Six Reasons why NCache is Better than Redis
Recorded webinar
By Iqbal Khan
Learn how Redis and NCache compare with each other at feature level. The goal of this webinar is to make your task of comparing the two products easier and faster.
The webinar covers the following:
- Different product functional areas.
- What support do Redis and NCache provide in each feature area?
- What are the strengths of NCache over Redis and vice versa?
NCache is a popular Open Source (Apache 2.0 License) In-Memory distributed cache for .NET. NCache is commonly used for application data caching, ASP.NET Session State storage, and pub/sub style Runtime Data Sharing through events.
Redis is also a popular Open Source (BSD License) in-memory data structure store used as database, cache and message broker. Redis is very popular on Linux but has lately gotten attention on Azure due to Microsoft promoting it.
Overview
Hi everybody, my name is Iqbal Khan and I am a technology evangelist at Alachisoft. Alachisoft is a software company based in San Francisco Bay Area and is the maker of the popular NCache product, which is an open source distributed cache for .NET. Alachisoft is also the maker of NosDB, which is an open source no SQL database for .NET. Today, I'm going to talk about six reasons why NCache is better than Redis for .NET applications. Redis, as you know, is developed by Redis labs and it was picked by Microsoft for Azure. The main reason for picking was that Redis offers multi-platform support and lots of different languages, whereas NCache is purely focused on .NET. So, let's get started.
Distributed Cache
Before I go into the comparisons, let me first give you a brief introduction of what distributed caching is and why do you need it and what problem does it solve. Distributed caching is actually used to help improve your applications scalability. As you know, if you have a web application or web services application or any server application, you can add more servers at the application tier. Usually the application architectures allow that to be done very seamlessly. But, you cannot do the same at the database tier, especially if you're using a relational database or a legacy mainframe data. You can do that for no SQL. But you know, in majority of the cases you have to use relational databases for both technical and business reasons.
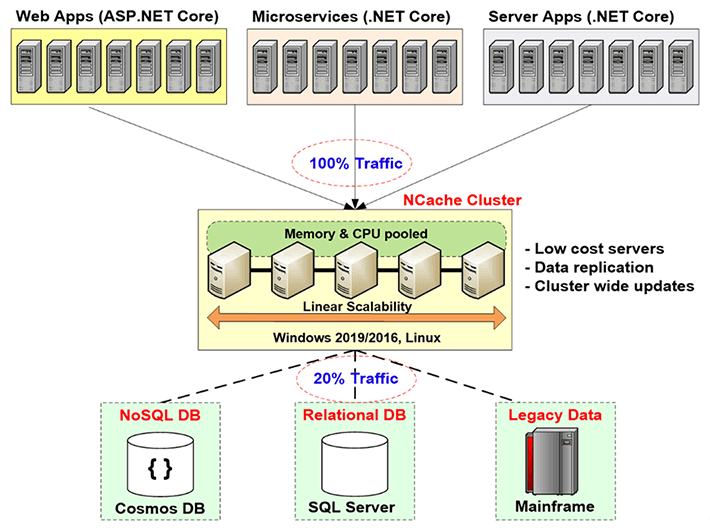
So, you have to solve this scalability bottleneck that relational databases or legacy mainframe give you through distributed caching, and the way you do that is by creating a caching tier in between the application tier and the database. This caching tier consists of two or more servers. These are usually low cost servers. In case of NCache, the typical configuration is a dual CPU, quad-core machine, with 16 to 32 Gig of RAM and one to two network cards, which are 1 to 10 gigabits in speed. These caching servers form a TCP based cluster in case of NCache and to pools the resources of all these servers together into one logical capacity. That way as you grow, the application tier, let's say if you have more and more traffic or more and more transaction load, you can add more servers at the application tier. You can also add more servers at the caching tier. Usually you maintain a 4 to 1 or a 5 to 1 ratio between the application tier and the caching tier.
So, because of this the distributed cache never becomes a bottleneck. So, you can start to cache application data here and reduce traffic to the database. The goal is to have about 80% of your traffic go to the cache and about 20% of the traffic, which is usually your updates, go to the database. And if you do that, then your application never faces a scalability bottleneck.
Common Uses of Distributed Cache
Okay so, keeping that benefit of a distributed caching in mind, let's talk about the different use cases that you know, the different situations in which you can use a distributed cache.
