NCache Architecture
Today, I'm going to talk about NCache Architecture. NCache is an In-Memory Distributed Store for .NET and Java applications. It is extremely fast and scalable. And, you can use it in your high transaction server applications to boost your application performance and scalability.
Common Uses of NCache
Distributed Cache
The two common ways NCache is used. Number one is as a Distributed Cache where you cache the application data to reduce those expensive database trips and, number two is a Messaging and Streams platform. I'll go over both of those briefly before I go into the architecture.
-
App Data Caching
So, in distributed cache, the application data caching means that you use an NCache API usually to just cache your application data so, you don't have to go to the database as frequently because cache is much faster than the database. It's also more scalable because it's in memory so, it's fast. It's close to your application so it's fast and, it's distributed so it's scalable. And, if you have a .NET application and, you're using EF Core then you can use NCache through EF Core as well and, also NHibernate and EF 6 as well. If you have Java applications you can use NCache as a Hibernate Second Level Cache. You can also use with as a Spring Cache or, you can program it against JCache. -
Web App Caching
The second part of the distributed cache use is, if you have web applications, that you can store your sessions in NCache and, then NCache replicates these sessions to multiple servers, so that if there is any one NCache server that goes down that you don't lose any data but these sessions are very again scalable because it's a distributed store and it's obviously super-fast. There is also multi-site session feature available in all the languages .NET, Java, Nodejs, etc. In addition to sessions, for example, for .NET 6, ASP.NET Core applications can store their Response Cache in NCache and, they can also use NCache as the backplane for SignalR. SignalR is for live web applications where the web app has to send events to the clients. And then if you're using .NET 4.8 you can also store your Session State, View State, Output Cache, and also SignalR.
NCache for Mission Critical Apps
Let me quickly show you what NCache looks like. Here is what it is as a distributed cache for mission critical applications. I use the word mission critical because in most cases we see there are customers use NCache in very sensitive applications that are customer-facing and, they are very important for their business. So, NCache is, you know, part of your very critical infrastructure in that case.
And, these are, as I said, server applications that are high transaction. These are web applications. These are Microservices, Web APIs, or other server applications. Obviously, you can do .NET, Java, Node.js, or Python. And, these applications are trying to access your database either as a SQL Server, Oracle, Db2, MySQL, or any other relational databases, or they are accessing maybe your legacy mainframe data or maybe they are using a NoSQL database like Mongo DB, Cosmos DB, Cassandra or others. In this situation, NCache becomes a distributed cache by… you use NCache as two or more servers as a separate caching tier, although you don't have to have a separate caching tier, your application can run in the same box as NCache and just works perfectly fine but the more popular deployment architecture is to have a separate caching tier, that's just a cleaner way to use NCache.
So, let's say, you start out with a 2-server cache cluster, NCache cluster, NCache pools the Memory, CPU, the network card resources of all these servers into one logical capacity and, let's say, you're putting more transaction load through your applications onto NCache and these two servers are maxed out well you can easily add a third server, or a fourth server, or fifth server and, so on so forth, NCache never becomes a bottleneck. This is something you cannot do with your databases. Databases do not scale. NoSQL does scale but, in most cases, we found that people have to use relational databases for a variety of business reasons and they also have legacy mainframes. So, because the data storage layer does not scale NCache helps your application scale by letting you cache as much data as you can. The general goal is to have about 80% of the time you should find the data from NCache rather than going to your database. If you can achieve that ratio then, you know, you've taken the pressure off of the databases and your application is going to scale.
Messaging and Streams
The second common use case, or use of NCache is to use it as a Messaging and Streams platform where you can have multiple applications that can communicate with each other through Pub/Sub Messaging, through Continuous Query, or NCache based Events. Let me show you what that looks like. So, for example, if you have a high transaction server application that need to do a lot of real time messaging or stream processing you can use NCache. Now the same NCache that was a distributed cache now becomes a messaging and streams platform. Again, it's an In-Memory Distributed Store. It scales linearly. It replicates the messages across multiple servers. In fact, NCache also has Persistence in it.
So, with that, you can have different applications, for example, Pub/Sub messaging is a very popular way, it's a methodology, it's a paradigm where you have multiple publishers and multiple subscribers that can communicate with each other in a decoupled fashion. Decoupled means the publisher does not know who the subscriber is they just publish messages on to certain topics, and these subscribers can get them. Continuous Queries is in the same way. So, those are the two common ways NCache is used.
.NET vs. Java Applications
Now let's talk about how NCache handles .NET vs. Java applications. NCache has a very unique native multiplatform capability that you'll find very interesting, let me go into that.
.NET Edition
NCache tries to provide you native solution for both .NET and Java. And, by that, I mean that when you have a .NET application your entire application stack experiences .NET, you’re not using anything but .NET. So, for example, NCache has a native .NET client which is what your application is going to use on your application. This runs on your application server and NCache has developed this in ‘C Sharp’ (C#), 100%.
Similarly, if you have server-side code like Read-through, Write-through, Right-behind, Loader/Refresher that you have written in .NET, NCache will run that code in its own .NET CLR process. Let me show you how. And, I'll come back to this diagram back and forth. So, for example, here's an NCache architecture you have a .NET application here that may be running on Windows or Linux. It has a native NCache .NET Client. And, this is talking to an NCache cluster which is a .NET Edition NCache Cluster. So, that means that the server-side code is also .NET.
