NCache Split Brain Recovery Architecture
NCache provides an important high availability architectural capability called Split Brain Detection and Recovery. Watch this video to learn about this capability and then see a hands-on demo of NCache Split Brain Recovery.
Today, I will talk about the NCache split-brain recovery architecture and also give you a demo of it.
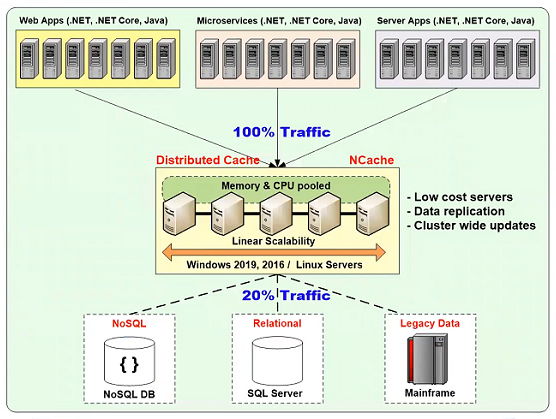
NCache is an in-memory distributed cache for .NET and .NET Core applications. It also supports Java and Node.js applications. NCache is used in higher transaction applications where your application is running on multiple application servers. These may be your web applications, your microservices applications or any other server applications. And, NCache sits in between the application tier and your database, be that be a SQL server or Oracle type of relational database or any NoSQL database like CosmosDB or MongoDB or any legacy mainframe database or data. And, NCache usually has two or more cache servers in a cluster and for this mission critical application environment NCache provides you high availability and as part of that high availability, there's a very important feature called split-brain detection and split-brain recovery that I'm going to talk about.
Dynamic Cache Cluster Architecture
Peer to Peer Architecture (Self Healing)
- No single point failure (no master/slave)
- Cluster Coordinator oldest node, next oldest is auto successor
Before I go into split-brain, let me quickly give you an overview of the NCache dynamic cache clustering architecture.
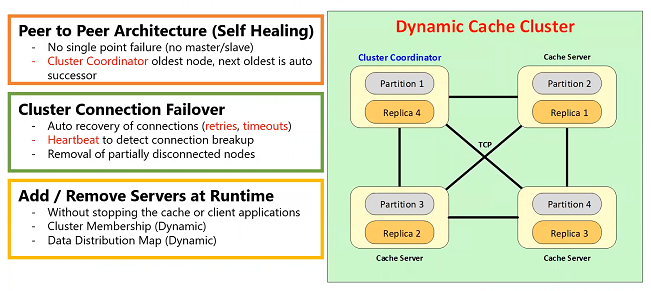
This is a TCP based architecture where every server is connected to every other server through a TCP socket. It is a peer-to-peer architecture which is self-healing. Self-healing means it automatically adjusts itself to any changes. And, there's no single point of failure because of that peer-to-peer architecture. That means there's no master there's no slave. There is a cluster coordinator node which is usually the oldest node in the cluster. But, if that ever goes down, the next oldest node automatically becomes its successor. A cluster coordinator is responsible for managing the cluster. It manages the cluster membership. It manages, in case of a Partition or Partition-Replica topology, it manages the data distribution map. And, it also manages the health of the cluster.
Cluster Connection Failover
- Auto recovery of connections (retries, timeouts)
- Heartbeat to detect connection breakup
- Removal of partially disconnected nodes
Now, as I said, every node in this cluster is connected every other node and it keeps track of that connection. And, if that connection ever breaks, there's a connection failover feature within the cluster which is that, that node automatically does retries, multiple retries which is a configurable option and each retry has a timeout. And, there's also a heartbeat feature where it keeps sending a heartbeat at a configurable interval to make sure that that socket connection is up. The reason all of that is done is because in most situations that is sufficient for ensuring that any connection breakage is automatically restored or recovered from. And, the reason for that is because the cache servers are usually deployed in the same data center, in fact, in the same subnet. So, the connection between these cache servers usually very reliable. And, the split-brain does not happen very frequently but sometimes it does. And, when it does then I’m going to talk about how we manage it.
Add / Remove Servers at Runtime
- Without stopping the cache or client applications
- Cluster Membership (Dynamic)
- Data Distribution Map (Dynamic)
Anyway, this architecture allows you to add or remove any cache servers at runtime without stopping the cache or any of your applications. And, whenever you add a cache server to the cluster, the cluster coordinator updates the cluster membership map and dynamically propagates it to all the cache servers, who then dynamically propagate to all the clients. And, then similarly, if it's a partition or partition replica topology then even the data distribution map is updated and you can go into the NCache architecture video for more details on that. But, a partition or partition replica topology has 1000 buckets which is the distribution map and the map basically, tells the servers which buckets each server has and when that is sent to the clients the clients know where the data is. So, this is the dynamic cache cluster.
Dynamic Client Connections
Add/Remove Clients at Runtime
- Without stopping the cache or client applications
The second aspect of this is the dynamic client connections which is that, just like the connection within the cluster is dynamic, the connection between the clients and the cluster is also dynamic.
