DEVintersection 2016
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
Your .NET applications may experience database or storage bottlenecks due to growth in transaction load. Learn how to remove bottlenecks and scale your .NET applications using distributed caching. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
Overview
Hello Everybody. My name is Iqbal khan. I am a technology evangelist at Alachisoft. We are a software company based in San Francisco Bay Area. NCache is our flagship product which is a distributed cache and this is my topic today. My topic is not about NCache today, its caching in general. NosDB is another product that we have, its an open source NoSQL database for .NET. I'm going to use Azure for demonstrating distributed cache so that you guys can see how it is actually used.
So, today's topic is scaling .NET applications for distributed caching. I prefer to have more interactive discussion. So, as I'm talking if you guys have a question please raise your hand. So, we can talk about that right at that point instead of waiting to the end. I find that makes it much more meaningful conversation.
So, let me get started. Okay! So, we're going to go through a few definitions. I'm sure most of you know this already but this is for completion purposes.
Scalability
The first definition is scalability. Scalability is high application performance under peak loads. So, if you have, let's say an ASP.NET application or any .NET application that performs super-fast, with, let's say, five users, it's not necessarily scalable. Of course, if it doesn't perform fast with five users then you have other problems than this. But most applications do perform super-fast with five users but it's when you go to 5,000 or 50,000 or 500,000 users that's when things really start to break down. So, if you want your application to be scalable, it must perform under peak loads.
Linear Scalability
Linear scalability means that your application architecture, your deployment strategy, if it is done in such a way that adding more servers gives you an incremental capacity of handling more transactions than you are linearly scalable.
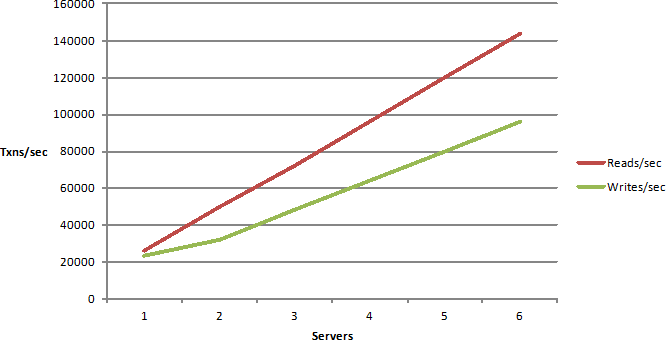
That means if you had two servers and if you add, let’s say a thousand users with a three server you should be having 1500 users or something like that.
Non-Linear Scalability
But, if your app if your architecture or deployment is not linearly scalable, it is going to look more like a logarithmic curve which goes up and down which means that after a certain point it doesn't really matter if you add more servers.
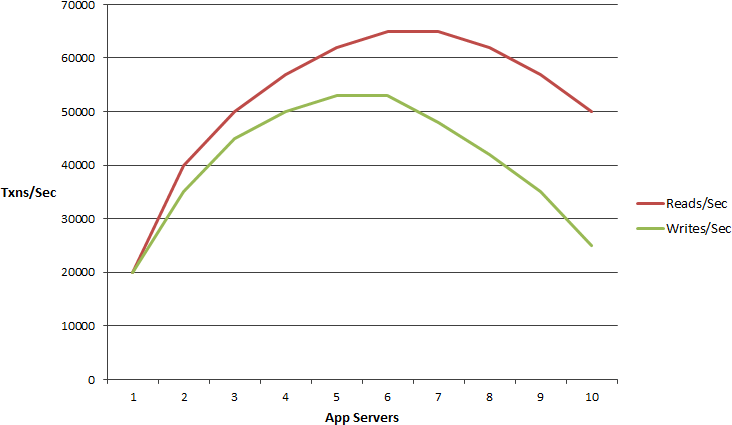
It will slow things down. If you have more transactions you just can't get out. You cannot buy yourself out of that problem. So, you want not only scalability but linear scalability.
Which Applications Need Scalability?
The following applications are the one that usually have these types of issues. These are ASP.NET web applications, these are web services, these are internet IOT back-end which is usually also web services, you might have big data processing which is usually not that common in .NET but, big data processing is also something that needs to scale or any other server applications. You may be a financial institution that has a compliance requirement to process certain number of transactions.
So, you may have a server application that has a compliance requirement to, let's say, if you're a bank wire application, you need to wire the funds for the next business day or by a certain time. So, you need to be able to process more and more transactions. So, if you have one of these applications then you've come to the right talk.
The Scalability Problem
So, let's define the scalability problem. Most of you know that your application architectures today, if you have an ASP.NET or web services application, the architecture of the application tier scales vary linearly. So, you can add more servers there's usually not a problem. The problem really is with your data storage and, when I use the word data storage I mean relational databases and mainframe. There are legacy data. Any data store that you traditionally used and that becomes a bottleneck and when it becomes a bottleneck then you have this problem. The NoSQL databases, I was supposed to say they're not always the answer. But NoSQL movement started partly because of this. Because relational databases were not scalable so NoSQL databases are scalable but, they're not good in all situations because, you know, they require you to move all of your data from your existing database into a NoSQL database which you can do that for a lot of new data but the traditional business data, your customers, their accounts, all of that data has to stay in relational for both, business purpose reasons and for technical reasons. Technical reasons of course are that a relational database has an ecosystem that is not matched by any NoSQL database and business reasons are of course of the same nature.
So, the NoSQL database is not always the answer and even though we have NoSQL database product that we sell is called NosDB, that is used only as an augmentation of relational databases. So, you cannot get out of relational databases. Relational databases are here to stay. So, you need to live with that reality. So, you need to solve the scalability with relational databases still being in the picture.
The Scalability Solution
The solution of course is that you should use an in-memory distributed cache. NCache is one such solution. It's an open source distributed cache. We are the oldest .NET distributed cache in the market. We've been around for the last 10 years, actually 11 now. And, we're the only really native .NET cache.
Most of you have heard of Redis, right? So, more than 2 years ago, we never heard of Redis because they were really not focused on that. It wasn't until Microsoft did a partnership with them for Azure.
Distributed Cache Deployment
The benefit of an in-memory distributed cache is that you can use it with your existing databases. So, you can solve that problem that your relational databases are providing you through an in-memory distributed cache. So, how do you solve that problem? You solve that problem by, let's see this picture here.
