Wells Fargo SF Bay Area Technology
Scaling .NET Core Apps and Microservices to Extreme Performance
For .NET, Java, and Node.js
By Iqbal Khan
President & Chief Technology Officer
Today’s server applications need to process a lot of transactions very fast. Many of these are web applications serving millions of users every day. Others are Microservices serving millions of mobile apps or Internet of Things (IoT) smart devices.
Most of these applications are now being deployed in containers like Kubernetes in order to simplify and automate deployment, scaling, and management. And, the choice deployment environments have shifted away from on-premises to leading clouds like AWS, Azure, Google Cloud, and more.
Learn how to develop such applications that meet today’s extreme performance requirements by removing performance bottlenecks related to data storage and databases and also communication among different parts of the Microservices applications.
Overview
Thank you very much Mike and thank you Jason for giving me the opportunity to talk to such an important group at Wells Fargo, the San Francisco Bay Area Technology Group. As Mike mentioned, I work at Alachisoft and the word Alachi, I was explaining to Mike and Jason is sort of a derived from the Hindi word Ellachi which is or Elaichi, which is a spice name cardamom. So, we were just naming the company many years ago, and we wanted to come up with something unique so, we came up with Alachisoft.
Our product is actually NCache. So, I’m not going to be talking about NCache. Today's talk is about ‘How you can Scale your Web Applications and Microservices to Extreme Performance?’ If you are developing these applications in Java, .NET, .NET Core or Node.js, then you've come to the right talk.
What is Scalability?
So, let's get a few definitions understood, before I get into the actual talk. The first is: What is scalability? Scalability is actually high application performance but under peak loads. So, if your application is performing super-fast with only 5 users it's not really scalable unless you have the same super performance in a speed with 5000, 50,000 or 500,000 users. If your application can do that than it is scalable and obviously we want many of our applications to be scalable and I’ll go over into that.
What is Linear Scalability?
The next definition is ‘What is linear scalability?’ This is more of an application architecture and deployment terminology. If your application is architected correctly it will be linearly scalable which means that if you need to increase the transaction per second capacity, which means how many users can you handle? How many application requests can you handle? If you want to increase that you just add more servers and every server that you add increases the transaction per second capacity in a linear fashion.
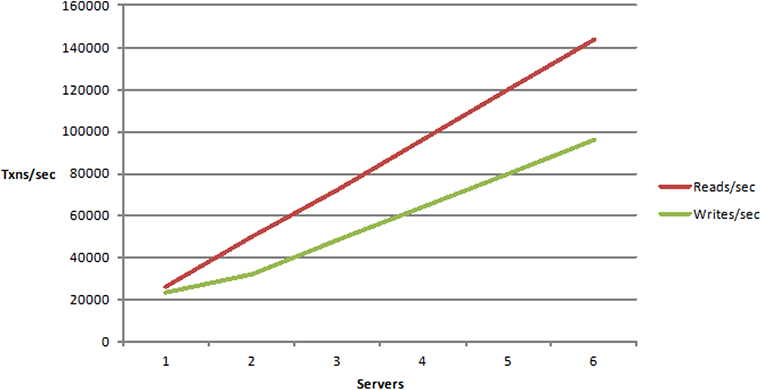
So, there's no blockage, there's no bottleneck. Obviously, the reads versus write curves are different but they're both linear. If you can do that, your application is linearly scalable and which is something that we definitely want.
What is non-linear Scalability?
This is something that we do not want and it is if you architected your application in a way where there are some bottlenecks, so, as you increase your load on the application and you add more boxes, something starts to give in and your application starts to slow down, in fact, it even at times even crashes.
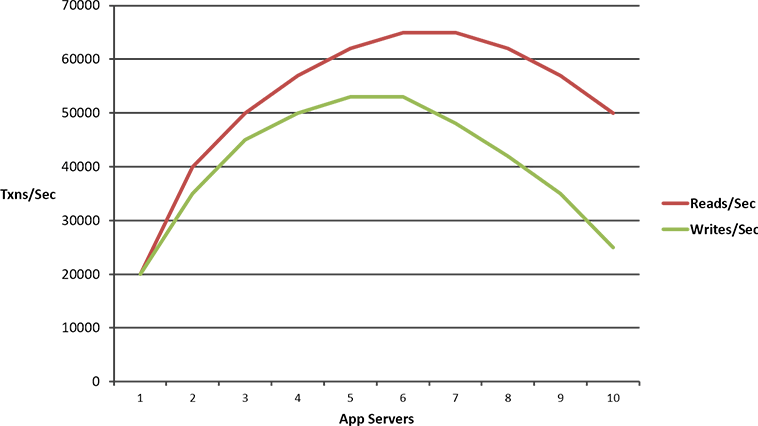
So, we definitely don't want our applications to be architected to be non-linearly scalable.
Who Needs Scalability?
Okay, so, now that we've understood what scalability means, the next thing to understand is, who needs it? Which applications need scalability?
- Web Apps
The most common applications are web applications. These are for a bank like Wells Fargo or other banks that we work with like Citi group and, Bank of America and, Barclays and, bank of Tokyo. These are customer facing applications, you have wellsfargo.com, that is for consumer banking and small business and these web applications need to be able to handle a lot of users without slowing down. So, it's very important that these applications perform super-fast under extreme load.
- Web Services / Web API
Number two are web services, web API applications. These are generally there to service many mobile applications or any other application that call on them to do certain tasks. So, if you have, let's say, Wells Fargo has a mobile application for consumer banking, that mobile application has to talk to some back-end, and that back-end today is most likely web services. Obviously, I don't know that but I’m assuming it is, because, many of the other banks that we work with, have this situation where web services are the ones that are handling this mobile application request. And, they have the exact same sensitivity. They need to be able to handle a lot of load without slowing down.
- Microservices
Microservices is something that is a very hot buzzword these days and, I’m going to talk about it a little bit more in a bit, but it is essentially, you are re-architecting the web services in a new better way, let me just say it that way at this time.
- Server Apps
The fourth type of application is any other server app that you might have. These might be, server apps are doing batch processing. These might be also handling live transactions but, they fall under some other category. But, they also have the same type of a transaction per second throughput requirement.
So, if you're developing any of these four types of applications. There are also a few other, let's say, you might be doing live machine learning and AI but I’m not going to go into that in this talk, we don't have enough time. But, let's say, if you have these four applications, you definitely need them to be scalable. And, this is the talk that's going to go over them. As far as, the technology is concerned, the web applications generally, are developed in Java or ASP.NET, ASP.NET Core, being the new version of ASP.NET and Node.js and, all the other three types are either Java or .NET/.NET Core, Microservices being either in Java or .NET Core because it's the new technology.