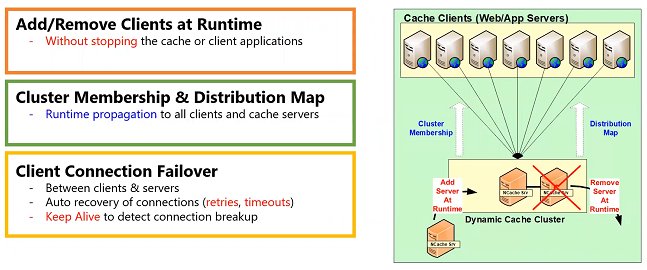
Client Connection Failover
- Between clients & servers
- Auto recovery of connections (retries, timeouts)
- Keep Alive to detect connection breakup
And, it’s a very light TCP based connection. And, if that connection ever goes down, there's again, a connection failover feature where there are retries and timeouts. And, there's also keep alive feature where the client keeps sending a heartbeat type of a message to the cluster to make sure that the connection stays up. Actually, the connection breakage probability between the clients and the cluster is more likely than within the cluster itself and the reason is because the clients could be deployed in a separate subnet, even across the firewall. So, all of that usually increase the chances of sockets breaking. So, whenever that happens the clients can reconnect. So, there's a connection failover feature. This entire architecture allows you to add or remove clients at runtime without stopping the cache or the application.
Cluster Membership & Distribution Map
- Runtime propagation to all clients and cache servers
And, whenever a client is added, the client obtains the cluster membership information from the cluster and then if it's a partition or partition replica topology then it also obtains the data distribution map that I showed here from the cluster. And, that allows the client to automatically know exactly how many servers are in the cluster, who are they. So, you can connect to them in just a partition or partition replica topology and also know what the data distribution map is.
Split Brain Detection
Each Node Detects Connection Breakup
- Keeps connection with any nodes where possible
- Assumes others are down
So, considering all that architecture, there is still situation despite the fact that there's resilience built into the TCP connection through retries and timeouts but a connection may actually genuinely break between the cache servers for some reason. It could be a hardware reason. It could be a network driver issue or it could be any variety of reasons. Whenever that happens, we call it a connection breakup.
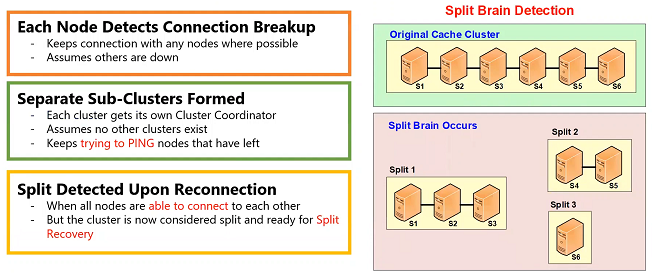
Separate Sub-Clusters Formed
- Each cluster gets its own Cluster Coordinator
- Assumes no other clusters exist
- Keeps trying to PING nodes that have left
So, in the cache clustering architecture, every node in the cluster keeps detecting whether there's a connection breakup, which means that despite retries the connection still broke. Whenever a connection breaks up, each node assumes that the other node has died. So, it keeps talking to all the other nodes. So, for example if you have a server here, this node is talking to all three of these. So, this node may go down. So, this node may be able to talk to these three. When that happens, it will assume that these three are now a cluster of three and this node has left. So, when something like that happens, let's say, a cluster of six nodes and I’m just going to give the example that the connections break up in such a manner that three of them are able to talk to each other, these two are able to talk to each other and this one is not able to talk to anybody.
So, when that happens when these nodes are detecting all of that then they all assume that, okay I am a cluster of three because I’m able to talk to these three nodes and when I’m a cluster of three then one of my nodes is going to become a cluster coordinator which may already be a cluster coordinator because if it's the s1 which was probably the oldest and that continues to be the cluster coordinator here. But, in case of split two, s4 becomes the new cluster coordinator for this cluster. And, for split 3, s6 being the only node becomes the coordinator as well. Now, in this situation, these nodes know that these three nodes are able to talk to these three nodes. So, it says okay I’m good, the others have died. This thinks the same thing, I’m good the others have died. These thinks I’m good the others have died.
But, they also know that, I’m supposed to be a cluster of six nodes. So, they keep trying to ping all the other nodes to see whether they're going to come back up. And, the pinging happens for a configurable interval, after which they will just give up and assume that these nodes have permanently gone down and I’m the only one left. But, within that interval, if let's say the connection, the network connection restores and these nodes are now visible to each other. So, let's say all of them are able to see each other in this example. So, now they realize oh, we have created three separate splits but we are able to talk to each other.
