Talk at Live 360 Orlando 2016
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
Your .NET applications may experience database or storage bottlenecks due to growth in transaction load. Learn how to remove bottlenecks and scale your .NET applications using distributed caching. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
What is Scalability
So, let's start with some definitions. I'm sure most of you know this already but we'll just go over it for completeness purposes. The first definition is scalability. So, what is scalability? People often confuse scalability with performance. Performance is really fast response time by application but that could be with five users only and if you take that from five users to five thousand or 50,000 users and that performance remains good then your application is scalable. That's the nutshell of what we're trying to achieve.
In whatever application you have, if you can achieve the same performance that you had with five users or a really low transaction load, if you can achieve the same performance with high transaction load then you are scalable. If you don't have good performance with five users then you have other issues.
Linear Scalability
Linear scalability is more of an infrastructure definition which is that if your application is architected in such a way that adding more servers to the deployment, whether that's adding more application servers or database servers or whatever, if that can increase the transaction capacity in a linear fashion then you have a linearly scalable application architecture.
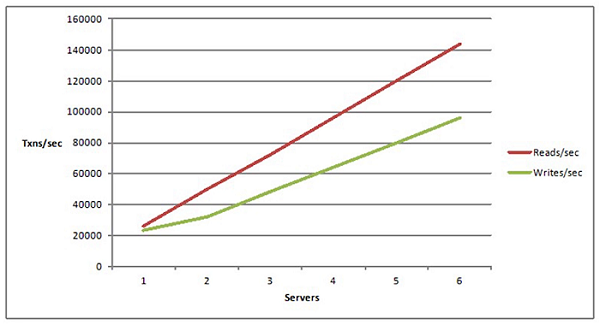
However, if you are not able to do that, if adding more servers is not adding any value than there's something fundamentally wrong and you're not able to scale the application in a linear fashion. The goal here is, of course, to be able to scale in a linear fashion.
Nonlinear scalability
Nonlinear would be where, as you add more servers you see increase but at a certain point after that there's no more increase, in fact, there's a drop of performance even if adding more servers because the architecture of the application and the deployment there's some bottlenecks which you just are not able to overcome.
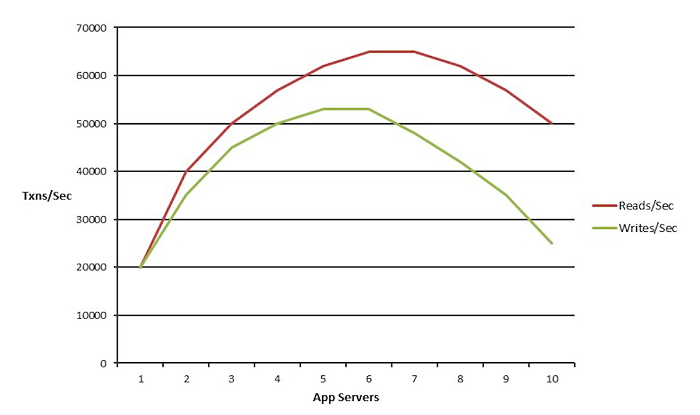
Which applications need scalability?
These are usually web applications.

So, these are ASP.NET for.NET folks, web services, back-end for the Internet of Things which is a very strong emerging space and big data processing. Big data processing is more common on the Java side. Not a lot of people do it in the .NET side but big data processing is also another space. And, any other server application, this could be your batch processing application. You may be a financial services company and you have millions of customers and they call and change addresses or maybe they're transferring funds from one account to the other and as you have certain compliance requirement that by the middle of the night or something you have to complete those processing and there are some batch processing happening in the backend, in a workflow, in a manner. So, any other server applications that are under time constraint to get a certain number of transactions done, need scalability.
Scalability Problem
So, where is the scalability problem? We talked about linear and nonlinear scalability. So, the scalability problem is that the application tier scales in a very nice linear fashion. If you have a web application or web services, your application tier, you just add more servers, no problem. It's the data storage that's the bottleneck. And, when I say the word data storage, I mean relational databases and mainframe legacy data. I don't mean NoSQL database. NoSQL databases are great. We also have a NoSQL product called NosDB but no SQL databases are not always the answer. They are an answer if you can move the more data you move to NoSQL database is the more of a scalability solution you get. But, the problem is that you cannot move all data to NoSQL. There's a lot of data that has to stay on relational for both technical and business reasons.
So, relational databases are here to stay. They're not going anywhere in terms of, this problem. So, you have to work around this reality or work with this reality that you are going to be working with relational databases and still you have to solve this problem. And, the reason you have to solve this problem is that you have all those applications that I mentioned that need scalability.
Distributed Cache Deployment
And, the answer of course, is to have a distributed cache plugged in between the application tier and the database tier.
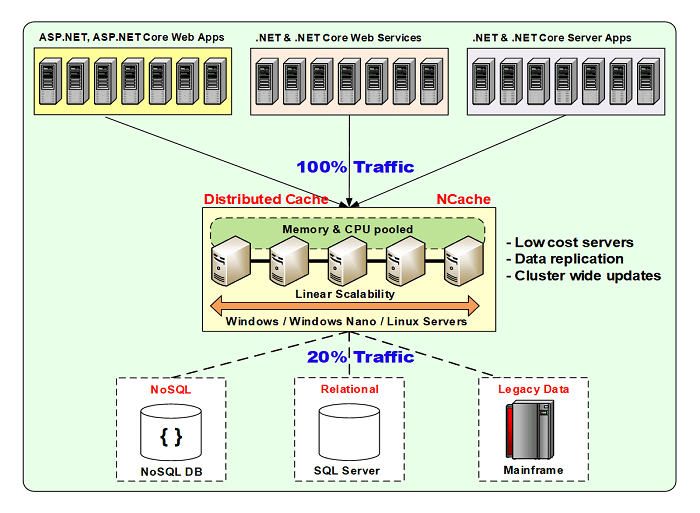
So, a distributed cache is, essentially, it's a very powerful and yet very simple concept. You have two or more low cost servers and they're clustered together and that cluster pools the memory and the CPU resources of all the servers together into one logical capacity. the bottleneck and scalability comes in three areas. One is memory, second is CPU, third is network card.