Intro to Microservices
For those of you who do not know what Microservices look like, I just wanted to give you a brief architectural view of it. And, for those who do it, just bear with me. So, a Microservices, the reason they're becoming so popular because they allow you to break down your monolithic applications into byte-size Microservices and, every Microservice is decoupled from other Microservices. And, that decoupling means, that they don't call each other. They have their own usually logical databases. They don't have to have physical databases separated but, at least logically, they usually have their own. Some of the Microservices might use a NoSQL database, MongoDB or something else. Some of them will use relational databases, SQL Server, Oracle, DB2. Some of them might be going to the legacy mainframe data.
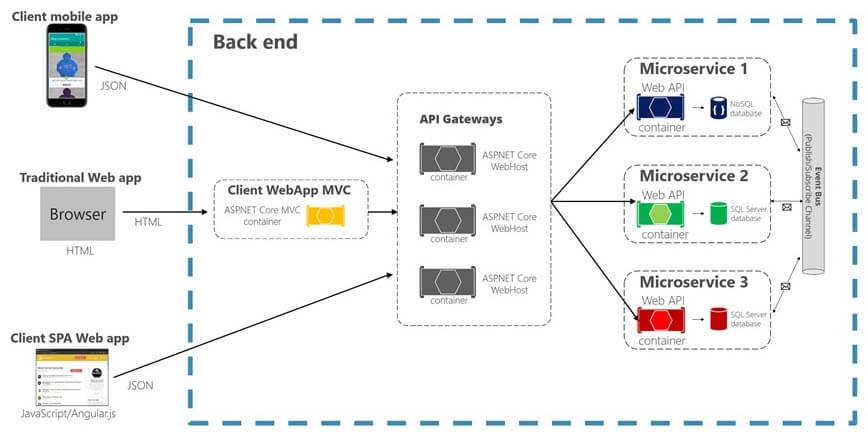
So that, decoupling requires them to then talk to each other through some sort of an event bus, which is what that pipe on the right side is. And, they're called by mobile applications, single page web applications, or standard MVC web application in Java, .NET or Node.js, through the API gateway. So, this is just a good view of what Microservices are. And, I’m going to go into how even they have the same scalability issues that other applications that traditionally have had.
App Deployment Environments
Another thing that I wanted to quickly touch base to because I wanted to put the context around what I’m going to talk about is, the different types of deployment environments that we had to tackle over the years. I've been doing this for more than 15 years now and for the longest time it was all on-prem, datacenters with full control. Even now, many of the banks that we work with, they're still with their own datacenters. But, almost everybody is moving or at least planning to move to the cloud. Some small to medium-sized businesses move to public cloud. Many larger businesses especially, again financial services and banks are generally preferring a private cloud deployment. In fact some of the banks that we work with, they prefer a private cloud on either a Pivotal Cloud Foundry or Red Hat Open Stack type of a framework, which gives them total control over the private cloud environment, it doesn't matter where the private cloud exists. Whether it exists inside a public cloud as a leased space or it's on top of their datacenter that they have right now, or it's something else, it gives them freedom. But, either way they are going to the cloud.
And, Kubernetes is something I’m going to also touch base later on but, it's becoming really another buzzword just like Microservices. Because, it is a very powerful technology that simplifies your Dev Ops. It also gives you environment portability. So, whatever you do once, works in every environment. Whether you're on-prem, you're in any of the clouds, you have the same deployment environment that works. And, in Kubernetes also, many of the banks that we work with are preferring a more cloud platform neutral offering like Tanzu Kubernetes or Red Hat OpenShift. So, I’m just going to go over those concepts later on as part of the scalability topic that we're talking about.
Scalability Problem
Okay, so, let's come back to the actual problem that we talked about, which is, is there a scalability problem that we need to solve? Yes, there is. But, it is not in the application tier. It's not in the application architecture. It is in the data storage, which becomes the bottleneck. And, when I say the word data storage, I mean relational databases or mainframe legacy database or data. NoSQL databases, they don't have the same type of bottleneck and they are being used more and more. But, unfortunately, they cannot be the answer to this entire scalability problem.
The Scalability Bottlenecks
If you see this picture you'll see that the reason relational databases and legacy mainframe are a bottleneck is because, unlike the application tier, where you can add more servers. Let's say, you have the web apps here being deployed in a multi-server load balanced environment, you have web services and microservices also in the same fashion.
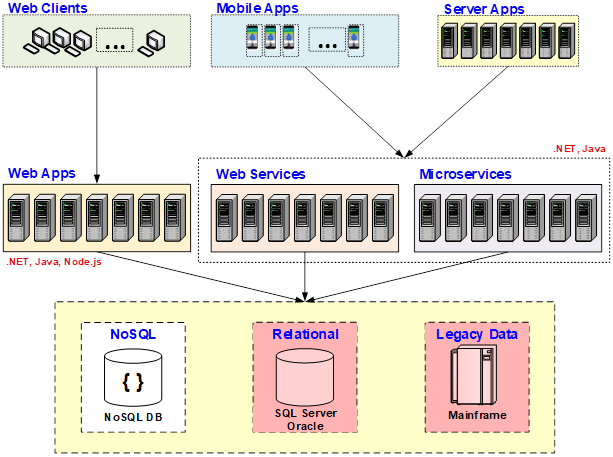
Again, I’m not talking about their environments at this time, just giving you a logical breakdown of being multiple servers. So, by having the ability to add more servers means the application tier never becomes a bottleneck. But, as you grow that tier in size, the data storage becomes more and more of a bottleneck. And, even though NoSQL does not become a bottleneck, the reason that's not an answer to all of your problems is because, NoSQL requires you to move your data away from relational & away from mainframe. Which, in an ideal world, shouldn't be a big deal but it is a huge deal. Most businesses cannot move away from relational entirely. They cannot move away from mainframe entirely. They can use NoSQL as a combination of some data could be put into NoSQL database but a lot of the data has to continue to be in relational databases and in the mainframe. And, as long as that is true, then what that means is that whatever scalability solution we have to come up with cannot be a NoSQL database. It has to be something else other than a NoSQL database. It has to work with relational databases and with the legacy mainframe database.
Microservices Bottlenecks
Microservices, as I showed you the architecture, even they are not giving you a scalability built into them. Even they have the same performance bottlenecks, that web services or web applications have. Unless they're using a NoSQL database, which of course they're not going to have but, even they have to talk to the mainframe for legacy data and many of them are going to continue to talk to relational databases. And, they have an additional potential bottleneck which is the event bus that is there to communicate with each other.
