Philly .NET Code Camp
Optimize ASP.NET Core Performance with Distributed Cache
By Iqbal Khan
President & Technology Evangelist
ASP.NET Core is fast becoming popular for developing high traffic web applications. Learn how to optimize ASP.NET Core performance for handling extreme transaction loads without slowing down by using an Open Source .NET Distributed Cache. This talk covers:
- Quick overview of ASP.NET Core performance bottlenecks
- Overview of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important distributed cache features
- Hands-on examples using Open Source NCache as the distributed cache
Today's topic is how to optimize the ASP.NET core performance. I prefer to have more interactive discussions so, as I'm talking if you guys have any questions, please raise your hand so we can get. So, I'm sure you are here because the ASP.NET core is now the popular technology for developing any new .NET applications or .NET web applications because it has a clean and lightweight architecture. You are probably already on MVC from ASP.NET. So, if that's the case then moving to a ASP.NET core is going to be pretty easy. ASP.NET core is lightweight. It's cross-platform, it’s open source and there's a huge legacy ASP.NET user base that makes it a very likely case that most of you guys will be moving to ASP.NET Core.
So, ASP.NET core going forward is going to be the choice, the technology choice for .NET, for developing high traffic web application or high traffic server applications and web applications. That means ASP.NET core needs scalability and I'm sure that's why you're here. Let's just get definitions understood before we dive into more depth.
What is Scalability?
What is scalability? Scalability essentially means that if you have an application with five users and it performs super-fast, good response time then you can maintain the same response time, same performance with five thousand or fifty thousand or five hundred thousand users, simultaneous users then your application is scalable. If your application is not performing well with five users then this is not the talk for you then you have other, you probably need to look the way you’re accessing your database and you're doing your overall programming. This is assuming that you've done a good job, developing application for at least few users and then you need to know how to scale it.
What is Linear Scalability?
Linear scalability means that you are able to add more servers in production and as you add more servers, you can in a linear fashion add the transaction capacity.
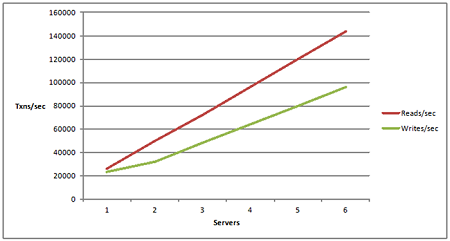
Now I'll go into more detail but what happens is, let's say you start with two server web farm load balanced. After certain number of users, those two servers are going to max out and your performance is going to start to slow down and then you add the third server and suddenly the capacity should increase by at least one third or whatever the new formula is and then when you go when you max out three servers then for sure again add incremental. if you're able to do that then you have a linearly scalable application architecture. If you're not able to do that then you have a nonlinear.
What is Non-Linear Scalability?
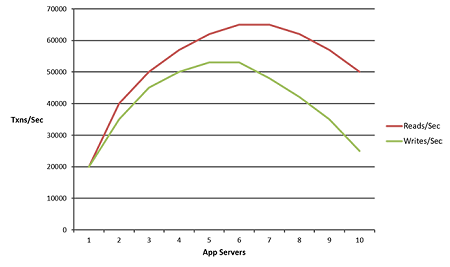
Non linear basically means that after a few servers, adding more servers is not going to make any difference because there's some bottleneck in your application that is preventing it from scaling. So, your performance is actually going to drop as you add more load and talk to the extent where your application might even crash. So, you definitely don't want non linear scalability which basically means after certain point there is no scalability.
Which Apps Need Scalability
So, what type of applications need scalability? These are all server applications. These are your web applications which has the ASP.NET core web services, again ASP.NET core. If you develop in microservices, microservices is becoming a big buzzword now and because of the fact that you can run them in containers and in containerized environment, you can run even ASP.NET core in containerized environment but microservices is another very good use case for scalability or any other server application where you are processing a lot of transactions on the backend.
So, if you have any of these types of applications, usually these are customer facing, output facing applications or at least they're part of the output facing application. Let's say if your web services application, you may be part of an overall web application and there's a web services tier and the same goes with microservices but they are generally customer facing or output facing application but not always. If you're a large company, you may have tens of thousands of internal users but most of the time it's outside things.
The Scalability Problem and Solution
So, there is a scalability problem and that's why we're having this conversation today and the scalability problem is not in your application tier. So, if you have a load balanced environment, your application tier scales very linearly. You can add more servers, no problem. It's the database or the data storage. Any type of data that is storing that could be your application data, that could be your sessions, that could be any other data that you're storing or fetching that becomes a bottleneck and it's for that, it’s one of the reasons why NoSQL databases gained popularity.
NoSQL Database
The problem with NoSQL databases is that, they require you to move away from relational databases. What we've seen that for a lot of situations, let me say a majority of the cases, you can use NoSQL databases for some data but a lot of data still has to reside in relational databases. So, you're still going to use SQL Server or SQL database in Azure. So, you need to solve this scalability problem with relational databases. NoSQL databases are not always the answer because you cannot use them, you cannot replace a relational database with a NoSQL database always. And, if you can't replace it, if you can't use it, you can't benefit from it. Even if you could use a NoSQL database, they still don't provide the performance than in memory distributed cache provides. So, you would still need a lot of the things that I'm talking about.