So, if you have, let's say, one database server here and you have 20 application tier boxes that one database server you can take it up in terms of the hardware strength is concerned, you can add more memory, a lot more CPUs, but there's a limit to that. So, the answer is, to be able to have more and more servers which are not very high-end, in fact, they should not be high-end by definition. And, what we've seen over the last 10 years or more of doing this is the most common configuration is a dual CPU quad-core type of an equivalent. So, let’s say, an 8-core box and a 16-core box is actually a pretty high-end configuration for a caching server. 8-cores is pretty much the common.
Memory, of course, you need a lot of memory because and memory is cheap so it's not it's not a big factor. You need a lot of memory, why because cache is an in-memory store so it stores everything in memory and, a typical configuration would be about 16 to 32 gig of memory in each cache server and 2 cache servers is the minimum you should have for redundancy purposes. So, by having this architecture, now you are in a situation where as you add more servers in the application tier. You add more servers proportionally in the caching tier. So, usually, it's a 4 to 1 or 5 to 1 ratio is what we've seen as the most practical one. In some cases, you can go a lot more than 5 to 1. Means 5 application servers to 1 caching server but there's no limit to how many servers you can have. You can have 2, you can have 4, 10, 20, 30 servers but for you to have 20 servers here, you probably need a hundred server in the load balancer environment.
So, at some stage, that becomes a pretty much a high end of any application that we've seen in the web or e-commerce on online business scenario. So, by adding more servers here, this is no longer the bottleneck. So, the distributed caching is actually becoming a best practice. If you have scalability as the need. Because now, not only you have a database which is there for its own purpose, you need permanent data store persistence for all the application data but you also have this really really fast and scalable infrastructure which is part of your application architecture now. So, when you're programming, you're no longer just programming for the database. You're always thinking of a cache because the cache will now make sure that your application never slows down even under peak loads. Even though the database wasn't designed to scale in the same fashion. So, this is a typical picture.
About 80% of the traffic will get trapped or will be 80% of time you will go to the cache, 20% of the time you will go to the database and that those 20% are mostly updates and of course, some reads because you need to get data into the cache but you can also pre-populate the cache and there are a lot of other ways to do that. But, by reducing traffic so dramatically in the database tier, that's how you achieve performance and scalability.
So, that's kind of the case for using a distributed cache. Why you must keep that as part of your application architecture.
Common Use Cases
So, now that we've kind of made the case for using a distributed cache, the next question is well how do you use it? Where do you use it? what type of usage should you have of a distributed cache?

Application Data Caching
Well, the most common use is the application data caching. This is where as I was just talking about, whatever data you have in the database, you cache it. So that you don't have to go to the database. The thing to keep in mind and I'll go over this point in more detail in the follow-up slides is that in an application data caching use case, the data exists in two places. One is in the database which is where it always has to be and second is the cache. So, whenever data exists in two places, what's the first problem that comes to mind? Syncing! Yeah.
So, any cache that cannot handle that situation, forces you to cache read only data, data that you know is never going to change. In fact, most people when you talk about cache, the knee-jerk thinking that comes to their mind is why it's for read-only data? I really don't want to cache my customers and accounts and, data that's changing every 30 seconds. But, the research shows that the biggest use of a cache is in the transactional data and once you cache it you'll probably need it in the next one minute or two minutes, whatever that activity, whatever that moving window of your use is. That's when you need the same data again and if you can get it from the cache you're reducing those trips to the database and multiply that by millions of transactions that are happening in your application and it becomes a pretty significant boost. So, keep that issue in mind as we go forward that any good cache must handle that very very effectively.
ASP.NET Specific Caching
Second use case is, if you have an ASP.NET application, there's a lot of transient data. Transient means temporary and that you can put in the cache and this data doesn't really belong in the database. For example, a database is there for permanent. It's a permanent store. That's your master record. So, a session state, you probably need to keep it for only as long as the user is logged in maybe 20 minutes after, you know. So, why keep it in the database? Database is not as fast. Relational databases were not designed to store blobs and sessions are usually stored as blobs. So, there's a big performance hit when you store sessions in the database. So, session state is a very good use case for ASP.NET to put it in the distributed cache.
And, if you are not using the MVC framework then view state is also there which is a pretty heavy piece of data that flows from the web server to the browser for only one purpose, to come back to the browser at a postback. So, it's a pretty long trip, for nothing as they say. So, it would be so much nicer if you just keep it on the server side and just send a small key. So, that's a very very good use case for caching.
The third use case is page output, a lot of your pages their output doesn't change every time. So, if it's not changing, why execute the page because when you execute the page you are consuming the CPU and the memory and all other resources. Why not just take the output from the last execution and display it. So, Microsoft or ASP.NET has an output cache framework where you can plug in a distributed cache. So, now in this use case, in these three use cases under ASP.NET, the nature of the problem has completely changed. It's no longer synchronization between the cache and the database. Why? Because there is no database. Cache is the database.
