasons, why NoSQL databases started to gain traction but turn out that in the majority of the situations you still have to use relational databases, for both technical and non-technical reasons. So, if you look at most of the applications that you guys have done or are doing, you end up using relational databases in the case of .NET the most popular one of course is a SQL server. So, if you're not able to use a NoSQL database, what good is it for helping with scalability? And the reason is that the NoSQL database asks you to abandon relational database and move the data into NoSQL, which for some data you can, for a lot of business data you cannot, all your customers, your accounts, your activities all that still needs to remain in a relational database. So, you have to solve this scalability problem with relational databases in the picture and that's why I say that NoSQL database is not always the answer because you're not able to use it.
The Solution (Distributed Caching)
So, the way to solve this, of course, is to use a distributed cache and this is how a distributed cache is deployed in your environment.
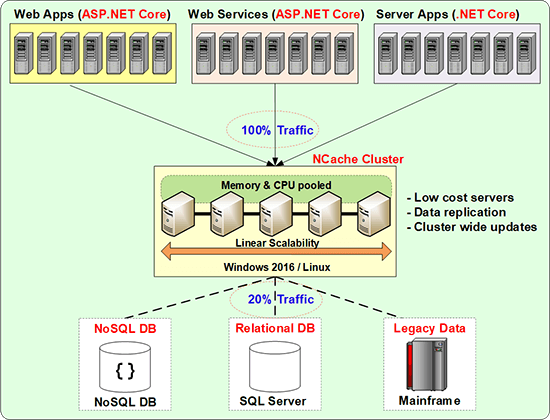
So, this is the application tier, in some cases, you may have a load balancer in front here, which is directing the traffic to all of the application servers. In some cases, there may not be a load balancer, there may be some other way that the load is being shared because these are some backends applications but anyway, you have multiple servers that are running your applications. So, this is very scalable but the database you cannot keep adding more and more databases. Now that relational database companies are trying to do as much as they can to scale on their end, for example, they have in-memory tables, which are much faster. I think SQL server has also not introduced this concept of read-only replicas where these are, so if you combine in-memory tables with read-only replicas, you get a performance boost but as you'll see, I'll go into this. The more replicas you create the more headache you have, in terms of updating every time you update anything it has to be updated on all the replicas. So, to achieve the best performance with scalability is to make sure that you have no more than one replica. So, one master copy and one replica of every piece of data, and at the same time, you have to be able to scale. So, the reason they cannot do that is that a relational database cannot be partitioned in the same way that a distributive cache can be or a NoSQL database can be because both distributed cache and NoSQL are key-value pairs, which is a very different design than a relational database, but in the end, you do have to put in a distributed cache as a caching tier in between the application tier and your database.
So, what does this look like in terms of what is the configuration? So, typically these are not very expensive boxes. These are usually 8 cores to 16 core boxes, lots of memory 16 to 32 gig memory, and 1 to 10-gigabit network cards. Sometimes you have two network cards, one for the clustering to happen and one for the tools sort of the clients but that's about it, that is very different than getting a high-end, a lot of processing power database server to do your job because there's only one of them or very few of them. So, there's no other way to get around this. We tell our customers don't get more than 64 gigs of RAM per box because when you have more than 64 gig RAM in a .NET environment, that memory has to be collected through garbage collection, and collect as you collect more and more memory than you need more processing power. So, then you enter into the same issue of starting to get really expensive boxes. It's better to get 32, 16 to 32 bit, 16 to 32 gig memory but more boxes keep it cheaper.
How does a Distributed Cache Work?
So, what is a distributed cache do? It actually builds a cluster and again I'm talking from an NCache perspective, there also are others like Redis that do similar things but in a different way. So, the distributed cache will build a cluster, it's a TCP-based cluster and the most important thing in a cluster is that just like you don't want the database to go down and in production, you don't want the cache to go down either. So, this cluster has to be highly available. So, the best way to make it highly available to customers is to make sure it has a peer-to-peer architecture, where every node is an equal citizen and any node can go down or you can add more boxes, there's no master-slave because that creates complications and high availability issues. So, it pooled the resources, memory, CPU, and network card as resources. So, as you add more, let's say you've got more and more traffic or more and more transactions you add more server’s hereafter at a 4 to 1, 5 to 1 ratio you usually you would add more boxes. Minimum of two cache servers and then you keep adding more, so you'll start with two, you'll start to have more and more load and suddenly everything will start to slow down and you add a third box everything improves when you add more load and add more boxes, here things start to slow down to a certain point. You add a fourth box and the picture goes.
