Modern applications typically process and generate large volumes of data. Thus, the possibility of data loss due to a single web server/data source failing is a common nightmare among software developers. However, high data availability is still achievable if all the application server nodes contain an identical copy of the data. This replication process ensures that there won’t be any data loss if a few nodes fail in the cluster. However, what happens when the data begins to expand? In these cases, you must dial back replication and begin partitioning the data.
NCache being a distributed in-memory caching solution provides linear scalability, improved performance, and high availability for data-intensive applications. It lets users divide data into multiple chunks (buckets) and place them in different partitions, evenly spreading out the read and write operation loads. Additionally, when employing the Partition-Replica topology each node in the cluster has a backup of another partition that acts as a passive partition called a replica. In case of a node failure, the cache cluster knows that the data owned by the lost partition is still available in its replica.
This solves the initial scalability problem by dividing the data, and offers high availability through the Partition-Replica topology, but how exactly is the data partitioned equally and what effects does that have? This blog aims to educate you about how data partitioning takes place in NCache.
Key Takeaways
Linear Scalability: NCache achieves high scalability by dividing data into 1,000 logical buckets, which are distributed across all nodes in the cluster.
Deterministic Lookup: Unlike Round-Robin, NCache uses Hash-Based Partitioning. This allows clients to use a Distribution Map to locate data with O(1) complexity, avoiding expensive broadcast searches.
High Availability: Through the Partition-Replica Topology, each data partition has a backup (replica) on a different node, ensuring no data loss if a server fails.
Intelligent Rebalancing: When nodes join or leave, the State Transfer engine moves only the necessary buckets in the background. This minimizes network overhead and keeps the cache fully available.
Automatic Load Balancing: NCache periodically exchanges bucket statistics between nodes to ensure an even data distribution based on actual load and quantity, rather than just item count.
Hash-Based Partitioning for Equal Data Distribution
More often than not, applications employ a round-robin strategy when assigning data to different partitions. While this approach guarantees even distribution, it presents a challenge when it comes to locating specific data items. Data search and retrieval can become time-consuming and ineffective when using such a strategy as there is no way to track item locations.
| Feature | Round-Robin | NCache Hash-Based |
|---|---|---|
| Data Placement | Sequential/Cyclic | Deterministic (Key-to-Bucket) |
| Key Lookup | Broadcast Search (Ask all nodes) | Direct Access (Via Distribution Map) |
| Lookup Complexity | O(n) cluster-wide | O(1) cluster-wide |
| Rebalancing | Simple | Data-Centric & Automatic |
To resolve this issue, NCache incorporates Hash-Based Data Partitioning. Therefore, data is split into buckets which are subsequently dispersed among several partitions. The goal is to evenly distribute buckets across all the nodes in the cluster to optimize performance and ensure high availability. To achieve this, NCache employs a hashing technique that maps each data item to a specific bucket based on the item key. Thus, to figure out the owner of the bucket, you only need to apply the hash function on the item’s key and mod it by the total number of buckets (1000).
What is a Distribution Map?
The coordinator server node is essential in a distributed cache cluster as it oversees bucket distribution and ensures that each and every item is assigned to a particular bucket based on its key. To achieve this, it creates a distribution map. This map includes the bucket distribution. It then distributes these buckets to all other partitions in the cluster, as well as, to all the connected clients as appropriate.
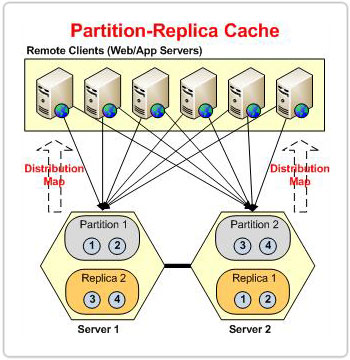
Figure 1: Data Redundancy in NCache Partition-Replica Topology.
No matter how many servers are in the cluster, NCache ensures that each item is given a consistent bucket address through this method. This is because the distribution map remains constant, even if the number of servers in the cluster changes. As a result, even if a bucket moves from one partition to another at any stage, the bucket address of an item remains the same. This guarantees that the data stays intact, and no data is lost during bucket movements.
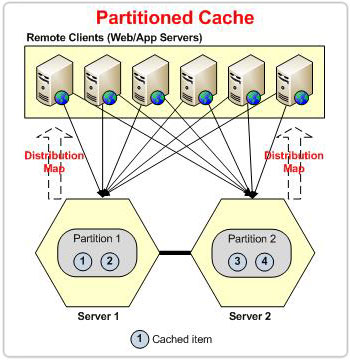
Figure 2: NCache Partitioned Topology with Dynamic Distribution Map.