Now the way NCache is architected and, this is why what makes it really powerful for multiplatform native support, is that there is a cache process, there is a management process, those are separate from your server-side code process. And, there's a very high-performance RPC. It's an in-memory RPC that NCache uses, that NCache has developed its own proprietary RPC which is super-fast. So, that's how the cache talks to your server-side code. So, for example, if it has to call the Read-through Handler, your Read-through Handler is going to be running inside this .NET CLR process to go to your database to get the data and then it passes it to the cache. And, the same thing goes for Write-through, the Loader, and the Refresher. So, the entire experience that your application has is .NET.
Java Edition
Well, let's switch to the Java side. Again, the same way, you have a Java server-side code. NCache has a 100% Java Client that runs on your application server and then the same way as .NET. Here is the Java Edition. Let's say, you have a Java application that may be running on Linux most likely, or maybe even Windows, maybe Docker, maybe Kubernetes. So, that application will embed the NCache Java Client which is as I said right here 100% native Java, and then this Java Client is a grounds-up identical to the .NET Client. It also talks to the NCache Cluster the same way that the .NET Client does by using NCache’s own proprietary socket protocol and the NCache server is architected so that your server-side Java code is going to run on its own JVM.
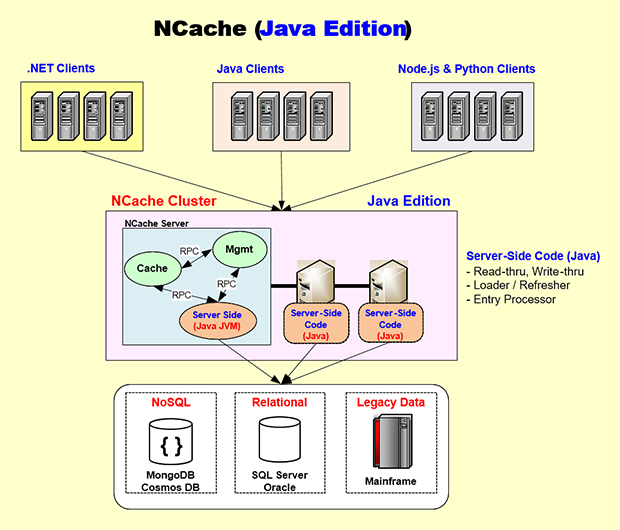
So, all of the development and testing and debugging that you will do will be all in Native JVM processes. And, this cache process will call the, let's say, Read-through handler which will go into, let's say, maybe Oracle or Db2, or even SQL Server Database and get the data and give it to the cache process. Again the same high performance in-memory RPC is used. So, by having an architecture which kind of encapsulates the .NET and the Java code in their own native processes, NCache is able to give you a native stack for both Java and .NET.
And, again in case of a Java application you may want to do your development either on Windows or Mac OS and NCache supports it completely, or even Linux and, then you're more likely to use Docker and Kubernetes, than the .NET folks NCache provides you the Docker images, and then also full support for Kubernetes, the Azure AKS, the AWS EKS, the Google GKE or the Red Hat OpenShift. You can use it in a very seamless fashion.
So, NCache is very unique. It gives you a native .NET experience and at the same time a native Java experience. So, if you're a Java shop you don't feel like you're using a non-Java product and if you're a .NET shop you're not you don't feel like you're using a non .NET product. That's the beauty of NCache the way it's architected.
Dynamic Cluster
Peer to Peer Architecture (Self Healing)
- No single point of failure (no master/slave)
- Cluster Coordinator oldest node, next oldest is automatic successor
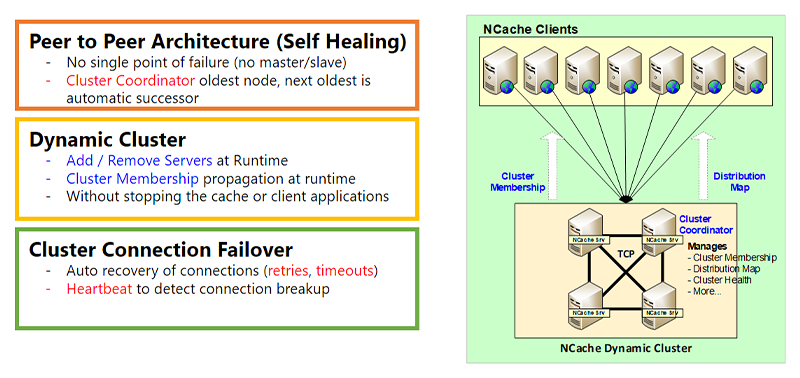
Okay, let's now get into the Dynamic Clustering part of NCache Architecture which is for high availability. And, one second, okay. So, the first part is the Dynamic Cluster. When I use the word cluster I do not mean Kubernetes Cluster, any other operating system-level cluster. This is NCache's own TCP-based cluster. And, this cluster has a peer-to-peer architecture. What peer-to-peer means is there's no master, there's no slave. Master/slave has problem is that if the master goes down the slave either becomes inoperative or becomes limited, whereas in a peer-to-peer architecture, every node is equally capable. There is obviously a cluster coordinator node, which is the oldest node and, then if that node ever goes down the next oldest is automatically selected as the cluster coordinator. The cluster coordinator does cluster membership. It manages the distribution map, the cluster health, and a bunch of other things that I'll go over some of that.