So, let's see what happens actually and let me actually go into it. The scalability problem is something that you really don't want to wait until it happens. Because if you're developing an application and you say what it's performing fine today and it's good for a thousand users or whatever is the number of users you have and suddenly your business starts to become popular, you got lot more customers coming your way. You’re marketing or your business department has done a good job and suddenly your application starts to slow down and it's been documented through studies that are every one second of slow down, a web application results in revenue loss. Because your customers in a lot of these online businesses, the types of businesses that are online are ecommerce businesses, the retail businesses with online stores, this could be health care, E-government, social media, online gambling, travel industry. A lot of businesses are going online because any business that has to deal with consumers that are going to conduct business with them. These are consumers or tens of thousands, they're usually going to come online with them. And online doesn't always be a web application, it could also be a web services application because you may have a mobile application that's going to talk to a back-end.
So, it's not a good idea to wait until you have scalability problems because then it's going to be very costly to your business. These applications are going to slow down as you saw that nonlinear curve at that time adding more service is not going to help. So, you need to plan this ahead of time. Make sure your application architecture is correct and it is taking advantage of this. It's almost like a mandatory thing as a best practice for you to be an incorporating a distributed cache in your application architecture.
Distributed Caching
So, how does a distributed cache help? I'm going to use NCache as an example here and NCache is an open source distributed cache for .NET. You can find it on GitHub and you can also find it on our website and there's also Enterprise Edition. So, if you don't have the money or you don't have the budget, go with the open source. If you want a more supported version with some more features than open source then goes with Enterprise. So, I'm going to use NCache as the example but I'm not talking about NCache. I am talking about caching overall. So, how does a distributed cache help? Well, Let's say in case of NCache it creates a cluster of two or more servers so as you can see this middle tier which is a caching tier is going to have a two and these two servers and maybe more than two depending on how many servers you have here? How much load you have here?
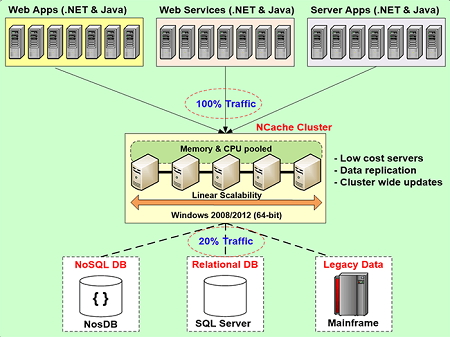
So, when you don't have a distributed cache, the database is just one server you can't really distribute a relational database. I mean, SQL server relational databases are trying to improve their performance. For example, they have in memory tables now. SQL also has read-only replicas of the database. So, that the reads can be replicated but the problem with replicas is that every update is that much slower because every time you update is going to be updated five places or four places. So, it's not the ideal way to solve this. There's a better way which is the distributed cache and the reason a distributed cache is scalable is the word distributed and the way the reason it can distributed is because it's a key value store. Everything is stored based on a key. Key can easily be hash mapped into multiple partitions and every partition is a server and that's how you achieve the distribution.
So, you have a minimum of two cache servers, a typical configuration that we see is about 16 to 32 gig per server as the memory because again, it's an in-memory store so, you got to have a lot of memory. And it forms a cluster, it's a TCP-based cluster which pulls this memory and CPU as a resource of the cluster. So, let's say you started out with a web application clear with 4 or 6 web servers so, you'll have 2 cache servers and your let's say 16 to 32 gig memory and now you're starting to get more and more and 80% of the time you go into the cache, 20% you're going to go to the database for the updates. It may even be less than 20% depends on how many updates you're doing. For some data the updates are more than the others but let's say again, you're going to add more servers to the application tier here and it's going to again do what it did to the database. It's going to max out the caching tier. So, you've got only 2 servers. Let's say you reached about 8 servers in the web farm up here. Because as I said, as you have more users you have more application service. So, this is going to max out. As soon as it maxes out, we added third server. And these are not very high-end servers. These are low-cost servers.
Usually, a typical server is about 8 cores. If you get more than 30 gigs of ram, then you should go 16 core because more RAM you have more garbage collection it has to do because not being of managed memory thing and then you need more processing power. But, we recommend to most of our customers, and again these recommendations also apply to open source, we recommend to our customers to go between 16 and 32 gig RAM per server. Just add more servers instead of getting really high-end few services add more servers. So, when two servers are maxed out just add a third one and the same thing goes you can add a fourth or fifth one and you probably never max out because whatever transaction capacity you need, let's say if you have 20,000 30,000 concurrent users, that's pretty much on the high end of most web applications, I mean there may be some which are more maybe there may be a hundred thousand plus concurrent users but if you have 20,000 concurrent users that means probably have millions of people coming to the website every day. So, I mean, we're talking that scale.
So, because of this, now suddenly the database is no longer the bottleneck. Your caching application data… So, it's a common cache. It's a shared cache. So, when you put this cache here, because it's an in-memory cache, in-memory means that if any one cache server goes down you're going to lose data. So, that means the cache has to provide intelligent replication but NCache does to make sure that if any one server goes down another server has a copy of that data but if you make too many copies that also slows down the whole thing. So, NCache only makes one copy of the data and it partitions. Every partition has backup on some others server and then as soon as one server goes down then partitions makes another copy. And, by having a shared cache, now these boxes become stateless. Stateless means there is no data being stored on the application tier .