Application Data Caching
Number one is the Application Data Caching, which is the same as what I just explained where you cache data that resides in your database, so that you can improve performance and scalability. The main thing to keep in mind for an application data caching is that your data now exists in two places. It exists in your database which is the master data source and it exists also in the caching tier and when that happens, the most important thing that you need to keep in mind is that, you know, the biggest worry that comes is, you know, is the cache going to become stale? Is the cache going to have an older version of the data, even though the data has changed in the database. If that situation occurs, then of course you have a big problem, and many people because of this fear of data integrity problems, they only cache read-only data. Well, the read-only data is a very small subset of the total data that you should be caching and it's about ten to fifteen percent of the data.
The real benefit lies, if you can start to cache transactional data. This is your customers, your activities, your history, you know, all sorts of the data that gets created at runtime and it changes very frequently, you need to still cache that data but you need to cache it in a way that the cache always stays fresh. So, that's the first use case, and we'll come back to that.
ASP.NET Specific Caching
The second use case is for ASP.NET specific caching, where you cache the session state, the view state and if you don't have the MVC framework and a page output. In this situation you're caching the session state because a cache is a much faster and more scalable store than your database, which is where you would otherwise be caching these sessions or the other options that Microsoft gives and, in this case the data is transient. Transient means it's temporary in nature. It is only needed for a small period of time after which you just throw it away and the data only exists in the cache. The cache is the master store. So, in this use case, the worry is not that the cache needs to be synchronized with the database but instead the worry is that if any cache server goes down you lose some of the data. Because, it's all in-memory storage and memory, as you know, is volatile. So, a good distributed cache must provide intelligent replication strategies. So, that you have every piece of data exists in more than one servers. If any one server goes down, you don't lose any data, but the replication has cost associated, performance cost. So, the replication must be super fast, which is what NCache does, by the way.
Runtime Data Sharing
The third use case is the Runtime Data Sharing use case, where you use the cache as essentially a data sharing platform. So, a lot of different applications are connected to the cache and they can share data in a Pub/Sub model. So, one application produces the data, puts it in the cache, fires an event and other applications that have registered interest in that event will be notified, so, they can go and consume that data. So, there are also other events. There are key based events, the cache level events, there's a continuous query feature that NCache has. So, there are a number of ways that you can use a distributed cache like NCache to share data among different applications. In this case also, even though the data is created from data in the database but the form in which it is being shared may only exist in the cache. So, you must make sure that the cache replicates data. So, the concern is the same as for ASP.NET caching. So, those are the three use cases that are common for a use distributed cache. Please, keep these use cases in mind as I compare the features that NCache provides which Redis does not.
Reason 1 – Keeping Cache Fresh
So, the first reason, why you should use NCache over Redis is that, NCache provides you very powerful features to keep the cache fresh. As we talked about this, if you cannot keep the cache fresh, you are forced to cache read-only data and if your caching read-only data then, you know, that's not the real benefit. So, you need to be able to cache pretty much all your data. Even data that is changing every 10-15 seconds.
Absolute Expirations / Sliding Expirations
So, the first way that you keep the cache fresh is through the expirations. Expiration is something that both NCache and Redis provide. So, for example, there's an absolute expiration where you tell the cache please expire this data after 10 minutes or 2 minutes or 1 minute. After that time, the cache removes that data from the cache and you are making a guess, you're saying, you know, I think it's safe to keep this data in the cache for this long because I don't think it's going to change in the database. So, based on that guess, you're telling the cache to expire the data.
Here's how Expiration looks like. I'm just going to show you something. In case of NCache, when you install NCache by the way, you know, it gives you a bunch of samples. So, one of the samples is called basic operations which I have it opened here. So, in basic operations, let me just quickly also give you, here's what a typical .NET application using NCache looks like.
You link with NCache at runtime NCache.Web assembly then you use the NCache.Runtime namespace, NCache.Web.Caching namespace and then at the beginning of your application, you connect with the cache. All caches are named.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...If you want how to create a cache, please watch our getting started video. That's available on our website. But, let's say that you've connected to this cache, so, you've got a cache handle. Now you create your data, which is some bunch of objects and then you do cache.Add. cache.Add has a key which is a string and the actual value which is your object and then in this case you're specifying an absolute expiration of one minute. So, you're saying expire this object one minute from now and by saying that you're telling NCache to expire this object. So, that's how expiration works which of course, as I said, Redis also provides you.