Dynamic Cluster
- Add / Remove Servers at Runtime
- Cluster Membership propagation at runtime
- Without stopping the cache or client applications
The Dynamic Clustering means that you can add or remove servers to the cluster at runtime without stopping the cache or your application. There's no interruption. And, when you, let's say, if you add a new server to the cluster the cluster membership is obviously updated at runtime and, that runtime information is then propagated to the clients. And, I'll talk about that in the next slide a little bit more.
Cluster Connection Failover
- Auto recovery of connections (retries, timeouts)
- Heartbeat to detect connection breakup
There’s also a cluster connection failover feature. So, because these are sockets, although the cluster servers usually are in the same subnet fairly close to each other but that may not always be the case. We do have customers that have servers even deployed in different regions and, it works perfectly fine although we recommend that in most cases, the NCache servers should be fairly close to each other. But, there could still be connection failure. If that is the case NCache has a retries logic and, there are timeouts. There is heartbeat logic, all of that is to make sure it's all dynamic.
Dynamic Clients & Dynamic Configuration
Dynamic Client Connections
- Add/Remove Clients at Runtime
- Without stopping the cache or client applications
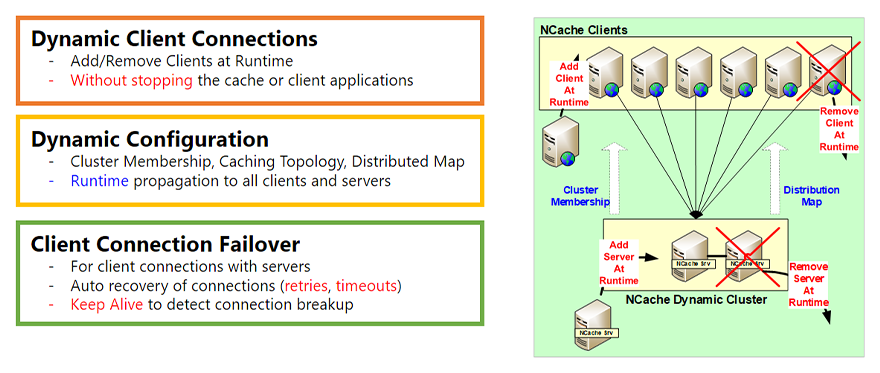
The other part of the dynamic architecture is the Dynamic Clients. So, just like this, the cluster had the ability to add or remove servers at runtime you also have the ability to add or remove clients at runtime. What does a client mean? A client is the NCache Client that runs on your application server, your web server, that's the part that your application talks to. So, you can add a client at runtime you can remove a client at runtime without stopping NCache, the cache, or your application without having any interruption. So, that's the first part.
Dynamic Configuration
- Cluster Membership, Caching Topology, Distributed Map
- Runtime propagation to all clients and servers
The second part is the Dynamic Configuration. So, as I mentioned in the last slide when you add a server to the cluster the cluster membership changes. Well, that gets propagated to all the existing clients that are connected, so that, they now know that there's a new server that they need to connect to. So, if they choose to based on the caching topology they may connect to that server as well. Additionally, depending on topology there may be a Distribution Map. A Distribution Map is more for Partitioned Cache and Partitioned Replica cache. But, as you add a server it gets updated, and that gets propagated at runtime. And, also a bunch of other configuration changes. There's a hot apply feature that you can do and, that gets propagated at runtime. So, that's the second part.
Client Connection Failover
- For client connections with servers
- Auto recovery of connections (retries, timeouts)
- Keep Alive to detect connection breakup
The third part is, again there's a Client Connection Failover which is the same way as the cluster connection failover. But, this is actually needed even more because the clients will probably not be very close to the cluster servers always. And, it may be some routers or firewalls in between. So, the connection between the clients and the cluster is more likely to break. So, NCache has fairly intelligent retry capability, timeout. There is also keep alive capability, so, that the client stays connected even if the connection breaks the client reconnects itself to the NCache Cluster.
Split Brain Detection & Recovery
Another important topic of dynamic aspect of NCache Architecture is the Split Brain. The Split Brain is a phenomenon that can occur in the cluster.
Split-Brain Occurs at Connection Breakup
- Sub-clusters formed when connection retries fail
- Each sub-cluster selects its own coordinator and assumes others are dead
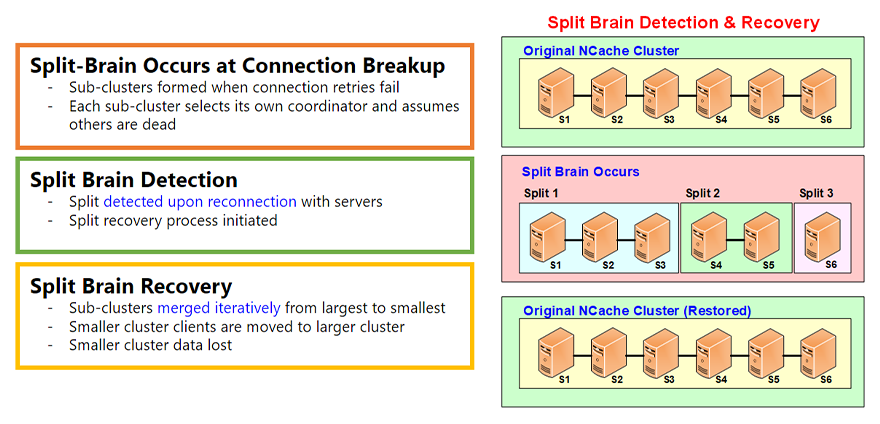
And, Split Brain occurs whenever, let's say, if you have a healthy cluster of six servers, a split-brain occurs when the connection between some of these servers breaks for some reason and, anytime you have network connections they can break. And, we see that all the time. So, when that happens that sub clusters are formed. Let's say, in this case there's a split 1, split 2, split 3. Each sub cluster thinks it's the survivor. So, it creates its own cluster coordinator and becomes an independent cluster.