So, what you should do is when you can achieve that goal that your application tier is stateless that means you can bring any of the application server down without causing any interference. Let's say you got to apply a patch, operating system patch or an application upgrade or something you can just keep applying it here because all the data is either in the database or at this layer so these can easily be bugged up.
Distributed Cache Use Cases
So, now that we've established the case for why you should use caching, what's the benefit? What problem does it solve and how it does it solve that problem. The first question is what do you use it for? What are the use cases? Where in the application do you use a distributed cache?
App Data Caching
Number one is the application data caching. That's the use case that I talked about already which is that you have a database which has the application data you cache this data in the cache so that you don't have to go to the database. Now, there's one thing that you got to keep in mind and I will come back to this that in application data caching, the data has two copies, one is in the master which is the database and one is in the cache. Whenever you have that situation where the data lives in two places, what could go wrong? Yeah, the two copies could become inconsistent or out of sync that means the cache could become stale. So, any cache that becomes still forces you to cache only static data, read-only data. And, read-only data is only 20% of your total data 80% is what we call transactional data. If you cannot cache transactional data then that cache is going to limit you and this is where NCache has some really powerful feature and again all open source, all really powerful feature that will help you make sure that the cache always stays fresh. It's good and I'll go into that moment.
ASP.NET Core Specific caching
Number 2 use case is that again App data caching is for ASP.NET core and also other applications but for ASP.NET core, there are at least two other uses, one is the sessions that you can restore your session in a distributed cache like NCache and there's no programming needed to do that so that's a really really quick. If you want to get the quickest benefit performance wise to your application and let's say your application is already live or it's done, this just start to show your sessions in distributed cache like NCache. And, because there's no Programming, there's very little testing that you have to do if you need to do, of course some basic sanity test to make sure everything is working in your environment, but there's no development effort involved. because of that no development schedules and no release schedules are involved in this. So, very very quick.
The second ASP.NET core specific caching is the response caching which is in ASP.NET it used to be called output cache, in ASP.NET core they've actually made it more standards-based. So now it uses the HTTP based caching directives that can be understood by third party edge caching solutions but it is essentially you are caching the output of a page so the next time that page is called, if the output is going to be the same, why execute the page? Why not just deliver the output? Now, that is good in those situations where the output does not change very frequently which are a lot of cases but if you have an application which is very dynamic, you probably won't have that much of a static contact, but even if you can have it for a short period that still saves you. So, ASP.NET core response caching has a middleware concept and you can plug in a distributed cache like NCache as a middleware which basically lives on the same tier as the ASP.NET core or it's the same but the middleware cache could be here and here is the actual ASP.NET core application. So, that's the second biggest common use case for distributed caching and I'll go into a little more detail of these but I'm just giving you an overview.
Pub/Sub Messaging and Events
The third use case is something that a lot of people don't know about which is you can do pub/sub messaging and events with a distributed cache. Pub/Sub messaging allows multiple applications or multiple instances of your application to coordinate work with each other by sharing data information in an asynchronous event-driven manner. What are some of the examples we might link this? Microservices, again, microservices are independent decoupled services but they need to coordinate. I mean one microservice might produce something that is used by other microservices that's how the work flow is going to be done but they don't want to depend on each other directly otherwise the whole model breaks. So, then what you do is you actually think of this as no longer a cache for your database but think of this, and I'm going to actually.. give me one sec I will just spin it just for one picture, think of the distributed cache now as a messaging platform.
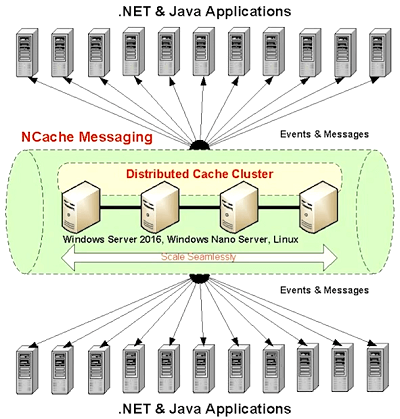
So, the whole paradigm shift which is that now you have applications. These could be multiple VMs or containers running your microservices or any other applications and they can communicate to each other in a pub/sub manner. So, there are topics and so there are publishers and subscribers and that really simplifies your application.
Now, there are other Pub/Sub solutions like rabbit and MSMQ messaging queuing requisite. What's so special about a distributed cache like NCache? Why should you use this over that? The reason for using a distributed cache is because this is very very fast. It's all in memory. It does not have all the features that a message queue will have because they also will be persistence and store the messages for long periods of time but in a lot of situations you don't need to keep them for that long if everything is running within the same data center and it's really transactional environment but you're using this more for workflow then replication is more than sufficient. The fact that you have all of the data is kept on more than one server is more than sufficient to make sure that your messages your events are not going to be lost. So, unlike the application data caching where there were two copies of the data so the nature of the problem was different, you have to keep the cache fresh. In second and third case it's the opposite, there's only one copy of the data which is the cache. So, now within the cache there has to be more than one copy that is consistent for replication purposes because if you don't have that then Cache being in memory will lose your data. So, you don't want to lose your Messages, your sessions and your page output just because once server is down. So, Pub/Sub messaging in events usually is a really powerful use case for a distributed cache and again all this is open source.