The nature of the problem now is.. so cache is in memory, all right? That's how you get all the performance. So, when you're keeping data in memory and that's the only store, what is the biggest concern that you have? You might lose it! What if that box reboots? Windows is known to reboot or recycle worker processes. What if and I mean, even if a Linux box would have to reboot but, what if your box reboots? Are you ready to lose that data? What if you're an airline and that customer was in that last page of hitting submit a $5,000 worth had that family vacation ticket that they were going to buy for Hawaii and suddenly it says, sorry you got to start all over again! You know and they went through all sorts of flight research and check times and did Google flights also and see which ones matched and all the other stuff so, not a good experience.
As a business, you don't want to lose customer, the shopping cart, you don't want to lose that. So, the answer to that is a distributed cache. You should only keep sessions in it or all that transient data if it can ensure reliability, if it ensure that you'll never lose that data, has it ensure it does replication. So, a good distributed cache does a replication of data across multiple servers. Now replication is actually a waste of time, it's extra thing that being doing just for that contingency that we're just talking about. So, the negative side of replication is that it has a performance hit. So, if a cache doesn't do it intelligently and a lot of them don't, then you will have you'll see a performance hit when you turn on the replication.
Runtime Data Sharing Through Events
So, keep these two points in mind and the third use case is what most people don't know actually that a distributed cache, once you have that infrastructure in your environment, it's a very powerful event-driven data sharing platform. So, you may have multiple applications that need to share data in a work flow. You may have a pub/sub type of a situation, that you are going to probably use a message bus, enterprise service bus or a message queue for it. A distributed cache is a very powerful platform for that. Since you have it in-house already, it's actually faster and more scalable than the other options because it was designed for performance whereas the other applications were designed more for sharing only.
So, event-driven pub/sub type of a sharing between multiple applications. One application produces some data, puts it in the cache, fires off an event. There are other applications which have registered interest in that event, that I want to consume this data whenever that's available for me. So, they receive the event and again one application could be here, one application could be here this becomes very very powerful scalable event engine that they can all tap into.
So, that's a third use case. Even in the event, in the runtime data sharing feature or use case, most of the data is transient. Although it's being derived from permanent data and it could probably recreate it from that permanent data but it's a lot of work to do that and that data is usually in this temporary, because the nature of that uses temporary. It's not usually, it doesn't need to be saved in the database. It just needs to be consumed. So, cache is that again the only store that it'll be and so just like the sessions and others the issues are the same that reliability has to kick in. So, those are the three common ways that you would use a distributed cache.
So, the nice thing about these three use cases is there's no programming needed to do that because the ASP.NET framework allows you to plug in a third-party provider. So, for sessions for example, if you were to have I'm just going to quickly show you a one quick sample where all you do is you go to the web config and of course, in the ASP.NET core, that paradigm is going to slightly change but the idea is the same.
Configuring ASP.NET Session Caching
So, if you go to the Web.config, this is just a simple ASP.NET application. You go to Web.config, you need to first fall add the assembly of whichever cache you're going to use in case of NCache, you're going to just do the add assembly on the NCache session store provider and you just copy paste and the second thing which is what you need to do really is to make changes here.
So, there's a session state tag in the web that config where you need to make sure that the mode is custom and the timeout is whatever your timeout is going to be. And, in case of NCache, then you need to actually just add this line and there a bunch of other parameters that you can specify that I'm not going to go into but one of them is to just the name of the cache. In case of NCache, all caches are named and I'll actually give you a demo of that too but. So, you just specify the name of the cache. The cache is already created. That's like a connection string that tells you which cache to connect to because you might have multiple caches, one for Sessions, one for application data and that's All. I mean you make that change and you just do a sanity test, go through all the common use cases of your application and your application is suddenly ready to store sessions in a distributed cache like NCache. So, the easiest way to benefit and the biggest gain actually is sessions.
So, that's all you have to do for the session state usage in a distributed cache like NCache or any other and the same goes for view state output cache. It's all the configuration based change. I'm not going to go into those each of them. I just wanted to show you this as an example.
App Data Caching
So, let's come to the heart of a distributed cache and I say heart because that's where most of your time is going to be spent. If you choose to incorporate a distributed cache, you'll be doing most of the your time doing application data caching. So, what is a typical API look like?
Cache cache = NCache.InitializeCache("myCache");
cache.Dispose();Employee employee = (Employee) cache.Get("Employee:1000");
Employee employee = (Employee) cache["Employee:1000"];
bool isPresent = cache.Contains("Employee:1000");cache.Add("Employee:1000", employee);
cache.AddAsync("Employee:1000", employee);
cache.Insert("Employee:1000", employee);
cache.InsertAsync("Employee:1000", employee);
cache["Employee:1000"] = employee;
Employee employee = (Employee) cache.Remove("Employee:1000");
cache.RemoveAsync("Employee:1000");If you guys know ASP.NET cache object, NCache tries to mimic it as close as possible although we are a superset so there's more. Every cache has its own API. This is what an NCache API looks like. You connect with the cache, it's a named cache. You get a cache handle, you keep that cache handle around and within the application you keep just do Cache.Get. Get, Contains, Add, Insert, Remove, there's also add Async, Insert Async. Insert means add if it doesn't exist or update if it already exists. That's the same terminology that ASP.NET cache object you use it that's why we also used it. And, the Async method basically means that you don't have to wait for that operation to be completed. You can actually, there's a third parameter which is that you can specify a callback. So, your callback will be called in case something goes wrong or else you can pretty much assume that everything went fine.