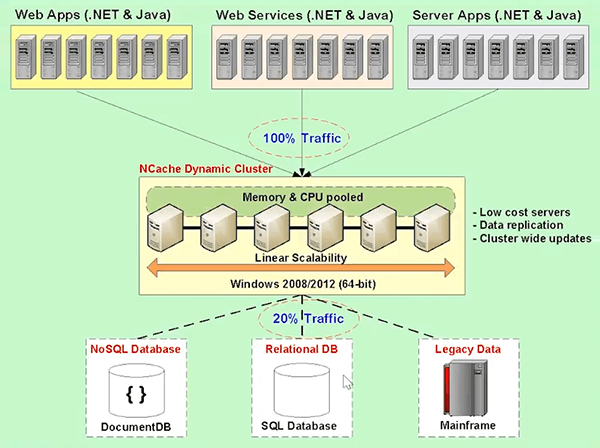
So, you have an application tier which is your web applications, your web service, any other server applications and you can add more servers here. For web application and web services there is usually a load balancer up there that I did not draw in this. So, you can add more servers at this layer. You cannot add more servers at the database layer. Yes! You can add more servers in the NoSQL layer, but, as I said, it's not always the answer. So, you have to solve these two boxes. So, you put an in-memory distributed cache in between the application tier and the database.
The distributed cache usually forms a cluster. So, not all distributed caches form cluster. Memcached never formed a clustering even though it was a distributed cache. Redis does form a cluster, NCache definitely does form a cluster. A distributed cache forms a cluster of two or more servers here. The reason I say two is for redundancy purposes and for replication and for a lot of others and also for a scalability purpose. If you only need one cache server, you probably don't need a distributed cache. So, you should have a minimum of two cache servers here and this cache cluster actually pools the memory and the CPU resources from all the cache servers into one logical capacity. What that means is that as you add more servers you get more memory, more CPU processing and more network card capacity. Those are the three bottlenecks to scalability; memory, CPU and network card. Network card these days are … one gigabit or ten gigabits is pretty much standard. It's pretty hard for max out of one gigabit card or ten gigabits unless your object sizes are large. But, if your object sizes are large, large means hundreds of kilobytes per object, then it's pretty easy to max out a network card if you have a lot of traffic. But, if you have more servers and of course that's more network cards and then memory is the same way.
The reason it's an in-memory distributed cache is because memory is much faster than disk and that's what really adds the value. It’s faster, it's more scalable. So, the goal here is to capture about 80% of the application access going to the distributed cache. So, that only 20% will be left to go to the database.
A lot of people initially saw caching as a performance boost. Yes! It is a performance boost because in-memory is faster than this. But more importantly it's a scalability need because, you cannot scale without something like this in your infrastructure. In fact, more and more companies are now almost making it a standard that just like they'll have a database in their application environment they will also have a distributed cache. Some people call it in-memory data grid which is on Java side, that's a term. Some people call it a bit of data fabric but distributed cache is the most common name for the .NET ecosystem. So, this is an infrastructure. Once you have it in place, you can use it as a really powerful tool. The ratio between the application servers and the caching tier is usually about 4:1, 5:1, assuming that these are pretty loaded servers in terms of the transactions. You can go more than 5:1 also depending on the nature of these. And, a typical cache server is about 16 gig to 32 gig in memory and dual CPU quad core type of configuration. So, not a very high-end box. In fact, you don't want a very high-end box in this layer. You want more boxes than a few very high-end boxes. If you add more memory you can go up to 128 or 256 gig memory but more memory means you need to have a stronger CPU. Why is that? Because, if you have more memory your heap is bigger, your garbage collection is going to be a much bigger task and garbage collection is not the fastest thing in .NET and it will eat up your CPU. So, you look more and more like a database. So, it's better to have 16 to 32 gig is a pretty good sweet spot per cache server. Any question up until now?
NCache Scalability Numbers
Here is the scalability numbers of NCache. Different caches would have different numbers but the goal is to have this as scalable. So, the reads scale in this fashion the writes are scaling this. The reads are slower than writes because the replication happening with reads. I'll talk about those capabilities.
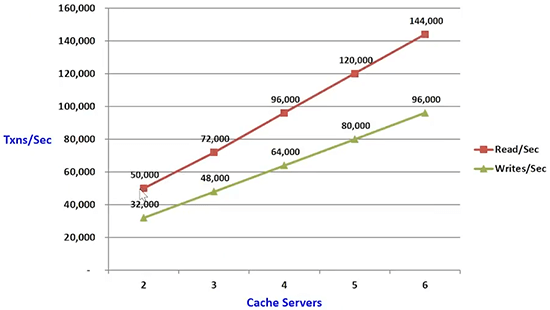
The reason you need replication is because memory is volatile. So, if any one server goes down you will lose that data. So, you don't want to lose that data in many cases.
Common Uses of Distributed Cache
The goal of the talk up until now was to kind of show you why you need distributed caching. And, now that we've established that case, let's talk about what is it that you will use a distributed cache for.
App Data Caching
The most common use case is what I was talking about which is an application data caching. You cache the data that exists in your database, right here. So, you cache as much of it as you can and then you improve your performance and scalability.
The main thing to notice in application data caching use case is that the data exists in two places. One in the database, one in the cache. Whenever that happens, what's the first concern that comes to your mind that what could go wrong if there existed in two places? Yes, consistency!
So, it's really important for a good distributed cache to handle that. Because, if a cache is not able to handle the fact that data must be consistent in both places then you are forced to cache more read-only data. Read-only data is about 10% to 15% or 20% of the data. The majority of the data is what I call transactional data. These are your customers your accounts. That's data that's changing. It might change every few seconds, although most of the time it might change every two minutes. So, even if you could cache it for one minute or 30 seconds that you would still benefit that you will read it multiple times and if you multiply that by the total number of transactions that are happening in a given day, you have millions of transactions that are no longer going to the database. So, it's really important that for application data caching, a good distributed cache must handle this consistency and I'll go over those features that are really important to have that consistency. So, application data caching caches permanent data. Permanent data means this exists in your database permanently.
ASP.NET Specific Caching
The second use case is, if you have an ASP.NET application, this of course applies to other web application too but I am focusing on .NET. You can cache your session state, your view state, if you're not using the MVC framework and you can cache your output, the page output. All of that data is temporary in nature. It's not permanent. Any data that is not permanent should not really exist in the database. It's a transient data.
When data is transient, when it's temporary and it's not existing in the database, it's only existing in the cache, what's the biggest concern that comes to mind that what could go wrong? Persistence… Or lack of it. So, if you don't persist you lose data. What if this cache server goes down and you have this shopping basket or whatever and let's say, you're an airline and this customer of yours has just done this flight search and they going to buy 10 tickets or four tickets worth at least $5,000 and the last page they say submit or whatever the last page and suddenly the session is gone because the cache server went down and they have to start all over again. The entire activity is lost. You may lose that customer. Not a very good experience.