Synchronize Cache with Database
But, the problem with expiration is you're making a guess which may not be correct, may not be accurate. So, what if the data changes before that one minute before that five minute that you had specified. So, that's where you need this other feature called synchronize the cache with the database. This is the feature that NCache has and Redis does not have.
So, NCache does that in a number of ways. Number first is SQL Dependency. SQL dependency is a feature of SQL server through ADO.NET, where you basically specify a SQL statement and you tell SQL server and say, you know, please monitor this data set and if this data set changes, well it means any row is added, updated or deleted that matches this data set criteria, please notify me. So, the database sends you a database notification and then you can take appropriate action. So, the way NCache does this is, NCache will use the SQL dependency and there's also an Oracle dependency which does the same thing with Oracle. They both work with database events. So, NCache will use the SQL dependency. Let me show you that code here. So, I'm just going to go to the SQL dependency code. Again, same way you link with some of the assemblies. You get the cache handle and now that you're adding stuff I'm just going to go to this, go to definition. So, now that you're adding this data, as part of the adding you specify a SQL dependency. So, Cache dependency is an NCache class that takes a connection string to your database. It takes a SQL statement. So, let's say, in this case you're saying, I want the SQL statement is where the product ID is this ID. So, since you're caching a product object, you're matching it with the corresponding row in the product table. So, you're saying, you're telling NCache to talk to SQL server and use SQL dependency so that SQL server can monitor this statement, and if this data changes SQL server notifies NCache.
So, now the cache server has become a client of your database. So, the cache server has asked your SQL server to please notify me if this data set changes and when that dataset changes SQL server notifies the cache server and the NCache server then removes that item from the cache and the reason it removes it is because once it's removed the next time you need it you will not find it in the cache and you'll be forced to get it from the database. So, that's how you kind of refresh it. There's another way that you can automatically reload the item that I'll talk about in a bit.
So, SQL dependency allows NCache to really synchronize the cache with the database and with Oracle dependency it works exactly the same way, except it works with Oracle instead of SQL server. The SQL dependency is really powerful but it's also chatty. So, let's say, if you have a 10,000 items or a 100,000 items you're going to create a 100,000 SQL dependencies which puts a performance overhead on the SQL server database because for every SQL dependency SQL server database creates a data structure and the server to monitor that data and that's an extra overhead.
So, if you have a lot of data to synchronize, maybe it's better to just to DB dependency. DB dependencies is our own feature where instead of using a SQL statement and database events, NCache actually pulls the database. There's a special table that you create it's called NCache DB sync and then you modify your triggers, so, that you go and update a flag in a row, corresponding to this cached item and then NCache pulls this table every so often, let’s say, every 15 seconds or so by default and then you can, you know, if it finds any row that have been changed, it invalidates the corresponding cached items from the cache. So, both of these and of course DB dependency can work on any database. It's not just SQL server, Oracle but also if you have a DB2 or MySQL or other databases.
So, with the combination of these features allows you to really feel confident that your cache will be always synchronized with the database and that you can cache pretty much any data. There's a third way which is a CLR stored procedure, so that you can actually implement a CLR stored procedure. From there you can make an NCache call. So that, you call the stored procedure from the database trigger. Let's say, you have a customer table and you have an update trigger or delete trigger or even an add trigger actually. In a case of CLR procedure, you can also add new data. So, that's CLR procedure gets called by the trigger and the CLR procedure makes NCache calls and that way you're pretty much you're having the database adding the data or updating the data back into the cache.
So, those three different ways allow NCache to be synchronized with the database and this is a really powerful reason for using NCache over Redis because Redis forces you to only use expirations which is not sufficient. It really makes you vulnerable or it forces you to cache read-only data.
Synchronize Cache with Non-Relational Database
You can also synchronize the cache with non-relational database. So, if you have a legacy database, mainframe, you can have a custom dependency which is your code that runs on the cache server and every so often NCache calls your code to go and monitor your data source and you can maybe make web method calls or do other things to go and monitor the custom data source and that way you can synchronize the cached item with data changes in that custom data source. So, the synchronization of the database is a very powerful reason, why you should use NCache over Redis because now you cache practically all data. Whereas, in case of Redis you'll be forced to cache data that's either read-only or where you can very confidently make guesses about the expirations.
