SDD 2017 London
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
If you are growing data transaction volume, session volume or object size, this talk is for you. Learn how to boost app performance using a distributed cache between your apps and your database. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
Overview
Hello everybody, my name is Iqbal Khan. I'm a Technology Evangelist at Alachisoft. We are the makers of NCache. How many people have heard of NCache before? Good, good number. Today's topic is scaling .NET applications with distributed caching. It is not about NCache, it's about overall the scalability problem that .NET applications face and how to resolve this problem.
I prefer a more interactive discussion. So, instead of waiting until the end to ask questions, please raise your hand if you have a question as I'm talking. I'm going to go through a combination of architectural and then actual code and also I'll show you NCache as an example of what a cache looks like.
What is Scalability?
So, let's get a few definitions out of the way. I'm sure most of you know this already but what is scalability? Scalability is not application performance. It is application performance under peak loads .So, if you have an application that performs super-fast with 5 users, it's not necessarily scalable unless it performs super-fast with 5,000 or 50,000 or 500,000 users. Of course if your application doesn't perform fast with 5 users then you have other problems than scalability.
Linear Scalability vs. Non-Linear Scalability
Linear scalability is more of a deployment architecture. Is your application architected in such a way that you can keep adding more servers in a load balanced environment and then as you add more servers you increase the transaction capacity. By the way when I use the word scalability, I mean transaction scalability not the data of scalability. We are not talking about huge amounts of data. We're not talking about terabytes or petabytes of data. We're talking about a lot of activity. So, if your application is architected in a way where you can add more servers and as you add more servers your capacity increases in a linear fashion then you are linearly scalable.
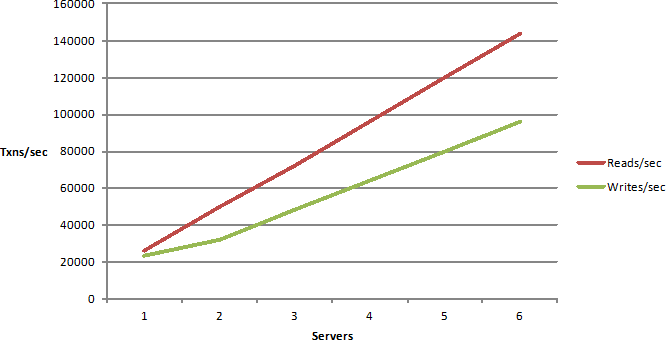
If not, then you have more of a logarithmic curve, for those of you who still remember their calculus from college and the problem with this curve is that you will see an increase, but after a certain point adding more servers actually has no benefit, actually drops the performance down because there are some bottlenecks in your application that just won't go away. So, you definitely don't want to be nonlinear.
Which Applications Need Scalability?
So, which applications need scalability? These are usually Server Applications of course. Web Applications, ASP.NET, now ASP.NET Core also. Web Services. Again you can do it either through WCF. You could do it ASP.NET web API or ASP.NET Core web API. And, that is, the web services are usually the backend for Internet of Things which is a pretty fast emerging space these days.
These are also big data processing applications. So, if you have a lot of data, so that's where the data part of scalability comes but even there it's not about the data it's about how fast can you process it. So, if you have a big data processing application it needs to scale. Most of the big data processing applications are generally not in .NET. They're more on the Java side and my focus is more on the .NET application. But, conceptually speaking the big data processing applications are also something that needs scalability.
And, finally any other server applications. You may be a financial institution, you may be a large bank, you have millions of customers, they call, change their address, issue a new card, or whatever and you need to process, maybe they want to transfer funds and you need to process all those requests within a certain time frame for compliance purposes. So, you have a lot of these back-end batch processes going on and they need to process more and more transactions within that very small amount of time, small in terms of just a few hours that you get every night. So, any server application. So, if you have any of these application and they need scalability then you're in the right place, today.
The Scalability Problem
So, what is the scalability problem? Well, the application tier is not the problem. In most of these applications that I mentioned the application tier seems to work perfectly fine. You can add more servers. You have usually a load balanced environment. If you have a let's say an ASP.NET application you'll have a load balancer on the top and you'll have a group of servers that the load balancer sends the traffic to and as you need more traffic, as you need to handle more users you just add more servers. So, it's very simple.
But the problem is that your database is whether that is relational or that's mainframe data they become the bottleneck. And, relational does not mean any one specific database. It could be SQL server, it could be Oracle, MySQL, Db2, any of these. All relational databases have this inherent weakness that they cannot scale. So, that's exactly why NoSQL movement started and in fact we even have a product on the .NET space called NosDB which is an open source NoSQL database but, the NoSQL databases are not always the answer. I mean they definitely solve the scalability problem. Technically speaking if you use a NoSQL database you will not have scalability bottlenecks. But, the problem is for a combination of technical and business reasons you cannot move all of your data outside of the relational or the legacy mainframe into NoSQL.
So, the NoSQL is more of some of the what we call the new data, you know. The traditional business data still resides in relational databases for a variety of reasons. So, what that means is you have to solve this problem while living with relational databases. You cannot say I'm just going to remove relational database from my picture. In fact even none of our customers move completely into a NoSQL. They move some of the data into NoSQL. Even bigger players like MongoDB, they have the same story that the people who move to NoSQL database move some of the data to NoSQL and they still keep the traditional data in the relational database.
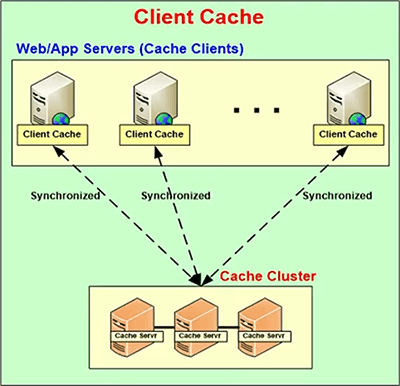
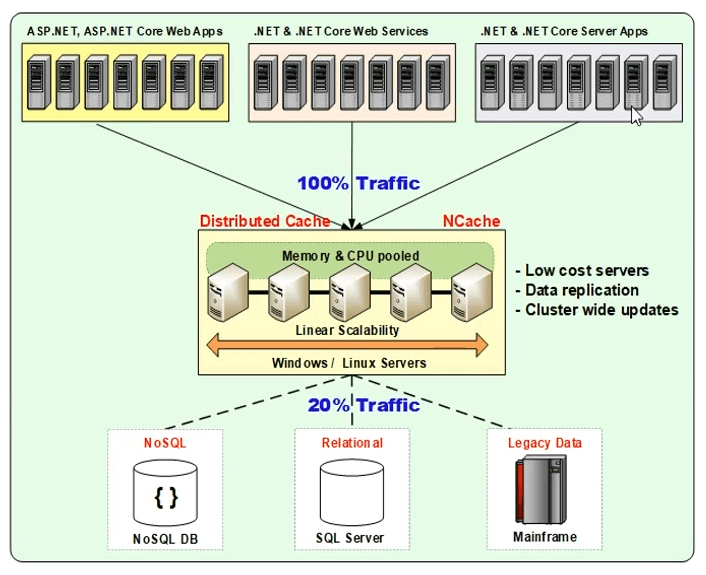
Distributed Cache Deployment (NCache)
So, you need to solve the problem with relational databases in the picture and that's where a distributed cache comes in. It actually gives you the same benefit often NoSQL database. It's actually, if you think about it, it's a NoSQL in-memory key value store. So, you know, if you've looked into NoSQL databases, there's the JSON document database, there's the key value store and there's the graph database and there's the other types. So, the key value store, if it's an ... The only thing that a distribute cache is that it doesn't do persistence, it's all in memory. It’s the key value store. And, it's distributed across multiple servers, so it gives you that same benefit, it scales because you can add more servers. So, think of this as the application tier up here. Right here is the application tier and then usually a load balancer up here somewhere. And, as you add more servers in this tier, the database is going to become more and more under stress unless you put a caching tier in between.
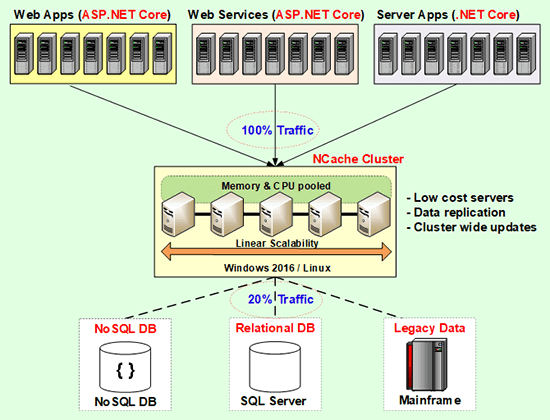
The caching tier scales just like the application tier. It has no bottlenecks, because, you just keep adding more and more boxes. The data is distributed across multiple servers. These are low cost servers by the way. These are not high end database type of servers. In fact our customers… The typical configuration is about 16 gig of RAM, about 8 core box, like a typical web server box but just more memory. 16 gig, 16 to 32 gig, we don't even recommend going more than 32. In fact 64 gig is pretty much the max that we will recommend to our customers. We'll say, add more servers. Why is that? Because, if you increase the memory too much .NET has this thing called garbage collection. And, garbage collection takes a lot of processing power. So, the more memory you have, the more garbage collection it needs to do and the faster your CPU has to become and then your cache is not becoming more and more like a database and it's becoming more expensive and the whole thing. So, it's better to have more servers then to have a few high-end servers.