Split Detected Upon Reconnection
- When all nodes are able to connect to each other
- But the cluster is now considered split and ready for Split Recovery
So, NCache will formally detect a split. Even though the split happened the moment the connections broke, NCache nodes did not know that this was a split because they thought they all had died. But, if those node came back within that specified interval then and cache nodes will say, okay a split has occurred and now it's time to do a split recovery. And, the reason this is done is because your application needs a healthy cache cluster in order to continue working and although the split is not a healthy situation, if you can recover from it automatically, instead of your admin staff having to intervene at odd hours of the day or night or weekends. Then it makes your life easier NCache automatically comes back to a healthy state, a healthy cluster of six. But, how does that happen?
The first is that split is detected as I said it is detected only when the connection is restored and they are able to see each other. Until that time they assume that other others are dead. Okay? Now that split is detected, now the split recovery kicks in.
Split Brain Recovery
Splits Merge in Largest to Smallest Order
- Size based on number of nodes in each split cluster
- In each merge iteration, smaller cluster nodes join the larger cluster until all splits merged
So, in split recovery the two largest sub clusters or two largest splits are merged first. And, the cluster of this split and the cluster of this split, they coordinate amongst themselves to say okay since I’m the smaller of the two and the size here is based on the number of nodes in each cluster. It could have been based on the amount of data. It could have been based on amount of activity and number of clients but we chose number of nodes because that was the most likely situation. Because, in most situations, every node has pretty much same amount of data because of the hash map distribution, because there are a thousand buckets that are evenly distributed, because there's a data balancing feature in NCache that rebalances data across nodes if it ever goes out of the balance.
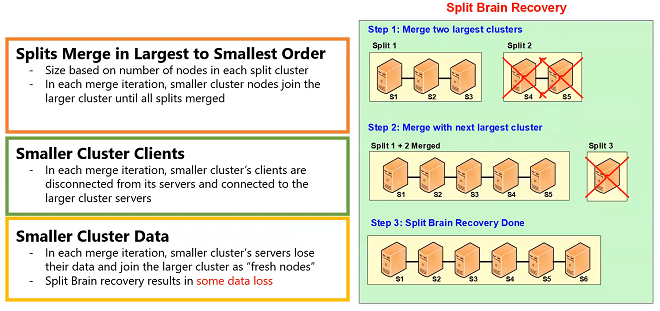
Smaller Cluster Data
- In each merge iteration, smaller cluster’s servers lose their data and join the larger cluster as "fresh nodes"
- Split Brain recovery results in some data loss
So, all of that means that the most likely situation is that every node has approximately the same amount of data. So, the largest number of nodes means the largest amount of data. So, that becomes the master. And, this other split has to give up its data to and rejoin this cluster as fresh nodes. So, the first thing it does, it gives up its clients, it tells. So, these two servers, this coordinator tells its other node that okay we need to give up the clients and tell the clients to connect to this cluster. So, the first thing that happens is the clients move to the new cluster because this is the healthy, this is the master cluster. Once the clients have moved here, now this cluster gives up its data and essentially you can see it reboots. Although, it doesn't reboot, it just gives up its data and rejoins this cluster as a healthy node.
And now, as a result, you have a five-node cluster which is a merging of split one and split two. So, after that is done then it goes to the next largest split and merges that with this. Now, in our case, we had only three splits but you could have more than three and the algorithm is you start with the largest and you merge it with the next largest and the next largest and so-and-so. So, you go through as many iterations as you need to but at any point in time only two splits are merged. So, while these two splits are being merged the third split is considered independent it's going to continue to do its operations until the split is merged and now this merge is going to happen.
And, if there was a fourth split that would be merged after this one as well. So, in this process, please note that depending on how many nodes had to lose or give up its data, you will have data lost. So, for Example, in this case, three nodes become master, the other three lose their data. Even in a partition replica topology, you only have one replica per partition. So, you will lose data and that's just the part of this situation. However, the other part of this reality is that if for data caching situation, this data is already coming. This already exists in the database. So, you're not losing the data, you just have to reload it from the database. You could reload it based on the hit and miss of operations of your application. You could also reload it based on read through. You could also reload it based on cache refresher feature of NCache but either way that data is not lost.
However, if the data was more of a session state, any other transient data, that did not exist in a permanent store then that data you have lost. So, in that case you have to recreate those sessions. But, despite that data loss is still a better situation because after all you have had a failure of network. So, that has consequences.
In the next version of NCache, we are going to be providing a persistence feature where you can have the cache persisted. And, a persistent cache means that whatever was in the cache, is kept in its own, NCache's own persistence store and that way in in a split-brain recovery, you will not lose even the transient data, because NCache is keeping a copy of it on a persistent store. But, I’ll go over that when that feature is made public. So, at this time I’m just going to talk about this.
Hands-on Demo
So, I hope I have explained this architecture. Now, I’m going to actually give you a demo of exactly how you can do this in NCache. So, I have an example where I have five cache servers and I’m going to create a split between this and this list.