Reason 2 – SQL Searching
Reason number two, okay. Now that you've, let's say, you've started to use synchronization with the database feature and now you can cache practically a lot of data. So, the more data you cache the more the cache starts to look like a database and then if you only have the option of fetching data based on keys which is what Redis does then that's very limiting. So, you need to be able to do other things. So, you need to be able to find data intelligently. NCache gives you a number of ways in which you can group data and find data based on either object attributes or based on groups and subgroups or you can assign tags, name tags. So, all of those are different ways that you can get collections of data back. For example, if you were to issue a SQL query, let me show you that, let's say, I go a SQL query here. So, I want to go and find, let's say, all customers where customer.city is New York. So, I will issue a SQL state, I’ll says select customers, you know, my complete namespace, customer where this.City is question mark and in the value that I'm going to specify New York as a value and when I issue that query, I will get a collection of those customer objects back that match this criteria.
So, this is now looking a lot like a database. So, what this means is that you can actually start to cache data. You can cache it entire data sets, especially look-up tables or other reference data where your application was used to issuing SQL queries against those in the database and the same type of SQL queries you can issue against NCache. The only limitation is it can do joins in case of NCache but a lot of these you don't need to really do the joints. SQL searching makes the cache very friendly to really search and find the data that you're looking for.
Grouping and sub grouping let me show you this the example of grouping. So, for example here you can add a bunch of objects and you can add them all. So, you are adding them as a group. So, this is the key, the value, here's the group name, here is the subgroup name and then you can later on say give me everything that belongs to the Electronics Group. This gives you a collection back and you can iterate over the collection to get your stuff.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}You can also fetch the keys based on the group. You can do other things based on the group also. So, groups and tags work in similar fashion. Name tags are also the same as tags except it's a key value concept. So, let's say, if you're caching freeform text and you really want to get some of the metadata of the text indexed, so you can use key value concept with the name tags and that way once whatever groups tags and name tags you have then you can include those in SQL queries.
You can also issue LINQ queries. If you're more comfortable with LINQ, you can issue LINQ queries. So, in case of LINQ, for example, let's say, here's your NCache. So, you would do an NCache query with a product object. It gives you an IQueryable interface and then you can issue a LINQ query just like you would against any object collection and you're actually searching the cache.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}So, when you run this query, when you execute this query, it is actually going to the caching tier and searching your objects. So, you know, the interface available to you is very simple, in a very friendly fashion but behind the scenes it is actually caching or searching the entire cache cluster. So, the reason number two is that you can search the cache, you can group data through groups and subgroups, tags and named tags and it makes finding data in a friendly fashion possible, which is something that none of these features exist in Redis.
Data indexing is another aspect of this, that when you are going to search based on these attributes, then it's imperative, it's really important that the cache indexes, it creates indices on those attributes. Otherwise, it's an extremely slow process to find those things. So, NCache allows you to create data indexing. For example, every group and subgroup, tags, name tags are automatically index but you can also create indices on your objects. So, you could, for example, create an index on your customer object on the city attribute. So, the city attribute because you know that you are going to search on the city attribute. You say, I want to index that attribute and that way NCache will index it.
Reason 3 – Server Side Code
The reason number three is that with NCache you can actually write server-side code. So, what is that server-side code and why is that so important. Let's look at that. It is read-through, write-through, write-behind and cache loader. So, read-through is essentially your code that you implement and it runs on the cache server. So, actually let me show you what a read-through looks like. So, for example, if you implement an IReadThruProvider interface.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}This interface has three methods. There's an init method which gets called when the cache starts and its purpose is to connect your read-through handler to your data source and there's a method called dispose that gets called when the cache is stopped and that way you can disconnect from your data source and there's a load from source method, which passes you key and it expects an output of a cache item, a provider cache item object. So, now you can use the key to determine which object it is that you need to fetch from your database. So, the key as I said could be customer, customer ID 1000. So, it tells you that the object type is customer, the key is customer ID and the value is 1000. So, if you use formats like that then you can, based on that you can go ahead and come up with your data access code.