So, anything that you cache that is transient, the cache must replicate. Any cache that does not do replication, it is not a viable cache. And, replication has cost, so, the cache must do effective and efficient replication. The session state is a very common use case for a distributed cache because sessions are very common in ASP.NET.
Runtime Data Sharing thru Events
The third common or the third use case which is actually, not very commonly known is called runtime data sharing. This is, if you have multiple applications that need to share. One application produces something or update something, that another application or the another instance of that application needs to use. Usually you would use message queues for this traditionally or you would just put that data in the database and the other application will pull. But, a distributed cache is very good for that use case. It's not there to replace message queues. Message queues have their other use but if your application is running in the same datacenter, all the instances and they need to share data then this is a much more scalable data or data sharing platform because all the applications are connected to the same platform and this platform can fire up events, in a Pub/Sub model. Pub means one application is the publisher, they publish something and they fire off an event. All the subscribers of that will be notified and they will consume that data.
There's also other types of notifications. When certain items are modified your application can show interest in certain items and if this item changes notify me. Or there's a continuous query feature that NCache has which is like a SQL dependency feature in SQL server, where NCache allows you to say a SQL type of query that says SELECTS Customers WHERE Customers.City = "New York". So, if any customer with this criteria has ever added, updated, or removed from the cache notified.
So, it's a much more intelligent way of monitoring changes to the cache. So, all of those things allow you to share data between applications in a very fast and scalable way at runtime. And, this is also transient data, although many much of that data exists in the database but the form in which you are sharing it probably doesn't. So, it's transient. So, this must also be replicated. Any questions up until now? Either you guys know this stuff completely already or I am super good.
App Data Caching Overview
So, let's go through and see some source code in terms of how … what are the features that you should use and how to use them. I'm going to use NCache as the example but as I said my focus is more on the actual features.
Here's a typical way that you would use any cache.
Customer Load(string customerId)
{
// Key format: Customer:PK:1000
string key = "Customers:CustomerID:" + customerId;
Customer cust = (Customer) _cache[key];
if (cust == null)
{
// Item not in cache so load from db
LoadCustomerFromDb(cust);
// Add item to cache for future reference
_cache. Insert(key, cust);
}
return cust;
}You would load a customer from a database. Before you go to the database, you'll check the cache and you'll use the key, a string-based key. Let’s says Customers:CustomerID and the actual customer ID is may be 1000 or something and you say check the cache. If you have it in the cache no need to go to the database, you've got it. If you don't have it in the cache then you go to the database, you load that customer and you put it in the cache. When you put it into the cache, the next time you come, you or anybody else comes you’ll find it in the cache. So, that's a very simple paradigm. Once you do this everybody gets to find things worth more than the cache.
Of course there's a lot of other features that you can pre-populate the cache with a lot of the data that you think is good to be needed anyway. So, that you will save a lot of the database hits upfront and then you'll still incrementally keep adding data to the cache that is not found in the cache. For example, here's a visual studio project. If you were to use NCache you would link two of these assemblies. One is NCache.Runtime and one is NCache.Web. You will use two of the namespaces here similarly NCache.Runtime and NCache.Web.Caching. We named our namespaces to be fairly close to ASP.NET cache. So, that you know, when NCache came out ASP.NET cache was the only cache available. So, you've got this and at the beginning of your application, this is a console application of course, yours is going to be different one. You will connect to the cache and you get a cache handle. Every cache is named and you've got a cache handle and then you add your objects to the cache. So, let's say, you've just added, you do cache.Add here. You specify your key. Although, this this should probably not be David Jones it should be customer ID of some sort and then you have the actual object and then you have specified expirations. And, you specify the absolute expirations of one minute. You’re saying after one minute expire this item from the cache. Everything else you just kept at default. And, later on you can do cache.Get and get that same customer from another place. So, just simple cache operations.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("demoCache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Hands-on Demo
In case of NCache, all caches are named. I'm going to quickly now show you what a cache looks like and then we'll come back to the code. I've set up a bunch of VMs in Azure. So, you can run NCache in Azure, in Amazon, an on-premises. In all cases, the cache servers themselves are just VMs. This is just Windows 2008, 2012 VMs. The cache client in Azure can either be a VM, it could be a web role, it could be a worker role, it could be a website.
Create a Clustered Cache
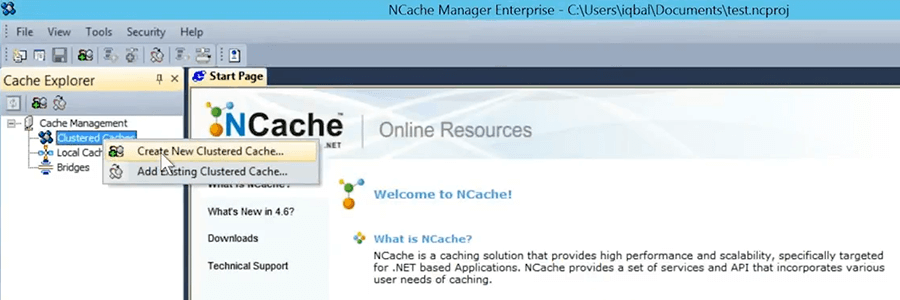
I’ve logged into the demo client, right here. I'm going to now quickly go and create a cache. So, I can show that how cache looks like. Use this tool called the NCache manager, graphical tool and lets you … I'm going to come here and say it create a ‘New Clustered Cache’.
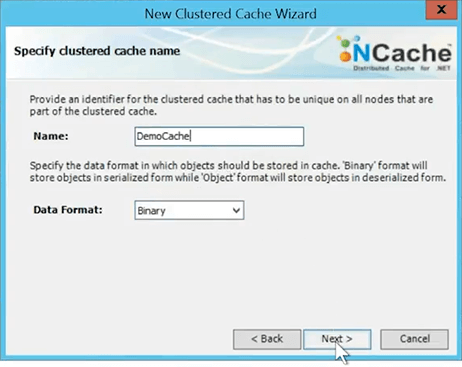
All caches in NCache are named. So, I am just going to name my cache. I'll take everything else as default at this time.
I'll choose a topology for Partitioned Replica. I will quickly go over that at the end of this talk. Partitioned Replica is my topology.