So, that's how it scales linearly, in theory, nothing is unlimited but it scales in for more situations, it scales in an unlimited fashion where there is no bottleneck. So, this allows you to not have your database become a bottleneck. So, this has become pretty much an essential best practice of your application architecture. If you're doing high transaction applications, you have to incorporate distributed caching and because that is the only way, you'll be able to achieve performance because it's all in-memory, anything that touches the disk can never be as fast as in-memory and scalability because it is distributed. Any questions on this before I go? Actually, in the case of NCache you can. NCache supports .NET and Java but if you have other applications like Python or others, then you cannot use NCache, you have to then use other caching solutions but the application needs to be in a scalable environment. Basically, it doesn't matter what language you use, the functionality stays the same. There’re some benefits, if you are a .NET application then NCache offers you a lot of .NET specific benefits that it's a full .NET stack, its .NET course stack, so it fits in very nicely. There are similar products on the Java side also which are called in-memory data grids and so, they fit the Java stack very nicely. For example, I'll just share some information. So, NCache has a Java API but the only people who use the Java API are the ones who buy NCache or use NCache from a .NET perspective. So, they've got NCache in-house and they said might as well use it for Java and a Java shop would go look for a Java-based in-memory data grid, a .NET shop would look for NCache. So, that's how the market is segmented because of all the expertise, if you're a .NET shop, you have all the .NET expertise versus Java. So, why complicate the picture? For databases, so non-SQL database any database can be used? Anybody, any because the way you access the database is through your own custom code that lives on the caching tier.
So, that's another feature, that I'll go through is that one of the essential features of making sure that cache stays synchronized with the database is that your custom code needs to live on the cache server. If you make the cache a black box, where there's nothing on the cache except data that's like having a relational database with no triggers and stored procedures or other things. So, that limits your use of the cache. So, caches started out as being just the black box. Memcached was a popular cache, it was it did nothing, was just a store, and over time, they evolved into a proper intelligent entity where they can run your code also. Any NoSQL, any relational database can be used with it. And again, all of these features that I'm talking about are open source and enterprise both. So, that's why I'm mentioning it because it is open source. Any other questions? When dealing with NCache is it mostly automatic caching or is it you use API to cache? So, I'll go into more detail but it depends on what you're caching? Certain types of cache usage are automatic. For example, if you're putting ASP.NET core sessions then it's a pluggable module, it just plugs in and starts to store the sessions in the cache, so there's nothing that you have to do, but if you're going to cache the application data which is where the bulk of the benefit is, so there's an API that you have to call to determine, what you want to cache? How long do you want to cache it? How do you want to synchronize it with the database? There are a lot of other things, that you have to keep in mind. So, I'll go over all those features of how you should use distributed cache like NCache to make sure that you can cache all sorts of data but there's an API. Yes.
Using Distributed Cache
Okay. So, now that we've established that a distributed cache is important. It gives you performance and scalability, let's go into how do you use a distributed cache and there are three possible ways that you can use it. The three big technical use cases.
App Data Caching
And the number one is the application data caching that's what I've been talking about so far and I'll go into more detail about that soon. In the application data caching, there's one thing that is that you've got to keep in mind that the data exists in the database and the cache. So, there are two places that the data exists, when the data exists in two places, what's the most common thing that could go wrong? They could get out of sync, so a customer could withdraw those million dollars twice from the bank once from the cache, ones from the database and so you don't want ever to have that situation. That situation was so bad in the past that people used when you mention the word cache, the thought that came to most people is I'm just going to cache read-only data. The data never changes, because if I cache anything that changes, I couldn't potentially in trouble. So, I'll go into how you can make sure that does not happen but that's the most important thing to keep in mind in application data caching.
ASP.NET Core Specific Caching
The second use case is ASP.NET core-specific caching and there are two things that you can cache from the ASP.NET core. One is the sessions, which are pretty much every ASP.NET core application uses sessions and you in the previous ASP.NET environment, Microsoft gave three storage options InProc, state server and SQL and fourth was the custom. The first three practically did not work but the fourth one allowed you to plug in a cache but in ASP.NET core they've actually done the right thing which is they've from the git code, they've actually architected it so, that it is based on an IDistributedCache interface. So, it allows you to plug in a third-party store and you can plug in something like NCache and it automatically starts to store your sessions and I'll show you how that is done.
The second thing in ASP.NET Core is response caching, which is the page output that you can cache. So, the next time that page is called, the page shouldn't even be executed, it should just return the output if it hasn't changed. If it's going to reproduce the same output again then why do they rerun or execute the page? Why not just serve the output, so that's what output caching was called in ASP.NET, now it's called response caching. It's now based on more HTTP standards. So, you can plug in third-party content caching on the edge which was not possible but I'll go into that as well. The difference to keep in mind between application data caching and ASP.NET core caching is that unlike application data caching, where there were two places that data existed, now the data exists only in the cache and because the cache is in-memory, this data will be lost if any cache server goes down, unless there is replication. So, that's a very important point to keep in mind that any cache that does not give you good replication is not suitable for caching sessions or other trends in data.
There's a third ASP.NET core-specific thing which is called SignalR, which I'm not going to go into, if you have live web apps, which can give live feedback, let's say stock prices have to be updated all the time. So, that also can use a distributed cache as its backplane but I'd I did not mention it.
