A Split-Brain in medicine refers to a communication malfunction inside the brain, where half of the brain is unaware of the other half’s behavior. In distributed computing, Split-Brain describes a similar scenario: a loss of communication between active servers within a cluster. This leads to sub-clusters forming and preventing synchronization, potentially resulting in chaos across your system.
The chances of Split-Brain occurring in your distributed system are exactly the same as in a functioning brain. If such a calamity befalls your system, there’s no recovering from that. Unless you are using NCache as your distributed cache. Only then do you have hope.
Key Takeaways
Automated Detection: NCache automatically identifies a split-brain scenario the moment network connectivity is restored between isolated sub-clusters.
Majority-Rule Resolution: The recovery logic prioritizes the sub-cluster with the maximum node count to ensure the least amount of data is sacrificed during the merge.
Deterministic Tie-Breaking: In the event of equally sized sub-clusters, NCache uses the lowest Coordinator IP address as a definitive tie-breaker to select the “winner.”
Data Integrity via Re-initialization: Nodes in the “loser” sub-cluster are automatically restarted and rejoined to the winner, clearing stale data to maintain a single source of truth.
Split-Brain in NCache Cluster
NCache creates self-healing dynamic clusters where servers are connected for seamless intra-cluster communication. However, like any distributed system, the NCache cluster can also face Split-Brain problem where one or more cache servers get disconnected from the rest of the cluster and form isolated sub-clusters. Much like the human brain during a Split-Brain event, your cluster becomes divided, with each sub-cluster unaware of the other’s existence.
Let’s consider a cluster of 5 nodes as an example. Initially, the cluster operates smoothly, efficiently caching, communicating, and processing data. Then, a network glitch occurs, splitting the perfectly functioning cluster into two separate halves.
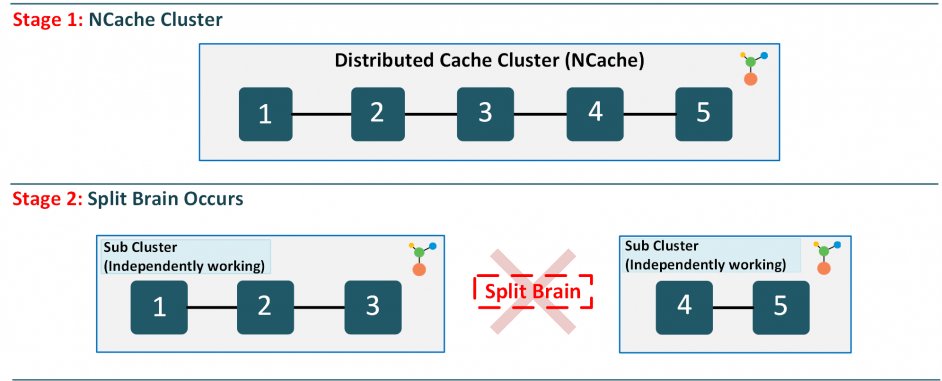
Figure 1: Split-Brain Occurrence and Detection in NCache Cluster.
In this Split-Brain scenario, each half of the cluster starts functioning independently, assuming the other half has failed. Consequently, both sub-clusters maintain their own copies of the data, with clients updating these copies without synchronization. This lack of coordination undermines the purpose of using a distributed cache, leading to cache operation failures and data integrity issues in your application.
How does NCache Recover from Split-Brain?
The first step of recovering from Split-Brain is to detect it in the cluster. And lucky for you, NCache is equipped with the capability to automatically detect such occurrences. NCache maintains cluster membership on all cache servers that comprise a cluster. So, whenever the connection breaks between the servers, the entire cluster is notified.
On top of acting individually as to not hinder the performance, the sub-clusters also keep trying to reconnect with the “lost cluster” to get the initial cluster back together. In the meantime, both sub-clusters log events to the Windows Event Log, indicating the state of the cluster. Additionally, NCache can send Email Notifications to the cache administrator, notifying them about the loss of connection with specific servers.
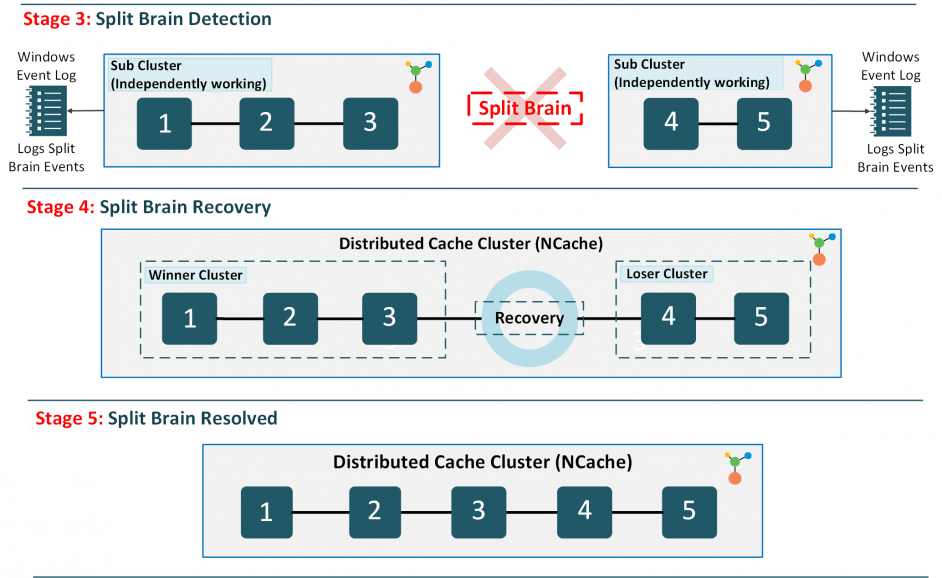
Figure 2: Split-Brain Detection, Recovery, and Resolution.