Keep Cache Fresh
So, when we were here, we talked about application data caching, the biggest concern is that you have to keep the cache fresh. So, a good distributed cache must allow you to do that because if it doesn't, it forces you to cache read only data. Read only data is about 10 to 15% of your data, anyway. So, how are you going to really get benefit out of this cache if you're only caching 10 to 15% of what you should be caching? So, what you want to do is cache all data, practically all data, very very few pieces of data would be where you say it really doesn't make any sense to cache. But, almost all data. Some of the data you'll cache for a short time. So, once you cache that data, this is all application data, the hardest cache ensure that the cache is fresh the different ways that it can do that number one is expirations.

Using Time based Expirations
Expiration is an absolute expiration and there's a sliding expiration. They 2 have very different meanings even though they both are expirations. Absolute expiration is what you should be doing for keeping the cache fresh because you're making the guess you're saying, I'm saving this customer object in the cache. I think it's safe to cache at five minutes. You're just making a guess based on, it's an educated guess but it's a guess. Within five minutes you hope that nobody's going to modify it in the database but if they do then your cache will be inconsistent with the database. Sliding expiration, on the other hand, has nothing to do with keeping cache synchronized. It has to do with the eviction or it has to do with the automatic cleanup of the cache.
So, sessions, you're saying when there is nobody logged in, after 20 minutes of inactivity remove the session. So, you're doing like a cleanup. You're saying the cache please clean it up, clean it up for me. I don't want to have to keep track of all of this. I've put it in the cache, I've specified how long it should stay in the cache even if nobody's touching It, after that clean it up. So, very different goals that you have from permanent from absolute expiration versus sliding expiration. So, sliding expiration, you would use for sessions for transient data. Absolute expiration, you would use for permanent data.
Another term I want to use is reference data versus transactional data. Reference data is data that does not change very frequently, but it does change, it's not a read-only. it's, it's your product table which the price might change every day or every week or something but it's not as frequent as a customer object or as activity object or something or an order object. So, transactional data is what we want to cache. Of Course, reference data is a given we want to cache that but transactional data is also something that's where we're going to get all the data. So, if expiration is not sufficient to ensure that your cache is going to stay fresh then, you need to have more features.
Using Database Dependencies
So, the next feature, a very powerful feature that a good distributed cache must have is that it should be able to synchronize the cache with the database without involving you, without having you monitor things. So, you should be able to tell the cache that I'm caching this object. This is related to this data set in the database. So, please monitor this data set in the database. See if it changes, please go and do one or two things, either remove this item from the cache, removal means that next time the application wants it, it will not find it in the cache. What happens when you don't find it in the cache? You get it from the database. So, it's like getting a new copy or second it might just reload a new copy automatically. Reloading a new copy automatically requires another feature called read-through which I'll talk about.
So, I'll come back to that but database synchronization is a very very powerful feature. This is what gives you peace of mind to make sure that your cache will stay fresh. That you will not have to worry about whatever data you're caching and there are different ways to synchronize the cache with the database. The most common is SQL dependency which is actually an ADO.NET or SQL server feature that NCache uses.
So, for example, I'm going to actually show you the code I was supposed to. So, let me quickly.. I'm going to quickly show you what the code looks like. Where'd that go? So, if you have a .NET application, let's say this is NCache, of course, you would reference two of NCache libraries. NCache.Runtime and NCache.Web. So, as again, we've tried to name it as close to the ASP.NET cache object namespace so NCache.Web. When we came out back in 2005, ASP.NET cache object was the only cache around so we are the oldest in the space so that's why we picked that name to make it easier for people. So, within the application you would include a couple of NCache namespaces. Then, you would connect with your cache, you get a cache handle and now you have a cache handle so, let's say, you create your object and you want to do Cache.Add. So, Cache.Add takes a key. Notice the key is actually a string so we've followed this. Well, this is not following that naming convention but usually it's Customer:CustomerID: whatever the ID was for that customer so you do Cache.Add after and then you, in this case, it is specifying one-minute absolute expiration. As saying don't do any sliding expiration and all the other stuff. So, it's just to sort of give you a flavor of what a cache looks like.
Very easy to use, very simple API, much simpler than doing ADO.NET or any other programming.
What a Cache looks like?Let me just actually, let me actually show you what a cache looks like but with an actual cache. So, I have these VMs and Azure. So, I've got demo 1 and 2 two. These are two cache servers that I'm going to use. These are cache VMs and I will have my application server. I'm just going to call it demo client. So, my application is going to run on demo client. Okay! So, I have Remote Desktop into this. I'm going to in case of NCache I'm going to run this tool called NCache manager, I actually have it here. And, I will go ahead and create. Let me just quickly make sure there's no cache already by that name. Okay! So, I'm going to go ahead and create a new cache. I will call my cache demo cache. I'm going to just take everything else as the default. I will pick a caching topology. I'm not going to go into the detail but this caching topology does both partitioning and replication at the same time. So, when you do this topology your cache will look something like this.
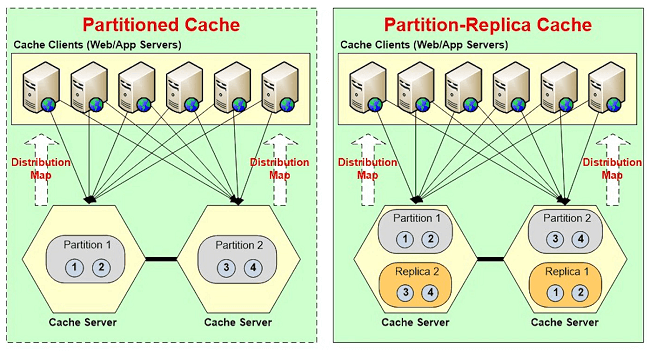
So, these are your cache servers. So, some of the data, this 1 2 3 4 are the data elements. So, some of the data is in partition 1 some of the data is in partition 2 and every partition is backed up on to a different server. So, if you had 3 servers here.