Secutiry
Any questions in the first two and I'll go into more detail if need on these. So, first of all, cache lives behind your application. It lives between the application and the database. Generally, in a fairly secure environment. We have customers that keep the cache either closer to, if their application is in the DMZ, they might keep the cache not in the DMZ but behind the firewall. Sometimes they keep it in the DMZ but most of the time, it's in a secure situation but many of our financial services customers like big banks and others, they're not satisfied with that, so, they want further securities. So, that's where the Enterprise Edition of NCache has features, where it can do encryption. So, all the data that you put in the cache will automatically be encrypted with like 3DES or AES256 encryption and then there's also security, that all of the connections to the cache will be authenticated through Active Directory and there's going to there are authorization things. So, the full security features are built into the enterprise edition.
An average customer does not use encryption unless their data is sensitive. So, if they're keeping financial data, there are some compliance issues or HIPAA, so if as soon as you enter into compliance issues then even if your environment is secure, you have to go a step further and that's where you would do encryption. So, NCache Enterprise, for example, will do the TLS connection between the client and the caching tier. So, that connection itself is completely secured plus you have encryption built-in, so whatever data is kept in memory, it's also kept in an encrypted form. And that satisfies pretty much, I mean we've got lots of financial services customers and they're totally satisfied with that.
NCache can be deployed and most of our customers still use it in an on-premises situation. So, they have their own data center where their application is deployed, so they deploy NCache as part of their application. If you are in the cloud, NCache is available in both Azure and AWS and it is available as either VM’s or we're just about to launch the managed cache service also, either way, we make sure that NCache lives within your virtual network in the cloud. So, in an on-prem, that's not an issue because always in your own environment, you just get a bunch of VM’s or if you're own data center, you get your own servers and you deploy them with the application. You install NCache as software and it's for installations inside, you can also use docker and you saw all the stuff that you would expect modern applications to be able to do, NCache will do. And then in the cloud, you can either get the VMs or get the managed cache but in the cloud, we will always make it within your VPC in case of AWS and vnet in case of azure. It's within your virtual network. So, it's close to your application because if it's not if you have to grow across multiple hops, and let's say if it were a hosted cache, which is probably okay for small applications but anything serious, NCache is almost always used in mission-critical applications where you are doing your business through that application. So, that's where you would use NCache.
So, in those situations, you cannot afford to have any slowdown and if you cannot afford to have slowed down, that's where you want all of the control and keep the cache as close to the application as possible. It depends on what use case are you going to do, so for example, the biggest and the quickest benefit is sessions and you would immediately just plug it in without any code change. It's just a config change. In the case of ASP.NET core, it's not a config change. It's a start-up file code change but just very small but if you want to do application data caching then it's still a very straightforward change.
Let me just quickly show you, what the API looks like. So, look at this API.
Cache ConnectionCache cache = NCache.InitializeCache("myCache");
cache.Dispose();Employee employee = (Employee) cache.Get("Employee:1000");
Employee employee = (Employee) cache["Employee:1000"];
bool isPresent = cache.Contains("Employee:1000");cache.Add("Employee:1000", employee);
cache.AddAsync("Employee:1000", employee);
cache.Insert("Employee:1000", employee);
cache.InsertAsync("Employee:1000", employee);
cache["Employee:1000"] = employee;
Employee employee = (Employee) cache.Remove("Employee:1000");
cache.RemoveAsync("Employee:1000");It's just a very small cache.get, cache.add, Insert, remove. So, you have a key and a value as your object. So, very easy to incorporate but you do have to go and make it, so whenever you get data from the database you first check the cache, if the cache has it, you take it from the cache, or else you go to the database get it and you put it in the cache, that's the model. Exactly. I'm going to speed up otherwise, I'm not going to make it. I'll show you NCache a little bit later.
Pub/Sub Messaging and Events
So, pub/sub messaging is also a very powerful feature. A lot of applications today have to coordinate the effort. I was talking to somebody today, who said that they have a need to do a lot of event-based programming. So, pub/sub messaging gives you a very powerful event-driven programming model because you have an infrastructure where it's an in-memory scalable platform now within your application, you can think of it as like a messaging bus. It is not for distributed environments. It is for the same data center one location type of a situation but it's super fast because it's all in-memory and it's scalable. So, that's the third use case that you will have for using a distributed cache like NCache. Yes, it does, it does and the open-source also supports it. So, all of these features are available both open source and enterprise, in fact, all of the NCache API is pretty much the same between open source and enterprise.
What we've seen with pub/sub is again if you have a high traffic application, high transaction then you really need the pub/sub engine to be super fast and that's where NCache really shines.
ASP.NET Core App Data Caching
Okay. So, application data caching. How do you do it? So, that's also to answer there, so there are three ways that you can do it.
IDistributedCache
You can use the IDistributedCache interface that ASP.NET core comes with and if you've programmed against it, you can just plug in NCache as a provider. So, there's no further code change once you've made the IDistributedCache API programming. So, the benefit is you'd program once and you're not locked into any one caching vendor. The drawback is it's the least common denominator. I'll show you what it looks like that's all it is. It's got Get and Put that's it. You know Get, Remove and Set, whereas there's a lot more that you need to be able to do to make full use of the cache, that we were talking about the fact that you want the cache to be synchronized with the database. So, there are pros and cons to it.
