Today’s applications are highly transactional and can scale for high transactions by running in a load-balanced, multi-server deployment. At the same time, many of these applications need to run in multiple data centers. This could be done for disaster recovery, where one active data center has disaster recovery as a passive data center that is usually in a different geographical location. Another reason is that if users of this application are distributed geographically, they will get faster response times as they are simultaneously accessing their own data center in their region.
NCache Details Bridge for WAN Replication NCache Docs
Cache Needs WAN Replication Just Like Database
When you have applications running in multiple data centers, the cache needs to be replicated. This is because the cache keeps transient data, and if the cache ever goes down, the data is lost. Transient data can be ASP.NET sessions, arbitrary data generated by your application, or aggregated data. However, temporary data is not permanent, so it is never stored in the database-it is only cached.
The other data NCache keeps for performance reasons is the application data. If you lose this data, it reloads from the database, which harms performance. Many businesses don’t want to deal with this due to high application traffic. This is why even the application data has to be replicated across the WAN if you have a multi-datacenter deployment.
NCache Details WAN Replication NCache Docs
Solution: NCache WAN Replication through Bridge
To deal with the above situation, NCache provides a WAN replication feature via a bridge. This allows you to deploy NCache across multiple data centers in active-passive, active-active, 3+ data center active-active configurations.
2-Site Active-Passive
In an active-passive configuration, NCache is deployed on both active and passive sites, creating a bridge topology on the active site. Figure 1 shows how this is laid out in an active-passive configuration. All application updates are sent from the active site’s cache to the bridge, which asynchronously sends them to the passive site within milliseconds. The only delay here is the latency between data centers if they are far apart. So, a bridge topology with an asynchronous queuing mechanism allows all these updates to happen without overflowing anything.
NCache Details Cache Synchronization modes NCache Docs
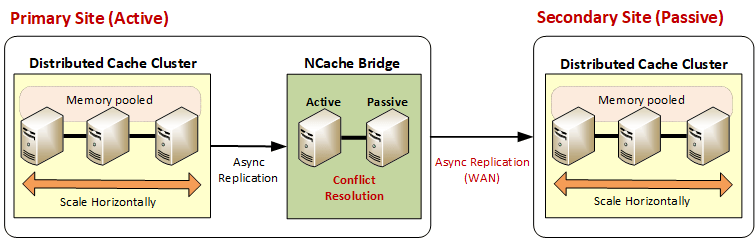
Figure 1: Active-Passive data centers
2-Site Active-Active
Another configuration that NCache supports is active-active, where both sites are active. One holds the cache and bridge topology, and the other holds the cache only. Figure 2 shows how this is done. Similar to active-passive, in active-active, a cache sends its updates to the bridge, which in turn sends them to other caches. However, now there is a difference. Conflicts can occur when the same item is updated on both sides at the same time. This means that the bridge must coordinate updates from both sites and resolve conflicts asynchronously to avoid adversely impacting cache performance on each active site.
NCache Details Multi- Datacenter WAN Replication NCache Docs
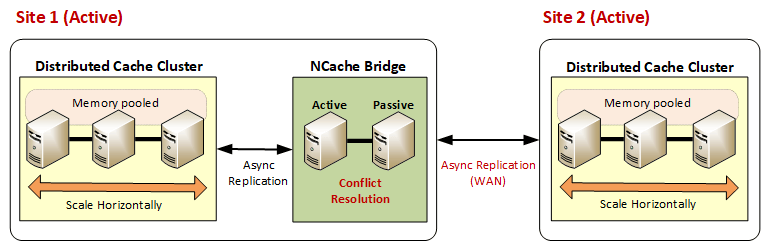
Figure 2: Active-Active data centers
3+ Site Active-Active
In the third situation, there are 3 or more active data centers. Here one of the active sites has cache and bridge, all other sites have cache only. That is, the bridge is local to one of the sites, but the other two sites access the bridge remotely. Similar to the active-active scenario, in this 3+ active-active scenario all caches send updates to the bridge, and the bridge propagates updates to all connected caches. At the same time, it performs conflict resolution to ensure that the same data updated from cache does not cause data integrity violations.