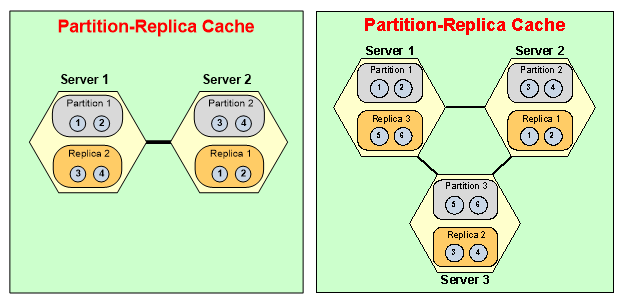
Let's say you would have partition 1 2 & 3, server 2 has the replica for partition 1, server 3 has a replica of partition 2 and server 1 has replica of a partition 3. So, the cache actually is a server. It's actually more than one server, which is in a cluster. They know each other and I'm gonna quickly now take you back to this. So, let's say I've picked a partition replica topology. I will pick demo 1 as my first cache server. Why is it so slow? Demo 2 as my second cache server. I think it's probably because the internet is slow, maybe. I don’t know. So, I've got a two node cache cluster. So, demo one and two now know about each other. So, they're going to talk to each other on this port. On port 7802 which I could change. Why is it so slow? Make sure.
Okay! So, the next I'm going to specify how much memory the cache should have. So, it has one gig, you'll probably have, as I said, 13 gig or something. And, then I'm going to specify the eviction policy which is least recently used. I'll save 15%... I'm sorry evict 5% of the cache. This is really slow, I don't know what's happening. This whole box is slow, even a click is, even the CPU is not, yeah! Looks like it. Yeah it is!
Okay! So, basically, you have a cluster of servers that logically are called the cache and you know them by a demo cache only. On your box, let's say, your application server box, let's say NCache is installed here. You're going to have a config file which will have that cache name and a list of servers that represent it. So, that's just a starting point but again you will know that entire cluster is just a cache name and you connect to it and then your client API will connect to all the cache servers in this picture. In case of partition replicas every client talks to all the servers so it can go directly where the data is, the partitioning part.
I'm going to go ahead and add a client for this which is my demo client. I'm going to go ahead and click on the cache assistant, taking a long time to click, and I'll say start the cache. So, just by saying that the cache will start on both of those boxes. NCache is a windows-based cache so it has all the easy to use capabilities that a good windows-based product has. So, you can do all of this from a central place, all this you can also do through scripting.
Database Synchronization - DemoSo, let me show you what database synchronization looks like. So, for example, what you do is, again it's the same type of an application, you've got the cache and when you try to add a data to the cache, let's say you're doing Cache.Add here and this is of course NCache code, you specify a SQL cache dependency which is an NCache class but it maps on the back end to the SQL server SQL dependency class. And, you pass it a SQL string which is then used by NCache to connect to the database and the cache server now becomes a client of your database. So, for example, if your application is here, let's say, your code is running here, you just issued this call. Oops sorry! You just issued this call of cache that ad and you pass this SQL cache dependency. The client sends all of this to the cache server.
So, one of the cache server or multiple. And, the cache server now opens a connection to the database because you've specified a connection string also here. And, this connection strength is of course pool. So. if multiple times you specify the same connection string then there's a connection pool on the back end. So, another cache now has become a client of your database. It will monitor your database so the database will notify the NCache server that this data has changed that you've asked me to monitor and the NCache server at that time can decide whether it should remove that item from the cache or reload it from the database. And, to reload it you have to actually go through the read-through feature.
Okay! So, that's one way to do it. It's really powerful. It’s event-driven. As soon as the change happens, the database notifies the cache, the cache immediately takes the action. However, there's an overhead on this database server end because every time you do a SQL cache dependency, a data structure has to be created within SQL server to monitor that data set. Now if you had 1 million of these, I can guarantee you your SQL server is going to crash. So again, since we're talking scalability you need to think in terms of really large numbers. So, if you have thousands or tens of thousands of these, no problem. But if you have hundreds of thousands or millions of them then a different strategy would be a better strategy.
Database DependencyOne other strategy is called DB dependency which is our own NCache feature which is a polling based dependency. We've implemented this where. There's a special table and we ask you to modify triggers so that you can update the flag in that table for that corresponding row and then whenever you do a DB dependency from the cache, the cache creates an entry in that table and then in one fetch, the cache can fetch thousands of rows where the flag is true, the update has been happened. So, it's like our own way of keeping track. It's polling based so it's not instantaneous. By defaults about 15-second delay but you can reconfigure that. You don't want to pull too frequently either. So, that's the other but even there you have limitation of, what if you have 1 million rows in that table with a flag of true and false, the index would look pretty big, right? There's a true and there's a false index, those are the two nodes of a tree. So, DB dependency is more efficient than SQL dependency but not as real-time but even it has limitations.
CLR ProceduresThe third one is the CLR procedures where you can actually call a CLR procedure from a trigger in the database so whenever any item is added, updated or deleted, you call the procedure. The procedure makes an Async call to the cache. It says please add or update or delete this item from the cache. The reason Async is critical is because you don't want to delay the transaction, the database transaction. It's going to start timing out otherwise. So, an Async call will immediately return and at least the database transaction can commit and the cache can be updated. So, the synchronization of the cache with database is critical feature.