Split Brain Detection
- Split detected upon reconnection with servers
- Split recovery process initiated
However, all these splits remember that they used to be part of a healthy cluster and these servers did not leave willingly, they did not leave in a smooth fashion. You did not do a ‘leave node’ from the NCache Management Tool instead the connection broke. So, they will keep looking for these servers to see if the network connection is restored. And, most of the time maybe five, ten minutes, half an hour, an hour later that connection will be most likely be restored.
Split Brain Recovery
- Sub-clusters merged iteratively from largest to smallest
- Smaller cluster clients are moved to larger cluster
- Smaller cluster data lost
When that happens, a Split Brain Recovery is done. And, that where these splits are merged. These sub clusters are merged in an iterative fashion from largest to smallest, and, there's some data loss obviously because these became independent clusters and, now some of the data has to be lost. But it's all done automatically based on the rules that you specify.
There's more detail about the split brain in a separate video but this kind of gives you an overview. It is a very important feature that ensures that your NCache cluster stays healthy and can recover whenever a split brain occurs.
Caching Topologies
Okay, now, let's move into Caching Topologies. Caching Topologies is essentially data storage, replication strategies, and also the client connection strategies. There are four topologies, one is Partitioned Cache, Partition Replica, Replicated Cache, and Mirrored Cache. Let's go with Partitioned Cache.
Partitioned Cache
- Cache divided into partitions at runtime
- One partition per cache server. 100 buckets for the entire cache cluster distributed evenly
- Adding / removing server creates / deletes partition
Partitioned Cache is basically that the entire cache is broken up into partitions, every server has one partition. And, there are this concept of buckets. So, every partition has buckets. A total of 100 buckets for the entire cache. So, depending on how many partitions you have that those buckets are evenly divided among them.
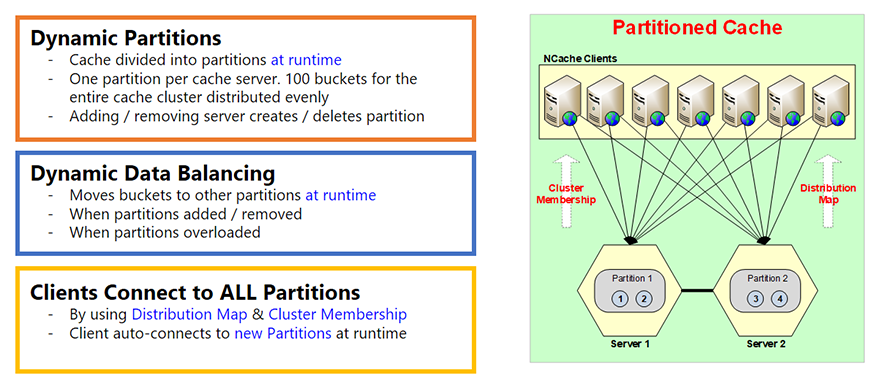
And, these partitions are created at run time that's the important part in this. So, as you add a server a partition is created. Let's say, you start with one server, there's only one partition, all the 100 buckets are in that partition. If you add a second server at runtime not only is the cluster membership information updated which I mentioned in in previous slides but now distribution map is also updated. A distribution map essentially is a map of which partition contains which buckets. So, let's say, if you added a second partition the distribution map will now be changed. A distribution map is actually, it's a hash map mapping to buckets. The hash map value ranges to buckets. And, this does not change based on how much data you've added, it changes only when you change the number of servers, the number of partitions, or you do the data rebalancing. So, the partitions are dynamic.
Dynamic Data Balancing
- Moves buckets to other partitions at runtime
- When partitions added / removed
- When partitions overloaded
The second part is that there's dynamic data balancing. So, because this is all hash map based, it is very possible that based on the type of keys you used that some of the buckets will get more data than others. And, you will end up with some partitions almost being full and, the others are almost empty. And, when that happens the NCache has this feature where you can set a threshold. Let's say, if a partition becomes more than 80% full remove 20% of it, or 10% of it, or 5% of it. Not remove, I mean dynamically balance it out. So, data balancing means taking those buckets from partition 1 and copying them to other, or moving them to other partitions. So, data balancing ensures that the data and all partitions is fairly even.
Client Connects to All Partitions
- By using Distribution Map & Cluster Membership
- Client auto-connects to new Partitions at runtime
In Partitioned Cache every client connects to all the partitions or all the servers. The reason it does that is because it wants to directly access whichever item it wants in one call. If it were only connected to one server, let's say, and it wanted item number 3, it will talk to server 1, Server 1 will go to server 2 and get it. And, that's a two-hop operation which is not as optimized as if the client could directly go where the data was. And, the client knows that because of a distribution map. That's why the distribution map is created to help the clients know where the data is, so, they can directly go and get it from there.