So, a distributed cache essentially forms a cluster of servers. This is usually a TCP-based cluster and that cluster means that every server in the cluster knows about each other and they pool the resources together into one logical capacity. By having the cluster means that when you need to increase the capacity, you just add another server to the cluster. Or, when you need to decrease the capacity, you drop a server. And, when you have this caching tier, it's an in-memory store because you don't need to persist data. It's not a permanent store. The permanent store still is the data base and because it's an in-memory store it needs to provide data replication also.
The goal in this whole picture is to essentially go to the cache about 80% of the time. So, if you could just imagine, if you went to the cache 80% of the time your database will be totally stress-free, you know. You could really increase the scalability quite a bit.
Question: Does application still not have to talk too much to database?
It doesn't, actually. So, it depends on the data. But, most application data falls between the category of either reference data or transactional data that does not change every few seconds. It changes maybe every few minutes. So, for all of that data, you do a lot more reads than you do writes. So, the first read goes to the database and even that there are features like NCache has a feature where you can preload the cache with data. So, you can warm up the cache with all the data that you think you're going to have and then even that traffic is not being hit, the database is not being hit. But, it depends on the data. For example, if you have other type of data, let's say, if you were to store sessions in it, then for every one read there's one write. So, it depends and I'll go over those details but that's a good question.
Well, the reason you wouldn't be, because the cache loads the data and keeps it in the cache. So, the traffic between the cache and the database is very infrequent. Again as I said 80 % of the time the reads are done and the cache has the data. So, when you cache it you're caching it for a certain amount of time and for that duration the cache is not going to the database every time. But, the application is coming every time to the cache. So, even though you have a lot of traffic, it's all coming to the cache and suddenly the database is very light.
Actually, there's partitioning for each box is storing different data and there's also some redundancy built in for reliability but I'll go into that in more detail.
So, this picture (Fig-1) is meant to kind of convince you that in today's high scalability environment distributed cache is sort of like the de-facto best practice. So, if you design your application, keep a cache in mind. It doesn't matter which cache. That's a separate discussion. The first discussion is that you need to design the application in a way that you're going to be going to a distributed cache. If you do that and you can feel confident that when the business needs your application to perform, the application is not going to choke.
And, if you don't plan it ahead of time the really downside of not being able to scale is that this problem happens when the business is really doing well. Imagine if you're an airline and you just ran this weekend promotion to some vacation spot and millions of new users are coming to a website to do flight search and maybe buy tickets. If your website performance started to slow down every click was one minute, you lose customers. And if it goes even worse and your application starts to crash because the database just choked, you lose a lot of business. So, you need to plan ahead. Even though you're not facing that problem today and, again this is not about performance.
Many people think, use cache because it's going to improve performance. It does improve performance but databases are pretty fast these days. If you only have those five users. I haven't heard anybody complain about the database being slow. So, the problem is not performance. The problem is scalability, because, there's only one database server and you can add more servers up in the application tier and then suddenly the database becomes a bottleneck.
Question: Should we use VMs or Physical boxes for cache clusters?
Very good question. I was going to talk about that and I forgot and it's good that you ask. So, these could be physical boxes. We still have customers who have physical boxes but more and more of our customers are moving to VMs and now the new trend is the containers. So, at the minimum you'll have VMs. So, every cache server is a VM. So, you have a minimum of two cache server VMs. As I said 16 to 32 gig each. Of course you don't want to have both the VMS on the same physical box. Because, then you lose that high availability benefit. Because, if that box crashes both the VMS are gone.
One more question. So, the physical data is stored in memory?
In memory. Exactly, exactly. It's all in-memory storage. And, because it's a temporary store, you store it for a few minutes, a few hours, a few days, a few weeks, you know, you don't store it permanently. The permanent store still is the data base. Whatever that is. That could be, as I said, it could be a legacy mainframe it could be relational, it could be NoSQL.
Even with NoSQL database, you should use a distributed cache. Because NoSQL is not as fast as a distributed cache and because we have both the products we know. We do the benchmarks. It's still 10 times faster.
I am not familiar with NoSQL database, so I was just wondering, why it performs better than a relational database?
It scales more because it also distributes across multiple servers. So, just like a distributed cache can have 5, 10, 15, 20 servers, you can do the same with a NoSQL database. You cannot have 20 servers for SQL. You can have maybe 2, for active-passive or active-active but that's about it. You know, you can't really scale. So, it's for scalability reasons.
So, it's either VMs or now containers are becoming more and more popular for management and this could be either on-premises or it could be in the cloud, any environment.
Common Uses of Distributed Cache
So, I hope this picture (Figure-1) kind of convinces you that you guys need to use caching. So, now you are convinced, let's say. The next question that comes is, well how do I use it? Where do I use it, you know? So, there are three common places that you use caching.
App Data Caching
Number one is what I've been talking about up until now, which is the application data, which was this exact picture. You cache data here, so that you don't have to go to the database. The only thing to keep in mind in caching application data is that now the data exists in two places. One is the cache, one is the database. When data exists in two places what could wrong? Synchronization. So, that's such a big issue that most people are afraid to use the cache, for anything other than read-only data. If you ask an average person, have you thought about using the cache or are you doing any caching? People sometimes they'll build these hash tables or some in memory store, they'll only put read-only data. Data that never changes in the entirety of the application or in really very comfortable time frame. Well, the read-only data or the reference data is only 10-15 % of the total data. So, it gives you a lot of benefit sure but the real benefit is if you can cache all data. That means that you really need to be able to handle…
A good distributed cache must handle synchronization. So, it must ensure that the cache is always fresh. So, that you have that confidence in the cache that whatever you're reading from the cache is the latest copy of that data.
And, if you don't have that confidence that you will be restricted to read-only data which pretty much really minimizes or reduces the value of the cache.
ASP.NET Specific Caching
So, the second benefit is the ASP.NET specific caching. I'm not going into ASP.NET Core at this time but I'll kind of touch on that briefly. But, ASP.NET caching, there are three places where you do this and two at least now. If you have the MVC framework then you don't have the View State but, the sessions every ASP.NET application has sessions and the sessions have to be stored somewhere. By default, they're either stored in-memory, which is In-Proc, which is within the worker process of the ASP.NET application or SQL server. The state server is not available in the cloud it is only on-prem and all those have problems. Some have scalability problems. Actually, all have scalability problems. Some also have performance issues. Like SQL database has performance issues also.
So, a very great use case for distributed cache is to just put those sessions in the cache. You know, those sessions are stored … if you store them in SQL they are stored as blobs. And, relational databases are not designed for blob storage. But, NoSQL or key value stores, the value is the blob. So, it fits really really nicely in a distributed cache. Of course you also have to solve … more and more people are going to multi database or multiple datacenters for either disaster recovery or for load balancing, geographical load balancing. So, you need to also solve that issue.
A view state is something that is no longer in ASP.NET but if you are previous - I think ASP.NET 5. If your on to ASP.NET 4 then view state or pre MVC, view state existed. It still exists in majority of the ASP.NET applications that were developed on all that time.
For those of you, who don't know what a view state is, a view state is an encrypted string that is sent by the web server to the browser, only to come back when a post back happens. So, this string could be hundreds of kilobytes and it travels to the browser gets stored in the browser and then comes back. Multiply that by millions of transactions that your application has to process and it has two issues, one it consumes a lot of bandwidth which is not cheap bandwidth is, you have to pay for bandwidth. Second, it slows down the response time because it is a heavy payload that's traveling. So, it's an ideal case for caching that on the server and just send a small key and when it comes back next time, the view state is fetched from the cache and serve to the page. Again, view state is only a matter if you are not using MVC framework and it's definitely not even there in ASP.NET Core because ASP.NET Core is MVC.
ASP.NET output cache is also something which is part of the ASP.NET framework, not in the ASP.NET Core where it pretty much caches the page outputs. So, if your page does not change on the next request why execute it again? So, ASP.NET cache the page, so the next time the request comes with the same parameters, same everything, an output of the last execution will be served to the page.
So, that framework is already there and it's really a good thing to use a distributed cache for it, so that, in a multi-server environment once it gets cached it's available immediately to all the servers. ASP.NET Core has only sessions for caching and there's no view state and there's no output cache. But, there's another thing called it's called response caching. So, ASP.NET Core has sort of standardized now with the overall web applications where the content caching happens outside of the server. So, that's also a good candidate for caching. So, ASP.NET Core has this a response caching middleware concept. So, there's a built-in middleware that you can use and then you can do a third party middleware. Like NCache will provide one pretty soon.