So, there's another feature in NCache called continuous query that actually no other .NET space cache has, some of the Java caches do have it, and a continuous query allows you to specify an SQL type of a query on the cache so, for example, you could say something like select customers where customer.city is New York and you say I'm interested in this case so and you're asking the cache can you please monitor this data set. So. any customer object with this attribute, ever added, updated or deleted from the cache, please notify. So, now you don't have to watch every object yourself which you can't anyway or it's to check , the cache will do it for you. It's similar to how SQL Server in SQL dependency. You can ask your server to monitor data set and notify you when that data set changes. Except that is a one or more rows in a table but here it's objects at a distributed cache. So, those are the three common use cases.
ASP.NET Core – App Data Caching
So, I think the most common use case is the application data caching. Actually, the word distributed cache is more of a Microsoft ecosystem word. On the Java side, it's called in memory data grid. We use three words. We use the distributed cache, we use in memory data grid for web advantage of Java folks, although we're in the Microsoft ecosystem. So, we're not that much and then there's the distributed in-memory data store. So, application data caching is the distributed caching use case.
IDistributedCache Interface
So, if you're going to use application data caching, there are three ways that you can do this. There's an IDistributedCache interface and it's available in ASP.NET 4 which is basically, looks like this here.
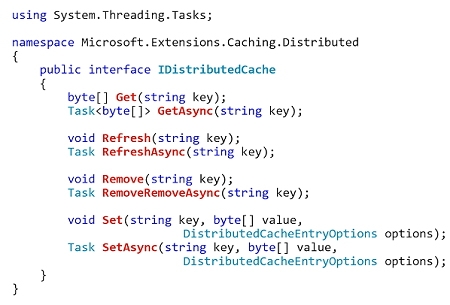
Very simple interface. Microsoft finally gave an interface that allows you to plug in any distributed cache underneath. The only problem with this is it's really really simple. So, you can't do much through this. You can just do really basic. And, the only thing that it does is it gives you expirations. You can specify cache entry option which are the expirations. So, yes! NCache implements this so if you're programming through IDistributedCache interface you can just plug in NCache without any code change, any further code change and you've done the programming but I would not recommend that you should do this because if you're really gonna tap into a distributed cache and the benefit then you want to understand what all the other features? Why should you not use them? Now I'll go with That.
Entity Framework Core Cache
Another is if you're doing EF core, again, if you want to minimize the code that you want to write, NCache present EF core extension methods provider, let me just quickly show you this. So, EF core extension methods really simplify the way you would use cache. Again, just like IDistributedCache, the features are not as extensive.
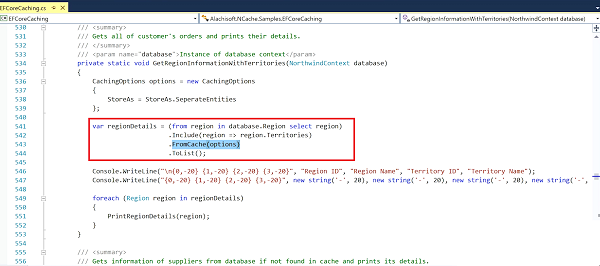
So, for example, let's say that you wanted to see your typical EF Core or EF LINQ based query, what we've done is we've implemented a farm cache extension method and there are other extension methods, as soon as you just say that when behind the team this query will first be looked at and in the cache. If the cache has it you'll get it from the cache otherwise you'll go to the database, get it and cache it before it gives it to you. So, simplifies your programming quite a bit. If that's something that you want, let's say you have any EF core application already and you want to plug in as quickly as possible, this is the fastest way to get NCache in there as you can see this is.
NCache API
The third option is to use NCache API which is also fairly straightforward API. NCache API looks almost identical to ASP.NETcache object but more than that we've tried but we came out long time ago. ASP.NET Core is the only interface for object that was around so we tried to keep it as close to it as possible.

So, it's a simple concept, you connect to the cache, you get a cache handle, you do a cache.get, there's an index or forget, you can do contains, you do Add, insert,remove and they're Async versions of these so that you don't have to wait for the cache to be updated. There are obviously more than that. So, this kind of gives you a flavor of how simple it is to use a cache.
App Data Caching Features – Keep Cache Fresh
Now, the main thing that I wanted to come to was this page. Yeah, I guess I told you there two copies of the cache. If you cache is not able to keep itself fresh, you are going to really limit the use. That's very important to understand. What do caches do?
Expirations (Absolute + Sliding)
Most of the caches provide you Expirations. Expiration is also called TTL, Time to live, we call it absolute expiration because that's where ASP.NET cache object use that term so we just kept with it. What does it do? You're adding an object to the cache, you're saying please expire this five minutes from now or ten minutes from now because I think it is safe to cache it for that long. You're making an educated guess which is fine in some of the reference data cases. For example, you've got a product catalog. It's probably not going to change every 10 minutes. It's pricing is not going to change in there. So, it's more predictable changes for some of the situations. So, it's okay to use expressions there. But, if you're caching a customer or an activity, you don't know when that's gonna change because the customers gonna call and make some changes so you may not be able to live off of Expirations only. So, that's where you need other features in the cache and this is where all these features are in Cache in NCache as Open Source.