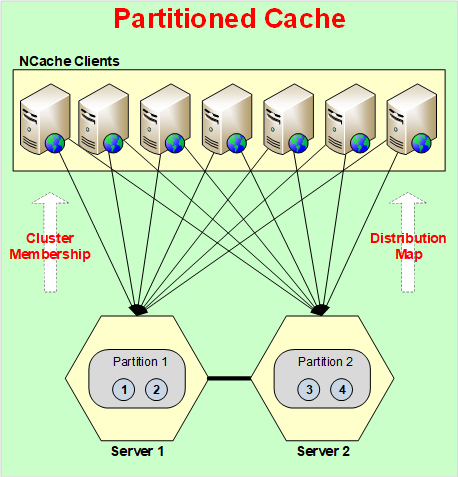
So, Partitioned Cache has no replication. So, if any server goes down you lose that data. There's no way except if you use ‘Persistence’ which I'm going to talk about in a bit. Then even Partitioned Cache does not lose any data.
Partition-Replica Cache
Replicas of Partitions (Dynamic)
- Created at runtime when partitions added / removed
- Located on different server than the partition
- No clients talk to them. Clients talk to Partitions.
Partitions talk / replicate to Replicas.
The next topology is the Partition-Replica Cache. This is our most popular topology by the way because it gives you best of both worlds. It gives you the partitioning, which is the scalability. And, it also gives you replication which is the high-availability. So, there's no data loss. So, for example, it's the same way as Partitioned Cache, everything is the same but every partition now has a replica on a different server. So, partition one is on Server 1 then its replica is called Replica 1 which is, let's say, in this case on Server 2. So, just like the partitions were created dynamically at time the replicas are also created at runtime, when the partitions are added or removed. And, they're obviously located always on a different server.
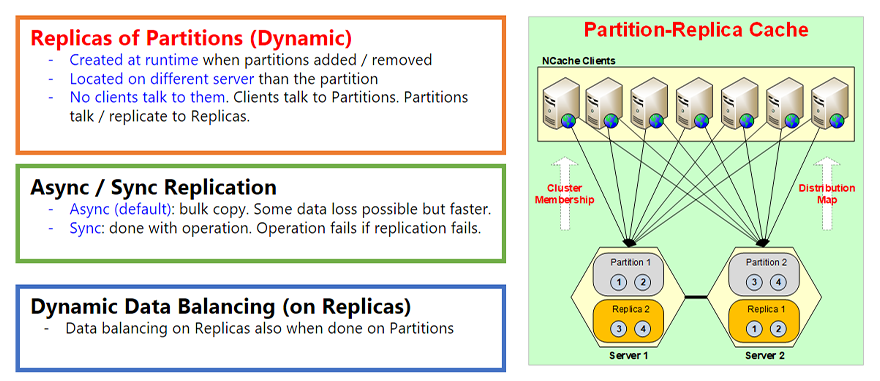
The other part is that all the replicas are passive. Passive means no clients talk to them directly. The clients means these only talk to the partitions and, the partitions then update their replica. So, whenever you update something in partition the partition updates it in the replica. And, that update by default is asynchronous. Asynchronous is, so that it can be faster. First of all the client does not have to wait for that replication to happen, second you can do a bulk replication. So, you can combine hundreds or thousands of those updates together and move them or push them to the replica at once. Because, the cost of this network trip is much faster or much costlier than combining data.
Async / Sync Replication
- Async (default): bulk copy. Some data loss possible but faster.
- Sync: done with operation. Operation fails if replication fails.
However, the async replication obviously has that it's not always consistent. It is eventually consistent which is good enough for maybe 95% to 99% of the times and, there's maybe 1 to 5% of the cases where you are dealing with very sensitive data. So, you don't want asynchronous replication, you want synchronous replication. So, there's a feature called Sync Replication you can turn that on, and when you do that then whenever the client updates items in partition that operation does not complete until the partition updates the replica first. So, if that replication fails the operation fails. So, that's how, you know, that if the operation succeeded the replication also succeeded. So, that's a very important feature of this.
Dynamic Data Balancing (on Replicas)
- Data balancing on Replicas also when done on Partitions
And, then finally just like partitioned topology, partitioned cache topology there's also Dynamic Data Balancing on the replicas as well. So, when the partitions are dynamically data balanced then the replicas have to match that because the replicas are always an identical copy of the partition. So, they will also go through a data balancing.
Dynamic Partitioning
Let's quickly now go through how dynamic partitioning really occurs. So, let's say, if you had a two server cluster and, you had 6 items in it and you wanted to add a third server, I'm not adding more data yet because that's another use case, this is just how the data is shifted to other partitions as you add another node.
Let's say, you add a node. So, there's a third server now. So, Partition 3 is created and Partition 3 now gets data from Partition 1 and Partition 2. So, it gets some data from 1 some from 2. So, say let's, say it takes Item 3 from Partition 1, Item 4 from Partition 2 and becomes Partition 3.
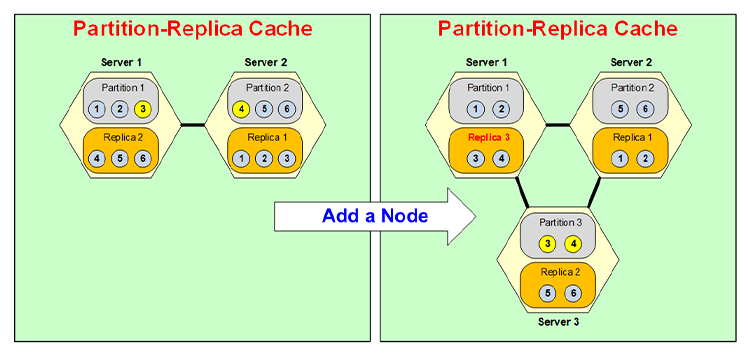
Now, that it became Partition 3 its replica has to be on a different server, so, let's say, it gets put on Server 1. So, Server 1 used to have Replica 2 it gets converted into Replica 3 and then Replica 2 gets moved into Server 3. So, for example, now Replica 3 will contain 3, 4 instead of 4, 5, 6, and Replica 2 will contain 5, 6. All of that is going to be done dynamically at run time without your application seeing any interruption.