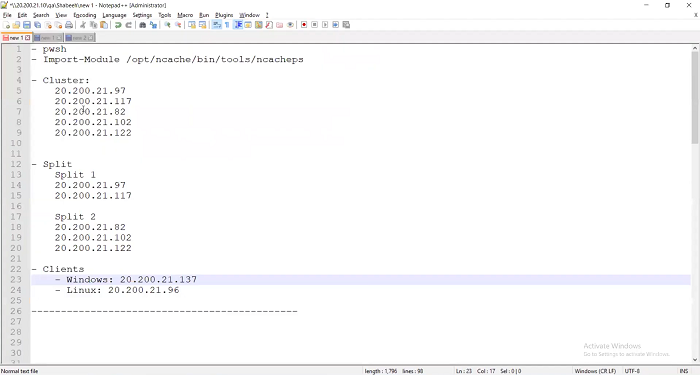
I’m just going to create these two splits. Split one is going to contain these two cache servers and split two is going to contain these two cache servers. And, I’ve got one windows client that I’m going to use which is where I’m sitting right now, which I’m going to use for doing management and monitoring. And, I have a Linux client that I have two shelves open to this client. So, I can have two separate client applications launched from there. So, I have this cluster running right now. I’m not going to show you how to add this cluster because there are other videos that show you how to do that. I’m just going to show you the split-brain part of it.
Monitor Cluster Health and Statistics
So, here, I’ve got a five-node cluster. I’ve got a five-node cluster. So, I’ve got a five-node cluster which is right here and it's running. Okay and I’m going to go ahead and open the statistics and I’m going to also open its monitor. So, what I have done is I’ve opened two different NCache manager windows. One is connected to the .97 which is right here, and one is connected to .82 right here. So, this one is .97 which I’ve got the actual manager. I’ve got the monitor and I’ve got the statistics. And, the second one is the .82 and I’m going to do this again. It's the same cluster but I’m just talking to a different server for management. I’m talking to this server as compared to this one, right here. And, in this, I’m going to again do statistics. So, I can see the activity. Currently there's no activity because I don't have any clients running yet. And, I’m going to also open the monitor.
So, why did I open two of these? Because, I want to monitor, I want to connect to this node and I want to connect to this node. So, that when I do the split I can see. Because, if I’m only connected to this when split happens, it's just going to show that I’ve got only two servers left and these it's not going to be able to see. So, I want to see this from both perspectives. Because, I’m going to introduce the split through a firewall rule, of course, in your case you're not going to have the firewall rule. You will have some sort of a network outage. So, I’m going to sort of introduce or simulate that through a firewall rule. So, I’m now connected to this node for management and monitoring and this node for management and monitoring. And, I’m going to now come here and I’m going to… oh no not yet.
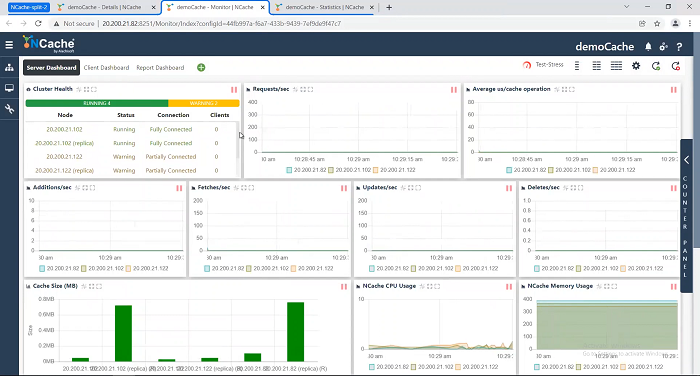
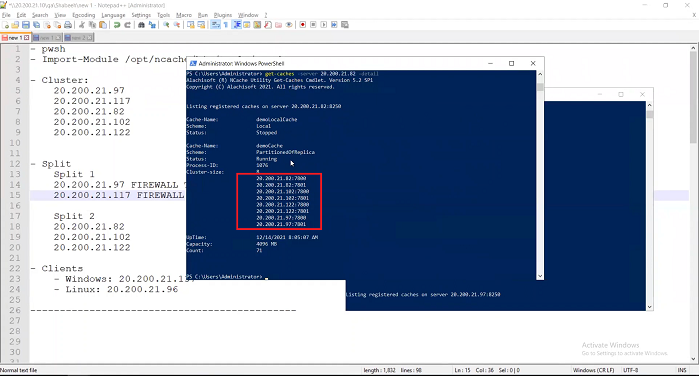
I’m going to also use this command line to call Get-Caches-Server and I will talk to .82 here.
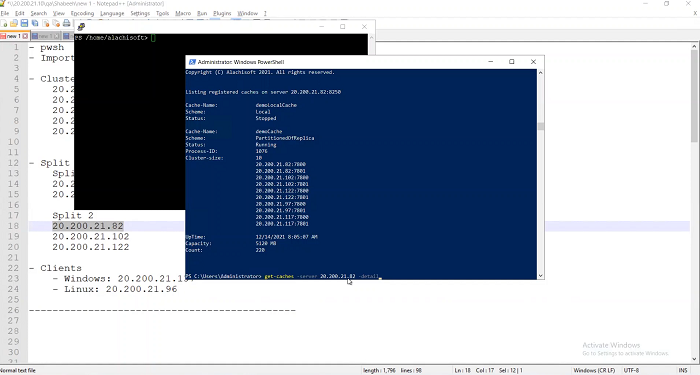
I’m going to talk to 82 and say give me the details of all the caches that you have. So, .82 is saying, I have a cache called democache in which I have five servers; 82, 102, 122, 97 and 117. A five-server cluster which is because there's no split right now.
