NCache Architecture
Recorded show
By Ron Hussain and Zack Khan
Today's webinar is going to be based on NCache Architecture. Now, we're going to be covering an overview of distributed caching and, how it resolves your bottlenecks in .NET and .NET Core. We're going to go over common use cases, as well as the distributed cache architecture and, clustering details, as well as any of the questions you might have in regards to not only in NCache, but caching in general. Now, anytime throughout this webinar, we do have the option for questions here in the GoToWebinar questions tab, so please take a look at your convenience for the questions tab. And, once you write in a query, I will be able to bring it up during the presentation to be answered by Ron or myself. We also have a small amount of time at the end of this session in order to be able to go through any other questions that come in, but we're looking forward to having a great time.
So, without further ado, I'm going to hand it over to Ron, and let's get underway. Very good, thank you, Zack. So, everybody as Zack just mentioned, today's topic is NCache architecture. In this webinar, I'm going to cover in great details how NCache clustering works, what are the most common topologies that you can choose from, and one of the main benefits of NCache in terms of your application use cases. What are those use cases, and how you can take full advantage of NCache within your server applications?
So, I hope everybody can see my screen. If I can get a quick confirmation on that, I will quickly get started on this. Yeah, I think we're all good if you can. There you go, I think. Yep, looks good. Perfect. Okay, so let's quickly get started with this.
The Scalability Problem
All right, so let's first of all define what NCache is? And for that, I will have to go ahead and define what a scalability problem is, and then how NCache is able to resolve that scalability problem. So, in a typical server architecture where you have applications deployed, it's usually more than one instance or more than one server, you know, whether those applications are deployed. So, it's safe to say that your application tier is something that's very scalable.
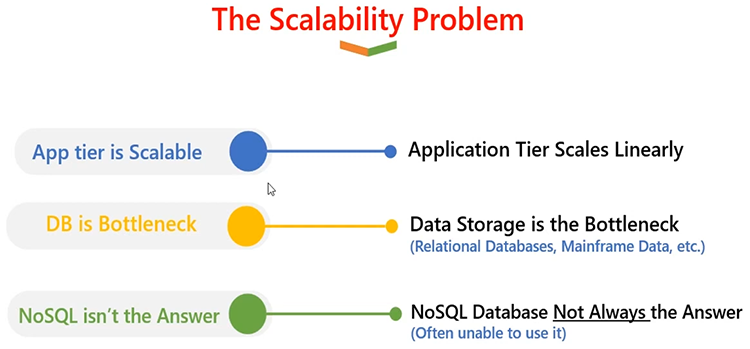
You can add as many servers in an application tier. You can construct a web form, an app form, were multiple application servers or web servers are hosting the same application, but they are working in a team and, they're dividing the request load among themselves. And, if you go towards a newer architecture, with even microservices architecture, you have ability to individually scale your application services, microservices which need more computation or more request-handling capacity.
So, App tier is very scalable. It's linearly scalable. As you grow, you're able to handle more and more request load. The issue comes into play when you're dealing with the database, such as a relational database. Because all of these applications, regardless on a level of scalability how scalable they are, they would always have to talk to a backend database. And, when they talk to a backend database, that's usually a single source. And, that's not very scalable. It's very good for storage; you can have a lot of disk resources. So, you can draw storage benefits from it. But when you have a huge transactional load on your applications, and that translates onto a database transactional load, databases tend to choke down. And, that's the main problem, you know, where the application struggles with request handling. It's not scalable, end user experience is compromised as well.
NoSQL databases are somewhat resolve this problem. You can have SQL database, but that requires that your application is re-architectured in such a way that it stops using a relational database and starts using a NoSQL database and, that's a big project. So, NoSQL is not always a solution to a scalability problem.
The Solution: NCache Distributed Cache
So, what should we do now when we have this? The solution is very simple: you should have an in-memory distributed cache like in NCache. First of all, it's in-memory, so the number one benefit that you get is that your application's performance will be increased. It's super-fast in comparison to a relational database. And, the main benefit is that it's linearly scalable. Unlike a database server, which is usually a single source. NCache can reside on multiple servers. It allows you to create a cache cluster which can run on multiple boxes. And, as you know, your requirements or needs grow, where you have to have more request-handling capacity that needs to be handled from your application tier, you can add more servers at runtime in the cache cluster.
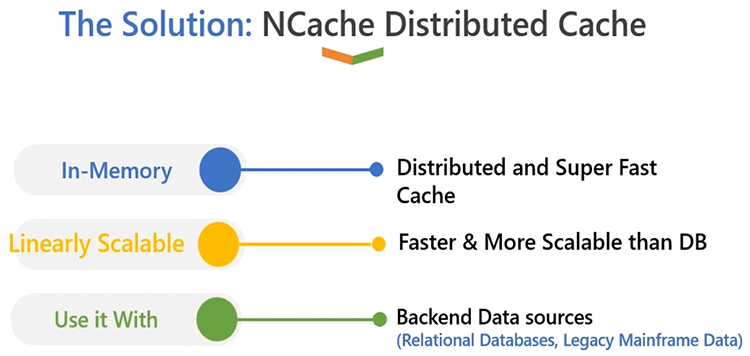
The nice thing about NCache is that you use it in addition to a relational database; or a back-end database, it's not a replacement of your conventional data sources. It's something which will complement, you know, the existing data sources in such a way that it's able to increase performance for your applications. It's able to increase the request-handling capacity for your applications. And, as you grow on the application end, you can always grow the number of servers in the cache cluster, because these are servers in a cluster, so they work as a team. They're able to divide the request load among themselves in such a way that they give you linear scalability as a result. So, NCache is a linearly scalable model, and it's very easy to use. Let's talk how the deployment architecture works. So, in a typically large production environment, this is how NCache would look like:
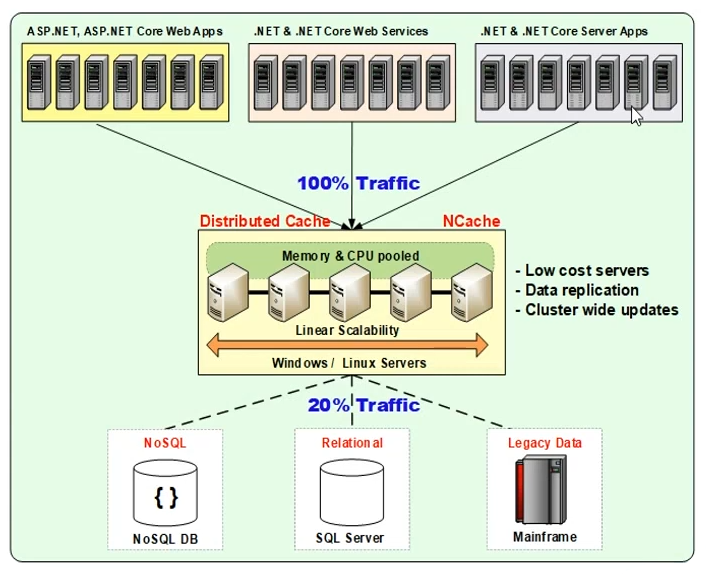
You would have a bunch of servers. These could be windows or Linux service, designed in such a way that NCache sits in between your application and the database. For example, you can start off with two or three NCache servers, and then you can grow up to four or five NCache servers, and different kinds of applications—for example, your ASP.NET or ASP.NET Core web apps, your .NET or .NET Core services, or .NET/.NET Core server apps. Or even it could be Java or Node.js. So, those applications can also take advantage of the distributed caching.
NCache itself is written in .NET/.NET Core. It runs on Windows as well as on Linux boxes. Similarly, your applications could be on any platform and it would work without issues. Typically, we recommend that you have NCache on dedicated setup servers, which are hosting just NCache, so that you have dedicated nature of resources for NCache. And, then your application servers are on a separate tier. So that you have dedicated nature of resources for your applications as well. But there's another deployment option as well, where for smaller configurations you can have NCache sitting on the same boxes, where your applications are also running. So, that's always a possibility with NCache. But, as discussed, the recommended option is that you have a separate cache tier, as shown in the diagram. And, then NCache sits in between your application and the database. The idea here is that your cache whatever data that you most frequently use inside your applications. It could be a reference data or a transactional data. By "reference", I mean data which is more read-intensive, and by "transactional", I mean data which is read as well as write intensive. And, once you know what data to cache, you can call that data to be your "working set". For the first time, you can retrieve that data from the database, and, then you can also add it inside NCache and, subsequent calls can be handled through NCache only, you save expensive trips to the database. This is what we typically term as "cache-aside" pattern, where any changes that you make are also propagated to cache and then to database. And, any database doesn't exist in the cache, you always fetch it from the database and keep it in inside NCache but you always check cache first. So, if you find data from within the cache, you don't have to go to the database and you return from that point.