The same thing happens backwards that if a server goes down, let's say, you had a three partition NCache Cluster and, Server 3 went down, either you brought it down or it went down, as soon as that happens, because Partition 3 is no longer available Replica 3, as you can see I changed its color, it becomes active. Normally, as I said, replicas are not active, right? Only the partitions are active but now this becomes a partitioned. But, it's only temporary because you don't want to have two partitions on the same box and then no replica.
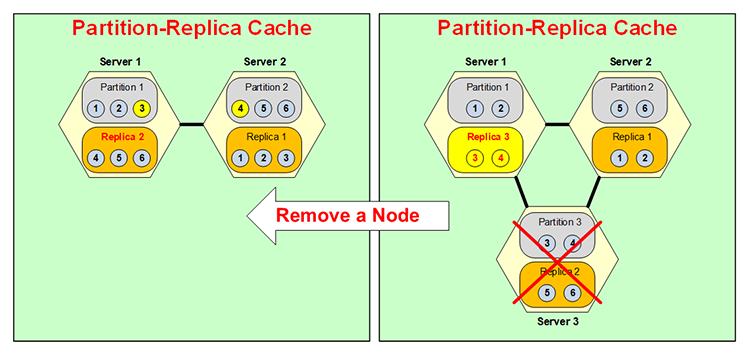
So, now this merges itself here with Partition 1, so, let's say, Item 3 goes to Partition 1, Item 4 goes to Partition 2, and your situation is like this here and, this Replica 3 now becomes Replica 2. So, the same thing happens backwards, all at runtime, Dynamic Partitioning, very very flexible, very dynamic. This dynamicness adds the high availability power of NCache.
Maintenance Mode
Well, although that dynamic partitioning is very useful and very powerful but, there are some cases where you don't want to repartition and one of those cases is scheduled maintenance. Let's say, you are doing an operating system patch and, that patch is going to be bringing the server down for five minutes or ten minutes. Well, you know, that your entire cache cluster might have tens of gigabytes of data. So, you don't want to repartition just for that five minutes and then repartition again when you bring that node back up. So, you can turn on a schedule maintenance feature of NCache in which case when you bring this node down, again you have to bring it down through your Management Tool, it triggers things that this replica becomes active but there's no repartitioning.
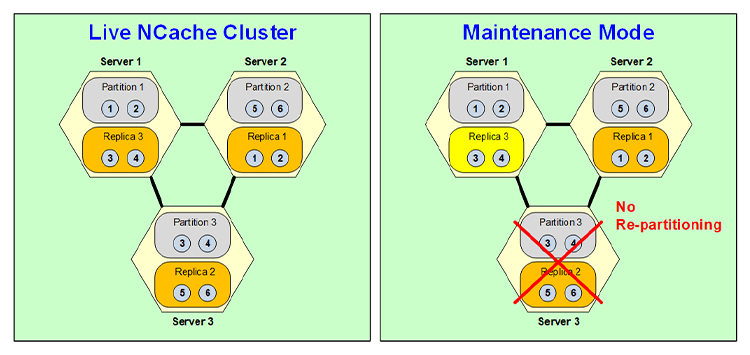
So, it stays as two Server configuration with Partition 1 Replica 3, Partition 2 Replica 1 and, this Replica 3 is actually Partition 3 which is means it's active and it operates. Obviously, it's not high availability because although Partition 1 is backed up here. Partition 2 has no backup and Replica 3 has no backup. But, this is only temporary because you only need it for 5, 10 minutes. So, once this server comes back up it goes back to the old state and becomes a replica again when this becomes a partition again. So, that's how the scheduled maintenance feature of NCache works.
Replicated Cache
The next topology is called a Replicated Cache. In this topology you can have two or more servers where every server has an entire copy of the cache and every server is active which means every server has clients connected to it. But, here every client only connects to one server. Because, that server has the entire cache. So, it does not need to connect to two servers like partition or partition replica.

This topology, all the reads are super-fast because the entire cache is right there but, the updates have to be done synchronously. Because, both of these are active servers so, the same item could be updated here and here simultaneously and you obviously don't want to go into a data integrity issue. So, it's done in a synchronous fashion where there's an indexing scheme, there's an index, there's actually like a sequence number that is issued, and every item is updated in the same sequence. So, that allows the updates to be done always in a correct fashion. However, the cost is that a synchronous update means that if you have a client that updates Item 1, this Server will notify Item 2 to update Item 1. When both servers have updated Item 1 successfully only then the update is successful, and the control goes back. So, that means it's not as fast as Partition or Partition Replica topology but the operation is guaranteed to be, if that update succeeds that means it's always done to all the servers.
This topology is good for read-intensive operations. For a two-server cluster even the writes are pretty fast, not as fast as partition replica but reasonably fast for most situations. However, as you add more servers that performance of updates drops. Actually, it becomes slower because more servers have to be updated synchronously. So, this this topology has its own uses that's why we keep it. Many of our customers do use it in special situations.