So, anyway, for ASP.NET caching and that's an important thing to keep in mind now is that you're not storing this data in the cache anymore. So, unlike the application data where the data exists in two places, now the data exists only in one place and that's the cache and it's an in-memory cache. So, when in-memory store is your only store what could go wrong? Yes. I mean if that box goes down you’re hosed. Because, memory is volatile. It's not persisted. So, the way to handle that of course is to do replication. To have that data on more than one server. But, again two very different problems to solve. A good distributed cache must do intelligent replication. If you are to confidently store ASP.NET Sessions, for example. Otherwise, what's going to happen? Let's come back to that, you know, airline. I have just gone to that website. I'm going to buy a $5,000 worth of tickets. I did all my flight search, all sorts of combinations and I'm about to… I entered my payment information and about to submit and, suddenly I have sent back to the, you know, the startup page, whatever, because my session is lost. Because when I hit submit it went to the web server, that web server was not there, it crashed and the session was gone. So, definitely not a good picture.
Runtime Data Sharing Through Events
Third use case is a runtime data sharing through events. This is something that a lot of people don't know it's now becoming more and more popular that a distributed cache once you have it in your environment, it's a really powerful platform for data sharing among multiple applications through like a Pub/Sub model or other event-driven data sharing.
For example, you might have multiple applications that need to share data. One application produces something, puts it in the cache, fires off some events, there are subscribers to that event. So, there are other application instances or other applications, a lot of times you have some sort of workflow happening in applications. That something gets done first and then based on that something else gets done. And, in that case there are these subscribers to those events. Those applications will be notified.
Think of now this picture (Figure 1) here. Don't see this as a cache between the application and the database. Think of that as like a message bus and these applications are all connected to the message bus. One application from this server puts data in the cache, fires off an event. Other applications maybe on some of these servers get notified and they will immediately go and consume the data. Very powerful way.
Some people use message queues. For a lot of that message queues have a definite purpose. A distributed cache is not here to replace them completely but a subset of the cases. When all of the data sharing is within that the same datacenter, not a very distributed environment and it's a high traffic environment. A message queue is not scalable, unlike a distributed cache. Because, a message queue does not have a cluster like this. You can't really add more. So, if you had millions of transactions happening and part of that was also message information, message queues cannot handle that load but a cache can.
So, a runtime data sharing is a really powerful way and I'll touch that. Again, in runtime data sharing, the data exists usually only in the cache. Although, a different form of it might exist in the database. Because, it was read from the database, transformed through some other form and then put it in the cache for sharing.
So, some of the features are common across all caches. Some are only NCache on the .NET side but everything that is NCache on the .NET side is not a .NET proprietary feature. Because, you see the same features on the Java side and all the Java caches. So, Java is a lot more advanced or a lot more mature of a market because, Java has been the server-side technology for longer than .NET. So, you see that... On the Java side. On the .NET side you'll see it in some of the caches, not all. For example, AppFabric, I think didn't have it. Redis has some of it not all of it. NCache has a full blown like the Java caches.
So, these are the three use cases. Any questions on this, before I dive deeper into each of them?
Hands-on Demo
Before, I go into any of these, let me first show you what a cache looks like? I'm going to of course use NCache as the example but the purpose is to give you a feel of what a cache really looks like. So for example, I have three VMs in Azure. They are running. Demo1 and demo2 are my cache server VMs. So, I'm going to have a 2 node cache cluster.
Demo client is my application server. So it's a cache client VM.
Create a Clustered Cache
I’m logged into the demo client VM here. I’m going to go ahead and create a clustered cache. In case of NCache, I will use this tool called NCache Manager, which is a graphical tool. I will come here and say, let me first make sure that cache does not exist already. Okay, it doesn't, Okay, I'm going to come here and say create a new clustered cache.
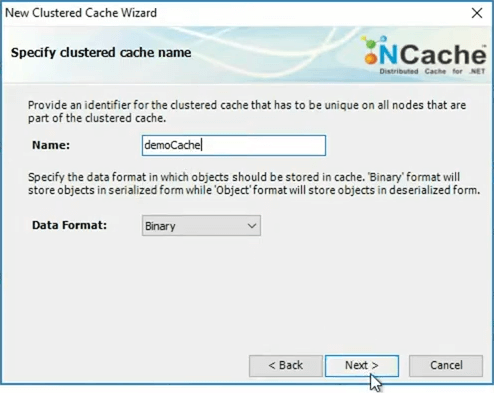
In case of NCache all caches are named. So, my cache is called demoCache. I'm going to just leave all the default. I'm not going to go into the details of this. I'll just keep… I'll talk about only those parts that are important.
The first thing that you'll pick is what we call a caching topology in NCache and this is where the one of you asked the question about partitioning. Is the data really distributed or the same data exists in every server. So, partition replica is a topology that NCache gives you.
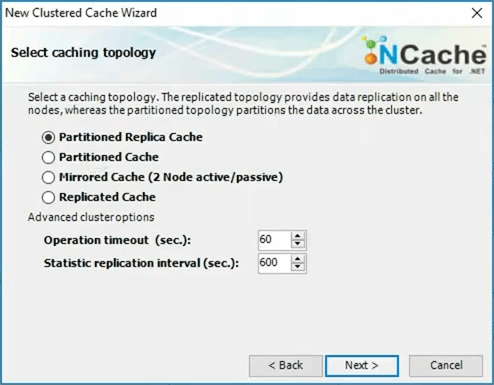
For example, I'm going to quickly jump this and I'll quickly talk about what that topology is? So, a partition replica topology… So, this is a partitioned topology, this is partition replica.
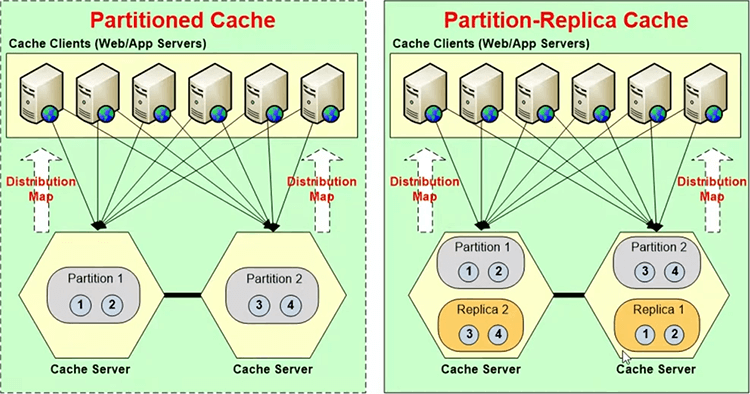
In a partitioning every server has 1nth of the data. So, if you have, let's say, in case of NCache, when you build a clustered cache, it creates one thousand buckets. So, if you have a two server cluster, every server 500. If you have three then every server is one third of thousand.
So, those buckets are essentially just like a hash table buckets. Every bucket is a assigned a key value range. So, there's a hash map function that transforms your keys into hash values and they will fall into whatever buckets they should fall into based on the keys. So, a partitioned replica has one partition on every server. Let’s say, if you were to come here. Let's say, here's a three server cluster, so, the three partitions and every partition has a backup or a replica on a different server.
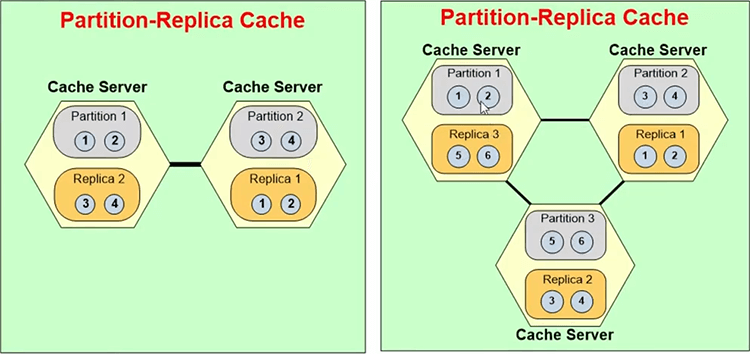
In case of NCache the replica is not active. It is passive. So, only the partition talks to the replicas. The application talks to the partitions. So, let's say every cache client, every application server connects to all the cache servers. It connects and it gets all the cluster membership information. The distribution map is that bucket map. So, it gets the bucket map which tells it where each bucket is? Based on that it knows, okay, if I need to add item number three, I need to go to server 2. Because, that's where partition 2 lives, which is supposed to have key for item number 3. So, it goes straight to that server and it can do that.
And, then if a server goes down, then, let's say, partition 3 goes down, so replica 3 will immediately become active. So, it'll become a partition now. It'll transform from a replica to a partition. Because, you don’t know, you want to continue. The cache has to run, application has to continue. It is high availability, right. So, and then this partition three realizes that there are only two servers, so, it needs to merge itself in these two partitions and sort of go away, vanish. So, it merges itself in the other two partitions and then once that is done then a replicas for partition two is created here.
So, again just to give you overview what that topology means and this is how the distribution happens to ensure that as you add more servers, you have more and more storage and this is also how the replication happens so that every data exists in two servers. So, there's no loss of data if any server goes down.
Again, the theory of high availability says that two servers will not go down simultaneously. The chances of two servers going down simultaneously is astronomically low as compared with any one server going down. Of course, as I said, if two servers are on the same power supply, that power supply goes down, then I'm assuming that everything is redundant. Then two things will not fail at the same time. So, that's why just having two copies is more than enough.