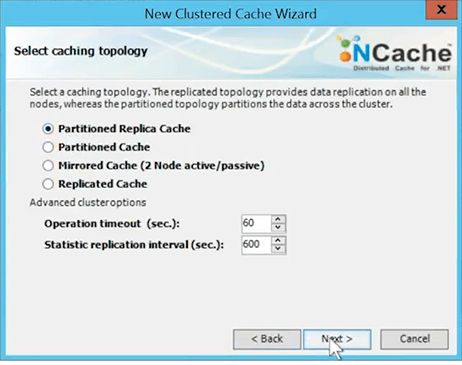
I'll use Asynchronous Replication.
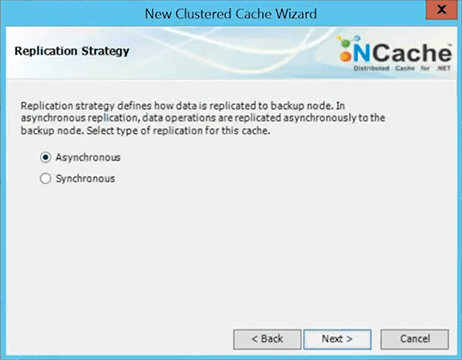
I'll pick my first cache server which is demo2. So, those are two my cache nodes.
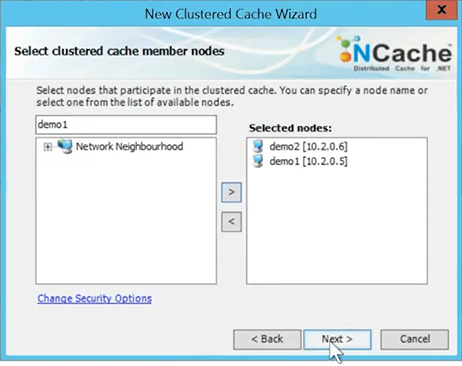
I'll hit Next. I'll take all the defaults. I'll specify how much memory I want to allocate to this cache. So, that way the cache will not consume more memory than this. I've just given one gig but of course yours is going to be much larger. That's the size of a partition.
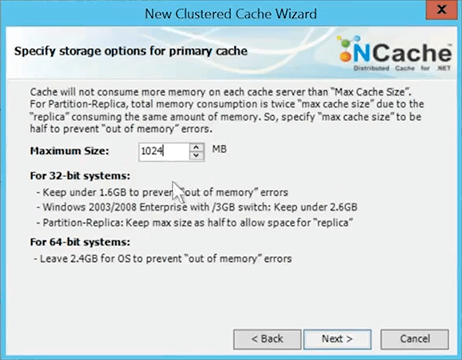
So, once the cache uses that much memory, the cache is full. So, either it will reject any new items or it's going to evict some of the existing items. So, I'm going to say, evict 5% of the cache on this and I'll say least recently use is the algorithm to use and I've just created the cache.
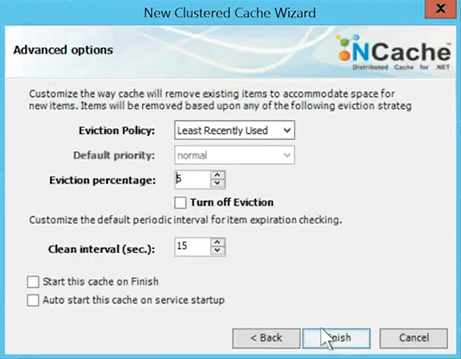
I'm going to go ahead and add a client to this.
So, I've just created a cache and we're going to start the cache.
Simulate Stress and Monitor Cache Statistics
I will choose the statistics, so, I can use some PerfMon statistics. I'm going to also do monitor the cluster. So, I've just started the cache. This cache is called demo cache. I am going to just quickly test it. So, I just ran a stress test tool that comes with NCache and lets you quickly test the cache in your own environment.
So, this cache is now working. So, what is happening is, on the client box, and the client means their application server box I've got a configuration file, right here. So, I just created cache and it now knows what the cache servers are. Now, let me go back to the code. So, when I actually, picked this cache name then this is what actually, happened, my application now connected to all the cache servers in the cluster and gave me a cache handle, so that when I do a cache.Add, it’s actually going to add it to the appropriate place in the cache and also do the replication all for me, all of that is done.
So, the API hides all of that detail but I wanted to show you what that cache looks like behind the scenes and, how easy it is to use the NCache in that situation. So, let's come back to our main. Here is what the API would look like.
- Cache Connection
ICache cache = CacheManager.GetCache(“myDistributedCache”); cache.Dispose(); - Fetching Data
Employee employee = cache.Get<Employee>("Employee:1000"); bool isPresent = cache.Contains("Employee:1000"); - Writing Data
cache.Add("Employee:1000", employee); cache.AddAsync("Employee:1000", employee); cache.Insert("Employee:1000", employee); cache.InsertAsync("Employee:1000", employee); Employee employee = (Employee) cache.Remove("Employee:1000"); cache.RemoveAsync("Employee:1000");
You do a cache.Get, cache.Contains, cache.Add, Insert, Remove. Insert means add if it doesn't exist otherwise update.
App Data Caching Features
OK, now that we've got an idea what a cache looks like, what is a simple API. Let's come to the feature that we talked about. Which are important for a distributed cache.
Keep Cache Fresh
So, the first thing that we had said is that a distributed cache must keep the data fresh, the cache fresh. So, there are four ways that it can do that. Number one is expiration, which a lot of caches have almost every cache allows you to expire things.
So, there's an Absolute Expiration and there is a Sliding Expiration. Absolute Expiration is what I just showed you, which is, it says expiring this item, let’s five minutes from now regardless of what happens. And, the reason I say this is because as I say, this data exists in the database and I can only trust it for five minutes that it's not going to be change in the database. I don't want to keep it for more than that in the cache because it might change in the database. So, you're making a guess about the nature of the data. Some data you can cache for hours and days. You know, this may be your look up tables. May be your pricing changes once a day or something. So, you can cache this for 24 hours.
Other data is your transactional data. You can cache it only for maybe 30 seconds or one minute because that's as long as you feel comfortable. So, absolute expiration is for permanent data and it's one way of you estimating or guessing how long is it safe to keep the data in the cache. It’s very important. Distinction that I want to be make between the absolute expirations and sliding.
Sliding expiration basically says remove this item from the cache when nobody is touching it anymore, for this interval. Touching means fetching or updating. So, for example, a session state. When you log out a session state is no longer being touched by anybody. So, after 20 minutes or so, it needs to be removed from the cache.
Sliding expiration is used for transient data, usually. It's more of a clean-up operation. It has nothing to do with keeping data fresh. It has to do with just getting rid of it because you no longer need it. But, absolute expiration is what you need to keep the data fresh. Secondly, you know, expirations is a very important thing. Every cache must have it and most of them do, in fact I think all of them, at least absolute expiration.