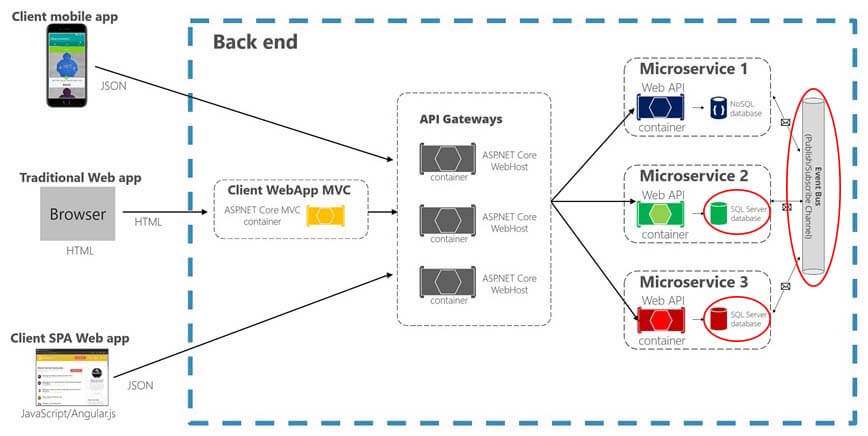
If you have a really high transaction environment that event bus can also be a bottleneck. If you don't have the right solution put into place for event bus.
Scalability Solution
So, there is fortunately a solution to this and, that is an in-memory distributed cache. And, I’ll go into the reasons why it is? But, let me, just make some claims. The reason it is a solution is because, it's extremely fast. It provides linear scalability and it gives you high availability. So, those are the three reasons why it is a solution for scalability problem. And, there's an added benefit that you get by using an in-memory distributed cache that in a large enterprise like Wells Fargo, you can actually use it as a data sharing platform across multiple applications. I'll go over that a little bit more but that's a sort of a fringe benefit or like a side benefit of using this. The main reason is scalability.
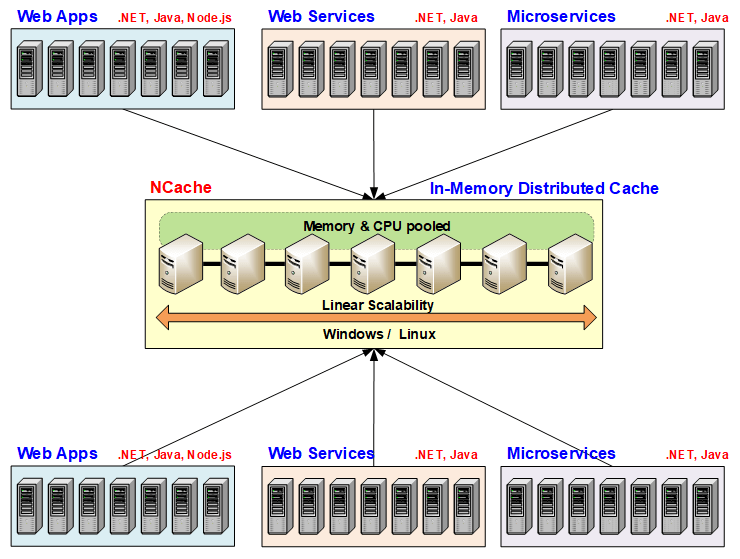
In-Memory Distributed Cache
So, how does an in-memory distributed cache provide this answer? How is it that solution to that problem? The reason it is a solution is because an in-memory distributed cache, first of all is in memory, so, it's super-fast. In-memory is faster than even NoSQL databases. And, second it is distributed. An in-memory distribute cache actually is a collection of multiple low-cost cache servers. And, each cache server is not a database type of a server. These are more like web servers, 4 to 8 cores, sometimes more. 16 to 32 gigs of RAM. Get as many of them as you want for each application and create that as a super-fast and highly scalable infrastructure for the application. Once you have applications tier that you see up here with the web apps, the web services and the micro services and the databases, whether these are relational, these are legacy or NoSQL. Even NoSQL, as I said, is not as fast as an in-memory distributed cache.
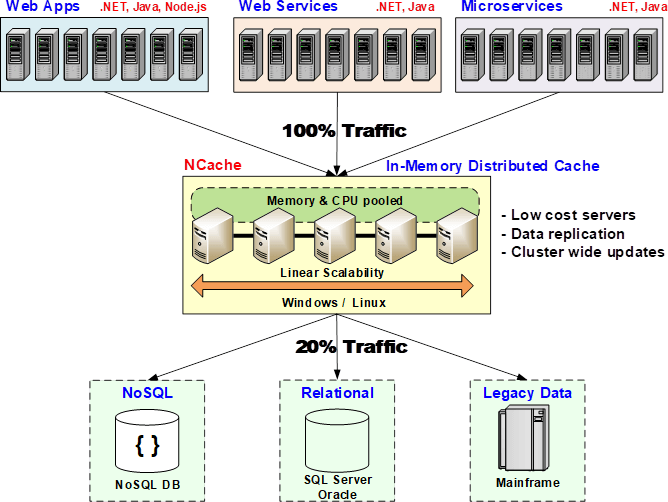
So, what in-memory distribute cache does? It creates a cluster of these cache servers and that cluster pools the memory, the CPU and even the network card capacity of all of these cache servers together. Just like the application tier and, just like the NoSQL database, although even more easily than the NoSQL database, you just keep adding more cache servers as your transaction capacity grows. So, now suddenly you have a redundant and, on top of it, because it's in-memory, it has to provide data replication in a smart way and I’ll go over that in a bit to make sure that if any one cache server goes down, you don't lose any data. Because otherwise, any in-memory store is not valuable. Because, if you lose gigabytes and gigabytes of data just because one server goes down, it's not really a very attractive solution.So, an in-memory distributed cache not only distributes the data, it also replicates it in a smart fashion without compromising performance and scalability.
So, by having an in-memory distributed cache as part of your infrastructure, suddenly now you have the ability to remove that bottleneck, 80% of your data reads are going to the distributed cache. The 20% goes to the actual databases because, the databases are still the master data source. So, any updates that you do to that data, have to be made to the relational database of the legacy mainframe or the NoSQL. But, sometimes even more than 80%, 90% of your read or write traffic can just be limited to the distributed cache. And, suddenly your applications no longer feel any bottleneck.