Synchronize Cache with Database
One of the features is the NCache can synchronize itself with database. Now the database can be SQL Server, it could be Oracle or it could be OLEdb in case of polling but synchronization means that NCache becomes a client, the cache server becomes a client of the database. It will now use SQL dependency that I was talking about. The same thing as a continuous query but for SQL server. It will use a SQL dependency and I'll show you how that works.
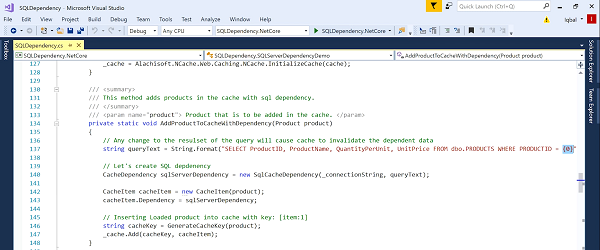
So, let's say… So, when you're adding, let's say you're adding this product object to the cache so you've got a key and you've got the cache item that contains the product. What you want to do is you want to specify a SQL statement that identifies a specific product in the product table and again this SQL statement is for SQL server. You passing event cache, NCache we'll pass it to SQL server. NCache, when it caches this product, it will now notify a register with SQL server a SQL dependency and it'll keep the mapping. So, if SQL server sends an event to NCache saying this product was updated in the database now NCache knows it's still in the cache. So, it will do one of two things. you need to just remove it from the cache. I mean your application doesn't have to do anything it's all being done by the cache or if you've implemented this feature called read- through then it will automatically reload the item. So, I'll come to database in a bit. So, database synchronization is a very very powerful feature. It give you the peace of mind and cache all data. Without which, if you're only doing your explorations, you're limited and it's so bad that if you talk to typical person who knows about caching in the basic manner will give reaction to caching, “oh that's for read only data”. Caching is for static data only. Everybody is afraid to touch the transactional data and that's because of these things, because expirations is nothing more than an educated guess, which may be valid for more predictable cases like product catalog and others, but it is not valid for transactional data.
Synchronize Cache with Non-Relational
So, the same issue if you have a non-relational datastore. It could be something in the cloud, it could be legacy databases, could be mainframe. You can achieve the same goal as SQL dependency except in that case you're not in that notificatio n. A Custom dependency is something that you implement. It is your code that this is server-side code so NCache has this concept of server-side code. Code that you write, that lives on the cache server.
Read-Thru & Write-ThruCustom dependency is one, read-through write-through is Another. I just talked about read-through being, that you can reload the thing if in a database synchronization, if the removing the item NCache can go and reload. How can it reload? Though your read-through code. What is Read-through? Look like I'm jumping back and forth but I wanted to connect these .s that's why. How do you… write and read-through is just a simple interface so you have a read-through interface here. Yes three methods there is an Init which allows you to connect to the data source. Dispose is the disconnect and they are too overloads of LoadFromSource. So, LoadFromSource is a key and you give back cache item and LoadFromSource has an overload where you can give back a Dictionary So, LoadFromSource is something that NCache calls your read-through handler .
So, let's say your application does the Cache.Get and that item is not in the cache and you tell NCache if its not in the cache , please go and ask the read-through handler. NCache will call the read-through handler because Read-through handler is your code that lives within the cache cluster. NCache will call this method. This method is your code, goes to your database, your data source, which may be anything, could be a SQL or called mainframe and get the data and then put them. Now that NCache has the ability to go to your database, it mean it can do auto reload . So, that's the convenience part. So, you can synchronize it with the relational database and non-relational database.
Caching Relational Data
The last thing is caching relational data. You have to do book keeping with data application and keep track of one data and relationship with other. I'm just going to give an example of a customer having multiple orders. Although you usually don’t delete a customer but let's just say if you did and the cache doesn't know it so let's say if you deleted it a customer object from the cache and it had ten orders in the cache, those orders are no longer valid, they should not be kept in the cache. So, whenever you have a one-to-many, usually the many depends on the one, so if you delete one from the cache, you should also delete many from the cache. Now it's something that you would have to keep track of every time you delete one you have to go and delete many. So what you can do instead is that ASP.NET cache object had was attached dependency concept. NCache implemented this so you can relate these two and then if the customer object is ever updated or moved, all of the orders are automatically removed .
You can use the cache dependency for one too many, for one to one and also if you wanted to cache collections and then stored individual objects separately also. So, that's in your collection of customers as one object cached and you had some of the customers also individually cached. Because in the cache you can keep multiple copies. It's all being kept by your application. So, unlike your database which has to have normalization and data integrity and it in that way cache can have multiple copies because it's all about performance. When you have multiple copies and you have to be able to clean up when one copy is updated and that's what this cache dependency allows you to do. So, those are the four different ways that you keep your cache fresh. They're all available as part of NCache open source.
App Data Caching Features – Read-Thru & Write-Thru
I am through read-through write-through again, write-through is the same as read-through, except, when you update the cache you ask the cache to go and update the database.