Synchronize the Cache with the Database
The second feature is something that most of them don't do. And, this is where you want to synchronize the cache with the database.
Using Database Dependencies
You say, you know, I really can't predict how frequently or when is this going to be updated in the database. I don't know when the data is going to update in the database. Because, I got multiple applications that are updating it. May be other people are directly touching the data. So, I just want the cache to monitor the database. So, and the cache should be aware of this change in the database. This is a feature that NCache has. It's called SQL dependency. Actually, it uses a SQL server feature called SQL dependency, where NCache becomes a client of the database.
Let me quickly show you what that looks like. So, if I have a cache here. So, again, the same way we did the libraries and then you connect to the cache. Now, when you're adding the item to the cache, right here. If I come here and then I say 'AddProductToCacheWithDependency', go to definition. So, here you're saying to this cache, here's my SQL statement.
private static void AddProductToCacheWithDependency (Product product)
{
// Any change to the resulset of the query will cause cache to invalidate the dependent data
string queryText = String.Format("SELECT ProductID, ProductName, QuantityPerUnit, UnitPrice FROM dbo.PRODUCTS WHERE PRODUCTID = {0}", product.ProductID);
//Let's create SQL depdenency
CacheDependency sqlserverDependency = new SqlCacheDependency(connectionString, queryText);
CacheItem cacheItem = new CacheItem(product);
cacheItem.Dependency = sqlserverDependency;
//Inserting Loaded product into cache with key: [item:1]
string cacheKey = GenerateCacheKey(product);
cache.Add(cacheKey, cacheItem);
}
private static string GenerateCacheKey (Product product)
{
string cacheKey = "Product#" + product.productID;
return cachekey;
}So, your SQL statement usually reflects that one row in the table. So, if you adding a product it should be that SQL statement with the product ID equals this. So, you're creating this SQL statement for SQL Server. Because, this is what you pass as part of the SQL dependency to SQL Server. You will pass it to NCache. So, you on the client box is passing this to NCache. So, you're specifying this as your SQL statement. You're creating a ‘cache Item’ object and within the cache item you’re specify the ‘SQLServer Dependency’. So, SQLCacheDependency is a class of NCache, actually. This is not the same as the SQL server dependency. This has the sort of the same name except the SQL cache dependency. This keeps that SQL statement, you specify that and you add the item to the cache. So, you've done this and you are at this time sitting on this box, right here.
So, you pass this on to NCache. It goes to one of the cache servers. This cache server becomes a client of the database now. Because, you've specified connection string information also. Somewhere here, you specify the connection string. So, NCache server becomes a client of your database. Now that database could be SQL server, that could be Oracle and NCache will establish a SQL dependency connection. SQL server will create a data structure within SQL server that will monitor the data set.
So, just like NCache had that continuous query feature that I talked about for run-time data sharing, where NCache was monitoring all the customers, where Customer. City = “New York”. Now the SQL server is monitoring this dataset within SQL server and if any row matching that criteria is either added, updated, or removed from SQL database, SQL server notifies the cache server. The cache server now knows that this data has changed in the database. So, it has two options. It can either remove that from the cache which is the default behavior or it can reload a new copy.
Using Read-Through/Write-Through
The way it will reload a new copy is, if you use another future of NCache called read-through. I'm going to skip this and I'll have to come back to this. So, there's a feature called read-through which is your code. You implement a read-through handler and I'll show you the read-through handler. So, here is a IReadThroughProvided.
{
// <summary>
// Contains methods used to read an object by its key from the master data source.
// </summary>
public class SqlReadThruProvider : Alachisoft.Ncache.Runtime.DatasourceProviders. IReadThruProvider
{
private SqlDatasource sqlDatasource;
// <summary>
// Responsible for loading the object from the external data source.
// Key is passed as parameter.
// <param name="key">item identifier; probably a primary key</param>
// <param name="exh">Current expiration hint; you can modify the value and attach a new hint</param>
// <param name="evh">Current eviction hint; you can modify the value and attach a new hint</param>
// <returns></returns
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemonExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
// <summary>
// Perform tasks like allocating resources or acquiring connections
// </summary>
...You implement this. It has an Init method which initializes it. A Dispose method and actually like a Get method. So, the get pass you the key and you give it back the cache item. So, you go to the data source of yours and you'll load that item, you specify the expiration or any other thing and you pass it back to NCache. This code of yours runs on the cache server. This is an important thing to keep in mind.
So, the read-through actually, runs on the cache server itself. Actually, I have another diagram.
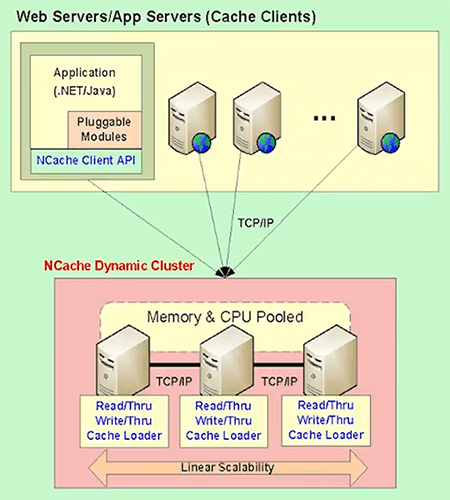
So, the read-through runs on the cache server itself. So, the cache server has to be developed in .NET for your .NET code to run on it, right? So, if your .NET shop, if your application is in .NET, the reason I said the whole stack of yours should be .NET for all of these benefits.
So, coming to, for example Redis, Redis is a Linux based cache. So, it's a great cache, I've got nothing against them but if you're a .NET shop you need to do all of these things and your code must run on the cache server for the cache to be able to synchronize itself with the database and automatically reload that item from the database. So, your read-through handler is what gets called when a SQL dependency fires, if you want it that way. If you don't want that, then it's just going to remove that item from the cache. And, when it's removed from the cache then, the next time your application looks for it, it will not find it and it's going to go and get it from the database. Now, in certain cases, for example, it's a product catalog that you have cached and you've just updated the price. Why remove the product from the cache, you just updated price? Because, now the application has to have the logic to go and get it from the database. It's better to reload automatically.
So, a lot of the data if you think is going to be needed over and over again either the expiring it or when the database synchronization happens it's better to reload it than to remove it. Because then the application does not have to do this. The more of this the cache does the easier the application become. So, another way that cache can synchronize itself with the database. So, if you don't have SQL server or Oracle, let’s say, you have MySQL or DB2, then these two features that exist, then you can use DB dependency, which is another feature of NCache that where NCache pools a specific table and you modify your database triggers to go update the flag at that row. NCache picks it up and say this item has change. So, I need you to remove it or reload it.