Read-Through / Write-Through
The alternative approach of this is to use "read-through" or "write-through" which is represented here by dotted lines. NCache has a feature which can automate this, where it gives you "cache-through" option and, it is termed as "read-through" for reads and "write-through" for writes. That'll work in such a way that you always use cache as your main source, and you implement a read-through a write-through handler on the cache and, that will take charge of updating the backend data sources. So, whatever read operations you perform, if data doesn't exist, it will seamlessly go to your database based on your provider, retrieve it for your application, and also return to the app and, also store it inside NCache. For updates, it will update the cache as well as the database in a sync or async approach, depending upon what model you have called from the application.
So, I'll share more details about read-through, write-through, and caching patterns, but just to give you a high-level deployment picture, this is how you would see NCache deployed in a server form, where multiple applications or application forms, they can connect to NCache and, then they can take advantage of a distributed caching, where in memory access improves applications performance. And, having multiple servers in the cache tier is able to give you linear scalability. I hope that was clear; please let me know if there are any questions. Well, luckily, at this time, looks like there are none, so please feel free to continue. Very good.
NCache Scalability Numbers
So next, I'll talk about NCache's scalability numbers. We just mentioned that NCache is able to resolve the scalability problem for your application. So, NCache itself is linearly scalable. So, with application tier being scalable, you know, having a database bottleneck resolved through a linearly scalable model, here are some numbers that you can take for a reference. These were our benchmark tests that we conducted in our QA environment, we used servers that were high on CPU and RAM so that we could really stretch them, and use them in a high load situation. We started off with one server and we kept on increasing application load with two servers. As soon as, a set of servers got maxed out on CPU and RAM capacity that, was the point where we added another server.
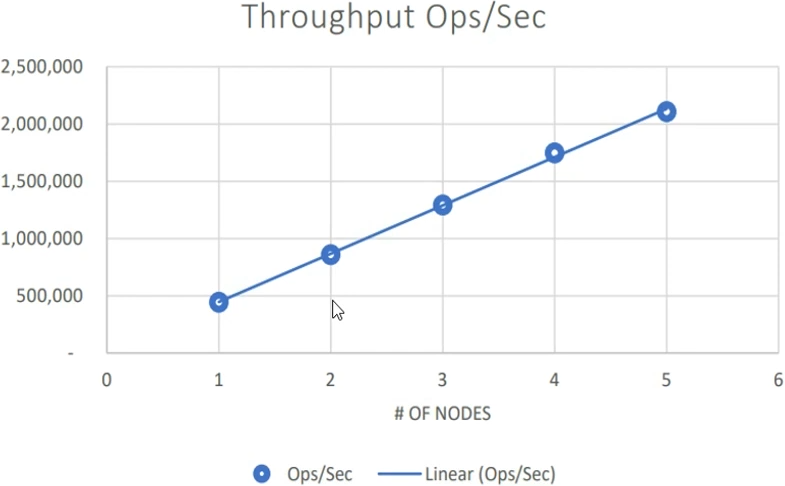
That's the thumb rule; where you can keep using existing cache servers start off with two NCache servers, and when you see that those two servers are being maxed out on hardware capacity, if your CPU is being maxed out or your RAM is being maxed out—that's the point where you make a choice that I now need to scale out and I need to add a third server in the cache cluster. This is exactly what we've done with an average of 1-kilobyte object size, we kept on increasing application load and kept on increasing number of servers. Until the given set of servers were maxed out. And, this was not a touch-and-go data; it was a real-life application data but simulated in our QA lab. So, with two servers, with three, four, five, up to five servers we were able to handle 2 million requests per second with average of 1-kilobyte object size.
So, it was a combination of reads and writes consistently applied on the cache. So overall, a 2 million requests per second throughput was achieved. And, at the same time, without compromising on the performance. So, throughput is not just having a lot of requests per second; but individual requests latency should also be maintained, and it should be super-fast. A video demonstration of this, as well as, a white paper is published on our website (See here). And, that's something that you can review as well.
Common Uses of Distributed Cache
Okay, let's talk about some of the common use cases of NCache.
-
App Data Caching
The number one use case is caching application data, we call it App Data Caching. Now this is the data which is coming from a backend database. We've already established that database is slow in general because it's disk-based, in comparison RAM is a faster source. The other issue is database tends to choke down under high traffic. If you have a lot of transactional load and there's a single server, it is expected that it is not going to give you the needed performance you need on the application end. So, it makes a lot of sense to cache application data inside your applications by using NCache. It's very simple; you use NCache APIs and you simply call cache. You connect to cache by calling cache initialization APIs. Once, you're connected to the cache, then you can call 'cache.Add, cache.Update, cache.Remove' or 'cache.Get' to retrieve data from the cache. So, I will show you some examples towards the end. But, the idea here is that whatever data, that you think that you're going to read more than once, be it's reference data or transactional data. For reference data, NCache is going to add a lot of value because it doesn't have to go back to the database to retrieve any changes.

Common Uses of Distributed Cache Right so, data in the cache is going to be usable for a longer period of time. And, while you're using data from NCache, you don't have to go to the backend database. That improves your application's performance. And, it gives you scalability because NCache is scalable in comparison.
So, it's very intuitive that you cache all of your reference data but we also recommend that you should cache some of or even most of your transactional data as well. In our experience any data that you read more than once, even if it is something you'll read two or three times, we recommend caching it. Because even if it is being changed in the database, and after that change, if you read more than once—two or three times — it makes a lot of sense to cache that data, so that, you don't have to have to go to the backend database. And, we have features built into NCache which can give you a 100% synchronization with database as well. That's something that that you can also, you know, always consider.
Ron, I had a quick question that came in, primarily being:
Do I always have to go to my clustered cache over the network? I'm scared that network issues might lead to my applications not working. Is there some way to maintain some of my data locally?Okay, so typically, the default deployment is that we recommend that you have NCache on separate boxes, and then your application on separate boxes, right? So that, when NCache is based on the TCP Protocol, so it's it is a network call. There is a feature called "Client-Cache", which is a local cache which sits on the application boxes. And, in some cases if you really need more performers and you don't really want to have any kind of latency caused by network, it can also be made "in-proc" which means that it will sit inside your application process. So, when that happens, the subset of the data is automatically brought inside client cache. So, that will save any process-to-process communication. And then also will save any network communication or any network overheads. So, we do have a feature; that's something that I'll cover once we will go to our topologies. So, I'll share some more details, but just to give you a quick overview, this is how client cache works. It's a cache which sits on the same box where your applications are. And, idea here is that it doesn't require frequent network trips if you have client cache enabled. And, this works without any code changes. So, I hope that answers the question. Please let me know if there are more questions. Yep, sounds good. Ron, take it away. Very good.
-
ASP.NET & ASP.NET Core Caching
The next use case of NCache is in a web application. If there are, you know, some requirements of caching user data, right? And, typically it's ASP.NET or ASP.NET Core session state. Now this data doesn't belong in the database, because it's a transient data. It's a data that a user will construct and it stays in the application scope while that user is active. In some cases, you may keep it in the database for historical point of view, but in most of the cases, the data belongs to a user.
So, Microsoft ASP.NET or ASP.NET Core session. There are few options you can use state server you can use in-proc you can use a database server all of these have options have Issues. For example, in-proc is a single point of failure; you have to use sticky session load balancing. ASP.NET State Server is again a single point of failure, and you know, it's not Scalable. Database is an option, is again not a single point of failure because you can back it up, but in some cases, it could be a single point of failure, but it's slow and not scalable. So, What should we do here? Again, consider using NCache for ASP.NET and ASP.NET Core session state caching. It works in such a way that you plug in our provider. It's a no-code-change option, but as soon as you plug in NCache inside your applications, NCache becomes your main session storage. And, idea here is that it's going to be Super-fast because it's RAM based. It's very scalable because there are multiple servers. And, within NCache, once we will progress into the presentation and I'll cover topologies, you would understand that NCache has backups, with the help of replications. And, session data is a user data, right? So it's a data that you wouldn't want to lose in any situation because once you lose that data, that's an impact on the user, that's an impact on the business. So, with replication, data is backed up as well.