So, this read-through handler actually runs on the cache servers. So, you actually deploy this code on all the cache servers. In case of NCache it's pretty seamless. You can do that through an NCache manager tool. So, you deploy that read-through handler to the cache servers and that read-through handler gets called by the cache. Let's say, your application does the cache.Get and that item is not in the cache. NCache calls your read-through handler. Your read-through handler goes to your database, fetches that item, gives it back to NCache. NCache puts it in the cache and then gives it back to the application. So, the application feels like the data is always in the cache. So, even if it's not in the cache, the cache has the ability to now go and get the data from your database. That's the first benefit of read-through.
The second benefit of read-through is that when the expirations happen. Let's say, you had an absolute expiration. You said expire this item 5 minutes from now or 2 hours from now, at that time instead of removing that item from the cache, you can tell NCache to reload that item automatically by calling the read-through handler. And reloading means that item is never removed from the cache. It's only updated and this is really important because a lot of the reference look-up tables, you have a lot of transactions just reading that data and if that data is removed even for a brief period of time, a lot of transactions against the database will be created to fetch that data, simultaneously. So, if you could just update it in the cache then it's much better. So, that's one use case.
The second use case is with database synchronization. So, when the database synchronization happens and that item is being removed, instead of removing it, why not reload it from the database and that's what's NCache will. You can configure NCache, so, that when database synchronization kicks in, the NCache will instead of removing that item from the cache, it'll call your read-through handler to go and reload a new copy of it. Again, in the same way as expiration that item gets never removed. It never gets removed from the cache. So, read-through is a really powerful feature.
Another benefit of read-through is that it simplifies your applications, because you're moving more and more if you persistence code in the caching tier and if you have multiple applications that are accessing the same data, all they have to do is do a cache.Get. A cache.Get is a very simple call then doing a proper ADO.NET type of coding.
So, read-through simplifies your application code. It also makes sure that cache always has the data. It does automatic reload on expirations and database synchronizations.
The next feature is write-through. Write-through works just like read-through, except it's for updating. Let me show you what write-through looks like. So, this was read-through. Let me just go to write through. So, you implement a write-through handler. Again, you have an init method. You have a dispose method, just like read-through but now you have a write to datasource method and you have a bulk write to datasource method. So, this is something that is different from read through.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}So, in case of write-through, you know, you get the object and the operation also and this operation could be an Add, it could be an Update or it could be a Delete, right. Because you could do a cache.Add, cache.Insert, cache.Delete, and all of that will result in a write-through call being made. This can now go and update the data in the database.
Similarly, if you do bulk operation, bulk update, then a bulk update to the database can also be done. So, the write-through has also the same benefits as read-through that it can simplify the application because it's moving more and more of the persistence code into the caching tier.
But, there's also write-behind feature that is a variation of write-through. With the write-behind is basically, you update the cache and the cache then updates your data source asynchronously. Basically, it updates it later. So, your application does not have to wait.
Write-behind really speeds up your application. Because, you know, the database updates are not as fast as cache updates. So, you know, you can use a write-through with a write-behind feature and the cache gets updated immediately. Your application goes back and does its thing and then the write-through is called in a write-behind fashion and it goes and updates the database, and of course if the database update fails, then the application is notified.
So, anytime you have a queue being created, there's a risk that what if that server goes down that queue will be lost. Well, in case of NCache the write-behind queue is also replicated to more than one server and that way if any cache server goes down you're write-behind queue is not lost. So, that's how NCache ensures high availability. So, write-through and write-behind are very powerful features. They simplify the application code and also in case of write-behind they speed up the application because you don't have to wait for the database to be updated.
The third feature is cache loader. There's a lot of data that you would prefer to preload in the cache, so that your applications don't have to go to the database. If you don't have a cache loader feature, now you have to write that code. Well, not only that you have to write that code you also have to run it somewhere as a process. It's the running as a process that really becomes more complicated. So, in the in case of a cache loader, you just register your cache. You implement a cache loader interface, you register your code with NCache, NCache calls your code whenever cache is started, and that way that you can make sure that the cache is always preloaded with that much data.
So, these three features read- through, write-through, write-behind and cached loader, these are very powerful features that only NCache has. Redis does not have any such features. So, in case of Redis you lose all this capability that NCache provides otherwise.
Reason 4 – Client Cache (Near Cache)
Reason number four is Client Cache. Client cache is a very powerful feature. It’s really, it's a local cache that sits at your application server box, but it's not isolated cache. It's local to your application. It can be In-Proc. So, this client cache could be objects kept as on your heap and in case of NCache if you choose the In-Proc option that NCache keeps the data and object form. Not in a serialized form, in the client cache. In the clustered cache it keeps it in a serialized form. But, in the client cache it keeps it in an object form. Why? So, every time you fetch it, you don't have to deserialize it into an object. So, it speeds up the fetches or the gets a lot more.