So, this is sort of like an essential application architecture pattern now, where you have to have an in-memory distributed cache, if you want your applications to be able to scale.
Distributed Cache Scalability
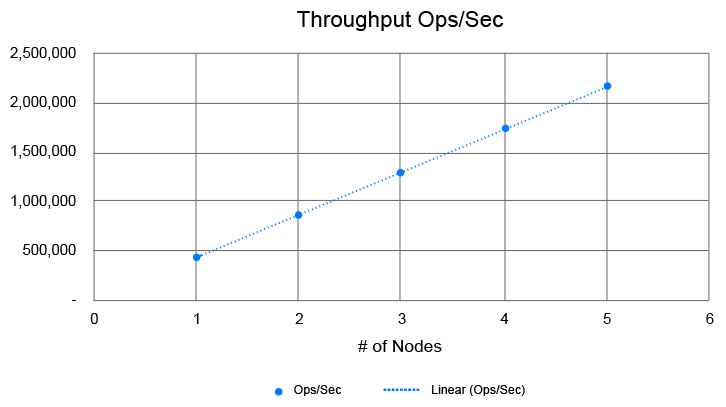
These are some scalability benchmark numbers of NCache, where you can see that with just 4 to 5 nodes, you can do 2 Million operations per second. And, as it's a linear scale, so, if you wanted to go to 4 Million just add 5 more nodes. And, as you know, 2 Million operations per second is a pretty high transaction load, that most of your applications, if they can stay in that load, 90% of your applications are going to be happy within that type of a load. Maybe some will not and they need more. And, when they need more, just add more servers.
Common Uses of Distributed Cache
So, I’m hoping that by now, I’ve convinced you that an in-memory distributed cache is a great idea as far as an application architecture. So, the next or the first question that comes to mind after that is, okay, how do I take advantage of it, as an application developer? Because, these are all about applications. How do I use a distributed cache to take advantage?
- App Data Caching
So, there are three common ways that you can use a distributed cache. Number one is App Data Caching. This is the most common way which is what I was just talking about. Which is that, whatever data you're reading from the database, you keep it in the cache, so next time, you just read it from the cache, very simple. And, whatever you update, you update both the cache and the database.
Now, one thing that you need to immediately understand, that for application data caching there's a unique problem that exists, which is that now the data exists in two places, one is the master database, which could be your relational, NoSQL or legacy mainframe and one is the cache. So, the first thing that can go wrong is that the cache may become stale. So, you've updated the data, you have an application that is not talking to the cache, it goes and updates the data in the database and, suddenly the cache got stale data and, stale data is really bad. I’m sure, you guys know that, more than anybody else a bank would know that stale data is very bad. Some stale data is okay but a lot of stale data is very bad. So, this is the reason why most people when they think about caching, the knee jerk reaction is that okay, I’m going to only cache read-only data, that never changes or, that at least in my application's lifetime or whatever is, in a very long time it's not going to change. Well, if that's only about 10%, 15% of your total data. If you're only going to cache 10%, 15% then you're not really taking advantage of a distributed cache. You have to be able to cache data that changes maybe every 5 Seconds. Or, even sooner than that. Because, even for that 5-10 Seconds you may read it 10 times. And, when you multiply that by millions of transactions that your application is processing every day, you're saving that many trips to the database and how you're going to gain scalability.
So, any distributed cache that does not address this skip this challenge, that the cache should not go stale, it should always be fresh, is going to force you to then not use it fully. So, that's the first thing to keep in mind.
- Web App Specific Caching
Number two use case is the web application. And, the most common use for web application is sessions. Whether you have Java, ASP.NET, ASP.NET Core or Node.js, they all want to save their sessions in a fast and scalable store. And, a distributed cache is a much better store than anything else that is out there. Whether that's Java or .NET or no Node.js. And, there are other things like, there is the page output caching. There's also live web applications. In case of .NET this is called SignalR, that you can use a distributed cache as a platform to share the events across.
But, a web application, when it's other than app data caching, when web application is storing its data in the distributed cache, it has a different type of problem to tackle. Which is, that now, there's no database that has a copy of that data. Cache is the master store. And a cache being a master store means that if the cache server goes down, you lose that data. Which is not acceptable, you don't want to lose a user session just because a cache server or a web server went down. If you want to have high availability you need to have the cache have the features of the capability to replicate that data intelligently to multiple servers. So, that if any cache server goes down you don't lose that data. So, that's the important part. App data caching has a different challenge. Web application specific caching has different challenge.
- Pub / Sub Messaging, CQ & Events
And, the third use case is that you can use and, this is something that a lot of people don't know at all, which is that you can use a distributed cache as a Pub/Sub Messaging platform and Events. We talked and I’m going to show you that even Microservices, they need to do Pub/Sub. So, if they use distributed cache as a Pub/Sub Messaging platform on top of using it for application data caching, then Pub/Sub Messaging will not be a bottleneck for them.
There are a lot of other messaging products that have a lot of messaging features. And, a distributed cache does not match all of those features but, what distributed cache does is that, it creates a very fast in-memory messaging platform for those messages which just needs to be shared within this Microservices or web application environment. So, it's a much simpler environment you don't need to keep those messages around for hours. They just need to be shared within the next few milliseconds maybe. But, there's so much transaction activity that without having a truly in-memory distributed architecture, the messaging platform itself becomes a bottleneck. So, now in addition to the data storage being a bottleneck, your messaging platform is also a bottleneck. So, keep that in mind. And, again messaging platform has the same problem that a web application specific caching which is that, usually, whatever is being kept as the message, it does not have a backup copy in the database. Well, it might be a transformed version of some data that already exists in the database and you might be able to recreate it but, you don't want to. So, you don't want to lose that data, you don't want to lose those messages. So, that's why a good distributed cache not only has to be fast and scalable but it also has to provide that intelligent replication for not only web specific caching but also for Pub/Sub Messaging.
Kubernetes and Distributed Caching
Here is how we have a Kubernetes environment running both web applications and Microservices and using a distributed cache. So, this green area is a Kubernetes cluster. And, Kubernetes has this concept of a cluster. Within each cluster you have multiple deployments. So, each of these three box rectangles is a deployment. So, there's a web app deployment, there are two Microservices deployments and there's a distributed cache deployment and there's an API gateway for the micro services.