I’m going to go to the other server, the 97.
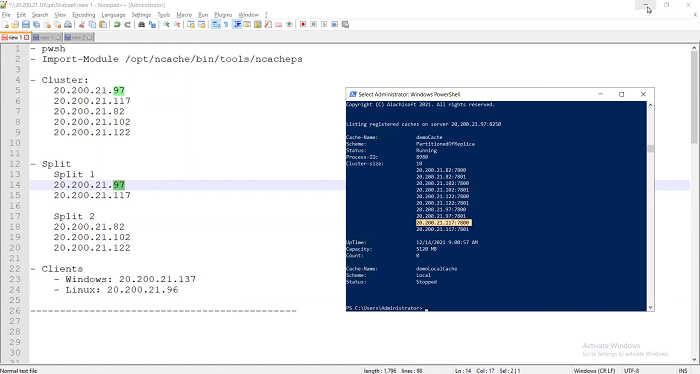
I’m going to ask it the same thing. I said give me your server. It all says okay I’ve got a five-server cache; 82, 102, 122, 97 and 117, currently. So, it's five server cluster, no Split, everything is fine.
Simulate Stress using Test-Stress Powershell Cmdlet
Everything's working Fine. I’m going to now start the application. I’ve got a PowerShell window. Actually, this is a Linux box right here. I’m going to show you what happened here. Come on! I’m just going to open PowerShell again. My apologies. I’m just going to import this module which is the NCache management module. You only have to do that on Linux. You don't have to import this on windows. Then I will say Test-Stress democache. Okay. So, now I’ve run this one of this tool. I’m going to do the same here.
I’m going to say Test-Stress democache. I’ve got both of these. Now watch, I’ve got activity happening. I’ve got activity happening on all five nodes, as you can see here, one two three four five. On all five nodes I’ve got activity happening. Right here, I can see that. Here as well. I’ve got five nodes. I’m talking 97 again, this is .97 now.
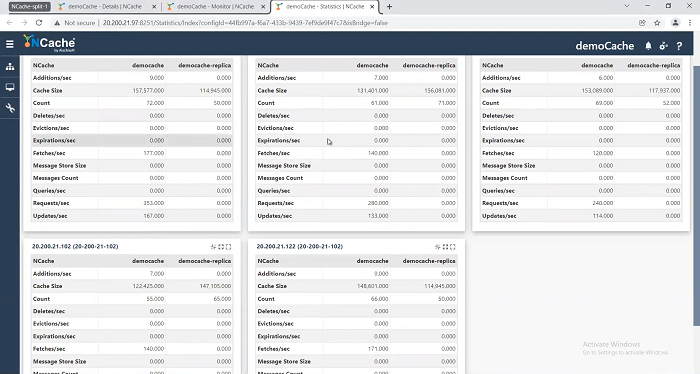
Let's see if I can see the same here as well. So, I’ll go to .82 and see I’ve got five nodes activity happening. The statistics window is also showing activity.
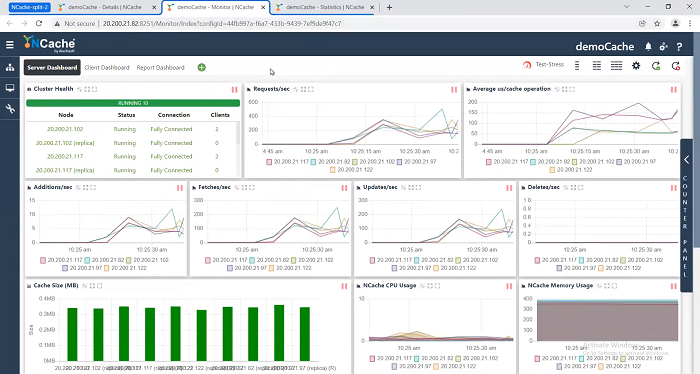
Okay! So, everything is working fine. Normally, I would not open this and cache manager monitor on two different servers. The reason I’m opening is because I need to show the split and when split happens I need to show you from both side of the split what is happening.
Inducing a Network Disconnect
Okay! Now that I have everything running. I’m going to now go ahead and introduce. So, what I’m going to do is on these two boxes, I’m going to use the firewall rule. So, I’m going to use firewall Here. I’ll use a firewall here. So, I’ve got those two rules already set up. So, I’m going to log In. I’m logged into 97 here. I’ve got a rule here. I’m going to go to the let's say I’ve got an inbound rule. It's NCache, I just called it NCache split-brain. This rule is saying block the connection on what ports, 78 to 7900, that's the cache.
