Client Cache
NCache Client Cache is the local synchronized cache L1 on the application node which maintains the most accessed data to avoid network latency; thus, it acts as a performance-optimized layer between the application and the clustered cache, L2. It supports both InProc and OutProc isolation modes. The Client Cache in NCache operates in two different configurations, Regular and Full-Data Client Cache.
Regular Client Cache
The Regular Client Cache functions as a local cache (L1 cache) on the client machine. It loads a subset of frequently accessed data from the clustered cache and stores it close to the application. This reduces frequent network trips to the server for similar data. To ensure data integrity, the Client Cache synchronizes itself with the clustered cache (L2 cache) by polling for change notifications from this L2 cache. However, since the L1 cache does not guarantee complete data in the Regular Client Cache, queries always occur on the clustered cache (L2 cache).
All key-based Write operations like, such as Add, Insert, and Remove, are first preformed on the clustered cache. Upon their successful completion, data is added to the Client Cache in Regular Client Cache. For Read operations, if data is not found in the Client Cache, it is fetched from the clustered cache, and data is then populated in the Client Cache.
Full-Data Client Cache
The Full-Data Client Cache provides quick access to cached data by loading complete datasets from the clustered cache (L1 cache) upon cache start. For optimized memory usage, it lets the user configure the reference data types. However, configuring the Full-Data Client Cache requires more memory on client boxes than usual. By default, if a requested key from the configured data type(s) is not found in the Full-Data Client Cache (L1), the search will automatically fall back to the clustered cache (L2) for read operations. For queries, these are executed on the clustered cache for non-configured reference data types. However, for configured reference data types, queries will be executed on the Client Cache first, and will fall back to the clustered cache only if the data is partially loaded.
Important
You cannot create a Full-Data Client Cache without configuring at least one reference data type.
However, for configured reference data types, if your use case demands strict reliance on local data—without any fallback to the clustered cache, you can enable Strict Local Reads and Strict Query Enforcement through the configuration options provided in the NCache Management Center. These features are described in detail below.
Note
The Full-Data Client Cache can not be configured while the clustered cache is running.
Important
If you make any configuration changes to the Full-Data Client Cache, you must restart the Client Cache.
Only those items that are configured as reference data types will be included in key-based Write operations like, Add, Insert, and Remove. These operations are first preformed on the clustered cache. Other Client Cache instances are updated through a background data synchronization mechanism, which is explained later.
Strict Local Reads
By default, for all read operations, the request goes to the Client Cache (L1). If the requested data is not found, the request then goes to the clustered cache (L2). However, if the data is not available in the Client Cache and you don't want the read operation to fall back to the clustered cache, you can use the Strict Local Reads feature. Using this, any key not found in the Full-Data Client Cache (L1) will result in a cache miss, with no attempt to fetch the data from the clustered cache (L2). This behavior ensures that all read operations are served strictly from the local cache only. You can enable this by selecting "Return a cache miss for any key not found in the client cache, with no fallback to the clustered cache" checkbox through the NCache Management Center. Hence, read operations rely solely on the client cache, thus, allowing for strict local reads.
Strict Query Enforcement
In the case of queries, these are executed on the Client Cache first, and will fall back to the clustered cache only if the data is partially loaded in the Client Cache. However, if you dont want queries to execute on the clustered cache, you can enable the Strict Query Enforcement feature. With this setting enabled, queries will execute only if the full dataset is present in the Client Cache. If the data is partially loaded, the query will fail immediately and throw the exception, "Unable to execute query on client cache as the type '{queryFQN}' is partially loaded." You can enable this by selecting the checkbox "Throw an exception when querying a partially loaded dataset in the client cache, with no fallback to the clustered cache" through the NCache Management Center.
Important
Strict Local Reads and Strict Query Enforcement only apply to reference data types that are configured in the Full-Data Client Cache.
Additionally, if a user attempts to execute a query on the Full-Data Client Cache while it is in a syncing state, such as during cache loading or resyncing, the operation will fail. In this case, NCache will throw the following exception: "Unable to execute query on client cache. Client Cache is still in syncing state."
Client Cache: Plug & Play
Using the Client Cache is quite simple. No code changes are required at the application end. It is a simple configuration. As such, you can create a Client Cache through the NCache Management Center or the NCache supported PowerShell cmdlets. Once the Client Cache has been configured, the client applications will automatically start using it. For already running applications, an application restart is required.
Other Client Cache instances are updated through a background data synchronization mechanism, which is explained later.
Note
In Full-Data Client Cache, only the data corresponding to the configured reference data types will be added to the Client Cache and made available to the application.
The Regular Client Cache holds only a subset of clustered cache data. Therefore, all the other non-key-based operations like GetGroup, SQL queries, and GetByTags, etc, are directly performed on the clustered cache. However, in Full-Data Client Cache, the Client Cache contains the complete configured reference data types, allowing the user to execute the query directly on the Client Cache.
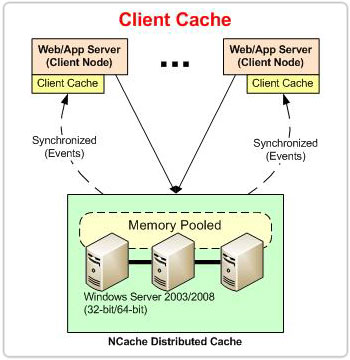
Client Cache: Isolation Modes
Client Cache runs on the client node where your applications are running. Depending on your performance needs and the application architecture, you can choose one of the following process-level isolation modes supported by the Client Cache.