Read-through and Write-through
So, read-through is when you read the cache you ask the cache to read from the database in case it doesn't have the data. Now, read-through and write-through allow you to consolidate of your persistence code into one caching tier. And, let the cache become more aware of your database and the application becomes simpler and simpler.
Write-behind
write-through also has an added benefit which is called write behind that anytime you update the database, that's the slowest operation in your application is updating the database. It's even slower than fetching data from the database and if you're using a cache for fetching data so you don’t have to go to the database that much. Why not use the cache for updated data if the data is not that sensitive. It means that you can queue it up for asynchronous update. If the data is very sensitive then obviously you don't want to queue it up for asynchronous update but a lot of the data is you can queue it up for asynchronous update. When you queue it and basically you do a write behind feature, you ask NCache to write it to the database in an asynchronous fashion, as a queue gets built or multiple update request, that queue is replicated to multiple servers, in case anyone server goes down you're not lost. And, your application certainly speed there because it's no longer waiting for the database to be updated. So, write-through has the performance benefit. And, write behind.. Read-through has all the benefit.
Auto Reload Items
You can even auto reload with expirations. So, when you expire, you can automatically reload that item. The expiration basically, let’s say, probably change in the database server. It's no longer valid in the cache so it's not removing it why not we load it because you're gonna need it anyway. Then it's probably some sort of a lookup data so read-through automatically. Again, the cache takes over more and more of that work from your application.
App Data Caching Features – Data Grouping
Once you are able to keep the cache fresh and you are confident, now you start to cache a lot of data. When you start to cache a lot of data then it's really nice if you can search data beyond this key value pair. I just talked to somebody last night and they had to really come up with techniques on how to format the keys to find different types of data. This is something that you don't have to do in NCache. You can assign these meta tags called groups and subgroups and tags and Named tags. This is metadata that you can assign to your objects instead of renaming the keys. These could be better data and based on that you can say give me everything that has this tag or these two tags or these three tags or give me everything that belongs to this group. That's one.
Second you can do SQL queries. Let me show you that. So, again, the cache starts to look more and more like a database.
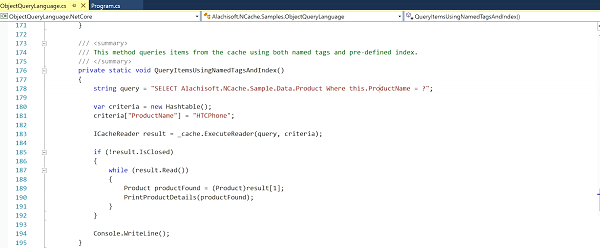
So, for example, you can say here, select all the products with this name so now you're doing a search based on an attribute of the product object. Now this is lot of NCache code so you do execute.reader just like SQL Server. It is very similar, you get an Icache reader back and you just look through it to your stuff. Now, this is something again make the cache do wherever you need to do . On one hand, you put a lot of data in the cache on second now you can search data from the cache.
ASP.NET Core Session Storage
I've talked about the ASP.NET core sessions. I think the main thing to keep in mind that there are two ways you can use it.
IDistributedCache Storage
One is that you plug in NCache. NCache has implemented an IDistributedCache provider. So, you plug in NCache as an IDistributedCache provider and ASP.NET core automatically starts to store the sessions in NCache. See if I have it here.
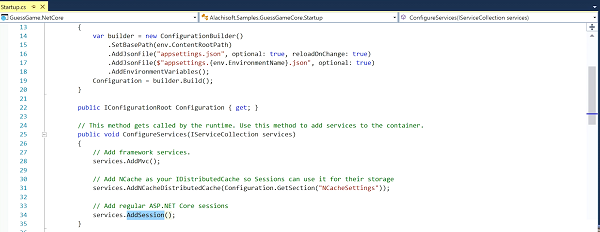
So, for example, here's an ASP.NET Core application, you go to the configure services and you just add NCache as a IDistributedCache provider and now you're using the regular ASP.NET core session which know to depend on IDistributedCache because they know that there's a provider now plugged In. So, when you do this, all of the sessions will be saved in NCache. And, I'm going to show you what caching looks like. I'm just going to give you an actual demo of NCache. So, that's one way.
NCache Session Provider
The second way is that you actually use NCache as its own provider of session Itself, so, you instead of going to a IDistributedCache, you go into the same configure services and you say add NCache session provider.
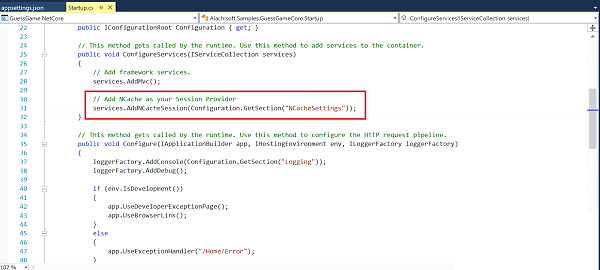
Now, this session provider has more features than the regular IDistributedCache. It has more session specific features. I mean, I would recommend you use the NCache on its own session provider that has been good to go with IDistributedCache. But, you can go to both option, ASP.NET core provides you this. As I said , this required nothing more than that for code changing. That's all. Everything else is automatic. So, if you're going to benefit from a distributed cache like NCache, plug this as an entry point in your application. You have to benefit today because the object cache your application data caching is going to take programming then gonna fit into your development schedules and a slightly longer process than this. But, this is done very very quickly and I know surely this already here.