Common Uses of Distributed Cache So, if I have to list down the benefits that you get, and you know, first of all, you you're going to improve your application's performance because of in-memory access. You have multiple servers supporting your applications for session caching, so it's very scalable. On top of it, it has high availability and data reliability features built into it. So, there is no session data loss or downtime to the application in case any NCache server goes down. And you don't have to use sticky session load balancing anymore because NCache is a shared entity. Request can go to any of the web server; it will always be able to find data from NCache based on our protocol. So, all of this without any code changes as well.
Another use case here you can also bundle your view state if you're using ASP.NET web forms. That's where it's also going to cache view state. View state becomes heavy; it eats up a lot of bandwidth. It becomes part of your request and response packets, and it's always sent back to the browser. And it's never really used there, but it is something that that is stored on the browser, on the client end. And when you post back, that's where the view state is brought back on the server side. So, with NCache, we allow you to cache view state on the server side, so your pay load doesn't have a heavy view state attached to it anymore. That improves performance. Although, you know, view state is something that that's always stored on this on the browser end. But if you keep it on the server side, where it is needed, it's going to you know improve overall application behavior. It will not eat up your bandwidth anymore because the actual request and response packet doesn't have a heavy view state attached to it anymore. And, it's also we're going to be very secure because view state is stored on the server side, and then you can set up some encryption and some security features on top of it. And this is also a no-code-change option. But it only applies to legacy web forms. So, I would recommend that you can, if you have ASP.NET web forms application, you should consider a caching view state as well.
And then we have ASP.NET and ASP.NET core response caching. So, static pages or page portions within a page which are static, you should consider caching those page outputs. And in ASP.NET core, we have a response caching option that you can choose, and this is also a no code change option. In addition to this, we also have ASP.NET and ASP.NET Core SignalR Backplane. Because in a web form, if you're using SignalR, you need a backplane as a must. And typical backplanes, such as a file system or a database, that can have all those scalability and performance challenges that we just discussed. With NCache, is going to be super-fast and very scalable and reliable, because we're using a very reliable messaging system behind the scenes. So, these are some of the use cases that you can leverage on ASP.NET or ASP.NET Core applications.
-
Pub/Sub Messaging
Sounds good. I think we can move on. Sure. All right, so next I'm going to cover Pub-Sub messaging. As you can see, NCache is already shared between applications, right. So it's an entity which you can use for your data requirements. You can add data to it; you can retrieve data from it. You are able to get performance and scalability benefits from NCache. You can extend this use case by using NCache as a messaging platform as well. So, NCache messaging is very powerful within NCache. It's an async, event-driven mechanism where multiple applications can drive messaging requirements or app coordination requirements among themselves. If you need multiple applications to talk to one another, building communication is a challenge. So, you would have to rely on something which is a centralized entity, NCache is that entity. And with its messaging support, it is able to give you that option where one application can add data or messages to NCache, and those messages can be propagated to all the subscribers on the other end: the other applications which need, you know, those messages.

Common Uses of Distributed Cache Similarly, this could be data-driven messages as well. For example, any data gets added, updated, or deleted, you get notified about it. These could be some custom application messages or data-driven messages so it covers both areas where any data being populated inside NCache and you want other applications to be aware of it, you can drive messaging requirements through that. Or, it could be custom messaging or application-driven messaging where one application needs to talk to another application. It's again based on in-memory scalable model. It has reliable, you know, replication options available as well. It's based on conventional Pub-Sub messaging platform where we have a concept of topic, and we have a concept of message broker, where multiple applications are connected to it. So, you can have publisher and subscriber applications defined. Publisher applications publish you know, messages to NCache which are then transmitted to all these subscribers. And then, subscribers can also send their own messages. NCache acts as a communication platform between these different applications.
-
Full-Text Search (Distributed Lucene)
Finally, we have another use case, which is full-text search. So, if you have an application and you need to drive any full text search requirements from NCache, you can consider using our Lucine.NET-based full-text search features.
You know typically, Lucene API is a standalone. Right, within guys, you can extend it on multiple servers. NCache gives you an ability to load indexes inside memory as Well. So, NCache would use disk-based indexes, but it allows, you to actually, you know, extend the storage and request-handling capacity by having multiple servers to it. So, although it's disk-based, but it's still going to be better than a single source on the database. Because, in cases where you have a lot of transactional load, each server will be responsible for its own set of indexes requests. So, it's going to be very scalable; it's going to be very reliable as well. Because this is assisted store, when it comes to the scene indexes, persistence itself is a feature with an NCache. Any data that you store inside NCache can be persisted on the disk as well, or based on some database providers, it can be persisted on some databases as well. But Lucene is the only feature where NCache uses disk in comparison to RAM, because the nature of use case is such that it requires data to be persistent.

Common Uses of Distributed Cache
Before I move on Zack; I think there's a question posted. Yeah. So, the question came in from basically saying and DB by default. So, in the midst of your --I wanted to wait until you finished it, but the question basically is asking. And in case, would you be able to elaborate on the question, sir?
Hi Ron, is NCache also suitable for data publishing purposes, with the requirement, where the requirement is to save data in-memory cache with options to sync data in the database as the background process? And can NCache take care of that sync mechanism between memory cache and databases by default?
Yes that's a very good question. For advanced cases, this is something that that could always be a requirement. It works in two ways. One is that your application is now using data which is coming from NCache, but data exists in the database. So, these are two different sources that need to be in sync for reading as well as for writing purpose. Now, if the application that is connected to NCache and database is the only application which is responsible for changing data inside NCache and database, you now, we recommend that you use read-through and write-through. And yes, this can be done in async or sync manner, depending upon your requirements. So, what will really happen is, whenever you try to fetch some data from NCache and it doesn't exist in the cache and you want it to be cached, you would automatically call read-through, and that will read from the backend database based on your code. And similarly, if data is coming from a database and, again, that data needs to be updated in the database, as soon as you update data in the cache, in that case, you will make use of write-through. Now write through can also be write-behind which means data has to be updated inside NCache and in the database by using your write-through handler. And if you want async invocation of that, in that case you can use write-behind, so it can be done in the background. But again, NCache and your application is responsible for that, where NCache is calling your code and your application is invoking that.
Another situation could be that there are other applications which may be changing data in the database directly and, your application is not aware of it. So, in that case, what will really happen is you need to use our database synchronization features. You should come up with custom dependency; you know, SQL Server has chain notification. We has database dependencies. So, there are a lot of synchronization features where any change in the database is captured by NCache automatically. And, you can again use read-through, and you can reload data inside NCache as well. So, to sum it up, NCache can, you know, handle both situations: where either it's your application which is the only entity changing anything inside NCache and database, or in a situation where database can be changed outside the scope of the application which is using the caching.
So, both scenarios are covered, and NCache will give you a 100 sync you know option for these cases. If you're talking about memory cache, typically memory cache is also featured by ASP.NET, right! But if you're referring NCache as a memory cache, so I've already answered the question. So, please let me know if there are more questions, and we can take it from there.
I hope it was straightforward. So, these were some of the use cases. Again, within these use cases, we have a lot of features; any kinds of applications, any specific requirement within an application, can be fully handled using our object caching and session caching features.
Just a quick question, Ron.
Is there a way for me to access my data in the cache like I do in my MySQL database? I want to be able to run SQL queries on my cache data. Can I do that?
Sure. NCache first of all supports a SQL search and LINQ queries. So, if you have an ability to write an application which can simply connect to NCache, and then run criteria-based searches, so that's the easy option that you can utilize, where you write a criteria-based search. For example, you can select all products where product.price is greater than 10 and less than 100. Or you can find all products based on a category; you can find customers based on a region. So, you can come up with SQL-based searches or LINQ-based searches, and NCache would give you the data from the cache. So that's one option.
The other option is that we have a LINQ Pad integration. So, if you just want to visualize data without, you know, having to go through an application development, LINQ Pad is an easy way out where you can run LINQ queries, and then you can visualize data by running LINQ queries.
And then, in our upcoming release, the third option is that we're giving a data analyzer tool. So we will give you an automated way, a monitoring tool, which will give you the ability to monitor your data which exists in the cache. And it will give you those criteria-based search options from a GUI, so that's something which is in the pipeline; requirements have been completed, dev work has been completed. I think it's going to be part of our next release.
Definitely looking forward to all of that. Perfect. Yeah. Very good. I think we're good for now, Ron. I'll save a couple of these questions for the end as well because we got some interesting ones, but yeah, let's keep Going. Sure.
