Lucene is a .NET full-text search engine library that contains powerful APIs for creating full-text indexes and implementing advanced and precise search technologies into your programs. Lucene offers much more than what you would expect from other text searching engines as the choices given to the user are multiple. It has a powerful searching algorithm and supports a wide range of queries for searching.
Although as powerful as Lucene is on its own, it is not without limitations. Lucene runs in-process in the client application and Lucene applications typically write data on a file and store it on the disk, resulting in a huge memory allocation. However, it is a stand-alone solution that does not scale as your data grows, you need to rebuild entire Lucene indexes to search data which is an expensive and slow task, that can result in a performance bottleneck. This means that Lucene isn’t scalable, and it has a single point of failure.
NCache Details Downlod NCache NCache Docs
How Distributed Lucene Helps You
NCache provides a distributed implementation of Lucene which makes Lucene applications scalable. NCache being distributed in nature with Lucene provides linear write scalability as the documents indexed by the applications are automatically distributed among cache nodes where they are separately indexed.
Similarly, Distributed Lucene also provides linear read scalability since queries are propagated on each partition and results are merged. A higher number of partitions provides a higher amount of read and write scalability. Lucene indexes are persisted on the physical drive. The more the nodes, the higher the scalability, performance, and storage capacity to accommodate a large number of Lucene documents and indexed data.
NCache Details Download NCache Distributed Lucene Docs
How Distributed Lucene works
Distributed Lucene contains multiple server nodes, each server of NCache has a dedicated Lucene module. The behaviors and working of Lucene and Distributed Lucene are similar, apart from a few changes.
The diagram below shows how Distributed Lucene model works.
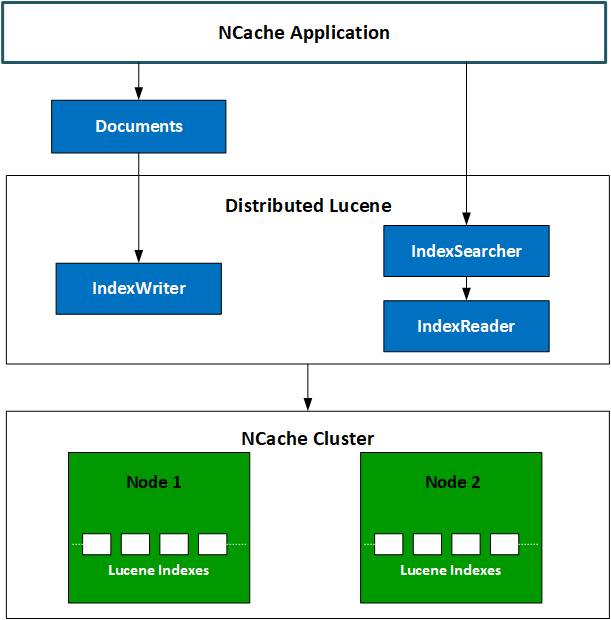
NCache Distributed Lucene Architecture
The client application may want to index documents or query existing indexed documents using the Lucene API. These interactions with the API act like Remote Procedure Calls (RPCs) between the client and server. API calls are directly forwarded to the Lucene modules attached to each server node. Lucene modules execute these calls, and depending on the nature of the calls, either of the following actions takes place:
- In case it was a query call, the Distributed Lucene modules return results to the client-side, where all of these results are merged and processed.
- In case it was a call to index a document, the Distributed Lucene Modules persist that document on a disk drive.
NCache Details Distributed Lucene Docs Distributed Lucene Cache
Data Distribution
A distribution map is generated against the NCache cluster for Distributed Lucene. This map contains information regarding the bucket’s distribution against the cache nodes. These buckets (100 buckets exist in the map) are distributed in the cluster using a specific strategy. The addition or removal of a node from the cluster will change the distribution map and trigger state transfer for the running server nodes, which transfer buckets with indexed data on the respective node.
Having 100 buckets means that a Lucene index is split into 100 sub-indexes across the NCache cluster. A single bucket contains a sub-index, which is the same as a Lucene index in Lucene.Net. A server node can contain multiple indexes, and each index within that server node contains buckets that are assigned to it according to the distribution strategy of the cluster. The data inside the indexes are evenly distributed via these buckets.