Entity Framework Core Cache
The second is if you've got an EF Core application, you've got it an EF core application, it's a simpler way to plug in NCache and I'll show you. So, we've actually implemented extension methods for EF Core and again this is both open source and enterprise. There's the EF Core sample. Okay. So, if you had an EF Core application, you would typically have an EF Core query like this, you'll kind of fetch something using LINQ style querying. So, we've implemented an extension method, let's say FromCache, so they're a bunch of methods, this is one of them so this will say go to the cache if this query was last stored in the cache, get it from the cache. If it's not in the cache go to the database, run this regular EF core query, get it, and put it in the cache. So, it's just that one line or just that one method call automatically starts to cache all the data that is coming from the database. So, it simplifies your work and you know exactly where to plugin, there's not a lot of extra API calling that you have to do.
So, for EF core applications, again there's code change but as much as little as possible that you can do and start to cache data. So, actually, for EF core they're a bunch of methods, this is FromCache, there's most of it is from, there just about four or five methods that you can use, the FromCache, then LoadIntoCache, FromCacheOnly. So, and then also with the EF Core, when you do save changes it also updates the cache before it or after it updates the database, it also updates the cache. So, the cache has the updated version of the data. The integrity of the cache is maintained first of all by making sure that whatever data you keep in the cache and I'm going to jump, for example, this is a cache server. Let’s say that if you have two servers and let's say you have three servers. The entire cache is broken up into partitions, every partition is got its own set of buckets, so your data resides only in one of the partitions. So, and then that data is replicated to some other server, which is called the replicas but the replicas in the case of NCache is not active, it’s passive your application doesn't talk to the replicas. Your application talks only to the partition. So, because the data is stored only in one location, there's no synchronization issue. Everybody is going to the same server but because it's partitioned, not everybody is going to the same server, some keys are stored here, some are stored here, some are stored here.
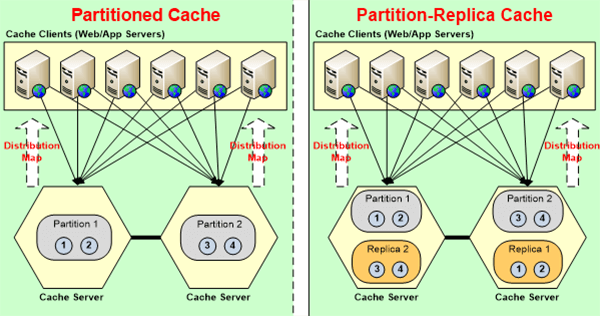
So, that's what a distributed cache like NCache is able to do which SQL server cannot do because the nature of relational database is that you cannot partition, but the nature of distributed cache is that you can and when you partition here, these are three servers, they are maybe shared by ten application servers and every application server may have four or five or six or eight worker processes. So, there are a lot of different client processes talking to the cache, there is no synchronization issue because the actual data is stored only in one location. Now there are other topologies in NCache that are replicated, where the same data exists active-active and multiple and in that case, NCache has to synchronize the changes. It's token-based, it's a sequence-based updating algorithm, it's not very scalable. So, we don't recommend it for a high transaction environment.
Partitioned cache with replication is the better strategy or we call it a better caching topology to use. So, that's how NCache makes sure that within the cache, the data is always correct. Did that answer your question? So, the port that you have shown, is there any configuration or setting on the code which says, from which cache it has to pick it up? Yeah. So, for example, when you go into the app.config, you'll see that it's going to say you use mycacheId and I'll show you what the cache is. So, when you create a cache in NCache. Every cache gets a name and that name behind the scene knows where the cache is, so all you got to do is specify the name here and then it knows where to go and get the cache from. And I'll show you what the cache actually, looks like. One cache name is on all of those servers and within the same servers you can have multiple cache names, on the same server you can have multiple caches and one cache can live on multiple and is a distributed cache, the one cache name has to live on multiple servers that's how it's distributed but the same servers can be used for other cache names also, and each cache name gives its isolation. Good question.
High Availability
So, this is where I was saying high availability is really-really important. If you're not able to add or remove servers at run time without any stoppage, then your application is really not highly available. We have customers that have been running NCache for months and years without any stoppage. So, for example, let's say that you have a two-server configuration and you've just added a third server because your load has grown. So, you need to add a third server, all you'll do is you'll add a third server and I'll show you it just through the tool, just add one, and NCache behind the scenes will repartition. So, these two partitions will now be transformed into three partitions. Some of the buckets from here and here will get assigned to the third partition automatically while an application is running, your application doesn't even notice this. Behind the scenes now that there's a third partition that exists and now the replica is also there's a third replica that is created, so let's say replica 2 needs to move here and replica 3 is created here.