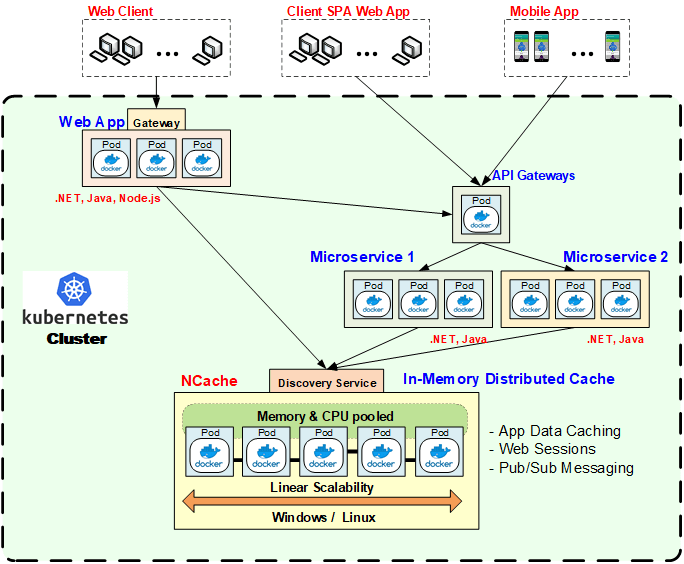
I’m not going to go into the details of how Kubernetes works but basically, in an environment like this Microservices are using the distributed cache both for application data caching and for Pub/Sub Messaging. Whereas, the web application is using the distributed cache for application data caching and web sessions.
Most web applications don't have a Pub/Sub Messaging because, Pub/Sub Messaging usually requires some sort of a stable server process to be talking to each other. But anyway, some of them might but most of them don't. But, the same caching infrastructure that you have in place for application data caching can be used for web sessions and can also be used for Pub/Sub Messaging and these are, in in this case as you can see, these are Docker instances as Pods. These could be Windows or Linux boxes, you know, that depends on your preference on which way you want to go. Most banks these days are moving everything to Linux and even .NET Core because, it supports Linux. Now you can have both .NET and Java applications and of course Node.js on Linux.
So, this is what a Kubernetes environment looks like both for services and web applications and also hosting a distributed cache. One thing that I wanted to point out here is that, a distributed cache to live in Kubernetes has to be compatible with Kubernetes. It has to have implemented what they call a Kubernetes Operator. NCache has it. And so, whichever distributed cache you look at, make sure it is compatible with Kubernetes.
App Data Caching Overview (API)
So, this is my only coding slide. I am not going to go any more into coding than this. The whole idea of this is that, okay, Application Data Caching is the main use case for distributed cache, which every application that you are developing should make use of. Whether that's a web application, web services or Microservices. And, you can see this is a very simple API that a distributed cache has.
- Cache Connection
ICache cache = CacheManager.GetCache(“myDistributedCache”); cache.Dispose(); - Fetching Data
Employee employee = cache.Get<Employee>("Employee:1000"); bool isPresent = cache.Contains("Employee:1000"); - Writing Data
cache.Add("Employee:1000", employee); cache.AddAsync("Employee:1000", employee); cache.Insert("Employee:1000", employee); cache.InsertAsync("Employee:1000", employee); Employee employee = (Employee) cache.Remove("Employee:1000"); cache.RemoveAsync("Employee:1000");
You have a cache handle, you do cache.Get, cache.Contains. There's a key which is usually a string and, you get back a value and a value can be either an object, it could be a .NET object, it could be a Java object, it could be a JSON document. Node.js obviously works in JSON. But, you could even have .NET and Java applications store their objects or data as JSON. And, that actually allows you to even use this as a data sharing platform because, you have a Java application that stores, let's say, a customer object which was a Java customer object. When it gets stored in the distributed cache, let's say, like NCache it gets transformed into a JSON document and then when a Node.js or a .NET application or .NET Core application wants to fetch it they get it … Let's say, .NET Core application will get it as a .NET customer object or a JSON document and Node.js would probably just get a JSON document anyway. So, simplicity is there, Get, Add, Insert, Remove as simple as it gets. So, the learning curve is very quick in using a distributed cache.
Features of App Data Caching
I’m just going to quickly go over a few of the key areas in App Data Caching because, if you're going to use the distributed cache, the biggest use case is App Data Caching. And, what is it that you need to be aware of? The number one, as I had mentioned, there are two copies of the data one in the database one in the cache, so how do you keep the cache fresh?
- Expirations (Absolute & Sliding)
Number one is a feature called Expiration that almost every distributed cache has as a feature and, usually it's the Absolute Expiration. Some call it TTL or or time to live expirations. The other expiration is called Sliding Expiration which is not for App Data Caching, that's more for session type of a situation where you want to expire the object if nobody uses it for a certain amount of time. But, the Absolute Expiration, you're saying to the cache I know that this data that I’m caching is not going to change for the next five minutes or for the next five hours or 24 hours. Whatever is the nature of the data you can specify that. And, at the end of that time the cache will automatically expire this. So, the application can just add it and move on. Application does not have to worry about keeping track of all that data. So, that's the minimum that every cache should have and most of them do have it. But the problem or the limitation of expirations is that you're only making an educated guess. In some cases it's okay because the data is not changing that frequently but, as I mentioned earlier the real benefit is in caching transactional data. So, in transactional data you want to be able to be more accurate.
- Synchronize Cache with Database
Another feature that a distributed cache should have is that it should be aware of your database to a certain extent, so that it can synchronize itself with the whatever data it has cached, if that data, the corresponding data in the database changes, then the cache should automatically either remove that item from the cache, so that the next time your application wants it, it doesn't find it in the cache and it'll be forced to get it from the database or the cache should reload a copy of it. And, reload is possible only through another feature I’m going to talk about, it's called read-through & write-through. But, if you can synchronize the cache with the database.
So, there are two ways that you can synchronize. One is Event based. So, most databases these days now have the data change events. SQL Server has it, Oracle has it, MongoDB, Cosmos DB they all have it. Cosmos DB calls it I think change feed, MongoDB calls it change stream and SQL Server calls it SQL Dependency and Oracle, I think calls it Database Notifications or something.
So, if your distributed cache is taking advantage of those capabilities in the database, so that, it can create some sort of a relationship between its cached items and the database record sets. So, that when that data changes the database notifies the distributed cache that okay this data has changed please take care of your own copy of it. So, then your cache can either remove it or reload from the database and if the database does not have events as a feature then you can use polling as another mechanism.
- Handle Relational Data
The third thing that you want to do is if you're caching relational data, there are some issues of data integrity related to relationships, one-to-many, one-to-one. So, if you can tell the cache that this item, I've got this customer object and I’ve got this order object, they're related. So, if the application removes the customer object, the cache automatically removes all of the orders. So, that way there's no, you know, what you call dangling references in the cache. It's stuff like that, if you can do that, then your cache is again going to always be fresh.