InProc Isolation Mode (In-Process)
As the name suggests, the Client Cache runs inside the application process, eliminating inter-process communication. User data is kept in object form to avoid the deserialization cost. This mode provides maximum performance to the application. As the Client Cache is hosted inside the application process, the data inside the Client Cache is not shared among other application instances. Each instance of the application hosts a dedicated Client Cache instance. Although InProc mode provides maximum process, it is suitable only if:
The application hot dataset is not too large.
The application only has a few instances on each client node with enough physical memory. Remember that each Client Cache instance holds its copy of data.
The application life cycle is long enough to reap the benefits of the Client Cache. Remember that the Client Cache life cycle depends on the life cycle of the application. When the application goes down, all data inside the Client Cache is lost as well. Applications with short life cycles would shut down or restart before the Client Cache is entirely populated.
Each application has its own hot dataset, which is different from other applications.
OutProc Isolation Mode (Out-of-Process)
This mode provides process-level isolation for the Client Cache. The Client Cache runs in its dedicated process on the client node. Applications communicate with the Client Cache over TCP sockets. Multiple application instances can communicate with the same Client Cache, hence, sharing data. Although InProc outperforms OutProc mode in performance, OutProc mode comes with its own set of advantages.
Multiple applications running on the same client machine communicate with the same Client Cache. Multiple applications share data. Data loaded or updated by one application becomes available for other applications.
Application restart does not result in Client Cache data loss.
Fewer physical resources like RAM and CPU are required to run the Client Cache in OutProc mode as compared to InProc mode when each application process holds its copy of the Client Cache.
Synchronization of Client Cache data (explained in the following paragraphs) with clustered cache puts less burden on the clustered cache since you run a single Client Cache instance per client machine.
Note
If the OutProc Client Cache is down, the application will directly perform operations on the clustered cache. When the Client Cache starts again, it will automatically connect with the Client Cache. You can change this behavior by setting the skip-if-unavailable flag in client.ncconf. If the flag is set to false, cache operations will fail if the Client Cache is down.
Synchronizing Data With clustered cache
Given that the Client Cache holds a copy of clustered cache data, changes made to the data in a clustered cache should be propagated to the Client Cache. Multiple Client Caches running with either InProc or OutProc mode may exist for a given clustered cache. Data changes made by the client application are performed on the Client Cache instance to which the application is connected. Therefore, this instance of the Client Cache is automatically synchronized. However, other instances of the Client Cache are unaware of these changes. The changes made to clustered cache data are synchronized with these Client Cache instances through a background data synchronization mechanism explained below for both Regular and Full-data Client Cache:
If a Client Cache is started, the Full-Data Client Cache performs an initial loading process to synchronize with the Clustered Cache. It loads all data associated with its configured reference data types to ensure the cache is fully populated and synchronized. In the case of a Regular Client Cache, there is no initial loading. It is populated only when the client requests data that is not already present in the Client Cache, causing the data to be fetched from the clustered cache.
When data is added to the Client Cache, it registers a data change notification with the clustered cache for the given data.
The clustered cache keeps a track of each
CacheItemthat a Client Cache holds and monitors the changes made to the data.When data is updated/removed from the clustered cache, the clustered cache records these changes.
A dedicated background worker thread inspects the data changes every second and determines which Client Caches contain the affected keys. It then sends a notification to all such Client Caches to inform that the data has been changed.
Another dedicated background worker thread running in the Client Cache is responsible for synchronizing data changes with the clustered cache upon receiving the data change notification. As soon it receives the notification, it requests the clustered cache and asks for data updates. We call this synchronization mechanism Client Cache polling.
This worker thread polls for the data change after every 10 seconds. If it has not received any notification from the clustered cache.
When eviction triggers on any of the specified reference data types (on cache-full) in Full-Data Client Cache, it will not remain synchronized with the clustered cache. To keep itself synchronized with clustered cache, the Client Cache will fetch the data of that specific data type from the clustered cache, after attaining the Data Reload Threshold (the percentage of the total cache size at which the system attempts to reload the evicted data).
If a Full-Data Client Cache restarts, it automatically synchronizes itself with the clustered cache to maintain consistency. This synchronization involves reloading data from the clustered cache based on the configured reference data types. However, for a Regular Client Cache, data is not persisted across restarts, and no automatic synchronization with the clustered cache occurs.
In Regular Client Cache, synchronization is key-based. Only the data against the keys present in the Client Cache is synchronized with the clustered cache.
In Full-Data Client Cache, synchronization is based on data against the configured reference data types.
Note
The reference data type will be evicted and resynchronized/reloaded as per the priority of the reference data type.
- With Full-Data Client Cache, if the clustered cache restarts, the Client Cache will clear itself to maintain data integrity.
This powerful synchronization mechanism ensures that the client applications are always served with the latest data from the Client Cache with enhanced performance and scalability.
Client Cache Synchronization Modes
Along with the background data synchronization mechanism, the Client Cache supports the following synchronization mode.
Optimistic Synchronization
This is the default synchronization mode of the Client Cache. When an application fetches data from the Client Cache and the Client Cache holds that data, data is simply returned to the application. Synchronization is performed in the background, as explained above.
See Also
Cache Topologies
Dynamic Clustering
Local Cache
Cache Client
Bridge for WAN Replication