Self Healing Dynamic Cluster
So, next I'm going to cover the dynamic cache cluster, you know, all the details about it. NCache is based on TCP IP based cache clustering protocol. It's our own implemented cache clustering. We're not using any third party or Windows clustering for this matter. It's 100% proprietary protocol. It's written in .NET and .NET Core, so, you know it's very convenient in terms of --- the TCP sockets are also .NET and .NET Core based. It's 100% peer-to-peer architecture, so, there's no single point of failure. You can add or remove servers at runtime. You don't have to stop the cache or the client applications which are connected to it. So, dynamically you can make changes to a running cache cluster and, NCache will not give you any issues for that. As you add a server, clients are notified at runtime, so they automatically know that this server is no more, you know, is part of the cache cluster now, so they start using the additional server, cluster automatically adjusts. Similarly, once you remove a server, other servers detect that this server is gone for good. They notify clients and, clients stop using the lost server. There's a connection failover support, which is also built on the client end, so any server going down will ensure that, you know, the cluster will ensure that the clients are aware of it and, they failover the connection and, start using the surviving servers.
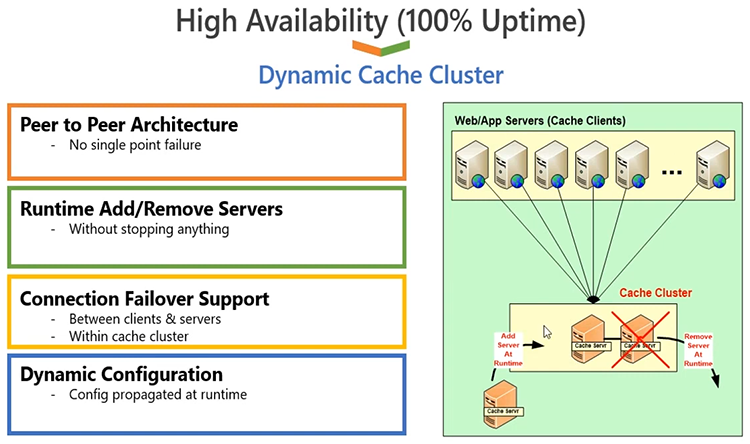
So, in any case, any changes in the cluster are propagated to the clients. Clients are intelligent, they are always aware of the state of the cache cluster. So, this ensures that there is no downtime or data loss, because we have replication support built into it as well. So, NCache is highly available and, also, it's very reliable with the help of replication. It ensures 100% uptime on on the application end, without any, you know, application Interruption, you can continue using NCache.
Caching Topologies
Next, I'll talk about the caching topologies. That's the main portion I wanted to cover. We have four options to choose from. First Option is again for smaller configurations. These dictate how you would configure a cache.
Mirrored Cache
So, we have an option of configuring a cache using a mirrored cache topology, and the way it works is that you only have two servers at max. One of those servers would act as an active server, where all the clients are going to be connected. The other server would act as a passive server, which sits as a backup, and backup is done by NCache. This topology, once you configure it, it automatically follows the architecture. You don't have to, basically you know, define that this becomes active or this becomes passive, it's done by NCache automatically. But, once you do that, what will really happen is, all the client applications would connect to active server and, that's where they're going to read and write data from. Whatever data that we have on the active server is going to be backed up on the passive server through an async mirroring option. So, client updates the active, returns, so cost of replication is not incurred on the client application end. Client application will be super fast. Behind the scenes, NCache should update the backup. And, the backup is there for an important reason, if server one ever goes down, the backup server automatically gets updated as an active server and, clients failover their connections and start using the newly active, previously backup server. And, now the first server comes back in, it will again join as a backup node, not as an active node, because we already have an active in the cache cluster. And all of this is done seamlessly to your applications. You don't have to make any interventions when a server is added or server is lost.
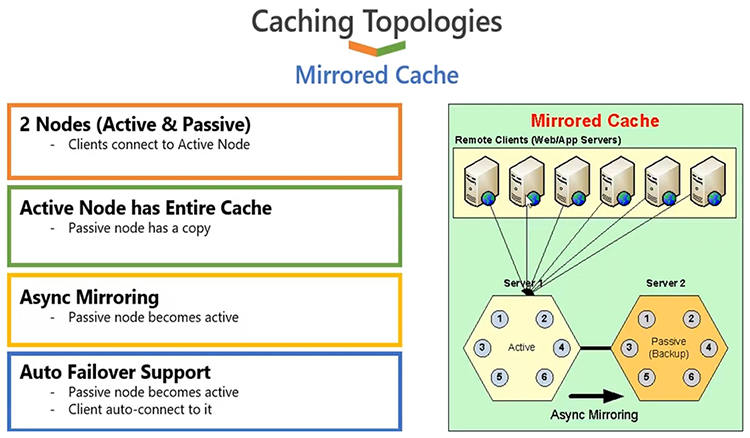
This topology is very good for reads as well as for writes. So, good for reference, good for transactional data, but it has a capacity issue because you only have two servers at max and, out of those two servers, only one server is active at any given point in time. So, for smaller configurations, with reliable data, you know caching, this could be one of the options.
Replicated Cache
Moving on, second option is a replicated cache. This is again for smaller configurations. This works in such a way that all the servers are active, as you can see server 1 and server 2, both are active. Clients are divided among different servers, so, if you have six clients as shown in the diagram some of them would connect to server one and, some would connect to server 2. Right, these three are connected to server one and these are connected to server 2.
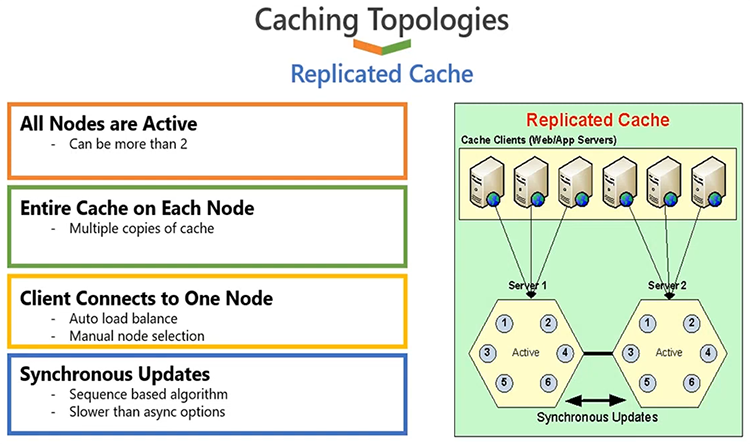
This is done automatically; the connection balancing is something which is built inside NCache. All servers are active but each server has a copy of cache. So, whatever data that you have on server 1, a copy is on server 2, and this copy is maintained with the help of sync updates. So, whatever updates that you perform on one server, those updates have to be applied on other servers in a sync call and, by that what we mean is, client is going to wait until that whole operation is completed. If operation fails on any server the whole operation is rolled back. And, that's how we achieve a 100% synchronized copy on all servers. Now this is very good in terms of reliability, but, and also if you have a read intensive use case, because you have more copies of data or more copies from different servers, so, as you have more servers, your reading capacity will increase because you have more servers to serve requests. But, as you've just noticed that we have a sync update, so, any write operation has to be applied on all servers. So, it's good for smaller configurations for write capacity. If you have three or four servers, you have to apply same operation three or four times, so that can negatively impact rise performance. So, this topology is more recommended for reference data scenarios, for smaller configurations. It's scalable for reads, not very scalable for writes, but it's very reliable. It brings in high availability and data reliability, because, if you lose any server, for example, server 1 is lost, there's no data loss or downtime because these applications will failover and start choosing the surviving server and, they have a copy of cache already available.
Partitioned Cache and Partition-Replica Cache
Next option is that you can choose, you know, you can configure a cache using partitioned cache. Now partitioned and, partition replica is most, you know, popular topologies. Partitioned cache allows you to distribute data among your available server nodes. For example, if you have two servers and, you have some data, half of the data would go on server 1, half of the data would go on server 2. Data distribution is also part of NCache. It's not something that your applications do, it is done automatically by applications at runtime. There's an intelligent distribution map and hash algorithm, and that dictates which data is going to go to which server.