NCache starts a separate process for every cache. So, that cache process uses by default, 7800 to 7900 port. Although it's configurable. So, you may be using a different port in which case you have to block those if you want to simulate this. And, port 8250 is the management port.
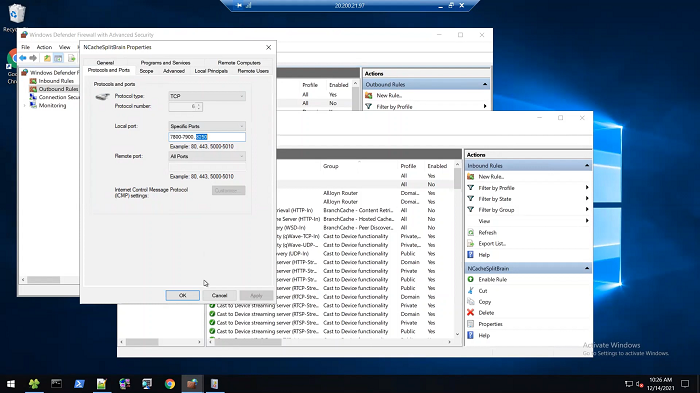
Scope is saying block for 82, 102, 122. So, I’m telling this one, block these three boxes from accessing you, that's basically what it's saying.
So, I’ve got this port. I’m going to say enable rule and I’ve got the same port for an outbound rule. It's an... So, it's blocking for outbound. And, now I’m going to go to the 117 and block that as well. I’ll come to 117. Again, I have an inbound right here. Same thing here. Block connection, ports, 78 79, scope, all these three boxes. Okay. So, I’m going to say enable rule. That's enabled. I’m going to go to the other one I’ll say enable rule right here.
Okay, now what I have done, I have turned on the firewall on all of these.
Formation of Two Sub Clusters
So, now the split is going to start happening. Although it's not going to happen immediately and I can see that by I’m going to first ask 82 which is this, how many servers do you have in the cache? It says okay! I’ve got 82, 102, 122, 97, 117. So, it still has all five because the split hasn't happened yet. It's still going through the retries and all the other stuff. I’m going to ask the other one, how many servers you have? It still has one, two, three, four, five. So, no split has happened yet because it's still going to retries and timeouts. But, the split is going to happen soon.
I’m going to come here and see if it's starting to see some stops. So, I’m talking to 97 here, 97 is the two-node cluster side.
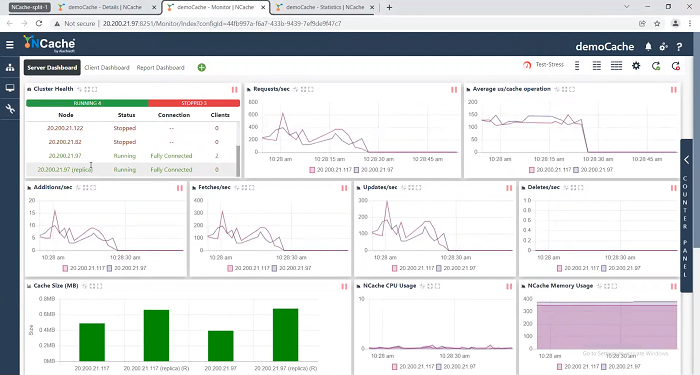
So, 97 is telling me that it is only seeing… So, it's not seeing 102, 182, 82 is saying those are stopped but 97 and 117 are running fine. Okay! Let's see what is the other side showing. The other side of the split which was this other side. So, I was talking to 97, now I’m going to talk to 82 as you can see this is the 82, right here is the 82. IP address… it's saying okay! Saying 102, 122. So, It’s saying 122 is partially connected and 82 is fully connected.
It's still going through that recovery. It's still going through this retries phase where 122 is not able to talk with some of the other nodes but it's going to go ahead and what’s going to happen is, I’m going to quickly show you…
So, there's a feature here that I told you about that in the cluster, if there's a partially connected node it removes that partially connected or partially connected node from the cluster to create a healthy cluster. So, that's what's happening right now is that it is removing that other cluster, that other node which is a partially connected node. Now, let's come here again and now see what does the command line say. I’m talking to 82 which is, as I said, that's the three node cluster. So, it should… let's see how many does it have? Oops right here, it's saying 82 it has one, two, three, four. So, it's got four. It doesn't have five yet. It has four. It's still going through the… it's going to forcibly remove the nodes as they are and now I’m going to go to 97 which is right here and I’ll say okay how many servers do you have? And, 97 only has two.
So, 97 has already established the fact that it cannot see the other three. So, it thinks okay I’m the only cluster here. It doesn't know there's a split because as I said the split only, NCache only knows about a split when this connection is restored. So, right now it just thinks the other nodes have died. So, and it says okay I’m going to continue with myself with these two nodes. And, let me go to the other one here. Let's see what does it have. Oh okay! Now it also has three left. So, it has gone through and it has also done this. It has removed the partially disconnected node to now reach a healthy cluster. But, it's a cluster of only three nodes, right?