Let’s go back. So, that was the partition replica. Then I will pick an asynchronous replication.
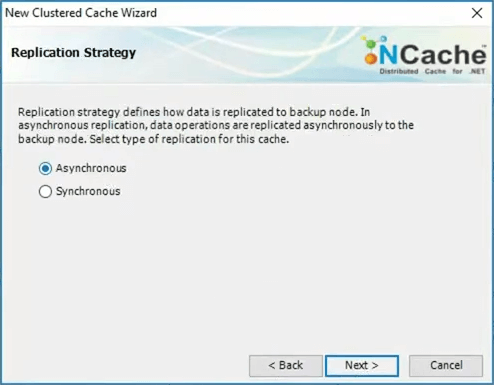
So, there are two modes. Most distributed caches do this thing called eventual consistency. Which means because of distribution, if you had to make immediate synchronization then everything will slow down. But most data you can afford to, sort of queue it up and have an asynchronous updates. So, the async is what will take as a default here.
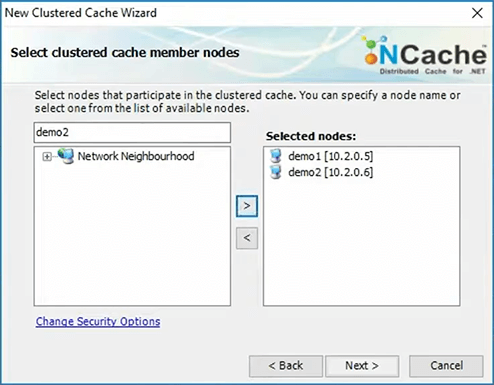
I will pick demo client or demo 1 is the first server. I'll pick demo 2 as a second server.
I'll come here I'll just take the defaults.
I will specify how much memory each server should use.
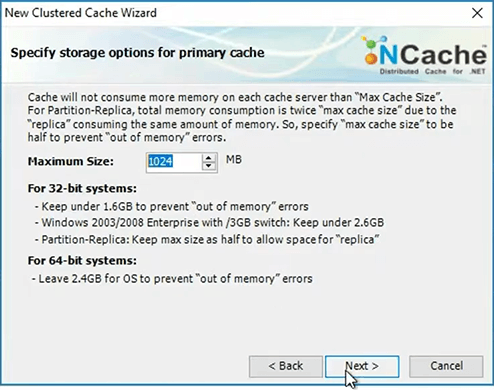
Of course in your case will be a lot more. So, let's say, if you have 16 gig memory in each box you need to allocate some for partition and some for the replica. So, let's say, 2 to 3 gigs should be left for operating system and other processes and about 13 gig is left. So, by 7.5 or 6.5 gigs, one for partition one for replica. And, because you specify that size to make sure that the cache does not consume more than this. Because, it's an in-memory store, memory is always limited and on that box there may be other applications running. So, you want to sort of limit how much memory the cache should use and once the cache has used that memory…
So, then the next page would be. Let's say you've used up all that memory. So, now the cache is full. So, there are only two things can happen. One, it either evicts some of the older data or other or second it rejects the new inserts. So, you have to pick those two. Of course you want to do your capacity planning, where the data that is, if the application data, it's okay to evict because you can always reload it from the database. It's not okay to evict sessions. So, you want to do your capacity planning in a way that these sessions are never evicted. Now you have enough memory, enough RAM and enough servers that you'll always have memory for sessions. And, you want to expire the sessions, not evict theme. Evict means the sessions were still not expired but there's no memory left, so, you're kind of forcibly evicting. Expiry in case of NCache means that you specified that a session is good only for, let's say, 20 minutes of inactivity. After that, the session is to be cleaned up. So, that is expiration. So, expiration is OK, there is no issue but eviction is something that you should not do to the session, it's okay to do them to the application data.
So, what you do in case of NCache, you make a cache for the sessions and make a cache for application data. So, that's how you separate the two. So, let's say I've just created this cache. So, it's a two node cache. I'm going to go ahead and add a client node which is my box the demo client and now I'll just start the cache.
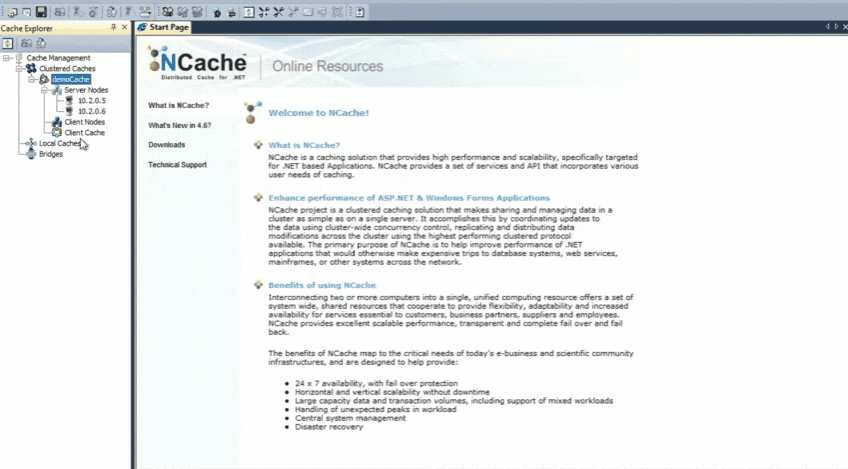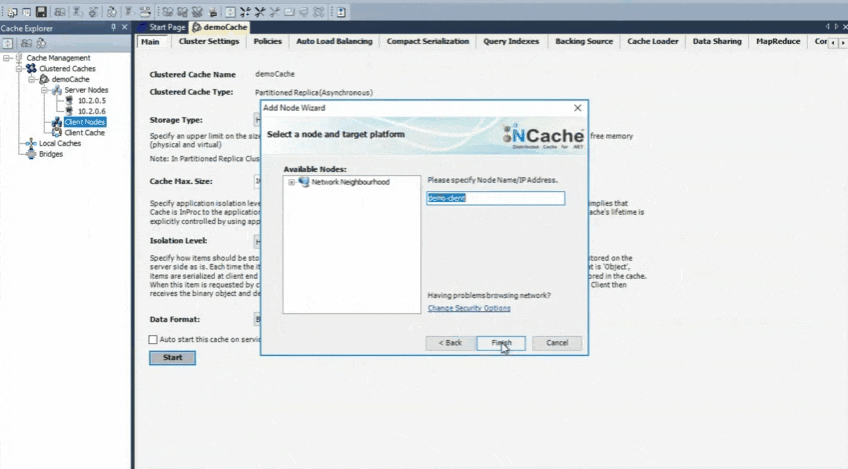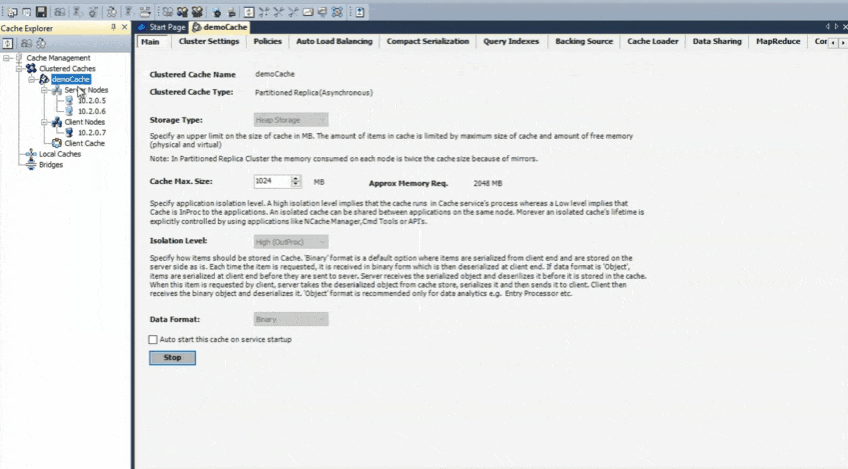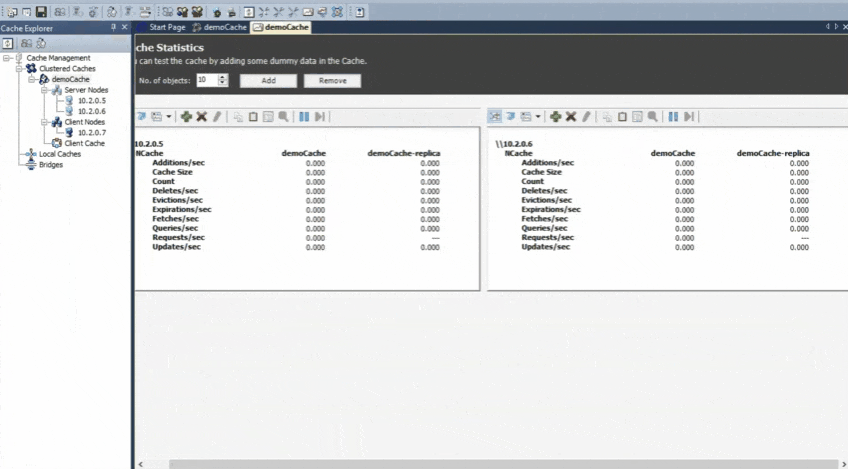
Simulate Stress and Monitor Cache Statistics
So, as you can see, it's pretty straightforward. It's a sort of Explorer style interface. From one place you can go ahead and create multi-server cache, manage it, monitor it and then once you've done that what happens is, let's say, now that it did that I will see some PerfMon counters and I am going to run this tool called stress test tool That comes with NCache, that lets you very quickly kind of simulate the application usage.