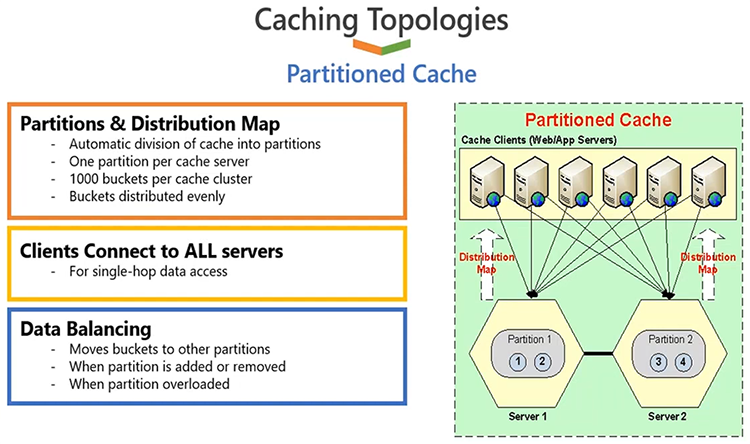
So, based on that, your applications are the ones which are going to distribute data evenly among all servers in the cache cluster. Now data is evenly distributed, so your request load will also be evenly distributed. So, this will give you more reads and writes capacity based on the number of servers. If you have two servers, you have two servers working in a team. And, if you grow from two to three, you have more servers handling your read and write requests. So, you get more scalability for reads and writes. So, in a linearly scalable manner, you get more scalability if you add more servers. By adding more servers, you're also pooling the memory resources as well, because data is distributed, so you're pooling the storage of all servers together. So, if you have two servers, you have a capacity of two servers. If you add a third or fourth server, you increase your capacity by, you know, those many servers. So, overall capacity is pooled, so you get a linear growth as you add more servers in the cache cluster.
Very good for reads, very good for writes, very scalable for reference as well as for transactional data. Only downside of this topology is that it doesn't have any backup. If you lose a server, you lose that partition. So, when that happens, you have to have a way to construct that data from a backend database. So, if your main goal is to achieve high performance, if a performance centric application, and you can afford to go back to a database, which commonly is the case, you're not relying on NCache for high availability and data reliability, this is going to give you the best performance in comparison to all other topologies.
But if you need high availability, and you know, data reliability requirements to also be served from NCache, I have a better topology, which is called Partition of Replica cache. Now, overall architecture is exactly like partitioned with an enhancement of replicas, where each server has partition of data, but every server maintains two partitions; an active data partition, where clients are connected and, a backup partition of another server. Server 1 is active, its backup is on 2, server 2 is active its backup is on 1. And you have ability to choose sync or async backup options. If you choose partition of replica with async, client will update the active partition and will return, that operations completed on the client and then, NCache will update the backup partition behind the scenes. If you choose sync, client application will update the active and backup as a transactional operation. Either way, you know, sync is obviously more reliable, async is faster. But in either way, NCache is able to handle, you know, the data reliability in such a way that if any server goes down, the backup topology becomes activated and you don't see any data loss or application downtime. Right.
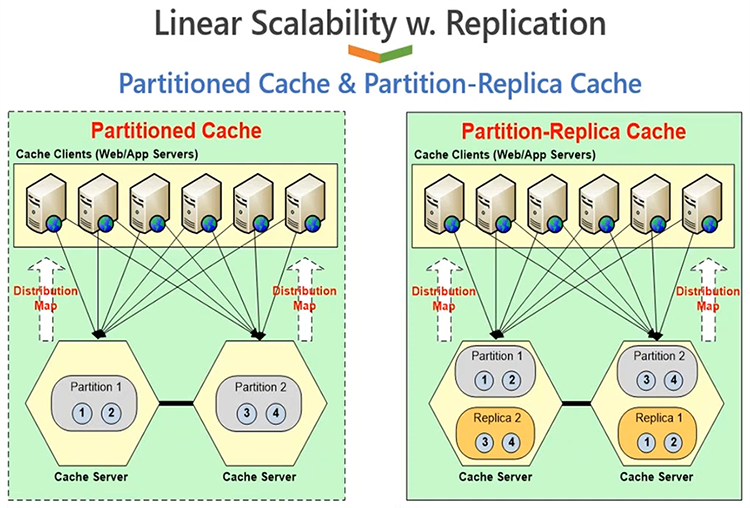
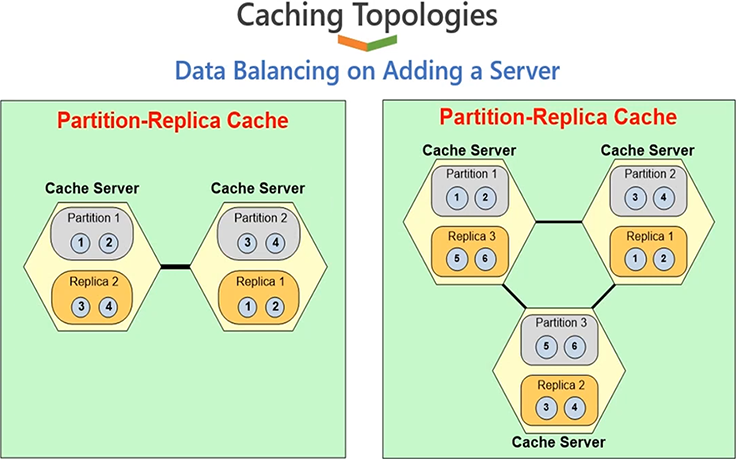
So, let me quickly show you this topology with 3 servers. So, we get all the benefits of high performance for reads, high performance for writes, you know, linear scalability for reads as well as for writes. In addition to that, we get scalability, you know, high availability and data reliability benefits. If any server goes down there is going to be no data loss or application downtime.
Demo
I hope it's clear. Let me take you to our demo environment now and, let me quickly show you how you can construct these caching topologies and, then I'll also show you how to quickly test a cache cluster. But, in the meantime, please let me know if there are any questions. Well just a quick reminder that everything that we're showing, we can also do with you with hand-holding sessions and technical support sessions in your environments, for your specific use cases. So, everything that we discuss here even post webinar we'd be happy as a team to be able to get together with you on that as well, to be able to demonstrate how it would work for you.
As far as questions go, I do have one that came in just right at the end. One of them is one of your favorites.
There's been a lot of discussion regarding the use of Hazelcast for application caching. What does NCache provide that Hazelcast does not?
Okay. First of all, it's more of a debate. NCache is actually written in .NET and .NET Core, so preferred platform for NCache is Windows. The nice thing about NCache is that it runs on .NET, as well as, you know, on Windows, as well as, on Linux. So, platform and compatibility support that NCache offers, there is no other product that is able to achieve that. So, that's the first bit, where it is more preferred choice if you're, you know, considered about the platform that that you're planning to use. The other difference is and, I would encourage everybody to go look up on, you know, our comparison pages, you would find very good material over there as well. But, to quickly summarize this, NCache object caching support has a lot of features, where, which other products completely lack. For example, the SQL searching, we have elaborate set of features available inside NCache. We have cache loader and, cache refresher. Those are features which are completely unique to NCache. Our read-through and write-through handler with an ability to run .NET and .NET Core code on the Server side, that's something which is an absolutely unique feature to NCache, and list goes on, right. So, some of the features that, you know, you can customize on the server side. Those are only available in NCache and then, from an application standpoint, there are a lot of features which are missing in other products. So, I would encourage everybody to check our comparisons page. There are some comparisons, feature by feature comparisons published, and that will give you more detailed information on that.
This is definitely our favorite line of questioning, whether it's a webinar or even a tech solution, it could be Hazlecast it could be Scala, it could be Redis, but thank you very much, Ron. Yeah, I think we're good to go. Please continue. Sure.
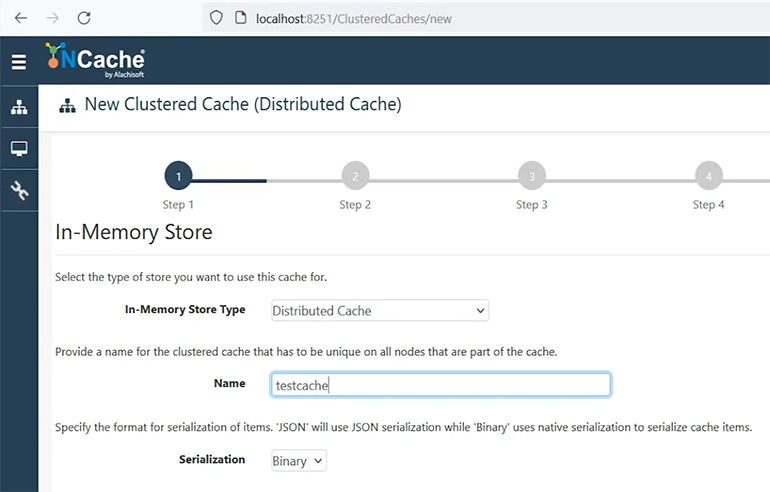
Create new Clustered Cache
So, let me give a quick demo of the product by creating a new clustered cache. Let's name it test cache. Right, let me move this bit here, just bear with me. Okay.