ASP.NET Core Response Caching
And, this is a config so again I'll go over and the same way response caching uses a distributed cache and you can plug in NCache to that and then it automatically works.

Architectural Requirements on Distributed Cache
Let me quickly go into some of the things that NCache will do.
High Availability
A distributed cache is something like a database, it's living in production with your application. So, you need to make sure that its architecture is flexible, is highly available.
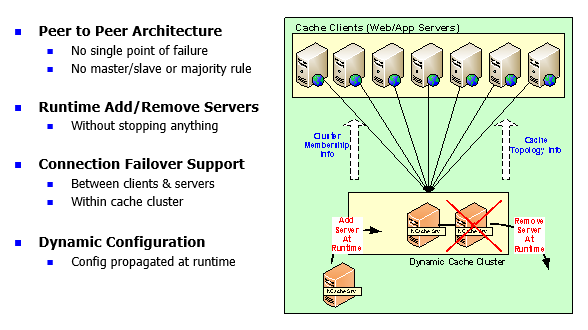
So, for example, NCache has a peer-to-peer architecture but other types of Redis do not have. So instead of having a master slave you want to have a peer-to-peer. As I said, a lot of the Java caches which they call in memory data grid have peer-to-peer architecture. The nice thing about peer-to-peer is everybody is peer so any node can go down and nothing happens. Probably the master slave is the slave cannot become master. If master dies, slave is still a slave. So, that it requires manual intervention for you to recover. In case of peer to peer, it automatically recovers. So, because of peer to peer it becomes what we call the self-healing dynamic cluster automatically adjusts itself. So, that's the first aspect.
Linear Scalability w. Replication
The second aspect is linear scalability which is the partitioning and again linear scalability with dynamic adjustment of partition.
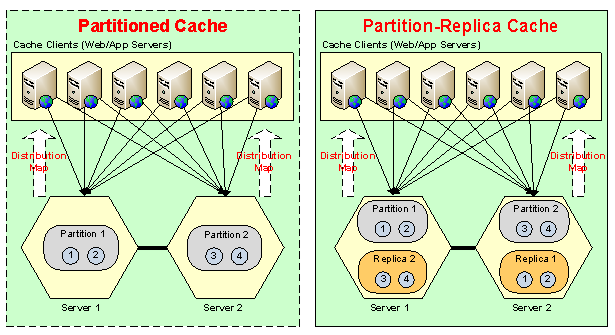
The things NCache does automatically is, let's say if you have a two server configuration and you want to add up that's two partition and now you want to add a third server so that's the third partition being added. NCache automatically, let’s say it goes from , let's say you you have two servers here with two partition. Every partition as a backup on to a different server and partition essentially is a collection of buckets with hash map distribution.
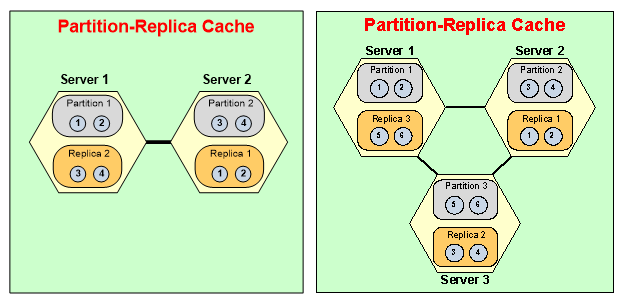
So, let's say if you have 1,000 buckets, 500 will go into partition 1, 500 world partition 2, everything is working fine, now you want to add a third server. St one time because again, by adding a third server now you can have three Partitions, so NCache will do automatically behind the scenes while the application is running, it'll create a third partition and we'll move some of the data for partition 1 and 2 into 3rd partition. Again, one third, one third one third. So, the buckets actually move and they all that happens dynamically. Once the buckets move then the replicas are also readjusted but, replica one and two are no longer the same replicas that they were previously, quickly have less data and there's the new replica called replica three. The server which had replicas two no longer replica 2,it is gonna have three and replica three is going to be created on third server, all that's done automatically for you.
So, that dynamism is what makes it highly available. So, when you adding a server there is a manual intervention but that you have to really… So, it's still very convenient if you can just go and do that. Literally, you just say add and everything is done for you. But, it's even more important when you dropping a server because dropping could also happen because of server crashing. So, when you are in three server configuration, that says server 3 goes down, now partition 3 is lost, what NCache will do is it'll immediately make replica three active because that has copy of partition 3. So, now you have partition 1, partition 2 and replica 3 because partition 3, temporarily. So, there is no interruption. Once that is done then NCache now realize it that only two servers it can only have three partitions, it merges replica 3 into partition 1 and 2, all at one time and then once that merging is done it now creates a replica 2 at this place here. So, you can go back to this picture.
Now this is something that with other fashions you cannot do automatically. What that means is that if this thing happened and the middle on died one of your IT department people will have to manually go and readjust and until that happens a cache for one and what they call limited functionality but NCache does it automatically just so. So, then you need to make sure high availability is really there in a cache.