A client cache is a very powerful feature. It’s a cache on top of a cache. So, one of the things that you lose when you move from a standalone In-Proc cache to a distributed cache is that in a distributed cache the cache is keeping the data in a separate process, even on a separate server and there's a inter process communication going on, there's a serialization and deserialization going on and that slows down your performance. So, compared to an In-Proc, object form cache a distributed cache is at least ten times slower. So, with a client cache you get the best of both worlds. Because, if you don't have the client cache, if you just had a standalone isolated cache then there's a lot of other issues about size of the cache, what if that process goes down? Then you lose the cache and how do you keep the cache synchronized with changes across multiple servers. All of those issues are addressed by NCache in its client cache.
So, you get the benefit of that stand alone In-Proc cache but you're connected to the caching cluster. So, whatever is kept in this client cache, is also in the clustered cache and if any of the client updates it here, the caching tier notifies the client cache. So that it can go and update itself, immediately. So, that's how you make sure or you rest assured that your client cache will always be synchronized with the caching tier which is then synchronized with the database.
So, in case of NCache a client cache is something that just plugs in without any extra programming. You make the API calls as if you're talking to the caching tier and the client cache just plugs into a configuration change and a client cache gives you 10 times faster performance. This is a feature that Redis does not have. So, despite all the performance claims that Redis has, you know, they are a fast product but so is NCache. So, NCache is head to head in performance with Redis without the client cache. But when you turn on the client cache, NCache is 10 times faster. So, that's the real benefit of using a client cache. So, this is reason number four for using NCache over Redis.
Reason 5 - Multi-Datacenter Support
Reason number five is that NCache provides a Multi-Datacenter Support. You know, these days if you have a high traffic application, the chances are very high that you either are already running that in multiple datacenters either for disaster recovery DR or for two active-active datacenters for load balancing or combination of DR and load balancing, you know, or maybe its geographical load balancing. So, you know, you may have a data center in London and New York or you know Tokyo or something like that to cater for regional traffic. Whenever you have multiple datacenters, you know, the databases provide replication because without that you wouldn't be able to have multiple datacenters. Because, your data is the same across multiple datacenters. If the data were not the same then, you know, it's a separate, there's no problem but in a lot of the cases the data is the same and then not only that but you want to be able to offload some of the traffic from one datacenter to the other in a seamless fashion. So, if you have the database replicating across datacenters, why not the cache? Redis does not provide any such features, NCache provides very powerful features.
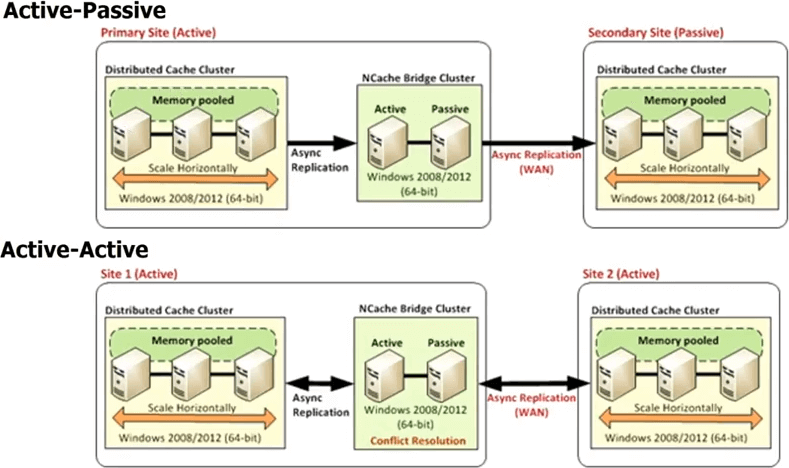
So, in case of NCache you have every datacenters going to have its own cache cluster but there's a bridge topology in between. That bridge is essentially connects the cache clusters in each datacenter, so that you can asynchronously replicate. So, you can have an active-passive bridge, where this is an active datacenter, this is passive. You can also have an active-active bridge and we're also releasing more than two datacenter active-active or active-passive configurations, where you can have, let's say, three or four datacenters and the cache will be replicated to all of them in an either an active-active fashion or an active-passive fashion. In an active-active, because the updates are being done async or the replication has been done asynchronously, there's a potential for conflict that the same item was updated in both datacenters.