Using CLR Stored Procedures
CLR procedures is another way to synchronize the cache with the database. Where you actually write a CLR procedure. You call it from your table trigger. So, let's say, if you have an Add or an Update trigger or a Delete. You call this CLR procedure, it calls NCache or it calls the cache.
In case of CLR procedure you need to make sure that the cache supports async methods which NCache does. So, you can make in a cache like an insert async call and the control immediately comes back to you. Because, if you don't do the async call your database transactions are then start timing out. Because, you're updating multiple servers in the cache, you’re going across the network which is not what a database transaction is designed them. So, you need to have async call.
So, those are the three ways you can synchronize the cache. So, any cache that you paid you need to make sure that you can keep the data fresh. These are the two ways.
Synchronize the Cache with the Non-Relational
Same way if you have a non-relational data source, let's say, you have your data in the cloud or it's any other place. You can even want to make a web method call. You can actually, implement a custom dependency which is again your code that registers and runs on the cache servers and NCache calls it and says please go and check your data source if it has changed or not. You check the data source, if it has changed you notify NCache that data and the data source has changed. So, NCache can either remove it or reload it.
So, again with a relational database NCache does it all for you. In case of non-relational, you have to do a custom dependency.
Handle Relational Data
The final aspect of keeping their cache fresh is the dependency features. Let’s say, if you have a one-to-many relationship between a customer and an order and you're caching both of them. What if the customer object is removed from the cache? Should the orders remain in the cache or not? What if you actually deleted the customer from the database. Well, you don't usually delete the customers, when I'm saying one-to-many. Let's say, what if the one side you remove from the cache really meant that you might have removed it from the database also. That means that the many side is no longer valid. So, who should keep track of all of this? If the cache can do it for you then it makes your life much simpler.
For example, ASP.NET cache object has this feature called cache dependency. NCache has implemented it and as far as I know, no other .NET cache has this feature. But, basically you register the relationship between items and say this depends on this item, if this item is ever updated or remove, please automatically remove this item. So, the cache does the cleanup for you.
The more of this the cache does for you, the better it is for you because you can rest assured that your data is going to be fresh. Once you have this confidence, you can cache pretty much all data. It's just a matter of which strategy you will use to keep data fresh.
Finding Data
So, now that you have the confidence of data being fresh, you'll start caching a lot of data. Well, once you start caching all the data the next thing that comes is well the cache is now starting to look more and more like a database. It's not a database, it's always a temporary store. But, especially a lot of that reference data, you pretty much store the entire data set into the cache. When that happens you want to be able to search on it. Instead of just always finding it based on keys, that's very inconvenient. Finding any item based on key is not always convenient. You want to be able to search that through other means.
One way is to do an SQL search. Again, SELECT Customers WHERE customers.City = "New York". Just like you would do or you would say give me all my products of this category. So, you'll get a collection of those objects back from the cache, not from the database. Coming from the cache means of course that the database no longer has to take that hit and it's all in-memory. It’s much faster with its coming from multiple servers at the same time.
So, all of these are parallel queries. And, for you to be able to do this, the cache must support indexing, which NCache does. I'm not sure other products do or not but make sure that cache supports indexing. Otherwise, it will be really really slow queries.
Data Grouping
One thing that you cannot do in a cache is join multiple objects or multiple tables which is what you can do in relational database. So, there are ways around it which is that you can group things, you can tag them in certain ways that you can get them back and that way you can fetch data based on some logical associations or grouping that is in the cache. So, let's say if you cache everything, I will give you an example. For example, let's say, you you've got a collection of customers back. So, I've got a collection of object tags and I want to cache every object separately into the cache. But, later on, I want to be able to fetch it all in one call.
//Caching Query Results (Collection)
//Cache Collection Objects Separately
static void CacheSupplierProducts(NorthwindEntities context, int supplierId)
{
Tag[] productTags = new Tag[1];
productTags[0] = new Tag("SupplierProducts:" + supplierId);
IQueryable<Product> products = context.Products;
var result = from product in products
where product.SupplierID == supplierId
select product;
foreach (Product p in result)
{
String key = "Products:ProductId:" + p.ProductID;
_cache.Insert(key, p, productTags);
}
}
...
ICollection productList = _cache.GetByAnyTag(productTags).Values;So, either I issue the same query, SQL query and I say give me all the things back. But, I got these objects from the database, I didn't get them from the cache. And, they're not an entire dataset. Let's say, whatever set that I wanted to fetch at that time. So, I have cached every object individually that I might need to access individually. But, I want to be able to fetch it all back as one collection. So, I use the concept of a tag. I tagged them all with the same tag. And, that tag could be any unique string and I say give me all the items that have this tag. So, in one call I can get all that entire collection back again. So, it's that type of stuff that you can do with tags, that kind of makes it up for the lack of joins in the cache.
So, you can do grouping. The groups and subgroups. You can do tags. You can do named tags. Named tags are essentially you have a key and then a value. If you're caching, for example, text, free form text. There's no way to index that text on its own because it's text. So, you have to make up the tags yourself and just tag itself may not be sufficient. You want to be able to name every tag.
So, just like an object has attribute names. So, the name tag is like attributes of an object. So, the name could be city and the value in this text could be New York or Las Vegas. So, you can do all that stuff and then later fetch those things and in case of NCache at least you can use if you specify all of this either through the API or through the SQL query. So, when you're fetching something based on SQL …
First question, great! Can we use hierarchical taxonomies? What you can do actually is … the groups and subgroups gives you only one level of hierarchy. So, within a group you can have multiple subgroups but you can't go beyond it.
You can use different types of tags to represent because you can assign multiple tags to one item. So, for example, if you had multiple hierarchies, you can assign for every level that you go down you can assign all of the top every level as a separate tag.
One more question. Can we can control over the internal representation of the cache? The indexes are built based on combination of hash table, in case of NCache, and red black trees. You can choose the indexes but you don't choose what the data structure is going to be used, internally. But, the indexes are built based on the nature of the use. So, for example, hash tables are good for certain types of access and if you are going to do the range type of searches then red black trees are much better. So, the NCache does it. I don't know what other products do but NCache indexes stuff quite a bit.
Read-Through & Write-Through
Let me quickly go through the read-through, write-through. So, why do you want read-through and write-through? Read-through, we've seen one example of it, which is that you could reload stuff automatically.
Another benefit of read-through is of course you're consolidating as much of your data access into the cache itself. The more you access … the more of that goes into the cache or caching layer, the less it is in your application and the application becomes simpler. The application does just a cache.Get and of course the other benefit of that was that you can automatically load stuff.