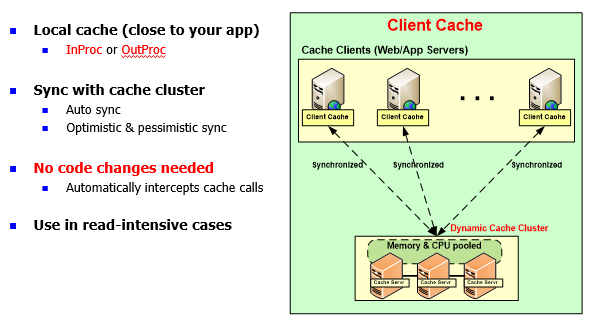
Client Cache
I've talked about the InProc speed already.
Wan Replication
There's another feature and now this is a feature for Enterprise Edition which is that, if you have multiple data centers which a lot of applications now have been moved to, because of cloud its easier to deploy application in multiple regions.
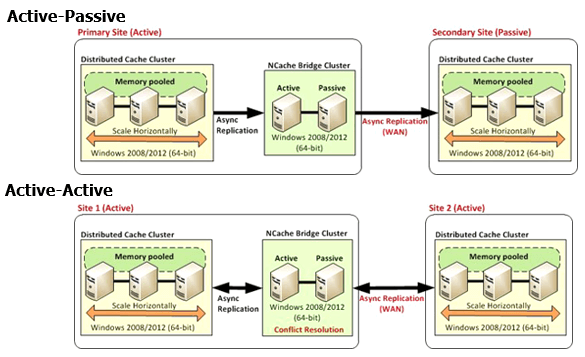
So, if your application is multi data-centered, your cache may also need to be replicated to multiple and because there's a lot of latency you can't really have the entire cluster span multiple regions. So, you going to have a cluster in one in a cluster and there's a bridge in between which asynchronously replicates. So, it's a two-way replication case of active-active and the bridge does conflict resolution because of the same key is updated for both places. Now you have keep track of that.
NCache Demo
Let me quickly show you what NCache looks like. So, I have got Azure so I have basically procured or provisioned, if I can just get the portal, there it is! So, I have got… it's really slow. Come on! Taking four yeah, Okay! So, we have four VMs in this and I'm logged into one of them which is the… So, I've got basically two cache Servers, is all windows, one cache client Windows, one cache client which is Linux. Because it's .NET core, I can do all. Even the cache servers can be living but NCache as I said is .net core so you can just go, when you come to our website, Just, you can actually download either the .msi or the Tar.gz depend on your preference. You can either install the Windows or Linux. Actually, you can download open source also from here. Our enterprise is built on top of our open source so in the we are owners of open source and an enterprise one.
Create a Clustered Cache
So, let me quickly now, sorry about this, I'm gonna create 2 node cache cluster, again, this tool is not open source but all this stuff you can do in open source. It's just not as pretty. Actually, this is going to be a web-based tool now. So, I'm just going to go ahead. This is my first cache server. This is my second cache server. So, I am going to do two server cache Cluster. I will take all the other defaults as Is. I'm going to go ahead and add two clients, one is myself which is the Windows client and the second one I will add 10.0.0.7 client, and the Linux client. Let's start the cache. I mean this is how quick it is for you to create and configure caches.
Simulate Stress and Monitor Cache
I'm going to start my first one stats on this. NCache comes with this program called stress test tool which allows you to simulate load on NCache. So, its like a program. It gets inputs on its own. I have PowerShell opened here so I'm going to do test-stress and enter cache name which is the cache name I just gave here, write here, and I have right now this box, this is first one. So, I am going to client box so I'm just going to run this and you see there's suddenly activity starts here. So, I'm doing about 500 operations per second per box right now, okay? So, let's say, I want to increase my load, I want to test how NCache is gonna perform in my environment so I'm going to go ahead and launch another instance of the same on same box. Suddenly, you'll see that my load has gone up to almost double and now I have two Linux boxes, as you can see here is Linux, this is the . seven box which is right here. So, I'm going to do first start PowerShell here, I want to just quickly copy this module and I will do the same stress- test demo cache and as soon as I do this you'll see this has suddenly gone up about to be 60…
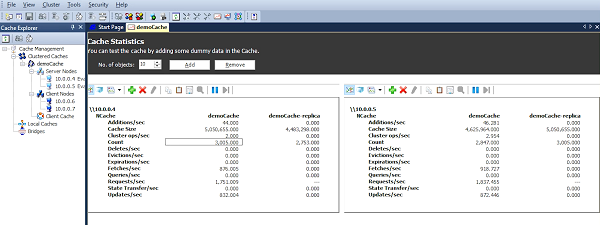
So, every time I do this, about 500 operations per second per box is being added. I'm going to do one more and then we will be done with that. I will add… So, you can keep adding more and more load until you see they will start to max out and then you add a third server. And, of course you need also add more clients. All this is perf-mon that you can easily just monitor, even in third-party tools. This is as simple as it is. These are cached items that you are adding.
You can go into our website download, either the open source, so, open source is available, there's an MSI installer also so that you download the open source. So, you can either go down with open source or if you're really sure that you want to use it in a supportive environment, just go ahead and straightaway download enterprise. Let's say, if I will come to open source, so you can download the installer, that way you don't have to be billed for source code. Again, although all the source code is on GitHub.