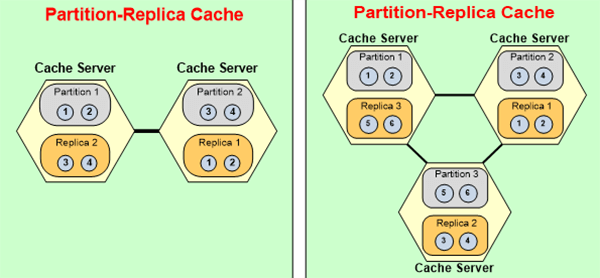
NCache maintains it, behind this NCache uses keys for hash mapping but it does it all dynamically, so like a distribution map, which is like a bucket map that gets repartition and reassigned. So, data actually moves from one server to the other automatically at runtime.
Location Affinity
So, in some cases, you may want to keep some of the data together on the same partition. NCache has a location affinity feature, where you can specify and then you will specify it. You’ll say these two pieces of data are related, I want it to be on the same server and then NCache will keep it on the same server through an extra key that it creates on top of it. As I said all of those are advanced features, that you don't get if you just go with the least common denominator, and by using those features, then you can adjust NCache to your environment on your needs specifically.
App Data Caching Features
So, the first thing that I wanted to cover, these topics, these are very important. For application data caching, the most important thing is that the cache is always fresh which means fresh means it has correct data, if the data changes in the database, the cache has the latest data.
Time based Expirations
So, expiration is the most common way that caches do it, almost all caches have expiration as a feature. NCache also has it. There's an absolute expiration and then there's a sliding expiration. Absolute expiration is, let's say you're adding data to the cache, can say ok after five minutes expire this because I don't think it's safe to you to keep it in the cache for more than five minutes. So, you're making an educated guess, that it's safe to keep the data in the cache for five minutes and that's good enough for some data, for other data it may not be.
Sliding expiration is more for when you're storing sessions and you're saying okay after nobody is using it, after everybody is done using that session just remove it. So, it's more of a clean-up expiration. Absolute expiration is synchronization is to keep it consistent with the database, sliding is clean up, but expiration is an educated guess whatever that guess is wrong
Database Dependencies
In some cases, you can afford to have the data be inconsistent in some cases you cannot. So, if you cannot then you got to have other features, so this is where NCache really stands out which is that for example, you can have a synchronization of the cache with the database. So, NCache uses SQL dependency that is built into SQL Server to monitor SQL Server. So, you can for every item that you cache, you can say ok map this with this corresponding row in the SQL database table, NCache monitors it, if that row changes, NCache then either removes that item from the cache or it reloads it again. So, now suddenly you have an Intelligent cache, it is able to make sure that whatever you're caching it will always be consistent and this is something that you don't get if the cache is a black box.
So, you have to be able to have that type of intelligence with the cache, and SQL dependencies is a .NET feature, so that's where NCache being .NET helps if your database is SQL. Now, we are also Oracle dependency which is also, uses the Oracle database notifications and there's another way to do which is our polling-based notification, which is more efficient but it's not as real-time and then you can also synchronize the cache with non-relational data sources. Your data might be in a NoSQL database, it might be in the cloud, it might be wherever and you want to be able to monitor it. So, you can create what we call a custom dependency, which is your code that lives on the cache server. NCache calls it at a certain interval, it goes and checks your data source, if the data changes, it notifies NCache, ok the data has changed please remove this or reload it.
So, this is an area where NCache is really really strong. If you want to keep your data fresh, you've got to be able to do these things to make sure the cache is fresh.
Read-Through & Write-Through
Another feature is read-through and write-through. So, now this is combined with expiration and database synchronization. This allows the cache to load data from your database and that's what so for example, if you have a read-through, I'll show you what a read-through looks like. It's just an interface that you implement and your code actually resides on the cache, so here's an interface you implement this code. So, there's a load from source call it gives you a key and then NCache calls your method, the cache server calls your method, this code is running on the servers, all the cache servers, NCache calls this method and says please go ahead and load this key because it's not in the cache. So, if I do a cache.Get, I think that key is not in the cache, I either return a null, saying the key does not exist, or if I have a read-through, I can just go to the cache, and NCache can go to the database and read it for you. So, you'll always have it. Now, this is very useful in many cases, where you want to just keep that data in the cache always.
So, read-through allows you to, when you combine read-through with expirations or database synchronization, what that does is when the data expires NCache can automatically refresh it, why remove it? If you're going to reload it, next time anyway because that data is needed and you expiring it just to keep it fresh. So, why not just have NCache go back and reload it. If you have read-through implemented, NCache will do that automatically and the same thing happens, if the data changes in the database or data source and this synchronization feature figures that out there ok that database has changed then if you have implemented read-through, it'll automatically go and reload it.
Similarly, write-through gives you another benefit which is that if you have a write-behind you can update the cache. So, some data, it's not that sensitive for updates, I mean of course if it's financial data bank balances you don't want to do write-behind but in some cases, it's ok if you can just queue up the updates. So, if you update the cache, updating the cache is much faster than updating the database, of course, more scalable because it's distributed and you update the cache and you tell NCache please go ahead and update this, the database asynchronously behind the scenes. So, that's the write-behind feature, and that now suddenly speeds up your application because what is the bottleneck? Reads from the database and writes to the database. Reads you can cache, so that you're not even going to the database but the writes have to go to the database, you cannot I mean the database is the master right, so there's no going around it but write-behind kind of makes it easy.