Synchronize Cache with Non-Relational
You must have that and the same thing if you have non-relational or you may have mainframe or legacy or any other data source, you may have a cloud data source, you may want to make a web method calls to even check whether that data is updated or not and NCache allows you to have this custom dependency feature where it's your code that can monitor NCache, calls your code every small interval, you go and monitor your data source to see if that data has changed, if it has you notify NCache and NCache will either remove or reload again the same way.
Handling of Relational Data
So, keeping cache fresh is critical. Any cache that doesn't let you do that, it limits your ability to benefit. I'm going to skip the handling of relational data although, even that isn't and what, let me quickly say it, you have one-to-many relationships, one-to-one relationships. So, if you have one item in the cache and many items also in the cache, when you remove the one item in the cache logically the many items should also be removed because what if you've deleted that from the database. So, the cache should be able to keep track of all of this. You could do that in your application but it just complicates your application credit cause now you're doing a lot of bookkeeping for the cache. It's like you're building in database synchronization or data integrity code within the application which is not the job of your application. You don't do that for the database. The database does it for you so the cache should also do it for you.
Read-thru & Write-thru
So, read-through, write-through is another very powerful feature that your cache should have. Read-through is basically, again, the concept is very simple.

You implement an interface, in case of NCache you implement an interface called read-through provider, right here. Can you see that?
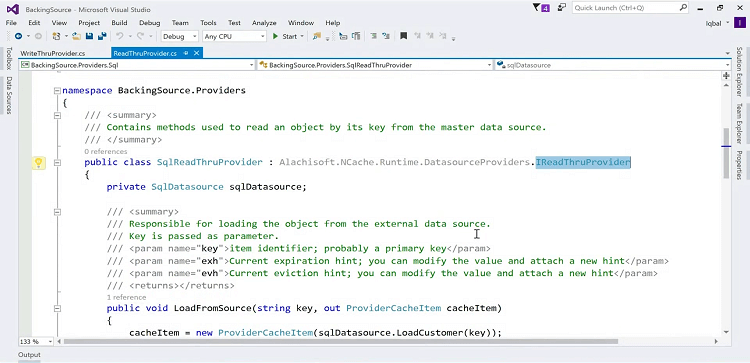
Yeah and it has three methods. There is an Init which gets called when the cache starts so that you can connect to your data source. There's a dispose when the cache stops you can do your cleanup and most of the time you will call this load from source. So, it passes your key. The key is your key to know, which item in your data source to fetch and then you give it back, in case of NCache a provider cache item. And, you can specify expirations and resync on expiration, all sorts of flags here and then pass it on to NCache. NCache caches it.
So, how does read-through work? The way we through works is, your application always asks the cache. It says Cache.Get. If the cache doesn't have the data, instead of saying I don't have it, it goes and gets it from the database. So, your application suddenly becomes much simpler. A lot of the persistence code, you've just taken out of your application. So, one benefit of read-through is the that you've sort of simplified the code, you've encapsulated it all into the caching tier. The caching tier has now has more and more of your persistence layer. Not all code can be done though read-through but a lot of it can be.
Reload on Expiration
The second benefit of read-through is what I talked about earlier which is the reload feature. Now imagine, if you have an e-commerce application and your pricing change and every time pricing change those items have to be removed from the cache and reloaded but it's really heavy traffic so while they're removed, a lot of client requests will hit the database. The first one will fetch it and put it in the cache but until that time the cache suddenly have a lot of unnecessary traffic and if that keeps happening, if you have a lot of that happening the database is going to get a lot of unnecessary hits which you could have avoided if you just said reload on expiration. So, reload an expiration, what does that do? It does not remove the item on expiration. It just reloads it so it when expiration happens, the cache will call the read-through and go and get it from your data source and just update. So, there's only an update operation happening. There's no remove and add operation and because of that the data or the item is always in the cache. So, the cache suddenly now becomes. It can take care of itself and it can go and reload itself whenever data needs to reloaded.
Write-through
So, that's a really powerful capability of read-through. So, when you combine that with expiration and you can do that also with database synchronization. When the database synchronization happens, again, why remove it? Just reload. The other feature is write-through which works just like a read-through except it does writing. There's one more thing that it does, it can also do bulk write. And, the reason it does bulk write I'll explain in a bit. So, the same way there's an Init, there's a dispose and now there's a write to data sources. The write does not mean add or insert only. It also could be delete so the write has an operation type which can then either be add, update or remove. And, that depends on what the cache operation was. And, then you can also do that on a bulk. So, the write-through has the same benefits of read-through in terms of simplifying your code but again has one more benefit. So, the read-through had the reload benefit the write-through has the benefit where you can write-behind.
Write-behind
And, write-behind is a very very powerful feature. Why? Because the database updates are a bottleneck. Again, database is that necessary evil that you have to live with. You cannot live without it but it's causing all sorts of bottlenecks in your application. So, the less you can depend on it the better your application. The fact that you cannot live without it you still have to have it. So, what does a write-behind do? It says you update the cache which is super-fast, ten times at least faster than the database if not more, and then the cache takes care of the database update. So, there's an asynchronous write-through, that's a write- behind. So, you will go and update the cache, come back and you continue your stuff and the cache goes and updates database.
Of course, there are a lot of issues that the cache must address. As soon as you say that cache has to update the database, what if the cache server crashes? What happens to that queue? So, in case of NCache, the queue itself is replicated to multiple servers if any server goes down you don't lose the queue. Then there's also retries. What if that update fails then you can retry. You can also do batch update. So, there are a bunch of them you can do a bulk update. So, it can optimize things further. So, write-through and read-through are very very powerful features. That’s called server-side code. This is your code that lives on the cache cluster. It lives here and keeping that code on the server simplifies your app. So, the more code you push down, the simpler the application becomes.