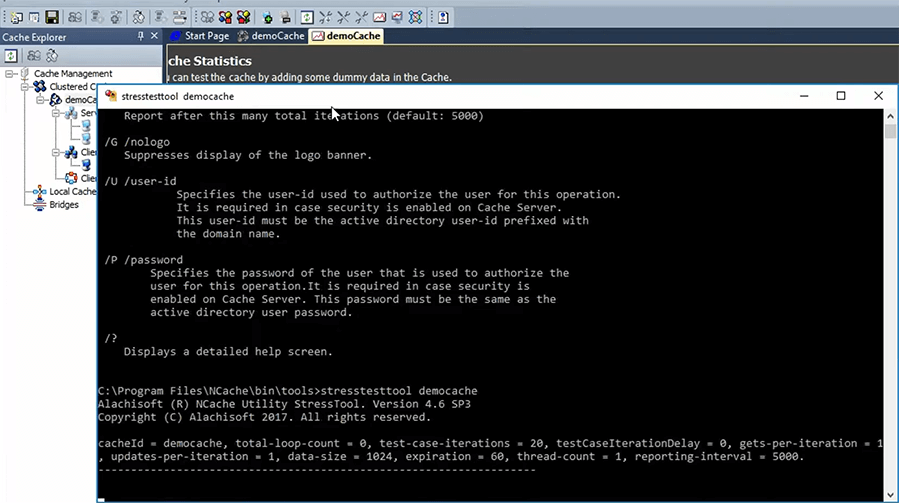
So, let's say I just did that and now it's starting to… So, it's doing about 500 to 800 transactions per server. So, that's about times 2, that's the load. I want to increase the load. So, I want to add one more stress test tool. Our customers use this quite a bit because almost everybody wants to see how the cache performs in their environment. You know, we do have all the benchmarks published and everything, but they want to see it in their environment. So, they instead of programming and application to do it, this can very quickly simulate. So, let's say, I ran two of them and now the load increased. So, I can keep adding more and more of these until I max out these two servers. So, that's where scalability comes.
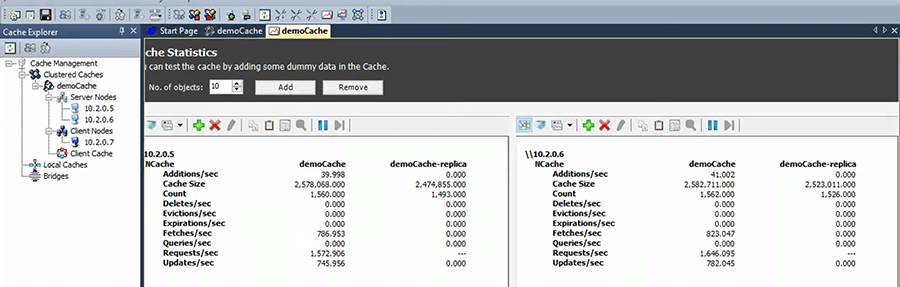
These two servers are performing super-fast right now. But, as I increase the load, after a certain point they'll max out, which is what happens to a database. The only difference is, you can come here and add another node. So, if you had a third VM, you just come here and add that here and as soon as you do that suddenly the load will get distributed and, we have that picture where, you know, where I showed you where you started out with the two server and now this these two got maxed out, you want to add a third one. So, you just get another VM and add it and now it becomes a three server and NCache will automatically readjust everything, we'll repartition or redistribute the bucket map. So that, there's a third server added at runtime. So, suddenly you don't have that capacity issue.
Yeah, so, what you do is you install the NCache server software, on all of these VMs. In case of cloud you usually have a pre-configured VM image that you create the instances off and so you just launch a new VM, it has NCache software running and you just add it to this cluster.
But, again the main point being that unlike a database where once you reach that max out state you’re hosed, you know. What do you do? You know, okay, I want to buy more expensive one. Well then you have to go and buy another box and bring this box down and it's a nightmare. Here you just add another box.
Using NCache with ASP.NET Sessions
So, I'm going to go to that one next now. So, now that we know what a cache looks like. So, now we see that … in case of NCache, all caches are named. So, as long as you know the name of the cache you just connect to the cache. So, how do you connect to the cache for sessions? That's the easiest. Again, most of our customers, the first thing they do with NCache they use it for sessions. Why? Because there's no programming needed. The only thing you have to make sure in case of sessions is that whatever objects you're putting into the session are all serializable. If you are already storing session in SQL then you've already ensured that. If you're storing sessions in In-Proc mode then you might not have ensured it. So, you know, that's the only test you have to do. But, after that it's pretty straightforward.
I'm just going to show you a small sample here. So, for example, there's a sample here called session store provider sample. So, I have an ASP.NET application. I will go to the web.config. Assume that I am on this application server box, you know. If you see that picture here. In fact, let me, go back here. So, here's the cache server right but my application is running on this box. So, on this box, I created two server cluster and I added a client to this, right. So, now what happened on that client is, is that in case of NCache, oops no not here. Okay, in case of NCache it actually creates in the config folder there's a client.ncconf, so it creates an entry. So, that's how the application knows which server to connect to.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<ncache-server connection-retries="3" retry-connection-delay="0" retry-interval="1" command-retries="3" command-retry-interval="0.1" client-request-timeout="90" connection-timeout="5" port="9800" local-server-ip="10.2.0.5" enable-keep-alive="False" keep-alive-interval="0"/>
<cache id="demoCache" client-cache-id="clientCache" client-cache-syncmode="optimistic" skip-client-cache-if-unavailable="True" reconnect-client-cache-interval="10" default-readthru-provider="" default-writethru-provider="" load-balance="False" enable-client-logs="False" log-level="error">
<server name="10.2.0.5"/>
<server name="10.2.0.6"/>
</cache>
</configuration>Again, these are just the initial server list. It's not the final list. Why? Because, for a high availability environment what if you added that third server at runtime? That is not in this list, right? So, let's say, that was dot eight (.0.8), something. So, this is only the initial list. Once the application knows any one of them it connects to that. The first thing that happens to the application, once it connects, it receives the cluster membership information and also whenever that cluster membership changes and you add another server and updated cluster membership is sent to the client and it's all kept in-memory. It's all hidden from your application. It's all managed by the NCache client portion but that's how the application knows how to connect to your cache.
So, in case of sessions, you just come here. So, in the sessions what you do is you have to first add the assembly.
...
<compilation defaultLanguage="c#" debug="true" targetFramework="4.0">
<compilers>
<compiler language="c#" type="Microsoft.CSharp.CSharpCodeProvider, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089" extension=".cs" compilerOptions="/d:DEBUG;TRACE" />
</compilers>
<assemblies>
<add assembly="Alachisoft.NCache.SessionStoreProvider, Version=4.6.0.0, Culture=neutral, PublicKeyToken=CFF5926ED6A53769" /></assemblies>
</compilation>
...In case of NCache you just … this assembly implements the session state provider interface that is part of the ASP.NET framework and by doing that NCache becomes a third party, a custom storage. And so, this is just a copy-paste and then the actual changes in the session state tag. So, what you do here you make sure that the mode is custom.
...
<sessionState cookieless="false" regenerateExpiredSessionId="true" mode="Custom" customProvider="NCacheSessionProvider" timeout="20">
<providers>
<add name="NCacheSessionProvider" type="Alachisoft.NCache.Web.SessionState.NSessionStoreProvider" sessionAppId="WebF1" cacheName="democache" writeExceptionsToEventLog="false" enableLogs="false" />
</providers>
</sessionState>
...So, the modes are, there is In-Proc, the state server, the SQL and there's the custom. So there's four modes that you have. So, if the mode is custom then you want to also make sure that the timeout is whatever you want the session timeout to be and then copy the provider detail. Which is, in case of NCache it's this line and the only thing they got to go and change is the cache name. So, for example, here the cache name is already changed. You make that change, that's all. And, as soon as you make that change, ASP.NET restarts your worker process anyway and you will see that every session will be saved as one object in the cache and you'll immediately see a huge performance boost. Because, now you're not saving them in SQL.
So, the fastest way to benefit from a distributed cache like NCache is to just, put it for sessions. Because, for object for application data caching there's more work. Of course you know, you want to do that to that and that's what I'm going to go into but the first use case is the ASP.NET specification.
Any questions on this? So, what we've seen, for example, some of our higher-end customers have about 50 to 100 servers in the application tier. For that, let's say, keep a 1 to 5 ratio is what usually happen. So for a 100 server configuration they'll have 20 cache servers. More than 50, they're very few, you know, you really have to have a lot of traffic to have more than 50 servers in a load balanced environment. Most customers are anywhere between 4 to 12 servers. And, we recommend having a, as I said, 4 to 1 or 5 to 1 ratio depending on what the nature of the application is. Sometimes, it can even be more than 5 to 1, but I mean this is like the average use case. So, if you have a 5 to 1 and you have 12 servers in the application tier, you have a three server caching tier. So, not that many connections, yeah.