- SQL Queries
So, with these features, if your cache at least has the first two features then you will have the confidence to put all types of data in the cache. And, once you have that confidence you'll start to put a lot of data in the cache. And, once you put a lot of data in the cache another problem comes up, which is now just finding data based on keys is not sufficient. So, you want to be able to find data just like you can find it in the database, which is SQL queries. For .NET, .NET Core there's also a LINQ. So, if you can search data based on object attributes. You can say something like give me all the customer objects, where the city is San Francisco. Then it's acting more like a database. There's also reference data that you can search. There's a lot of lookup data that you can search. So, if you can search the data, now the cache becomes more friendly. You feel more confident caching more and more data because you can find it. Because, if you couldn't do SQL queries, then you your application suddenly becomes very complicated. You have to keep track of every key that you've stored.
- Groups, Tags, Named Tags
The other aspect is again in the same relation is you want to be able to group related data so that you can fetch it all at once. So, different distributed caches provide this concept of groups and tags and name tags that you can then get everything that matches this one tag. Or delete it all from the cache or fetch it from the cache. So, by ability to find data quickly, other than the keys it becomes very important once you start to cache more and more data.
- Read-through and Write-through
This is the feature I was talking about, the read-through, write-through feature. The importance of this feature is that, let's say … Let me first explain what this is. So, when you have a distributed cache, if you don't have this feature then your application goes and reads all the data puts it in the cache and also updates the database with it. But, as you make the cache more and more relevant to multiple applications, now the cache is supposed to … if the cache can become more self-sufficient, it can take care of itself, then that simplifies the applications. Then you have multiple applications that they are just treating that cache as an in-memory representation of whatever the master data sources were. You know, as they could, as I said mainframe, relational or NoSQL. So, they go to this in-memory distributed cache as a key value store, which is very straightforward very simple, it's all in memory, so it's super fast and the distributed cache is able to read the data, if it's not available to read-through is something it's your code that gets registered on the distributed cache. So, the distributed cache calls your code it goes to the database and reads the corresponding item. So, let's say you do a cache.Get on a certain key and that item was not in the cache, the cache will call the read-through to go and get it from the database.
- Write-behind
Same way you can also use the cache to update the data not only in the cache but also have the cache updated in the database. And, the write-behind is a more advanced version of it where the cache update happens synchronously but the database update happens asynchronously.
- Cache Loader / Refresher
The cache loader and refresher is again another way where you can warm up the cache. When you start the cache, you populate it with all the data as you know you're always going to have. So, that way you don't have to call read-through every time. So, once you've loaded that cache with let's say, millions of objects, then cache refresher is another feature which can periodically update certain subsets of that data, based on whatever business rules you specify. Those could be event based, they could be time based, whatever is your business logic says. You can say, okay, go and fetch a more latest copy of the data from the master data source.
Now, in many of these situations, you will have this the scenario where if the data is not very business sensitive it's okay to have some stale copy of it, if it's not too late or too much delayed. But having this all three features, read-through, write-through and cache loader/refresher, suddenly now you have a cache that is very smart. It can go in and load itself from multiple data sources and make itself available not only within the application, as I mentioned already, but across multiple applications.
Data Sharing Platform
So, there's multiple applications, as I mentioned earlier, is the side benefit. The fringe benefit of using an in-memory distributed cache. So, what does that mean? What that means is that now the distributed cache becomes a common infrastructure across multiple applications. So, when applications need to share data with each other, instead of having each other call each other or go to their databases, just put it in a very simple to understand key value store, which is in memory, super fast, highly scalable. And, because all of the features I mentioned the read-through, write-through, cache loader, refresher, all of the others SQL searches, all of those make this a database like thing but, it's not a master data source .
So, in data sharing platform the cache is not the master. It is only a copy of other masters but, it is intended only for sharing purposes. And, I know that a lot of businesses these days they're focusing a lot on consolidating multiple applications to have one common view, one common functionality.
I know that many of the banks that we talked to, they want to have the customer journey understood across multiple applications. So, how do those applications talk to each other? What is that central point where they can share data with each other? It has to be something in-memory. If it's not in-memory it's going to be yet another bottleneck. And, the beauty of in-memory is that you can always restart it and, there's no loss of data. Because, it just reload data from the master data sources. But, it will make itself available. And, because it's redundant, it replicates on to multiple servers. You know, the probability of losing a distributed cache entirely is very very low. And, I’ll go over some of the other features where you can actually have the same cache live across multiple regions, multiple datacenters, one in San Francisco, one in New York and, so and so forth. And, that way, if you have any disaster recovery situation, I know I saw in the news that a few years ago you guys faced a pretty major shutdown. Well, situations like that require you to have a true disaster recovery. So, everything has to be replicated across multiple regions. And, when you use a distributed cache for data sharing purposes, that distributed cache should also be replicated across multiple reasons, I’ll go to that. But, this is a very very important fringe benefit for large corporations especially like Wells Fargo to bring together multiple applications. And, again you can have multiple of these because, you you're such a big company, you may not have one master for the entire company or you may. Or you may have multiple of these in certain parts of your company to share data.
Distributed Cache Architecture
Now that I’ve talked about all the ways that you can use a distributed cache, what should you expect in a good distributed cache in terms of its architecture?
High Availability
Number one is high availability. Because, a distributed cache is being used in live production environments, if it is not giving you truly high availability, you need to be very skeptical of it and high availability means that the cluster that the distributed cache is creating has to have a peer-to-peer architecture. If it does not have a peer-to-peer architecture, if it's got a master slave thing, then once the master dies, you know, that slaves become read-only or inoperable. So, the ability to add or remove server, any server at runtime is very critical.
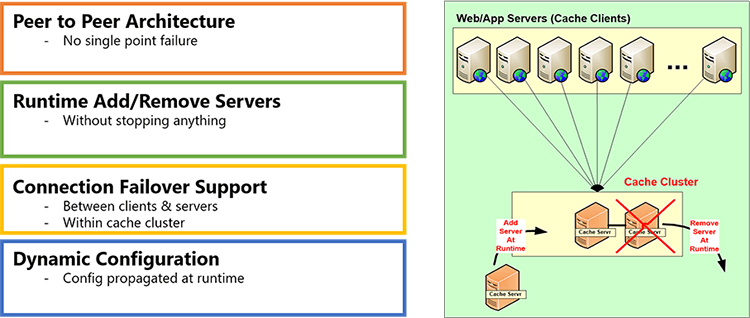
Linear Scalability
Number two is linear scalability and that comes by partitioning the data. I’m just going to go to the next slide and talk about it. So partitioning is in two ways, one just partitioning without replication and, the second is partitioning with replication. So, a distributed cache, as I mentioned, it provides you redundancy and a smart replication.