NCache Details Bridge Topology NCache Docs
Figure 3 shows three active-active data centers. NCache allows for very seamless and asynchronous cache replication. No application code changes. Applications don’t even know that the cache is being replicated, but it is replicated asynchronously over the WAN of the data center.
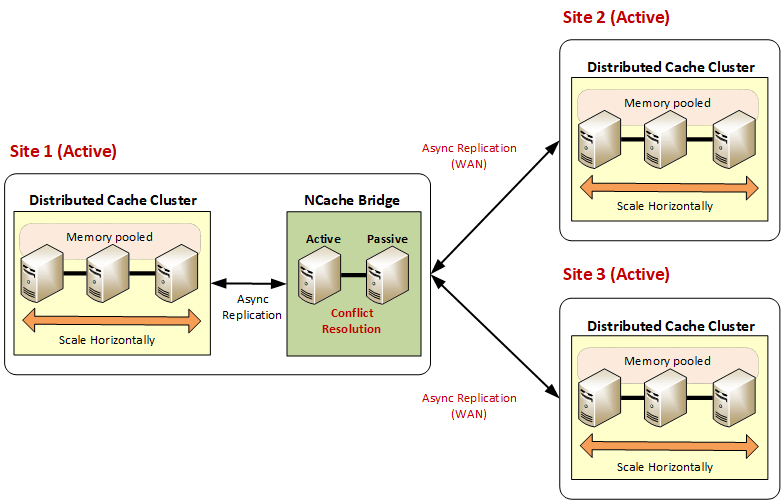
Figure 3: Three active-active data centers
Parallel & Bulk Async WAN Replication
All updates to the cache are asynchronous. The reason they are asynchronous is the distance between multiple data centers. This distance can lead to poor performance due to latency. Access times between servers are very fast when applications are cached in the same data center. But over a WAN, it’s usually very slow. So, if you don’t do asynchronous updates, whoever is making the update request has to wait for the update to complete – synchronous updates, which slows down your application.
However, asynchronous replication means that applications and caches at each site are not waiting for their data to be replicated to other data centers. Data is queued at the bridge. The bridge itself is a two-node cluster, queuing all update requests from all caches. For active-passive, requests are queued only from the active cache and applied asynchronously to the passive cache. If you have three or more data centers, the bridge applies updates to multiple active sites in parallel.
Additionally, the bridge performs bulk updates. This means that you can combine multiple data items into a single request and send them to other sites as a single bulk request, greatly reducing network trips. This powerful combination of parallel, bulk, and asynchronous replication therefore, improves performance while replicating caches across multiple data centers.
NCache Details WAN Replication Topology NCache Docs
Conflict Resolution
If you have multiple active sites, each of those sites can update the same data at the same time. Make sure your local computer is in sync with the local time zone. Of course, there is no problem if it is not updated at the same time. Suppose you update item 1 at time T1 and update item 2 at time T2. The update at time T2 is the last update applied. However, if both updates occur at the same time, the bridge must resolve the conflict in one of two ways.
- Default “Last Update Wins” logic: The bridge automatically retrieves the timestamp from each cache, and all caches have their clocks synchronized so they have the same time. The bridge receives update times from each cache and the latest updates are applied to all caches. Again, the purpose of conflict resolution is to apply the same version update to all caches to avoid data integrity issues.
- Conflict Resolution Handler: Another way the bridge resolves conflicts is that it can provide a conflict resolution handler according to its logic for analyzing updates. Since this resolver is configured with NCache, the bridge will provide both copies of the object and the resolver will analyze which version is better according to the supplied logic. This will return the final version to the bridge and apply this update to all caches.
The following code snippet gives you a sample of the conflict resolver implementation which is deployed on the cache:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
public class Resolver : IBridgeConflictResolver { public void Init(System.Collections.IDictionary parameters) {. . .} public ConflictResolution Resolve(ProviderBridgeItem oldEntry, ProviderBridgeItem newEntry) { var conflictResolution = new ConflictResolution(); switch (oldEntry.BridgeItemVersion) { case BridgeItemVersion.OLD: { /* Replace item with new entry */ } break; case BridgeItemVersion.LATEST: { /* Keep old entry */ } break; case BridgeItemVersion.SAME: { /* Your logic to replace entry if needed */ } break; } return conflictResolution; // Configure this implementation on cache } public void Dispose() {. . .} } |
Hence, by having a conflict resolution mechanism in NCache, you rest assured that your cache will never be out of sync. It will never have two different versions of the data updates and will always be consistent across multiple data centers.