Mirrored Cache
The fourth topology is called the Mirrored Cache. This is again a very specific topology. It's a 2-node topology only. There's an Active and a Passive node. Again, the active node has the entire cache, and a copy of the cache, sits on the passive node. All the clients connect to the active node, and they update the active node for all the stuff, and the updates are asynchronously mirrored or replicated to the passive node. And, that asynchronous means it's also pretty fast just like Partition Replica.

In this topology if active node ever goes down the passive node automatically becomes active and all the clients automatically move to the passive or the newly active node. And, that way there's no downtime, there's no interruption and, that's called the auto of failover support, that's what I meant by that. And, then obviously when the active node comes back up this becomes active again the same thing happens in reverse.
So, Mirror Topology also is very useful for specialized cases. It is not scalable beyond these two servers but it's got its own use because of the fact that all the clients connect here, and then you can do a replica onto a different box. I mean this could be used for example, in case of disaster recovery situation for example.
Live Persistence
Another very powerful feature of NCache is called Live Persistence. Live Persistence is available for partition and partition replica topologies only, and it is live which means as you update the cache at runtime the persistence store is also updated immediately. The update to the persistent store is asynchronous. So, it does not interfere with your application performance or NCache performance. So, that's how your application can stay very fast. The persistence is done at bucket level. So, there are 100 buckets that represent the entire cache that are kept in a NoSQL document store. It's a file based store, so it's not a server-based store. It's not a NoSQL database server, it's a NoSQL document store that NCache uses. You can use it in a common location that is common to all the servers in the NCache cluster, and that way they can all rely on the same persistent store.
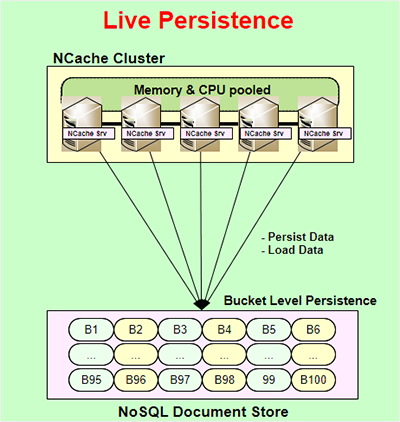
Some of the benefits of this are, and the reason this feature is provided, number one that whatever you are persisting you can, for example, persist the entire cache, and the entire cache is always persisted. You can say that whatever you're updating in the cache is, you know, with the difference of a few milliseconds it's also kept in the persistent store. So, you can take that and reload that into a different cache, or if all the servers were to go down you can always restart them from the persistent stores. You don't lose any data except very very small amount of data. Or maybe you want to take cache from one environment to the other you can easily do that.
The other benefit is that it actually adds more high-availability to partition and partition replica topologies. Well, partition topology, and I'll go into that here. So, Partitioned Cache as I mentioned earlier does not have any replication, so, if any partition, any server were go down you lose that partition, right? Well, if you have persistence on then you don't. Because, a copy of that data is also being kept in these buckets. So, if this server were to go down the buckets in memory get reassign but obviously without data to other servers and now those servers know that these are empty buckets whose data exists in the persistence store, so, they will reload that data from the persistence store.
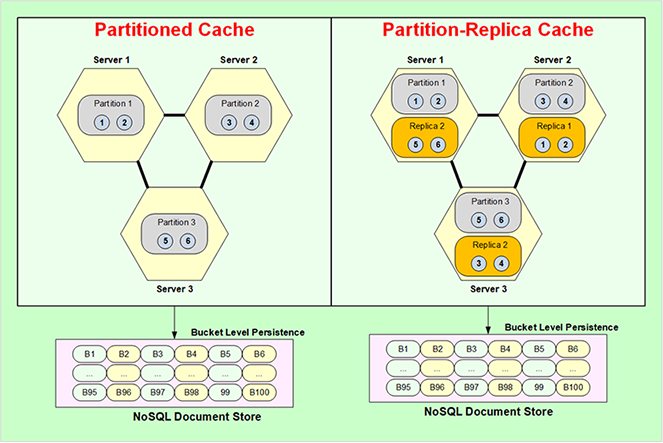
So, that's how you don't lose any data even if a server goes down, even though you're using Partitioned-Cache. And, you have the same benefit as a Partition Replica as Partitioned-Cache.
The benefit you'll get here is that you can use more memory. You can store more data in the cache because here you have to allocate more memory for replica which you don't have to allocate here but, you do have to allocate the persistence store. So, that's the benefit in Partitioned Cache. There's also benefit in Partition-Replica. And, it's kind of interesting that although this is already giving you high availability but if the high ability happens only if one server goes down at any one point in time but, let's say, if two server were to go down simultaneously without the persistence even in Partition-Replica you would lose data. Because, you know, there's only one copy of every partition and if two servers were to go down then you've lost more servers than you can afford to. Well with persistence you don't have any problem, you can just reload all of that data from the persistence store.
Obviously, in both cases, you have to keep in mind that whenever you load data from persistence store you had three servers now you have two. Well, the data may be worth too big to fit in the two servers that may be another issue that you have to deal with is to make sure that you have enough memory on these two remaining servers so that it can accommodate the equivalent of all three servers. So, that's the only limitation. Otherwise, persistence really adds value to both the Partitioned and Partition-Replica cache.