Data Grouping
Okay! Now that, let’s say, you're convinced that you should use caching. You have the different use cases where now you are confident of caching a lot of data. So now, cache has started to look like the database. it's starting to have a lot of, You are going to have millions of items in the cache. So, when you have millions of items in the cache, is it good to just read things based on a key? No! if the only way to read items from the cache for based on the key, your application would be very very challenging compared to if you could do things, well give me all the things based on this search criteria.

So, searching and grouping becomes a very very powerful need or very important need of a cache. Again, as I Said, the purpose is for you to understand what are the benefits. The benefit is if you can cache more and more data. The more data you cache, the more you need to see it or have more of the database type of features. One of those features is to be able to do metadata. In database you can have indexes on a lot of different attributes. Here you can do tags, named tags and actually when you cache the objects, in case of NCache it also lets you create indices. So, you can index an object. Let's say a customer could be indexed on city attribute because you're going to search on city so it should be indexed. If it's not indexed that search is going to be really painful. Imagine millions of items that you have to first deserialized to inspect every object just to know which customers in Orlando. Not a good picture not a pretty sight.
So, grouping subgrouping tags and name tags again from a coding perspective very simple. I'm just going to quickly show you this. From recording perspective very easy to use. You add a bunch of items and you assign it tags and then, I'm sorry! group and subgroup, group subgroup and then you say get group data or you can also do an SQL search and say give me all of the product object where the group name is electronics. So, grouping and sub grouping tags and tags are also something that AppFabric provided, by the way AppFabric is being discontinued in February. We've gotten more minutes I'm going to speed it up.
Finding Data
Again, finding data is related to grouping data you want to be able to search data based on SQL so I think I… where is object query language? There it is. So, I could, basically, I've got a bunch of data and I could issue a SQL statement and I can specify multiple attributes and pass parameters and I'll get a record set back in case of NCache and just like SQL server, although, it's a subset of the full SQL. It doesn't do joints but instead of doing join you can do grouping and tagging and that's how you can group multiple objects together.

So, in case of LINQ, NCache has implemented a LINQ provider so the Iqueryable interface. You go and get that collection from NCache and then you do a LINQ query just like you do against any other object collection and it's going to go ahead and get you a collection of these objects, the product objects back. So, if LINQ is your really comfort zone in terms of searching, use LINQ to search. When you issue this query, you're going to the cluster that same query is going to be sent to all the servers and the results are going to come and get merged and then shown to you. So, it might, although it looks very simple here, behind the scenes there's a lot of work being done by NCache.
So, we have SQL and LINQ. We also have bulk and as I said, you can do Indexing.
Runtime Data Sharing
I am just going to very quickly… there's key based events, there's cache level events, there's pub sub events, there's a continuous query.

Continuous query is a feature that's like a SQL dependency feature except it's on the cache. You're asking the cache to monitor a data set for you. So, just like we were using SQL dependency and asking SQL server to monitor this data set and said if this data set changes please notify me. Now, you're asking NCache, saying please, here's my SQL statement, select customers where Customer.City equals New York and you're saying if any customer that matches this criteria is added, updated or deleted from the cache, please notify me and that could be any place on the network, any place on the cache cluster and you could be any other clients. You'll be notified. So, by having those types of features now you can suddenly monitor what's happening to the cache and be notified instead of polling things and that's what I was saying the cache becomes really powerful runtime data sharing platform.
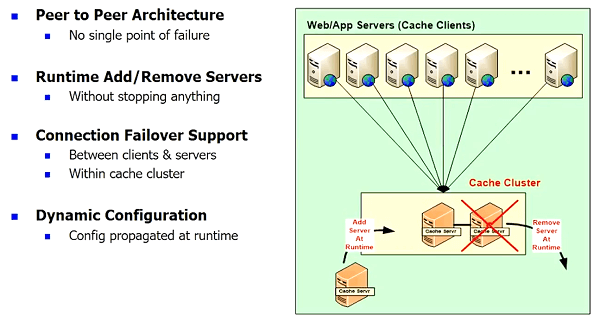
High Availability
Okay! I'm going to skip this also. I mean any cache that you use has to have dynamic. It has to provide high availability which in case of NCache, it's got a peer-to-peer architecture.
Client Cache
There's one feature that I do want you to know which is called client cache. Some people call it near cache.
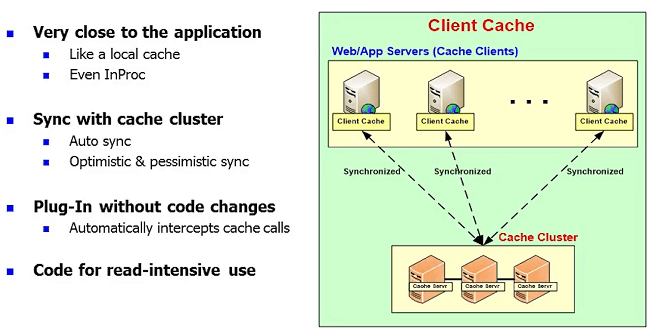
This is actually a cache that sits locally on your application server box. It's like a standalone cache except it's not standalone. So, it can even be InProc. It can be within your application process that means you're actually fetching things as on your object heap. Your heap has data in object form. Nothing beats that performance, right? If you can just get that data from the heap versus going to a cache local box OutProc because when you go across processes it has to go through IPC, it has to do serialization, deserialization, when you go across the network it's even more, when you go to the database it's phenomenally expensive, comparatively.