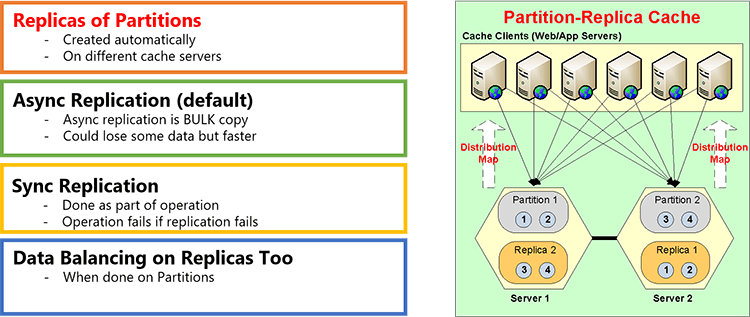
What is that smart replication? Smart replication means that every data is … the data is partitioned and every partition is backed up onto a different server and all of that is dynamic. So, it is self-healing. So, when you add a new server a new partition is created and new replicas are created and the data is automatically balanced.
So, here is an example. Let's say you started with a two server cache cluster and you wanted to add a third one because your transaction load is growing. As soon as you add a third server, it automatically creates a third partition. Now you have three partitions. So, the replicas also have to re-adjust it. All that happens dynamically or automatically.
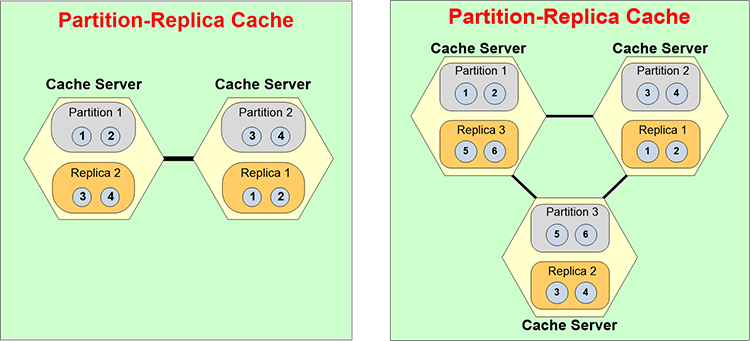
And, the same way, let's say, you want it or one server went down for some reason. Let's say, server 3 went down, partition 3 is down. As soon as partition 3 is down, replica 3 becomes active. And, now you have an anomaly where you have two servers and three partitions. So, now it has to automatically merge itself back into two partitions and two replicas. All of that should be done automatically without any human intervention. If it requires human intervention then it's not truly high highly available. NoSQL databases, because they're databases that they have to deal with persistent storage a lot of data, they do not provide this dynamic repartitioning. And, it's okay for a NoSQL database. But, it's not okay for an in-memory store. In-memory store has to be a lot more quick, a lot more agile in moving up and down in terms of the number of servers.
WAN Replication
Here's that high availability where you have multiple sites. So, if you have a distributed cache in site 1, let's say at San Francisco and you want to have site 2, you can have an active-passive or an active-active. We used to see active-passive more, now almost everybody's moving to active-active because of the cloud. It's a lot easier to get the infrastructure going. So, people just have active-active sites.
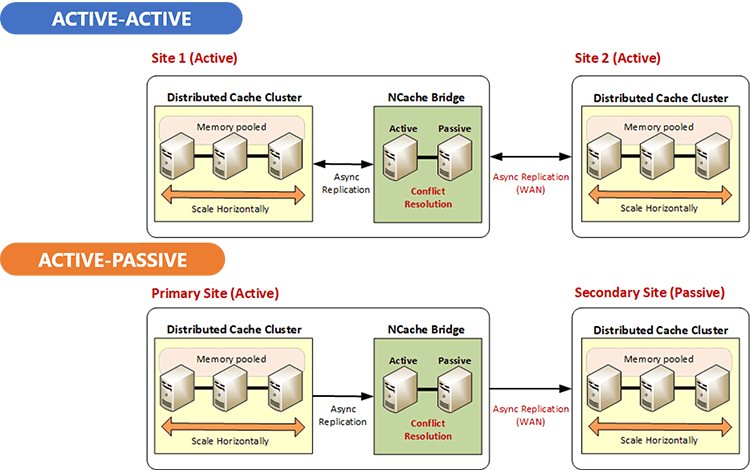
And in active-active challenge is more because both sides might be updating the same data, so there has to be some conflict resolution capability built into the distributed cache which NCache has but, you need to be aware of this that, to get true high availability, you got to go beyond one datacenter and you got to go into multiple datacenters.
In many situations you may not two datacenters might not be sufficient, so, if you have three or more data centers, you still need to have the same active-active replication capability. So, if any one data center goes down the other two data centers should be able to take over the load and then you should be able to bring that one data center back up and have it rejoin and, your users should not see any interruption.
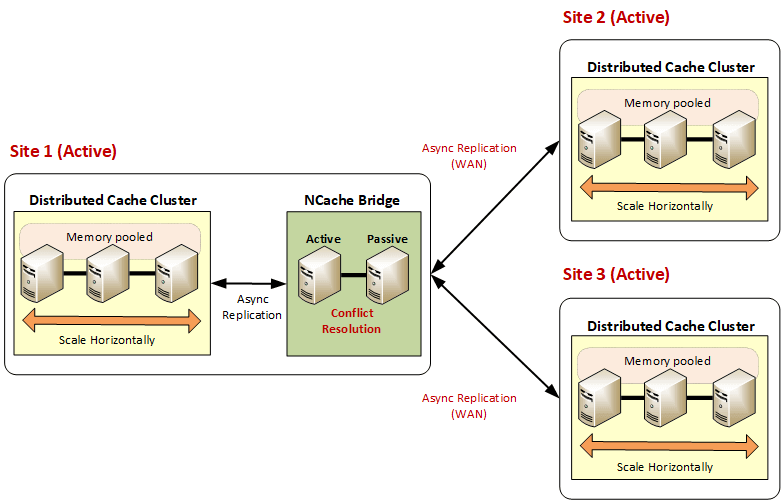
If you can achieve that goal with a distributed cache, all dynamically, without any human … again of course bringing a data center back up needs human intervention. But, there should be no human intervention when a data center goes down, for the high availability to be truly high. If it's even a five minute down, it's not acceptable.