At this stage, neither half of the cluster is aware of the Split-Brain occurrence. It’s only when the network connection is restored and servers begin communicating again that the reality of the split becomes evident. If you have notifications enabled, you will receive alerts not only when a node disconnects but also when a Split-Brain event is detected.
Manual vs. Automated Recovery
| Feature | Manual Resolution | NCache Auto-Recovery |
|---|---|---|
| Admin Effort | High (Requires manual restart) | Zero (Fully Automated) |
| Service Availability | Interrupted (Manual intervention) | Continuous for “Winner” sub-cluster |
| Resolution Logic | Admin chooses survivor | Node Count (Primary) / Lower IP (Tie-breaker) |
| Data Integrity | High risk of manual error | Automated (Losing nodes cleared & rejoined) |
The NCache Split-Brain Auto-Recovery Process
- Split-Brain Detection: Once network connectivity is restored, NCache sub-clusters exchange heartbeats and recognize the existence of a split-brain scenario.
- Cluster Comparison: NCache evaluates the Node Count of all sub-clusters to identify the majority “winner”.
- Tie-Breaking Logic: If sub-clusters are of equal size, the sub-cluster with the lower Coordinator IP address is automatically designated as the winner.
- Losing Node Re-initialization: The winner sub-cluster triggers a restart of the “loser” nodes. These nodes clear their local data and rejoin the winning cluster to synchronize and restore data integrity.
Upon reconnection, the next step is to determine which of the two sub-clusters will be designated as the “winner”. The winning cluster is selected based on the following criteria:
- Node Count: The sub-cluster containing the maximum number of nodes. This is done to ensure minimal data loss.
- Coordinator Node IP Address: If both sub-clusters are of equal size, the one with the coordinator node having the lower IP address is selected as the winner.
Once the winner is decided, it takes on the responsibility of restarting the “loser” cluster and redistributing data among the nodes. Through all this redistribution, the loser cluster will lose its data, but on the bright side, the winner cluster continues to operate as usual. This ensures that the distributed cache maintains integrity even after a Split-Brain scenario.
Enabling Split-Brain Auto Recovery
By default, the Split-Brain Auto Recovery feature in NCache is disabled. You should enable this feature if your data cannot bear complete data loss. Provided below are the ways through which you can enable Split-Brain Auto Recovery for your cluster.
Using the NCache Management Center
You can easily enable Split-Brain Recovery for your cache cluster using the NCache Management Center. Please refer to the Enable Split-Brain Auto Recovery documentation to help you enable this feature.
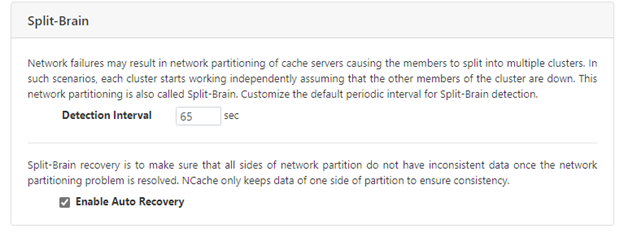
Figure 3: Enabling Split-Brain Auto-Recovery in NCache Management Center.
Using Cache Config File
Split-Brain Recovery can be enabled through the NCache configuration file. Manually edit the cache config file by following the steps mentioned here: Manually Edit NCache Configuration for Split-Brain Recovery.
|
1 2 3 |
<cache-settings...> <split-brain-recovery enable="True" detection-interval="60"/> </cache-settings> |
Conclusion
In conclusion, network glitches that divide your cache cluster into sub-clusters can jeopardize your cached data. Fortunately, NCache provides a robust solution with its Split-Brain Auto Recovery feature. By enabling this feature, you can rest assured that even if your cluster is temporarily split, NCache will seamlessly manage the recovery, ensuring data integrity and resume normal operations. With NCache, your distributed system is well-protected against the challenges of split-brain scenarios.
Frequently Asked Questions (FAQ)
Q: How does NCache detect a split-brain scenario?
A: Detection occurs automatically once the network connection is restored between isolated sub-clusters. NCache servers exchange heartbeats to identify the existence of parallel cluster memberships, triggering the auto-recovery logic to reconcile the two halves.
Q: What is the “Majority Node Rule” in NCache recovery?
A: NCache maintains cluster integrity by designating the sub-cluster with the highest number of nodes as the “winner.” This majority-rule approach is designed to preserve the largest portion of the cached data and minimize the impact of the network split on the application.
Q: How does NCache break a tie if sub-clusters are of equal size?
A: If two sub-clusters have an identical number of nodes, NCache uses a deterministic tie-breaker based on the Coordinator Node IP address. The sub-cluster whose coordinator has the numerically lower IP address is selected as the winner.
Q: Does NCache split-brain recovery result in data loss?
A: To ensure absolute data consistency and prevent “stale” data from merging, nodes in the “loser” sub-cluster are automatically restarted. While this clears the local cache on those specific nodes, the “winner” cluster remains operational, and data is redistributed to maintain a single source of truth across the restored cluster.