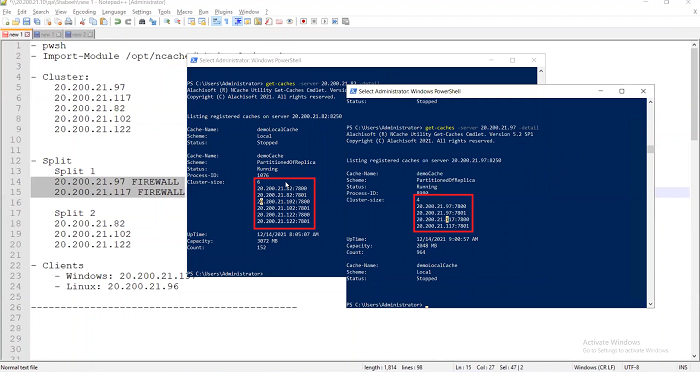
So, I talked to server .82 here which is right here. I asked it how many servers you have in your cache, it says only three. I asked 97 how many servers do you have in your cache, it says only two.
Okay! So, a split has happened. As part of the split you will see that so far the application has not thrown any exceptions. That means the split has happened without any data loss. This probably could be that the application has not encountered but in some cases, you will encounter some exceptions.
Split Brain Detection and Recovery upon Network Restore
Okay! Now, the next step that I’m going to do is to go ahead and kick in the split-brain. So, I want to now restore the connection so that split-brain is detected and a recovery is started. But, before I do that, I’m going to show you that in my cache configuration if I go to the cluster settings which is the first topic here, if I go all the way to the bottom, I have already enabled auto recovery for split-brain.
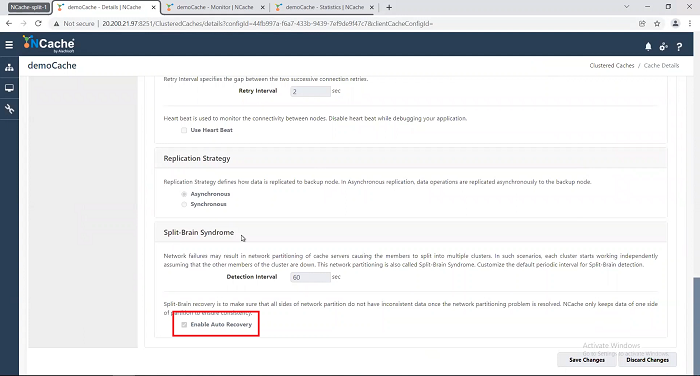
So, if you enable auto recovery that means NCache will automatically recover from a split brain once it detects the split brain. And, as I mentioned, it detects the split-brain when the connection is restored.
So, let's now go back to 97 and this and turn off this firewall. And, I’m going to do on 97 first. I’m going to come here and I’ll say, disable this rule and I’ll come here and I’ll say disable this rule.
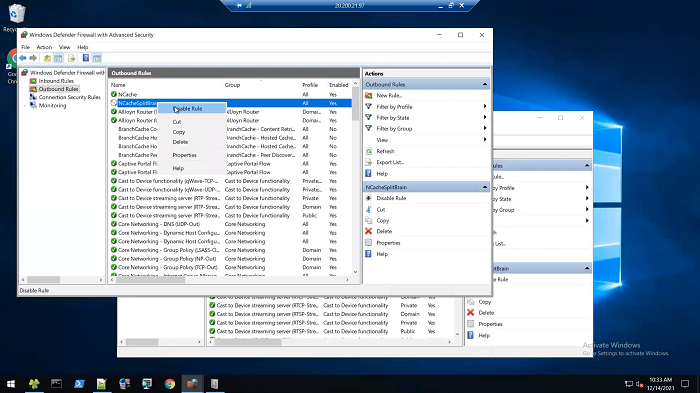
Okay! I’ve done that now I’m going to come here to 117 and I will say let's do disable the rule here as well. Disable the rule. Disable the rule. Okay! Now I have disabled the rules. So, this firewall is turned off that means they are now able to see, or pretty soon, they will be able to see each other. It's not going to happen instantaneously but they will be able to see each other. And, as you can see…
So, I’m going to actually come here again and I will say show me your cache. I’m again, I will keep this in front of me and I will say sure I’m talking to 82 right now and I say show me your caches, 82 says, I’ve got 82, 102, 122. So, so far it still has three caches. It's not seeing the other two. I’m going to go to the other one and I I’m going to say show me your caches. It's saying 97 and 117. So far split-brain recovery has not kicked in but it will. It will because it takes a little bit of time for the retries to happen. As you can see here, I’m seeing one two three four five servers already. And here one two three four five servers.