So, NCache provides two different mechanisms for handling that conflict resolution. One is called last update wins. Where whichever item was updated last, gets applied to both places. So, let's say, you update an item here, another user updates the item here. Both of them now to start to propagate to the other cache. So, when they come to the bridge the bridge realizes that they've been updated in both places. So, then it checks the timestamp and whichever timestamp was the last it applies that update to the other location and it discards the update that was made by the other location. So, that's how the active-active last update wins conflict resolution happens. If that's not sufficient for you, then you can implement a conflict resolution handler. That's your code. So, the bridge will actually in case of a conflict call your code, pass both copies of the objects, so you can do content-based analysis and then based on that analysis you can then determine which object is more appropriate to be updated, to be applied to both the datacenters. The same rule applies if you have even more than two datacenters.
So, a multi-datacenter support is a very powerful feature NCache gives you out of the box. Once you buy NCache, it's all there, Redis does not and if you either plan to have multiple datacenters or even if you just want to have the flexibility, even if you don't have multiple datacenters today but you want to have the flexibility of being able to go to multiple datacenters, would you buy a database today that does not support replication? You probably wouldn't, even if you only have one datacenter. So, why go with the cache that does not support across the WAN replication. So, this is a very powerful feature of NCache.
So, up until now we've talked about mainly features that a good distributed cache must have. NCache, you know, shines. It wins hands down over Redis. Redis is a very basic simple cache.
Reason 6 – Platform & Technology (for .NET Apps)
.NET & Windows vs Linux
Reason number six is probably one of the most important reasons for you, which is, platform and technology. If you have a .NET application, you know, you would prefer to have the complete .NET stack. I'm sure you would want, you would not want to mix .NET with Java or Windows with Linux, in most cases. In some cases, you know, you may but in most cases people who are developing .NET application prefer to use Windows platform and prefer to have all the their entire stack to be .NET, if possible. Well, Redis is not a .NET product. It is a Linux based product that was developed in C/C++.

Let me show you little. Here's the Redis labs website which is the company that makes Redis. If you go to the download page you'll see that they don't even give you a Windows option. So, despite the fact that Microsoft has picked them for Azure, they have absolutely no intention of supporting Windows. So, as far as Redis Labs is concerned, Redis is only for Linux. Microsoft open Technology Group has ported Redis on to Windows. So, there is a Windows version of Redis available. It open source and is unsupported but, you know, it's buggy and unstable and the proof is in the pudding but that Microsoft itself doesn't use it in Azure. So, the Redis that you use in Azure is actually a Linux based Redis and not the Windows base. So, if you want to incorporate Redis into your application stack, you're going to mix oil with water, you know. Whereas, in case of NCache everything is native .NET. You have Windows. You have 100 % .NET. NCache was developed in C Sharp (C#). It is certified for Windows Server 2012 R2 and every time a new version of operating system comes it is certified for that. You know, we're going to be pretty soon launching the ASP.NET Core support. So, we have a .NET Client officially. We also have a Java Client officially. So, I think, if you use NCache and again NCache is also open source. So, if you don't have the money, go with the open source version of NCache. But, if your project is important then go with the Enterprise version which gives you more features and support both. But, I would highly recommend that you use NCache if you have a .NET Application for both the .NET and Windows combination.
On-Premises Support
The second benefit that NCache gives you is, if you're not in the cloud, let's say, you haven't decided to move to the cloud, you are hosting your own application, so, it's on-premises essentially. So, it's in your own datacenter well Redis that is available by Microsoft is in Azure only. So, anything that is on-premises, so, there's a Redis that is available on-premises by Redis Labs but that's only Linux and the only on-premises on Windows is the open source, the one that comes with no support and the one that's buggy and unstable and the one that is so buggy that Microsoft itself doesn't use it in Azure.

Whereas, in case of NCache you can either continue to use the open source which is free, which is unsupported of course, if you don't have the money. But, it's all native .NET or if you have a project that's important for your business then by the Enterprise Edition that has more features and comes with support and it's a perpetual license. It's pretty affordable, you know, to own it and we also give you 24 by 7 support in case that's important for you.