So, this is a local cache within your application process or locally on the box. But, it stays synchronized. You don't do any special API programming for the client cache. You just make the calls to the cache, in case of NCache, it just plugs into the configuration change and it intercepts the calls and whatever you're fetching it keeps a copy of it in locally. So, the next time you fetch it, it'll automatically get it from the local cache. Huge boost in performance. This is something that only NCache has on the .NET side. On the Java side, there are other products that have client cache but on the .NET said this is only. This is like a cache on top of a cache and this is the reason many people, when they move from the standalone InProc cache to a distributed cache, they complain, my performance has actually dropped, my application is slower, I thought distributed cache was supposed to increase my performance and we tell them no it's supposed to increase the scalability. Nothing matches a local InProc cache, nobody can. I mean this not something that we can invent and do something. You're going across processes, that's a cost as it takes.
So, then we say well, one way you can overcome that challenge is by using a client cache. So, a client cache again is a subset. Usually, you would have 16 to 32 gigs in each cache server. So, if you have three to four servers you've got about a hundred plus gig of cached data potentially and the client cache maybe one gig, maybe two gig, maybe three or four gig, maximum each and depends on how many worker processes you have. If you have only one worker process, make it four gig. If you have eight worker processes, which many of our high-end customers have on their web tier then you don't want to have four times eight just at the client cache. So, then maybe, it's good to have a four gig out of process cache which is still better than going to the caching tier. It's still faster or you can have a smaller one gig or less than one gig cache which is InProc. Now, you have eight copies of it but they're also synchronized. So, definitely a client cache is something you must consider using if you're going to gain the value out of a cache.
Now, my goal and this is not to sell you any caches features but to say what a good cache must have and many of these features you will find on the Java side. Java is a much more mature market on the caching side. They use the word in-memory data grid instead of distributed cache, but whatever feature you're seeing with NCache, you'll see many of them also on the Java side, but on the .NET side NCache is the only one.
WAN Replication
Another feature is, well if you have multiple data centers, you'd want your database to be replicated so why not the cache? What are you going to do? Are you going to rebuild the whole cache? What about the shopping cart? What about the sessions? So, multiple data centers is a reality and the cloud has made it even easier because there's no effort on your part. You just go and say region one and region two and you've got two data centers, right? But the underlying problem doesn't go away, which is if you use a distributed cache that does not support WAN replication, you're stuck. You can't have an active-active or even an active-passive, multi data center solution without the cache being replicated, so very important feature.
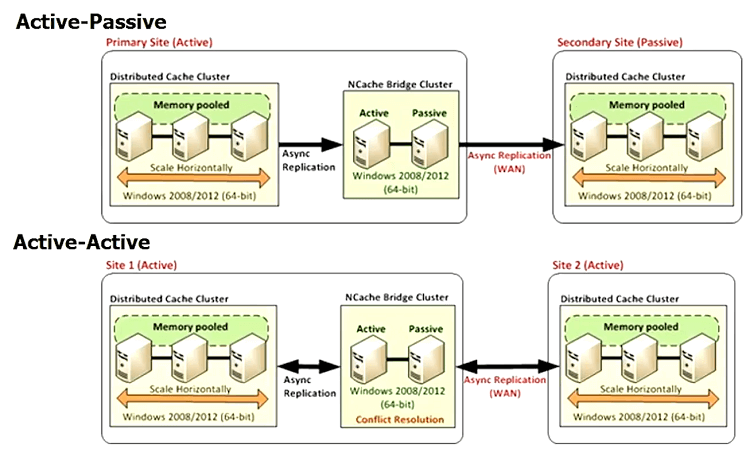
NCache of course has this. I've already given you the hands-on demo. NCache is the oldest .NET cache in the market. We were launched in 2005, much older.
NCache vs Redis
So, I'm going to quickly go over NCache versus Redis, very very high level and that's because Redis is a lot of people come and ask us that how do you compare with Redis since that Microsoft chose them for Azure.

Redis, is a great product. It's super-fast. It comes mainly from the Linux side. It does not have a lot of features. It doesn't win on features. It just wins on the fact that it came from the Linux side and Microsoft wanted to capture the AWS market so they couldn't adopt a .NET solution. They had to adopt, multi-platform. So, their Linux version is very stable, very good, but the Windows port that Microsoft did itself is kind of an orphaned port. Microsoft doesn't use it themselves. When you are in Azure and use Redis, you're not using the Windows port of Redis, you're using the Linux version. So, if you're not on azure and you're going to use the Windows port of Redis, beware. I mean nobody owns it. Redis labs, if you go to their website, they don't even have a Windows download. I mean they only have Linux downloads which is the creator of Redis. Microsoft, as I said themselves, they didn't put their money where their mouth was in terms of the use the commitment.
So, NCache is the only viable option for you and it's open source so if you don't have the money, go with the free open source version. If your project is important and you want support and more features which is the enterprise features. The enterprise NCache is built on top of open source. It's not like a separate thing. Open source is not orphan. I mean we own it, we maintain it and the enterprise is built on top. So, open source has to be stable but if you want support and more features then just purchase the Enterprise Edition.
We are native .NET. We developed in c-sharp and we've got Windows Server 2012 r2 certification. We're going to get the next one also soon. So, we mean we're not on top of the game as far as Microsoft is concerned. We're pretty much .NET that's what we are. We have a Java client but almost all of our Java usages by customers who buy NCache for .NET and since they have it in-house they also use it from Java. So, our bread and butter our entire survival is on .NET. So, we're always going to be the on the latest and the greatest, the first and the easiest.