Client Cache
Okay, another very important feature of NCache is called Client Cache. It gives you an InProc speed in a distributed store environment. So, for example, you have a distributed NCache cluster, your application is running here, this is usually a cache on top of your database or whatever else you're doing, a Client Cache is usually used when you have a distributed cache scenario, and a Client Cache is a cache on top of this cache cluster, and it sits very close to your application. It sits on the application server or the NCache client box. And, it can even be InProc or OutProc depending on your preference. An InProc cache is super-fast because it actually keeps the data in a deserialized object form on your heap. So, it's like having that object on your heap. It can get faster than that.

So, an InProc cache is super-fast but at the same time the beauty is that it is synchronized with the NCache cluster. And, the way it's synchronized is whatever is kept in the Client Cache the cluster knows about it. So, if something that was kept in this Client Cache another Client updates in the cluster, the cluster notifies that Client Cache to go and update itself. And, then that Client Cache updates itself asynchronously. Obviously, there's a few millisecond delay but that's, you know, as I said eventual consistency is the model in most cases, and that's usually acceptable for 99% of the cases.
If that is not acceptable then NCache provides you … and the optimistic synchronization is the default which is where there's a few millisecond delay and there could be technically a situation where you have stale data, which is okay as I said 99% of the time. But, let's say, if it weren't okay and your data was very sensitive but you still wanted to use the Client Cache then you could use a pessimistic synchronization capability where it makes sure that before your application fetches anything from the Client Cache the Client Cache checks only to see if there's a newer version of that data, that's a faster call than getting the data itself because, NCache then keeps multiple versioning information. And, then if there's a newer version of that data then the Client Cache fetches it, if not then it'll just gives it back from the Client Cache.
A Client Cache you can use without any code changes. It just plugs into your environment, and it is good for read-intensive situations. Where you're doing a lot more reads at least 5:1, 10:1 is ideal but when there's 1:1, let's say, in case of web sessions then Client Cache actually does not help at all. In fact, it's not recommended at all.
WAN Replication
Multi-Zone / Multi-Region
Okay, another part of NCache is the where NCache does WAN Replication to handle multi-zone or multi-region deployment of your applications. So, for example, you could have your application deployed on two different sites for DR, for Disaster Recovery, one is active one is passive. And, you've got this application, an NCache running with it, and you have an application here which is not running. But, you want to make sure that if this site were to ever go down this will immediately be able to pick up the load. So, you can put a bridge. A bridge is a 2-node cluster itself which can be on the same boxes as the NCache main, or it could be a separate dedicated one it's up to you. And, then whatever you update in this cache is asynchronously replicated across the WAN to the other cache. So, that's the active-passive.

You can do the same thing with an active-active. Let's say if you have a situation where even this site is active what you can do the same exact thing with an active-active where both sites can update each other. In that case, there's also a situation where conflict may resolve, may arise. And, what a conflict means is that the same item, the same key is being updated on both sites simultaneously. If that happens the bridge by default applies the ‘last update wins’ logic. So, whichever has the later time stamp that update wins. But, for example, if you wanted you could also provide a conflict resolution and conflict resolution handler which is your .NET or Java code that the bridge will call, and it'll pass both copies of the data or the object to that resolution handler and then you can analyze the content to determine which one is more correct, and then you say, okay, this update wins and then that update gets applied to both sites. As long as that gets applied to both sides then there no conflict.
The NCache has the ability to give you three or more sites in an active-active, or active-passive, or some combination of those. So, for example, you need at least one active but then these could all be passive or these could all be active or it could be a combination of active or passive. And, again the same way when there's more than one active this could be conflict resolution.

Containers (Docker and Kubernetes)
Finally, containers have become really popular Docker and Kubernetes. So, NCache obviously supports them because they're more popular on the Java and Linux side than they are on .NET and Windows side yet but, I'm sure that's going to change, you know, with time. So, either way, NCache is fully capable of handling it in both environments. So, for example, here's a typical Kubernetes deployment of NCache.

Here's an NCache deployment. There’s NCache got its own Discovery Service. These are pods that can scale and then you have applications within Kubernetes cluster that are NCache clients and this could be either Azure, AKS, AWS, EKS, Google GKE, or Red Hat OpenShift. Red Hat OpenShift usually is either another cloud like AWS, Azure, or Google or maybe another Cloud but NCache supports all of them. And, this Pod could be Linux which is the case with more common in Kubernetes, and NCache works perfectly fine. And, the application can also be Linux or Windows. So, these could be either Linux or Windows, Linux or Windows.
Docker / Kubernetes (Multi-Zone)
The same way the WAN replication kicks in also that if you wanted to, let's say, because of cloud you can have multiple availability zones. You wanted to do a multi-zone Kubernetes.

So, the way we recommend is you create one Kubernetes cluster, have two NCache deployments, these could be active-active or active-passive. And, then the bridge can either sit completely here, or completely here. Or you can even have a bridge split where one part is on this zone and one part is on that zone and then the replication happens asynchronously.
I think that pretty much covers the topic today. I will strongly recommend that you come to our website and either take a look at NCache Playground which is really a very quick and easy way from your browser to use a live running copy of NCache, and you can even get a 2-Node NCache Cluster with all the tools without any installation effort. Or if you are ready just come here and register and download either NCache Enterprise for .NET Edition or NCache Enterprise for Java Edition. As I said, you can get either the .tar.gz for Linux, .msi, or you could also get the Docker. You can just pull a Docker image of NCache. That's the end of my presentation. Thank you very much.