That's the end of my talk. I’ve tried to keep it as quick as I could, just so that we have some time left. I’m just going to give you some summary thoughts. I think the main thing I wanted to drive across is that every application that you're developing, I strongly recommend that you must have an in-memory distributed cache, for those three use cases that I’ve talked about. And, then ideally you should also use it for data sharing across multiple applications. And, either way even within the same application you should try to have multiple sites to make sure that you have the disaster recovery in this.
And, I’m talking about this from 15 years of experience. We've been doing this. NCache has been in the market for more than 15 years and we've been working with lots of banks. We've traditionally been a .NET shop but NCache now fully supports .NET and Java and Node.js. Both, client side and server side code for .NET and Java and Node.js being only the client API. That is the end of my talk.
Thank you, Iqbal. I can't stress enough that as we at Wells Fargo go down the modernization path how timely and relevant this presentation was. So, thank you for that. Team, I will remind you if you have any questions please go ahead and ask them in your chat. We've got a series of questions Iqbal. A lot of the questions team is around, will this presentation and the video be made available? The answer is, yes. After the presentation this will be made available to you on demand. We’ll send you the link up. So, Iqbal, here is the some of the questions that have come in.
How do distributed caches handle sensitive data? Like, transparent encryption is a question.
Yeah, I think I didn't have time but to go into that but that's also a very important aspect. A product like NCache, for example, provides security at multiple levels. There is the Authentication, Authorization, Security. There is the Encryption. So, multiple encryption algorithms. Some 128 bits, some 256 bit encryption. There is the TLS, transport security. So, the cache for a bank like Wells Fargo has to provide security and, that's why because we work with banks. That’s the feature that we've had for a long time. So, data can be encrypted. And again, all of this is automatic. There's no programming needed to do this. These are just configurations. But, a distributed cache must address security through these different features.
The next question is, what is the difference in having the database such as Oracle cache objects and memory and having another memory cache in front of Oracle? Basically, can I achieve the same result by allocating more memory to oracle?
I think the keyword is that ‘distributed’. Anything, that is not distributed, you can be fast but not scalable. That's why my first slide was the definition of the word scalability. Can you go from 1 box to 10 boxes to 50 boxes as a deployment? Some of our customers they have an application server farm of 150 or more application servers. And, you know, we also work with … by the way State Street Bank is also another customer of ours, and with that, there's absolutely no way any in-memory caching by a single database server can handle that. Yes, that's a very important feature to make Oracle and SQL Server and others fast but, they cannot be scalable. Scalability can only be achieved through distribution.
How does NCache performance compared to Redis, Coherence and other market products. And, then the another part of the question is, do you have any plans in your roadmap to support additional programming languages like Scala or Python? Actually, let me, answer the second question first. Yes, we very much are going to support Scala and Python. In fact we're going to do that this year. We have been supporting Java for the last almost 10 years now. Most of the customers who use NCache, if they're large corporation they use it for both Java and .NET. Even though, they might buy it from a .NET perspective. So, that's the first.
The second question was, how does NCache performance compare with Redis and others? I mean, they're all fast. I’m not going to make anybody look bad and I think you guys should do your own comparison but, they're all fast. I think, the only thing that I would warn you against is that some of the players, sort of, you know, give you the wrong impression of doing the benchmarks. For example, the benchmarks that we give, they include complete round trip. So, if you are doing a cache.Get or cache.Insert unless that insert operation comes back to the application that operation is not completed. But, some of the other vendors they would actually show you a much bigger benchmark than ours but they will do what they call fire and forget. So, if I’m only going to send it and not worry about it, obviously I can do a lot more. And, in fact on the Java side Hazelcast and Redis Labs have been going after each other on the exactly same point. So, I’m just going to leave it to that.
You've worked with other banks and stuff, other compliance issues around using PCI data back to the sensitive data in the cache space. Have you encountered any regulatory compliance issues there?
Actually no. I mean, first of all, the fact that we provide all those different security features encryption, both at the data level. Because, you can encrypt data before you cache it and, also at the transport level. We also have authentication and authorization at the server end and, this is the cache server end. And, I think that is sufficient for … and on top of it a cache runs within a secured datacenter. A cache is not something that is accessible to any outside entity. So, when you combine all of these with the fact that cache runs inside we've not had any and, you know, we've had … I mean for example, Citi Group and Bank of America and Barclays have been using NCache for more than a decade now and, did not have any issues.
How will it work with mainframe databases?
I think a mainframe is something that you… Let’s say, that most likely you guys will be… you probably have web services today and you're going to probably develop some Microservices to let applications access the mainframe. Mainframe is another case where to fetch data from mainframe is very costly. Both in terms of speed and, also sometimes if your mainframe is being hosted outside you may even have to pay on a per transaction or per trip basis. So, if you can cache more of that data within your Kubernetes or Microservices layer, as I said, and make fewer trips to the mainframe, not only are you going to gain on performance but you can also probably save a lot of money.
How is consistency and availability of the data across the in-memory distributed cache ensured when nodes are added and removed?
So, at least I can talk about NCache that NCache ensures that when you add or remove nodes, any updates that are being done, any changes that are being done are completed with the fact that we're doing the state transfer, let's say, we are moving partitioning and stuff, NCache is aware that it needs to make sure that all those updates are applied correctly while making sure, that the node is being added and the state transfer, what we call state transfer which is the data balancing to move data from one partition to the other that also keeps happening. So, NCache ensures it.
When having Microservices distributed with their own databases, as I saw in the picture, how can these provide an omni channel experience to the customer?
So, the distributed database part, I think the jury is out on how distributed those databases are going to be. How partitioned those databases are going to be. Because, as I said in my talk, at least in theory every micro service can have its own logical database, even though physically they might reside on the same database servers, because, when you are deploying things, you're not going to have 100 different database servers, each one for each micro service. You are going to have some consolidated database servers. The fact that you have separation probably gives you a little more flexibility just like NoSQL but, the jury is still out on how much can you really get away with that limitation of a relational database. My prediction is that you're going to end up with the same relational database servers. You may or may not have the logical separation. You may have separate schemas or you may have the same schema, you are just talking to different tables but, the database servers are going to still be the same. So, it's the same issue that you are tackling even in web services, they're going to tackle in Microservices. I think with time running out. I can't thank you enough. This has been very interesting. The questions continue to flood in but clearly, we can't get to all of them. So, with that I’ll turn it over back to you.