NCache Details Configure Bridge Configure Conflict Resolver
Handling Disaster at Runtime
Now let’s talk about what happens in case of a disaster situation where one site goes down.
Active-Passive
Case 1: The passive site goes down
An active-passive configuration acts as a disaster recovery site. So, if the passive side goes down, the active side will still work, and your application will continue to run. The bridge cannot replicate data to the passive site until you intervene to restore the passive site. When you revert the passive site, it reconnects to the bridge and resynchronizes, thus discarding the existing cache and effectively getting a complete copy of the active site’s cache across the bridge. After synchronization is complete, it switches to normal WAN replication mode.
NCache Details Sync Bridge Caches Active-Passive Cache
Case 2: The active site goes down
If the active site goes down, that means you have some sort of a disaster, because the bridge is down, and the application is probably down. You have to send all the traffic now to the passive site that now becomes active. All data is replicated from the original active site to the original passive site, with no disruption to users. The original passive site is now active, so all updates happen here, but the users see no interruptions.
However, once the original active site is up again, it connects to the new active site (the original passive site) and synchronizes itself completely. Once the sync is done, both are active-active even though all of the traffic goes to the original passive site. You have the flexibility to offload all traffic to the original active site and change the status of the active-active site back to passive on the bridge. NCache allows you to do all of this at runtime without any interruption in case of an active-passive disaster.
Active-Active
When the active site with the bridge goes down, WAN replication stops because the bridge is down. However, other active sites will continue to function, and all traffic will be routed to them. Once you bring the down site up, you can start the bridge and connect the active site to the bridge, so both sites are in sync. This is all done at runtime, so no downtime is required. Once the bridges are synced, both sites will be able to push updates to each other. NCache thus provides fault tolerance.
NCache Details Cache Synchronization Modes NCache Docs
3+ Active Sites
The third situation is when you have 3 or more active sites where one site has the bridge, and the others do not. Two scenarios can take place in this case as mentioned.
Case 1: The non-bridge active site goes down
In this case, other sites will continue replicating each other, and the traffic of this site is re-routed to the other connected sites without disrupting users. Once the site is up, it reconnects to the bridge and resynchronizes to get the latest copy of the cache. This is the signal to get the traffic back on track.
NCache Details Change Cache Sync Modes Bridge Topology
Case 2: The active site with the bridge goes down
In the case where the bridge goes down, the other two active sites keep working, but they are not able to replicate their updates to each other because there’s no bridge. So, what you can do at this time is to start a bridge in one of the other two active sites.
To start the bridge, you need two nodes as a cluster. Ideally, you should have a dedicated set of servers for the bridge topology on that site, but you can also use two cache servers as a cluster since it’s most likely temporary. However, it may have some performance impact on those cache servers because now the bridge also consumes resources like CPU and memory.
You need to start the bridge on one of the active sites where both active sites are already running. The running cache can now connect to a bridge. So, they both connect to a bridge and synchronize by replicating all the updates with each other. The users don’t experience any interruption as the two sites are synchronized and propagating updates with each other. Hence, if any site goes down, you don’t lose any data.
NCache Details Add Clustered Caches Bridge Management
Now once the original site with the bridge comes back up, you can simply:
- Take the bridge down on the temporary site.
- Remove the bridge from the existing cache.
- Bring the bridge up on the original site.
- Connect all the caches to this new bridge.
Since you can connect the cache to the bridge at runtime, NCache allows you to automate all of this work through scripting so you can seamlessly handle the situation where a bridge site goes down and you have to bring it back up.
Conclusion
NCache gives you a powerful WAN replication mechanism that allows you to handle a lot of different advanced scenarios. Moreover, it performs WAN replication in a fast and efficient manner and handles active-passive, active-active, or three or more active-active data centers.