So, that's another feature that if you have it, NCache suddenly gives you further boost into your application. Question: So, just in case, it’s not able to write in the database and doing async, it will throw an exception? Yes. It will throw an exception, you can have a call-back that gets called by NCache and again the code is, this write-behind code is running on the cache servers but the call-back is here, so it'll notify back the client and your call-back will be called, so then you can take corrective actions. Once you've become comfortable with that cache, NCache can synchronize the cache with the database, you'll cache more and more data. The more data you cache, the more cache starts to look like a database, which means a key-value way of fetching data is not smart enough. So, you got to be able to find data based on SQL, especially reference data.
SQL Search
When we talked about the EF Core query that you're fetching data based on attributes, not just the key. So, if you're able to search the data with SQL or LINQ queries or with EF core that makes the cache much faster. That's another way NCache stands out is that once you put all that data in the cache, you can search, you can say give me all my customers which are based in Boston or New York and it'll give you a collection of customer objects from the cache. So, it's starting to look more like a database and you're taking all that pressure off of that database of it, especially for reference data. So, SQL searching is really-really important.
Okay. Now I want to show you what NCache looks like or any cache would look like? So, I am logged into Azure. So, I have two cache server VM's. so, I have two cache servers, one Windows client and one Linux line because there's .NET Core, you could be running the application either on Windows or Linux and NCache works might actually, the cache servers also can run on Linux because of .NET Core because NCache is the .NET Core native.
Create a Cache
So, I am, for example, I've done a remote desktop to the Windows client. I'm going to actually go ahead and create a cache, so my cache is going to have two servers and I'll have one Windows client, one Linux client, and when I use the word client that actually is your application server boxes. Okay. So, I'm going to use this NCache manager tool. Now this tool is part of the Enterprise Edition but you can do all the same things through the open-source command-line tools or config files but just for convenience purposes, I'm going to go ahead and create a cache.
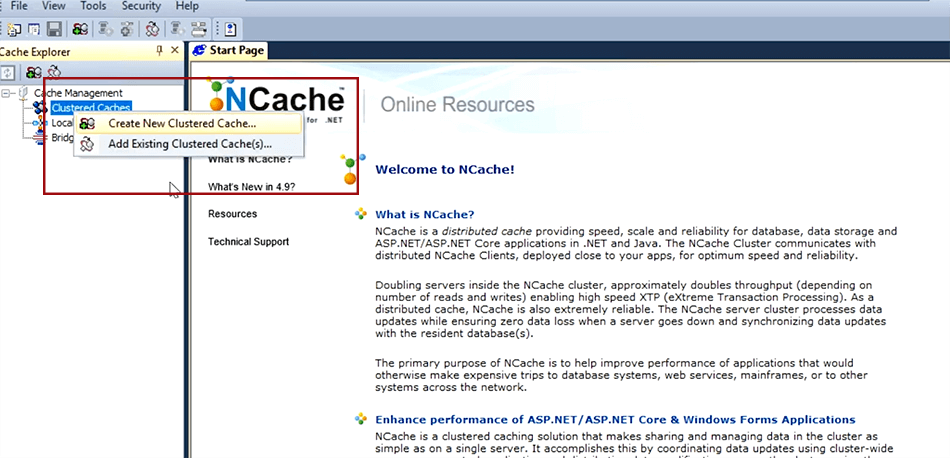
I'll call my cache democache as I said all the caches are named.
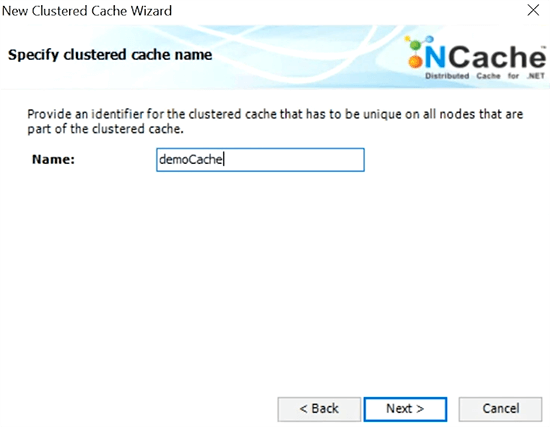
I'll pick a topology. I'll choose partitioned cache with replication.