Theoretically, yes. If you keep adding more and more servers you're going to have a lot of redundant. But, the use cases that we're talking about, it doesn't fall. The big data processing could have 50 or 100 servers but there are no clients in that case and a big data processing it's only the server's. Because, everything is running on the server's themselves. But, in case of a web application or web services application what we call the e-commerce, the online business model. I mean that's pretty much. I think you can assume that in most cases you'll have less than 20 servers and very small percentage of the customers will have more than 20 and more than 50 is very small.
Yeah, definitely. So, for example, if I were to come here I'm just going to … if I were to come here. I'm not using the NuGet package here but I could come here and go to the NuGet and I could say here NCache, for example, and you will get an NCache SDK, NCache Session Services for the Enterprise and Professional and there's also an Open-Source, there's also NHibernate. So, there are a bunch of NuGets. So, a typical… for the sessions you'll just include this session NuGet package. For the application data caching you just include the SDK and that'll include everything that you need in this.
App Data Caching Overview (API)
So, application data caching is something where you have to program. So, you see the cache as a database. You connect to the cache. In case of NCache we have this method called InitializeCache.
Cache ConnectionCache cache = NCache.InitializeCache("myCache");
cache.Dispose();Employee employee = (Employee) cache.Get("Employee:1000");
Employee employee = (Employee) cache["Employee:1000"];
bool isPresent = cache.Contains("Employee:1000");cache.Add("Employee:1000", employee);
cache.AddAsync("Employee:1000", employee);
cache.Insert("Employee:1000", employee);
cache.InsertAsync("Employee:1000", employee);
cache["Employee:1000"] = employee;
Employee employee = (Employee) cache.Remove("Employee:1000");
cache.RemoveAsync("Employee:1000");You may have some other methods for other caches and there's a cache name in case of NCache as we talked about and this gives you a cache handle.
So, let's go into an application. Again, we'll just go into … This is a simple console application. What you do is, if you had included the NuGet package then all of this will be done for you. You would reference some NCache assemblies. So, there's only two assemblies that you need to reference, NCache.Runtime and NCache.Web. NCache.Web is the actual public API in case of NCache. Then in your application, you include the namespace. So, you have the NCache.Runtime and NCache.Web.Caching as the namespaces.
Then at the beginning of the application, you get the cache name from the, let say, the App.config and then you do initialize cache and you get a cache handle. So, here's that cache handle that you need to use everywhere in the application.
Now, let's go into that cache handle. So, you can do cache.Add, specify key. Key is as I said, usually a string. Object is your actual object whatever that is. It's any .NET object, NCache will actually serialize it and send it to the cluster. So, all of this is happening on the client side, on the applications server.
// Alachisoft (R) NCache Sample Code.
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Sample.Data;
using Alachisoft.NCache.Web.Caching;
using System;
using System.Configuration;
namespace Alachisoft.NCache.Samples
{
/// <summary>
/// Class that provides the functionality of the sample
/// </summary>
public class BasicOperations
{
private static ICache _cache;
/// <summary>
/// Executing this method will perform all the operations of the sample
/// </summary>
public static void Run()
{
// Initialize cache
InitializeCache();
// Create a simple customer object
Customer customer = CreateNewCustomer();
string key = GetKey(customer);
// Adding item synchronously
AddObjectToCache(key, customer);
// Get the object from cache
customer = GetObjectFromCache(key);
// Modify the object and update in cache
UpdateObjectInCache(key, customer);
// Remove the existing object from cache
RemoveObjectFromCache(key);
// Dispose the cache once done
_cache.Dispose();
}
/// <summary>
/// This method initializes the cache
/// </summary>
private static void InitializeCache()
{
string cache = ConfigurationManager.AppSettings["CacheID"];
if (String.IsNullOrEmpty(cache))
{
Console.WriteLine("The CacheID cannot be null or empty.");
return;
}
// Initialize an instance of the cache to begin performing operations:
_cache = NCache.Web.Caching.NCache.InitializeCache(cache);
// Print output on console
Console.WriteLine(string.Format("\nCache '{0}' is initialized.", cache));
}
/// <summary>
/// This method adds object in the cache using synchronous api
/// </summary>
/// <param name="key"> String key to be added in cache </param>
/// <param name="customer"> Instance of Customer that will be added to cache </param>
private static void AddObjectToCache(string key, Customer customer)
{
TimeSpan expirationInterval = new TimeSpan(0, 1, 0);
Expiration expiration = new Expiration(ExpirationType.Absolute);
expiration.ExpireAfter = expirationInterval;
//Populating cache item
CacheItem item = new CacheItem(customer);
item.Expiration = expiration;
// Adding cacheitem to cache with an absolute expiration of 1 minute
_cache.Add(key, item);
// Print output on console
Console.WriteLine("\nObject is added to cache.");
}And, then once you've done that then you can also do _cache.Get and get that same object back. So, if you were to see that in terms of the API, here is cache.Get, Get, Contains, Add, Insert, Remove and all three have an async version, which basically means that the application doesn't wait for the cache to be updated, the control comes back immediately. But, the key is usually a string. It usually is of something like this. You have the type name. In case of NCache that depends. If you have used this feature called client cache. So, I'm just going to jump into that.
Client Cache (Near Cache)
So, by default you will assume that whenever you do a cache.Get, you're actually going to the caching tier. But, there is an interesting thing that most people don't realize, which is that, if you have been using an In-Proc cache, like ASP.NET cache object and you decided to move to something like NCache because we said it will improve your performance and scalability. Well it's kind of improve scalability but suddenly your performance is actually going to drop we have many customers who call us and say, you know, my application has actually slowed down since I plugged in NCache. So, why do I really need it, you know. It's really not good, it's a-you know. So, then we have to explain to them that when you do an In-Proc cache, there is no serialization, there's no inter process communication between the application and the cache whether that's on the same box or in a separate box, usually it's a separate box, right. So, if the object is kept on your heap in an object form it's super-fast, right. You just go and get a reference. Nothing can match that performance. But, the reason you move to a distributed cache is because that In-Proc model has a lot of limitations. It cannot scale. You cannot add more and more data, it's only one process and if you have more than one process the duplication is not synchronized. So, there are a lot of other issues that's why you move to a distributed cache, but you lose that benefit, right. So, what we did is we came up with this thing called a client cache which on the Java side is called near cache and on the .NET side by the time and cache is the only one that has it.
So, what this does actually, it actually creates an In-Proc local cache within the application. So, it keeps that object in an object form on your heap. So, you get that same performance that you're used to within standalone In-Proc cache. The only difference is that this cache knows that it is part of a clustered cache. So, whatever it's keeping in its local copy, it has a link to the caching tier. It has told the caching tier that, you know, I have this object, please notify me if anybody changes that object. So, if any, let's say, if this client has item number one another client and, of course that item number one is also in this caching tier. Another client comes in and updates that item number one. The caching tier knows that these client caches have item number one, so, they notify that through events, you know. In case of NCache it's pretty fast events. These are not .NET events, these are socket level communication. So, the client cache immediately updates itself. So, we're talking maybe a millisecond delay.
So, that way you are confident that you're, whatever you're getting is all or most of the time it's accurate. There’s technically some small probability that maybe an older copy. In case of NCache, if you're too concerned about that then you can use what we call the pessimistic synchronization mode where every time you fetch anything, you know, NCache internally checks the caching tier see if it has a latest copy. If it doesn't, it gives it from the data from the client cache otherwise it goes and gets it from the cache tier. But, you don't need that for most cases. Most cases you're OK with taking that much chance. So, that gives you the performance boost of the In-Proc cache. But, again your application does not know that all of that is happening.
In case of NCache your application does know. The application thinks it's just talking to the caching tier. There is only one cache that it's talking to. It's called my cache or whatever. It's the demo cache and, the demo cache can have a client cache plugged in through configuration in case of NCache. Any questions on this?
JCache (JSR 107) API
So, I mean this is what a typical cache looks like. It's pretty easy to do this programming. What's happening now on the Java side, as again I keep praising them because they are a lot more advanced on this. They have a whole standard API called JCache. So, the JCache API is a very feature … it has all the features that I just talked about or that I'm talking about. So, JCache is a standard that every Java cache has to implement if they want to be compatible to the industry.
IDistributedCache API
On the .NET side there's no such thing yet. There's an ASP.NET cache object which up until recently was not pluggable. So, if you program to ASP.NET cache you cannot plug in NCache in place of it. So, you can't plug in a third party cache. It’s only a standalone cache. In .NET 4.0 they started a .NET cache which never really picked up. Now in ASP.NET core they have an iDistributedCache interface. Which is again, a very basic just get input methods.
So, the problem with the standard API would be that you will not be able to take advantage of all the features that a good cache should give you. You're really limited to really the basic get input. But again, most of our customers they encapsulate the caching tier anyway. So, even if they're making all the NCache calls, the whole application is not exposed to it. So, anyway here's what the API looks like.