In case of the Partitioned topology, whenever a node leaves the cluster, the cluster experiences data loss. The buckets owned by the leaving node will all be lost. However, in case of Partition-Replica, the replica is present on another node that will be redistributed on the basis on the distribution map – preventing data loss.
Data Distribution Based on a Distribution Map
Data is spread equally among all nodes in the cache cluster based on the NCache dynamic bucket distribution. All 1000 buckets are assigned to the node when you start a cache cluster. This results in all the data being stored in a single partition. To provide the best performance and load balancing, the buckets are then divided equally throughout the partitions when more nodes are added to the cluster.
The 1000 buckets, for instance, are divided equally between the two partitions when a second node is added to the cluster, giving each split 500 buckets. Similarly, when a third node enters the cluster, the buckets are redistributed, giving each partition 333, 333, and 334 buckets, accordingly.
Architectural Insight: Efficiency & Availability
Consistent Hashing via Fixed Buckets: NCache uses a fixed map of 1,000 logical buckets. Since the Key-to-Bucket mapping is constant, adding or removing nodes only requires moving a fraction of the total data, minimizing cluster-wide reshuffling.
Background State Transfer: Data rebalancing occurs via a non-blocking State Transfer engine. This process moves necessary buckets in the background, ensuring the cache remains fully available to clients with minimal impact on application performance.
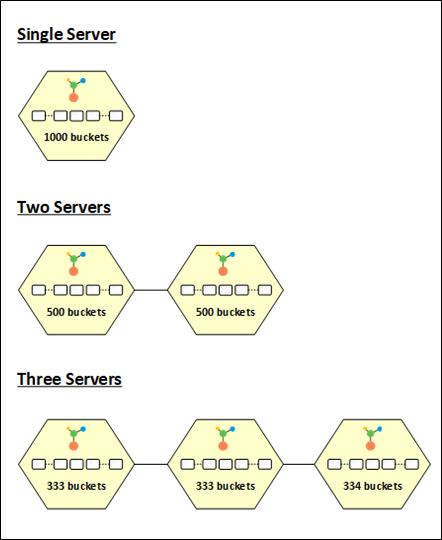
Figure 3: NCache Dynamic Bucket Distribution across Cluster Nodes.
Bucket distribution modifies once more if a partition leaves the cluster. to maintain an even distribution of the data. For instance, when a partition exits a three-node cluster, the 333 or 334 buckets that belong to that partition are dispersed across the two remaining nodes. NCache’s state transfer mechanism begins to rebalance the data between nodes. This happens whenever the bucket distribution changes. This setup ensuring that the data is distributed optimally in accordance with the established bucket distribution strategy. Similarly, the client also receives the distribution map that informs about the running server nodes and their hash-based distributions.
Data Load Balancing
While redistributing buckets across the cluster, NCache adopts a data-centric strategy. This ensures that the amount of data that each partition receives is balanced. Each partition in the cluster periodically exchanges the statistics of the buckets it owns with the other partitions in the cluster. This enables the creation of a balanced distribution map that accounts for the quantity of data each partition possesses. NCache automatically balances the data to ensure that each partition receives an equal share of data. It also allows users to balance data manually. You can read more about it here.
Conclusion
In conclusion, using Partition-Replica to divide data in NCache is an effective strategy for improving application speed and scalability. By splitting data into smaller segments and distributing them across multiple cache nodes, you can ensure data availability while reducing the risk of performance bottlenecks.
Frequently Asked Questions (FAQ)
Q: How does NCache determine which node owns a specific data item?
A: NCache applies a hash function to the item’s key and then performs a modulo operation by the total number of buckets (1000). The resulting bucket ID is then cross-referenced with the Distribution Map to identify the specific server partition.
Q: Can a client application locate data without asking the server cluster?
A: Yes. NCache provides the Distribution Map directly to all connected clients. This allows the client to calculate the exact server node location locally and jump directly to that partition for any read or write operation.
Q: What happens to the data if a node leaves a Partitioned Topology versus a Partition-Replica Topology?
A: In a standard Partitioned Topology, data owned by the exiting node is lost. However, in a Partition-Replica Topology, the cluster automatically promotes the existing replica on another node to active status based on the distribution map, preventing data loss.
Q: Does NCache allow for manual intervention in data distribution?
A: While NCache balances data automatically based on bucket statistics, it provides the flexibility for users to manually balance data through the management center or PowerShell if specific administrative control is required.