How to Start with Distributed Lucene
Distributed Lucene works just as Lucene does. One major comfort of using distributed Lucene is that it gives you the same API as Lucene. As a Lucene user, you get the scalability you wish for with an add-on of a single-line code change. You just have to use NCache Directory and your application is good to go. There are very few behavioral and API changes in distributed Lucene which are listed in the documentation.
Let us take a closer look at these steps from a technical aspect, and the primary step is to replace the Lucene.NET Nuget package from your library with Distributed Lucene Nuget package Lucene.Net.NCache.
Connecting to NCache Directory
NCache Directory, as the name suggests, is a base class for storing the indexes for making the indexes scalable. So, the first step is to connect with the NCache Directory.
Given below is the code which connects you to a cache named luceneCache and opens the provided directory at all the servers.
|
1 2 3 4 5 6 7 8 9 |
// Specify the cache name that is used for Lucene string cache = "LuceneCache"; // Specify the index name to create the indexes string indexName = "ProductIndex"; // Create a directory and open it on the cache and the index path NCacheDirectory ncacheDirectory = NCacheDirectory.Open(cache, indexName); |
NCache Details Distributed Lucene Geo-Spatial API Initialize Distributed Lucene
Index Data in Distributed Lucene
Once the directory is initialized, IndexWriter creates documents on the index with the same mechanism as in Lucene.NET using AddDocument method. When the document is written, IndexWriter.Commit is called to persist the document and make it searchable.
Distributed Lucene allows you to open multiple writers on the same directory for parallel indexing. The code sample below demonstrates how you can index your documents with Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// Create an instance of the writer IndexWriter indexWriter = new IndexWriter(ncacheDirectory, new IndexWriterConfig(LuceneVersion.LUCENE_48, new WhitespaceAnalyzer(LuceneVersion.LUCENE_48))); // Indexing // Add the products information that is to be indexed Product[] products = FetchProductsFromDB(); foreach (var prod in products) { // Create a document and add fields to it Document doc = new Document(); doc.Add(new TextField("ProductID", prod.ProductID, Field.Store.YES)); doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO)); doc.Add(new TextField("Category", prod.Category, Field.Store.YES)); doc.Add(new TextField("Description", prod.Description, Field.Store.YES)); // Writer is created previously indexWriter.AddDocument(doc); } // Calling commit on the writer saves all the write operations indexWriter.Commit(); // Dispose the objects after indexing indexWriter?.Dispose(); ncacheDirectory?.Dispose(); |
NCache Details Distributed Lucene Facets Distributed Lucene Indexing
Searching in Distributed Lucene
Searching can be performed after indexing the data. The IndexSearcher uses the IndexReader for fetching the results. The IndexSearcher is responsible for searching the data according to the given queries. Lucene provides a wide range of queries, and Distributed Lucene supports all the Lucene queries.
The code sample below demonstrates how you can search your indexed documents with Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Open a new reader instance IndexReader reader = DirectoryReader.Open(ncacheDirectory); // A searcher is open to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify analyzer type Analyzer analyzer = new WhitespaceAnalyzer(version); // Create a query parser and parse the query with the parser //Specify the searchTerm and the fieldName QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, "Category", analyzer); Query query = parser.Parse("Beverages"); // Returns the top 10000 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs; indexSearcher?.Dispose(); reader?.Dispose(); |
NCache Details Distributed Lucene Counters Distributed Lucene Search
Use Native Lucene Indexes with Distributed Lucene
If you already have a .NET application using Lucene, the chances are that you might have a large Lucene index built. NCache provides the Import-LuceneIndex cmdlet, which enables users to import an existing Lucene index into NCache Distributed Lucene without requiring to rebuild indexes.
This example command loads the native Lucene index from C:\Index to a Distributed Lucene store demoCache.
|
1 |
Import-LuceneIndex -CacheName demoCache -Path C:\Index -Server 20.200.21.11 |
NCache Details Distributed Lucene Docs Import Lucene Indexes
Conclusion
Lucene is a highly efficient search engine for performing full-text searching on your data but it lacks scalability. NCache can be used with Lucene to make it scalable with very little effort. Scalable distributed Lucene makes your application not just faster but also helps you deal with the major setback of a single point of failure. NCache can be easily plugged into your .NET Application with a single-line code change so consider it the best possible option for your scalable Lucene application.