App Data Caching Features
Now, let’s go into a few of the features that are important. So, most of them … go ahead. Just a simple question. Is there difference between insert and add? Yes, insert means add or update. If the data already exists, update it, if it doesn't then add it. Add will fail if the data already exists. And, again that's an ASP.NET cache API that we kind of stuck to, because, we want to be as close to whatever the standard was at time. No, no it's not. I mean, we have kept it. ASP.NET cache object is now gone because now, as I said, in the ASP.NET Core is not there anymore, ASP.NET still has it but ASP.NET Core doesn't.
Absolute Expirations
So, the first thing that you have to keep in mind is the keeping the cache fresh that we talked about, right. How do you do that number one technique is Expirations. Expirations looks something like this, let's go back to this. So, let's say that, I have … Can you guys see this? Can you see this? OK. Let's say, that I have a key and a value or some object. I want to add it to the cache and I will specify a 1-minute expiration. So, this is called the absolute expiration.
public static void AddObjectToCache(string key, Customer customer)
{
DateTime expirationInterval = new DateTime();
expirationInterval.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
_cache.Add(key, customer, expirationInterval, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Console.WriteLine("\nObject is added to cache");
}The absolute expiration means that after 1 minute has passed expire this no matter what. That means I'm saying to the cache, I really don't feel comfortable caching this for more than a minute. Because, I'm making an educated guess that it's safe to keep this in the cache for one minute.
Sliding Expirations
Sliding expiration on the other hand has a totally different purpose. It's for cleanup of things like sessions. It has nothing to do with synchronization or keeping the cache fresh. So, absolute expression is something almost all caches have. In fact, even the ASP.NET Core IDistributed Cache Interface has the absolute expression.
Synchronize Cache with Database
But, what's wrong with expression being the only way of making cache or keeping cache fresh? It’s that you're making a guess that this data is not going to change. What if it does? What if there are other applications, there are other scripts, that are modifying the data which in any Enterprise, there are usually more than one places where the data is being updated from. So, if you cannot predict that how frequently the data is going to be updated, then expressions are only a starting point. You have to go to the next stage, which is synchronize the cache with the database. So, you basically, in synchronizing the cache with the database in case of NCache we use this feature that is part of ADO.NET .NET called SQL dependency.
SQL dependency essentially, let me show you what that looks like. So, in case of a SQL dependency I'm doing that same cache.Add, right. I'll have the key and instead of having the value I'll have a cache item which is our own structure within which we put the actual object and now we have this and then we specify this thing called SQL dependency, SQL server dependency which is this variable which essentially creates the SQL statement.
private static void AddProductToCacheWithDependency(Product product)
{
// Any change to the resultset of the query will cause cache to invalidate the dependent data
string queryText = String.Format("SELECT ProductID, ProductName, QuantityPerUnit, UnitPrice FROM dbo.PRODUCTS WHERE PRODUCTID = {0}", product.Id);
// Let's create SQL depdenency
CacheDependency sqlServerDependency = new SqlCacheDependency(_connectionString, queryText);
CacheItem cacheItem = new CacheItem(product);
cacheItem.Dependency = sqlServerDependency;
// Inserting Loaded product into cache with key: [item:1]
string cacheKey = GenerateCacheKey(product);
_cache.Add(cacheKey, cacheItem);
}This code is running on the client box, right here.
It talks to the cache server. It tells the cache server to use the ADO.NET SQL dependency feature to connect to my database. So, it actually gives me a connection string to the database. So, now the application is telling the cache, here's my database for this cached item here's the SQL statement that represents the corresponding data in the database.
Entity Framework/ Entity Framework Core Integration
Good question. In case of Entity Framework the implementation that we have for Entity Framework we've implemented this inside. We even with Entity Framework there are two ways to use a cache. Either you, in case of EF Core now the new architecture allows the third party cache to plug in but up until EF6, there was no way to plug in a cache. So, you would have to make these API calls anyway. So, let's say, you got a collection of entities back and as you caching them you can specify the SQL dependency. Did you understand what I meant?
In case of NCache you're telling NCache here's my SQL statement. NCache we'll use ADO .NET to connect to your database and use the ADO.NET SQL dependency feature to then monitor that dataset. So, NCache is telling SQL server, please notify me if this dataset changes. Then SQL server sends a database notification to NCache because NCache is not a client of the database and then NCache now knows that this data has changed in the database. So, even though you had EF, it's sort of bypassing that and now that NCache knows that this data has changed NCache has two options. One it can either remove that item from the cache and when you remove it, you know, next time anybody needs it will they'll not find it in the cache, so, they'll have to go and get it from the database. So, in a way you're making it fresh or NCache can reload that data from the database itself for you and that is not possible unless you use another feature called read-through, I'll come to that.
So, the SQL dependency basically ensures that if you cannot predict when the data might change you just tell NCache or your cache please monitor the database for me.
SQL dependency has a limitation that you can't have joins in them. So, it's a single table thing. There are other ways that you can monitor. For example, in case of NCache there's a feature called Custom Dependency, which is your code. NCache calls your code and says please go and monitor your data source and see if data has changed. So, that's kind of like polling. So, NCache will poll through your custom dependency and then it could be a complex structure.
Yeah, exactly. Actually, when you do the SQL dependency the cache is not talking to the database as frequently, because it only … So, the database is the one that initiates the communication because there's an event. It's an event-driven architecture. So, the database sends an event whenever the data changes.
Actually the SQL server has this feature where it monitors the data set and it then fires database notifications to the clients. So, NCache becomes a database client.
So, one option was to remove that item from the cache. The other is to just reload it. Well, reloading means the NCache has to have a way to know how to go and get that data and that means there's this feature called read-through which is your code that you write and register with the cache server, the cache cluster. I'll quickly show you what that code looks like.
Read-Through Cache
No, actually it is just your custom code. So, even you can make the ORM calls within that code also. So, all that code looks like is this. So, there's an IReadThruProvider interface, right here.
...
// Perform tasks like allocating resources or acquiring connections
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect(connString == null ? "" : connString.ToString());
}
// Perform tasks associated with freeing, releasing, or resetting resources.
public void Dispose()
{
sqlDatasource.DisConnect();
}
// Responsible for loading an object from the external data source.
public ProviderCacheItem LoadFromSource (string key)
{
ProviderCacheItem cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncOptions.ResyncOnExpiration = true;
// Resync provider name will be picked from default provider.
return cacheItem;
}
...So, there's IReadThruProvider interface. It has three methods. There's an Init which is called only when the cache starts. So, it is supposed to connect to your data source. There's a dispose which is at the end and there's a load. So, load gives you a key and you're supposed to give back a cache item.
So, based on that key your code needs to know where to go because it has already connected to your data source. So, whether you use it ORM, whether you make EF calls NHibernate calls, ADO.NET calls, that's all your code and then you will go and load that, let's say, you'll go and load that object from the database and you put it in and you put expirations or whatever other metadata you want with it and you pass it back NCache. NCache will then cache it, before giving it back to the application.
So, the whole purpose of read-through … let me just come to this read-through itself. Read-through is a way for the cache to be able to load data from your database. So, you're actually moving some of your persistence code to the caching tier. And, if you have multiple applications wanting to share a cache it's perfect to have read-through, write-through mechanism. Because you consolidating, you're making the applications, sort of less code, you know. So, they'll have less code because more and more of persistence code is going to the caching tier. That's one benefit. You know, encapsulation and consolidation.
The second benefit of read-through is what we just talked about reload. So, reload happens in two cases. One in database synchronization, the other in expiration. Expiration is also a great case if you have a really high traffic application that, let's say, you have some sort of a lookup table or pricing table that changes and you have thousands of requests coming in to that, if you don't have the reload feature then when the data expires thousands of those requests will go and hit the database. And, they'll all load the same object into the cache. Which is finally just a lot of traffic to the database. You multiply that by thousands of items that you might have your database will see a lot of unnecessary traffic.
In fact one of our customers is a really high-end E-Commerce customers in the flowers business in the US, had that problem. So, when they implemented the reload feature suddenly that whole problem went away because now that item is never removed from the cache. So, the old copies kept until a certain point and the new copy is updated on top of it. So, the application never has to go to the database. So, because even on exploration it just updates the new copy. So, it's a lot of … So, those are the two benefits will read-through that you can combine with this synchronization.
Write-Through Cache
The other aspect is the write-through, which works just like the read-through except is for writing and a writing could either be add, insert or delete or remove. Again, the same way you have Init, you have Dispose and now you have WriteToDataSource. It says what the operation is and also has the data and you go and update the database. So, write-through means you update the cache, cache updates the database.
So, what's the benefit of write- through? Well, one benefit is the same as read-through. You consolidate all the persistence. Second, benefit is the write-behind. Because, the database updates are not as fast as the, you know, and if you trust that the database update will succeed, just update the cache and let the cache update the database asynchronously. Of course you can be notified if something fails but you can move on and do other stuff and that also improves the update performance of your application. So, now you don't have to wait for the database updates to be completed because they're all queued up. So, that's the write-behind part. And, the write-behind queue is again replicated to more than one server. So, if any one server goes down none of your operations are lost, in case of NCache.