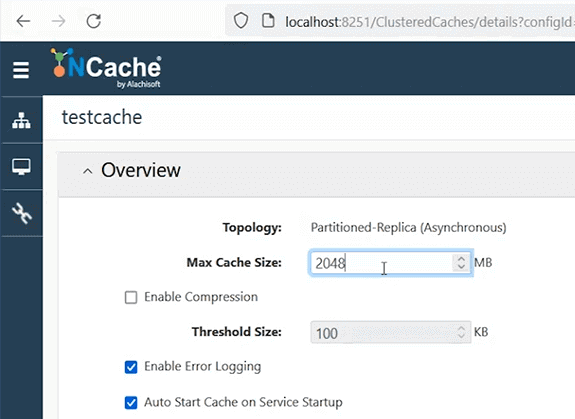
So, and we just explained four caching topologies. I'm gonna go with Partition of Replica cache, because that's the most recommended one with async replication option. I'll keep all of these defaults.
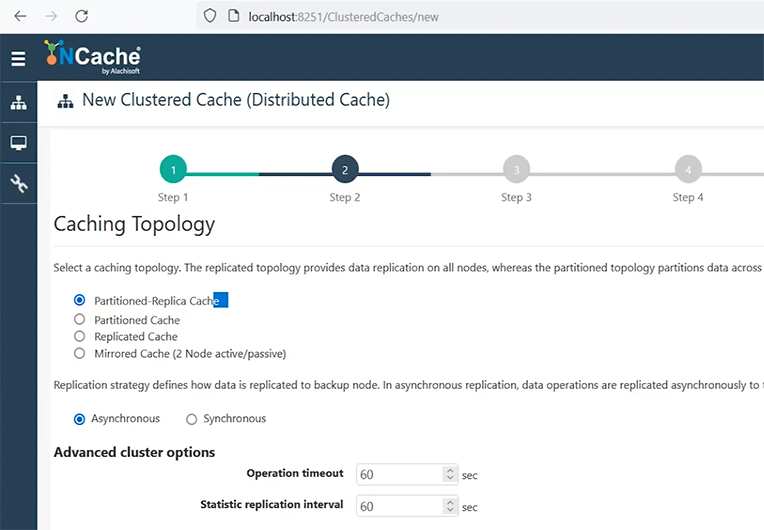
Move on, and I'll show you how easy it is to configure a cache using GUI tools. This is our web manager, but you can achieve everything using our PowerShell cmdlets as well, and you can automate this deployment as well, if that's a requirement. I'll add server one, where NCache is installed. I'll then add server 2. So, my 2 boxes with NCache with size of 2 gigs is going to be, you know, set up. So, my idea here is that I'm going to create a 2-node cache cluster using 2 gigs of cache size on each. So, total of four gigs with 2 servers where NCache is already installed. And then, I'll use my box to connect to this cache cluster.
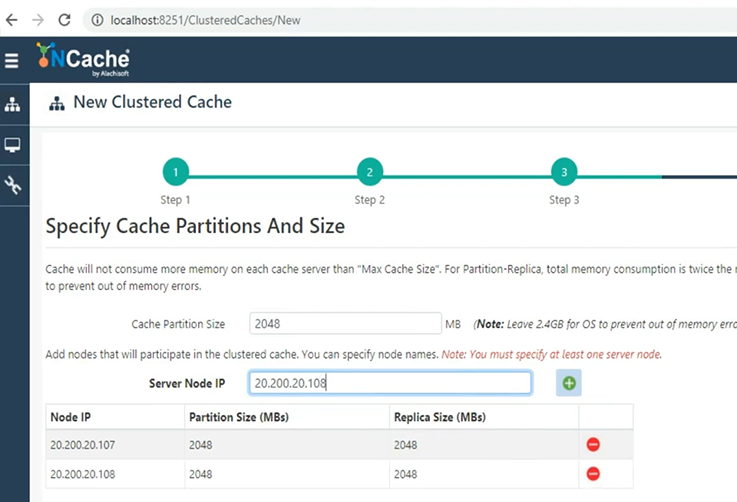
TCP parameters. this is the port that you need to set up, once you do that. Keep it default or specify any port where firewall is not, you know, impacting that port.
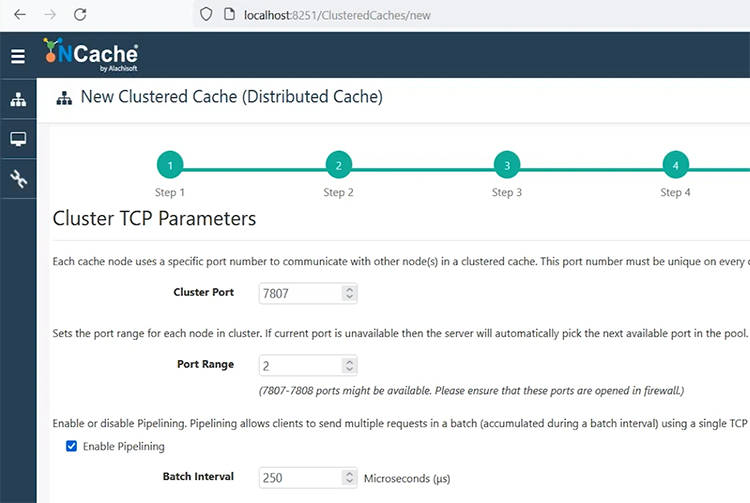
If you need to set up encryption and compression, this is the screen. I'll just keep it as is. Choose next. Evictions, if your cache becomes full, it's something that you can choose. One option is that your cache is going to simply not entertain any write operations. It will give you an error, ‘cache is full’. Other option is, that you set up eviction, and based on these algorithms, it will remove some of the items from the cache at runtime. So, based on priority, usage, least recently or frequently used items can be removed, and five percent of the items are going to be removed from the cache. I'll start this cache on finish and, auto start, so that every time my server reboots or NCache server restarts it is able to restart the caches which are stopped.
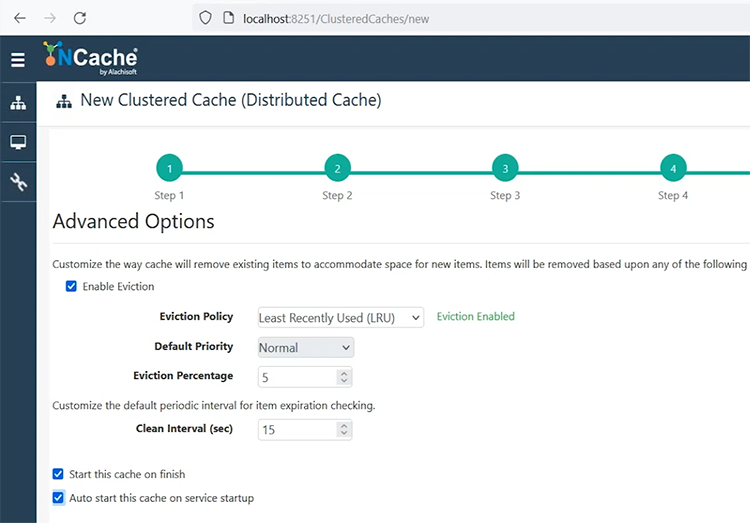
I'll choose finish, and that's it. That's how easy it is to set up a cache cluster. And in a bit, it will show me another view, where this cache will be started, and then I'll show you some monitoring and management details from there. We have some more detailed videos available on cache configurations, so if there is, there are any questions, let me know now, or we can, you know, rely on those videos as well.
I can select and choose monitor cluster, and that will open another dashboard, which will allow me to fully monitor my cache. It shows me a fully connected cache cluster, request throughput counters, latency counters, and then additions, fetches, update counters, are also there. Similarly, it shows me CPU and memory usage and, cache full situations.