Write-through is in the same fashion. One benefit is that you have consolidating all the writes. The second benefit is that you can actually speed up your writes. So, for example, write-behind is a feature, where you update the cache synchronously, and cache updates the database asynchronously. So, if the database updates are not as fast as the cache which is true, then your application performance suddenly improve because you'll only update the cache and the cache updates database.
So, the read-through and write-through and write-behind are really very powerful features that you should take advantage of. This is also server-side code that you write that runs on the cache cluster and, it simplifies your life. So, that your application can have more of the data in the cache and also update it through the cache.
Let me, quickly go through it and talk about something. I'm not going to go into the detail of ASP.NET session state caching. Just know that you can just plug it in without any code change and just make changes to web.config and it just automatically takes care of it and the same thing goes with view state and output caching.
High Availability (100% Uptime)
I'm going to quickly go through a couple of things. First I wanted to talk about… Any cache that you use, because, it's like a database, it's an in-memory database in production. So, a cache must be highly available. You must have highly available cache.
Dynamic Cache Cluster
NCache is highly available through a couple of things that it does. First it has a dynamic cache cluster. You can add or remove servers at runtime and it automatically readjust the cluster. You don't have to hard code the server names in the config, the clients automatically. Once a client talks to any cache server, it gets a cluster membership information. If the membership changes at runtime, let's say you add a new node or you drop a node, the updated membership is propagated to the client.
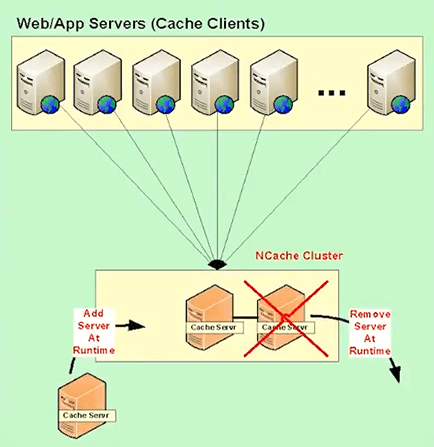
So, that's the first part that must be there. It’s really important that you to see it that way.
Caching Topologies
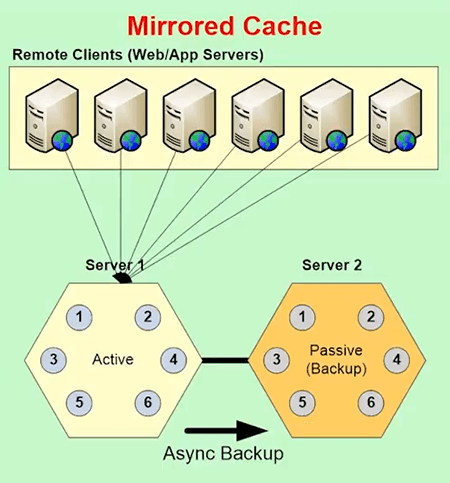
The second is the caching topology. So, there are different ways that NCache, for example, will give you four caching topologies. The first is called a Mirrored Cache. It’s a 2 node active/passive.
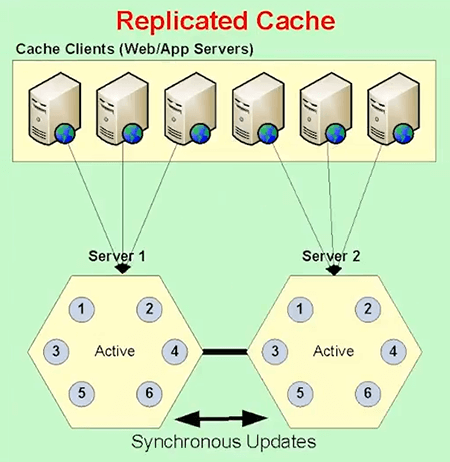
The seconds is called Replicated Cache, where every server in the cache has a copy of the entire cache. So, the more servers you have, the more copies of cache you have. It's scalable for read, not scalable for updates. But, it has its own use with cases.
The third topology is called Partitioned Cache, where the entire cache is broken up into partitions. Every server is one partition. And, these partitions are created automatically.
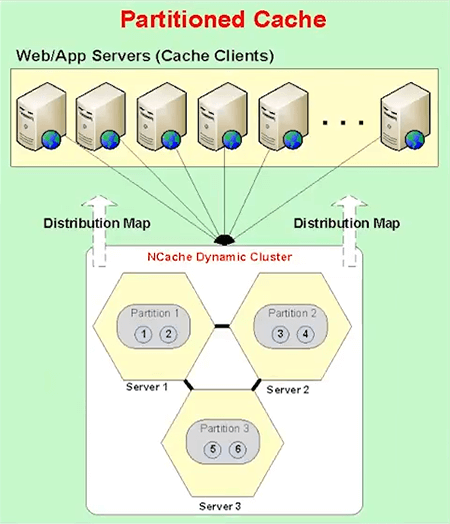
So, for example, in case of NCache each partition has a number of buckets inside it. So, the total cluster has 1,000 buckets. So, if you have three partitions, they have one third, one third number of buckets.
Partitioned Replica is the same with partition but every partition is backed up onto the different server and all that is done automatically for you. So, when you create a two node cluster you are going to have two partitions, the two replicas. When you add a third server, automatically, a third partition is created and when a third partition is created some of the buckets have to move from existing partition.
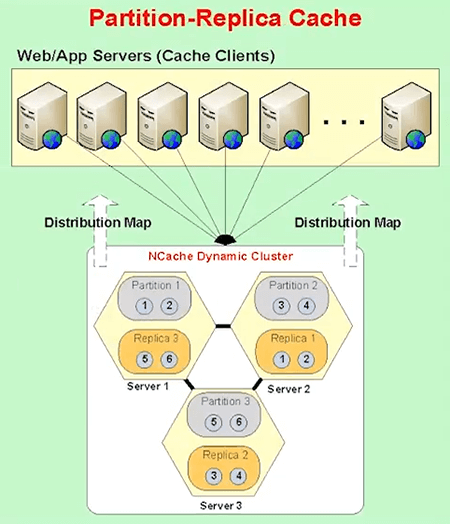
So, all that's done automatically for you. A new replica is automatically created. In fact, if you see it from this, let me just show you that, here. Let's say, if you had a two server partition … but let's say, if you only have a two server clustering, you have two partitions. Partition 1 was here and Replica 1. Partition 2, Replica 2. Now, you added a third server, suddenly you have to have a third partition and this will get some of the buckets from here, some others from here, that's one thing. Second the replica 2 is no longer going to be here, it's going to move here because now, the replica for Partition 3 has to be here.