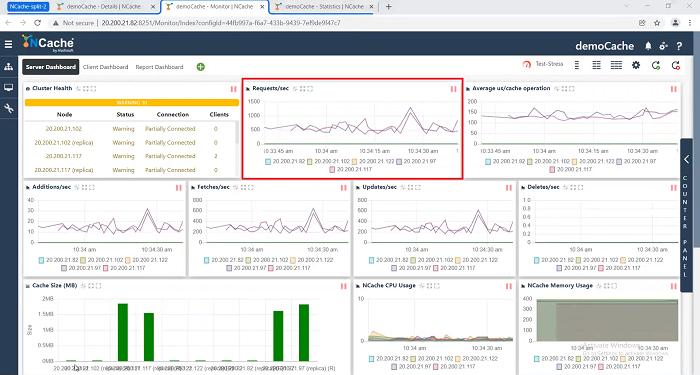
But, I’m going to again, depend on my good old command line PowerShell tool to tell me. I’ll do that get caches call. I’ll talk to 82 and say show me how many servers you have. It still has one two three. And, I say show me how many servers you have right here. It still has one two. So, again, one two and one two three. So, no connection has been. So, the split-brain has not been recovered from yet. And, that's why it's still going to partially connected, partially connected, and the clients are continuing to work.
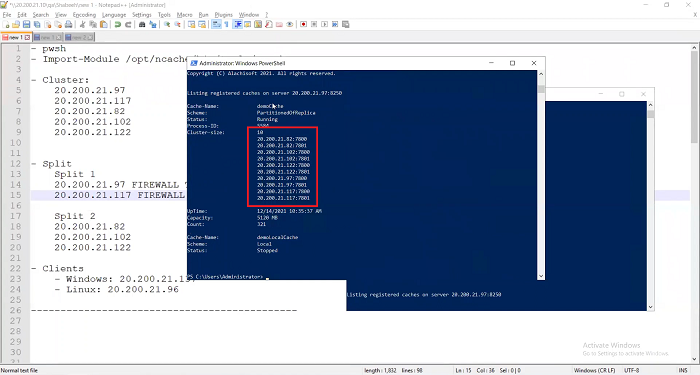
Okay! let me go again. Let's do another one. It's still not done. Okay! Go here. 97.. Come on! Okay! Now, it's starting to see the other node. 82, 102, 122 and also 97 right here. But, it's still partial. It needs to see two of these and you should see both partition and the replica and that's why it's probably not able to talk to 97 yet because… Okay! Now, 82, 102, 122, 97, again five nodes are restored here. All five.
Let me go to this one. This one. Somehow it… Come on! I will change it here. So, instead of 82 I’ll say 97 here. Now do that. I’ll see that 97 also is showing me five nodes, one two three four five. Okay. So, all five nodes are reconnected.
I’m going to come here. Let me just restart this monitor. I will come here again. This cache, I’ll say statistics. I see all five are working and the clients are talking to them. So, again the fact that the client is talking to all five means the client connections are also restored automatically. And, the monitor is also going to show me all five here. So, as you can see fully connected, all five nodes.
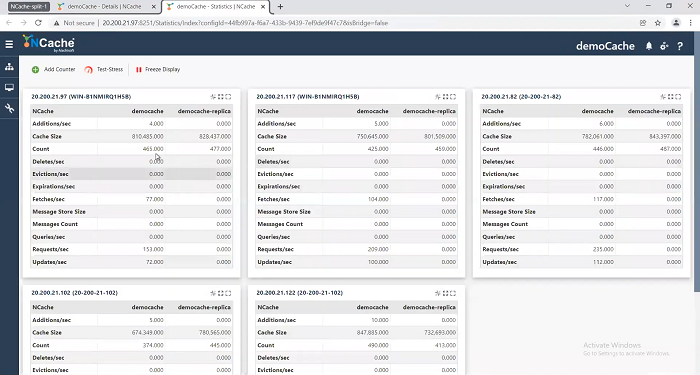
Okay! Now let me come here to the other One. Did I go to the other one? This one. Okay! I’ll say okay statistics. All five are I’m talking to all five here, as you can see, activity is happening on all of them and I’m going to say monitor all five are happening here.
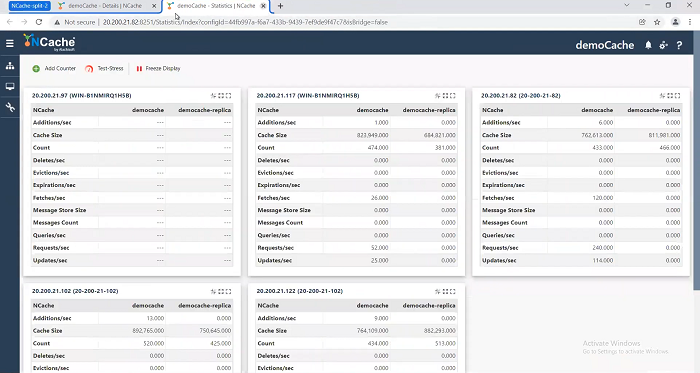
Conclusion
So, we went from having a healthy cluster to having a split to again having a healthy cluster. And, we're able to see that, here as well, that we have a five-node cluster. So, that's pretty much the end of this demo. Please go ahead and play with NCache and see that with split-brain recovery, you have this added capability of high availability.