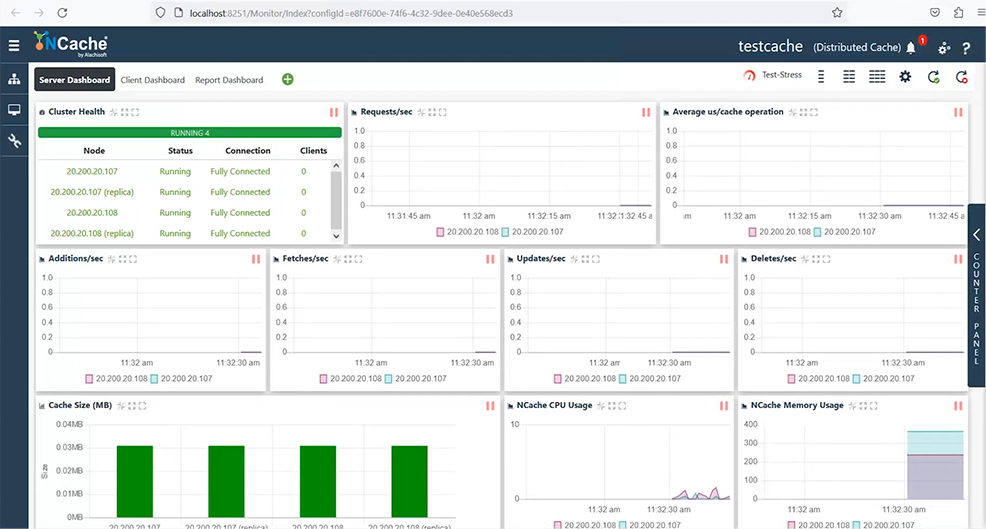
I also have dashboards for client, as well as, a report view, where we see server side and client-side dashboards. At the moment there is no application which is connected to it, but there is a way I can simulate some load using this test-stress button. So, I can start a dummy load, or some activity on my cache cluster by calling this test-stress. As soon as I will do that, you will see one client is connected and, this topology requires that my data is going to be distributed, right. So, some data would go on server 1 and, some on 2. So, this client is evenly using both servers. As you can see requests are coming to both servers, cache size is growing on both servers.
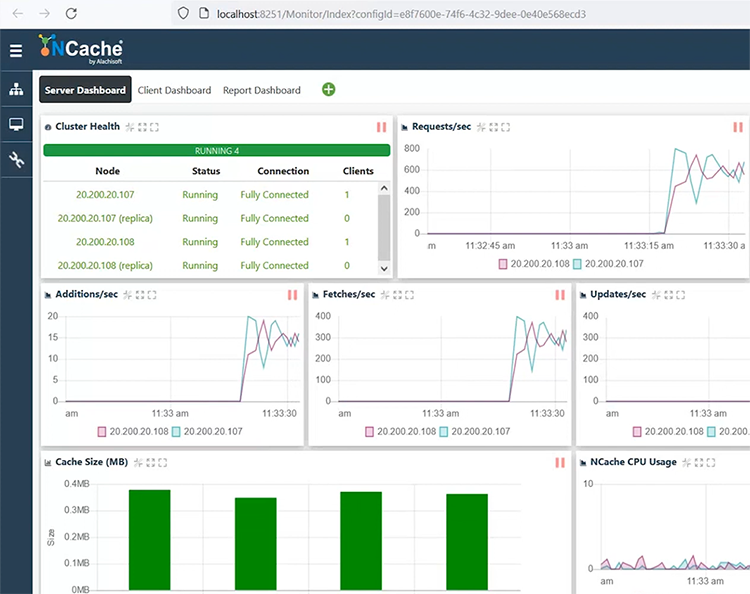
We have active and backup partitions also showing on both servers. And if I quickly show you the latency counters, it's sub millisecond latency, even microsecond latency, as far as my operations are concerned. And I can see the client dashboard showing these client-side statistics and, similarly we have a report which is showing the server-side statistics.
Ron I got a question, actually we've got a couple questions that came in, so, one of them is:
What is your recommendation for eviction? And, if eviction at least, hold on the next one is, if eviction is turned off, can we increase the cache size or decrease it?
Sure. So, you know, eviction is something that needs to be set up based on your use case, right. If data is something that you can afford to be evicted, right. Eviction itself is going to remove some data if your cache becomes full. The ideal situation is that you never have to do that, and your cache is well within the capacity, right. So, you give enough size or enough memory to your cache so it never becomes full. But, in cases where it does, you know, come to a point where it becomes full. In that case, if your data is something that you can always reconstruct from a backend database, evictions are recommended to be turned on. For example, for ASP.NET sessions, we don't recommend turning evictions on, because you would be removing some users to make room for the new users, and all users have their data of importance, right. So, it's a data that you wouldn't want to lose in any given scenario. So, for those scenarios we recommend that you increase your cache size. Plan your caching size in such a way that it is big enough, and in cases where it becomes full NCache allows you to change the cache size at runtime. You can edit this, right, and based on that you can increase and then save these settings on a running cache. So, it is hot applicable, and it will increase cache size at runtime.
Any other questions? Looks like that answered it, and I'll save a couple of them for the end, so that you can complete your demonstration. Sure. So, coming back to my demo environment, you know, you could add clients, for example, I can add my box as a client and, this is a quick overview of a sample application which I can run from my box. For example, this is available from GitHub as well, so if you search NCache on GitHub you would See some samples, and I've extracted one of the samples from there. So, what you really need to do inside your application is, include this NuGet package which is Alachisoft.NCache.SDK, and if you're interested in app data caching, this is the sample that you should consider. And, based on that, once this is added, you can include some resources inside the application.
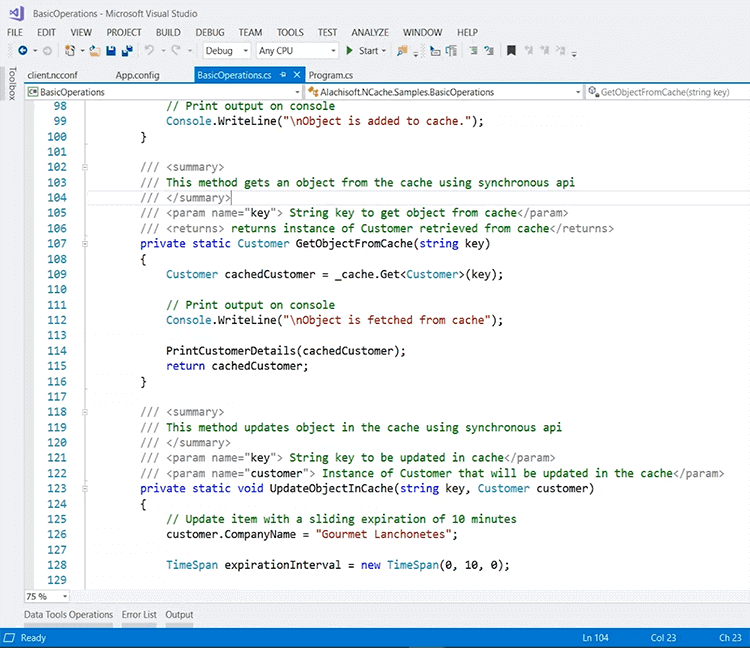
This will already include some, you know, libraries of NCache, as part of this new NuGet package. And, then you include this reference using Alachisoft.NCache.Client. Also add Runtime.Caching, right, and based on that you can define a cache handle and, within this we have a bunch of methods. For example, let me show you how to initialize cache. Let's actually go inside this. Bear with me. I'm having a hard time. Anyways, for some reason, I'm not able to actually go inside this, I think there's an issue with the box itself. But anyways, the APIs are pretty intuitive. Let me show you from our PowerPoint. This sample is actually using that, I'm not able to demonstrate because I'm not able to step into the code. It is not letting me.
So, this is a cache handle and this is the piece of code that I wanted to show, that the CacheManager.GetCache will allow you to connect to the cache. Then you can call cache.Get to actually get any data from the cache. Similarly, you can call cache.Add or cache.AddAsync to add any records in the cache and similarly insert as in upsert where it adds, as well as, updates data in the cache and similarly, you can call cache.Remove.

So, this sample is available that you can download and run against your cache. All you have to do is point to the cache from an application end. There are a bunch of configurations. You can specify the name of the cache and IP inline, or you can rely on a client.ncconf, which this NuGet Package includes in the project. So, if I quickly show you some resources, you see, a lot of files are actually added, and this file right here is a file which allows you to connect to the cache. So, it's already able to connect to my 'democache'. If I run it, it will do some activity against my cache, and will start the caching operations.
Similarly, I have another sample which is going to give, you know, some more options, for example, there was a question about searching inside NCache, right. So, I would recommend that you use this sample right here. This is for SQL searching. It's again downloaded from GitHub, and again it's using search, using, it has a sample data, and then its calling search using SQL. And, it has bunch of features right here, again on the same lines, the samples are pretty intuitive. You can insert items and then you can query using name tags, you can query, you know, query using defined indexes or projections.