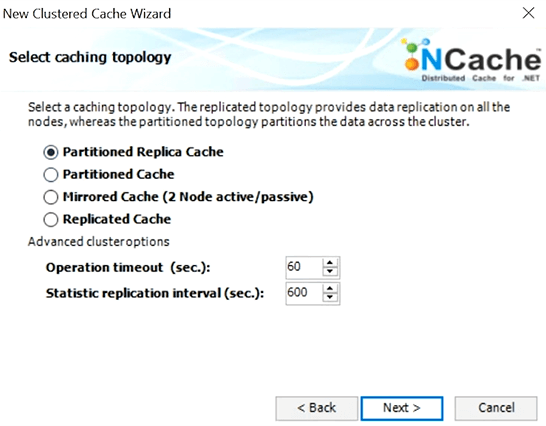
I'll do the asynchronous replication, so there's an async replication and async replication. Sync replication is when you cannot afford to do async if it's more sensitive data, financial data, and stuff where you want these replications to happen as part of the update, which of course slows things down but makes them more.
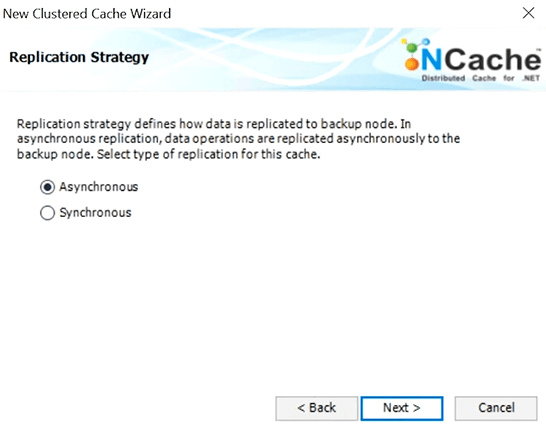
So, here's my cache server one, here's my cache server two, so I've just created a two-server cluster. it's not running yet. I'm going to add two client nodes. This is my windows, there was a server. So, 6 is my windows client and 7 is my UNIX client. Okay. So, I've got two cache servers and two clients usually, as I said you'll have a minimum of two cache servers and four to one, five to one ratio between the clients and the server. So, I'm just starting the cache now. Again, from one place, I can do all of this and the same in the next version that we're just about to launch, this is all web-based, so in the cloud, you can just do it. I'm going to open statistics and these are like monitoring, these are perfmon stats.
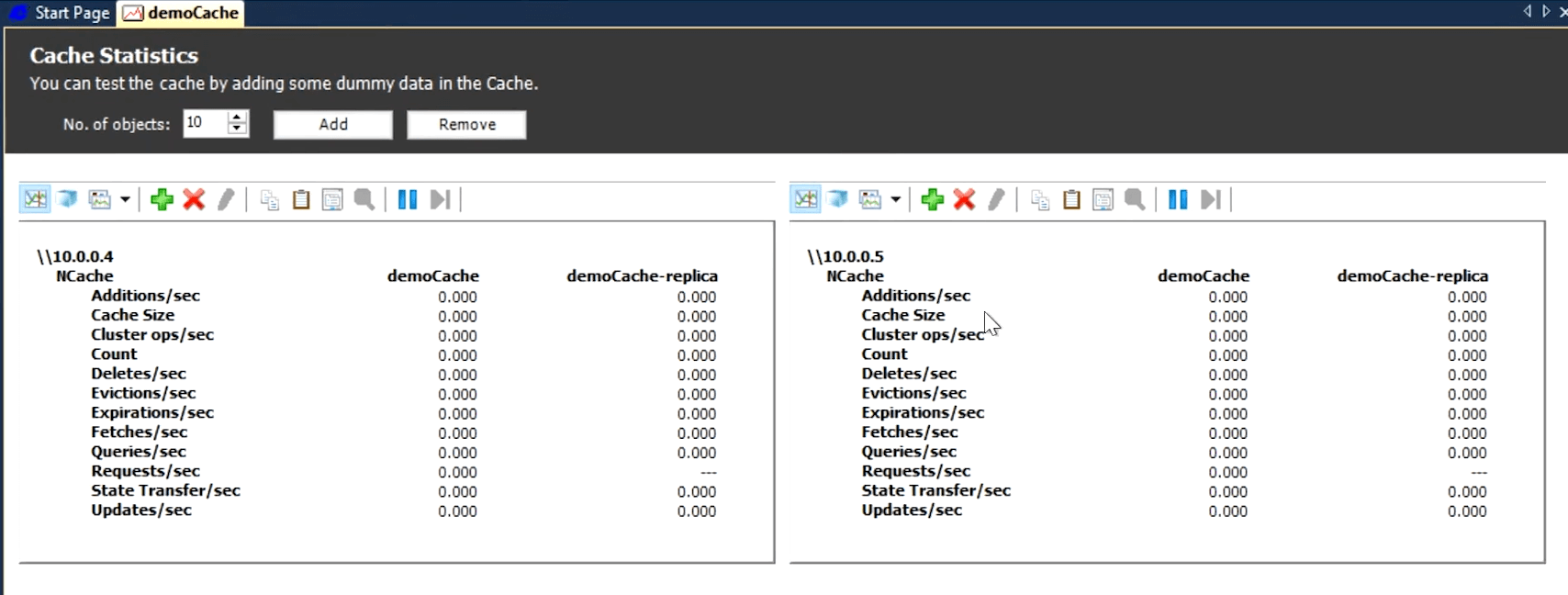
Simulate Stress and Monitor Cache Statistics
I'm going to test and see whether my client is able to talk to this, now this box is a client. so, I'm going to open up the PowerShell console. I'll have two partials from windows and I'm logged into two Linux here, so I've got a Linux here, now the Linux here. Right? Here, I need to start PowerShell and here, I need to also import my module which I don't need to do for windows, it's already there for me and I need to do the same here. I need to start PowerShell on Linux and okay now I'm going to start a client. So, NCache comes with this stress test tool, which makes it really easy for you to stress test in your own environment. So, that you can see exactly how NCache performs? So, you don't have to take a word for its performance. So, let's say here, I'm doing about 500 requests per second per server.