So, all that adjustment in is automatically done for you by NCache. So, that's one thing. Second, there's a feature called Client Cache some people call it Near Cache, which is really powerful that you must use. Basically it's a local cache within your client application. But, there's one special thing about this is that this local cache is not disconnected with the cache cluster. It is connected to the cache cluster. It keeps itself synchronized.
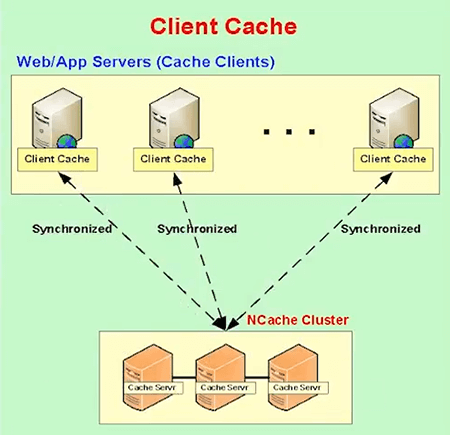
So, in case of NCache, for example, the client cache plugs in automatically behind the scenes to a config. Whatever you fetch from each of these applications, servers is what is automatically kept in the client cache. So, the next time you need it and you'll find it in the client cache. And, the cache cluster knows which data is in which client cache. So, if that data changes by, let's say, another client the cluster notifies all the client caches that have that data to go and update themselves. So, the client cache stays connected but it is a local cache. It can be even In-Proc. In-Proc means within your application process. So, that really speeds up your performance but at the same time you're part of the overall connected distributed cache.
WAN Replication
I'm going to skip a lot of the stuff, we don't have time. So, there's also WAN replication. If you have multiple datacenters, you should be able to have the cache replicates itself across the WAN and you can't build a cluster across the WAN. That will just die because these sockets break, the latency is just very high. So, there has to be some way of connecting caches across two datacenters.
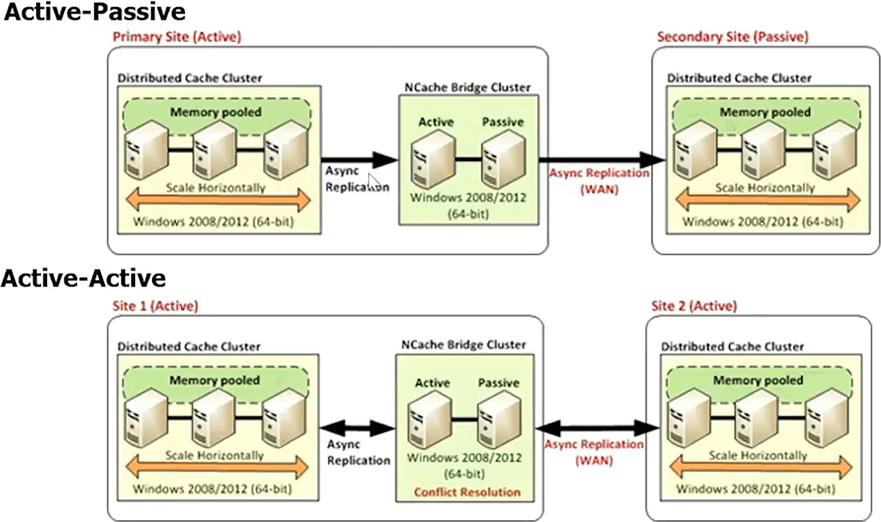
In case of NCache we have this thing called bridge topology which connects multiple datacenters. You can have active-active, active-passive or even more than two datacenters centers now. And, this is all done asynchronously and there's also conflict resolution done for you. So, as you can see, a cache is not just a simple key value store. So, there's a lot that you should keep in mind behind the scenes.
NCache vs. Redis
One thing I quickly wanted to cover was NCache vs. Redis, just a high level, I wanted to talk about this. NCache is the native .NET cache. It runs on Windows and you can do both the client side and server side caching, that's one benefit. Whereas, Redis is mainly Linux based cache. Before Microsoft did partnership with them, you know, most people in .NET side didn't even know they existed, even though they have been a very popular cache on the Unix and PHP and other environments.
Secondly, the Linux version of NCache is available on Azure, as a Cache as a Service. So, the reason is cache as a service is because for .NET applications, you can’t really run server-side code on a Linux based cache. You have to have a .NET based cache for you to run. So, that's one huge limitation that you will get.
Third if you are going to do anything outside of Azure, Redis is only available as a Linux based cache. The window support that Microsoft did is something that they don't use themselves. Even on Azure they don't choose to use it on the windows. It's not very stable. There are also more detail if you want to see a more detailed comparison between NCache and Redis, you can come here then see comparisons. So, we've got comparisons with everybody, because we're so confident about us.
So, as you can see, this is a full blown comparison. Just go through it. If you are thinking about using a distributed cache, which you should, you have all those scalability needs. Do your homework, make sure that whatever you use, fits your needs. And, as far as NCache is concerned, we'll make it easy for you to compare NCache with others. You can come to our website and download NCache. It is open source. So, you can download either the Enterprise Edition or the Open Source one here or you can go to GitHub and you will have NCache here.
That’s the end of my presentation. Any questions? You can pass a stored procedure call. It has to be all SQL, like the transact SQL stuff that will run within SQL server itself.
Yes. So, the cache can be on the same server as the application. We don't recommend it. It's not a good deployment strategy but if you have small configuration, yes, of course.
When you do partitioning all of the partitioning is done for you. So, the whole idea is that every partition should be equal in its weight, in terms of data size, in terms of transactions.
You don’t control the partitions, you just know they exist.
When you are updating the item table you can choose to update the cache from within the database itself, if you have a CLR procedure that can make a call straight from the database to the cache. You can also write separate code that can update the cache and all that depends how much of that you are and keep in the cache.
So, you know, I can talk about more offline if you want. But, I mean, there multiple ways that you can make sure that all that data that you need to access is kept fresh in the cache.
Yes, actually, I'm going to make the slides available. That’s the reason we’ve scanned everybody’s email. So, we can do that and we'll also have the video recorded and uploaded. So, you can watch and also your colleagues can watch it.
Actually, per application or … Actually across multiple applications. So, it all depends on the in transaction load. You can have minimum of 2 cache servers just to have the cluster and then the number of servers depends on how many application servers you have or how much, how much activity you have basically? How much data are going to cache? How much reads and writes are you doing?
It doesn't matter, yeah. Yeah, everything will continue to work. Thank you guys.