So, it's fully supported in an on-premises. Most of our customers that are high-end customers are still using NCache in an on-premises situation. NCache has been in the market for more than 10 years. So, it's really stable product.
Cloud Support
As far as the cloud support, Redis gives you a service model in the cloud, which is Microsoft has implemented a Redis service. Well, Redis service means that you don't have access to the cache servers. You know, it is a black box for you. There's no server-side code. So, all the read-through, write-through, write-behind, the cache loader, the custom dependency and a bunch of other stuff, you cannot do with Redis. You know, you only have the basic client API and as I said, you know, on Azure, Microsoft gives you the Redis as a service.
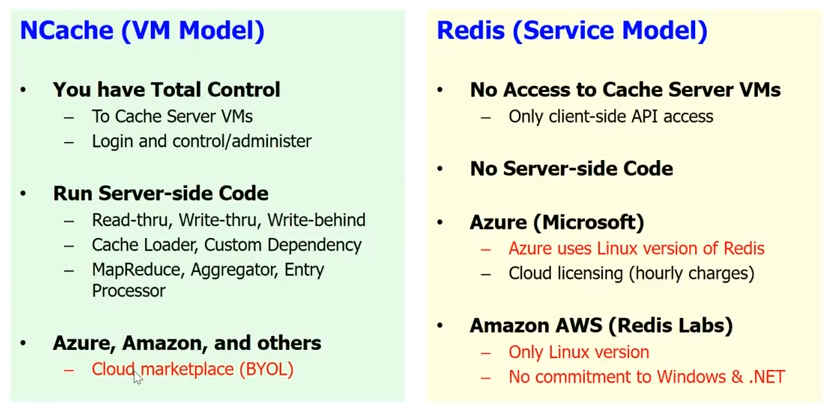
NCache, we've intentionally picked a VM model. Because, we want the cache to be close to your application and we want you to have a total control on the cache. This is something that's very important because we have many years of experience and we know our customers are very sensitive. Even a small, let's say, if you use the Redis as a service and you have to make one extra hop to get to the cache every time, that just kills the whole purpose of having a cache. Whereas, in case of NCache you can have it as part of the VM. You can have the client cache. It's really embedded within your application deployment. So, you can do all the server-side code.
NCache also runs on Azure. It runs on Amazon AWS and also other leading cloud platforms in BYOL model. So, you basically get your VM. Actually, you have the NCache in the marketplace. You get an NCache VM and you buy the license from us and you start to use NCache.
So, very different approaches. But this is the approach that is intended if your application is really important and you want to control the application, every aspect of it and not have to rely on somebody else managing a chunk of your application level infrastructure. It's one thing to manage VMs and the hardware underneath but as you start to go more and more upward, then you lose that control and of course in case of caching, in case of NCache, it's not only that control but also a lot of features that you would lose, if you went with the service model.
So, reason number 6 is platform technology. For .NET application, NCache is a much more suitable option than Redis. I'm not saying Redis is a bad option but I think for .NET applications NCache is a much more superior option than Redis.
NCache History
Let me just give you a brief history of NCache. NCache has been around since the middle of 2005. So, that's the 11 years, you know, NCache is been in the market. It’s the oldest .NET cache in the market. 2015 January, we became open source. So, we are now Apache 2.0 license. Our Enterprise Edition is built on top of our open source. So, the open source is a stable, reliable version. It has a lot of features. Of course, Enterprise has more features but open source is very usable product. The basic thing is, if you don't have the money go with open source. If your business application is important and you have the budget, go with the Enterprise Edition. It comes with support and also gives you more features.
We have hundreds of customers, pretty much in every industry possible that needs caching. So, we've got financials industry customers, we have Walmart, other retail industry. We've got Airlines, we've got Insurance industry, Car/Automobile, just across all industries.
So, that's the end of my talk. Please, go ahead and download the Enterprise Edition of NCache. Let me actually take you to our website. So, essentially, go to the download page and I would highly recommend that you download the Enterprise Edition. Even if you end up going to use using open source edition, download the Enterprise Edition. It's a fully working 30-Day trial, which we can easily extend and play with it.
If you want to go ahead and download the open source go ahead and download the open source. You can also go to GitHub and you can see NCache at the GitHub. Please contact us if you want us to do like a personalized demo. Maybe talk about your application architecture, answer your questions. Thank you very much for watching this talk.