But that's your code. I mean NCache calls yours. So, all of this is your code. So, NCache calls you and you figure out what the write means or what the read means.
So, read-through, write-through is another very powerful feature that you can combine with expiration and synchronization. So, you need to make sure that the cache stays fresh and then you need to make sure that you use the read-through, write-through. Now that you start to do that, you're able to cache a lot of data. And, now that cache is starting to look like the database. That means you can't really get, you know, key is not enough now. You need to be able to do searching. You need to be able to fetch things in a more intelligent fashion. So, that’s where you should be able to do SQL type of queries on to the cache. For example, something like select customers, where customer dot City equals London. It gives you a collection of all the customer objects back that matches that criteria. And, the cache indexes those objects based on, let's say, the city attribute. So, that's how it allows you to search.
So, if you're not able to do this then your application becomes more complex because you're only able to search things on keys and, you know, you're used to doing a lot of other stuff with the database that you cannot do with the cache.
There are no joins in a cache but you can do groupings. And, that kind of serve that purpose that you can get data and then kind of group it and then based on that groups you can say give me everything that belongs to these groups, subgroups, tags, name tags. So, there are other things that you can do to logically group things and the data itself that you are caching can come through joins. It's just that the cache cannot be … the cache is not search base engine. So, if you have join data, you just group it.
Cache Dependencies
So, there's a feature and again because there's so much of this that I can't really cover in this time. So, there's a feature called cache dependency which comes from the ASP.NET cache object by the way, NCache has also implemented which allows … You tell the cache this item depends on this item. If this item is ever updated or removed, this one is automatically removed. So, by creating those relationships you can have that one-to-many, let's say, if you had a one-to-many relationship where the many side cannot exist without the one side. Let's say, it's a customer and an order. So, if you remove the customer you want to also remove the order. So, you can let the cache handle that for you. Similarly, when you cache, let's say, you got a collection of objects, you can either cache the entire collection as one object or you can break them up into an individual. If you break them up, then you want to do the cache dependencies. So, if any one object is removed then that collection is no longer valid.
Yeah, so, that's a whole topic on which I have a talk, that you can come to our website. Let me just quickly show you. So, there is a whole talk on that. I think, it’s Handling Relational Data in a Cache. So, that goes over all of the one-to-many, one-to-one, many-to-many, that goes over collections that all that stuff that you just talked about. Just go and take a look at that. I'm just going to quickly go through because we don't have time left.
So, I sort of tried to make a case on why you should use a cache and how you should use it and maximize the benefit through it. I'm going to skip the runtime data sharing part, I think I've covered enough. You can go to our website and read about it more. I've talked about the client cache, I've talked about the high-availability through partitioning and all of that.
WAN Replication of Distributed Cache
There is also multiple datacenters. You know, you expect your database to be able to handle multiple datacenters, so, why not the cache, you know. So, again, NCache provides you this feature. On the Java side you have caches that do this. On the .NET side NCache is the only one. So, you can have an active-passive or an active-active datacenters and the caches are synchronized. Again, you cannot have a cluster spanning the WAN, because the performance just dies. You have to do an asynchronous replication or synchronization across the WAN because when you have two datacenters they may not be in the same location.
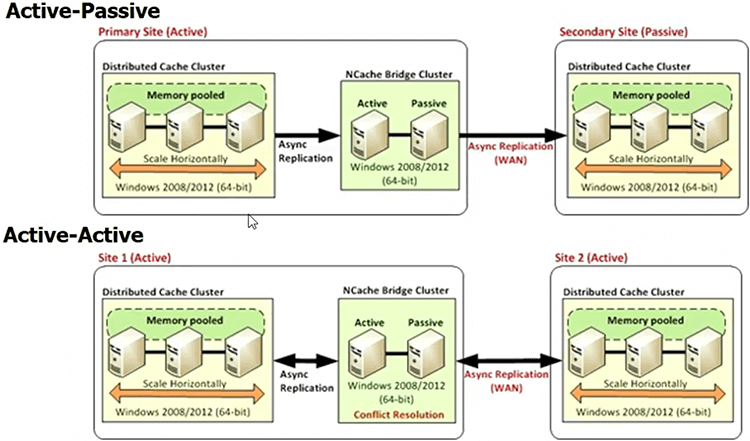
One of our customers is Ryanair which is a big airline here and they have a datacenter in Dublin London and Frankfurt. So, they have to make sure that they can synchronize. In case of NCache we also have WAN replication. There is also a multi datacenter session concept that where the session can move from one datacenter to the other. But, so anyway, so your cache has to be able to support multiple datacenters. So, make sure that you look into that.
NCache vs Redis
Most of the .NET folks know about Redis. NCache, I'm sorry, Microsoft has selected them as their choice for Azure even though Redis comes from a Linux background. I think the main reason Microsoft picked them is because they wanted to have multiple languages. So, Redis covers a lot of languages. NCache is pretty much .NET focused. We also have Java API but NCache itself is .NET focused. I want to do a very quick overview of the two just so that you can see what this means and then you can come to our website and actually there's a like a full-blown comparison. You can do a feature comparison here. And, then you can also download this. So, do take a look at this. It's based on their documentation and ours. So, it's nothing but … there's no spin in this.

NCache is also open source, so is Redis. In case of NCache you have the … you can come to our website and you can download either the Enterprise Edition or the open source or you can also go to GitHub, where is NCache? Right here on GitHub and then you can see NCache here also.
So, this enterprise edition is fully supported. In case of Redis Microsoft ported Redis from Linux to Windows. So, one would think that Microsoft would be using the port in Azure but they're not. So, the port that they have has lots of issues. A lot of customers have complained to us about it.
So, if you use Redis in Azure they use the Linux version it's stable, there's no issue with it, but you lose all the features that we just talked about. If you want to do an on-premises support, NCache will give you the either open source is all free, enterprise is something that you get more features than you pay for the support also. If you want on-prem with Redis, the only options you have is go with the Linux version from Redis labs. They also now have this in docker. So, you can run it technically on Windows but still the Linux environment for them. The on-prem from Windows is from Microsoft, which as I said is unstable and without support.

In Azure Redis gives you a cache service model, NCache gives you a VM model. VM model gives you a lot more control. All this stuff that we just talked about read-through, write-through, cache loader, database synchronization, you get all that control and there's is just a client API.
That's just a quick overview of the two. I wanted to kind of mention. Basically, NCache is the oldest cache in .NET space. We've got tons and tons of customers using NCache. Also a lot of them are in the UK. You know, UK is our second biggest market and if you have a .NET application, I hope you prefer the whole stack to be .NET. NCache gives you that .NET stack, Redis doesn't.
Any questions before I conclude this talk? But then you're exposing the partitioning yourself. Because, in a relational database you have to then kind of program the application in a way that the data resides in one or the other. I mean the whole concept of No SQL is that they do the sharding for you because everything is based on the key. In a relational you have a lot more complexities and so far none of the relational databases have been able to address the scalability issue. They've been trying very hard and they have improved performance tremendously. There’re lot of in memory options, so, they also have in-memory databases and they're do a lot of in-memory tables and stuff. So, performance has improved quite a bit, but performance is not the issue here. You know, it's the issue is the scalability. Can you handle that load and so far they can't.
So, the reason we have the indexing is so that you can search on those attributes. So, you could do a SQL statement and search on those attributes of the object that you were indexed on.
So, what we do is we don't allow you to do a search unless you have the index created. So, if you do a search NCache will throw an exception says, this attribute was not indexed. So, kind of in a more painful way, yes. But, what we tell our customers is, whatever you're trying to search on, you must create an index. And, unlike a database where everything is SQL, here everything is not going through the SQL. Again, you're doing a lot of stuff through just the API and then some of the stuff is through the SQL.
You mean for the cache name? There's a convention that the key should have the type information in it and then based on certain, let's say, if it's an individual object and the type and the either the primary key value or the primary key attribute name and then the value, that's the common thing and then if you are saving the entire collection, let's say, you are saving all other orders for customer and then you may want to fetch it based on the customer, then the key can be customer, customer ID, my orders or something like that, you know. So, the keys have to be meaningful based on how you want to fetch the data.
Yeah, all of those are options that you can choose. If you watch my handling relational data video, I go through all those options. And, again with caching, let's say, you have a many-to-many relationship in the database. There's no many to many at the application level. In the application either you approach from this side or from this side. It’s always one-to-many. So, its things like that that suddenly the perspective changes.
You're not trying to recreate the entire database in memory. Can you recap the benefits of using a distributed cache? You said that it was scalability. Are there other? I think, the most important benefit is scalability. The secondary benefit is performance and again for the use cases, for the ASP.NET specific use cases, the sessions, there's a huge benefit. Because, the alternatives to a distributed cache are all very slow or not scalable. So, if you do an In-Proc, it's not scalable. Because, you have to go to the same process every time.
I'm also recording this and I think so is the SDD Conf. We’ll have this talk up on YouTube and if you come to our booth and let us scan you then we can email you the link to the talk and then you can share this with your colleagues. Thank you very much guys for your patience.