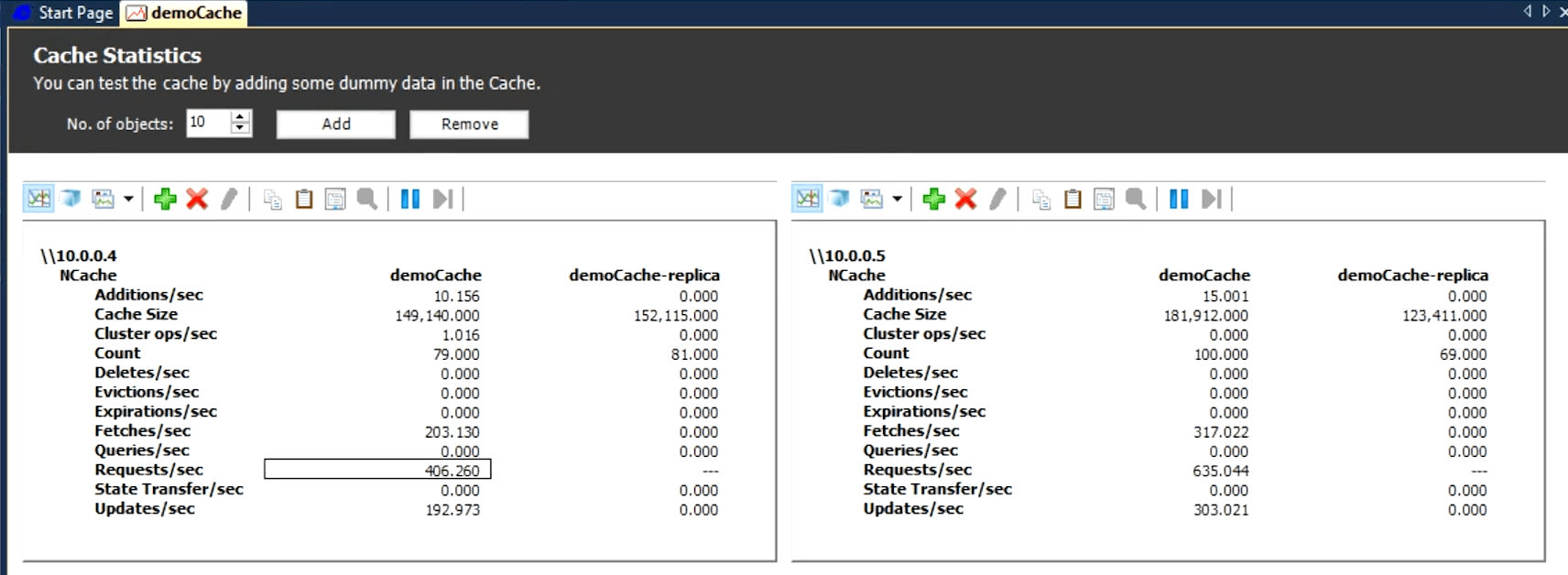
Okay. So, I want to increase the load, so I'm going to go to the second console and I'll say run a stress test again.
Now, suddenly you'll see this is going to jump doubled, right, and let me go ahead and add more stress. I will come to one of the Linux ones and I'll say the same thing and suddenly now I'm more like 1500 per request. So, now I'm a total of about 3,000 requests per second like let me do another one and now I'm doing more like 4,000 requests per second. So, I can keep adding more and more if I have more VM’s, I can or I can just have more instances and you'll see that pretty soon once, it reaches the maximum of whatever this is going to be and these two servers should be able to handle about at least 50,000 requests per second, but again that's with the small data set, as your object size increases that's going to go down of course but once I max that out I'll just go ahead here and again this is running right, I don't have a third VM but all I have to do is just do this and just add a third address and I'll say finish and it'll add a third box here and it'll do all that partitioning or repartitioning automatically for you.
Similarly, if I need to bring any of the VMs down, it's going to also do that. Yeah, that's it, that's the end of my talk. Can we answer any questions? It's the only native .NET solution, the only other native solution was AppFabric which got discontinued. So, Redis is not a .NET solution even though it is Microsoft picked it for Azure because they've wanted to be technology agnostic, so they picked it but we are native .NET. We've been that way from day one and as far as we know we’re the favorite choice for .NET.