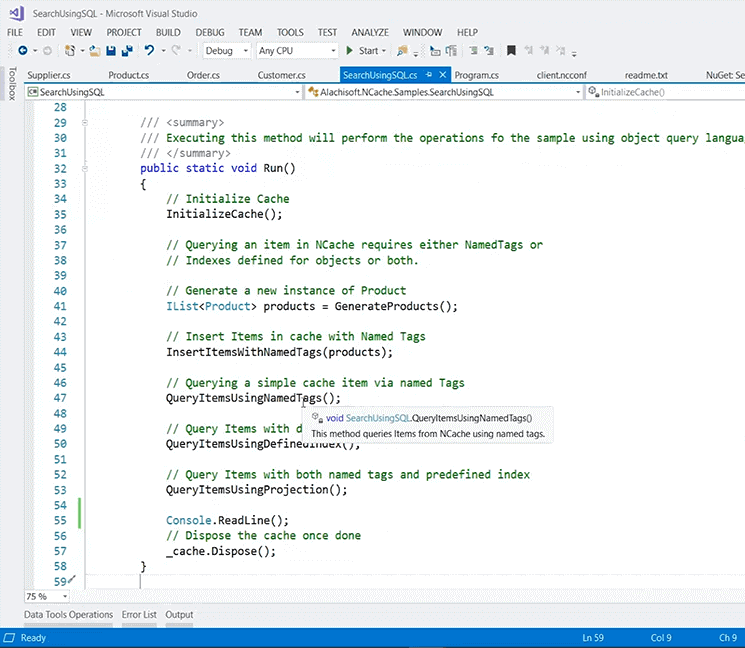
I unfortunately I cannot go inside these methods because of the environmental issues, but again these would serve as a great reference point for using NCache from any application, that needs to use caching within the application, or for they have a use case of searching within the application.
Client Cache
There was another question about Client Cache, so this topology is also, a no code change option. Any data that you cache from a database inside NCache, you can further cache it by using client cache. It's a cache on top of another cache. Works without any code changes. It's a synced cache with a clustered cache, so there's no data consistency issues. Synchronization is done by NCache. Any updates made on one client cache, are propagated to the clustered cache as a must, and then propagate it to other client caches, and in cache manages all the synchronization. For reference data scenarios, where you do not have a lot of writes, this is a very recommended option to choose from.
WAN Replication
Similarly, NCache also has a WAN replication. We have active-passive and active-active topologies. So, your entire cache data can be replicated from one data center to the other through our bridge cache. Bridge itself is backed up on active passive server, so you have a, you know, source cache and you have a target cache, one-way replication or east to west migration of data from one datacenter to the other for, DR scenarios or for east to west migration, you know, or for situations where you need data from one application and you need to use it to the target application. So, you could transfer entire cache data from one data center to the other.
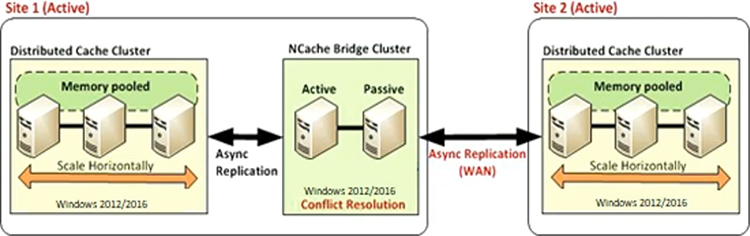
The other option is active-active. In this, we have both sites active, so site one is transferring data to site two and site two is transferring data to site One. Again it's a no code change option. It's just a configuration. Once you set up bridge, you connect two caches together and NCache takes over, and it starts replication of data between those caches.
And this is also extended to multi-active-active topology as well, so, it doesn't need to have just two sites, it could be three, four, or five sites where all sites are transferring data to one another. So, NCache’s ability to actually, you know, sync data from all sites, at once. And, by the way, this is done asynchronously so cost of replication is not again, you know, incurred on the on the application end, or on the on the user end. It's done on the application. Yyou have client applications connected here as well as here. They do not see any performance degradation because of this WAN replication. It's done behind the scenes by NCache. Let me know if there are any Questions. Let's conclude the presentation and feature set at this point. Zack, let me know if there are any questions.
Yeah, we do have a couple. And everyone, you know, I do appreciate your patience, so this is also a good time to toss in any other questions if you have been wondering throughout the presentation. So, let's start with one.
How do you confirm if your cache is running in a healthy state? Do we get any kind of notifications etc.? Like how do we know if there's an issue?
Sure. We have monitoring and management tools. So, one thing could be that you visually inspect and, you see the cluster health. You see, the CPU usage, RAM usage. If you know your baseline, how many, you know, how much request your applications are generating and, what is the typical utilization of NCache based on these counters, you can visually inspect using our monitoring and management dashboards. And then, we have alerts for any situation, for example, you start a cache, stop a cache, a node joins, leaves, cache size becomes full, or cluster goes in unhealthy state, such as, split brain, we have alerts, which we which we log into Windows event logs. And then you can also set up email alerts from NCache, and it can generate an email to you as well. So, this is something that will be a proactive monitoring, some alerting from NCache, where NCache would alert and you can take actions based on that. And, then we have historical data captured in the form of perfmon counter logs, as well as, cache logs. For those situations where you didn't know what went wrong, and you saw some issues with NCache, we can come and get involved, and we can review NCache logs, and make an assessment of the cache health in that case. So, there are a lot of you know avenues in this regard which we can explore.
Sounds good. Another question is:
What is the latest .NET version that NCache currently supports for clients?
Okay. Typically, we tend to be on the latest .NET framework version, .NET Core. .NET 6 is currently supported, that is a pre-req for NCache. You need to have .NET 6 as a mandatory thing on NCache servers. But, your applications can be on any, you know, .NET framework, I think from 3.5 onwards 4.0, 4.5, or even 4.7, 4.8. Your applications can be on either, you know, any of the .NET or .NET Core framework. It's only a limitation on the server side. And, as soon as a newer, you know, framework compatibility is tested for example, for .NET 7, we are already testing it in our QA lab. So, once we have, you know, that signed off, we will, you know, release an official support for that as well.
Wonderful. Another question is:
What would you consider is the safe amount of clustered caches between my cache servers? Can I make, say 15 clustered caches between my cache servers?
Okay. First of all, NCache does not enforce any limit on how many caches you can configure. As a matter of fact, if you look at my demo environment, I have two caches configured. So, you can create as many as you need to. But, there is a technical recommendation or a capacity related recommendation that we typically recommend in a production environment to not go beyond four to five caches. Because every cache is a separate cache cluster. It is actually going to consume all the resources for storage, for clustering, for communication, there's a cluster management overhead as well. So, as you grow number of caches, you're actually introducing that capacity issue on that environment, or within that environment. So, we recommend keeping it, you know, within four to five, if possible. In a situation where you have to have multiple caches, you can extend it up to 10. But, like I said, it’s again a recommendation. There is no actual limit which enforces this. It's a general-purpose recommendation from our end.
Okay. Let me just toss in one more since, I know we're at the end of the session and, I know folks have other things on the docker.
Can NCache provide DR replication?
Yes, it does. The WAN replication feature that I just discussed, the last topology, that covers the DR, disaster recovery. Sites can be transmitted with the data from active site so, you would have a DR site fully backed up. You just have to make switch on the application end. Since, all the data is already backed up, there’s no data loss in that situation where one data center completely goes down, or you need to bring it down for maintenance yourself.
All right. I think we pretty much nailed as many as we could. Ladies and gentlemen, please know that we are available outside of these sessions as well. We're very happy to work with you, side by side, when it comes to looking at your existing configurations, if you're already a user of NCache. If you're new to NCache, we'd be happy to get you set up with a trial and have hand-holding sessions to walk you through how this would work in your integrated applications, but most of all, please know that you can reach out anytime when it comes to any queries about NCache, or even using the product and if you need any help. We've got a lot of new stuff coming up on the way, new version releases too, so, you know, keep in tune and we'll have more of these webinars on the way soon.
A round of applause for Ron. I really appreciate, you know, you taking out the time for a session today and, I'm looking forward to our next one. Thank you, Everybody. Thank you, Zack. Of course. All right, everyone. You all Have a wonderful day, and we look forward to seeing you in our next webinar. And just a disclaimer, after this webinar is over, we will have a recording of the webinar uploaded to our website, once all is done and dusted. So, if you didn't have a chance to, you know, have any questions answered, if you'd like to revisit any of the points we've made, please feel free to come to our website again and, check out the recorded webinar.
All right, then. Salute to everyone. You have a good one. Thank you, guys. Bye, bye.